
Corso
Introduzione a Power BI
4 h
809.3K
Oggi, la quantità di dati generati da varie fonti richiede un approccio più avanzato alla gestione e all’analisi dei dati disponibili. Perché? Perché i metodi tradizionali non riescono a gestire l’enorme volume di dati. Servono strumenti avanzati per archiviare e recuperare le informazioni in modo efficiente.
Ecco perché il livello semantico funge da intermediario tra i database e le applicazioni utente. Fornisce una vista indipendente dei dati definendo un vocabolario di business comune, regole e relazioni tra gli elementi dei dati.
In questo articolo, esploreremo più nel dettaglio l’importanza e i vantaggi del livello semantico.
Il livello semantico colma il divario tra la struttura tecnica delle fonti dati sottostanti (come data warehouse e data lake) e le esigenze degli utenti.
I database spesso hanno nomi di tabelle tecnici e definizioni di campi criptiche. Il livello semantico crea una nuova vista indipendente dei dati utilizzando termini di business chiari che chiunque in azienda può comprendere.
Questo livello definisce anche un vocabolario di business comune, poiché reparti diversi potrebbero usare termini diversi per lo stesso concetto. Ad esempio, per il team vendite “sales” potrebbe essere “revenue” per il dipartimento finance. Di conseguenza, il livello semantico assicura che tutti parlino la stessa lingua ed evita confusioni durante l’analisi dei dati.
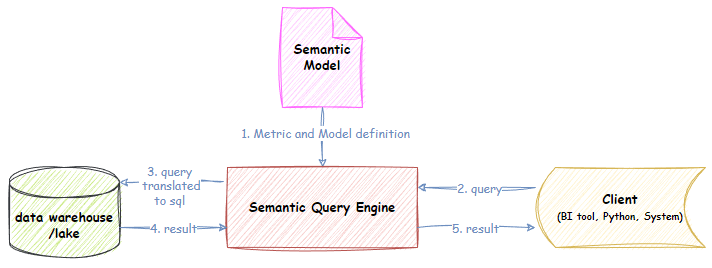
Struttura del livello semantico. Fonte: Dimodelo
La maggior parte delle organizzazioni affronta problemi come silos di dati, definizioni incoerenti e processi di accesso ai dati complessi. Implementare un livello semantico garantisce un accesso ai dati relativamente semplice e un funzionamento più fluido dell’organizzazione.
Vediamo perché serve un livello semantico:
Le organizzazioni hanno dati sparsi tra più database, fogli di calcolo e applicazioni cloud. Questo crea silos e rende difficile ottenere una visione olistica, causando ulteriori incoerenze nelle definizioni e nella terminologia.
Per affrontare il problema, il livello semantico unifica i dati sotto un vocabolario di business coerente. In questo modo i dati restano consistenti tra i reparti e seguono regole chiare. Di conseguenza, i team dati possono correggere le incoerenze derivanti da fonti diverse e utilizzare dati più puliti e affidabili per l’analisi.
Per lavorare con strutture dati complesse è richiesta competenza tecnica, cosa che limita l’accesso a insight preziosi per utenti non tecnici come business analyst e manager.
Il livello semantico democratizza l’accesso ai dati presentando informazioni intuitive e consentendo a più utenti di esplorare e analizzare i dati in autonomia. Puoi considerarlo un approccio self-service, che però riduce la dipendenza dai team IT per le attività di base.
Poiché chi lavora con i dati può trovare e analizzare le informazioni più rapidamente grazie a un livello semantico ben definito, può generare insight più in fretta e prendere decisioni data-driven migliori per cogliere le opportunità con maggiore agilità.
I livelli semantici hanno scopi diversi e il tipo di livello di cui la tua azienda ha bisogno dipende dalla provenienza dei dati e dalle aspettative. Vediamo i tipi più comuni:
Il livello semantico universale è un livello autonomo, separato dal data warehouse o dallo strumento BI. È un’unica fonte di verità per definizioni dei dati e logica di business, con vantaggi come gestione centralizzata, governance migliore e flessibilità:
Sebbene richieda investimenti aggiuntivi, il livello semantico universale è più adatto ad ambienti dati complessi.
Il livello semantico nel data warehouse risiede all’interno del data warehouse stesso. Aiuta i data engineer a organizzare e gestire il modello dati migliorando la manutenibilità dei dati all’interno del data warehouse. Si concentra su:
Come per il data warehouse, il livello semantico nel data lake viene utilizzato all’interno di un data lake per organizzare e gestire lo schema di dati non strutturati o semi-strutturati. Aiuta gli utenti a comprendere significato e relazioni tra i diversi elementi nel lake.
È il tipo più comune. Si colloca tra il data warehouse (o il data lake) e gli strumenti BI come Power BI o Tableau. Di conseguenza, rende i dati più accessibili per gli utenti di business, che possono analizzarli senza comprendere la struttura sottostante.
Il livello semantico di business definisce:
Sales invece di sales_table).Customer può collegarsi alla tabella Order).Total Revenue).Vuoi saperne di più sui modelli semantici di Power BI? Leggi il nostro articolo dettagliato What are Power BI Semantic Models? per scoprirne componenti, modalità e best practice per crearli e gestirli.
Una piattaforma di livello semantico collega il livello semantico alle applicazioni di business o agli strumenti di analytics come Power BI, Tableau o altri. Astrae le fonti dati per offrire una vista unificata e orientata al business dei dati sottostanti, così gli utenti possono accedere e analizzare rapidamente le informazioni.
I componenti principali di una piattaforma di livello semantico includono:
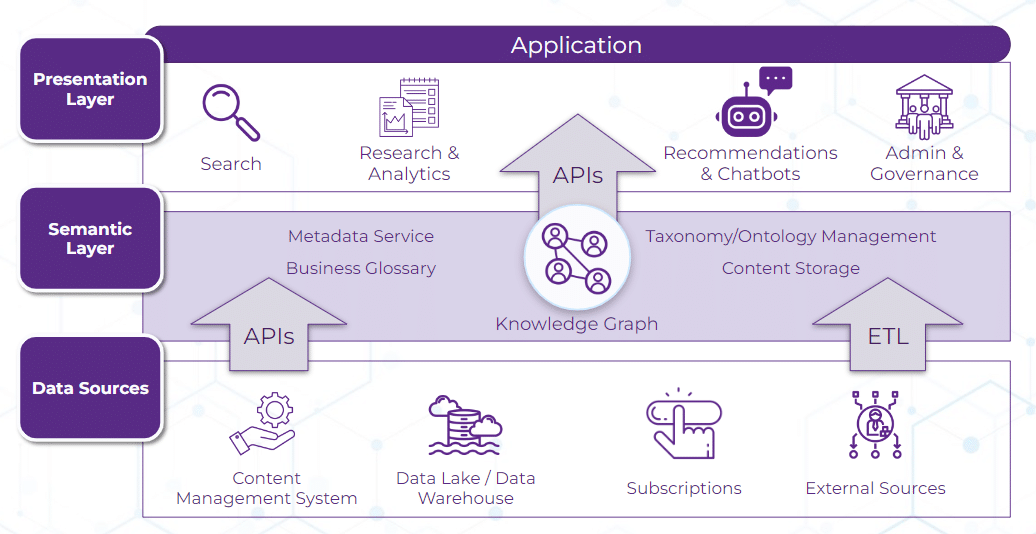
Componenti principali di un livello semantico. Fonte: Enterprise Knowledge
Capire come si costruisce un livello semantico è importante quanto comprenderne l’importanza. Segui quindi questi passaggi per creare un livello semantico efficace che offra una vista dei dati coerente e orientata al business:
Il primo passo è identificare i requisiti di business e comprendere le esigenze specifiche degli utenti finali. Per farlo, data analyst ed esperti di dominio collaborano per raccogliere informazioni sui tipi di dati richiesti, sulle domande a cui devono rispondere e sui report o analisi da generare.
Una volta raccolti tutti i requisiti, possono costruire un livello semantico che soddisfi le esigenze specifiche dell’organizzazione.
Dopo aver raccolto i requisiti, i team dati valutano le fonti esistenti dell’organizzazione. In questo modo comprendono formato e qualità dei dati archiviati in tali fonti. Questo aiuta a determinare la preparazione e le trasformazioni necessarie prima di integrare i dati nel livello semantico.
Successivamente, i team progettano il modello semantico in base ai requisiti di business e alla valutazione dei dati. Questo modello rappresenta entità e relazioni di business in modo significativo per gli utenti finali.
Durante la progettazione, i team utilizzano tecniche di modellazione standard del settore, come la modellazione dimensionale o il data vault modeling, per garantire che il modello semantico sia scalabile ed estensibile.
Una volta progettato il modello, i data analyst implementano il livello semantico con gli strumenti e le tecnologie appropriate. Creano viste e campi calcolati, gerarchie e altri costrutti per tradurre i dati grezzi nel modello semantico all’interno del loro strumento di data modeling o della piattaforma di business intelligence (BI), se usata.
I team dati utilizzano quindi connettori o API per creare connessioni tra il livello semantico e le fonti dati, scrivendo processi di estrazione e trasformazione per spostare e preparare i dati per il livello semantico.
In questo modo trasformano e normalizzano i dati per adattarli al modello semantico e assicurano che siano sincronizzati e aggiornati tra tutte le fonti.
Testano e convalidano inoltre accuratamente il livello semantico per garantirne l’accuratezza e l’allineamento ai requisiti di business. Ecco cosa fanno durante la fase di test e validazione:
Dopo aver completato tutto, i team distribuiscono il livello semantico nell’ambiente di produzione, rendendolo disponibile agli utenti finali. A questo punto stabiliscono processi di manutenzione continua per monitorare la qualità dei dati e aggiornare il livello semantico man mano che evolvono i requisiti di business.
Per garantire un funzionamento ottimale, rivedono regolarmente le prestazioni del livello semantico per individuare opportunità di miglioramento.
Sebbene la creazione di un livello semantico possa sembrare una vittoria per le organizzazioni, può presentare diverse sfide che chi lavora con i dati dovrebbe valutare attentamente in fase di implementazione. Vediamone alcune:
Considerando attentamente queste sfide, puoi aumentare le probabilità di un’implementazione del livello semantico di successo.
Un livello semantico migliora accessibilità e usabilità dei dati offrendo una vista unificata di set di dati complessi. Ecco alcuni metodi standard per implementare questa integrazione.
Un’architettura metadata-first utilizza un livello semantico per creare un’architettura logica incentrata sui metadati. Offre una vista unificata dei dati nell’organizzazione senza alcuna consolidazione fisica. Questo approccio standardizza definizioni e governance a livello enterprise, così i componenti su misura per specifiche unità di business possono essere decentralizzati.
Inoltre, è una scelta ideale per le organizzazioni che vogliono bilanciare standardizzazione e agilità delle unità di business nell’elaborazione dei dati.
In questo approccio, si crea un vocabolario comune in OML che può essere automaticamente istanziato da modelli distribuiti in un knowledge graph. Ciò facilita l’implementazione di accesso, classificazione, verifica e riuso di servizi informativi federati.
Nell’implementare questo tipo di livello semantico si utilizza UFO—un’ontologia fondazionale con un vocabolario condiviso per descrivere concetti e relazioni—che aiuta in particolare a integrare dati provenienti da domini diversi.
Questo approccio decentralizzato sfrutta le capacità semantiche intrinseche dei singoli strumenti e sistemi (ad esempio CMS, CRM, dashboard BI) per gestire i dati a livello di unità di business senza un framework enterprise connesso.
È un’opzione ideale per organizzazioni con unità di business eterogenee e indipendenti che necessitano di adattarsi rapidamente ai cambiamenti.
Questo modello centralizzato consolida i dati all’interno di un EDW o di un DL ed è la fonte autorevole per definizioni dei dati e logica di business. È una buona opzione per grandi imprese con requisiti dati complessi e regole di governance stringenti, come istituzioni finanziarie e organizzazioni sanitarie.
Tuttavia, le piccole organizzazioni dovrebbero evitarlo, poiché richiede investimenti iniziali consistenti in risorse e tempo.
Scegliere lo strumento giusto per il livello semantico aiuta a gestire e valorizzare efficacemente i tuoi dati. Ecco alcuni dei migliori strumenti disponibili sul mercato, le loro caratteristiche e come possono aiutare la tua organizzazione.
| Strumento | Caratteristiche principali | Vantaggi |
|---|---|---|
| Cube.js | Headless BI, Data modeling, Caching, API, Analisi in tempo reale | Il livello semantico di Cube.js abilita analisi in tempo reale e visualizzazione dei dati per un’analisi efficiente. |
| MetricFlow | Data modeling, Metrics layer, Caching, API, Trasformazione dei dati | Il livello semantico di MetricFlow supporta un’integrazione fluida con varie fonti dati e fornisce una vista unificata. |
| dbt | Trasformazione dei dati, Metrics layer, Caching, API, Data modeling | Il livello semantico di dbt offre una vista unificata modellando strutture e relazioni dei dati, rendendo più semplice analizzare e visualizzare dati complessi. |
| Tableau | Data visualization, Data modeling, Caching, API | Il livello semantico di Tableau supporta la visualizzazione dei dati così gli utenti possono creare dashboard e report interattivi. |
| Power BI | Data visualization, Data modeling, API, Integrazione dei dati | Le capacità di integrazione dati di Power BI facilitano il collegamento a varie fonti. |
Il livello semantico è un meccanismo di trasformazione per qualsiasi organizzazione che voglia sfruttare i grandi volumi e le molteplici tipologie di dati disponibili al proprio interno. Rende possibili decisioni informate e aumenta l’accessibilità con un approccio unico ai dati.
Naturalmente, insieme arrivano vari svantaggi di implementazione. Aumenta la complessità dei dati e può creare problemi di scalabilità. Tuttavia, i team dati possono gestirli con pianificazione, formazione e buoni strumenti.
Se vuoi capire come valorizzare i dati con strumenti come Power BI, DataCamp offre diverse risorse formative. Il corso Introduction to Power BI fornisce solide basi per chi inizia. Per qualcosa di più approfondito, valuta il percorso professionale completo Data Analyst in Power BI, co-creato con Microsoft.
Infine, se ti interessa integrare tecnologie avanzate, dai un’occhiata al corso Implementing AI Solutions in Business per vedere come incorporare l’AI nei processi aziendali per favorire innovazione ed efficienza.
Impara con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

