Curso
Introducción a Power BI
4 h
793.3K
Hoy en día, la cantidad de datos generados a partir de diversas fuentes exige un enfoque más avanzado para gestionar y analizar los datos disponibles. ¿Por qué? Porque los métodos tradicionales no pueden manejar el enorme volumen de datos. Necesitamos herramientas avanzadas para almacenar y recuperar información de forma eficaz.
Por eso la capa semántica actúa como intermediaria entre las bases de datos y las aplicaciones de los usuarios. Proporciona una visión independiente de los datos mediante la definición de un vocabulario empresarial común, reglas y relaciones entre los elementos de datos.
En este artículo exploraremos con más detalle la importancia y las ventajas de la capa semántica.
La capa semántica tiende un puente entre la estructura técnica de las fuentes de datos subyacentes (piensa en almacenes de datos y lagos de datos) y las necesidades de los usuarios.
Las bases de datos suelen tener nombres de tabla técnicos y definiciones de campo crípticas. La capa semántica crea una visión nueva e independiente de los datos, utilizando términos empresariales claros que todos los miembros de la organización puedan entender.
Esta capa también define un vocabulario empresarial común, ya que distintos departamentos pueden utilizar términos diferentes para un mismo concepto. Por ejemplo, "ventas" para el equipo de ventas podría ser "ingresos" para el departamento financiero. Como resultado, la capa semántica garantiza que todo el mundo esté en la misma página y evita confusiones al analizar los datos.
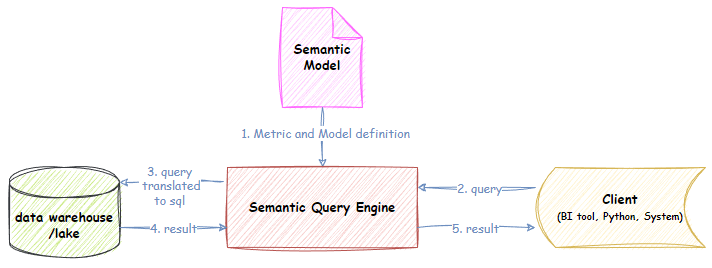
Estructura de la capa semántica. Fuente: Dimodelo
La mayoría de las organizaciones se enfrentan a problemas como silos de datos, definiciones de datos incoherentes y complejos procesos de acceso a los datos. Implementar una capa semántica garantiza que el acceso a los datos sea relativamente fácil y que las organizaciones funcionen sin problemas.
Comprendamos la necesidad de una capa semántica:
Las organizaciones tienen datos dispersos en múltiples bases de datos, hojas de cálculo y aplicaciones en la nube. Esto crea silos de datos y dificulta la obtención de una visión holística, lo que además provoca incoherencias en las definiciones y la terminología.
Para resolver este problema, la capa semántica unifica los datos bajo un vocabulario empresarial coherente. Esto garantiza que los datos sean coherentes en todos los departamentos y sigan normas claras. Como resultado, los equipos de datos pueden rectificar las incoherencias derivadas de las distintas fuentes de datos y utilizar datos más limpios y fiables para el análisis.
Se requieren conocimientos técnicos para trabajar con estructuras de datos complejas, lo que restringe el acceso a información valiosa a usuarios no técnicos, como analistas empresariales y ejecutivos.
La capa semántica democratiza el acceso a los datos presentando información fácil de usar y permitiendo que más usuarios exploren y analicen los datos de forma independiente. Puedes llamarlo enfoque de autoservicio, pero reduce la dependencia de los equipos informáticos para las tareas básicas de datos.
Dado que los profesionales de datos pueden encontrar y analizar los datos más rápidamente con una capa semántica bien definida, pueden generar perspectivas más rápidamente y tomar mejores decisiones basadas en datos para aprovechar las oportunidades con mayor agilidad.
Las capas semánticas tienen distintas finalidades, y el tipo de capa semántica que necesita tu empresa depende de la procedencia de los datos y de lo que se espera de ellos. Veamos los tipos más comunes de capas semánticas:
La capa semántica universal es una capa independiente, separada del almacén de datos o de la herramienta de BI. Es una única fuente de verdad para las definiciones de datos y la lógica empresarial, lo que te proporciona ventajas como la gestión centralizada, una mejor gobernanza y flexibilidad:
Aunque la capa semántica universal requiere una inversión adicional, es más adecuada para entornos de datos complejos.
La capa semántica del almacén de datos reside dentro del propio almacén de datos. Ayuda a los ingenieros de datos a organizar y gestionar el modelo de datos, mejorando la capacidad de mantenimiento de los datos dentro del almacén de datos. Se centra en lo siguiente
Al igual que la capa semántica del almacén de datos, la capa semántica del lago de datos se utiliza dentro de un lago de datos para organizar y gestionar el esquema de los datos no estructurados o semiestructurados. Ayuda a los usuarios a comprender el significado y las relaciones entre los distintos elementos de datos del lago.
Es el tipo más común. Está entre el almacén de datos (o lago de datos) y herramientas de BI como Power BI o Tableau. Como resultado, hace que los datos sean más accesibles para que los usuarios empresariales los analicen sin comprender la estructura de datos subyacente.
La capa semántica empresarial define:
Sales en lugar de sales_table).Customer puede conectarse a la tabla Order ).Total Revenue).¿Quieres saber más sobre los modelos semánticos de Power BI? Lee nuestra detallada entrada del blog ¿Qué son los modelos semánticos de Power BI? para conocer sus componentes, modos y mejores prácticas para crearlos y gestionarlos.
Una plataforma de capa semántica conecta la capa semántica con aplicaciones empresariales o herramientas analíticas como Power BI, Tableau u otras. Abstrae las fuentes de datos para ofrecer una visión unificada y empresarial de los datos subyacentes, de modo que los usuarios puedan acceder a la información y analizarla rápidamente.
Los principales componentes de una plataforma de capa semántica incluyen:
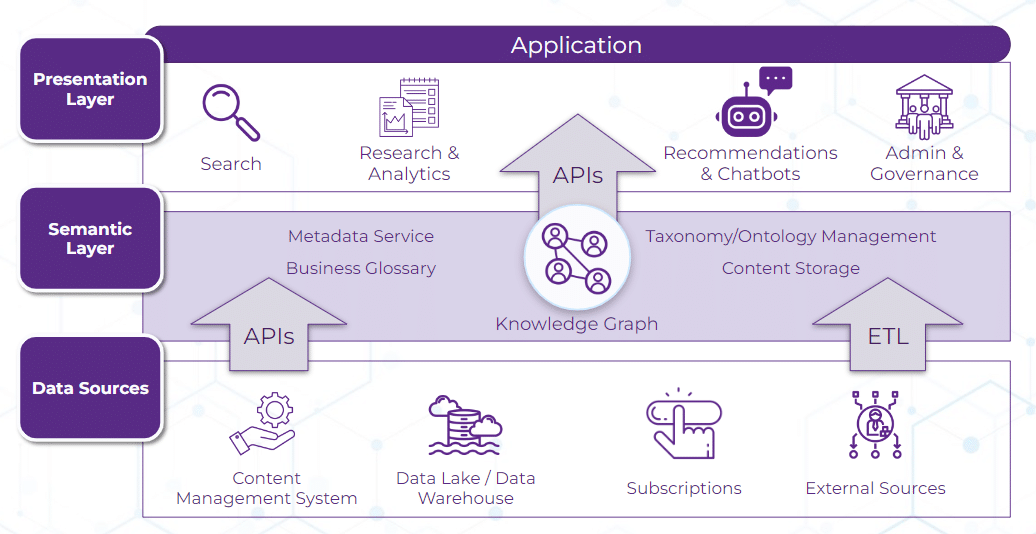
Principales componentes de una capa semántica. Fuente: Enterprise Knowledge
Comprender cómo se construye una capa semántica es tan importante como comprender su importancia. Por tanto, sigue estos pasos para construir una capa semántica eficaz que proporcione una visión de los datos coherente y adaptada a la empresa:
El primer paso es identificar los requisitos empresariales y comprender las necesidades específicas de los usuarios finales. Para ello, los analistas de datos y los expertos en la materia colaboran para reunir información sobre los tipos de datos que necesitan, las preguntas a las que deben responder y los informes o análisis que deben generar.
Una vez que tengan todos los requisitos, pueden construir una capa semántica que satisfaga las necesidades específicas de su organización.
Tras recopilar los requisitos, los equipos de datos evalúan las fuentes de datos existentes en su organización. Al hacerlo, comprenden el formato y la calidad de los datos almacenados en estas fuentes. Esto ayuda a determinar la preparación y transformación necesarias de los datos antes de integrarlos en la capa semántica.
A continuación, los equipos diseñan el modelo semántico basándose en los requisitos de la empresa y en la evaluación de los datos. Este modelo representa las entidades y relaciones empresariales de forma significativa para los usuarios finales.
Al diseñar este modelo, los equipos de datos utilizan técnicas de modelado estándar del sector, como el modelado dimensional o el modelado de bóvedas de datos, para garantizar que el modelo semántico sea escalable y extensible.
Una vez diseñado el modelo semántico, los analistas de datos implementan la capa semántica utilizando las herramientas y tecnologías adecuadas. Crean vistas y calculan campos, jerarquías y otras construcciones para traducir los datos brutos al modelo semántico dentro de su herramienta de modelado de datos o plataforma de inteligencia empresarial (BI), si utilizan alguna.
A continuación, los equipos de datos utilizan conectores o API para crear conexiones entre la capa semántica y las fuentes de datos, escribiendo procesos de extracción y transformación de datos para moverlos y prepararlos para la capa semántica.
De este modo, transforman y normalizan los datos para que se ajusten al modelo semántico y garantizan que estén sincronizados y actualizados en todas las fuentes.
También prueban y validan a fondo la capa semántica para asegurarse de que es precisa y se ajusta a sus requisitos empresariales. Esto es lo que hacen durante la fase de prueba y validación:
Una vez hecho todo, los equipos despliegan la capa semántica en el entorno de producción, lo que significa que está disponible para los usuarios finales. Ahora, establecen procesos de mantenimiento continuo para supervisar la calidad de los datos y actualizar la capa semántica a medida que evolucionan los requisitos empresariales.
Para garantizar que la capa semántica funciona de forma óptima, revisan periódicamente su rendimiento para identificar oportunidades de mejora.
Aunque la creación de una capa semántica pueda parecer una solución ventajosa para las organizaciones, puede presentar varios retos que los profesionales de los datos deben evaluar cuidadosamente durante la implementación. Veamos algunos de estos retos:
Si consideras detenidamente estos retos, puedes aumentar las posibilidades de éxito en la implantación de la capa semántica.
Una capa semántica mejora la accesibilidad y usabilidad de los datos al proporcionar una visión unificada de conjuntos de datos complejos. Aquí tienes algunos métodos estándar para llevar a cabo esta integración.
Una arquitectura de metadatos primero utiliza una capa semántica para crear una arquitectura lógica centrada en los metadatos. Proporciona una visión unificada de los datos de toda la organización sin necesidad de consolidación física. Este enfoque estandariza las definiciones y la gobernanza a nivel de empresa, de modo que puedan descentralizarse los componentes adaptados a unidades de negocio específicas.
Además, es una opción ideal para las organizaciones que quieren equilibrar la normalización y la agilidad de las unidades de negocio en el procesamiento de datos.
En este enfoque, se crea un vocabulario común en OML que puede instanciarse automáticamente a partir de modelos distribuidos en un grafo de conocimiento. Esto facilita el acceso, la clasificación, la comprobación y la reutilización de los servicios de información federados.
Al implementar este tipo de capa semántica, se utiliza UFO, una ontología fundacional con un vocabulario compartido para describir conceptos y relaciones. Ayuda especialmente a integrar datos de distintos ámbitos.
Este enfoque descentralizado aprovecha las capacidades semánticas inherentes a las herramientas y sistemas individuales (por ejemplo, CMS, CRM, cuadros de mando de BI) para gestionar los datos a nivel de unidad de negocio sin un marco empresarial conectado.
Es una opción ideal para organizaciones con unidades de negocio diversas e independientes que necesitan adaptarse rápidamente a los requisitos cambiantes.
Este modelo centralizado consolida los datos dentro de un EDW o DL y es la fuente autorizada para las definiciones de datos y la lógica empresarial. Es una buena opción para las grandes empresas con requisitos de datos complejos y normas de gobierno estrictas, como las instituciones financieras y las organizaciones sanitarias.
Sin embargo, las organizaciones pequeñas no deberían utilizar este enfoque, ya que requiere una fuerte inversión inicial en recursos y tiempo.
Seleccionar la herramienta de capa semántica adecuada ayuda a gestionar y aprovechar tus datos con eficacia. He aquí algunas de las mejores herramientas disponibles en el mercado, sus características y cómo pueden beneficiar a tu organización.
| Herramienta | Características principales | Beneficios |
|---|---|---|
| Cube.js | BI sin cabeza, Modelado de datos, Almacenamiento en caché, API, Análisis en tiempo real | La capa semántica de Cube.js permite el análisis en tiempo real y la visualización de datos para un análisis de datos eficaz. |
| MetricFlow | Modelado de datos, Capa de métricas, Almacenamiento en caché, APIs, Transformación de datos | La capa semántica de MetricFlow permite una integración perfecta con diversas fuentes de datos y proporciona una visión unificada. |
| dbt | Transformación de datos, Capa de métricas, Caché, APIs, Modelado de datos | La capa semántica de dbt proporciona una visión unificada de los datos mediante el modelado de estructuras y relaciones de datos, lo que facilita el análisis y la visualización de datos complejos. |
| Tableau | Visualización de datos, Modelado de datos, Caché, APIs | La capa semántica de Tableau admite la visualización de datos para que los usuarios puedan crear cuadros de mando e informes interactivos. |
| Power BI | Visualización de datos, Modelado de datos, APIs, Integración de datos | Las capacidades de integración de datos de Power BI facilitan la integración con diversas fuentes de datos. |
La capa semántica es un mecanismo de transformación empresarial para cualquier organización que desee utilizar los enormes volúmenes y variedades de datos disponibles en sus instalaciones. Hace posible una toma de decisiones informada y aumenta la accesibilidad mediante un enfoque único de los datos.
Pero, por supuesto, junto con eso vienen múltiples inconvenientes de implementación a través de una capa semántica. Aumenta la complejidad de los datos y crea problemas de escalabilidad. Sin embargo, los equipos de datos pueden manejar esto mediante la planificación, la formación y un buen soporte de herramientas.
Si quieres saber cómo aprovechar los datos mediante herramientas como Power BI, DataCamp dispone de varios recursos educativos. El curso Introducción a Power BI proporciona una base sólida para principiantes. Para algo más implicado, considera la carrera completa de Analista de Datos en Power BI, creada conjuntamente con Microsoft.
Por último, si te interesa integrar tecnologías avanzadas, consulta el curso Implantación de soluciones de IA en la empresa para ver cómo se puede incorporar la IA a los procesos empresariales para impulsar la innovación y la eficiencia.
Aprende con DataCamp
Curso
Curso
Curso
blog
Joleen Bothma
7 min
blog
Matt Crabtree
10 min
blog
Abid Ali Awan
6 min
blog
Tim Lu
12 min
blog
Javier Canales Luna
14 min
Tutorial
Kurtis Pykes



