
Programma
Nozioni di base sugli agenti AI
6 h
Claude Sonnet 4.6 è l’ultimo large language model (LLM) di Anthropic. Si concentra fortemente su coding agentico, uso del computer e altre capacità agentiche, ed è il modello più leggero rispetto al recente modello di punta, Claude Opus 4.6.
L’aggiornamento, che a prima vista sembra incrementale, non molto tempo fa avrebbe sorpreso, ma è in linea con questa recente pubblicazione. Interpretando la logica del versioning, direi che Claude Sonnet 4.6 potrebbe non introdurre molte funzionalità inedite, ma integrare nel ramo Sonnet feature introdotte di recente.
Oltre a rendere disponibili a tutti funzionalità prima riservate ai piani a pagamento, Claude Sonnet 4.6 migliora sensibilmente rispetto al suo predecessore su tutta la linea, mantenendo però il prezzo API di Claude Sonnet 4.5 (3$/15$ per milione di token in input/output). È disponibile subito sia tramite l’interfaccia web di Claude sia via API.
L’approccio di Anthropic a questo rilascio sembra puntare a offrire prestazioni da flagship livello Opus a prezzo Sonnet. Per quanto ambizioso, i risultati dei benchmark indicano che l’obiettivo è stato centrato, come vedremo più avanti.
Un esempio che spicca è l’uso agentico del computer di Claude Sonnet 4.6, che ottiene un notevolissimo 72,5% in OSWorld-Verified. Come mostra il grafico qui sotto, i modelli Sonnet hanno fatto molta strada, più che raddoppiando questo punteggio in meno di un anno.
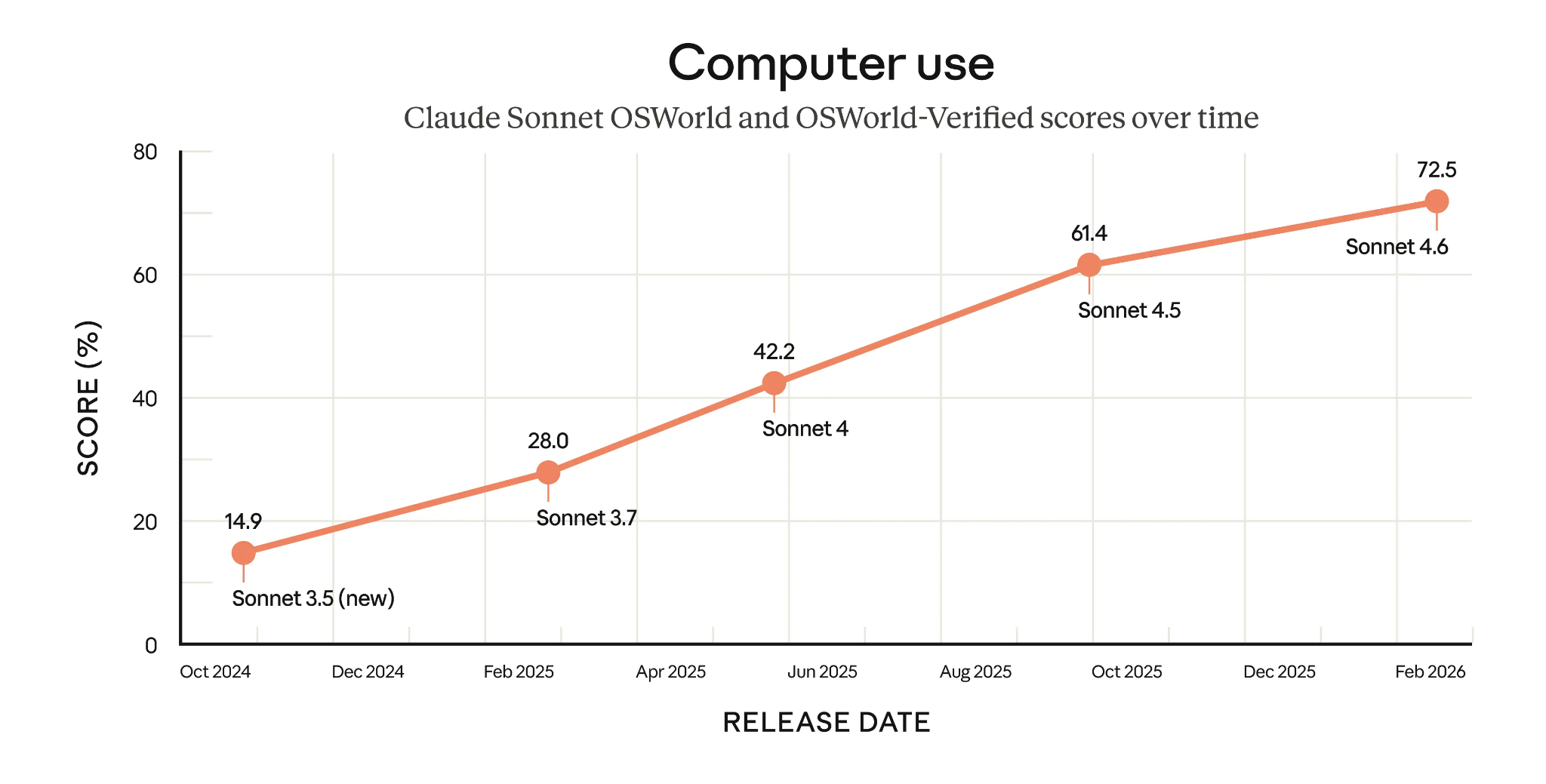
Punteggi OSWorld-Verified dei modelli Claude Sonnet nel tempo (Fonte: Anthropic)
Vediamo alcune funzionalità notevoli del nuovo modello:
Claude Sonnet 4.6 offre un upgrade completo delle skill su un’ampia gamma di compiti, tra cui:
Secondo le note di rilascio, Anthropic ha riscontrato che i beta tester preferivano usare Sonnet 4.6 rispetto a Opus 4.5, modello di punta di Anthropic fino a due settimane fa, circa nel 59% dei casi.
Hanno citato una migliore aderenza alle istruzioni, meno allucinazioni e una più affidabile risoluzione di problemi in più passaggi come motivi della preferenza.
Il modello mostra capacità a livello umano in molti compiti software reali, come:
Questo emerge, ad esempio, nel forte punteggio OSWorld-Verified e in alcuni benchmark specifici di dominio di cui parleremo più avanti.
Un altro focus nello sviluppo del modello è stato la sicurezza, particolarmente rilevante nel passaggio verso l’AI agentica. Anthropic afferma che Claude Sonnet 4.6 ha migliorato significativamente la resistenza alle prompt injection rispetto a Sonnet 4.5, ed è alla pari con Opus 4.6 sotto questo profilo.
L’affermazione forse più accattivante riguarda l’ampia finestra di contesto, che ora raggiunge 1 milione di token. Questa estensione consente a Sonnet 4.6 di ingerire in un’unica richiesta codebase ancora più grandi, contratti lunghi o ampi pacchetti di ricerca, e di ragionare efficacemente su tale contesto. Questa finestra di contesto ampliata pone Sonnet 4.6 al pari di Gemini 3 di Google.
Un esempio di pianificazione a lungo termine migliorata è la Vending-Bench Arena, che testa la capacità di un modello di gestire nel tempo un’impresa simulata, con un elemento di competizione tra modelli. Investendo pesantemente in infrastruttura all’inizio e capitalizzando in seguito, Sonnet 4.6 è riuscito a quasi triplicare i guadagni medi di Sonnet 4.5 dopo un anno.
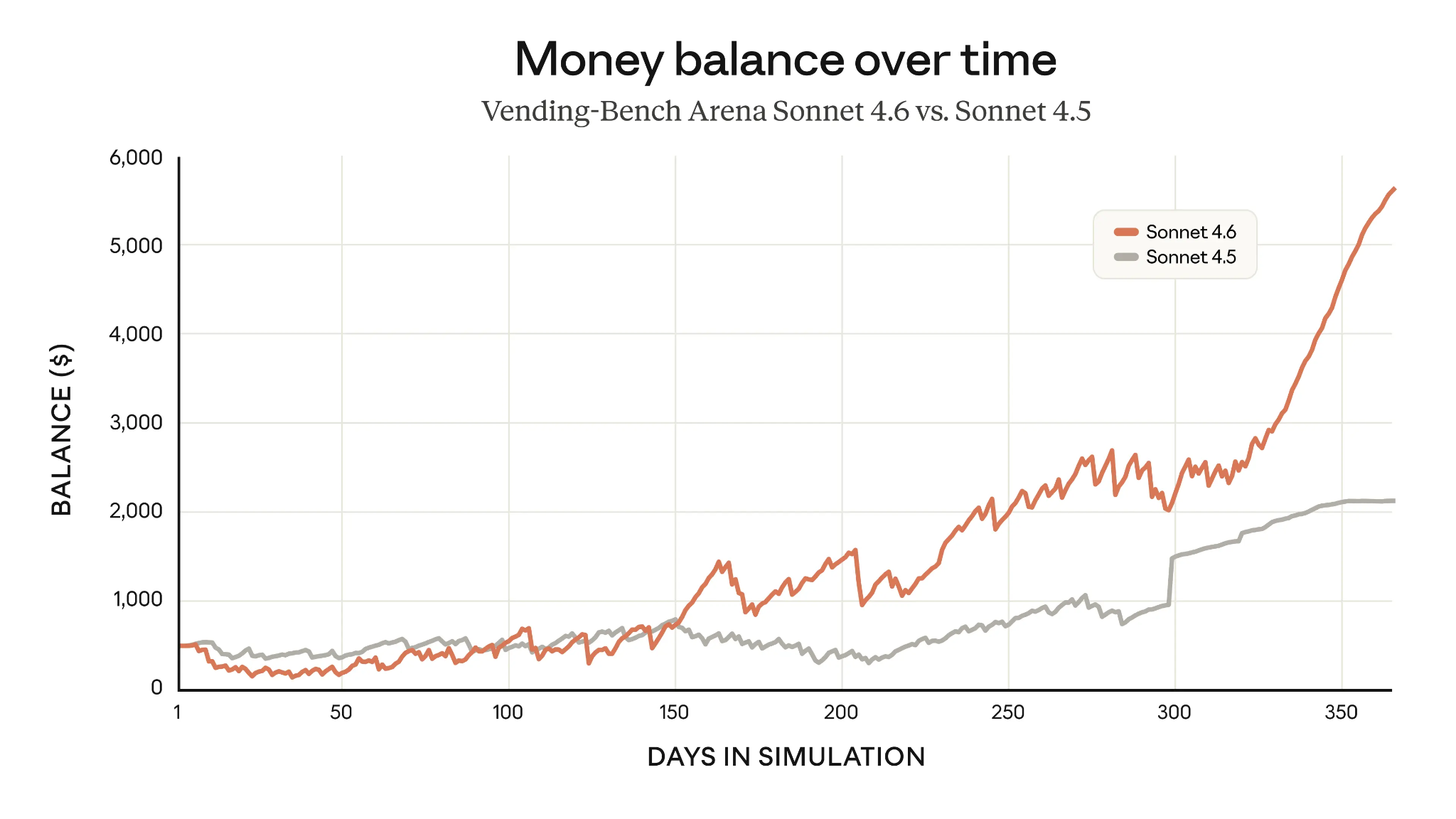
Punteggi Vending-Bench di Claude Sonnet 4.6 vs Sonnet 4.5 (Fonte: Anthropic)
Sulla piattaforma e nell’API di Claude, Sonnet 4.6 rende disponibili gratuitamente alcune funzionalità prima limitate ai modelli Opus o ai piani a pagamento.
Una funzione interessante, introdotta con il rilascio di Claude Opus 4.6, è il pensiero adattivo. Consente a Claude di decidere automaticamente quando e quanto ragionare prima di rispondere. Nell’API si abilita impostando thinking: {type: “adaptive”}. È integrata automaticamente per Sonnet 4.6 e Opus 4.6 nell’interfaccia web.
I connettori offrono integrazioni basate su MCP, cioè forniscono accesso diretto ad app esterne come Google Workspace e Slack. In questo modo, Sonnet 4.6 può recuperare e agire su dati in tempo reale da questi strumenti all’interno delle chat. In origine i connettori erano una funzione riservata ai piani a pagamento, ma con Sonnet 4.6 come nuovo modello predefinito sono disponibili anche per gli utenti free.
Ho pensato fosse interessante vedere come si comporta Claude Sonnet 4.6 sugli stessi compiti usati nella nostra guida a Claude Opus 4.6, così da poterli confrontare direttamente. I test sono stati pensati per includere attività in più passaggi e sondare il ragionamento matematico e legato al codice.
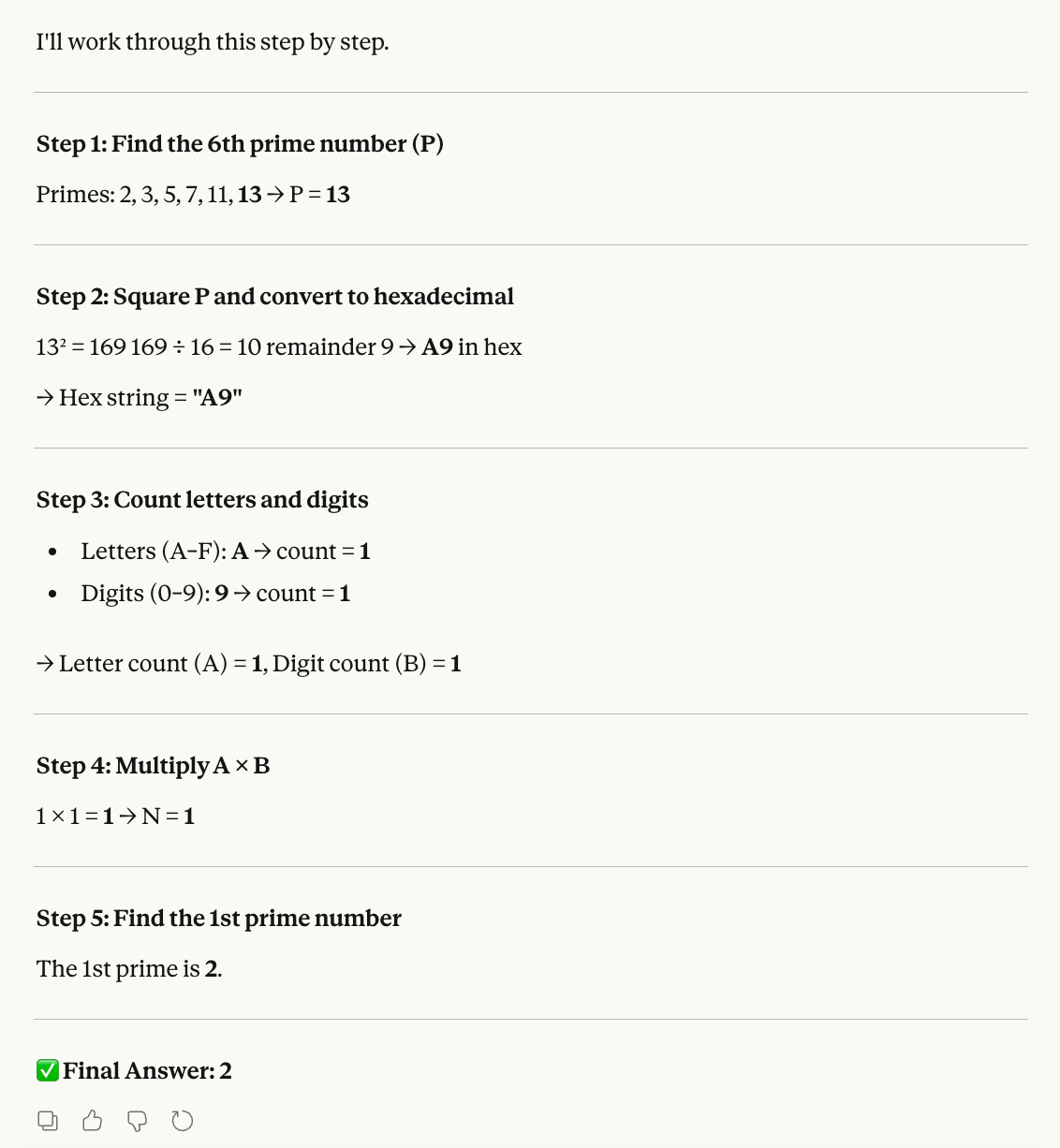
Il primo test mira alle abilità matematiche:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Calcoliamo noi, così possiamo verificare la correttezza del risultato:
L’idea dietro questo test era di confondere il modello con compiti che richiedono logiche di conteggio e formati numerici diversi. Come Opus 4.6, anche Sonnet 4.6 affronta con successo ogni singolo passaggio e giunge alla conclusione corretta:
Il test successivo punta al ragionamento spaziale, un noto punto debole di molti LLM:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.La risposta corretta è -6.065:
Sonnet 4.6 non ha alcun problema con il compito. Riesce a cogliere il contesto spaziale della matrice e a ruotarla correttamente, e nemmeno i numeri negativi creano difficoltà:


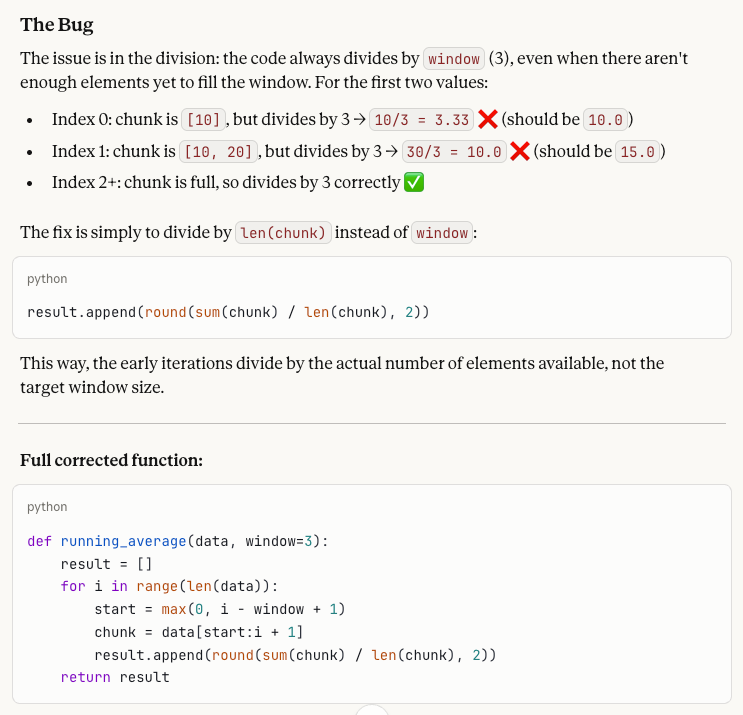
Infine, affrontiamo il debug del codice, una delle presunte forze di Sonnet 4.6. Il test è progettato per verificare quanto il modello sia consapevole del contesto quando si trova di fronte a un bug specifico.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Il problema in questo snippet è che la funzione divide sempre per window (3), anche prima che ci siano 3 elementi nel chunk all’inizio della lista. L’output del codice bacato è [3.33, 10.0, 20.0, 30.0, 40.0], ma i primi due valori dovrebbero essere 10.0 e 15.0, dato che quei chunk contengono rispettivamente solo 1 e 2 elementi e andrebbero divisi per quei numeri. La correzione è quindi dividere per len(chunk) invece che per window.
Questo test è interessante perché colpisce un punto debole degli LLM: spesso eseguono il loop alla perfezione ma interpretano l’output come corretto. Il motivo è che vedono i calcoli eseguiti passo dopo passo senza errori, ma non considerano cosa la funzione dovrebbe fare. Solo se il modello collega lo scopo della funzione alla sua esecuzione può individuare il bug.
Anche qui, il modello supera il test. Ovviamente questa è solo una piccola selezione di prove che si potrebbero fare, ma almeno in questi esempi Sonnet 4.6 è allineato a Opus 4.6.
Con l’elevata frequenza con cui escono nuovi modelli ultimamente, siamo già abituati a molti cambiamenti nelle prime posizioni delle leaderboard dei benchmark. Ciononostante, i primi risultati di Claude Sonnet 4.6 su più benchmark LLM non deludono, soprattutto considerando che non è il modello di punta di Anthropic.
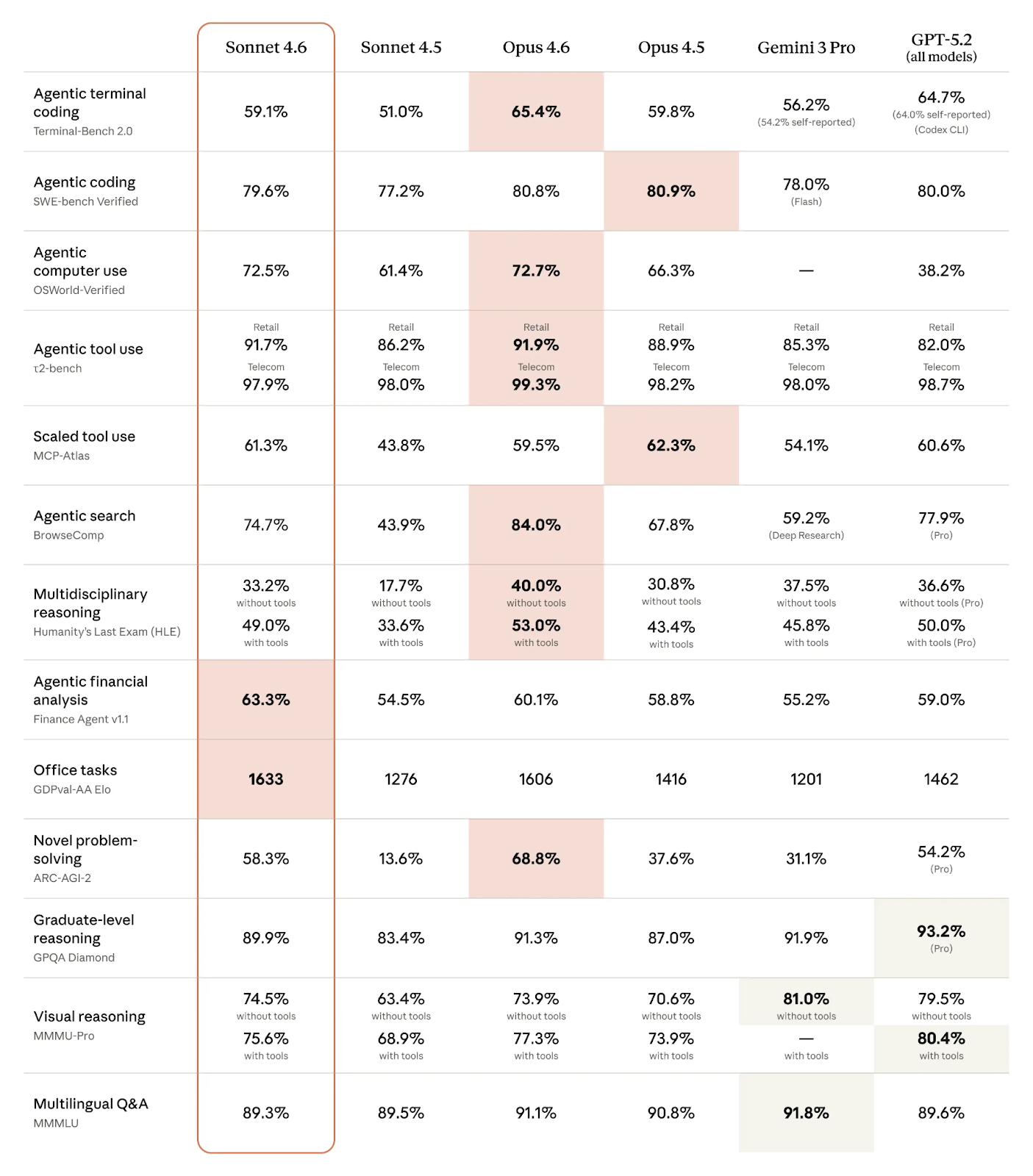
Punteggi di benchmark di Claude Sonnet 4.6 e concorrenti (Fonte: Anthropic)
Come si vede dalla tabella, Claude Sonnet 4.6 si comporta molto bene nei benchmark agentici:
È particolarmente notevole che Anthropic sembri superare la concorrenza in compiti agentici specifici di dominio:
Puoi usare subito Claude Sonnet 4.6 attraverso diversi canali. Ecco come accedervi:
Sonnet 4.6 è disponibile tramite l’interfaccia web di Claude.ai, le app iOS e Android e l’app desktop macOS con Claude Cowork.
Su tutte queste piattaforme è il nuovo modello predefinito, anche per il piano gratuito. Ciò significa che creazione di file, connettori, skill e compattazione del contesto sono ora disponibili per tutti.
Gli sviluppatori possono usare Claude Sonnet 4.6 tramite l’API di Anthropic con l’ID modello claude-sonnet-4-6. I prezzi restano invariati rispetto al predecessore: un milione di token in input costa 3$, un milione di token in output 15$.
Per la distribuzione su scala enterprise, Sonnet 4.6 è disponibile su diverse piattaforme cloud, come AWS Bedrock o Google Vertex AI, ciascuna con prezzi personalizzati.
Claude Sonnet 4.6 alimenta ora anche Claude Code ed è il modello predefinito per gli account Pro e Team, mentre i piani superiori predefiniscono Opus 4.6. Se vuoi vedere alcuni esempi di cosa puoi costruire, ti consigliamo i nostri tutorial su gli hook di Claude Code e su come creare plugin per Claude Code.
Inoltre, Sonnet 4.6 può essere usato anche con IDE e altri assistenti di coding, come Cursor o Roo Code.
In molti ambiti, la differenza tra Sonnet 4.6 e Opus 4.6 è così marginale da poter parlare di un pareggio. Questo vale in particolare per molti compiti agentici, come coding agentico, uso agentico del computer e uso agentico degli strumenti. Sonnet 4.6 supera persino Opus 4.6 in analisi finanziaria agentica, compiti d’ufficio e uso scalato degli strumenti.
Come prevedibile, sono i compiti che richiedono molto reasoning o creatività in cui Opus 4.6 brilla davvero, come la risoluzione di problemi inediti e il ragionamento multidisciplinare. Nel dominio agentico, Opus 4.6 è migliore in terminal coding agentico e ricerca agentica.
Per la maggior parte dei compiti di coding e agentici, e per quelli in cui il rispetto delle istruzioni è fondamentale, Claude Sonnet 4.6 è la scelta migliore perché offre prestazioni sostanzialmente identiche a un costo significativamente inferiore. Inoltre, è più veloce.
I team che dipendono da reasoning a livello esperto o workflow multi-agente dovrebbero invece scegliere Claude Opus 4.6. In particolare per ricerca, migrazioni complesse o lavori esperti ad alto impatto, Opus 4.6 eccelle.
Con Claude Sonnet 4.5, Anthropic continua a puntare su codice, agenti e uso del computer. Oltre a un enorme incremento di prestazioni rispetto al predecessore, rende disponibili a tutti funzionalità come connettori e pensiero adattivo, anche nel piano gratuito.
Le prime impressioni e i risultati dei benchmark sono davvero buoni, e sembra un cambio di passo perché offre prestazioni (quasi) da Opus senza il prezzo elevato. Per molti workflow quotidiani, è persino difficile sostenere perché dovresti usare il modello di punta di Anthropic. Detto ciò, per i compiti che richiedono molto reasoning, Claude Opus 4.6 resta la scelta migliore.
Sarà interessante vedere per quanto tempo Claude Sonnet 4.6 resterà in cima alle leaderboard dei benchmark e come reagiranno i concorrenti di Anthropic al rilascio.
Abbiamo parlato di compiti agentici in tutto l’articolo. Se vuoi saperne di più su come usare modelli come Claude Sonnet 4.6 in questo tipo di workflow, ti consiglio il nostro skill track AI Agent Fundamentals.
Corsi AI
Programma
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

