
Cours
Introduction au data engineering
4 h
127.6K
Cet article est une contribution précieuse de notre communauté et a été édité par DataCamp dans un souci de clarté et d'exactitude.
Vous souhaitez partager votre expertise ? N'hésitez pas à nous contacter ! N'hésitez pas à soumettre vos articles ou vos idées via notre formulaire de contribution communautaire.
De nos jours, les données sont à la base de toutes les décisions que nous prenons, et il est essentiel de comprendre et d'utiliser des données provenant de diverses sources. L'intégration des données est le processus par lequel des données provenant de sources multiples sont combinées et mises à disposition de manière unifiée et cohérente. Son objectif premier est d'offrir une vision globale, permettant aux entreprises de tirer des enseignements précieux, de rationaliser les opérations et de prendre des décisions fondées sur des données plutôt que sur la théorie.
Parmi la pléthore de stratégies et d' outils d' intégration de données disponibles, l'ETL (Extract, Transform, Load) et l'ELT (Extract, Load, Transform) sont les deux méthodologies prédominantes. Ces méthodes représentent des approches distinctes de l'intégration des données, chacune ayant ses avantages et ses applications.
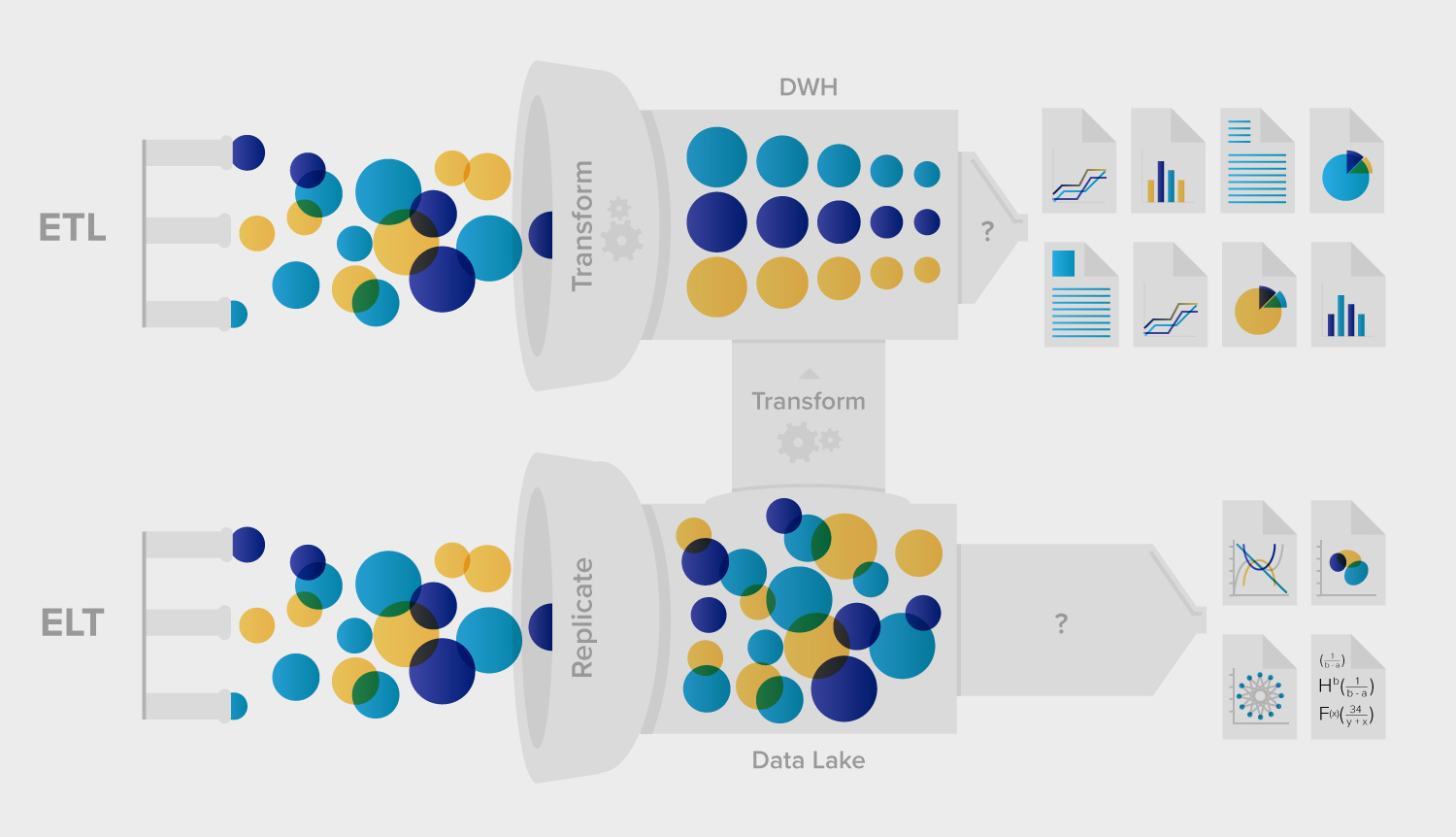
L'ETL, comme l'acronyme l'indique, consiste en trois étapes principales :
L'ETL est particulièrement bien adapté aux scénarios dans lesquels :
L'ETL est un excellent choix lorsque vous devez garantir la cohérence, la qualité et la sécurité des données. Il traite les données avant qu'elles n'atteignent l'entrepôt, réduisant ainsi le risque d'exposition des données sensibles et garantissant que les données sont conformes aux règles et aux normes de l'entreprise.
Python, un langage de programmation polyvalent et largement utilisé, est devenu un outil de choix pour l'intégration de données ETL. Son riche écosystème de bibliothèques et de frameworks facilite chaque étape du processus ETL, ce qui en fait un choix incontournable pour les ingénieurs de données.
L'intégration de Python dans les processus ETL peut rationaliser l'intégration des données et produire un mélange d'efficacité, de flexibilité et de puissance. Qu'il s'agisse de bases de données traditionnelles ou de plateformes de big data, les capacités de Python en matière d'ETL sont illimitées.
Les CLNA adoptent une approche légèrement différente :
La popularité croissante de l'ELT est étroitement liée à l'avènement des entrepôts de données basés sur le cloud, comme Snowflake, BigQuery et Redshift. Ces plateformes possèdent une immense puissance de traitement, ce qui leur permet de gérer efficacement les transformations à grande échelle au sein de l'entrepôt.
Si l'ETL et l'ELT impliquent tous deux l'extraction de données et leur chargement dans un entrepôt, leur principale distinction réside dans le lieu et le moment du processus de transformation. L'ETL transforme les données avant qu'elles n'atteignent l'entrepôt, tandis que l'ELT le fait après.
En général, la vitesse d'ingestion des données de l'ELT dépasse celle de l'ETL en raison de la réduction des mouvements de données. Toutefois, la vitesse globale peut être influencée par des facteurs tels que la complexité des transformations et les capacités de l'entrepôt de données.
Dans l'ETL, les transformations ont lieu dans un système intermédiaire, qui peut offrir un contrôle plus granulaire sur le processus. Ceci est vital pour les entreprises qui ont des exigences strictes en matière de conformité et de traitement des données. En revanche, l'ELT s'appuie sur les capacités du système cible, qui peut exposer des données brutes, non masquées, jusqu'à ce que les transformations soient terminées.
Lorsque vous décidez de choisir entre ETL et ELT, tenez compte des éléments suivants :
Les plateformes d'intégration de données modernes peuvent brouiller les frontières entre l'ETL et l'ELT, en offrant des outils qui combinent les points forts des deux approches. Ces plateformes peuvent aider les entreprises à choisir et à mettre en œuvre la bonne stratégie en fonction de leurs besoins spécifiques.
Le choix entre l'ETL et l'ELT n'est pas tout blanc ou tout noir. Les deux méthodes ont leurs mérites et le choix optimal dépend souvent des besoins et des circonstances spécifiques de l'entreprise. En comprenant les subtilités de chaque approche et en exploitant les plateformes modernes d'intégration des données, les responsables des données peuvent prendre des décisions éclairées, conduisant leurs entreprises vers un avenir plus informé.
Pour débuter avec l'ETL, le cours ETL with Python de DataCamp est la ressource idéale, couvrant divers outils et la façon de créer des pipelines efficaces. Si vous souhaitez entamer une carrière dans le domaine de l'ingénierie des données, consultez notre certification d'ingénieur en données pour prouver vos compétences aux employeurs.
Commencez dès aujourd'hui votre voyage dans l'ingénierie des données !
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Kurtis Pykes
9 min
blog
Nisha Arya Ahmed
15 min
Tutoriel
Samuel Shaibu
