
Cursus
Principes fondamentaux des agents IA
6 h
Claude Sonnet 4.6 est le dernier grand modèle de langue (LLM) d’Anthropic. Il met l’accent sur le code agentique, l’utilisation de l’ordinateur et d’autres capacités agentiques, et constitue le modèle plus léger par rapport au tout récent modèle phare, Claude Opus 4.6.
Cette mise à jour à l’intitulé incrémental aurait pu surprendre il y a peu, mais elle s’inscrit dans la logique de la sortie récente. On peut interpréter ce versioning ainsi : Claude Sonnet 4.6 n’introduit peut-être pas beaucoup de nouvelles fonctionnalités isolées, mais intègre aux modèles Sonnet des fonctionnalités apparues tout récemment.
En plus de rendre accessibles à tous des fonctions auparavant réservées aux offres payantes, Claude Sonnet 4.6 affiche des performances nettement supérieures à son prédécesseur sur l’ensemble des tâches, tout en conservant la tarification API de Claude Sonnet 4.5 (3 $ / 15 $ par million de tokens en entrée/sortie). Il est disponible immédiatement via l’interface web de chat Claude et l’API.
L’approche d’Anthropic avec cette sortie vise à offrir des performances de niveau Opus au prix de Sonnet. Ambitieux sur le papier, cet objectif semble atteint au vu des benchmarks, que nous détaillerons plus loin.
Un exemple marquant est l’utilisation agentique de l’ordinateur par Claude Sonnet 4.6, qui obtient un très impressionnant 72,5 % sur OSWorld-Verified. Comme on le voit sur le graphique ci-dessous, la progression des modèles Sonnet est spectaculaire : le score a plus que doublé en moins d’un an.
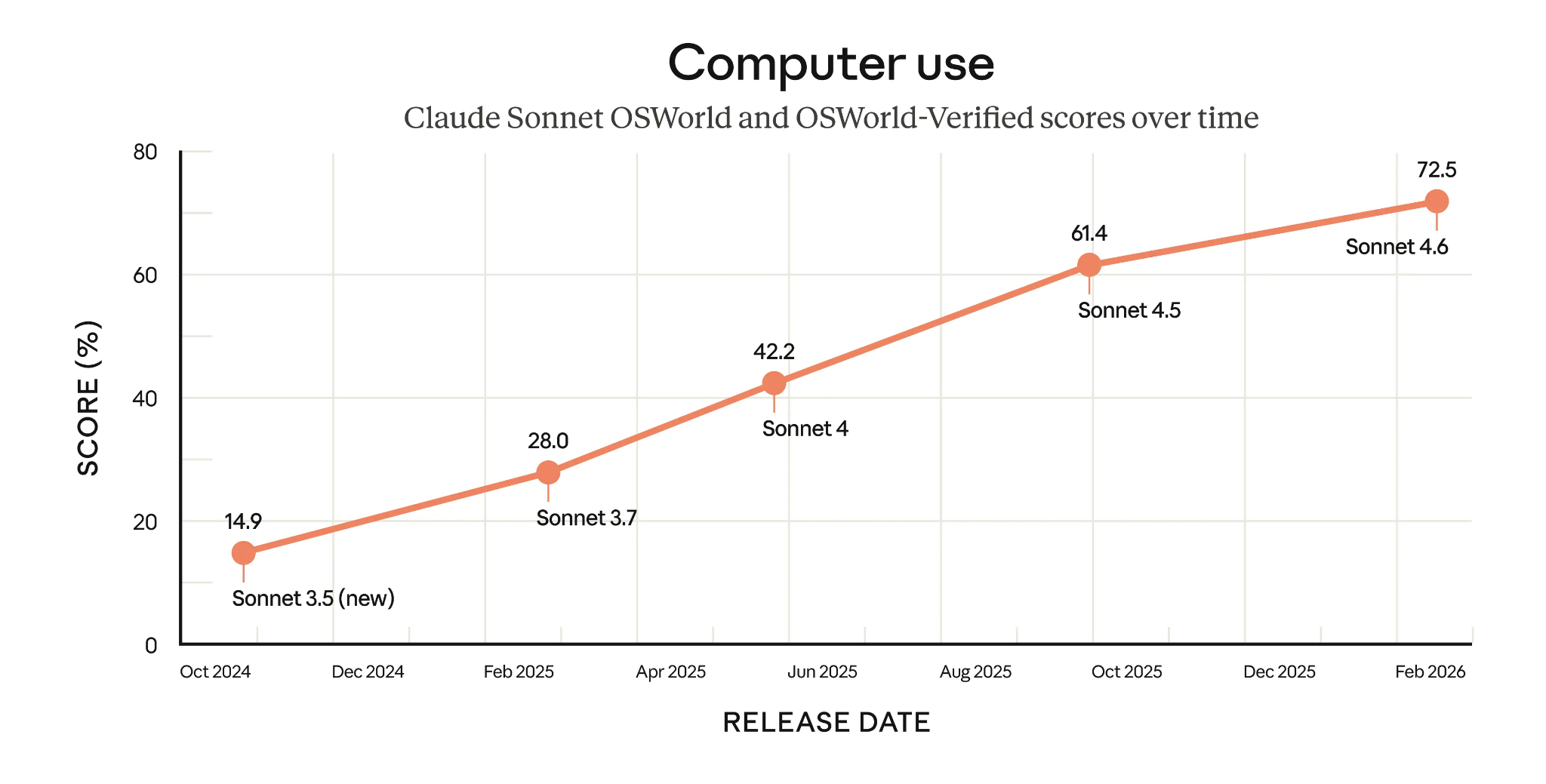
Scores OSWorld-Verified des modèles Claude Sonnet au fil du temps (Source : Anthropic)
Passons en revue quelques points saillants du nouveau modèle :
Claude Sonnet 4.6 bénéficie d’une véritable montée en compétences sur un large éventail de tâches, notamment :
D’après la note de version, Anthropic a constaté que les bêta-testeurs préféraient utiliser Sonnet 4.6 à Opus 4.5, ancien modèle phare d’Anthropic jusqu’il y a deux semaines à peine, environ 59 % du temps.
Ils ont cité une meilleure exécution des consignes, moins d’hallucinations et une résolution de problèmes en plusieurs étapes plus fiable pour expliquer cette préférence.
Le modèle présente des capacités proches du niveau humain sur de nombreuses tâches logicielles réelles, comme :
Cela se reflète notamment dans l’excellent score OSWorld-Verified et dans certains benchmarks métier que nous aborderons plus loin.
La sécurité a également fait l’objet d’un fort investissement, point crucial avec la montée de l’IA agentique. Anthropic affirme que Claude Sonnet 4.6 résiste nettement mieux aux prompt injections que Sonnet 4.5 et se situe au niveau d’Opus 4.6 sur ce volet.
La promesse la plus accrocheuse concerne sans doute la fenêtre de contexte étendue, qui atteint désormais 1 million de tokens. Sonnet 4.6 peut ainsi ingérer en une seule requête de très larges bases de code, des contrats volumineux ou d’importants corpus de recherche, puis raisonner efficacement à cette échelle. Cette fenêtre de contexte le place au niveau de Gemini 3 de Google.
Un exemple d’amélioration de la planification à long terme est Vending-Bench Arena, qui évalue la capacité d’un modèle à faire tourner une entreprise simulée dans la durée, avec un volet compétitif entre modèles. En investissant lourdement dans l’infrastructure au démarrage, puis en capitalisant ensuite, Sonnet 4.6 a quasiment triplé les gains moyens de Sonnet 4.5 après un an.
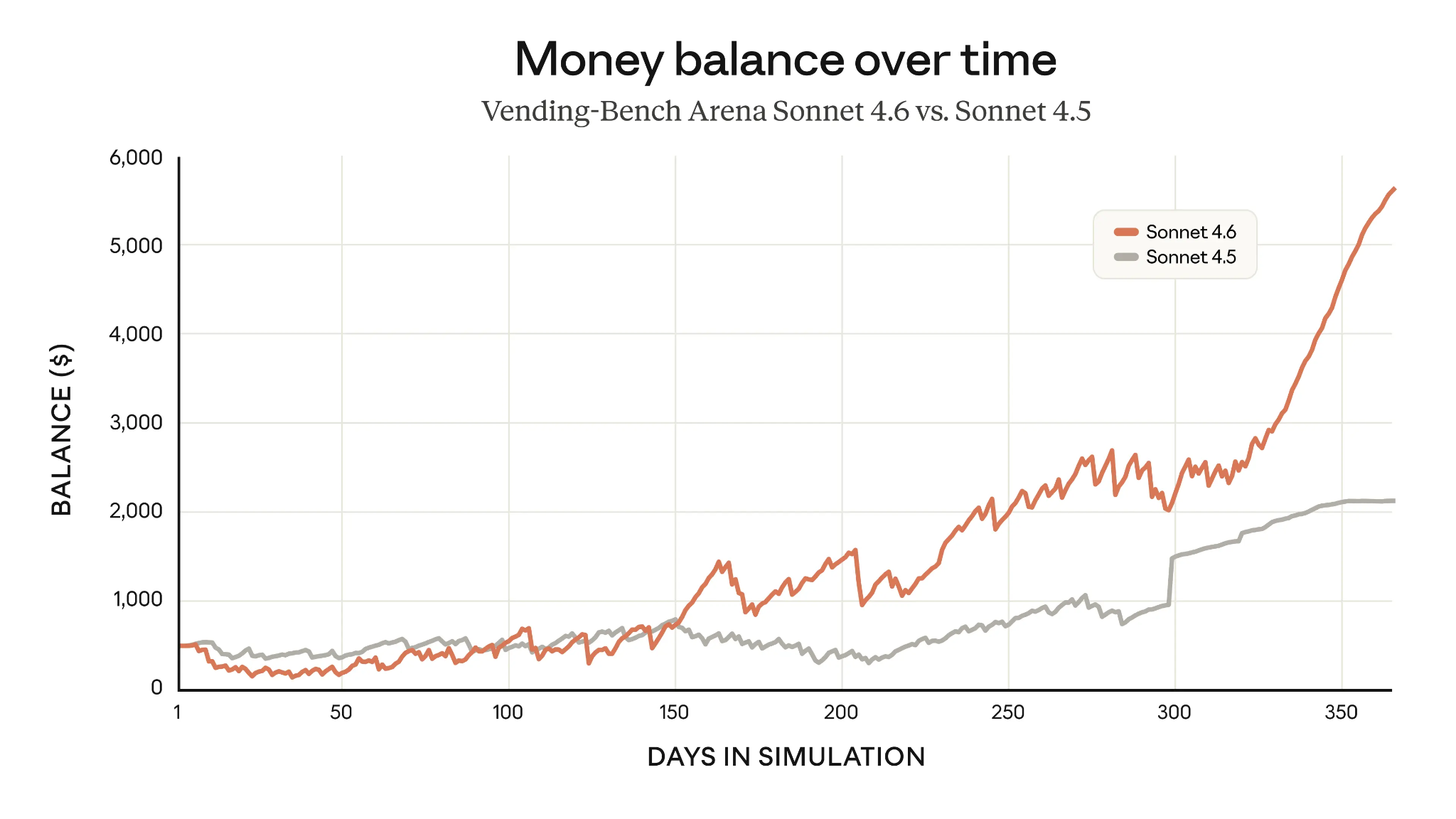
Scores Vending-Bench de Claude Sonnet 4.6 vs Sonnet 4.5 (Source : Anthropic)
Sur la plateforme Claude et via l’API, Sonnet 4.6 généralise des fonctions jusqu’ici réservées aux modèles Opus ou aux offres payantes.
Fonction introduite avec Claude Opus 4.6, le raisonnement adaptatif permet à Claude de décider automatiquement quand et combien raisonner avant de répondre. Dans l’API, on l’active via thinking: {type: “adaptive”}. Il est intégré par défaut pour Sonnet 4.6 et Opus 4.6 dans l’interface web.
Les connecteurs proposent des intégrations basées sur le protocole MCP, donnant un accès direct à des applications externes comme Google Workspace et Slack. Ainsi, Sonnet 4.6 peut récupérer et exploiter des données en temps réel issues de ces outils au sein des conversations. Initialement réservés aux offres payantes, les connecteurs deviennent accessibles aux utilisateurs gratuits avec Sonnet 4.6 comme nouveau modèle par défaut.
J’ai voulu évaluer Claude Sonnet 4.6 sur les mêmes tâches que dans notre guide sur Claude Opus 4.6 pour comparer directement les deux. Les tests visent des tâches en plusieurs étapes et sollicitent le raisonnement mathématique et lié au code.
Le premier test cible les compétences mathématiques :
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
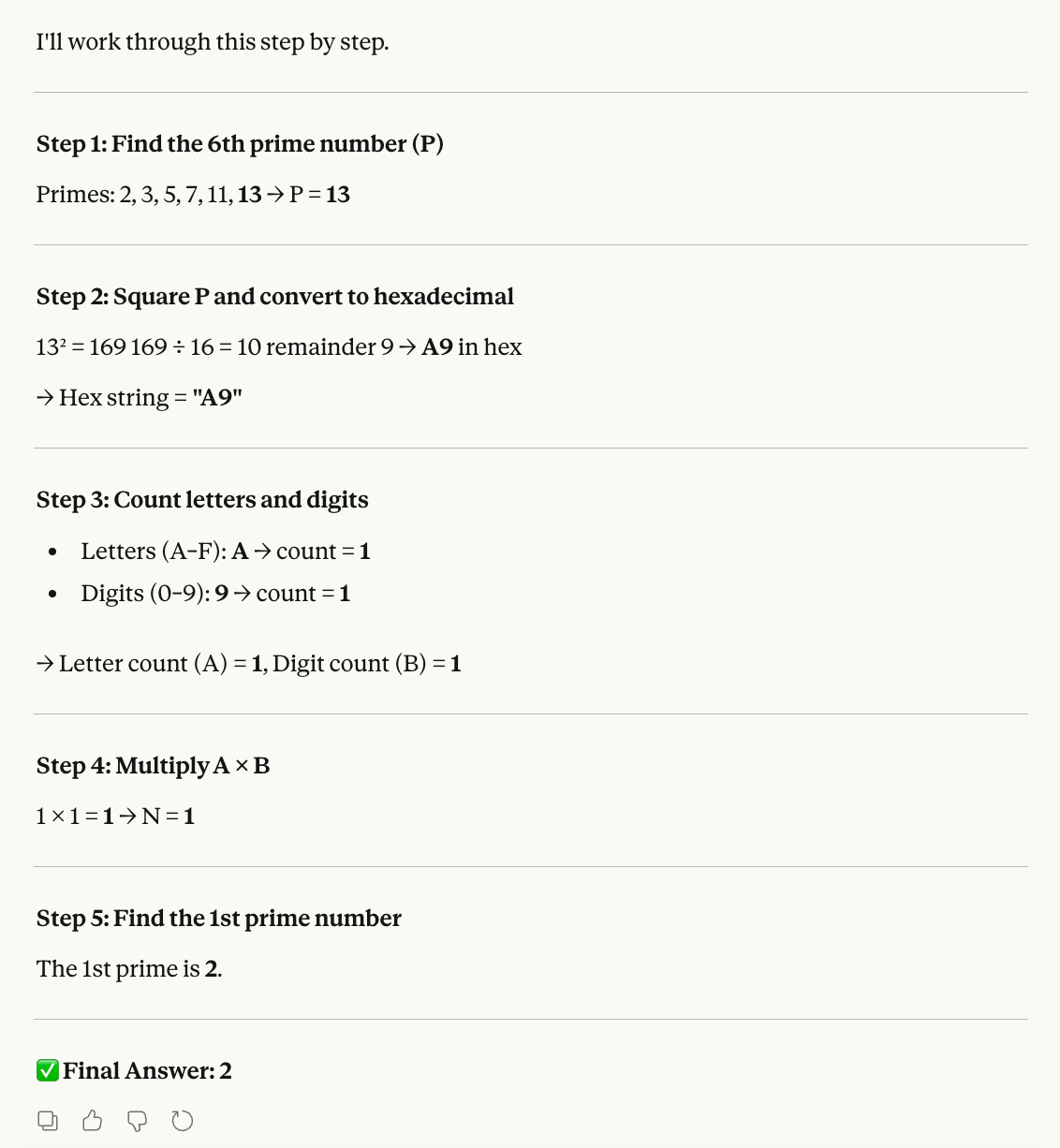
Step 5: Find the Nth prime number.Calculons nous-mêmes pour vérifier le résultat :
L’idée de ce test est de piéger le modèle avec des consignes impliquant différentes logiques de comptage et de formats numériques. Comme Opus 4.6, Sonnet 4.6 réussit chaque étape et aboutit à la bonne conclusion :
Le test suivant cible le raisonnement spatial, traditionnel point faible de nombreux LLM :
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.La réponse correcte est -6 065 :
Sonnet 4.6 ne rencontre aucune difficulté : il comprend le contexte spatial de la matrice et la fait pivoter correctement, et la gestion des nombres négatifs ne lui pose pas de problème non plus :


Terminons par le débogage, l’un des points forts annoncés de Sonnet 4.6. Le test vérifie jusqu’à quel point le modèle tient compte du contexte face à un bug précis.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
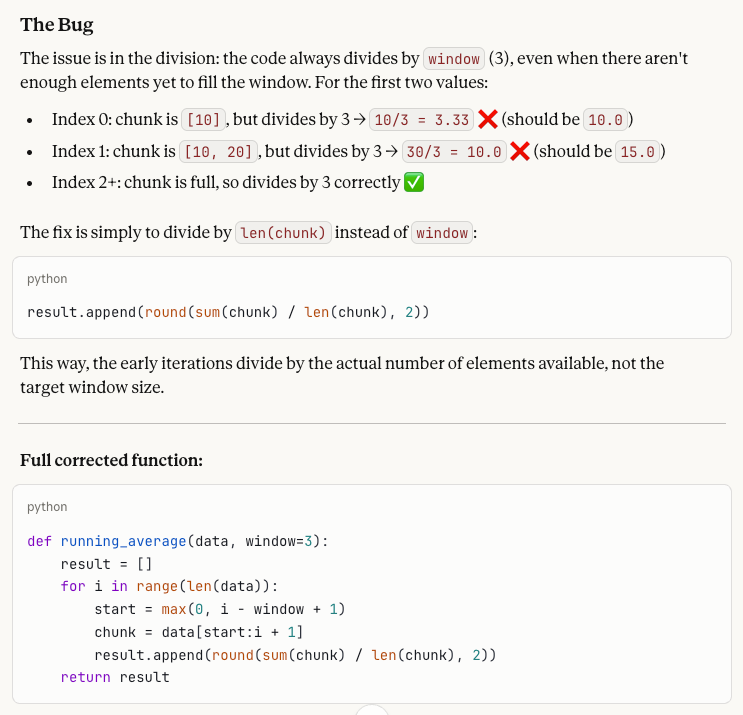
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Le problème, c’est que la fonction divise toujours par window (3), même lorsque le début de la liste ne contient pas encore 3 éléments. La sortie du code bogué est [3.33, 10.0, 20.0, 30.0, 40.0], mais les deux premières valeurs devraient être 10,0 et 15,0, car ces segments ne comptent respectivement que 1 et 2 éléments et doivent être divisés par ces nombres. La correction consiste donc à diviser par len(chunk) au lieu de window.
Ce test est intéressant car il vise un angle mort fréquent des LLM : ils exécutent souvent la boucle correctement mais jugent la sortie correcte. Ils voient les calculs s’enchaîner sans erreur, sans considérer ce que la fonction devrait faire. Seul un lien entre la finalité de la fonction et son exécution permet de repérer le bug.
Là encore, le modèle réussit le test. Bien sûr, il ne s’agit que d’un échantillon très limité de tests possibles, mais sur ces exemples, Sonnet 4.6 est au niveau d’Opus 4.6.
Avec la fréquence à laquelle de nouveaux modèles arrivent en ce moment, on est habitué à voir bouger les têtes de classement des benchmarks. Malgré tout, les premiers résultats de Claude Sonnet 4.6 sur plusieurs benchmarks LLM impressionnent, d’autant plus qu’il ne s’agit pas du modèle phare d’Anthropic.
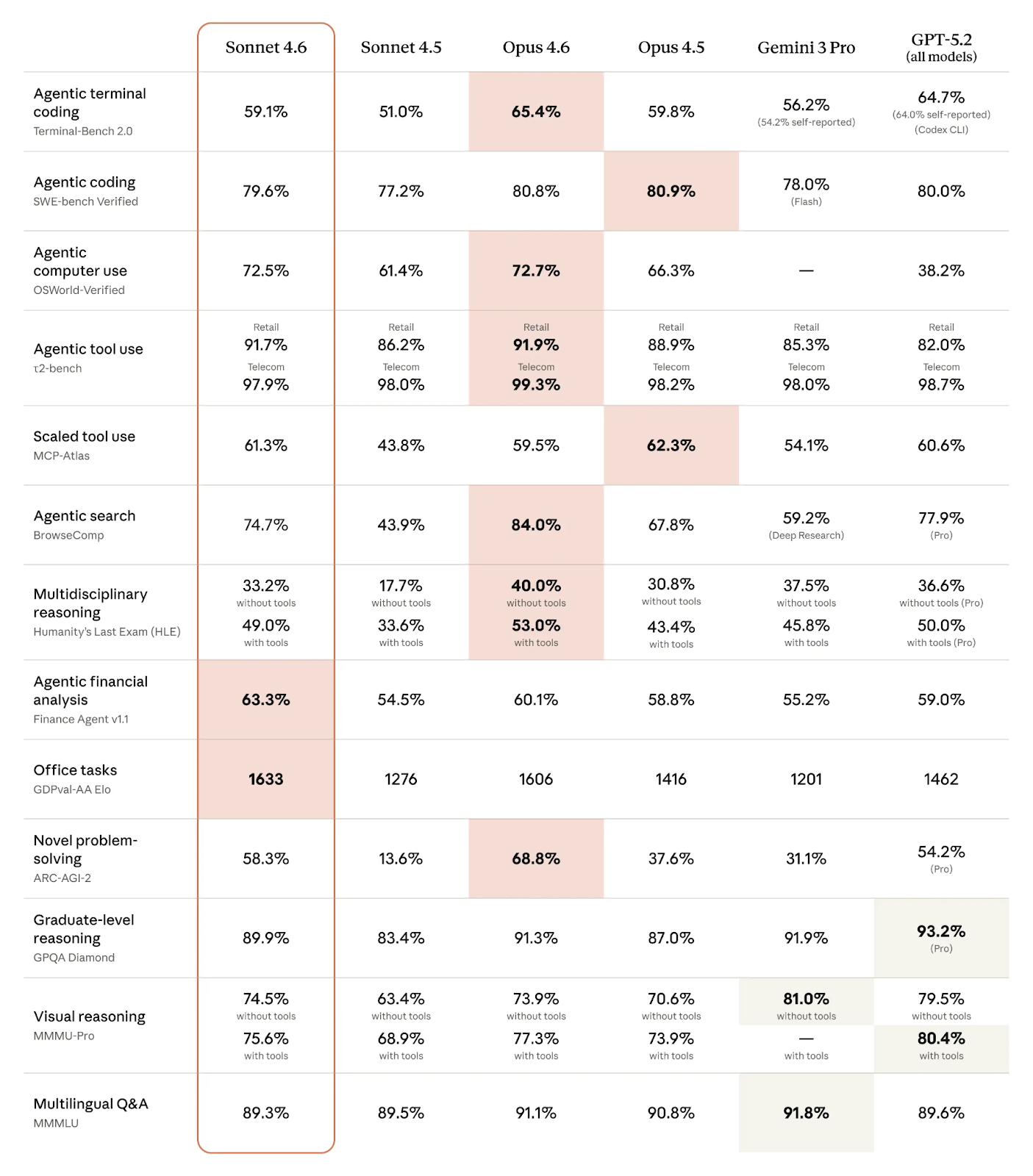
Scores de benchmarks de Claude Sonnet 4.6 et de ses concurrents (Source : Anthropic)
Comme on le voit dans le tableau, Claude Sonnet 4.6 s’illustre sur les benchmarks agentiques :
Point marquant : Anthropic semble prendre l’avantage sur des tâches agentiques spécifiques par domaine :
Vous pouvez utiliser Claude Sonnet 4.6 dès maintenant via plusieurs canaux. Voici comment y accéder :
Sonnet 4.6 est disponible via l’interface web Claude.ai, ses applications iOS et Android, ainsi que l’application de bureau macOS avec Claude Cowork.
Sur toutes ces plateformes, c’est le nouveau modèle par défaut, y compris pour l’offre gratuite. La création de fichiers, les connecteurs, les skills et la compaction de contexte sont donc accessibles à tous.
Les développeurs peuvent utiliser Claude Sonnet 4.6 via l’API Anthropic avec l’ID de modèle claude-sonnet-4-6. La tarification reste identique à celle de son prédécesseur : 3 $ le million de tokens en entrée, 15 $ le million de tokens en sortie.
Pour des déploiements à l’échelle entreprise, Sonnet 4.6 est disponible sur de nombreuses plateformes cloud, comme AWS Bedrock ou Google Vertex AI, avec des tarifs spécifiques.
Claude Sonnet 4.6 alimente désormais Claude Code et est le modèle par défaut pour les offres Pro et Team, tandis que les niveaux supérieurs utilisent par défaut Opus 4.6. Pour voir des exemples de projets à réaliser avec, consultez nos tutoriels sur les hooks Claude Code et la création de plugins pour Claude Code.
En outre, Sonnet 4.6 peut également s’utiliser avec des IDE et autres assistants de code, tels que Cursor ou Roo Code.
Dans de nombreux domaines, l’écart entre Sonnet 4.6 et Opus 4.6 est si faible qu’on peut parler d’ex aequo. C’est particulièrement vrai pour les tâches agentiques comme le code agentique, l’utilisation de l’ordinateur et l’usage d’outils. Sonnet 4.6 surpasse même Opus 4.6 sur l’analyse financière agentique, les tâches bureautiques et l’usage d’outils à grande échelle.
Sans surprise, Opus 4.6 brille sur les tâches impliquant un raisonnement intensif ou de la créativité, comme la résolution de problèmes inédits et le raisonnement pluridisciplinaire. Côté agentique, Opus 4.6 est meilleur en code terminal agentique et en recherche agentique.
Pour la plupart des tâches de code et agentiques, et lorsque le suivi des consignes est clé, Claude Sonnet 4.6 est le meilleur choix : des performances pratiquement identiques pour un coût nettement inférieur. Il a en outre un avantage de vitesse.
Les équipes qui ont besoin d’un raisonnement expert ou de workflows multi-agents opteront plutôt pour Claude Opus 4.6. Pour la recherche, les migrations complexes ou les missions critiques, Opus 4.6 excelle.
Avec Claude Sonnet 4.5, Anthropic continue de mettre l’accent sur le code, les agents et l’utilisation de l’ordinateur. Au-delà d’un bond de performances par rapport à son prédécesseur, il généralise des fonctions comme les connecteurs et le raisonnement adaptatif, y compris dans l’offre gratuite.
Les premières impressions et les benchmarks sont très positifs, et cela ressemble à un changement de dimension : on obtient des performances proches d’Opus sans le prix fort. Pour beaucoup de workflows quotidiens, il est même difficile de justifier l’usage du modèle phare d’Anthropic. Cela dit, pour les tâches qui exigent un raisonnement poussé, Claude Opus 4.6 reste le meilleur choix.
Reste à voir combien de temps Claude Sonnet 4.6 pourra rester en tête des classements et comment les concurrents d’Anthropic répondront à cette sortie.
Nous avons évoqué les tâches agentiques tout au long de l’article. Si vous souhaitez en savoir plus sur l’usage de modèles comme Claude Sonnet 4.6 dans ce type de workflow, je vous recommande notre parcours de compétences AI Agent Fundamentals.
Cours d’IA
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Lynn Heidmann
Tutoriel
Tutoriel
Laiba Siddiqui


