
Corso
Introduzione al Data Engineering
4 h
128.3K
Questo articolo è un prezioso contributo della nostra community ed è stato revisionato da DataCamp per chiarezza e accuratezza.
Ti piacerebbe condividere la tua esperienza? Ci farebbe piacere sentirti! Invia i tuoi articoli o le tue idee tramite il nostro Modulo per i contributi della Community.
I dati guidano ogni decisione che prendiamo oggi, e saper comprendere e utilizzare dati provenienti da fonti diverse è essenziale. L’integrazione dei dati è il processo con cui i dati di più fonti vengono combinati e resi disponibili in modo unificato e coerente. Il suo obiettivo principale è offrire una visione olistica, consentendo alle aziende di ottenere insight di valore, semplificare le operazioni e prendere decisioni basate sui dati anziché sulla teoria.
Tra la miriade di strategie e strumenti per l’integrazione dei dati disponibili, ETL (Extract, Transform, Load) ed ELT (Extract, Load, Transform) si impongono come le due metodologie predominanti. Questi metodi rappresentano approcci distinti all’integrazione dei dati, ciascuno con i propri vantaggi e campi di applicazione.
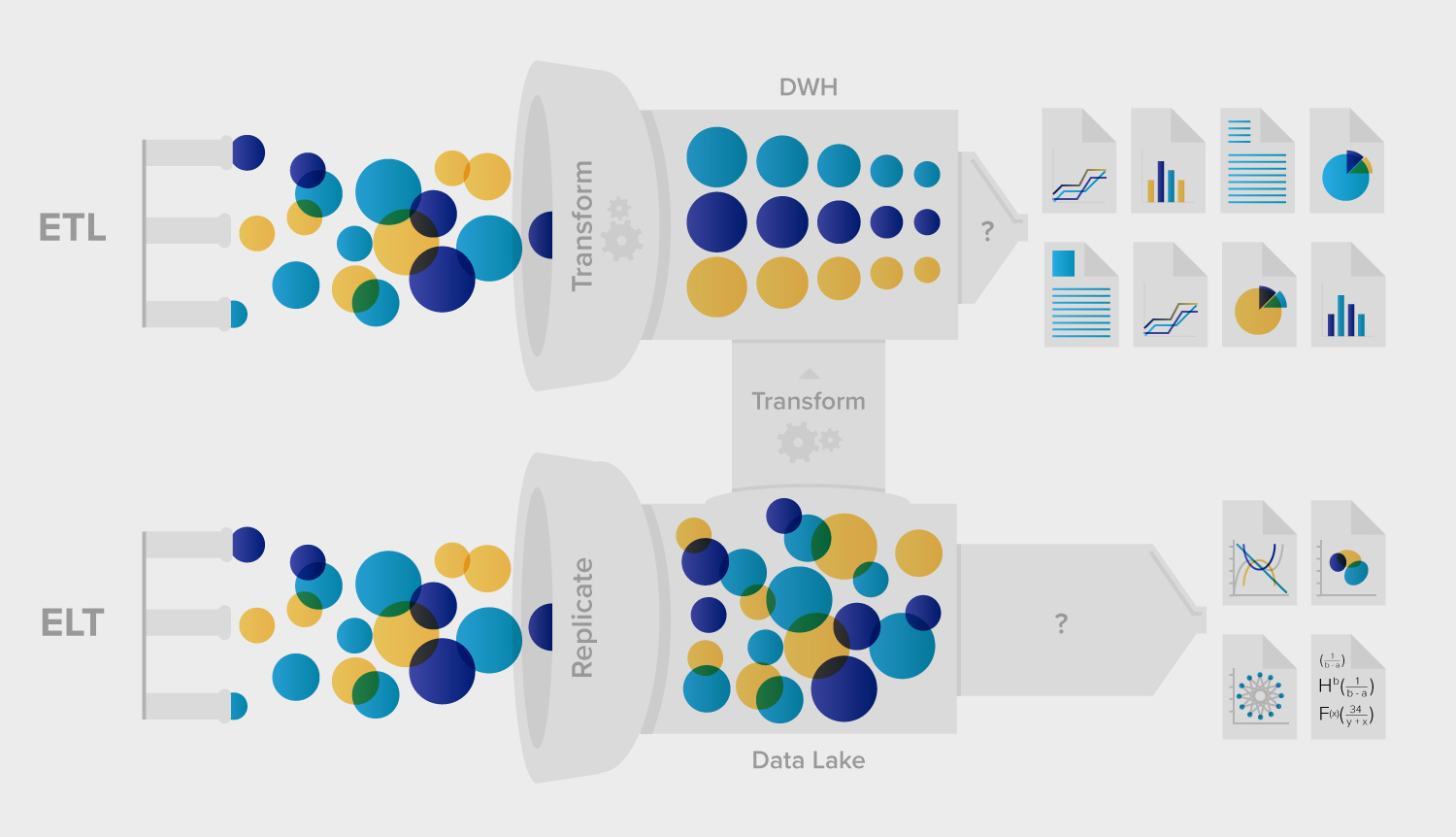
ETL, come suggerisce l’acronimo, si compone di tre passaggi principali:
ETL è particolarmente adatto a scenari in cui:
ETL è un’ottima scelta quando devi garantire coerenza, qualità e sicurezza dei dati. Elabora i dati prima che raggiungano il warehouse, riducendo il rischio di esposizione di informazioni sensibili e assicurando che i dati rispettino le regole e gli standard aziendali.
Python, un linguaggio di programmazione versatile e ampiamente utilizzato, è diventato uno strumento di riferimento per l’integrazione dati in ETL. Il suo ricco ecosistema di librerie e framework facilita ogni fase del processo ETL, rendendolo una scelta ideale per i data engineer.
Integrare Python nei processi ETL può semplificare l’integrazione dei dati e offrire un mix di efficienza, flessibilità e potenza. Che si tratti di database tradizionali o piattaforme big data, le capacità di Python nell’ETL sono pressoché illimitate.
ELT adotta un approccio leggermente diverso:
La crescente popolarità dell’ELT è strettamente legata all’avvento dei data warehouse cloud come Snowflake, BigQuery e Redshift. Queste piattaforme dispongono di un’enorme potenza di calcolo, che consente di gestire in modo efficiente trasformazioni su larga scala direttamente nel warehouse.
Sebbene sia ETL sia ELT prevedano l’estrazione dei dati e il loro caricamento in un warehouse, la differenza principale riguarda il luogo e il momento della trasformazione. L’ETL trasforma i dati prima che raggiungano il warehouse, mentre l’ELT lo fa successivamente.
In generale, la velocità di ingestione dati dell’ELT supera quella dell’ETL per via del minor movimento di dati. Tuttavia, la velocità complessiva può essere influenzata da fattori come la complessità delle trasformazioni e le capacità del data warehouse.
Nell’ETL, le trasformazioni avvengono in un sistema intermedio, che può offrire un controllo più granulare sul processo. Ciò è fondamentale per le aziende con requisiti stringenti di conformità e gestione dei dati. Al contrario, l’ELT si affida alle capacità del sistema di destinazione, il che potrebbe esporre dati grezzi e non mascherati fino al completamento delle trasformazioni.
Quando scegli tra ETL ed ELT, considera:
Le moderne piattaforme di integrazione dei dati possono sfumare i confini tra ETL ed ELT, offrendo strumenti che combinano i punti di forza di entrambi gli approcci. Queste piattaforme possono guidare le aziende nella scelta e nell’esecuzione della strategia giusta in base alle loro esigenze specifiche.
La scelta tra ETL ed ELT non è netta. Entrambe le metodologie hanno i loro meriti e l’opzione ideale dipende spesso dalle necessità e dalle circostanze specifiche dell’azienda. Comprendendo le peculiarità di ogni approccio e sfruttando le moderne piattaforme di integrazione dei dati, i responsabili dei dati possono prendere decisioni informate, guidando l’azienda verso un futuro più consapevole.
Per iniziare con l’ETL, il corso ETL con Python di DataCamp è la risorsa ideale: copre vari strumenti e come creare pipeline efficienti. Se vuoi intraprendere una carriera nel data engineering, scopri la nostra Certificazione Data Engineer per dimostrare le tue competenze ai datori di lavoro.
Inizia oggi il tuo percorso nel Data Engineering!
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

