
Cursus
Machine Learning met boomgebaseerde modellen in Python
5 Hr
117.2K
Machine learning, vaak afgekort als ML, is een subset van kunstmatige intelligentie (AI) die zich richt op de ontwikkeling van computeralgoritmen die automatisch verbeteren door ervaring en door het gebruik van data. Simpeler gezegd: machine learning stelt computers in staat te leren van data en beslissingen of voorspellingen te doen zonder hiervoor expliciet geprogrammeerd te zijn.
In de kern draait machine learning om het creëren en toepassen van algoritmen die deze beslissingen en voorspellingen mogelijk maken. Deze algoritmen zijn ontworpen om hun prestaties in de loop van de tijd te verbeteren en worden nauwkeuriger en effectiever naarmate ze meer data verwerken.
Bij traditioneel programmeren volgt een computer een set vooraf gedefinieerde instructies om een taak uit te voeren. Bij machine learning krijgt de computer echter een set voorbeelden (data) en een taak, en is het aan de computer om op basis van die voorbeelden uit te vogelen hoe de taak moet worden uitgevoerd.
Als we bijvoorbeeld willen dat een computer katten op afbeeldingen herkent, geven we geen specifieke instructies over hoe een kat eruitziet. In plaats daarvan geven we duizenden afbeeldingen van katten en laten we het machinelearningalgoritme zelf de patronen en kenmerken ontdekken die een kat definiëren. Naarmate het algoritme meer afbeeldingen verwerkt, wordt het beter in het herkennen van katten, zelfs op beelden die het nog nooit eerder heeft gezien.
Dit vermogen om te leren van data en in de tijd te verbeteren, maakt machine learning ongelooflijk krachtig en veelzijdig. Het is de motor achter veel technologische vooruitgang die we vandaag zien, van spraakassistenten en aanbevelingssystemen tot zelfrijdende auto’s en voorspellende analyses.
Machine learning wordt vaak verward met kunstmatige intelligentie of deep learning. Laten we bekijken hoe deze termen van elkaar verschillen. Voor een diepere vergelijking, bekijk onze gidsen over AI vs machine learning en machine learning vs deep learning.
AI verwijst naar de ontwikkeling van programma’s die zich intelligent gedragen en menselijke intelligentie nabootsen via een set algoritmen. Het vakgebied focust op drie vaardigheden: leren, redeneren en zelfcorrectie om maximale efficiëntie te behalen. AI kan zowel verwijzen naar machinelearning-gebaseerde programma’s als naar expliciet geprogrammeerde computerprogramma’s.
Machine learning is een subset van AI en gebruikt algoritmen die leren van data om voorspellingen te doen. Deze voorspellingen kunnen worden gegenereerd via supervised learning, waarbij algoritmen patronen leren uit bestaande data, of via unsupervised learning, waarbij ze algemene patronen in data ontdekken. ML-modellen kunnen numerieke waarden voorspellen op basis van historische data, gebeurtenissen als waar of onwaar classificeren en datapunten clusteren op basis van overeenkomsten.
Deep learning is daarentegen een deelgebied van machine learning dat zich bezighoudt met algoritmen die in essentie gebaseerd zijn op meerlaagse kunstmatige neurale netwerken (ANN), geïnspireerd op de structuur van het menselijk brein.
In tegenstelling tot conventionele machinelearningalgoritmen zijn deep-learningalgoritmen minder lineair, complexer en hiërarchisch, kunnen ze leren van enorme hoeveelheden data en leveren ze zeer nauwkeurige resultaten op. Taalvertaling, beeldherkenning en gepersonaliseerde geneeskunde zijn voorbeelden van toepassingen van deep learning.

Verschillende vaktermen vergeleken
In de 21e eeuw is data het nieuwe olie, en machine learning is de motor die deze datagedreven wereld aandrijft. Het is een cruciale technologie in het digitale tijdperk, en het belang ervan kan niet worden overschat. Dat blijkt ook uit de verwachte groei in de sector: het US Bureau of Labor Statistics voorspelt een banengroei van 26% tussen 2023 en 2033.
Hier zijn een paar redenen waarom het zo essentieel is in de moderne wereld:
Begrijpen hoe machine learning werkt, betekent dat je een stapsgewijs proces induikt dat ruwe data omzet in waardevolle inzichten. Laten we dit proces opdelen:
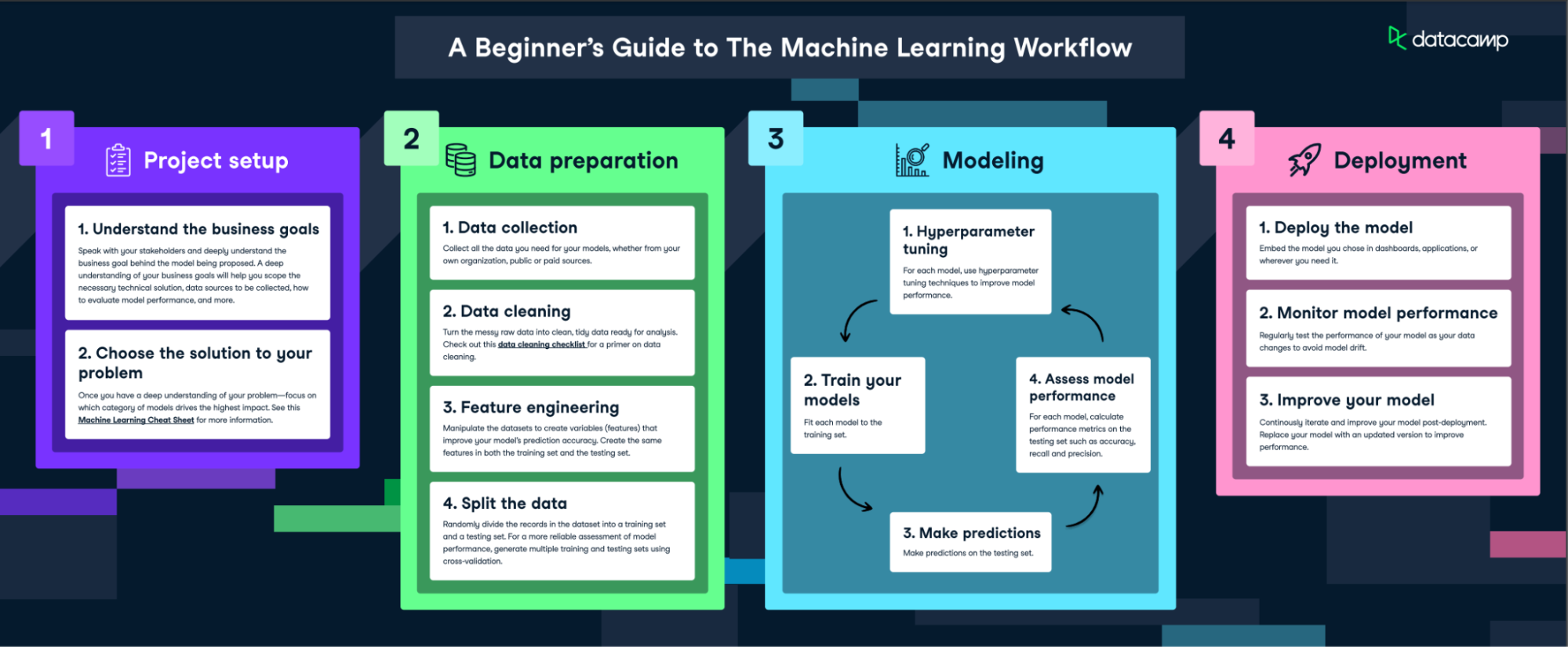
Bekijk hier de volledige workflow
De eerste stap in het machinelearningproces is dataverzameling. Data is de levensader van machine learning: de kwaliteit en kwantiteit van je data hebben direct invloed op de prestaties van je model. Data kan afkomstig zijn uit verschillende bronnen, zoals databases, tekstbestanden, afbeeldingen, audiobestanden of zelfs van het web worden gescraped.
Zodra de data verzameld is, moet deze worden voorbereid voor machine learning. Dit houdt in dat je de data organiseert in een geschikt formaat, zoals een CSV-bestand of database, en dat je zorgt dat de data relevant is voor het probleem dat je wilt oplossen.
Datapreprocessing is een cruciale stap in het machinelearningproces. Het omvat het opschonen van data (duplicaten verwijderen, fouten corrigeren), omgaan met missende waarden (verwijderen of invullen) en het normaliseren van data (schalen naar een standaardformaat).
Preprocessing verbetert de kwaliteit van je data en zorgt dat je model deze correct kan interpreteren. Deze stap kan de nauwkeurigheid van je model aanzienlijk verbeteren. Onze cursus Preprocessing for Machine Learning in Python laat zien hoe je opgeschoonde data klaarstoomt voor modelleren.
Als de data is voorbereid, kies je vervolgens een machinelearningmodel. Er zijn veel typen modellen, zoals lineaire regressie, beslisbomen en neurale netwerken. De keuze hangt af van de aard van je data en het probleem dat je wilt oplossen.
Factoren om te overwegen zijn de grootte en het type data, de complexiteit van het probleem en de beschikbare rekenkracht. Je kunt meer lezen over de verschillende machinelearningmodellen in een apart artikel.
Na het kiezen van een model is de volgende stap trainen met de voorbereide data. Trainen houdt in dat je de data aan het model voert en het zijn interne parameters laat aanpassen om de output beter te voorspellen.
Tijdens het trainen is het belangrijk om overfitting (het model presteert goed op trainingsdata maar slecht op nieuwe data) en underfitting (het model presteert slecht op zowel trainings- als nieuwe data) te vermijden. Meer over het volledige proces leer je in onze skill track Machine Learning Fundamentals with Python, waarin de essentiële concepten en hun toepassing aan bod komen.
Zodra een model is getraind, is het essentieel om de prestaties op onzichtbare data te evalueren voordat je het uitrolt. Met MLOps stopt monitoring niet bij deze eerste fase; het omvat doorlopende evaluatie om modeldrift te detecteren (wanneer de prestaties afnemen door veranderende datapatronen) en om de modelkwaliteit in de tijd te borgen. Continue monitoring en retraining-workflows helpen organisaties hun modellen effectief en betrouwbaar te houden in productie.
Veelgebruikte metrics om de prestaties van een model te evalueren zijn nauwkeurigheid (voor classificatieproblemen), precisie en recall (voor binaire classificatie) en mean squared error (voor regressie). We behandelen dit evaluatieproces uitgebreider in ons Responsible AI-webinar.
Naast het tunen op nauwkeurigheid omvat hyperparameteroptimalisatie binnen een MLOps-pijplijn tools voor geautomatiseerde hyperparameterzoektochten, wat efficiëntie en reproduceerbaarheid waarborgt. Veel teams gebruiken MLOps-platforms die hyperparametertuning ondersteunen, zodat experimenten herhaalbaar en goed gedocumenteerd zijn en consistente optimalisatie in de tijd mogelijk is.
Technieken voor hyperparametertuning zijn onder meer grid search (waarbij je verschillende combinaties van parameters uitprobeert) en cross-validatie (waarbij je je data opdeelt in subsets en je model op elke subset traint om te controleren of het goed presteert op verschillende data).
We hebben een apart artikel over hyperparameteroptimalisatie in machinelearningmodellen dat dit onderwerp uitgebreider behandelt.
Het uitrollen van een machinelearningmodel houdt in dat je het integreert in een productieomgeving, waar het realtime voorspellingen of inzichten kan leveren. MLOps (Machine Learning Operations) is uitgegroeid tot een standaardpraktijk om dit te stroomlijnen. Het omvat versiebeheer, monitoring en geautomatiseerd testen om te zorgen dat modellen reproduceerbaar, betrouwbaar en robuust zijn. MLOps-frameworks zoals MLflow of Kubeflow ondersteunen deze doelen met soepele workflows voor deployment, retraining en modelrollback als er problemen ontstaan.
Ontdek meer over MLOps in een aparte tutorial.
Machine learning kan grofweg in drie typen worden ingedeeld op basis van de aard van het leersysteem en de beschikbare data: supervised learning, unsupervised learning en reinforcement learning. Laten we elk type bekijken:
Supervised learning is het meest voorkomende type machine learning. Hierbij wordt het model getraind op een gelabelde dataset. Met andere woorden: de data gaat vergezeld van een label dat het model probeert te voorspellen. Dit kan variëren van een categorielabel tot een reële waarde.
Het model leert tijdens het trainen een mapping tussen de input (features) en de output (label). Eenmaal getraind kan het model de output voor nieuwe, ongeziene data voorspellen.
Veelvoorkomende voorbeelden van supervised learning-algoritmen zijn lineaire regressie voor regressieproblemen en logistische regressie, beslisbomen en support vector machines voor classificatieproblemen. In de praktijk kan dit eruitzien als een beeldherkenningsproces: met een dataset van afbeeldingen waarbij elke foto gelabeld is als "kat", "hond", enzovoort, kan een supervised model nieuwe afbeeldingen herkennen en correct indelen.
Unsupervised learning daarentegen traint het model op een ongelabelde dataset. Het model moet zelf patronen en relaties in de data ontdekken.
Dit type leren wordt vaak gebruikt voor clusteren en dimensiereductie. Clusteren groepeert vergelijkbare datapunten, terwijl dimensiereductie het aantal te beschouwen variabelen verkleint door een set hoofdvariabelen te bepalen.
Veelvoorkomende voorbeelden van unsupervised learning-algoritmen zijn k-means voor clusterproblemen en Principal Component Analysis (PCA) voor dimensiereductie. In de praktijk wordt in marketing unsupervised learning vaak gebruikt om de klantenbasis van een bedrijf te segmenteren. Door aankoopgedrag, demografische data en andere informatie te onderzoeken, kan het algoritme klanten groeperen in segmenten met vergelijkbaar gedrag, zonder vooraf bestaande labels.
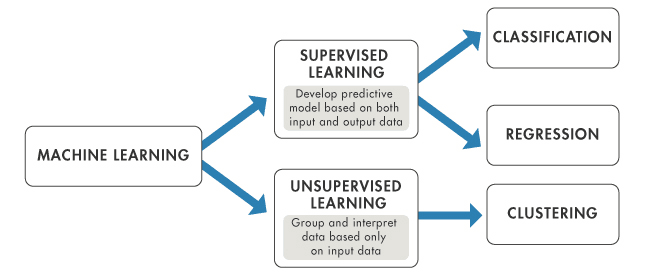
Supervised en unsupervised learning vergeleken
Reinforcement learning is een type machine learning waarbij een agent leert beslissingen te nemen door interactie met zijn omgeving. De agent wordt beloond of bestraft (met punten) voor de acties die hij onderneemt en streeft ernaar de totale beloning te maximaliseren.
In tegenstelling tot supervised en unsupervised learning is reinforcement learning vooral geschikt voor problemen met sequentiële data, waarbij de beslissing op elke stap toekomstige uitkomsten kan beïnvloeden.
Veelvoorkomende voorbeelden van reinforcement learning zijn spelbesturing, robotica, middelenbeheer en meer.
In 2024 is machine learning een drijvende kracht in uiteenlopende domeinen zoals gezondheidszorg, financiën en klimaatwetenschap. Met de opkomst van generatieve AI kunnen marketingteams op schaal gepersonaliseerde content maken, terwijl zorgverleners ML gebruiken voor vroege diagnose en gepersonaliseerde behandeling. Tegelijkertijd focussen toezichthouders steeds meer op ethische standaarden en gegevensprivacy, zodat ML zich verantwoord blijft ontwikkelen.
Laten we enkele van deze impacten verkennen:
“Machine learning is de meest transformerende technologie van onze tijd. Het gaat elke sector veranderen.”
- Satya Nadella, CEO van Microsoft
Machine learning vernieuwt de gezondheidszorg door diagnostische nauwkeurigheid te verbeteren en behandelplannen te personaliseren. Zo helpt Google’s Med-PaLM 2, een groot taalmodel dat is verfijnd voor medische toepassingen, clinici bij het interpreteren van complexe medische informatie, wat de patiëntenzorg verbetert. Lees meer over AI in de gezondheidszorg in onze aparte gids.
In de financiële sector is machine learning onmisbaar voor fraudedetectie en risicobeheer. Grote banken zoals JPMorgan hebben AI-chatbots ontwikkeld om medewerkers in vermogens- en assetmanagement te ondersteunen, waardoor operaties worden gestroomlijnd en klantinteracties worden verbeterd. We hebben een aparte gids over AI in finance die de mogelijkheden uitgebreider verkent.
Machine learning staat centraal in de revolutie rond zelfrijdende auto’s. Bedrijven als Tesla en Waymo gebruiken algoritmen die sensordata in realtime interpreteren, zodat voertuigen objecten herkennen, beslissingen nemen en autonoom navigeren. Evenzo is de Zweedse verkeersadministratie onlangs gaan samenwerken met specialisten in computervisie en machine learning om het beheer van de nationale weginfrastructuur te optimaliseren.
Toepassingen van machine learning zijn overal om ons heen, vaak achter de schermen om ons dagelijks leven te verbeteren. Enkele voorbeelden uit de praktijk:
Aanbevelingssystemen zijn een van de meest zichtbare toepassingen van machine learning. Bedrijven als Netflix en Amazon analyseren je eerdere gedrag en raden producten of films aan die je mogelijk leuk vindt. Leer hoe je een aanbevelingsengine in Python bouwt met onze online cursus.
Spraakassistenten zoals Siri, Alexa en Google Assistant gebruiken machine learning om je spraakopdrachten te begrijpen en relevante antwoorden te geven. Ze leren continu van je interacties om hun prestaties te verbeteren.
Banken en creditcardmaatschappijen gebruiken machine learning om frauduleuze transacties te detecteren. Door patronen in normaal en afwijkend gedrag te analyseren, kunnen ze verdachte activiteiten in realtime markeren. We hebben een cursus fraudedetectie in Python die dit onderwerp uitgebreider verkent.
Sociale mediaplatforms gebruiken machine learning voor uiteenlopende taken, van het personaliseren van je feed tot het filteren van ongepaste content.

Onze machine learning-cheatsheet behandelt verschillende algoritmen en hun toepassingen
In de wereld van machine learning zijn de juiste tools minstens zo belangrijk als de concepten. Deze tools, waaronder programmeertalen en libraries, vormen de bouwstenen om algoritmen te implementeren en uit te rollen. Laten we enkele van de populairste tools verkennen:
Python is populair voor machine learning vanwege de eenvoud en leesbaarheid, wat het een uitstekende keuze maakt voor beginners. Het heeft ook een sterk ecosysteem van libraries die zijn toegespitst op machine learning.
Libraries zoals NumPy en Pandas worden gebruikt voor datamanipulatie en -analyse, terwijl Matplotlib wordt gebruikt voor datavisualisatie. Scikit-learn biedt een breed scala aan machinelearningalgoritmen en TensorFlow en PyTorch worden gebruikt voor het bouwen en trainen van neurale netwerken. PyTorch is vooral populair onder onderzoekers, en het nieuwe PyTorch 2.0 biedt nieuwe functies voor meer snelheid en gebruiksgemak.
Python blijft de dominante taal in machine learning, maar het is het vermelden waard hoe veelzijdig het is in verschillende domeinen met libraries zoals:
R is een andere taal die veel gebruikt wordt in machine learning, vooral voor statistische analyse. Het heeft een rijk ecosysteem aan pakketten die het eenvoudig maken om algoritmen te implementeren.
Pakketten zoals caret, mlr en randomForest bieden uiteenlopende algoritmen, van regressie en classificatie tot clusteren en dimensiereductie.
TensorFlow is een krachtige open-sourcelibrary voor numerieke berekeningen, bijzonder geschikt voor grootschalige machine learning. Het is ontwikkeld door het Google Brain-team en ondersteunt zowel CPU’s als GPU’s.
Met TensorFlow kun je complexe neurale netwerken bouwen en trainen, wat het een populaire keuze maakt voor deep-learningtoepassingen.
Scikit-learn is een Python-library met een breed scala aan algoritmen voor zowel supervised als unsupervised learning. De library staat bekend om de duidelijke API en uitgebreide documentatie.
Scikit-learn wordt vaak gebruikt voor datamining en data-analyse en integreert goed met andere Python-libraries zoals NumPy en Pandas.
Keras is een high-level API voor neurale netwerken, geschreven in Python en in staat om te draaien bovenop TensorFlow, CNTK of Theano. Het is ontwikkeld met het oog op snel experimenteren.
Keras biedt een gebruiksvriendelijke interface voor het bouwen en trainen van neurale netwerken en is daarmee een uitstekende keuze voor beginners in deep learning.
PyTorch is een open-sourcelibrary voor machine learning, gebaseerd op de Torch-library. Het staat bekend om flexibiliteit en efficiëntie en is populair onder onderzoekers.
PyTorch ondersteunt een breed scala aan toepassingen, van computervisie tot natural language processing. Een belangrijke eigenschap is de dynamische computationele graaf, die flexibele en geoptimaliseerde berekeningen mogelijk maakt.
Machine learning heeft een breed scala aan carrièremogelijkheden geopend. Van data science tot AI-engineering: professionals met ML-vaardigheden zijn zeer gewild. Laten we enkele loopbaanpaden verkennen:
Een datascientist gebruikt wetenschappelijke methoden, processen, algoritmen en systemen om kennis en inzichten uit gestructureerde en ongestructureerde data te halen. Machine learning is een belangrijk hulpmiddel in de gereedschapskist van de datascientist, om te kunnen voorspellen en patronen in data te ontdekken.
Belangrijke skills:
Essentiële tools:
Een machinelearningengineer ontwerpt en implementeert machinelearningsystemen. Ze voeren ML-experimenten uit met talen als Python en R, werken met datasets en passen algoritmen en libraries toe.
Belangrijke skills:
Essentiële tools:
Een onderzoekswetenschapper in machine learning doet onderzoek om het vakgebied vooruit te helpen. Ze werken zowel in de academische wereld als in de industrie en ontwikkelen nieuwe algoritmen en technieken.
Belangrijke skills:
Essentiële tools:
|
Carrière |
Belangrijke skills |
Essentiële tools |
|
Datascientist |
Statistische analyse, Programmeren (Python, R), Machine learning, Datavisualisatie, Probleemoplossend vermogen |
Python, R, SQL, Hadoop, Spark, Tableau, |
|
Machinelearningengineer |
Programmeren (Python, Java, R), Machinelearningalgoritmen, Statistiek, Systeemontwerp |
Python, TensorFlow, Scikit-learn, PyTorch, Keras, MLflow, Kubeflow, Docker, Kubernetes |
|
Onderzoekswetenschapper |
Diepgaand begrip van machinelearningalgoritmen, Programmeren (Python, R), Onderzoeksmethodologie, Sterke wiskundige vaardigheden |
Python, R, TensorFlow, PyTorch, MATLAB, Hugging Face Model Hub |
Beginnen met machine learning kan overweldigend lijken, maar met de juiste aanpak en middelen kan iedereen dit spannende vakgebied leren. Enkele stappen om te starten:
Voordat je in machine learning duikt, is een stevige basis in wiskunde (vooral statistiek en lineaire algebra) en programmeren (Python is populair vanwege de eenvoud en beschikbare libraries) belangrijk.
Er zijn veel bronnen om deze basis te leren. Online platforms zoals Khan Academy en Coursera bieden cursussen in wiskunde en programmeren. Boeken als "Think Stats" en "Python Crash Course" zijn ook goede startpunten.
De juiste tools kiezen is cruciaal in machine learning. Python, samen met libraries als NumPy, Pandas en Scikit-learn, is populair vanwege de eenvoud en veelzijdigheid.
Om met deze tools te starten, kun je online tutorials volgen of cursussen volgen op platforms zoals DataCamp. Onze Machine Learning Fundamentals-skill track is de ideale plek om te beginnen.
Als je de basis beheerst, kun je beginnen met het leren van algoritmen. Start met simpele algoritmen zoals lineaire regressie en beslisbomen en ga daarna door naar complexere zoals neurale netwerken.
Werken aan projecten is een geweldige manier om praktijkervaring op te doen en je kennis te versterken. Begin met eenvoudige projecten zoals het voorspellen van huizenprijzen of het classificeren van irissoorten en pak daarna geleidelijk complexere projecten op. We hebben een artikel met 25 machinelearningprojecten voor elk niveau om je te helpen iets passends te vinden.
Machine learning ontwikkelt zich razendsnel, dus het is belangrijk om bij te blijven. Volg relevante blogs, bezoek conferenties en neem deel aan online communities. De DataFramed Podcast en onze webinars en live trainingen zijn een mooie manier om op de hoogte te blijven van trends in de sector.
Van gezondheidszorg en financiën tot vervoer en entertainment: machinelearningalgoritmen drijven innovatie en efficiëntie in uiteenlopende sectoren. Zoals we hebben gezien, vraagt starten met machine learning om een stevige basis in wiskunde en programmeren, een goed begrip van algoritmen en praktijkervaring met projecten.
Of je nu datascientist, machinelearningengineer, AI-specialist of onderzoekswetenschapper wilt worden, er zijn volop kansen in het machinelearningveld. Met de juiste tools en bronnen kan iedereen machine learning leren en bijdragen aan dit spannende domein.
Onthoud: machine learning leren is een reis. Het vakgebied evolueert voortdurend, dus het is belangrijk om bij te blijven met de laatste ontwikkelingen. Volg relevante blogs, ga naar conferenties en doe mee in online communities om te blijven leren en groeien.
Machine learning is niet zomaar een buzzword; het is een krachtig hulpmiddel dat verandert hoe we leven en werken. Door te begrijpen wat machine learning is, hoe het werkt en hoe je begint, zet je de eerste stap naar een toekomst waarin je de kracht van ML kunt inzetten om complexe problemen op te lossen en echt impact te maken.
Begin vandaag nog met machine learning met onze Machine Learning Fundamentals in Python-skill track!
Machine learning-cursussen bij DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
