
Programa
Fundamentos de agentes de IA
6 h
Claude Sonnet 4.6 é o mais recente LLM (modelo de linguagem) da Anthropic. Ele foca fortemente em programação agentic, uso de computador e outras capacidades agentic, e é o modelo mais leve em comparação ao modelo flagship lançado recentemente, o Claude Opus 4.6.
A atualização incremental pode ter surpreendido até pouco tempo atrás, mas está alinhada com este lançamento. Minha leitura sobre a versão é que o Claude Sonnet 4.6 pode não introduzir muitos recursos inéditos isolados, e sim integrar recursos lançados recentemente à família de modelos Sonnet.
Além de disponibilizar para todos recursos que antes eram pagos, o Claude Sonnet 4.6 tem desempenho significativamente melhor que seu antecessor em praticamente tudo, mantendo a mesma tarifa da API do Claude Sonnet 4.5 (US$ 3/US$ 15 por milhão de tokens de entrada/saída). Ele já está disponível tanto na interface web do Claude quanto na API.
A estratégia da Anthropic neste lançamento parece ser oferecer desempenho de nível Opus por um preço de Sonnet. Embora ambicioso, os resultados de benchmark indicam que a meta foi alcançada, como veremos adiante.
Um destaque é o uso agentic de computador do Claude Sonnet 4.6, que alcança 72,5% no OSWorld-Verified. Como dá para ver no gráfico abaixo, os modelos Sonnet evoluíram bastante e mais que dobraram essa pontuação em menos de um ano.
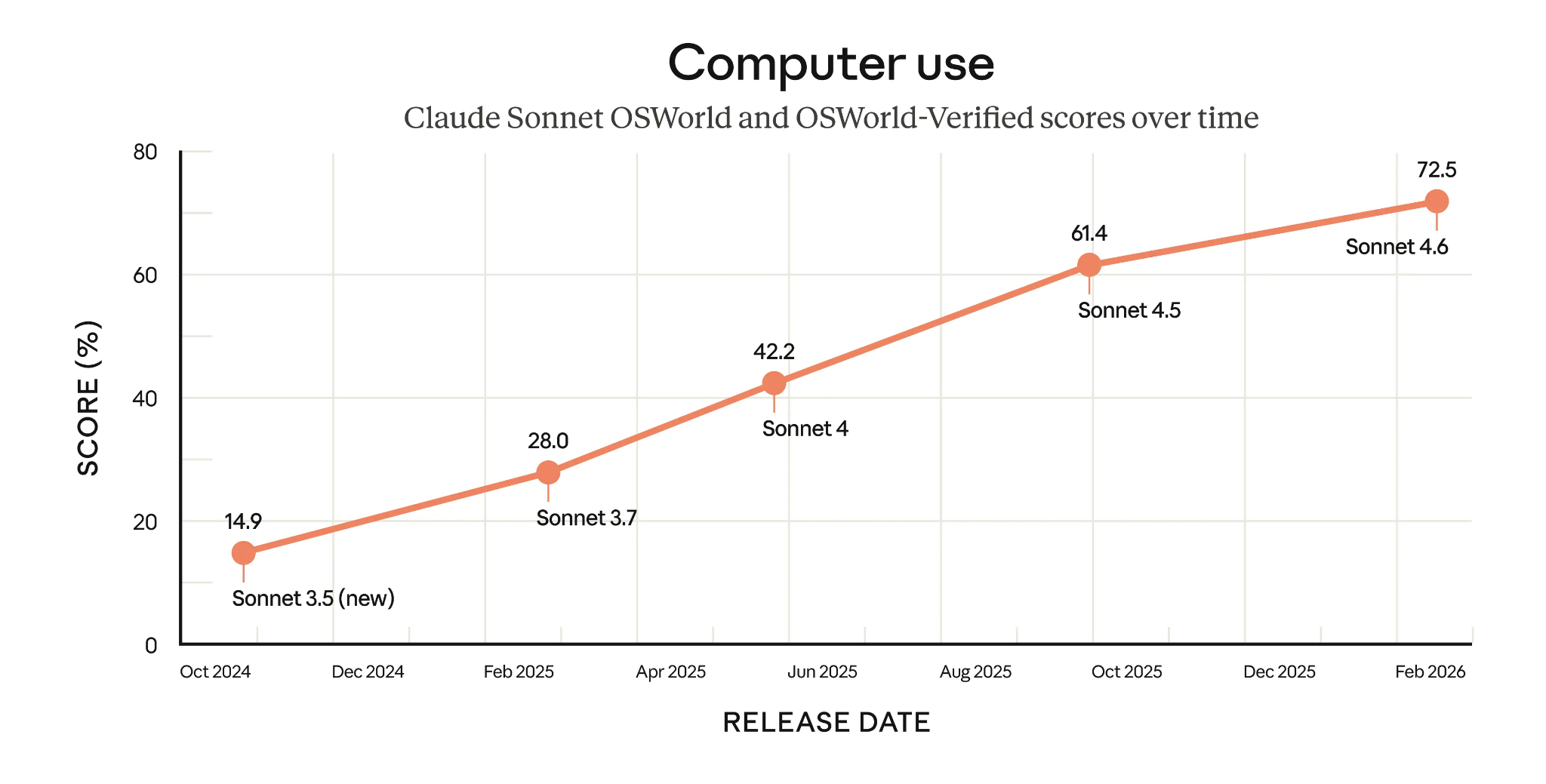
Pontuações OSWorld-Verified dos modelos Claude Sonnet ao longo do tempo (Fonte: Anthropic)
Vamos ver alguns recursos de destaque do novo modelo:
O Claude Sonnet 4.6 traz uma atualização completa de habilidades em uma ampla gama de tarefas, incluindo:
Segundo a nota de lançamento, a Anthropic observou que beta testers preferiram o uso do Sonnet 4.6 ao Opus 4.5, que era o modelo flagship da Anthropic até duas semanas atrás, em cerca de 59% dos casos.
Eles citaram melhor seguimento de instruções, menos alucinações e solução de problemas em múltiplas etapas mais confiável como motivos da preferência.
O modelo demonstra capacidade em nível humano em muitas tarefas reais de software, como:
Isso fica evidente, por exemplo, na forte pontuação do OSWorld-Verified e em alguns benchmarks específicos de domínio que veremos mais adiante.
Outro foco no desenvolvimento do modelo foi a segurança, especialmente relevante nessa transição para IA agentic. A Anthropic afirma que o Claude Sonnet 4.6 melhorou significativamente a resistência a prompt injections em comparação ao Sonnet 4.5, ficando no mesmo nível do Opus 4.6 nesse quesito.
Talvez a afirmação mais chamativa esteja na janela de contexto expandida, que agora chega a 1 milhão de tokens. Essa extensão permite ao Sonnet 4.6 ingerir bases de código maiores, contratos extensos ou grandes pacotes de pesquisa em uma única solicitação e raciocinar de forma eficaz sobre todo esse contexto. Essa janela ampliada coloca o Sonnet 4.6 no mesmo patamar do Gemini 3 do Google.
Um exemplo de planejamento de longo prazo aprimorado é o Vending-Bench Arena, que testa a capacidade de um modelo de administrar um negócio simulado ao longo do tempo, com um elemento de competição entre modelos. Ao investir pesado em infraestrutura no início e capitalizar sobre isso depois, o Sonnet 4.6 quase triplicou os ganhos médios do Sonnet 4.5 após um ano.
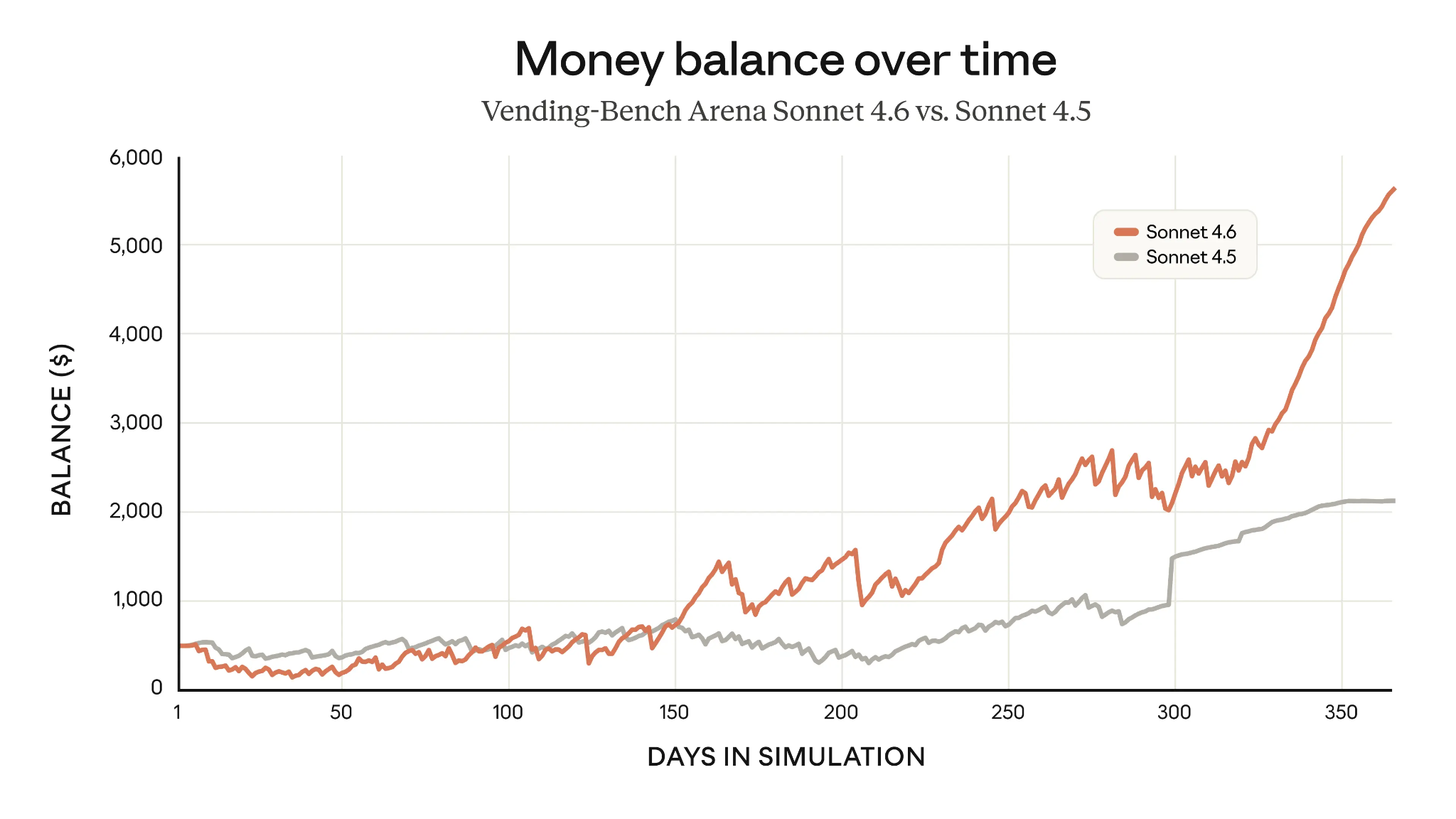
Pontuações do Vending-Bench: Claude Sonnet 4.6 vs Sonnet 4.5 (Fonte: Anthropic)
Na plataforma e na API do Claude, o Sonnet 4.6 libera para todos alguns recursos que antes eram restritos aos modelos Opus ou a planos pagos.
Um recurso bacana apresentado com o lançamento do Claude Opus 4.6 é o raciocínio adaptativo. Ele permite que o Claude decida automaticamente quando e quanto raciocinar antes de responder. Na API, pode ser ativado com thinking: {type: “adaptive”}. Na interface web, já vem habilitado para o Sonnet 4.6 e o Opus 4.6.
Os Connectors oferecem integrações baseadas em MCP, ou seja, acesso direto a apps externos como Google Workspace e Slack. Assim, o Sonnet 4.6 pode buscar e agir sobre dados em tempo real dessas ferramentas dentro dos chats. Originalmente, os conectores eram um recurso apenas do plano pago, mas como o Sonnet 4.6 é o novo modelo padrão, eles também estão disponíveis para usuários gratuitos.
Resolvi ver como o Claude Sonnet 4.6 se sai nas mesmas tarefas usadas no nosso guia do Claude Opus 4.6, para comparar diretamente os dois. Os testes envolvem tarefas em múltiplas etapas e investigam raciocínio matemático e relacionado a código.
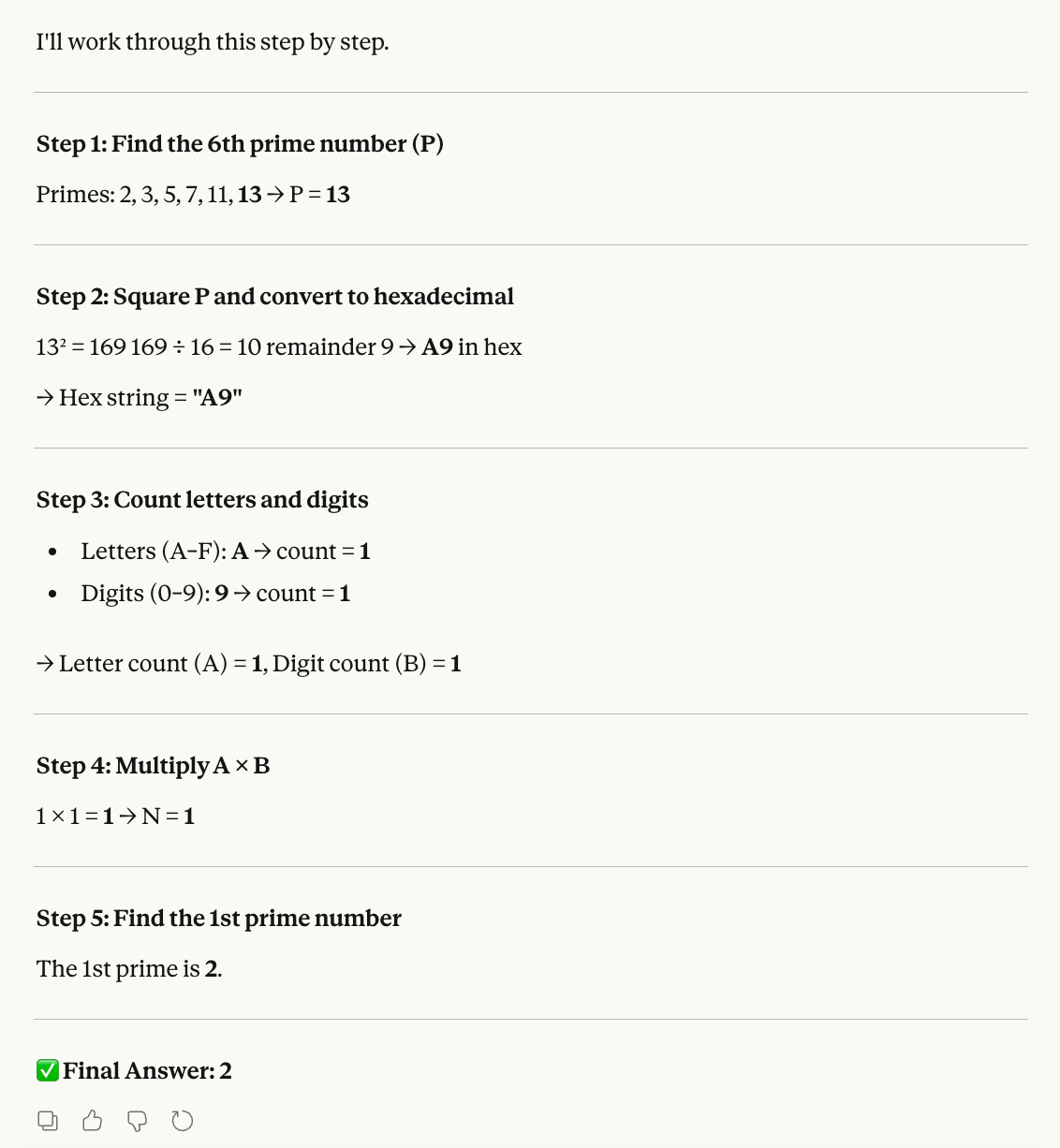
O primeiro teste mira habilidades matemáticas:
Passo 1: Encontre o 6º número primo. Chame-o de P.
Passo 2: Converta o quadrado de P para hexadecimal.
Passo 3: Conte as letras (A–F) e dígitos (0–9) nessa string hexa. Chame-os de A e B.
Passo 4: Multiplique A × B. Chame o resultado de N.
Passo 5: Encontre o N-ésimo número primo.Vamos calcular aqui para conferir se o resultado bate:
A ideia deste teste é confundir o modelo com tarefas que exigem lógicas de contagem e formatos numéricos diferentes. Assim como o Opus 4.6, o Sonnet 4.6 resolve cada etapa e chega à conclusão correta:
O próximo teste mira o raciocínio espacial, um ponto fraco notório de muitos LLMs:
Passo 1: Crie uma matriz 2×2 M com linha superior [4, 2] e linha inferior [1, 5].
Passo 2: Rotacione M 90 graus no sentido horário.
Passo 3: Calcule o determinante da matriz rotacionada.
Passo 4: Eleve esse determinante ao cubo.
Passo 5: Subtraia o 13º número de Fibonacci do resultado.A resposta correta é -6.065:
O Sonnet 4.6 não tem dificuldade com a tarefa. Ele entende o contexto espacial da matriz e a rotaciona corretamente; lidar com números negativos também não é problema:


Por fim, vamos mirar na depuração de código, uma das supostas forças do Sonnet 4.6. O teste verifica o quão consciente de contexto o modelo é diante de um bug específico.
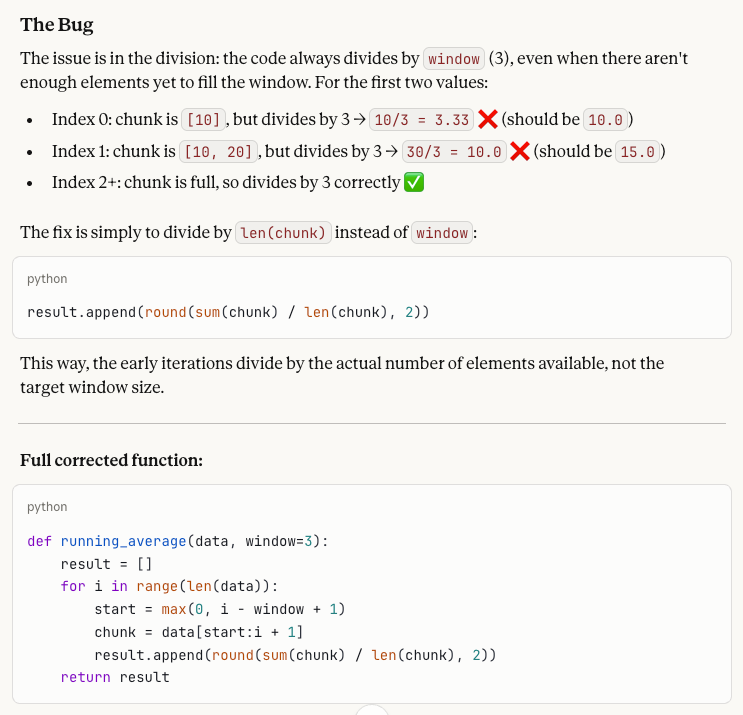
Um desenvolvedor escreveu esta função Python para calcular uma média móvel:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
Quando chamada com running_average([10, 20, 30, 40, 50]), os dois primeiros valores na saída parecem errados. Por quê? Ajude a corrigir o que está errado!O problema é que a função sempre divide por window (3), mesmo antes de haver 3 elementos no chunk no início da lista. A saída do código com bug é [3.33, 10.0, 20.0, 30.0, 40.0], mas os dois primeiros valores deveriam ser 10,0 e 15,0, já que esses chunks têm apenas 1 e 2 elementos, respectivamente, e deveriam ser divididos por esses números. Logo, a correção é dividir por len(chunk) em vez de window.
Este teste é legal porque mira um ponto fraco dos LLMs: eles frequentemente executam o loop perfeitamente, mas interpretam a saída como correta. Isso ocorre porque veem os cálculos passo a passo sem erro, mas não consideram o que a função deveria fazer. Só quando o modelo conecta o propósito da função com sua execução é que ele consegue identificar o bug.
Mais uma vez, o modelo passa no teste. Claro, este foi apenas um recorte pequeno de testes possíveis, mas, nesses exemplos, o Sonnet 4.6 fica no mesmo nível do Opus 4.6.
Com a enxurrada de lançamentos de modelos recentemente, já nos acostumamos a muita movimentação no topo dos leaderboards. Ainda assim, os primeiros resultados do Claude Sonnet 4.6 em vários benchmarks de LLM impressionam, especialmente considerando que ele não é o modelo flagship da Anthropic.
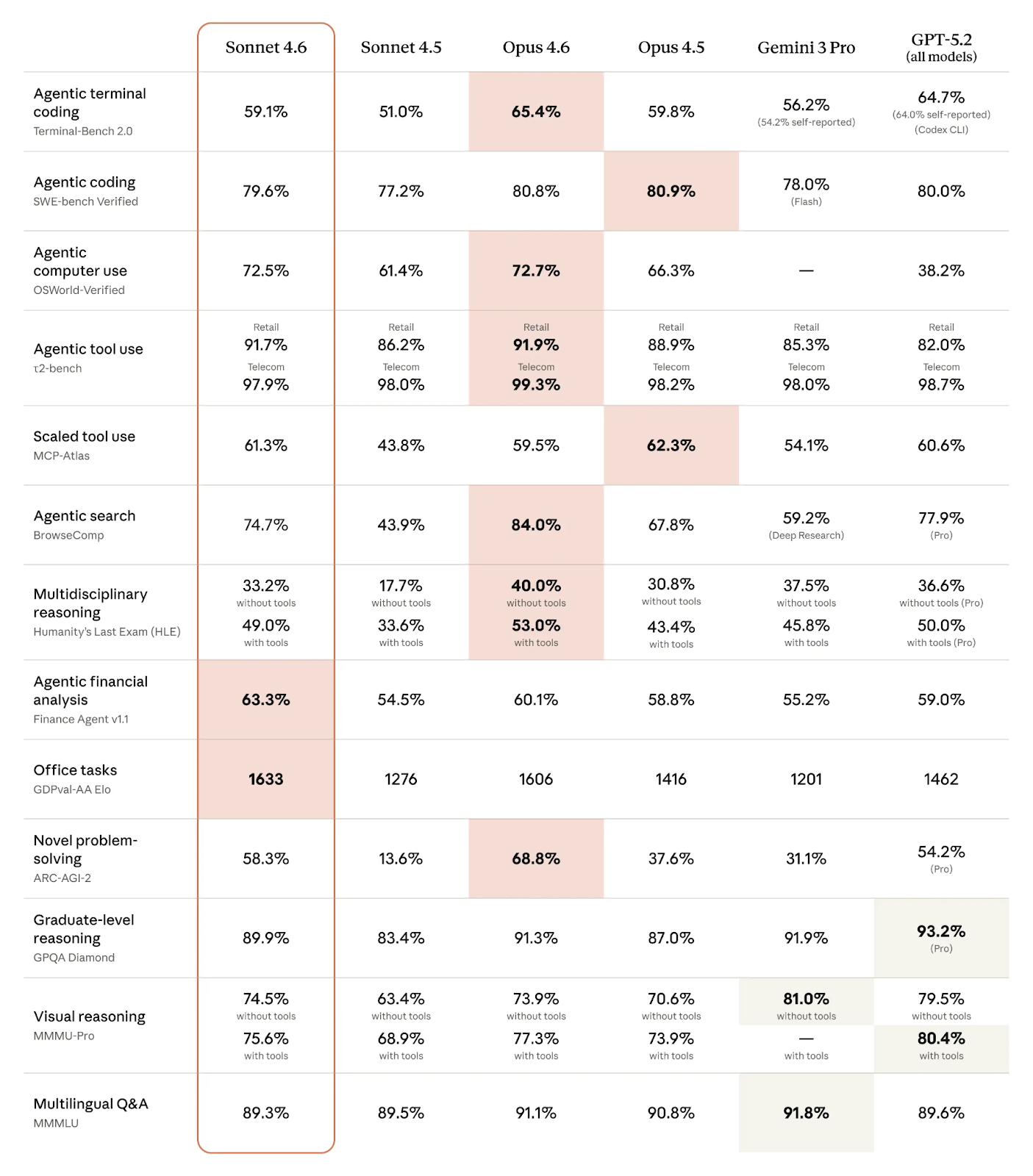
Pontuações de benchmark do Claude Sonnet 4.6 e concorrentes (Fonte: Anthropic)
Como vemos na tabela, o Claude Sonnet 4.6 vai muito bem em benchmarks agentic:
O mais interessante é que a Anthropic parece estar à frente em tarefas agentic específicas de domínio:
Você já pode usar o Claude Sonnet 4.6 por vários canais. Veja como acessar:
O Sonnet 4.6 está disponível na interface web do Claude.ai, nos apps iOS e Android, e no app para macOS com o Claude Cowork.
Em todas essas plataformas, ele é o novo modelo padrão, inclusive no plano gratuito. Isso significa que criação de arquivos, conectores, skills e compactação de contexto agora estão disponíveis para todos.
Desenvolvedores podem usar o Claude Sonnet 4.6 pela API da Anthropic com o ID de modelo claude-sonnet-4-6. Os preços permanecem iguais aos do antecessor: um milhão de tokens de entrada custa US$ 3 e um milhão de tokens de saída custa US$ 15.
Para implantação em escala corporativa, o Sonnet 4.6 está disponível em várias plataformas de nuvem, como AWS Bedrock ou Google Vertex AI, cada uma com preços próprios.
O Claude Sonnet 4.6 agora também impulsiona o Claude Code e é o modelo padrão para contas Pro e Team, enquanto planos mais altos usam o Opus 4.6 por padrão. Para ver exemplos do que você pode construir, recomendo nossos tutoriais sobre hooks do Claude Code e como criar plugins para o Claude Code.
Além disso, o Sonnet 4.6 pode ser usado em IDEs e outros assistentes de código, como o Cursor ou o Roo Code.
Em muitos domínios, a diferença entre o Sonnet 4.6 e o Opus 4.6 é tão pequena que dá para chamar de empate. Isso é especialmente verdadeiro para várias tarefas agentic, como programação agentic, uso agentic de computador e uso agentic de ferramentas. O Sonnet 4.6 ainda supera o Opus 4.6 em análise financeira agentic, tarefas de escritório e uso de ferramentas em escala.
Como era de se esperar, são as tarefas que exigem raciocínio pesado ou criatividade onde o Opus 4.6 realmente brilha, como solução de problemas inéditos e raciocínio multidisciplinar. No domínio agentic, o Opus 4.6 é melhor em programação agentic no terminal e busca agentic.
Para a maioria das tarefas de programação e agentic, e para aquelas em que seguir instruções é crucial, o Claude Sonnet 4.6 é a melhor escolha, pois oferece desempenho praticamente idêntico a um custo bem menor. Além disso, ele leva vantagem em velocidade.
Times que dependem de raciocínio em nível especialista ou workflows multiagente devem escolher o Claude Opus 4.6. Especialmente para pesquisa, migrações complexas ou trabalhos críticos de especialistas, o Opus 4.6 se destaca.
Com o Claude Sonnet 4.5, a Anthropic segue enfatizando código, agentes e uso de computador. Além de um grande salto de desempenho em relação ao antecessor, ele libera recursos como conectores e raciocínio adaptativo para todos, inclusive no plano gratuito.
As primeiras impressões e os benchmarks são muito bons, e a sensação é de mudança de patamar porque ele oferece desempenho (quase) de Opus sem o preço salgado. Para muitos workflows do dia a dia, chega a ser difícil justificar o uso do modelo flagship da Anthropic. Dito isso, para tarefas que exigem raciocínio pesado, o Claude Opus 4.6 continua sendo a melhor escolha.
Vai ser interessante ver por quanto tempo o Claude Sonnet 4.6 se mantém no topo dos leaderboards e como os concorrentes da Anthropic vão responder a este lançamento.
Falamos de tarefas agentic ao longo do artigo. Se você quer aprender mais sobre como usar modelos como o Claude Sonnet 4.6 nesse tipo de workflow, recomendo a nossa trilha de habilidades AI Agent Fundamentals.
Cursos de IA
Programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Richie Cotton
7 min
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer


