
Lernpfad
KI-Agent-Grundlagen
6 Std.
Claude Sonnet 4.6 ist Anthropics neuestes Large Language Model (LLM). Es legt den Schwerpunkt stark auf agentisches Coding, Computer-Nutzung und weitere agentische Fähigkeiten und ist das leichtere Modell im Vergleich zum kürzlich veröffentlichten Flaggschiff Claude Opus 4.6.
Das inkrementell klingende Update mag früher überrascht haben, fügt sich aber in die jüngsten Releases ein. Aus der Versionierung lässt sich lesen: Claude Sonnet 4.6 bringt zwar nicht massenhaft vollkommen neue Einzelfeatures, integriert aber die zuletzt eingeführten Funktionen in die Sonnet-Familie.
Zusätzlich macht Sonnet 4.6 vormals kostenpflichtige Funktionen für alle zugänglich und liefert gegenüber dem Vorgänger durchgängig deutlich bessere Ergebnisse – bei unverändertem API-Preis von Claude Sonnet 4.5 (3$/15$ pro Million Input-/Output-Tokens). Es ist sofort über die Claude-Weboberfläche und die API verfügbar.
Anthropic verfolgt offenbar das Ziel, Opus-Niveau bei der Performance zum Sonnet-Preis zu bieten. Das klingt ambitioniert, doch die Benchmarks deuten an, dass das gelungen ist – mehr dazu gleich.
Auffällig sind vor allem die agentischen Computerfähigkeiten von Claude Sonnet 4.6 mit einem sehr starken 72,5%-Score in OSWorld-Verified. Wie die Grafik unten zeigt, haben die Sonnet-Modelle in weniger als einem Jahr ihren Wert mehr als verdoppelt.
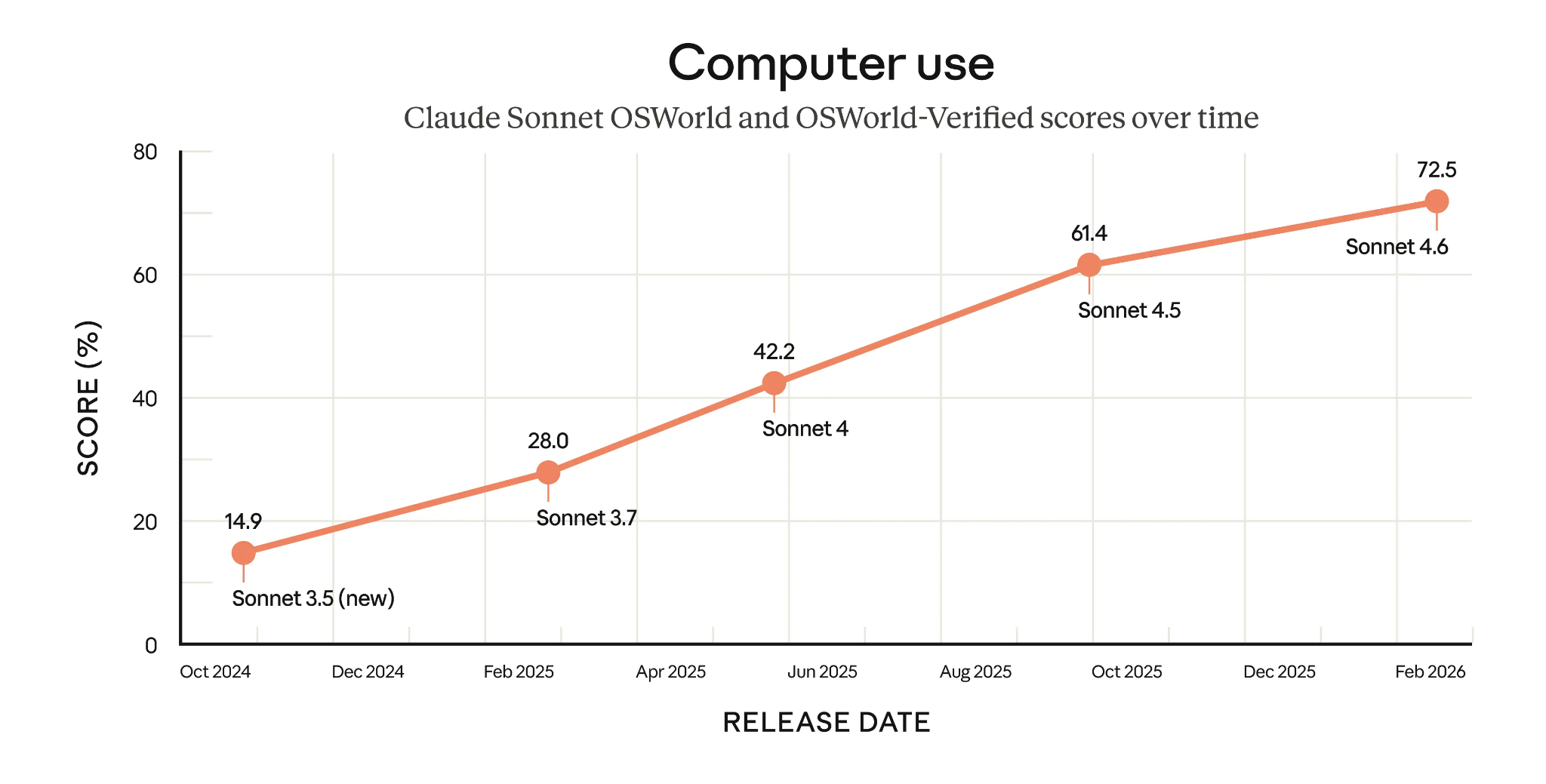
OSWorld-Verified-Scores der Claude-Sonnet-Modelle im Zeitverlauf (Quelle: Anthropic)
Werfen wir einen Blick auf einige Highlights des neuen Modells:
Claude Sonnet 4.6 liefert ein umfassendes Kompetenz-Upgrade über viele Aufgaben hinweg, darunter:
Laut Release Notes bevorzugten Beta-Tester Sonnet 4.6 gegenüber Opus 4.5 – bis vor zwei Wochen Anthropics Flaggschiff – in etwa 59% der Fälle.
Genannt wurden bessere Befolgung von Anweisungen, weniger Halluzinationen und verlässlicheres mehrstufiges Problemlösen als Gründe für die Präferenz.
Das Modell zeigt Fähigkeiten auf menschlichem Niveau bei vielen realen Softwareaufgaben, etwa:
Das spiegelt sich z. B. im starken OSWorld-Verified-Score und in einigen domänenspezifischen Benchmarks, auf die wir gleich eingehen.
Ein weiterer Schwerpunkt lag auf Sicherheit – besonders wichtig im Übergang zu agentischer KI. Anthropic gibt an, dass Claude Sonnet 4.6 deutlich widerstandsfähiger gegen Prompt-Injections ist als Sonnet 4.5 und in dieser Hinsicht auf Augenhöhe mit Opus 4.6.
Der wohl prägnanteste Claim betrifft das erweiterte Kontextfenster von jetzt 1 Million Tokens. Dadurch kann Sonnet 4.6 noch größere Codebasen, umfangreiche Verträge oder große Research-Pakete in einer Anfrage verarbeiten und über den gesamten Kontext schlüssig schlussfolgern. Damit liegt Sonnet 4.6 auf Augenhöhe mit Googles Gemini 3.
Ein Beispiel für besseres Langfristdenken ist die Vending-Bench Arena, die testet, wie gut ein Modell über die Zeit ein simuliertes Unternehmen führt – inklusive Wettbewerb zwischen Modellen. Durch hohe Anfangsinvestitionen in Infrastruktur und späteres Ausnutzen dieser Basis konnte Sonnet 4.6 die durchschnittlichen Gewinne von Sonnet 4.5 nach einem Jahr fast verdreifachen.
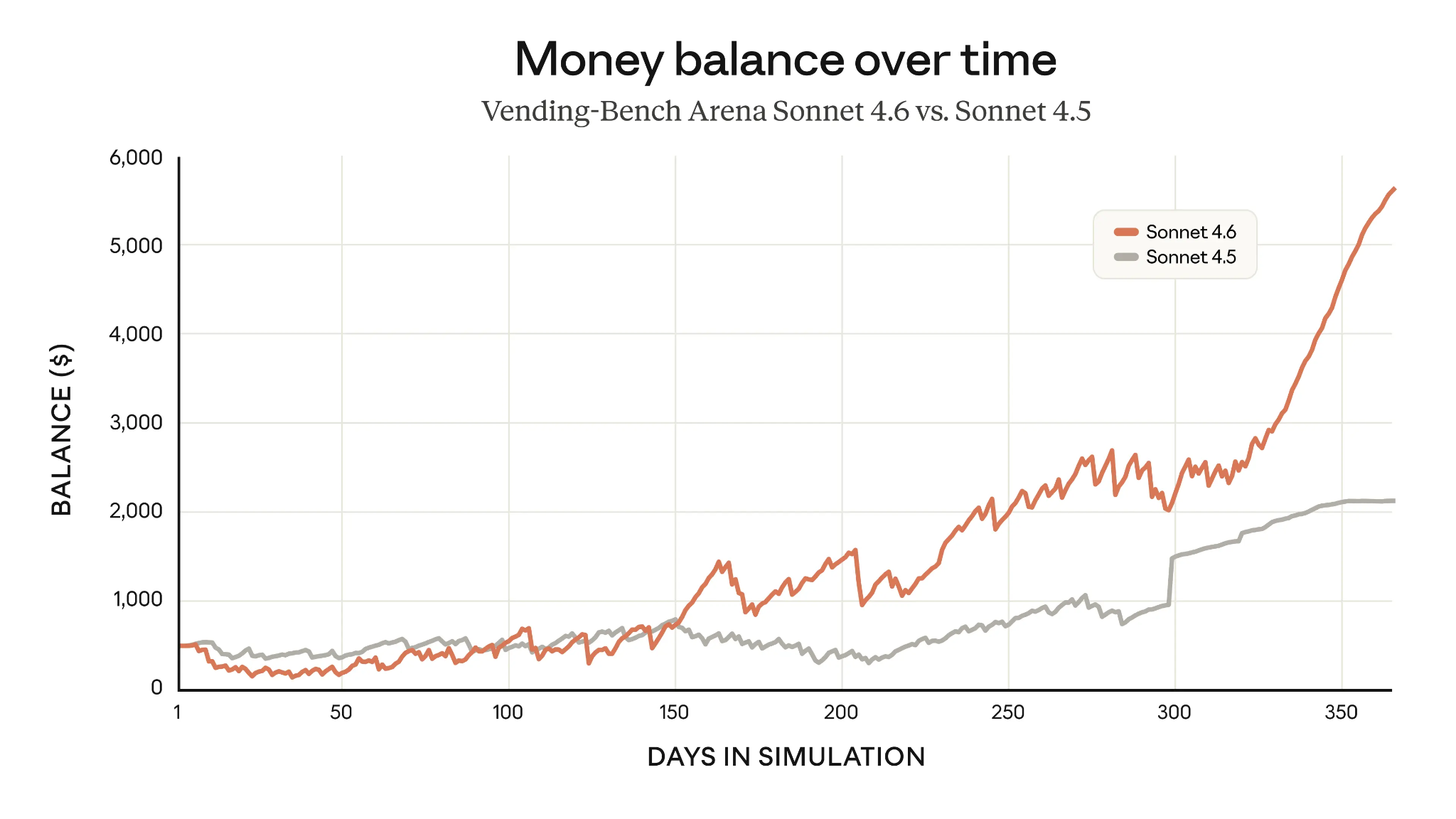
Vending-Bench-Scores von Claude Sonnet 4.6 vs. Sonnet 4.5 (Quelle: Anthropic)
Auf der Claude-Plattform und in der API macht Sonnet 4.6 einige bisher Opus- oder Bezahl-Tiers vorbehaltene Funktionen frei verfügbar.
Ein mit Claude Opus 4.6 eingeführtes Feature ist Adaptive Thinking. Es lässt Claude automatisch entscheiden, wann und wie viel es vor der Antwort „nachdenkt“. In der API aktivierst du es mit thinking: {type: “adaptive”}. In der Weboberfläche ist es bei Sonnet 4.6 und Opus 4.6 standardmäßig integriert.
Connectors bieten Integrationen auf Basis des MCP und damit direkten Zugriff auf externe Apps wie Google Workspace und Slack. So kann Sonnet 4.6 in Chats Echtzeitdaten aus diesen Tools abrufen und darauf reagieren. Ursprünglich nur für Bezahl-Tiers verfügbar, stehen Connectors mit Sonnet 4.6 als neuem Standardmodell nun auch kostenlosen Nutzern zur Verfügung.
Ich wollte sehen, wie sich Claude Sonnet 4.6 bei denselben Aufgaben schlägt wie in unserem Guide zu Claude Opus 4.6, um direkt vergleichen zu können. Die Tests erfordern mehrere Schritte und prüfen mathematisches sowie coderelatiertes Reasoning.
Der erste Test zielt auf mathematische Fähigkeiten:
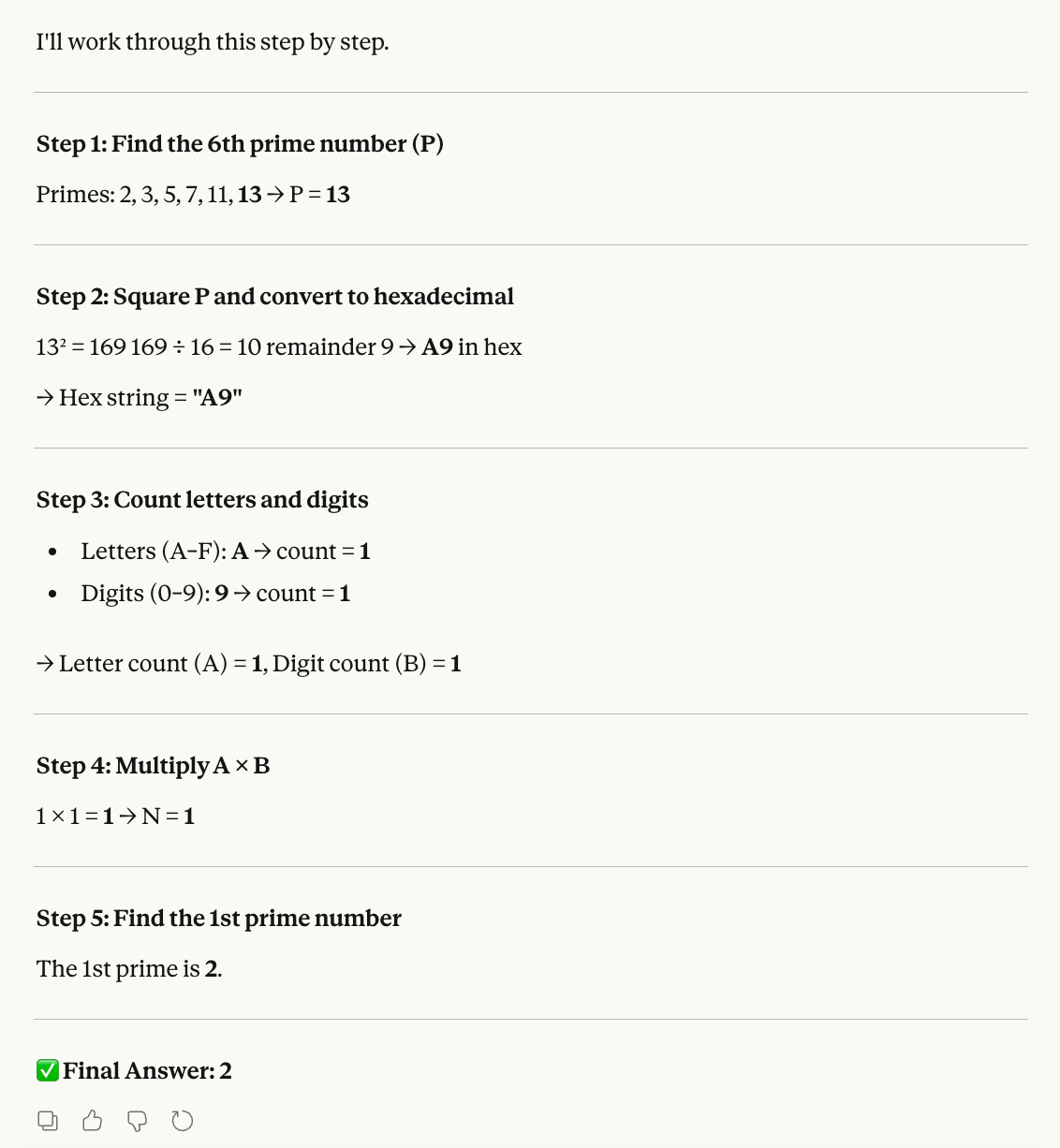
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Rechnen wir es selbst nach, um das Ergebnis zu prüfen:
Die Idee hinter diesem Test: Das Modell mit unterschiedlichen Zähllogiken und Zahlenformaten verwirren. Wie Opus 4.6 meistert Sonnet 4.6 alle Teilschritte und kommt zum richtigen Schluss:
Der nächste Test zielt auf räumliches Denken – ein notorischer Schwachpunkt vieler LLMs:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Die richtige Antwort ist -6.065:
Sonnet 4.6 hat mit der Aufgabe keine Probleme. Das Modell erfasst den räumlichen Kontext der Matrix, dreht sie korrekt, und auch negative Zahlen sind kein Stolperstein:


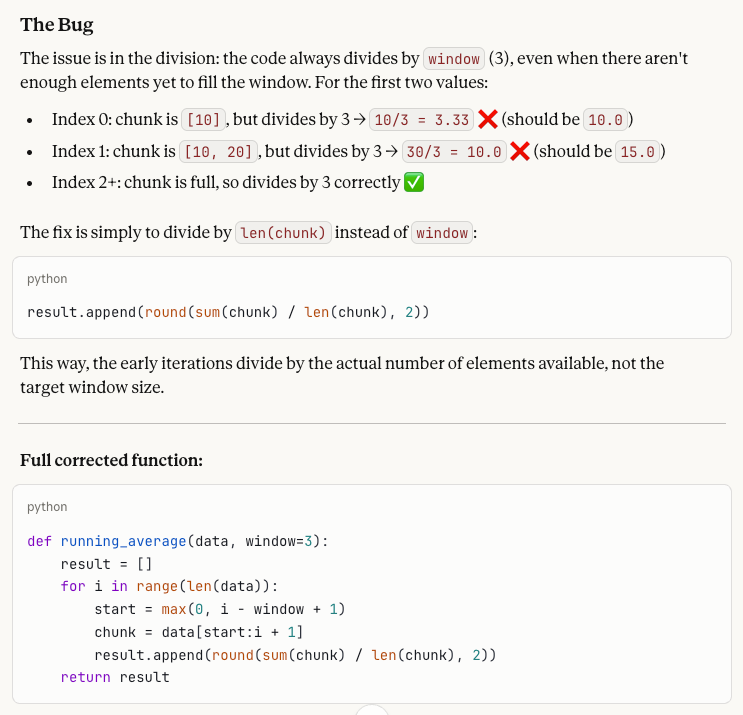
Zum Schluss geht es um Code-Debugging – eine der ausgewiesenen Stärken von Sonnet 4.6. Der Test prüft, wie kontextbewusst das Modell auf einen konkreten Bug reagiert.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Das Problem: Die Funktion teilt immer durch window (3), auch wenn am Anfang der Liste noch keine 3 Elemente im Chunk sind. Die fehlerhafte Ausgabe ist [3.33, 10.0, 20.0, 30.0, 40.0], korrekt wären die ersten beiden Werte 10,0 und 15,0, da diese Chunks nur 1 bzw. 2 Elemente enthalten und entsprechend durch diese Größen geteilt werden müssten. Die Lösung ist daher, durch len(chunk) statt durch window zu teilen.
Dieser Test adressiert eine typische LLM-Schwäche: Oft wird die Schleife korrekt ausgeführt, aber das Ergebnis unkritisch akzeptiert. Der Grund: Die Berechnungen laufen fehlerfrei, ohne zu prüfen, was die Funktion eigentlich leisten soll. Erst wenn das Modell Zweck und Umsetzung verknüpft, findet es den Bug.
Auch hier besteht das Modell. Natürlich ist das nur eine kleine Auswahl möglicher Tests, aber in diesen Beispielen liegt Sonnet 4.6 auf Augenhöhe mit Opus 4.6.
Bei der aktuellen Veröffentlichungsfrequenz sind wir schon an viel Bewegung an den Benchmark-Spitzen gewöhnt. Trotzdem beeindrucken die ersten Resultate von Claude Sonnet 4.6 über mehrere LLM-Benchmarks – zumal es nicht das Flaggschiff ist.
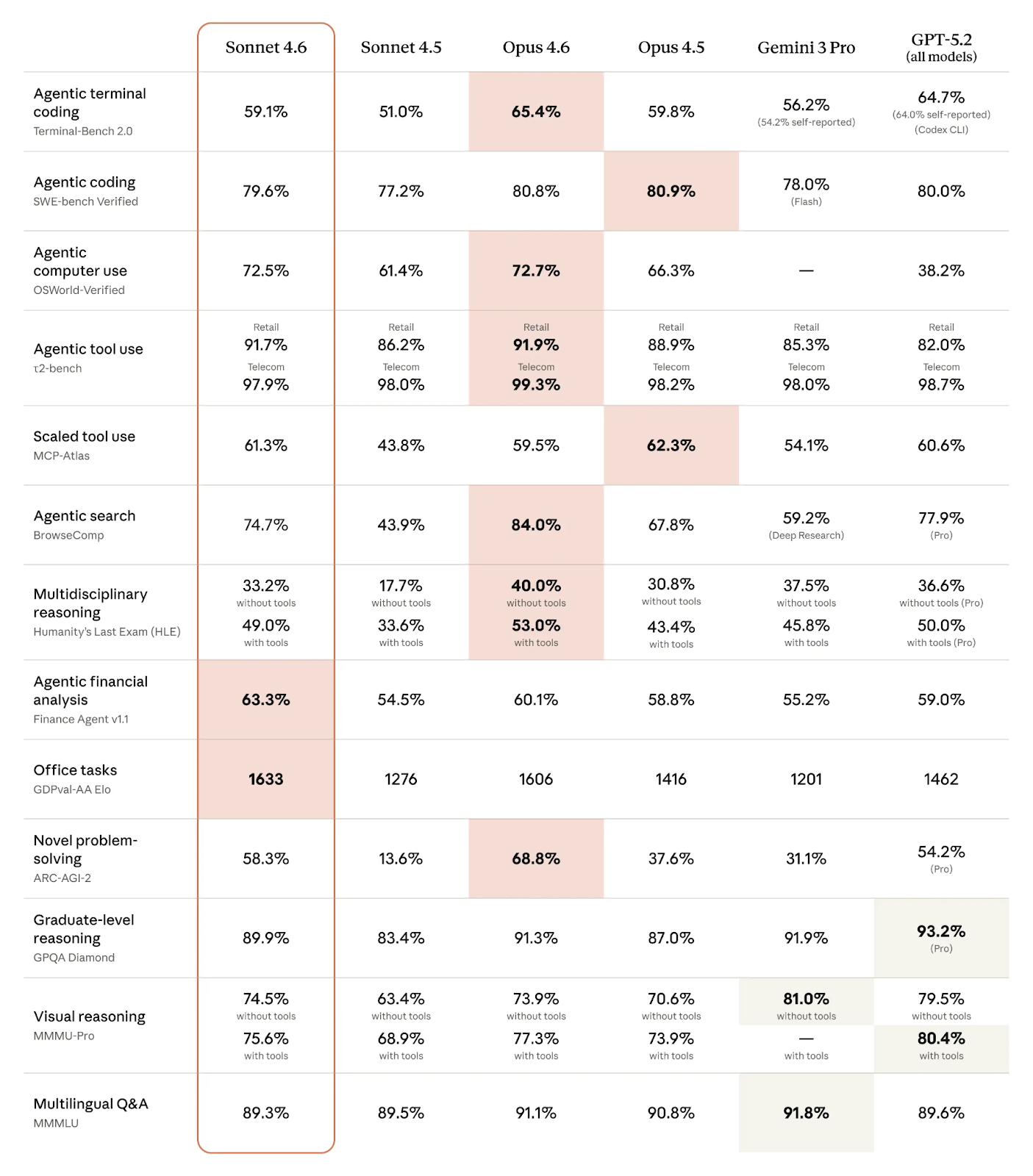
Benchmark-Scores von Claude Sonnet 4.6 und Wettbewerbern (Quelle: Anthropic)
Wie die Tabelle zeigt, schneidet Claude Sonnet 4.6 in agentischen Benchmarks sehr stark ab:
Auffällig ist, dass Anthropic bei domänenspezifischen agentischen Aufgaben besonders stark wirkt:
Du kannst Claude Sonnet 4.6 jetzt über mehrere Kanäle nutzen. So kommst du dran:
Sonnet 4.6 ist über die Claude.ai Weboberfläche, die iOS- und Android-Apps sowie die macOS-Desktop-App mit Claude Cowork verfügbar.
Überall ist es das neue Standardmodell – auch im Free-Tier. Das heißt: Dateierstellung, Connectors, Skills und Kontextkomprimierung stehen jetzt allen Nutzenden zur Verfügung.
Entwicklerinnen und Entwickler nutzen Claude Sonnet 4.6 über die Anthropic API mit der Model-ID claude-sonnet-4-6. Die Preise bleiben wie beim Vorgänger: Eine Million Input-Tokens kosten 3$, eine Million Output-Tokens 15$.
Für den Unternehmenseinsatz ist Sonnet 4.6 auf diversen Cloud-Plattformen wie AWS Bedrock oder Google Vertex AI verfügbar – jeweils mit individuellen Preisen.
Claude Sonnet 4.6 treibt jetzt auch Claude Code an und ist das Standardmodell für Pro- und Team-Tiers, während höhere Tiers standardmäßig Opus 4.6 nutzen. Beispiele, was du damit bauen kannst, findest du in unseren Tutorials zu Claude Code Hooks und zum Bau von Plugins für Claude Code.
Zusätzlich lässt sich Sonnet 4.6 mit IDEs und anderen Coding-Assistenten wie Cursor oder Roo Code nutzen.
In vielen Bereichen sind die Unterschiede so gering, dass man fast von einem Unentschieden sprechen kann. Das gilt besonders für agentische Aufgaben wie agentisches Coding, Computernutzung und Tool-Einsatz. Sonnet 4.6 übertrifft Opus 4.6 sogar bei agentischer Finanzanalyse, Office-Aufgaben und skaliertem Tool-Einsatz.
Wie erwartet glänzt Opus 4.6 dort, wo intensives Reasoning oder Kreativität gefragt sind – etwa bei neuartigen Problemlösungen und interdisziplinärem Denken. Im agentischen Bereich ist Opus 4.6 besser beim Terminal-Coding und der agentischen Suche.
Für die meisten Coding- und agentischen Aufgaben sowie für Use Cases, in denen es auf präzise Anweisungsbefolgung ankommt, ist Claude Sonnet 4.6 die bessere Wahl: praktisch gleiche Performance zu deutlich geringeren Kosten und mit Geschwindigkeitsvorteil.
Teams, die auf Expert-Reasoning oder Multi-Agent-Workflows angewiesen sind, sollten zu Claude Opus 4.6 greifen. Besonders für Research, komplexe Migrationen oder sensible Expertenarbeit spielt Opus 4.6 seine Stärken aus.
Mit Claude Sonnet 4.6 setzt Anthropic weiter auf Code, Agenten und Computernutzung. Neben dem großen Performance-Sprung gegenüber dem Vorgänger werden Funktionen wie Connectors und Adaptive Thinking allen zugänglich – sogar im Free-Tier.
Die ersten Eindrücke und Benchmarks sind sehr stark und es fühlt sich wie ein Gamechanger an, weil (nahezu) Opus-Niveau ohne hohen Preisschild geboten wird. Für viele Alltagsworkflows ist es schwer zu begründen, warum man stattdessen das Flaggschiff nutzen sollte. Für Aufgaben mit intensivem Reasoning bleibt Claude Opus 4.6 jedoch die bessere Wahl.
Spannend wird sein, wie lange Claude Sonnet 4.6 die Benchmark-Tabellen anführt und wie die Konkurrenz reagiert.
In diesem Artikel ging es immer wieder um agentische Workflows. Wenn du mehr darüber lernen willst, wie du Modelle wie Claude Sonnet 4.6 darin einsetzt, empfehle ich dir unseren Skill Track AI Agent Fundamentals.
KI-Kurse
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Tutorial
Laiba Siddiqui
Tutorial
Matt Crabtree
