
Cursus
Introductie tot Power BI
4 Hr
809.3K
Tegenwoordig vereist de hoeveelheid data die uit allerlei bronnen wordt gegenereerd een geavanceerdere aanpak voor het beheren en analyseren ervan. Waarom? Omdat traditionele methoden het enorme datavolume niet aankunnen. We hebben geavanceerde tools nodig om informatie efficiënt op te slaan en op te halen.
Daarom fungeert de semantische laag als een tussenlaag tussen databases en gebruikersapplicaties. Ze biedt een onafhankelijke dataview door een gemeenschappelijke zakelijke vocabulaire, regels en relaties tussen data-elementen te definiëren.
In dit artikel gaan we dieper in op het belang en de voordelen van de semantische laag.
De semantische laag overbrugt de kloof tussen de technische structuur van de onderliggende databronnen (denk aan datawarehouses en datalakes) en de behoeften van gebruikers.
Databases hebben vaak technische tabelnamen en cryptische velddefinities. De semantische laag creëert een nieuwe, onafhankelijke weergave van de data met duidelijke zakelijke termen die iedereen in de organisatie begrijpt.
Deze laag definieert ook een gemeenschappelijke zakelijke vocabulaire, omdat verschillende afdelingen mogelijk andere termen gebruiken voor hetzelfde concept. Zo kan "sales" voor het salesteam "omzet" betekenen voor de financiële afdeling. Hierdoor zorgt de semantische laag dat iedereen dezelfde taal spreekt en voorkomt ze verwarring bij de data-analyse.
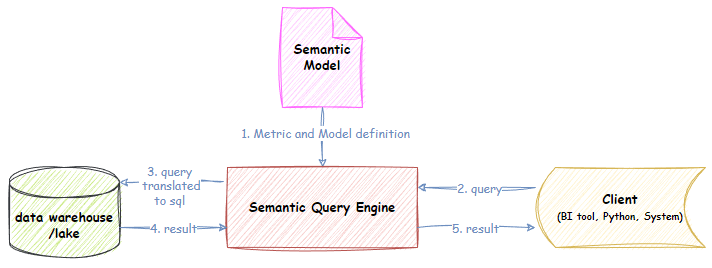
Structuur van de semantische laag. Bron: Dimodelo
De meeste organisaties kampen met problemen zoals datasilo’s, inconsistente datadefinities en complexe data-toegangsprocessen. Het implementeren van een semantische laag zorgt voor relatief eenvoudige data-toegang en een soepelere bedrijfsvoering.
Laten we de noodzaak van een semantische laag begrijpen:
Organisaties hebben data verspreid over meerdere databases, spreadsheets en cloudapplicaties. Dit creëert datasilo’s en maakt het lastig om een holistisch beeld te krijgen, wat weer leidt tot inconsistenties in definities en terminologie.
Om dit aan te pakken, brengt de semantische laag de data samen onder een consistente zakelijke vocabulaire. Zo blijft data afdelingsbreed consistent en volgt ze duidelijke regels. Hierdoor kunnen datateams inconsistenties uit verschillende bronnen rechtzetten en schonere, betrouwbaardere data gebruiken voor analyses.
Voor het werken met complexe datastructuren is technische expertise vereist, wat de toegang tot waardevolle inzichten beperkt voor niet-technische gebruikers zoals businessanalisten en leidinggevenden.
De semantische laag democratiseert de data-toegang door informatie gebruiksvriendelijk te presenteren en meer gebruikers in staat te stellen zelfstandig data te verkennen en te analyseren. Je kunt het een selfservice-aanpak noemen, maar het vermindert de afhankelijkheid van IT-teams voor basistaken.
Omdat dataprofessionals met een goed gedefinieerde semantische laag sneller data kunnen vinden en analyseren, genereren ze sneller inzichten en nemen ze betere, data-gedreven beslissingen om kansen wendbaarder te benutten.
Semantische lagen hebben verschillende doelen, en het type dat jouw bedrijf nodig heeft, hangt af van waar de data vandaan komt en wat ermee wordt verwacht. Laten we de meest voorkomende typen bekijken:
De universele semantische laag is een zelfstandige laag, los van het datawarehouse of de BI-tool. Het is een single source of truth voor datadefinities en bedrijfslogica, met voordelen zoals gecentraliseerd beheer, betere governance en flexibiliteit:
Hoewel de universele semantische laag extra investeringen vergt, is ze geschikter voor complexe data-omgevingen.
De semantische laag in het datawarehouse bevindt zich binnen het datawarehouse zelf. Ze helpt data-engineers het datamodel te organiseren en te beheren door de onderhoudbaarheid van data binnen het warehouse te verbeteren. De focus ligt op het volgende:
Net als de semantische laag in een datawarehouse wordt de semantische laag in een datalake gebruikt om de schema’s van ongestructureerde of semi-gestructureerde data te organiseren en te beheren. Ze helpt gebruikers de betekenis en relaties tussen verschillende data-elementen binnen het lake te begrijpen.
Dit is het meest voorkomende type. Het zit tussen het datawarehouse (of datalake) en BI-tools zoals Power BI of Tableau. Daardoor wordt data toegankelijker voor businessgebruikers om te analyseren zonder de onderliggende datastructuur te hoeven begrijpen.
De zakelijke semantische laag definieert:
Sales in plaats van sales_table).Customer kan bijvoorbeeld gekoppeld zijn aan Order).Total Revenue).Wil je meer leren over de Power BI-semantiemodellen? Lees onze uitgebreide blogpost What are Power BI Semantic Models? om meer te weten over de componenten, modi en best practices om ze te maken en te beheren.
Een semantische-laagplatform verbindt de semantische laag met bedrijfsapplicaties of analysetools zoals Power BI, Tableau of andere. Het abstraheert de databronnen om een uniforme en zakelijk-vriendelijke weergave van de onderliggende data te bieden, zodat gebruikers snel toegang hebben tot informatie en die kunnen analyseren.
De belangrijkste componenten van een semantische-laagplatform zijn:
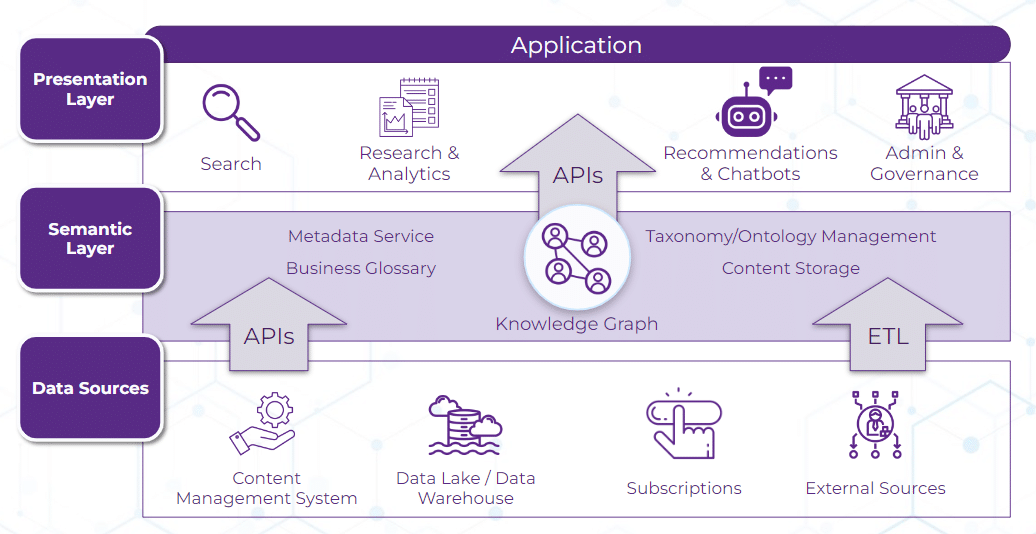
Belangrijkste componenten van een semantische laag. Bron: Enterprise Knowledge
Begrijpen hoe een semantische laag wordt gebouwd is net zo belangrijk als het belang ervan begrijpen. Volg deze stappen om een effectieve semantische laag te bouwen die een consistente en zakelijk-vriendelijke dataview biedt:
De eerste stap is het identificeren van de zakelijke vereisten en het begrijpen van de specifieke behoeften van eindgebruikers. Hiervoor werken data-analisten en inhoudsdeskundigen samen om inzicht te verzamelen in het type data dat ze nodig hebben, de vragen die ze willen beantwoorden en de rapporten of analyses die ze moeten maken.
Zodra alle vereisten helder zijn, kunnen ze een semantische laag bouwen die aansluit bij de specifieke behoeften van hun organisatie.
Na het verzamelen van de vereisten evalueren datateams de bestaande databronnen van de organisatie. Zo krijgen ze inzicht in het formaat en de kwaliteit van de data in die bronnen. Dit helpt bepalen welke voorbereiding en transformatie nodig is voordat de data in de semantische laag wordt geïntegreerd.
Vervolgens ontwerpen teams het semantisch model op basis van de zakelijke vereisten en de data-evaluatie. Dit model representeert de bedrijfsentiteiten en hun relaties op een manier die zinvol is voor eindgebruikers.
Bij het ontwerpen gebruiken datateams gangbare modelleertechnieken, zoals dimensioneel modelleren of data-vaultmodellering, om te zorgen dat het semantisch model schaalbaar en uitbreidbaar is.
Zodra het semantisch model is ontworpen, implementeren data-analisten de semantische laag met de juiste tools en technologieën. Ze maken views en berekende velden, hiërarchieën en andere constructen om ruwe data naar het semantisch model te vertalen binnen hun datamodellerings-tool of business intelligence (BI)-platform—als ze dat gebruiken.
Datateams bouwen vervolgens verbindingen tussen de semantische laag en de databronnen met connectors of API’s, door extractie- en transformatieprocessen te schrijven om data te verplaatsen en voor te bereiden voor de semantische laag.
Zo transformeren en normaliseren ze data zodat die past binnen het semantisch model en zorgen ze dat data over alle bronnen heen gesynchroniseerd en actueel is.
Ze testen en valideren de semantische laag ook grondig om te garanderen dat die accuraat is en aansluit bij de zakelijke vereisten. Dit doen ze in de test- en validatiefase:
Na afronding rollen teams de semantische laag uit naar de productieomgeving, wat betekent dat die beschikbaar is voor eindgebruikers. Vervolgens richten ze doorlopend onderhoud in om de datakwaliteit te monitoren en de semantische laag bij te werken naarmate zakelijke vereisten veranderen.
Om ervoor te zorgen dat de semantische laag optimaal werkt, beoordelen ze regelmatig de performance om verbeterkansen te identificeren.
Hoewel het bouwen van een semantische laag een win-winsituatie lijkt voor organisaties, kan de implementatie verschillende uitdagingen met zich meebrengen die dataprofessionals zorgvuldig moeten afwegen. Laten we enkele van deze uitdagingen bekijken:
Door deze uitdagingen zorgvuldig te overwegen, vergroot je de kans op een succesvolle implementatie van een semantische laag.
Een semantische laag verbetert de toegankelijkheid en bruikbaarheid van data door een uniforme weergave van complexe datasets te bieden. Dit zijn enkele gangbare methoden om deze integratie te realiseren.
Een metadata-first-architectuur gebruikt een semantische laag om een logische architectuur te creëren met focus op metadata. Ze biedt een uniforme weergave van data in de hele organisatie zonder fysieke consolidatie. Deze aanpak standaardiseert definities en governance op bedrijfsniveau, terwijl componenten die zijn toegesneden op specifieke businessunits gedecentraliseerd kunnen zijn.
Bovendien is dit ideaal voor organisaties die standaardisatie willen balanceren met de wendbaarheid van businessunits in dataverwerking.
In deze aanpak wordt een gemeenschappelijke vocabulaire in OML gecreëerd die automatisch kan worden geïnstantieerd vanuit gedistribueerde modellen in een knowledge graph. Dit maakt het eenvoudiger om gefedereerde informatiediensten te ontsluiten, classificeren, controleren en hergebruiken.
Bij het implementeren van dit type semantische laag wordt UFO—een fundamentele ontologie met een gedeelde vocabulaire voor het beschrijven van concepten en relaties—gebruikt. Dit helpt met name bij het integreren van data uit verschillende domeinen.
Deze gedecentraliseerde aanpak benut de inherente semantische mogelijkheden van individuele tools en systemen (bijv. CMS, CRM, BI-dashboards) om data op het niveau van businessunits te beheren zonder een verbonden enterprise-framework.
Het is een ideale optie voor organisaties met diverse en zelfstandige businessunits die zich snel moeten kunnen aanpassen aan veranderende eisen.
Dit gecentraliseerde model consolideert data binnen een EDW of DL en fungeert als de gezaghebbende bron voor datadefinities en bedrijfslogica. Het is een goede optie voor grote ondernemingen met complexe data-eisen en strenge governance-regels, zoals financiële instellingen en zorgorganisaties.
Kleinere organisaties kunnen deze aanpak beter vermijden, omdat die veel initiële investeringen in middelen en tijd vereist.
De juiste tool voor de semantische laag kiezen helpt je data effectief te beheren en te benutten. Hier zijn enkele van de beste tools op de markt, hun features en hoe ze jouw organisatie kunnen helpen.
| Tool | Belangrijkste features | Voordelen |
|---|---|---|
| Cube.js | Headless BI, Datamodellering, Caching, API’s, Realtime-analyse | De semantische laag van Cube.js maakt realtime-analyse en datavisualisatie mogelijk voor efficiënte data-analyse. |
| MetricFlow | Datamodellering, Metrics-laag, Caching, API’s, Datatransformatie | De semantische laag van MetricFlow ondersteunt naadloze integratie met diverse databronnen en biedt een uniforme weergave. |
| dbt | Datatransformatie, Metrics-laag, Caching, API’s, Datamodellering | De semantische laag van dbt biedt een uniforme weergave van data door datastructuren en relaties te modelleren, waardoor complexe data eenvoudiger te analyseren en te visualiseren is. |
| Tableau | Datavisualisatie, Datamodellering, Caching, API’s | De semantische laag van Tableau ondersteunt datavisualisatie, zodat gebruikers interactieve dashboards en rapporten kunnen maken. |
| Power BI | Datavisualisatie, Datamodellering, API’s, Dataintegratie | De dataintegratiemogelijkheden van Power BI maken het eenvoudig om met diverse databronnen te integreren. |
De semantische laag is een mechanisme voor bedrijfstransformatie voor iedere organisatie die de enorme hoeveelheden en variëteit aan data binnen de muren wil benutten. Ze maakt onderbouwde besluitvorming mogelijk en vergroot de toegankelijkheid via één uniforme aanpak voor data.
Maar natuurlijk kleven er ook nadelen aan de implementatie van een semantische laag. De datacomplexiteit neemt toe en er kunnen schaalbaarheidsproblemen ontstaan. Datateams kunnen dit echter ondervangen met goede planning, training en passende tooling.
Als je wilt leren hoe je data benut met tools als Power BI, heeft DataCamp diverse leermiddelen. De cursus Introduction to Power BI biedt een solide basis voor beginners. Voor iets uitgebreiders kun je het volledige Data Analyst in Power BI-carrièrepad overwegen, dat samen met Microsoft is ontwikkeld.
Als je ten slotte geïnteresseerd bent in het integreren van geavanceerde technologieën, bekijk dan de cursus Implementing AI Solutions in Business om te zien hoe AI in bedrijfsprocessen kan worden opgenomen om innovatie en efficiëntie te stimuleren.
Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
