Recurrent Neural Networks (RNNs) for Language Modeling with Keras
BasicSkill Level
4 Hr
16.3K learners
Een recurrent neural network (RNN) is een type kunstmatig neuraal netwerk (ANN) dat wordt gebruikt in Apple’s Siri en Google’s spraakzoekfunctie. Een RNN onthoudt eerdere input dankzij intern geheugen, wat handig is voor het voorspellen van aandelenkoersen, het genereren van tekst, transcripties en machinevertaling.
In het traditionele neurale netwerk zijn input en output onafhankelijk van elkaar, terwijl de output in een RNN afhankelijk is van eerdere elementen binnen de reeks. Recurrente netwerken delen ook parameters over elke laag van het netwerk. In feedforward-netwerken zijn er verschillende gewichten per knoop, terwijl een RNN dezelfde gewichten binnen elke laag van het netwerk deelt en tijdens gradient descent de gewichten en bias afzonderlijk worden aangepast om het verlies te verkleinen.
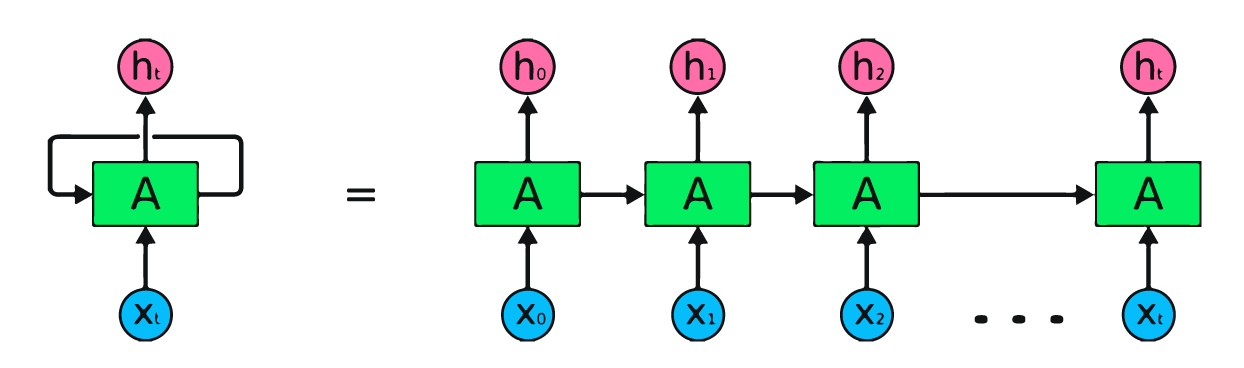
De afbeelding hierboven is een eenvoudige weergave van recurrente neurale netwerken. Als we aandelenkoersen voorspellen met eenvoudige data [45,56,45,49,50,…], bevat elke input van X0 tot Xt een vorige waarde. Zo heeft X0 45, X1 56, en deze waarden worden gebruikt om het volgende getal in een reeks te voorspellen.
In een RNN circuleert de informatie door de lus, dus de output wordt bepaald door de huidige input en eerder ontvangen inputs.
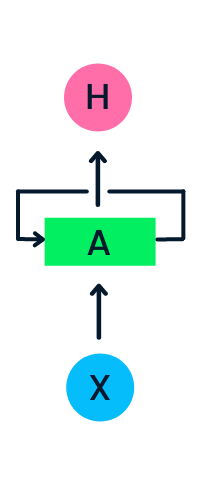
De inputlaag X verwerkt de initiële input en geeft deze door aan de middenlaag A. De middenlaag bestaat uit meerdere verborgen lagen, elk met eigen activatiefuncties, gewichten en biases. Deze parameters zijn gestandaardiseerd binnen de verborgen laag zodat er, in plaats van meerdere verborgen lagen te maken, één wordt gemaakt die wordt herhaald in een lus.
In plaats van traditionele backpropagation gebruiken recurrente neurale netwerken backpropagation through time (BPTT)-algoritmen om de gradiënt te bepalen. Bij backpropagation past het model de parameter aan door fouten van de output naar de inputlaag te berekenen. BPTT somt de fout op elke tijdstap, omdat RNN’s parameters over elke laag delen. Leer meer over RNN’s en hoe ze werken in What are Recurrent Neural Networks?.
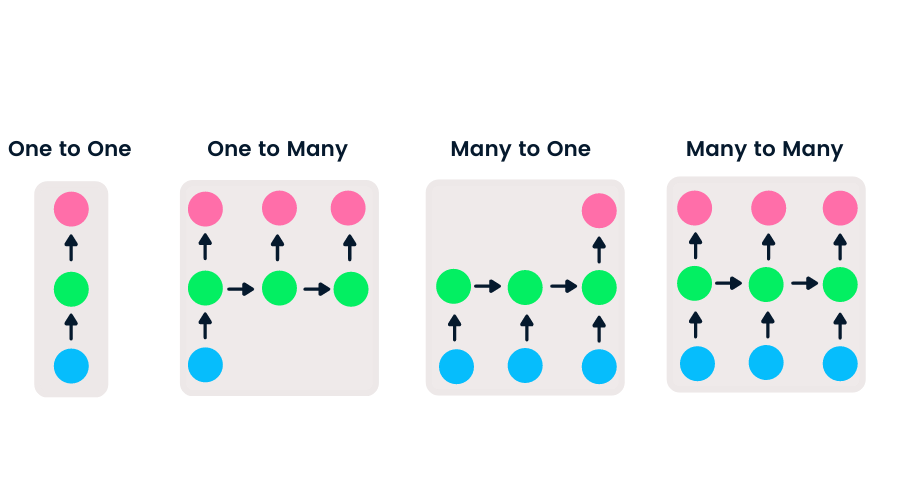
Feedforward-netwerken hebben één input en één output, terwijl recurrente neurale netwerken flexibel zijn omdat de lengte van inputs en outputs kan variëren. Dankzij deze flexibiliteit kunnen RNN’s muziek genereren, sentiment classificeren en machinevertaling uitvoeren.
Er zijn vier typen RNN op basis van verschillende lengtes van inputs en outputs.
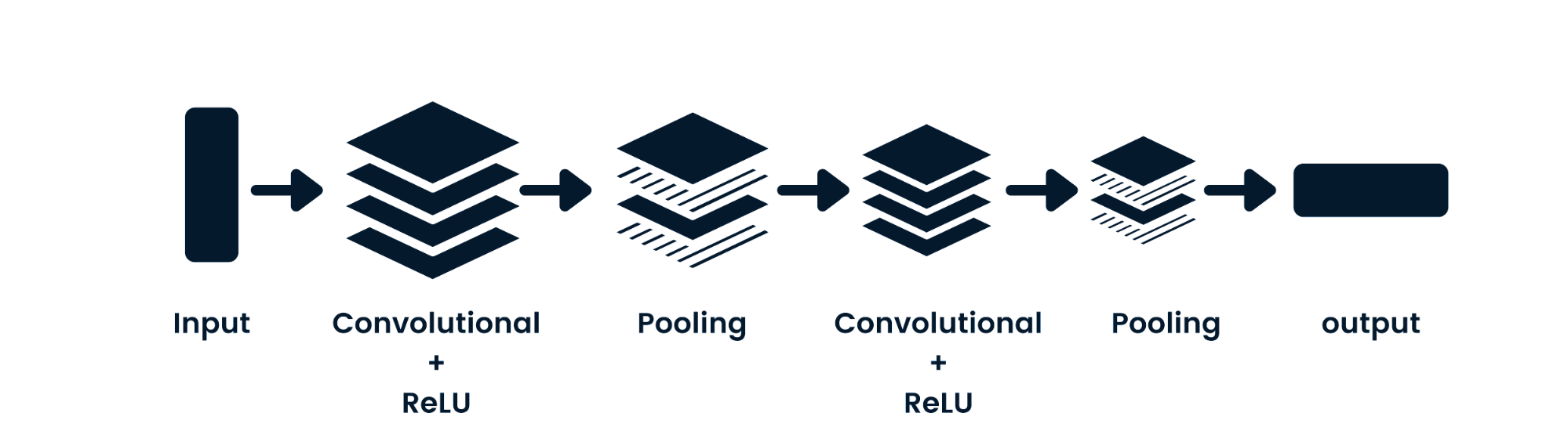
Het convolutional neural network (CNN) is een feedforward-neuraal netwerk dat ruimtelijke data kan verwerken. Het wordt vaak gebruikt voor computervisie-toepassingen zoals beeldclassificatie. Eenvoudige neurale netwerken zijn goed in eenvoudige binaire classificaties, maar kunnen niet omgaan met beelden met pixelafhankelijkheden. De CNN-modelarchitectuur bestaat uit convolutionele lagen, ReLU-lagen, pooling-lagen en volledig verbonden outputlagen. Je kunt CNN leren door te werken aan een project zoals Convolutional Neural Networks in Python.
Eenvoudige RNN-modellen lopen meestal tegen twee grote problemen aan. Deze problemen hebben te maken met de gradiënt, de helling van de verliesfunctie samen met de foutfunctie.
De eenvoudige oplossing voor deze problemen is het verminderen van het aantal verborgen lagen binnen het neurale netwerk, wat de complexiteit in RNN’s zal verminderen. Deze problemen kunnen ook worden opgelost met geavanceerde RNN-architecturen zoals LSTM en GRU.
De eenvoudige, herhalende RNN-modules hebben een basisstructuur met één tanh-laag. De eenvoudige RNN-structuur kampt met kort geheugen: hij heeft moeite om informatie van eerdere tijdstappen vast te houden in grotere sequentiële data. Deze problemen kunnen eenvoudig worden opgelost door long short term memory (LSTM) en gated recurrent unit (GRU), omdat die in staat zijn langetermijninformatie te onthouden.
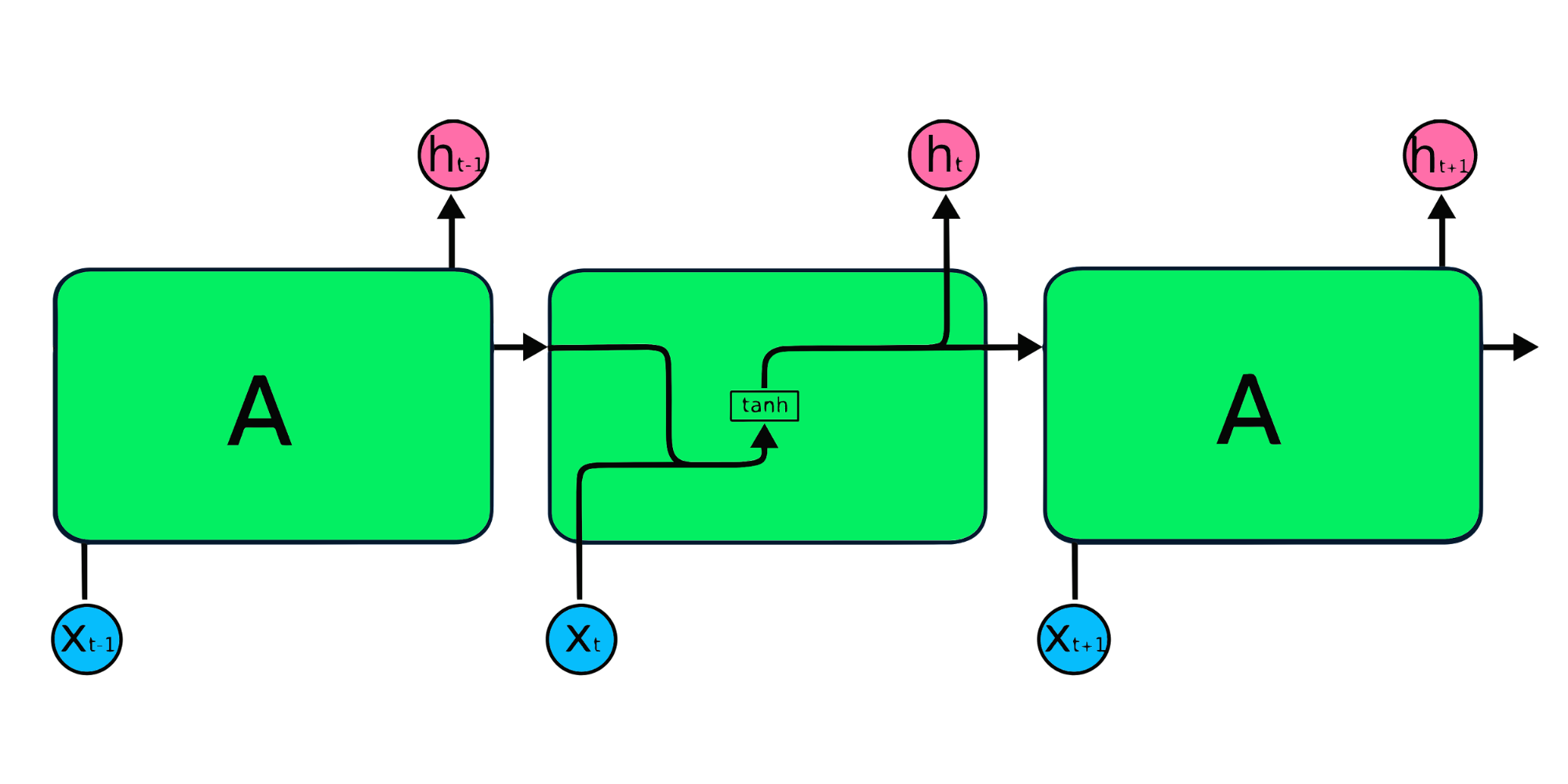
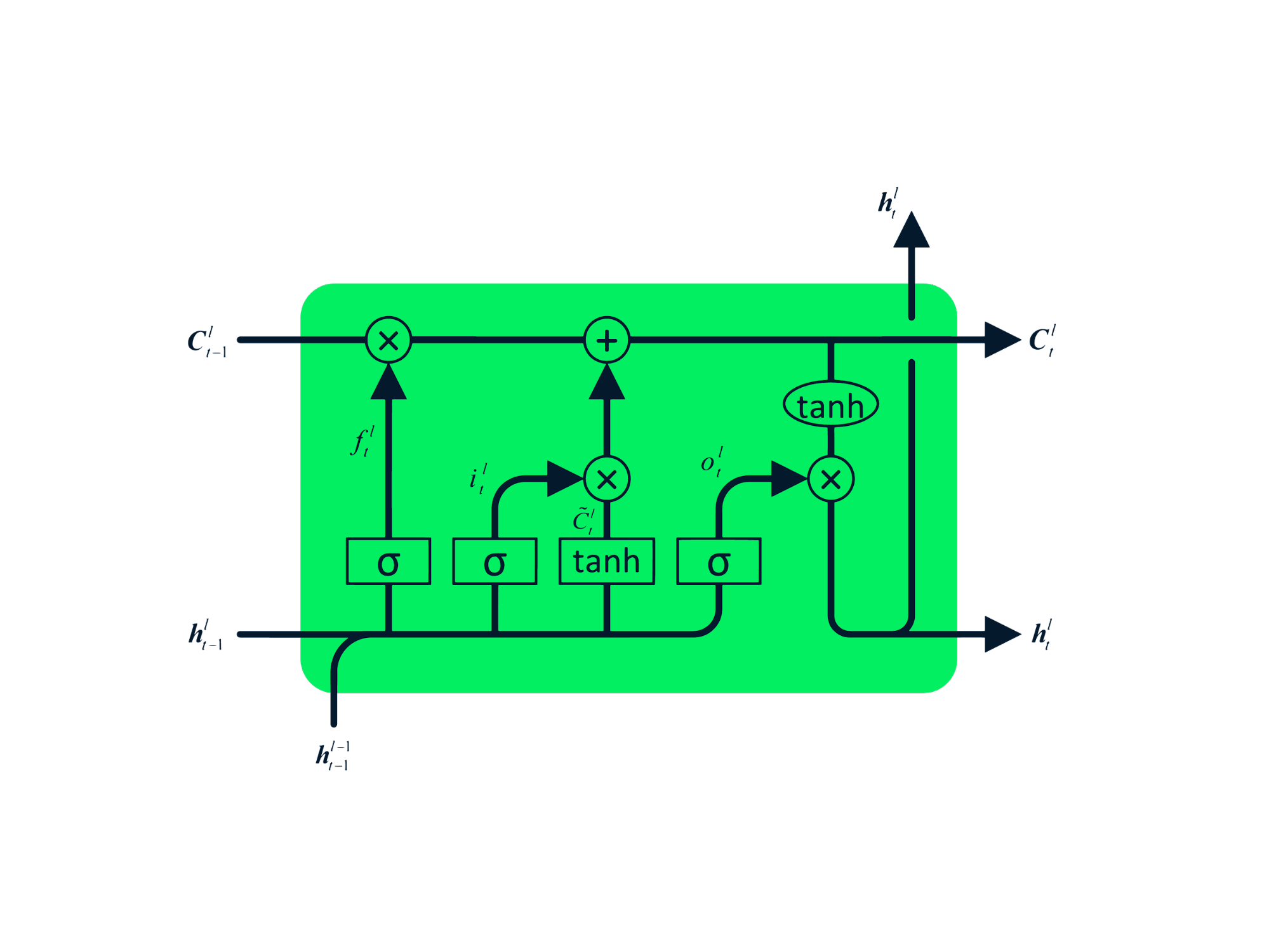
De Long Short Term Memory (LSTM) is het geavanceerde type RNN, ontworpen om zowel vervagende als exploderende gradiëntproblemen te voorkomen. Net als RNN heeft LSTM herhalende modules, maar de structuur is anders. In plaats van één tanh-laag heeft LSTM vier samenwerkende lagen die met elkaar communiceren. Deze vierlagige structuur helpt LSTM om langetermijngeheugen vast te houden en kan worden gebruikt in verschillende sequentiële problemen, waaronder machinevertaling, spraaksynthese, spraakherkenning en handschriftherkenning. Je kunt praktijkervaring opdoen met LSTM via de gids: Python LSTM for Stock Predictions.
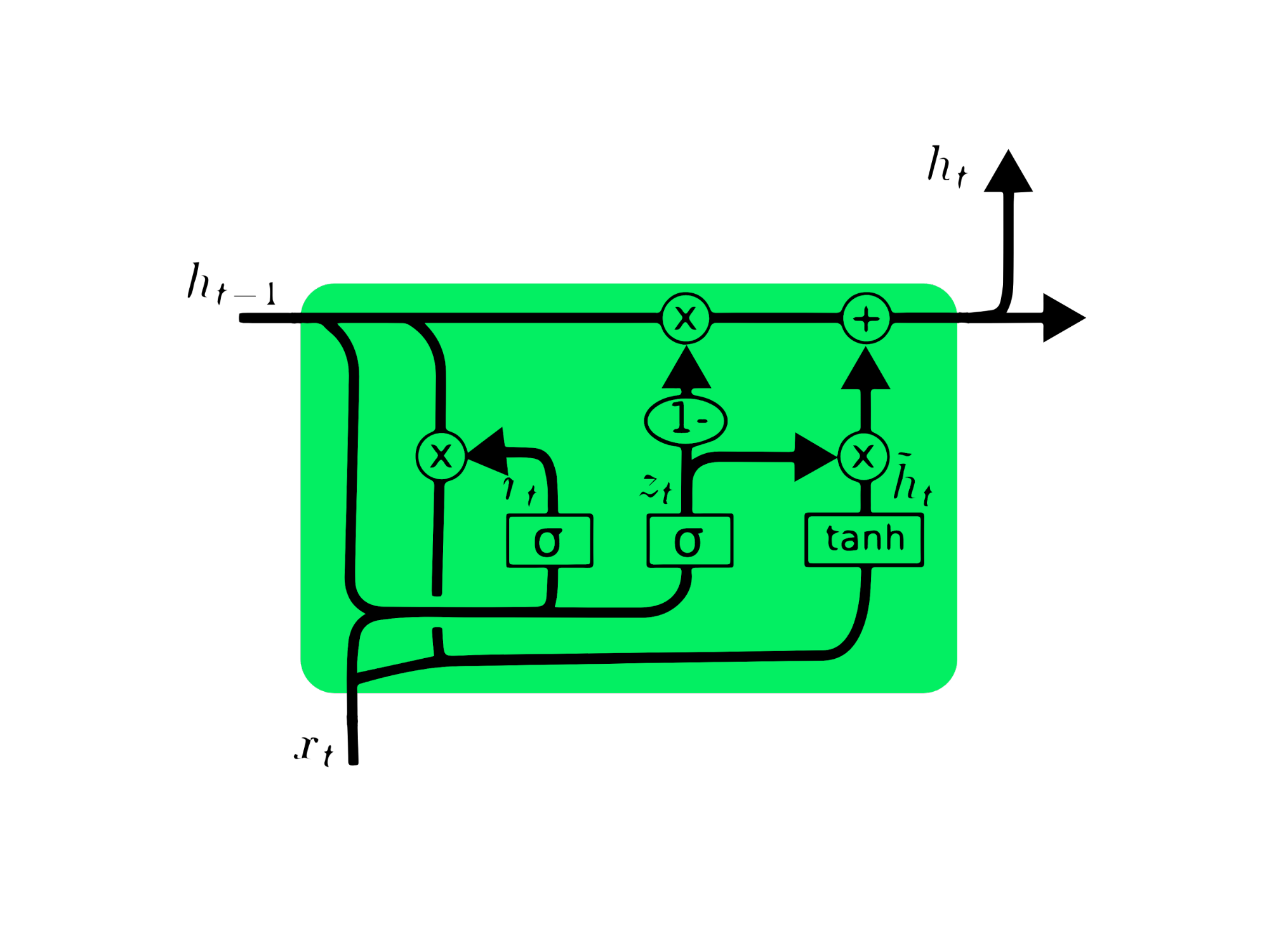
De gated recurrent unit (GRU) is een variant op LSTM: beide hebben ontwerp-overeenkomsten en in sommige gevallen leveren ze vergelijkbare resultaten op. GRU gebruikt een update gate en reset gate om het vanishing gradient-probleem op te lossen. Deze gates bepalen welke informatie belangrijk is en geven die door aan de output. De gates kunnen worden getraind om informatie van lang geleden op te slaan zonder met de tijd te vervagen of irrelevante informatie te verwijderen.
In tegenstelling tot LSTM heeft GRU geen celtoestand Ct. Het heeft alleen een verborgen toestand ht, en door de eenvoudige architectuur heeft GRU een kortere trainingstijd dan LSTM-modellen. De GRU-architectuur is eenvoudig te begrijpen: hij neemt input xt en de verborgen toestand van de vorige tijdstap ht-1 en geeft de nieuwe verborgen toestand ht uit. Je kunt diepgaande kennis opdoen over GRU via Understanding GRU Networks.
In dit project gebruiken we Kaggle’s MasterCard-aandelendataset van 25-mei-2006 tot 11-okt-2021 en trainen we de LSTM- en GRU-modellen om de aandelenkoers te voorspellen. Dit is een eenvoudige, projectgerichte tutorial waarin we data analyseren, de data voorbewerken om te trainen op geavanceerde RNN-modellen en tot slot de resultaten evalueren.
Voor het project heb je Pandas en Numpy nodig voor datamanipulatie, Matplotlib.pyplot voor datavisualisatie, scikit-learn voor schalen en evaluatie, en TensorFlow voor modellering. We zetten ook seeds voor reproduceerbaarheid.
# Importing the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, GRU, Bidirectional
from tensorflow.keras.optimizers import SGD
from tensorflow.random import set_seed
set_seed(455)
np.random.seed(455)
In dit deel importeren we de MasterCard-dataset door de kolom Date aan de index toe te voegen en te converteren naar DateTime-formaat. We verwijderen ook irrelevante kolommen uit de dataset, omdat we alleen geïnteresseerd zijn in aandelenkoersen, volume en datum.
De dataset heeft Date als index en Open, High, Low, Close en Volume als kolommen. Het lijkt erop dat we met succes een opgeschoonde dataset hebben geïmporteerd.
dataset = pd.read_csv(
"data/Mastercard_stock_history.csv", index_col="Date", parse_dates=["Date"]
).drop(["Dividends", "Stock Splits"], axis=1)
print(dataset.head())
Open High Low Close Volume
Date
2006-05-25 3.748967 4.283869 3.739664 4.279217 395343000
2006-05-26 4.307126 4.348058 4.103398 4.179680 103044000
2006-05-30 4.183400 4.184330 3.986184 4.093164 49898000
2006-05-31 4.125723 4.219679 4.125723 4.180608 30002000
2006-06-01 4.179678 4.474572 4.176887 4.419686 62344000
De functie .describe() helpt ons de data grondig te analyseren. Laten we focussen op de kolom High, aangezien we die gaan gebruiken om het model te trainen. We kunnen ook de kolommen Close of Open kiezen als modelfeature, maar High is logischer omdat die aangeeft hoe hoog de koers die dag is geweest.
De minimumaandelenkoers is $4,10 en de hoogste is $400,5. Het gemiddelde ligt op $105,9 en de standaarddeviatie op $107,3, wat betekent dat de aandelen een hoge variantie hebben.
print(dataset.describe())
Open High Low Close Volume
count 3872.000000 3872.000000 3872.000000 3872.000000 3.872000e+03
mean 104.896814 105.956054 103.769349 104.882714 1.232250e+07
std 106.245511 107.303589 105.050064 106.168693 1.759665e+07
min 3.748967 4.102467 3.739664 4.083861 6.411000e+05
25% 22.347203 22.637997 22.034458 22.300391 3.529475e+06
50% 70.810079 71.375896 70.224002 70.856083 5.891750e+06
75% 147.688448 148.645373 146.822013 147.688438 1.319775e+07
max 392.653890 400.521479 389.747812 394.685730 3.953430e+08
Met .isna().sum() kunnen we de ontbrekende waarden in de dataset bepalen. Het lijkt erop dat de dataset geen ontbrekende waarden heeft.
dataset.isna().sum()
Open 0
High 0
Low 0
Close 0
Volume 0
dtype: int64
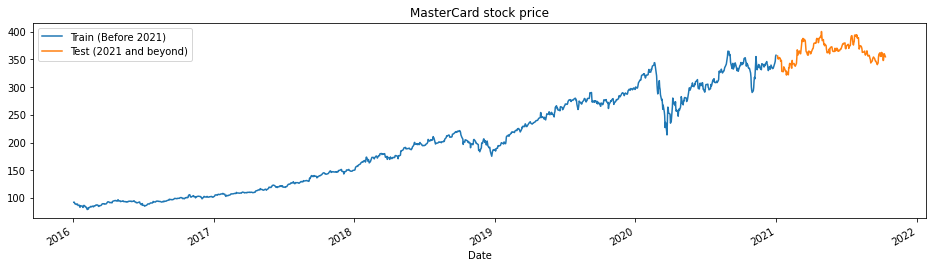
De functie train_test_plot neemt drie argumenten: dataset, tstart en tend en plot een eenvoudige lijngrafiek. De tstart en tend zijn tijdslimieten in jaren. We kunnen deze argumenten aanpassen om specifieke perioden te analyseren. De lijngrafiek is opgedeeld in twee delen: train en test. Zo kunnen we de verdeling van de testdataset bepalen.
De MasterCard-koers stijgt sinds 2016. Er was een dip in het eerste kwartaal van 2020, maar de koers kreeg een stabiele positie in de tweede helft van dat jaar. Onze testdataset bestaat uit één jaar, van 2021 tot 2022, en de rest van de dataset wordt gebruikt voor training.
tstart = 2016
tend = 2020
def train_test_plot(dataset, tstart, tend):
dataset.loc[f"{tstart}":f"{tend}", "High"].plot(figsize=(16, 4), legend=True)
dataset.loc[f"{tend+1}":, "High"].plot(figsize=(16, 4), legend=True)
plt.legend([f"Train (Before {tend+1})", f"Test ({tend+1} and beyond)"])
plt.title("MasterCard stock price")
plt.show()
train_test_plot(dataset,tstart,tend)
De functie train_test_split verdeelt de dataset in twee subsets: training_set en test_set.
def train_test_split(dataset, tstart, tend):
train = dataset.loc[f"{tstart}":f"{tend}", "High"].values
test = dataset.loc[f"{tend+1}":, "High"].values
return train, test
training_set, test_set = train_test_split(dataset, tstart, tend)
We gebruiken de functie MinMaxScaler om onze trainingsset te standaardiseren, wat helpt om uitschieters of anomalieën te vermijden. Je kunt ook StandardScaler of een andere scaler proberen om je data te normaliseren en de modelprestatie te verbeteren.
sc = MinMaxScaler(feature_range=(0, 1))
training_set = training_set.reshape(-1, 1)
training_set_scaled = sc.fit_transform(training_set)
De functie split_sequence gebruikt een trainingsdataset en zet deze om in inputs (X_train) en outputs (y_train).
Als de reeks bijvoorbeeld [1,2,3,4,5,6,7,8,9,10,11,12] is en de n_step is drie, dan zet deze de reeks om in drie input-tijdstappen en één output, zoals hieronder weergegeven:
| X | y |
|---|---|
| 1,2,3 | 4 |
| 2,3,4 | 5 |
| 3,4,5 | 6 |
| 4,5,6 | 7 |
| … | … |
In dit project gebruiken we 60 n_steps. We kunnen het aantal stappen ook verlagen of verhogen om de modelprestatie te optimaliseren.
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence) - 1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
n_steps = 60
features = 1
# split into samples
X_train, y_train = split_sequence(training_set_scaled, n_steps)
We werken met univariate reeksen, dus het aantal features is één, en we moeten X_train reshapen om op het LSTM-model te passen. X_train heeft de vorm [samples, timesteps], en we reshapen dit naar [samples, timesteps, features].
# Reshaping X_train for model
X_train = X_train.reshape(X_train.shape[0],X_train.shape[1],features)
Het model bestaat uit één verborgen LSTM-laag en een outputlaag. Je kunt experimenteren met het aantal units; meer units geven vaak betere resultaten. Voor dit experiment zetten we LSTM-units op 125, tanh als activatie en stellen we de inputgrootte in.
Opmerking van de auteur: De TensorFlow-bibliotheek is gebruiksvriendelijk, dus we hoeven LSTM- of GRU-modellen niet from scratch te bouwen. We gebruiken simpelweg de LSTM- of GRU-modules om het model te construeren.
Tot slot compileren we het model met een RMSprop-optimizer en mean squared error als verliesfunctie.
# The LSTM architecture
model_lstm = Sequential()
model_lstm.add(LSTM(units=125, activation="tanh", input_shape=(n_steps, features)))
model_lstm.add(Dense(units=1))
# Compiling the model
model_lstm.compile(optimizer="RMSprop", loss="mse")
model_lstm.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 125) 63500
_________________________________________________________________
dense (Dense) (None, 1) 126
=================================================================
Total params: 63,626
Trainable params: 63,626
Non-trainable params: 0
_________________________________________________________________
Het model traint 50 epochs met een batchgrootte van 32. Je kunt de hyperparameters aanpassen om de trainingstijd te verkorten of de resultaten te verbeteren. De training van het model is succesvol afgerond met het best mogelijke verlies.
model_lstm.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 30ms/step - loss: 3.1642e-04
We herhalen de voorbewerking en normaliseren de testset. Eerst transformeren we en splitsen vervolgens de dataset in samples, reshapen, voorspellen en inverse-transformeren we de voorspellingen terug naar de standaardvorm.
dataset_total = dataset.loc[:,"High"]
inputs = dataset_total[len(dataset_total) - len(test_set) - n_steps :].values
inputs = inputs.reshape(-1, 1)
#scaling
inputs = sc.transform(inputs)
# Split into samples
X_test, y_test = split_sequence(inputs, n_steps)
# reshape
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], features)
#prediction
predicted_stock_price = model_lstm.predict(X_test)
#inverse transform the values
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
De functie plot_predictions maakt een lijnplot van echt versus voorspeld. Dit helpt ons het verschil tussen werkelijke en voorspelde waarden te visualiseren.
De functie return_rmse neemt test- en predicted-argumenten en print de root mean square error (rmse)-metriek.
def plot_predictions(test, predicted):
plt.plot(test, color="gray", label="Real")
plt.plot(predicted, color="red", label="Predicted")
plt.title("MasterCard Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("MasterCard Stock Price")
plt.legend()
plt.show()
def return_rmse(test, predicted):
rmse = np.sqrt(mean_squared_error(test, predicted))
print("The root mean squared error is {:.2f}.".format(rmse))
Volgens de onderstaande lijnplot heeft het LSTM-model met één laag het goed gedaan.
plot_predictions(test_set,predicted_stock_price)
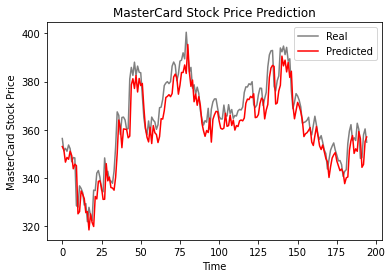
De resultaten zien er veelbelovend uit, want het model haalde 6,70 rmse op de testdataset.
return_rmse(test_set,predicted_stock_price)
>>> The root mean squared error is 6.70.
We houden alles hetzelfde en vervangen alleen de LSTM-laag door de GRU-laag om de resultaten goed te kunnen vergelijken. De modelstructuur bevat één GRU-laag met 125 units en een outputlaag.
model_gru = Sequential()
model_gru.add(GRU(units=125, activation="tanh", input_shape=(n_steps, features)))
model_gru.add(Dense(units=1))
# Compiling the RNN
model_gru.compile(optimizer="RMSprop", loss="mse")
model_gru.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gru_4 (GRU) (None, 125) 48000
_________________________________________________________________
dense_5 (Dense) (None, 1) 126
=================================================================
Total params: 48,126
Trainable params: 48,126
Non-trainable params: 0
_________________________________________________________________
Het model is succesvol getraind met 50 epochs en een batchgrootte van 32.
model_gru.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 29ms/step - loss: 2.6691e-04
We zien dat de echte en voorspelde waarden relatief dicht bij elkaar liggen. De voorspelde lijn sluit bijna aan op de werkelijke waarden.
GRU_predicted_stock_price = model_gru.predict(X_test)
GRU_predicted_stock_price = sc.inverse_transform(GRU_predicted_stock_price)
plot_predictions(test_set, GRU_predicted_stock_price)
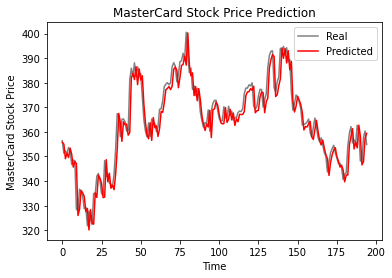
Het GRU-model haalde 5,50 rmse op de testdataset, wat een verbetering is ten opzichte van het LSTM-model.
return_rmse(test_set,GRU_predicted_stock_price)
>>> The root mean squared error is 5.50.
De wereld beweegt richting hybride oplossingen waarbij data scientists CNN-RNN-hybriden gebruiken op het gebied van afbeeldingsbijschriften, emotiedetectie, video-ondertiteling en DNA-sequencing. Hybride netwerken leveren zowel visuele als temporele kenmerken voor het model. Leer meer over RNN door de cursus te volgen: Recurrent Neural Networks for Language Modeling in Python.
De eerste helft van de tutorial behandelt de basis van recurrente neurale netwerken, de beperkingen en oplossingen in de vorm van meer geavanceerde architecturen. De tweede helft van de tutorial gaat over het ontwikkelen van MasterCard-koersvoorspellingen met LSTM- en GRU-modellen. De resultaten laten duidelijk zien dat het GRU-model beter presteerde dan LSTM, met een vergelijkbare structuur en hyperparameters.
Dit project is beschikbaar in de DataCamp Workspace.