
Leerpad
Basisprincipes van AI-agenten
6 Hr
Claude Sonnet 4.6 is Anthropic’s nieuwste large language model (LLM). Het richt zich sterk op agentisch coderen, computergebruik en andere agentische vaardigheden, en is het lichtere model vergeleken met het recent uitgebrachte vlaggenschipmodel, Claude Opus 4.6.
De incrementeel klinkende update had niet zo lang geleden misschien verrast, maar sluit aan bij deze recente release. Mijn interpretatie van de versienummering is dat Claude Sonnet 4.6 mogelijk niet veel volledig nieuwe standalone features introduceert, maar recent toegevoegde functies integreert in de Sonnet-modelfamilie.
Naast het beschikbaar maken van voorheen betaalde functies voor alle gebruikers, presteert Claude Sonnet 4.6 op alle fronten aanzienlijk beter dan zijn voorganger, terwijl het het API-tarief van Claude Sonnet 4.5 ($3/$15 per miljoen input/outputtokens) aanhoudt. Het is direct beschikbaar via zowel de webchatinterface van Claude als de API.
Anthropic’s insteek bij deze release lijkt het bieden van Opus-achtige vlaggschippresentaties voor een Sonnet-prijs. Dat klinkt ambitieus, maar de benchmarkresultaten wijzen erop dat dit doel is gehaald, zoals we later nader bekijken.
Een opvallend voorbeeld zijn de agentische computergebruikvaardigheden van Claude Sonnet 4.6, dat een zeer indrukwekkende 72,5% scoort op OSWorld-Verified. Zoals we in de onderstaande grafiek zien, hebben de Sonnet-modellen een grote sprong gemaakt en deze score in minder dan een jaar meer dan verdubbeld.
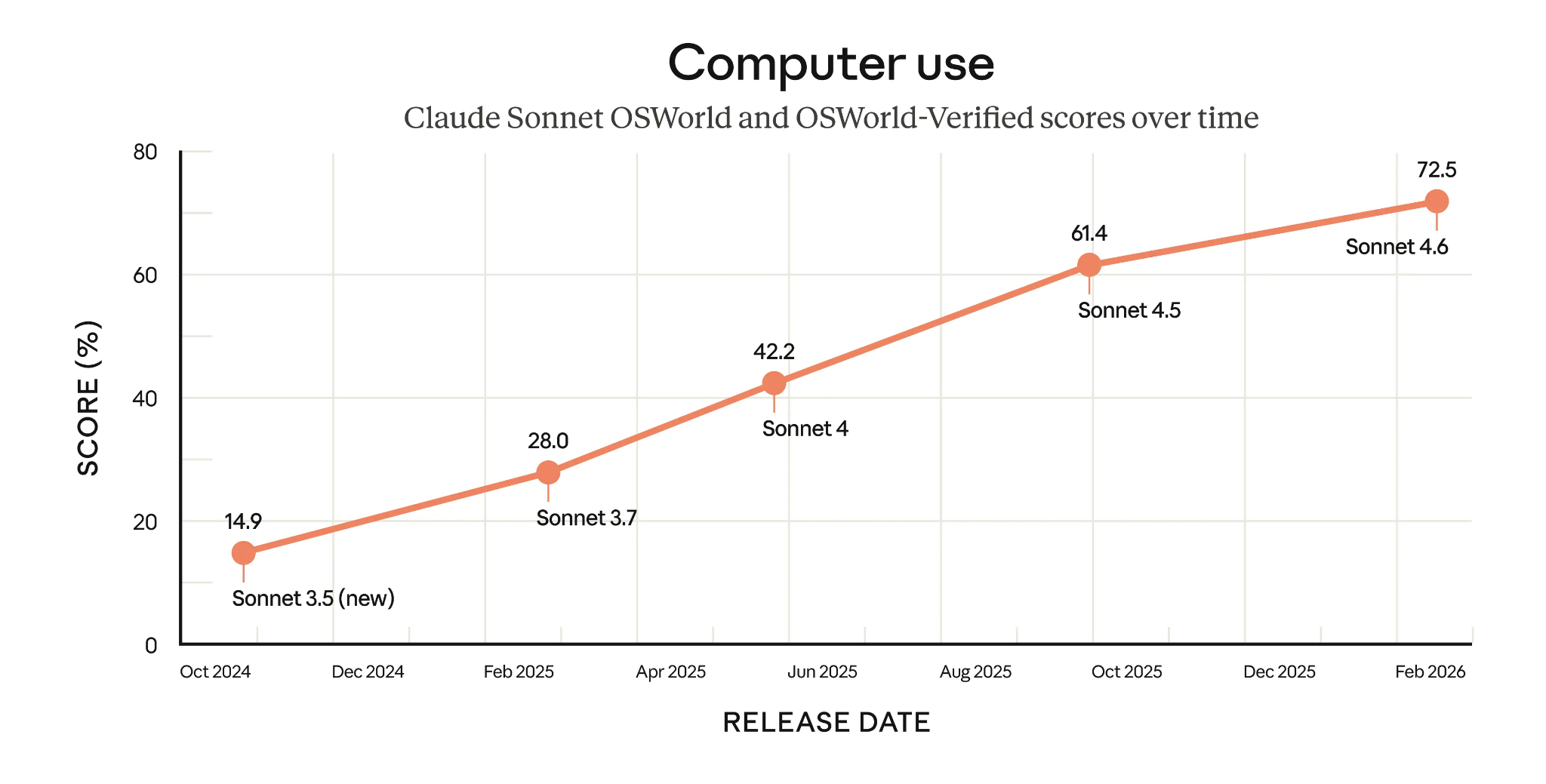
OSWorld-Verified-scores van Claude Sonnet-modellen in de tijd (Bron: Anthropic)
Laten we een paar opvallende features van het nieuwe model bekijken:
Claude Sonnet 4.6 levert een volledige upgrade van vaardigheden over een breed scala aan taken, waaronder:
Volgens de releasenote gaven bètatesters ongeveer 59% van de tijd de voorkeur aan het gebruik van Sonnet 4.6 boven Opus 4.5, tot twee weken geleden nog Anthropic’s vlaggenschipmodel.
Ze noemden beter instructievolgen, minder hallucinaties en betrouwbaardere meerstapsprobleemoplossing als redenen voor die voorkeur.
Het model toont mensniveau-capaciteit op veel echte softwaretaken, zoals:
Dit blijkt onder meer uit de sterke OSWorld-Verified-score en uit enkele domeinspecifieke benchmarks die we later bespreken.
Een ander aandachtspunt bij de modelontwikkeling was veiligheid, wat vooral relevant is bij de verschuiving naar agentische AI. Anthropic stelt dat Claude Sonnet 4.6 aanzienlijk beter bestand is tegen prompt-injecties dan Sonnet 4.5 en in dit opzicht gelijkwaardig is aan Opus 4.6.
De misschien wel meest aansprekende claim betreft het uitgebreide contextvenster, dat nu 1 miljoen tokens beslaat. Hierdoor kan Sonnet 4.6 nog grotere codebases, lange contracten of omvangrijke onderzoeksbundels in één keer verwerken en daar effectief over redeneren. Dit uitgebreide contextvenster plaatst Sonnet 4.6 op gelijke voet met Google’s Gemini 3.
Een voorbeeld van verbeterde langetermijnplanning is de Vending-Bench Arena, die test of een model een gesimuleerd bedrijf in de tijd kan runnen, met een element van competitie tussen modellen. Door in het begin zwaar in infrastructuur te investeren en daar later de vruchten van te plukken, wist Sonnet 4.6 de gemiddelde winst van Sonnet 4.5 na één jaar bijna te verdrievoudigen.
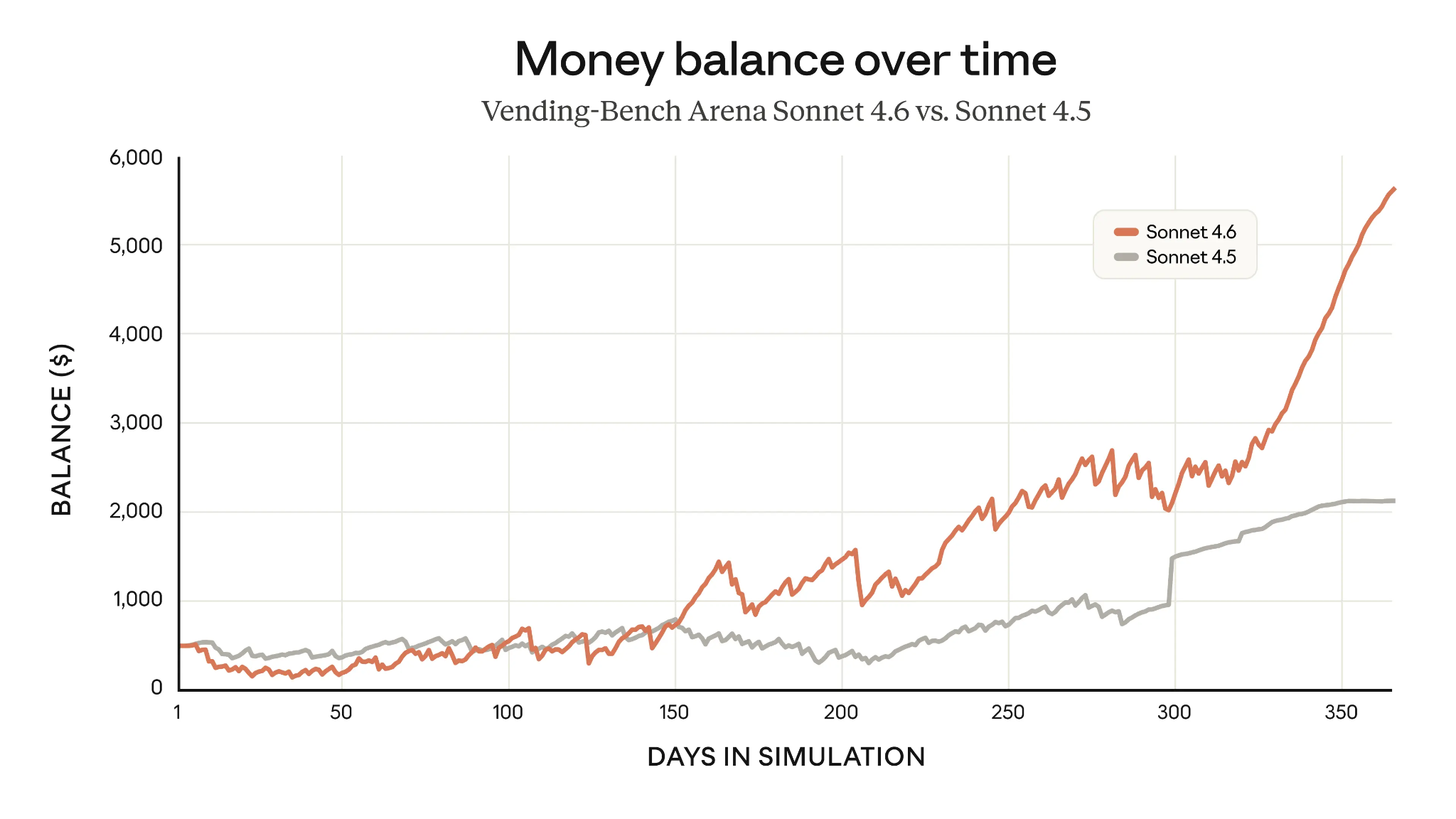
Vending-Bench-scores van Claude Sonnet 4.6 vs Sonnet 4.5 (Bron: Anthropic)
Op het Claude-platform en in de API maakt Sonnet 4.6 enkele functies die eerder beperkt waren tot Opus-modellen of betaalde lagen, gratis beschikbaar.
Een handige functie die werd geïntroduceerd met de release van Claude Opus 4.6 is adaptief denken. Hiermee kan Claude automatisch bepalen wanneer en hoeveel het moet redeneren voordat het antwoordt. In de API schakel je dit in met thinking: {type: “adaptive”}. In de webchatinterface is dit standaard ingebouwd voor Sonnet 4.6 en Opus 4.6.
Connectors bieden op MCP gebaseerde integraties, wat betekent dat ze directe toegang geven tot externe apps zoals Google Workspace en Slack. Zo kan Sonnet 4.6 realtime data uit deze tools ophalen en erop handelen binnen chats. Oorspronkelijk waren connectors alleen beschikbaar voor betaalde lagen, maar nu Sonnet 4.6 het nieuwe standaardmodel is, zijn ze ook voor gratis gebruikers beschikbaar.
Ik was benieuwd hoe goed Claude Sonnet 4.6 presteert op dezelfde taken die we gebruikten in onze gids over Claude Opus 4.6, zodat we de twee direct kunnen vergelijken. De tests zijn ontworpen als meerstapstaken en toetsen wiskundig en codegerelateerd redeneren.
De eerste test richt zich op wiskundige vaardigheden:
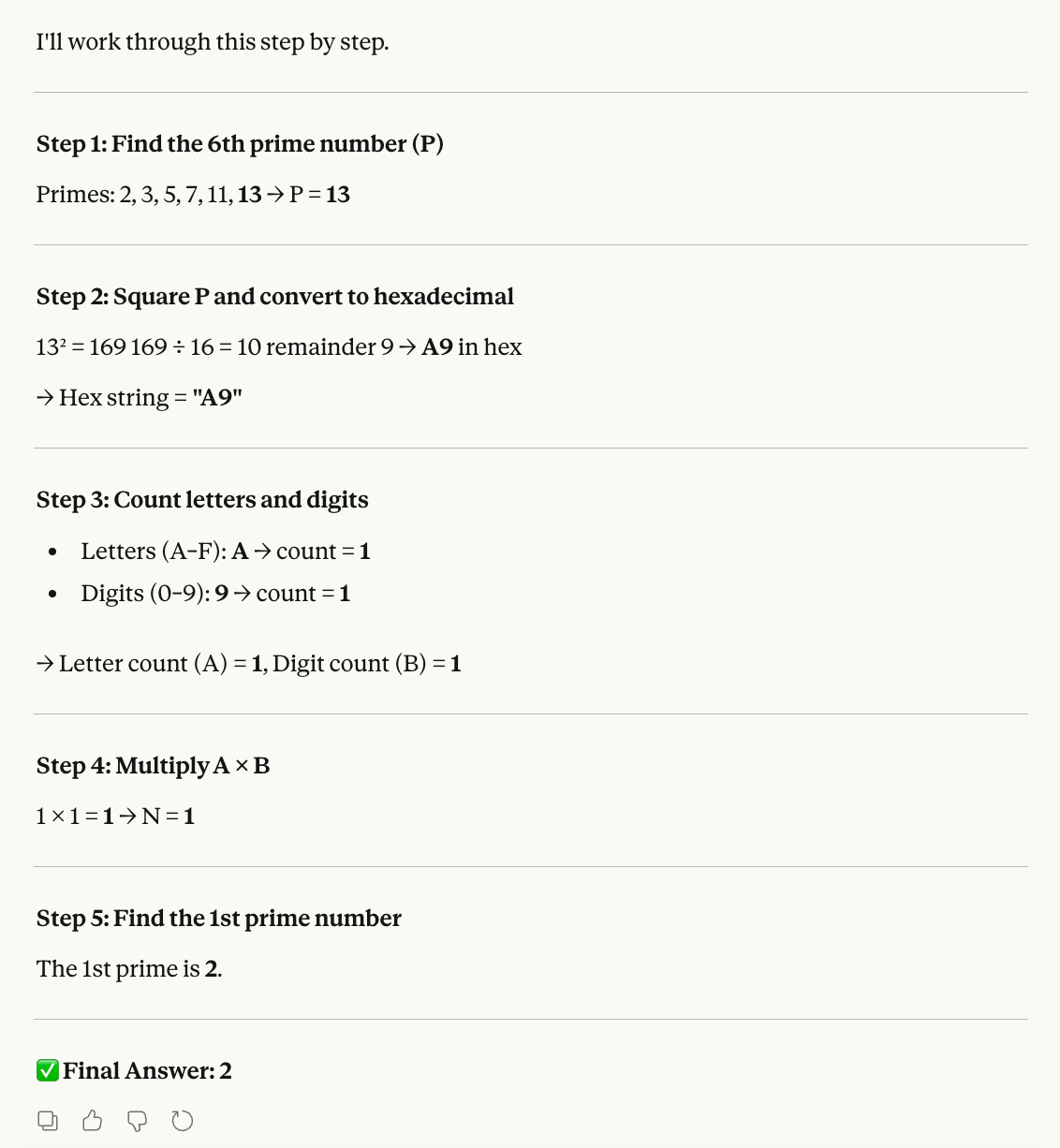
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Laten we zelf rekenen, zodat we kunnen controleren of het resultaat klopt:
Het idee achter deze test was om het model te verwarren met taken die verschillende tel-logica’s en talstelsels vereisen. Net als Opus 4.6 doorloopt Sonnet 4.6 elke stap succesvol en komt het tot de juiste conclusie:
De volgende test richt zich op ruimtelijk redeneren, een berucht zwak punt van veel LLM’s:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Het juiste antwoord is -6.065:
Sonnet 4.6 heeft geen moeite met de taak. Het begrijpt de ruimtelijke context van de matrix en roteert die correct, en ook negatieve getallen leveren geen problemen op:


Tot slot richten we ons op code debuggen, een van de veronderstelde sterke punten van Sonnet 4.6. De test is bedoeld om te zien hoe contextbewust het model is bij een specifieke bug.
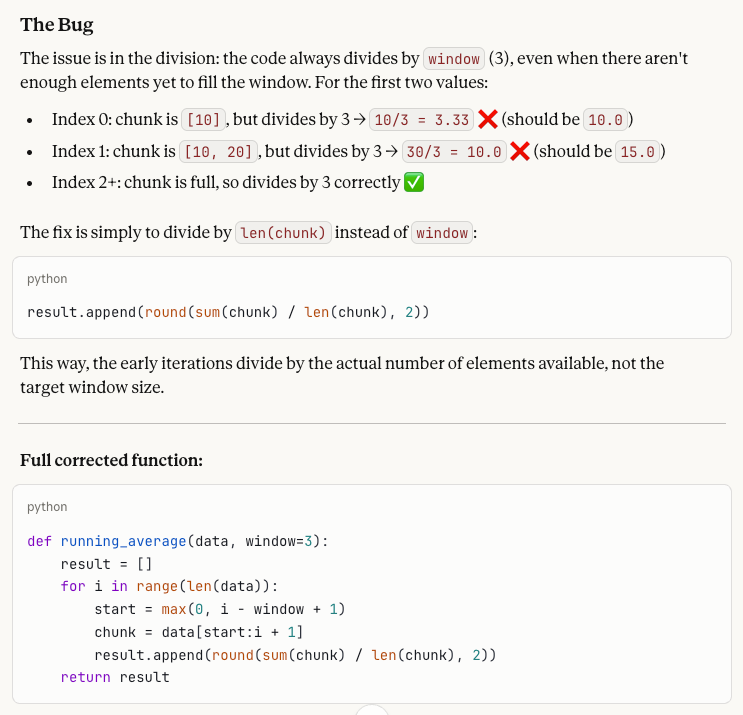
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Het probleem in deze code is dat de functie altijd door window (3) deelt, ook als er aan het begin nog geen 3 elementen in de chunk zitten. De output van de buggy code is [3.33, 10.0, 20.0, 30.0, 40.0], maar de eerste twee waarden zouden 10,0 en 15,0 moeten zijn, omdat die chunks respectievelijk 1 en 2 elementen bevatten en dus door die aantallen gedeeld moeten worden. De oplossing is daarom delen door len(chunk) in plaats van window.
Deze test is leuk omdat hij een zwak punt van LLM’s raakt: ze voeren de lus vaak perfect uit maar nemen de output als correct aan. Dat komt doordat ze de berekeningen stap voor stap zonder fouten zien, maar niet overwegen wat de functie zou moeten doen. Alleen als het model het doel van de functie aan de uitvoering koppelt, kan het de bug vinden.
Opnieuw slaagt het model. Dit was natuurlijk slechts een kleine selectie testen die je met het model kunt doen, maar in deze voorbeelden presteert Sonnet 4.6 op hetzelfde niveau als Opus 4.6.
Met de hoge frequentie waarmee de laatste tijd modellen verschijnen, zijn we al gewend aan veel beweging in de bovenste regionen van de leaderboard van elke benchmark. Toch maken de eerste resultaten van Claude Sonnet 4.6 op meerdere LLM-benchmarks indruk, zeker gezien het niet om Anthropic’s vlaggenschipmodel gaat.
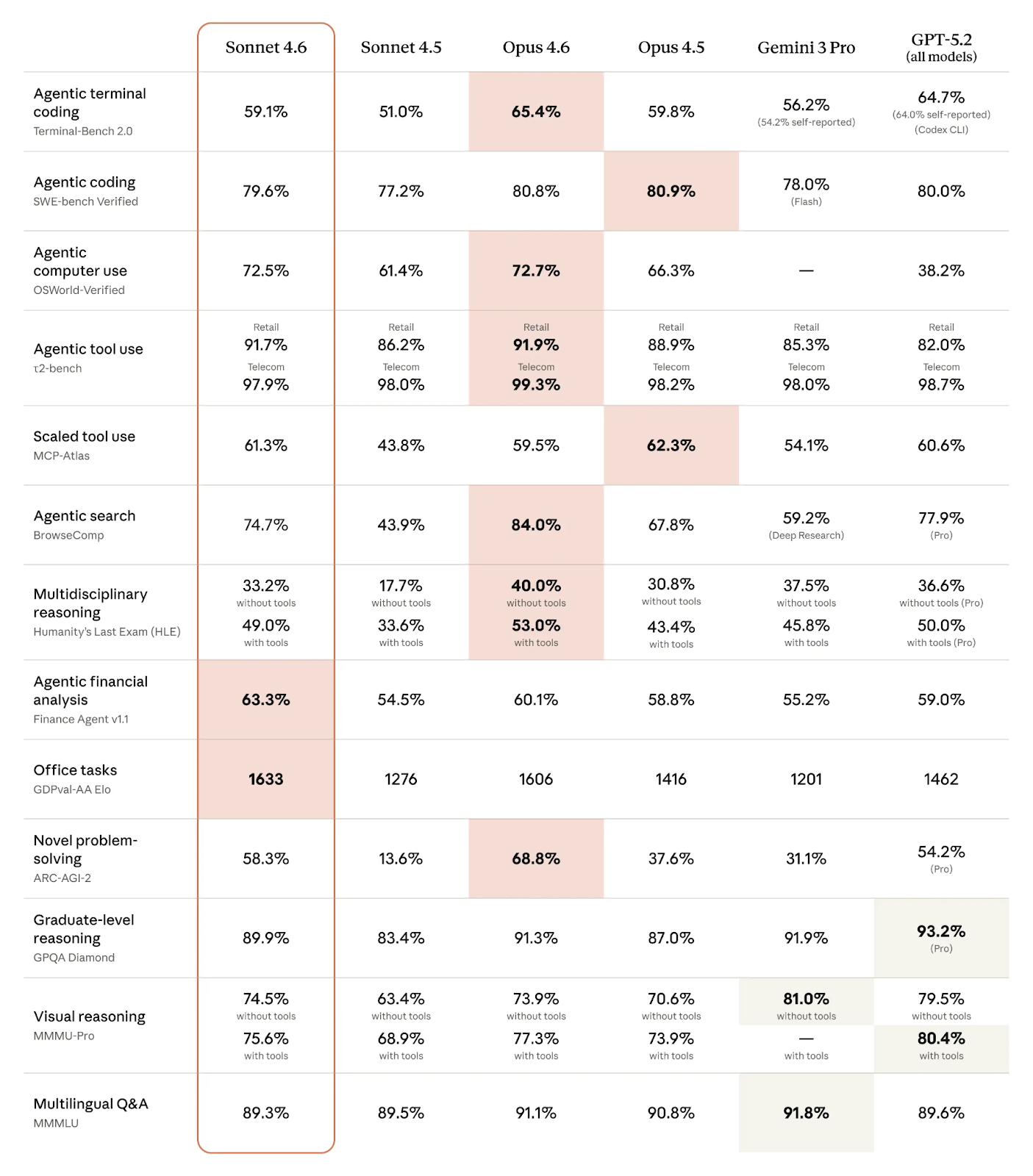
Benchmarkscores van Claude Sonnet 4.6 en concurrenten (Bron: Anthropic)
Zoals we in de tabel zien, doet Claude Sonnet 4.6 het erg goed op agentische benchmarks:
Opvallend is vooral dat Anthropic de concurrentie lijkt te overtreffen in specifieke domeingerelateerde agentische taken:
Je kunt Claude Sonnet 4.6 nu via meerdere kanalen gebruiken. Zo krijg je er toegang toe:
Sonnet 4.6 is beschikbaar via de webchatinterface Claude.ai, de iOS- en Android-apps en de macOS-desktopapp met Claude Cowork.
Op al deze platforms is het het nieuwe standaardmodel, zelfs voor de gratis laag. Dat betekent dat bestandscreatie, connectors, skills en contextcompactie nu voor alle gebruikers beschikbaar zijn.
Developers kunnen Claude Sonnet 4.6 gebruiken via de Anthropic API met het model-ID claude-sonnet-4-6. De prijzen blijven gelijk aan die van zijn voorganger: een miljoen inputtokens kost $3, een miljoen outputtokens $15.
Voor implementatie op ondernemingsschaal is Sonnet 4.6 beschikbaar op verschillende cloudplatforms, zoals AWS Bedrock of Google Vertex AI, elk met aangepaste prijzen.
Claude Sonnet 4.6 drijft nu ook Claude Code aan en is het standaardmodel voor Pro- en Team-accounts, terwijl hogere lagen standaard Opus 4.6 gebruiken. Wil je voorbeelden zien van wat je ermee kunt bouwen, bekijk dan onze tutorials over Claude Code hooks en plugins bouwen voor Claude Code.
Daarnaast kan Sonnet 4.6 ook worden gebruikt met IDE’s en andere code-assistenten, zoals Cursor of Roo Code.
In veel domeinen is het verschil tussen Sonnet 4.6 en Opus 4.6 zo klein dat je het een gelijkspel kunt noemen. Dit geldt vooral voor veel agentische taken, zoals agentisch coderen, agentisch computergebruik en agentisch toolgebruik. Sonnet 4.6 presteert zelfs beter dan Opus 4.6 op agentische financiële analyse, kantoortaken en grootschalig toolgebruik.
Zoals te verwachten, blinkt Opus 4.6 vooral uit in taken die zwaar leunen op redeneren of creativiteit, zoals nieuwe probleemoplossing en multidisciplinair redeneren. Binnen het agentische domein is Opus 4.6 beter in agentisch terminalcoderen en agentisch zoeken.
Voor de meeste codeer- en agentische taken, en voor taken waarbij instructies volgen cruciaal is, is Claude Sonnet 4.6 de betere keuze omdat het vrijwel identieke prestaties levert tegen aanzienlijk lagere kosten. Bovendien is het vaak sneller.
Teams die afhankelijk zijn van redeneren op expertniveau of multi-agentworkflows kiezen beter voor Claude Opus 4.6. Vooral voor research, complexe migraties of werk met hoge inzet excelleert Opus 4.6.
Met Claude Sonnet 4.5 blijft Anthropic de nadruk leggen op code, agents en computergebruik. Naast een enorme prestatieverbetering ten opzichte van zijn voorganger, maakt het functies als connectors en adaptief denken beschikbaar voor alle gebruikers, zelfs in de gratis laag.
De eerste indrukken en benchmarkresultaten zijn erg goed, en het voelt als een gamechanger doordat het (bijna) Opus-niveau biedt zonder het hoge prijskaartje. Voor veel dagelijkse workflows is het zelfs lastig te beargumenteren waarom je in plaats daarvan Anthropic’s vlaggenschip zou gebruiken. Dat gezegd hebbende, voor taken die zwaar leunen op redeneren blijft Claude Opus 4.6 de betere keuze.
Het wordt interessant om te zien hoe lang Claude Sonnet 4.6 bovenaan de benchmarklijsten blijft en hoe de concurrentie van Anthropic op deze release reageert.
We hebben het in dit artikel steeds over agentische taken gehad. Wil je meer leren over het gebruik van modellen zoals Claude Sonnet 4.6 in dit soort workflows, dan raad ik onze AI Agent Fundamentals skill track aan.
AI-cursussen
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
