Réseaux neuronaux récurrents (RNN) pour la modélisation linguistique avec Keras
14K learners
Un réseau neuronal récurrent (RNN) est le type de réseau neuronal artificiel (RNA) utilisé dans le Siri d'Apple et la recherche vocale de Google. Le RNN se souvient des entrées passées grâce à une mémoire interne, ce qui est utile pour prédire les cours de la bourse, générer du texte, des transcriptions et de la traduction automatique.
Dans le réseau neuronal traditionnel, les entrées et les sorties sont indépendantes les unes des autres, alors que la sortie du RNN dépend des éléments antérieurs de la séquence. Les réseaux récurrents partagent également des paramètres entre chaque couche du réseau. Dans les réseaux de type "feedforward", les poids sont différents pour chaque nœud. Alors que le RNN partage les mêmes poids dans chaque couche du réseau et que pendant la descente de gradient, les poids et la base sont ajustés individuellement pour réduire la perte.
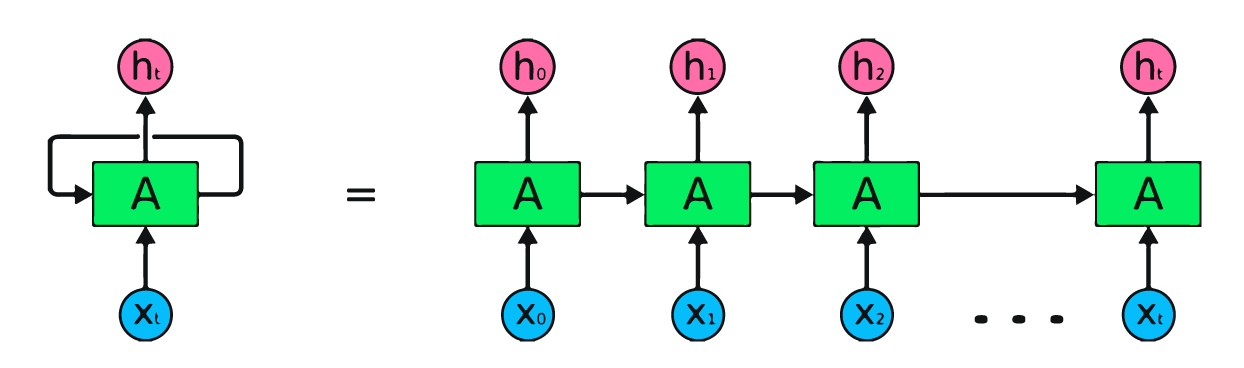
L'image ci-dessus est une représentation simple des réseaux neuronaux récurrents. Si nous prévoyons les cours des actions en utilisant des données simples [45,56,45,49,50,...], chaque entrée de X0 à Xt contiendra une valeur passée. Par exemple, X0 aura 45, X1 aura 56, et ces valeurs sont utilisées pour prédire le nombre suivant dans une séquence.
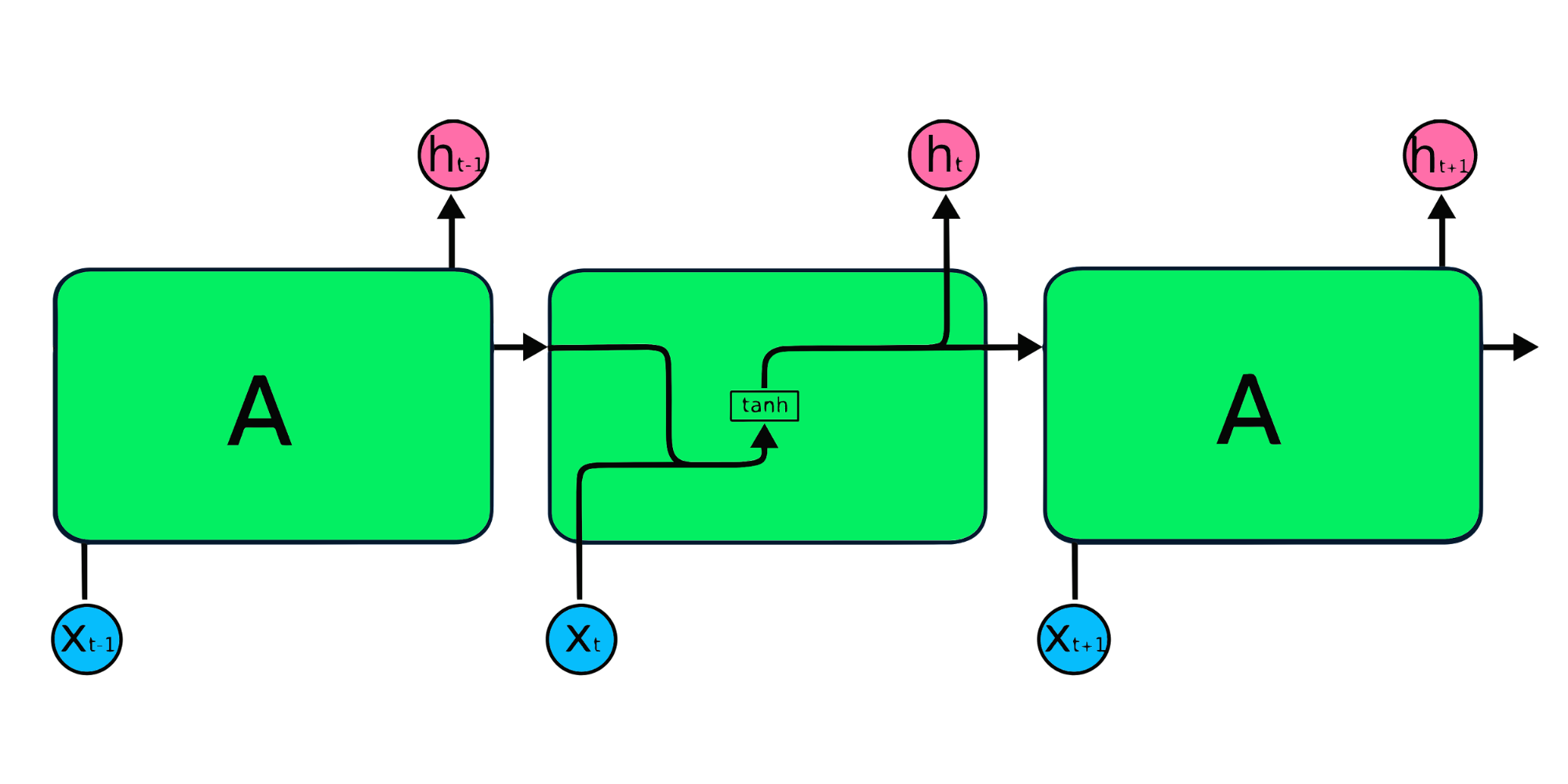
Dans le RNN, l'information circule dans la boucle, de sorte que la sortie est déterminée par l'entrée actuelle et les entrées reçues précédemment.
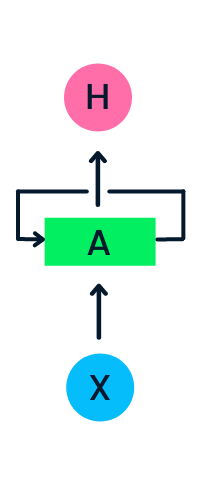
La couche d'entrée X traite l'entrée initiale et la transmet à la couche intermédiaire A. La couche intermédiaire se compose de plusieurs couches cachées, chacune avec ses fonctions d'activation, ses poids et ses biais. Ces paramètres sont normalisés pour l'ensemble de la couche cachée, de sorte qu'au lieu de créer plusieurs couches cachées, il n'en crée qu'une seule et la boucle.
Au lieu d'utiliser la rétropropagation traditionnelle, les réseaux neuronaux récurrents utilisent des algorithmes de rétropropagation dans le temps (BPTT) pour déterminer le gradient. Dans la rétropropagation, le modèle ajuste le paramètre en calculant les erreurs entre la sortie et la couche d'entrée. Le BPTT additionne l'erreur à chaque pas de temps alors que le RNN partage les paramètres entre chaque couche. Pour en savoir plus sur les réseaux neuronaux récurrents et leur fonctionnement, consultez le site What are Recurrent Neural Networks ?
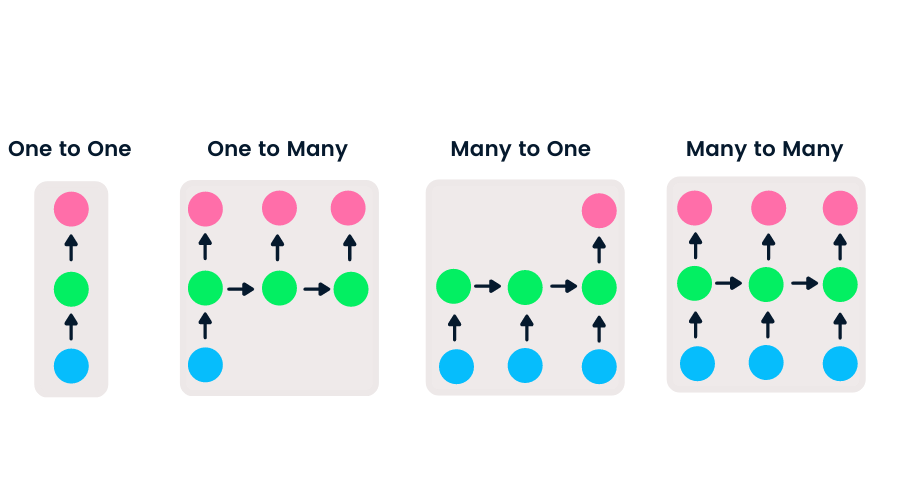
Les réseaux feedforward ont une entrée et une sortie uniques, tandis que les réseaux neuronaux récurrents sont flexibles car la longueur des entrées et des sorties peut être modifiée. Cette flexibilité permet aux RNN de générer de la musique, de la classification de sentiments et de la traduction automatique.
Il existe quatre types de RNN basés sur des longueurs différentes d'entrées et de sorties.
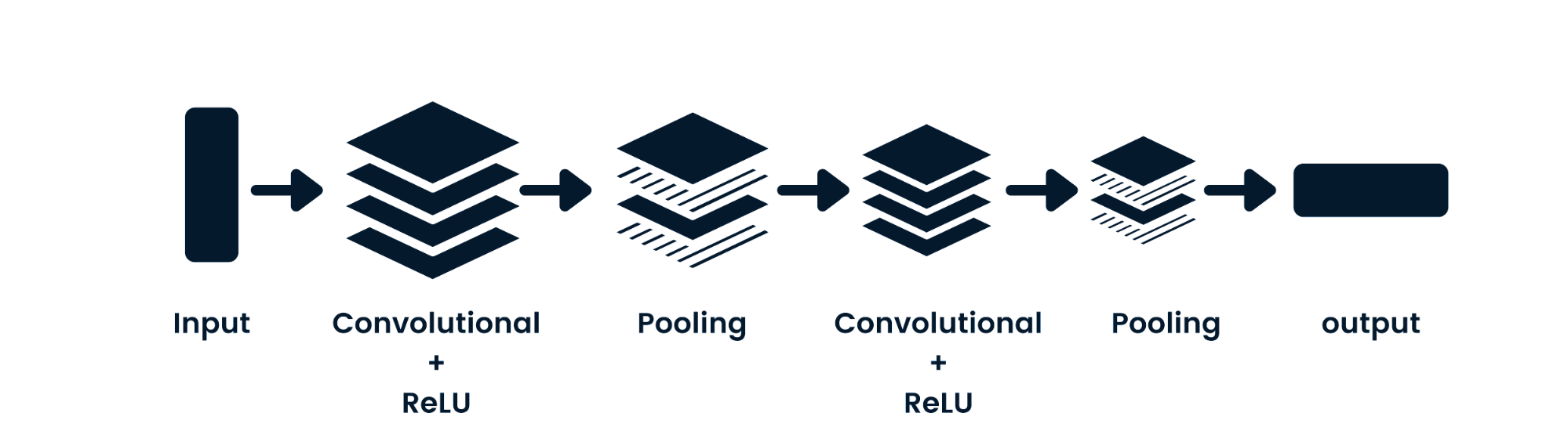
Le réseau neuronal convolutif (CNN) est un réseau neuronal feed-forward capable de traiter des données spatiales. Elle est couramment utilisée pour les applications de vision artificielle telles que la classification d'images. Les réseaux neuronaux simples sont efficaces pour les classifications binaires simples, mais ils ne peuvent pas traiter les images qui dépendent des pixels. L'architecture du modèle CNN se compose de couches convolutives, de couches ReLU, de couches de mise en commun et de couches de sortie entièrement connectées. Vous pouvez apprendre le CNN en travaillant sur un projet tel que Convolutional Neural Networks in Python.
Les modèles RNN simples se heurtent généralement à deux problèmes majeurs. Ces questions sont liées au gradient, qui est la pente de la fonction de perte avec la fonction d'erreur.
La solution simple à ces problèmes consiste à réduire le nombre de couches cachées dans le réseau neuronal, ce qui réduira la complexité des RNN. Ces problèmes peuvent également être résolus en utilisant des architectures RNN avancées telles que LSTM et GRU.
Les modules répétitifs RNN simples ont une structure de base avec une seule couche de tanh. La structure simple du RNN souffre d'une mémoire courte, car il a du mal à conserver les informations du pas de temps précédent dans des données séquentielles plus importantes. Ces problèmes peuvent être facilement résolus par la mémoire à long terme (LSTM) et l'unité récurrente gated (GRU), car elles sont capables de mémoriser de longues périodes d'information.
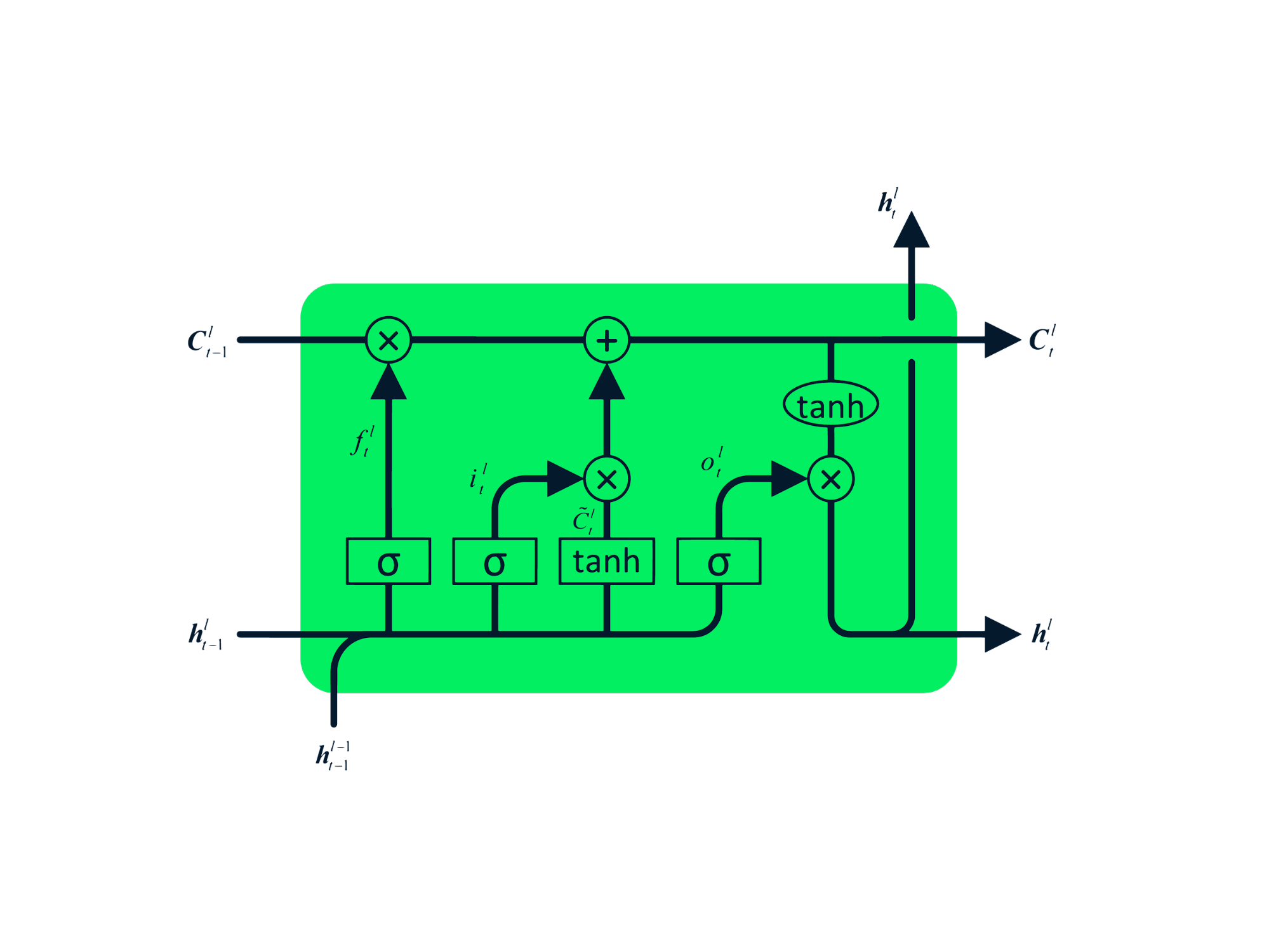
La mémoire à long terme (LSTM) est un type avancé de RNN, qui a été conçu pour éviter les problèmes de décroissance et d'explosion du gradient. Tout comme le RNN, la LSTM comporte des modules répétitifs, mais la structure est différente. Au lieu d'avoir une seule couche de tanh, la LSTM a quatre couches interactives qui communiquent entre elles. Cette structure à quatre niveaux permet aux LSTM de conserver une mémoire à long terme et peut être utilisée dans plusieurs problèmes séquentiels, notamment la traduction automatique, la synthèse vocale, la reconnaissance vocale et la reconnaissance de l'écriture manuscrite. Vous pouvez acquérir une expérience pratique de la LSTM en suivant le guide : Python LSTM pour les prédictions boursières.
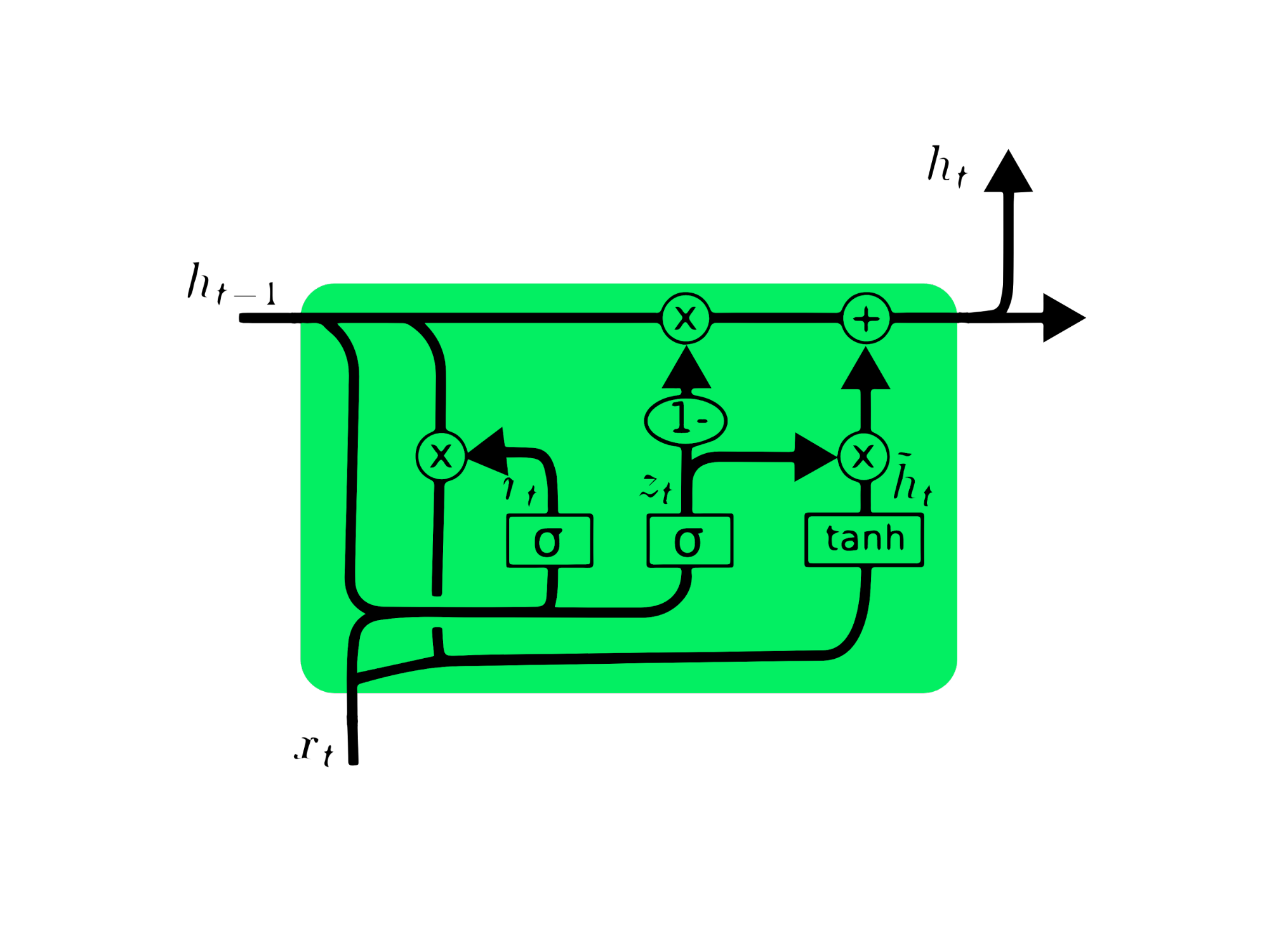
L'unité récurrente gated (GRU) est une variante de la LSTM, car toutes deux présentent des similitudes de conception et, dans certains cas, produisent des résultats similaires. GRU utilise une porte de mise à jour et une porte de réinitialisation pour résoudre le problème du gradient de fuite. Ces portes décident quelles informations sont importantes et les transmettent à la sortie. Les portes peuvent être entraînées à stocker des informations datant d'il y a longtemps, sans disparaître avec le temps ni supprimer les informations non pertinentes.
Contrairement à la LSTM, la GRU n'a pas d'état cellulaire Ct. Il ne possède qu'un état caché ht et, en raison de son architecture simple, le temps d'apprentissage de GRU est inférieur à celui des modèles LSTM. L'architecture de l'UGR est facile à comprendre : elle prend l'entrée xt et l'état caché de l'instant précédent ht-1 et produit le nouvel état caché ht. Vous pouvez acquérir des connaissances approfondies sur l'UGR en consultant le site Comprendre les réseaux de l'UGR.
Dans ce projet, nous allons utiliser l'ensemble de données Kaggle sur les actions de MasterCard entre le 25 mai 2006 et le 11 octobre 2021 et entraîner les modèles LSTM et GRU pour prévoir le prix des actions. Il s'agit d'un simple tutoriel basé sur un projet dans lequel nous analyserons des données, les traiterons pour les entraîner sur des modèles RNN avancés, et enfin évaluerons les résultats.
Le projet nécessite Pandas et Numpy pour la manipulation des données, Matplotlib.pyplot pour la visualisation des données, scikit-learn pour la mise à l'échelle et l'évaluation, et TensorFlow pour la modélisation. Nous jetterons également les bases de la reproductibilité.
# Importing the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, GRU, Bidirectional
from tensorflow.keras.optimizers import SGD
from tensorflow.random import set_seed
set_seed(455)
np.random.seed(455)
Dans cette partie, nous allons importer le jeu de données MasterCard en ajoutant la colonne Date à l'index et en la convertissant au format DateTime. Nous supprimerons également les colonnes non pertinentes de l'ensemble de données, car nous ne nous intéressons qu'aux cours des actions, au volume et à la date.
L'ensemble de données a pour index la date et pour colonnes l'ouverture, le sommet, le creux, la clôture et le volume. Il semble que nous ayons importé avec succès un jeu de données nettoyé.
dataset = pd.read_csv(
"data/Mastercard_stock_history.csv", index_col="Date", parse_dates=["Date"]
).drop(["Dividends", "Stock Splits"], axis=1)
print(dataset.head())
Open High Low Close Volume
Date
2006-05-25 3.748967 4.283869 3.739664 4.279217 395343000
2006-05-26 4.307126 4.348058 4.103398 4.179680 103044000
2006-05-30 4.183400 4.184330 3.986184 4.093164 49898000
2006-05-31 4.125723 4.219679 4.125723 4.180608 30002000
2006-06-01 4.179678 4.474572 4.176887 4.419686 62344000
La fonction .describe() nous aide à analyser les données en profondeur. Concentrons-nous sur la colonne High car nous allons l'utiliser pour entraîner le modèle. Nous pouvons également choisir les colonnes Close ou Open pour une caractéristique de modèle, mais High est plus logique car il nous fournit des informations sur la hauteur des valeurs de l'action le jour donné.
Le prix minimum de l'action est de 4,10 dollars et le prix maximum de 400,5 dollars. La moyenne se situe à 105,9 dollars et l'écart-type à 107,3 dollars, ce qui signifie que les actions ont une variance élevée.
print(dataset.describe())
Open High Low Close Volume
count 3872.000000 3872.000000 3872.000000 3872.000000 3.872000e+03
mean 104.896814 105.956054 103.769349 104.882714 1.232250e+07
std 106.245511 107.303589 105.050064 106.168693 1.759665e+07
min 3.748967 4.102467 3.739664 4.083861 6.411000e+05
25% 22.347203 22.637997 22.034458 22.300391 3.529475e+06
50% 70.810079 71.375896 70.224002 70.856083 5.891750e+06
75% 147.688448 148.645373 146.822013 147.688438 1.319775e+07
max 392.653890 400.521479 389.747812 394.685730 3.953430e+08
En utilisant .isna().sum(), nous pouvons déterminer les valeurs manquantes dans l'ensemble de données. Il semble que l'ensemble de données ne contienne pas de valeurs manquantes.
dataset.isna().sum()
Open 0
High 0
Low 0
Close 0
Volume 0
dtype: int64
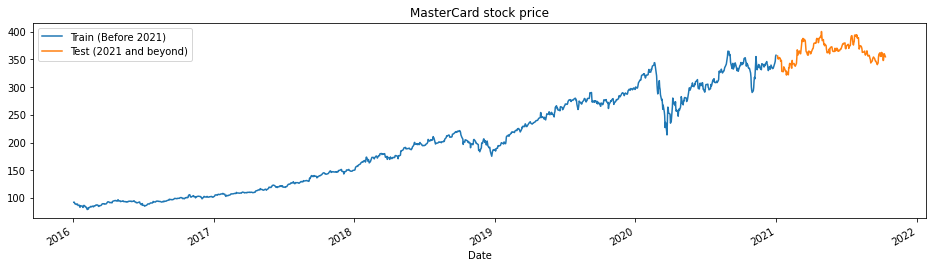
La fonction train_test_plot prend trois arguments : dataset, tstart et tend et trace un simple graphique linéaire. Les valeurs tstart et tend sont des limites temporelles en années. Nous pouvons modifier ces arguments pour analyser des périodes spécifiques. Le tracé est divisé en deux parties : formation et test. Cela nous permettra de décider de la distribution de l'ensemble de données de test.
Le cours de l'action MasterCard est en hausse depuis 2016. Il a connu une baisse au cours du premier trimestre de 2020, mais il s'est stabilisé au cours du second semestre de l'année. Notre ensemble de données de test comprend une année, de 2021 à 2022, et le reste de l'ensemble de données est utilisé pour la formation.
tstart = 2016
tend = 2020
def train_test_plot(dataset, tstart, tend):
dataset.loc[f"{tstart}":f"{tend}", "High"].plot(figsize=(16, 4), legend=True)
dataset.loc[f"{tend+1}":, "High"].plot(figsize=(16, 4), legend=True)
plt.legend([f"Train (Before {tend+1})", f"Test ({tend+1} and beyond)"])
plt.title("MasterCard stock price")
plt.show()
train_test_plot(dataset,tstart,tend)
La fonction train_test_split divise l'ensemble de données en deux sous-ensembles : training_set et test_set.
def train_test_split(dataset, tstart, tend):
train = dataset.loc[f"{tstart}":f"{tend}", "High"].values
test = dataset.loc[f"{tend+1}":, "High"].values
return train, test
training_set, test_set = train_test_split(dataset, tstart, tend)
Nous utiliserons la fonction MinMaxScaler pour normaliser notre ensemble d'apprentissage, ce qui nous aidera à éviter les valeurs aberrantes ou les anomalies. Vous pouvez également essayer d'utiliser StandardScaler ou toute autre fonction scalaire pour normaliser vos données et améliorer les performances du modèle.
sc = MinMaxScaler(feature_range=(0, 1))
training_set = training_set.reshape(-1, 1)
training_set_scaled = sc.fit_transform(training_set)
La fonction split_sequence utilise un ensemble de données d'apprentissage et le convertit en entrées (X_train) et en sorties (y_train).
Par exemple, si la séquence est [1,2,3,4,5,6,7,8,9,10,11,12] et que le n_step est trois, il convertira la séquence en trois horodatages d'entrée et une sortie, comme indiqué ci-dessous :
| X | y |
|---|---|
| 1,2,3 | 4 |
| 2,3,4 | 5 |
| 3,4,5 | 6 |
| 4,5,6 | 7 |
| … | … |
Dans ce projet, nous utilisons 60 n_pas. Nous pouvons également réduire ou augmenter le nombre d'étapes afin d'optimiser les performances du modèle.
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence) - 1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
n_steps = 60
features = 1
# split into samples
X_train, y_train = split_sequence(training_set_scaled, n_steps)
Nous travaillons avec des séries univariées, donc le nombre de caractéristiques est de un, et nous devons remodeler le X_train pour qu'il s'adapte au modèle LSTM. La formation X_train a [échantillons, pas de temps], et nous allons la remodeler en [échantillons, pas de temps, caractéristiques].
# Reshaping X_train for model
X_train = X_train.reshape(X_train.shape[0],X_train.shape[1],features)
Le modèle se compose d'une seule couche cachée de LSTM et d'une couche de sortie. Vous pouvez expérimenter avec le nombre d'unités, car un plus grand nombre d'unités vous donnera de meilleurs résultats. Pour cette expérience, nous fixerons le nombre d'unités LSTM à 125, l'activation à tanh et la taille de l'entrée.
Note de l'auteur: La bibliothèque Tensorflow est conviviale, nous n'avons donc pas besoin de créer des modèles LSTM ou GRU à partir de zéro. Nous utiliserons simplement les modules LSTM ou GRU pour construire le modèle.
Enfin, nous compilerons le modèle avec un optimiseur RMSprop et l'erreur quadratique moyenne comme fonction de perte.
# The LSTM architecture
model_lstm = Sequential()
model_lstm.add(LSTM(units=125, activation="tanh", input_shape=(n_steps, features)))
model_lstm.add(Dense(units=1))
# Compiling the model
model_lstm.compile(optimizer="RMSprop", loss="mse")
model_lstm.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 125) 63500
_________________________________________________________________
dense (Dense) (None, 1) 126
=================================================================
Total params: 63,626
Trainable params: 63,626
Non-trainable params: 0
_________________________________________________________________
Le modèle s'entraînera sur 50 époques avec 32 lots. Vous pouvez modifier les hyperparamètres pour réduire le temps d'apprentissage ou améliorer les résultats. La formation du modèle a été menée à bien avec la meilleure perte possible.
model_lstm.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 30ms/step - loss: 3.1642e-04
Nous allons répéter le prétraitement et normaliser l'ensemble de test. Tout d'abord, nous allons transformer puis diviser l'ensemble de données en échantillons, le remodeler, prédire et transformer inversement les prédictions sous forme standard.
dataset_total = dataset.loc[:,"High"]
inputs = dataset_total[len(dataset_total) - len(test_set) - n_steps :].values
inputs = inputs.reshape(-1, 1)
#scaling
inputs = sc.transform(inputs)
# Split into samples
X_test, y_test = split_sequence(inputs, n_steps)
# reshape
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], features)
#prediction
predicted_stock_price = model_lstm.predict(X_test)
#inverse transform the values
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
La fonction plot_predictions permet de tracer un graphique linéaire de la valeur réelle par rapport à la valeur prédite. Cela nous aidera à visualiser la différence entre les valeurs réelles et les valeurs prédites.
La fonction return_rmse prend en compte les arguments test et prédit et imprime la métrique de l'erreur quadratique moyenne (rmse).
def plot_predictions(test, predicted):
plt.plot(test, color="gray", label="Real")
plt.plot(predicted, color="red", label="Predicted")
plt.title("MasterCard Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("MasterCard Stock Price")
plt.legend()
plt.show()
def return_rmse(test, predicted):
rmse = np.sqrt(mean_squared_error(test, predicted))
print("The root mean squared error is {:.2f}.".format(rmse))
D'après le graphique ci-dessous, le modèle LSTM à une seule couche a donné de bons résultats.
plot_predictions(test_set,predicted_stock_price)
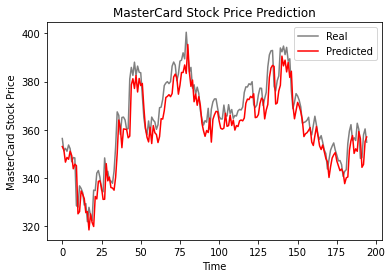
Les résultats sont prometteurs puisque le modèle a obtenu 6,70 rmse sur l'ensemble de données de test.
return_rmse(test_set,predicted_stock_price)
>>> The root mean squared error is 6.70.
Nous allons tout garder à l'identique et remplacer la couche LSTM par la couche GRU afin de comparer correctement les résultats. La structure du modèle contient une seule couche GRU avec 125 unités et une couche de sortie.
model_gru = Sequential()
model_gru.add(GRU(units=125, activation="tanh", input_shape=(n_steps, features)))
model_gru.add(Dense(units=1))
# Compiling the RNN
model_gru.compile(optimizer="RMSprop", loss="mse")
model_gru.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gru_4 (GRU) (None, 125) 48000
_________________________________________________________________
dense_5 (Dense) (None, 1) 126
=================================================================
Total params: 48,126
Trainable params: 48,126
Non-trainable params: 0
_________________________________________________________________
Le modèle a été entraîné avec succès avec 50 époques et une taille de lot de 32.
model_gru.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 29ms/step - loss: 2.6691e-04
Comme nous pouvons le constater, les valeurs réelles et prédites sont relativement proches. Le graphique linéaire prédit correspond presque aux valeurs réelles.
GRU_predicted_stock_price = model_gru.predict(X_test)
GRU_predicted_stock_price = sc.inverse_transform(GRU_predicted_stock_price)
plot_predictions(test_set, GRU_predicted_stock_price)
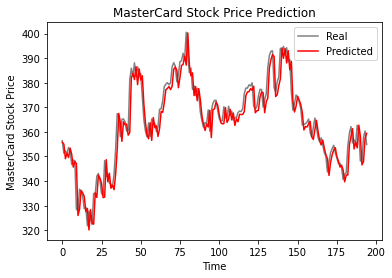
Le modèle GRU a obtenu 5,50 rmse sur l'ensemble de données de test, ce qui constitue une amélioration par rapport au modèle LSTM.
return_rmse(test_set,GRU_predicted_stock_price)
>>> The root mean squared error is 5.50.
Le monde évolue vers des solutions hybrides où les scientifiques utilisent des réseaux hybrides CNN-RNN dans le domaine du sous-titrage d'images, de la détection d'émotions, du sous-titrage vidéo et du séquençage de l'ADN. Les réseaux hybrides fournissent des caractéristiques visuelles et temporelles au modèle. Apprenez-en plus sur les RNN en suivant le cours : Réseaux neuronaux récurrents pour la modélisation linguistique en Python.
La première moitié du tutoriel couvre les bases des réseaux neuronaux récurrents, leurs limites et les solutions sous la forme d'une architecture plus avancée. La seconde moitié du tutoriel est consacrée à l'élaboration de prévisions du cours de l'action MasterCard à l'aide de modèles LSTM et GRU. Les résultats montrent clairement que le modèle GRU est plus performant que le modèle LSTM, avec une structure et des hyperparamètres similaires.
Ce projet est disponible sur l'espace de travail de DataCamp.
blog
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Sejal Jaiswal
Tutoriel
Satyabrata Pal
Tutoriel
Laiba Siddiqui

