
programa
Fundamentos de agentes de IA
6 h
Claude Sonnet 4.6 es el último modelo de lenguaje grande (LLM) de Anthropic. Se centra especialmente en programación agentic, uso del ordenador y otras capacidades agentic, y es el modelo más ligero frente al modelo insignia publicado recientemente, Claude Opus 4.6.
Aunque la actualización suena incremental, está en línea con este último lanzamiento. Mi lectura del versionado es que Claude Sonnet 4.6 quizá no introduzca muchas funciones totalmente nuevas, sino que integre en la familia Sonnet características presentadas recientemente.
Además de abrir a todos los usuarios funciones que antes eran de pago, Claude Sonnet 4.6 rinde mucho mejor que su predecesor en todos los frentes, manteniendo el precio de la API de Claude Sonnet 4.5 (3 $/15 $ por millón de tokens de entrada/salida). Está disponible de inmediato tanto en la interfaz web de chat de Claude como vía API.
La apuesta de Anthropic con este lanzamiento parece ser ofrecer rendimiento de nivel Opus a precio de Sonnet. Aunque suena ambicioso, los resultados en benchmarks apuntan a que lo han logrado, como veremos más adelante.
Un ejemplo destacado son las habilidades de uso agentic del ordenador de Claude Sonnet 4.6, que logra un 72,5% en OSWorld-Verified. Como muestra el gráfico, los modelos Sonnet han avanzado muchísimo y más que duplicado esta puntuación en menos de un año.
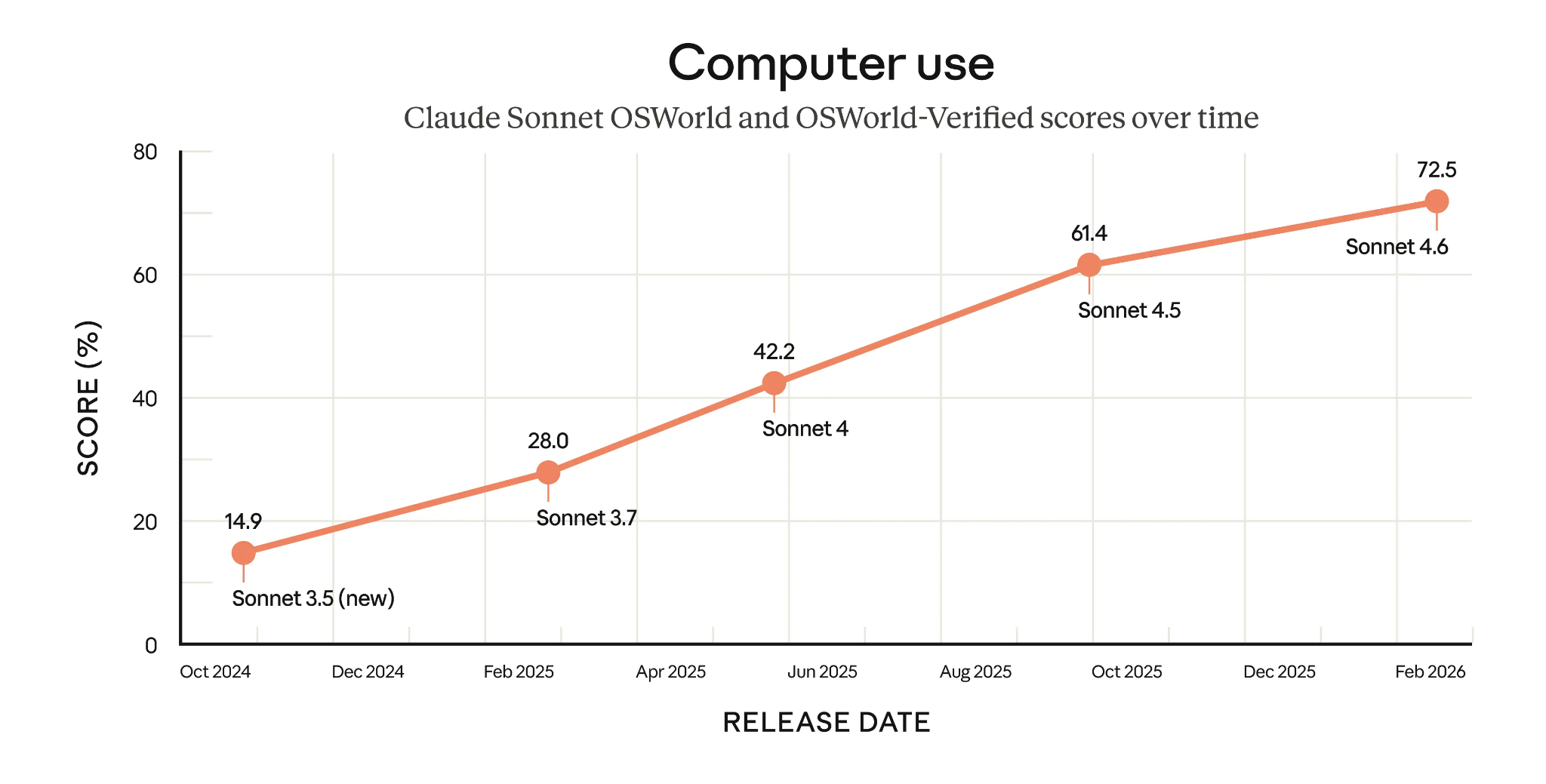
Puntuaciones OSWorld-Verified de los modelos Claude Sonnet a lo largo del tiempo (Fuente: Anthropic)
Veamos algunas de las novedades más destacadas:
Claude Sonnet 4.6 supone una mejora completa de habilidades en una amplia variedad de tareas, incluyendo:
Según la nota de lanzamiento, Anthropic observó que los beta testers preferían usar Sonnet 4.6 frente a Opus 4.5, que fue el modelo insignia de Anthropic hasta hace apenas dos semanas, en torno al 59% de las veces.
Argumentaron un mejor seguimiento de instrucciones, menos alucinaciones y una resolución de problemas multietapa más fiable como motivos de su preferencia.
El modelo muestra capacidad a nivel humano en muchas tareas reales de software, como:
Esto se aprecia, por ejemplo, en la alta puntuación de OSWorld-Verified y en algunos benchmarks por dominios que comentaremos más adelante.
Otro foco del desarrollo ha sido la seguridad, especialmente relevante en el giro hacia la IA agentic. Anthropic afirma que Claude Sonnet 4.6 ha mejorado notablemente su resistencia a las prompt injections respecto a Sonnet 4.5 y está a la par con Opus 4.6 en este aspecto.
La afirmación más llamativa gira en torno a la ampliación de la ventana de contexto, que ahora abarca 1 millón de tokens. Esta ampliación permite a Sonnet 4.6 ingerir bases de código aún mayores, contratos extensos o amplios paquetes de investigación en una sola petición, y razonar eficazmente sobre ese contexto. Esta ventana ampliada sitúa a Sonnet 4.6 a la altura de Gemini 3 de Google.
Un ejemplo de planificación a largo plazo mejorada es Vending-Bench Arena, que evalúa la capacidad de un modelo para gestionar un negocio simulado a lo largo del tiempo, con un elemento de competición entre modelos. Al invertir mucho en infraestructura al principio y rentabilizarla más tarde, Sonnet 4.6 casi triplicó las ganancias medias de Sonnet 4.5 tras un año.
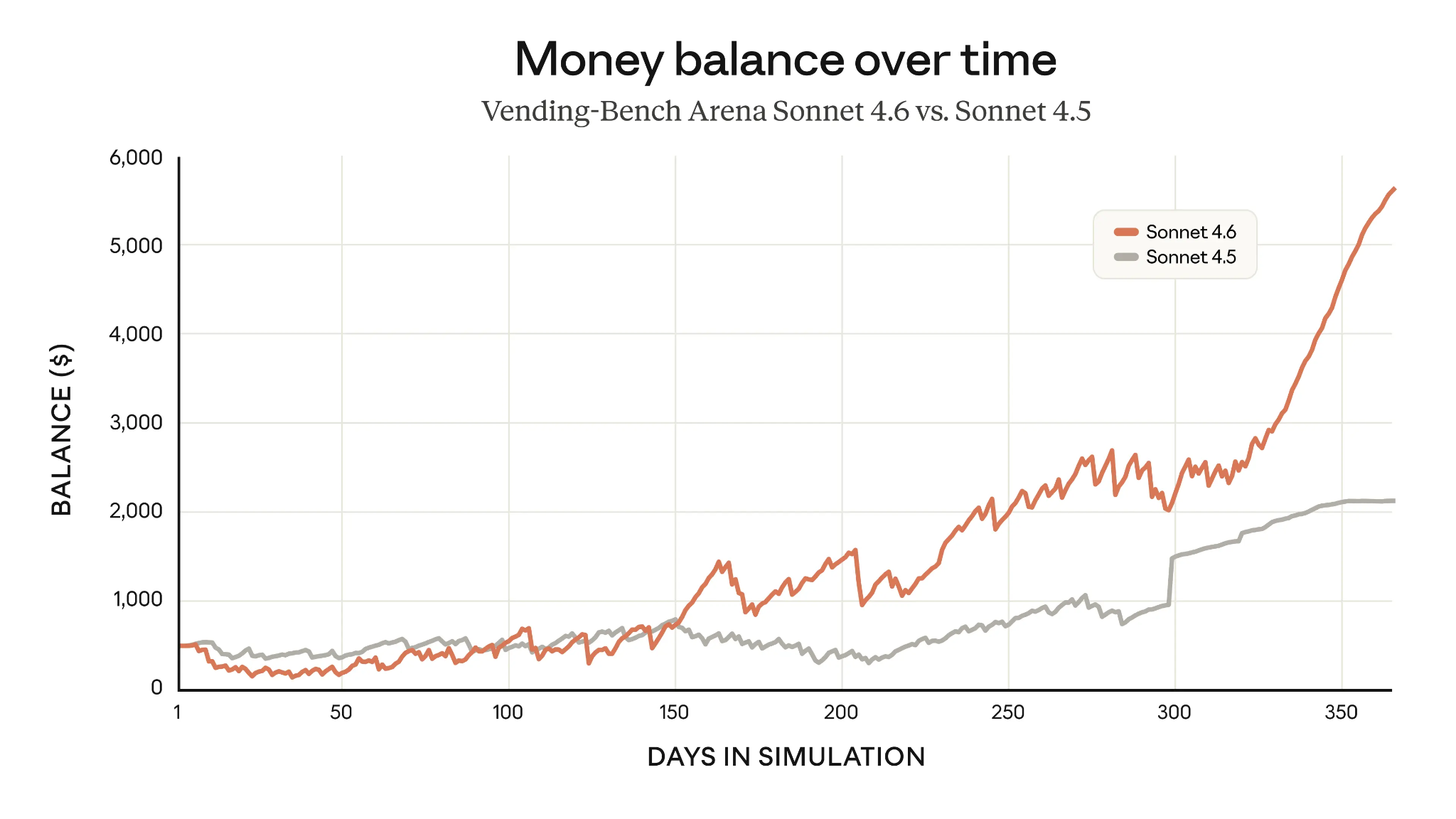
Puntuaciones de Vending-Bench de Claude Sonnet 4.6 vs Sonnet 4.5 (Fuente: Anthropic)
En la plataforma de Claude y su API, Sonnet 4.6 hace disponibles gratis algunas funciones que antes estaban restringidas a modelos Opus o a planes de pago.
Una función interesante introducida con Claude Opus 4.6 es el pensamiento adaptativo. Permite a Claude decidir automáticamente cuándo y cuánto razonar antes de responder. En la API, se activa con thinking: {type: “adaptive”}. En la interfaz web está integrado automáticamente en Sonnet 4.6 y Opus 4.6.
Los conectores ofrecen integraciones basadas en MCP, lo que significa acceso directo a apps externas como Google Workspace y Slack. Así, Sonnet 4.6 puede obtener y accionar datos en tiempo real de estas herramientas dentro de los chats. Originalmente eran una función solo para planes de pago, pero al ser Sonnet 4.6 el nuevo modelo por defecto, también están disponibles para usuarios gratuitos.
Me parecía interesante ver cómo rinde Claude Sonnet 4.6 en las mismas tareas que usamos en nuestra guía de Claude Opus 4.6, para poder compararlos directamente. Las pruebas se diseñaron con tareas multietapa y para evaluar razonamiento matemático y de código.
La primera prueba apunta a las habilidades matemáticas:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Calculemos nosotros mismos para comprobar si el resultado es correcto:
La idea de esta prueba es confundir al modelo con tareas que exigen lógicas de conteo y formatos numéricos distintos. Igual que Opus 4.6, Sonnet 4.6 supera cada paso y llega a la conclusión correcta:
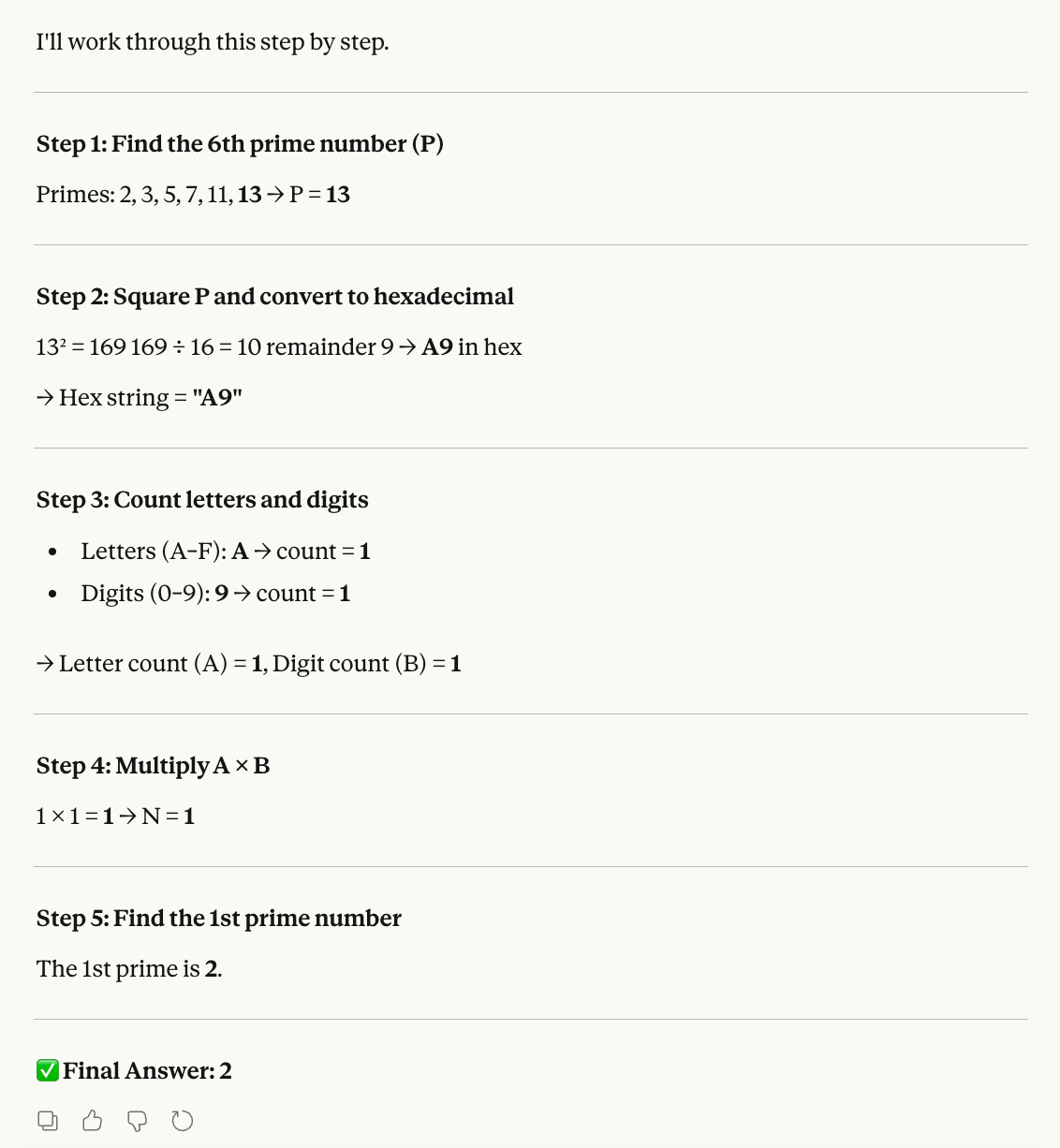
La siguiente prueba evalúa el razonamiento espacial, un punto débil habitual de muchos LLM:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.La respuesta correcta es -6.065:
Sonnet 4.6 no tiene problemas con la tarea. Capta el contexto espacial de la matriz y la rota correctamente, y trabajar con números negativos tampoco le supone dificultad:


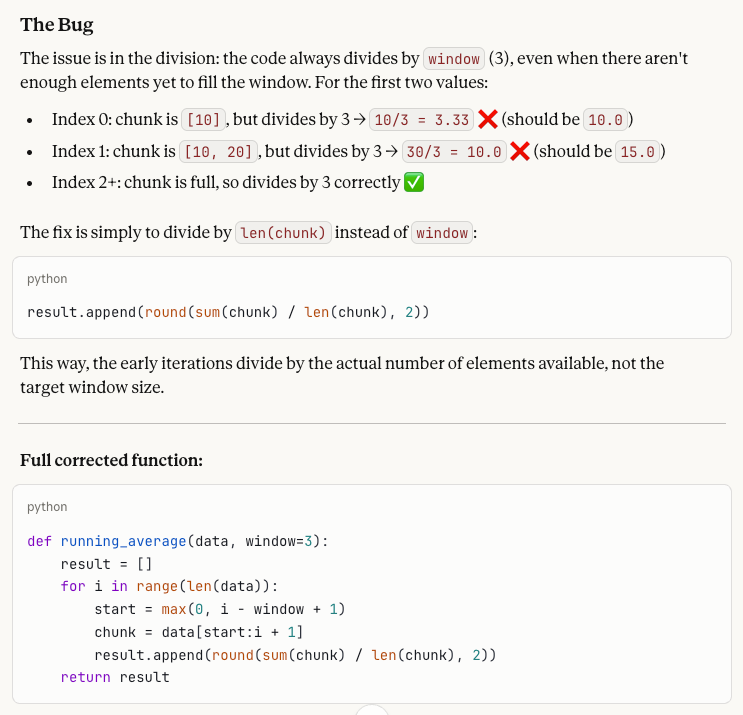
Por último, probemos la depuración de código, uno de los puntos fuertes atribuidos a Sonnet 4.6. La prueba está diseñada para comprobar cuánta conciencia de contexto tiene el modelo ante un bug concreto.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!El problema de este fragmento es que la función siempre divide por window (3), incluso antes de que haya 3 elementos en el chunk al inicio de la lista. La salida del código con bug es [3.33, 10.0, 20.0, 30.0, 40.0], pero los dos primeros valores deberían ser 10.0 y 15.0, ya que esos chunks contienen solo 1 y 2 elementos respectivamente y deberían dividirse por esos números. Por tanto, la corrección es dividir por len(chunk) en lugar de window.
Esta prueba es interesante porque ataca un punto débil típico de los LLM: a menudo ejecutan el bucle a la perfección pero dan por buena la salida. Ven los cálculos paso a paso sin error, pero no consideran lo que la función debería hacer. Solo si el modelo conecta el propósito de la función con su ejecución puede detectar el bug.
De nuevo, el modelo supera la prueba. Por supuesto, esto es solo una pequeña muestra de las pruebas que podrías hacer, pero al menos en estos ejemplos Sonnet 4.6 rinde a la par que Opus 4.6.
Con la alta frecuencia de nuevos modelos últimamente, ya estamos acostumbrados a mucho movimiento en los primeros puestos de cada leaderboard. Aun así, los primeros resultados de Claude Sonnet 4.6 en varios benchmarks de LLM impresionan, sobre todo teniendo en cuenta que no es el modelo insignia de Anthropic.
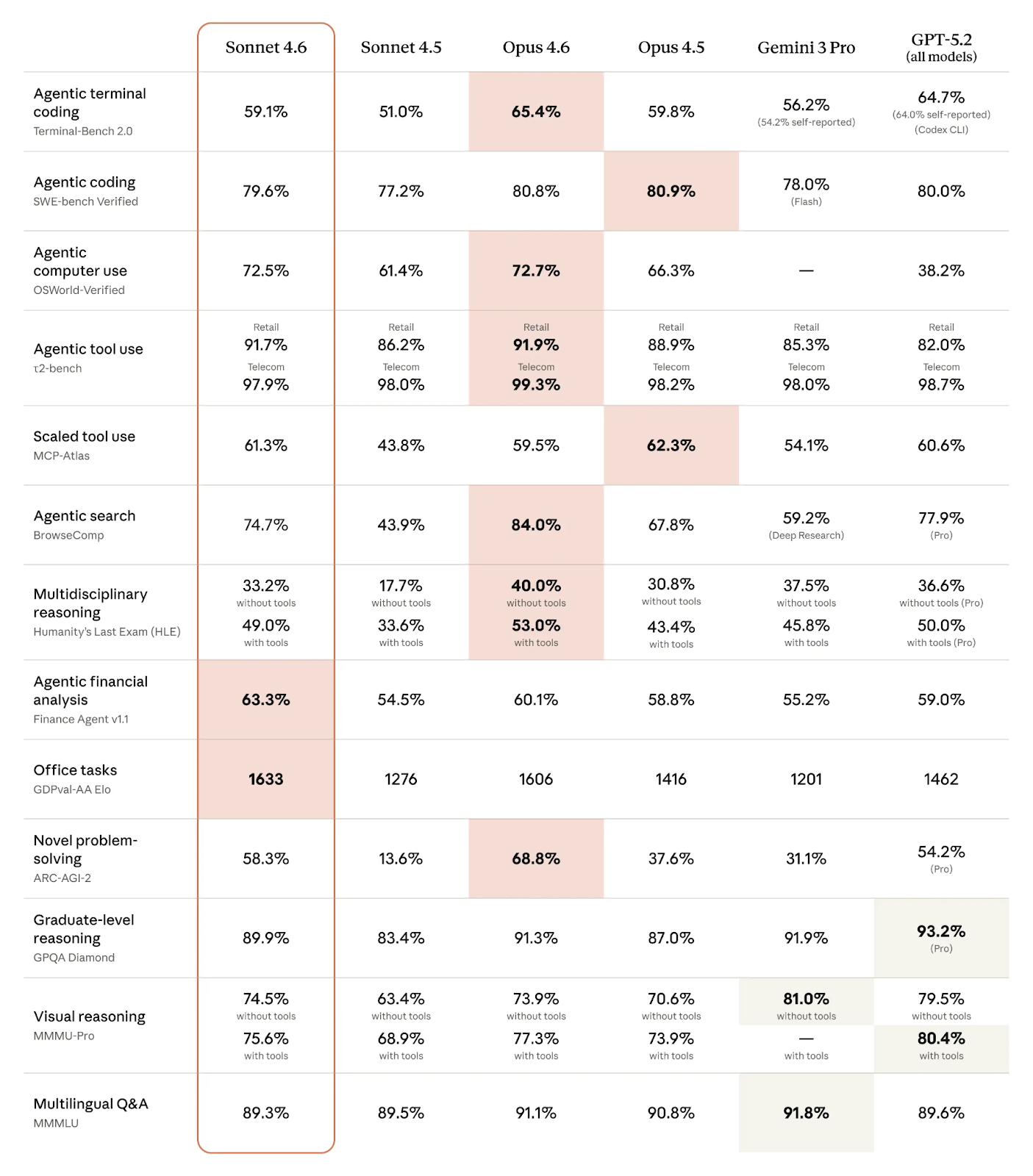
Puntuaciones de benchmarks de Claude Sonnet 4.6 y competidores (Fuente: Anthropic)
Como vemos en la tabla, Claude Sonnet 4.6 brilla en benchmarks agentic:
Destaca especialmente que Anthropic parece ir por delante en tareas agentic específicas por dominio:
Ya puedes usar Claude Sonnet 4.6 a través de varios canales. Así es como puedes acceder:
Sonnet 4.6 está disponible en la interfaz web de Claude.ai, en sus apps para iOS y Android, y en la app de escritorio para macOS con Claude Cowork.
En todas estas plataformas es el nuevo modelo por defecto, incluso en el plan gratuito. Esto significa que la creación de archivos, los conectores, las skills y la compactación de contexto están ahora disponibles para todos.
Los desarrolladores pueden usar Claude Sonnet 4.6 a través de la API de Anthropic con el ID de modelo claude-sonnet-4-6. El precio se mantiene respecto a su predecesor: un millón de tokens de entrada cuesta 3 $ y un millón de salida, 15 $.
Para despliegues a escala empresarial, Sonnet 4.6 está disponible en múltiples plataformas cloud, como AWS Bedrock o Google Vertex AI, cada una con precios personalizados.
Claude Sonnet 4.6 también impulsa ahora Claude Code, y es el modelo por defecto para cuentas Pro y Team, mientras que los planes superiores usan por defecto Opus 4.6. Si quieres ver ejemplos de lo que puedes construir, te recomiendo nuestros tutoriales sobre Claude Code hooks y cómo crear plugins para Claude Code.
Además, Sonnet 4.6 puede usarse con IDEs y otros asistentes de código, como Cursor o Roo Code.
En muchos ámbitos, la diferencia entre Sonnet 4.6 y Opus 4.6 es tan pequeña que podríamos llamarlo un empate. Esto es especialmente cierto en tareas agentic como programación, uso del ordenador y uso de herramientas. Sonnet 4.6 incluso supera a Opus 4.6 en análisis financiero agentic, tareas de oficina y uso de herramientas a escala.
Como era de esperar, donde Opus 4.6 realmente brilla es en tareas que exigen razonamiento intenso o creatividad, como la resolución novedosa de problemas y el razonamiento multidisciplinar. En el ámbito agentic, Opus 4.6 es mejor en programación en terminal y búsqueda agentic.
Para la mayoría de tareas de programación y agentic, y para aquellas donde seguir instrucciones es clave, Claude Sonnet 4.6 es la mejor opción porque ofrece un rendimiento prácticamente idéntico a un coste mucho menor. Además, suele ser más rápido.
Los equipos que dependan de razonamiento experto o flujos multiagente deberían optar por Claude Opus 4.6. Especialmente para investigación, migraciones complejas o trabajo experto de alto impacto, Opus 4.6 destaca.
Con Claude Sonnet 4.5, Anthropic sigue poniendo el foco en código, agentes y uso del ordenador. Además del gran salto de rendimiento frente a su predecesor, pone a disposición de todos funciones como conectores y pensamiento adaptativo, incluso en el plan gratuito.
Las primeras impresiones y resultados en benchmarks son muy buenos, y se siente como un cambio de juego porque ofrece rendimiento (casi) de Opus sin el precio elevado. Para muchos flujos de trabajo del día a día, cuesta incluso justificar el uso del modelo insignia. Dicho esto, para tareas que exigen razonamiento intenso, Claude Opus 4.6 sigue siendo la mejor opción.
Será interesante ver cuánto tiempo puede mantenerse Claude Sonnet 4.6 en lo alto de los rankings y cómo responden los competidores de Anthropic al lanzamiento.
Hemos hablado de tareas agentic a lo largo del artículo. Si quieres aprender más sobre cómo usar modelos como Claude Sonnet 4.6 en este tipo de flujos, te recomiendo nuestro itinerario de habilidades AI Agent Fundamentals.
Cursos de IA
programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Matt Crabtree
13 min
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Arunn Thevapalan

