
Corso
Machine Learning con modelli ad alberi in Python
5 h
117.2K
Il Machine Learning, spesso abbreviato in ML, è un sottoinsieme dell'intelligenza artificiale (AI) che si concentra sullo sviluppo di algoritmi informatici che migliorano automaticamente con l'esperienza e grazie all'uso dei dati. In parole semplici, il machine learning consente ai computer di imparare dai dati e di prendere decisioni o fare previsioni senza essere esplicitamente programmati per farlo.
Alla base, il machine learning riguarda la creazione e l'implementazione di algoritmi che facilitano queste decisioni e previsioni. Questi algoritmi sono progettati per migliorare le proprie prestazioni nel tempo, diventando più accurati ed efficaci man mano che elaborano più dati.
Nella programmazione tradizionale, un computer segue una serie di istruzioni predefinite per eseguire un compito. Nel machine learning, invece, al computer viene fornito un insieme di esempi (dati) e un compito da svolgere, ma sta al computer capire come portarlo a termine sulla base degli esempi ricevuti.
Per esempio, se vogliamo che un computer riconosca immagini di gatti, non gli forniamo istruzioni specifiche su come è fatto un gatto. Invece, gli diamo migliaia di immagini di gatti e lasciamo che l'algoritmo di machine learning individui i pattern e le caratteristiche comuni che definiscono un gatto. Nel tempo, man mano che l'algoritmo elabora più immagini, diventa più bravo a riconoscere i gatti, anche quando vengono presentate immagini mai viste prima.
Questa capacità di imparare dai dati e migliorare nel tempo rende il machine learning incredibilmente potente e versatile. È la forza trainante dietro molti progressi tecnologici che vediamo oggi, dagli assistenti vocali e i sistemi di raccomandazione alle auto a guida autonoma e all'analisi predittiva.
Il machine learning è spesso confuso con l'intelligenza artificiale o il deep learning. Vediamo come questi termini differiscono tra loro. Per un approfondimento, dai un'occhiata alle nostre guide di confronto su AI vs machine learning e machine learning vs deep learning.
AI si riferisce allo sviluppo di programmi che si comportano in modo intelligente e imitano l'intelligenza umana tramite un insieme di algoritmi. Il campo si concentra su tre abilità: apprendimento, ragionamento e autocorrezione per ottenere la massima efficienza. L'AI può riferirsi sia a programmi basati su machine learning sia a programmi per computer esplicitamente programmati.
Machine learning è un sottoinsieme dell'AI che utilizza algoritmi che apprendono dai dati per fare previsioni. Queste previsioni possono essere generate tramite apprendimento supervisionato, in cui gli algoritmi apprendono pattern dai dati esistenti, o apprendimento non supervisionato, in cui scoprono pattern generali nei dati. I modelli ML possono prevedere valori numerici basati su dati storici, classificare eventi come veri o falsi e raggruppare punti dati in base a somiglianze.
Deep learning, invece, è un sotto-campo del machine learning che si occupa di algoritmi basati essenzialmente su reti neurali artificiali (ANN) multistrato ispirate alla struttura del cervello umano.
A differenza degli algoritmi di machine learning convenzionali, gli algoritmi di deep learning sono meno lineari, più complessi e gerarchici, in grado di apprendere da enormi quantità di dati e di produrre risultati altamente accurati. Traduzione linguistica, riconoscimento delle immagini e medicina personalizzata sono alcuni esempi di applicazioni del deep learning.

Confronto tra diversi termini del settore
Nel XXI secolo, i dati sono il nuovo petrolio e il machine learning è il motore che alimenta questo mondo data-driven. È una tecnologia cruciale nell'era digitale di oggi, e la sua importanza non può essere sopravvalutata. Ciò si riflette nella crescita prevista del settore: il Bureau of Labor Statistics degli Stati Uniti prevede una crescita del 26% dei posti di lavoro tra il 2023 e il 2033.
Ecco alcune ragioni per cui è così essenziale nel mondo moderno:
Comprendere come funziona il machine learning significa approfondire un processo passo dopo passo che trasforma i dati grezzi in insight di valore. Scomponiamo questo processo:
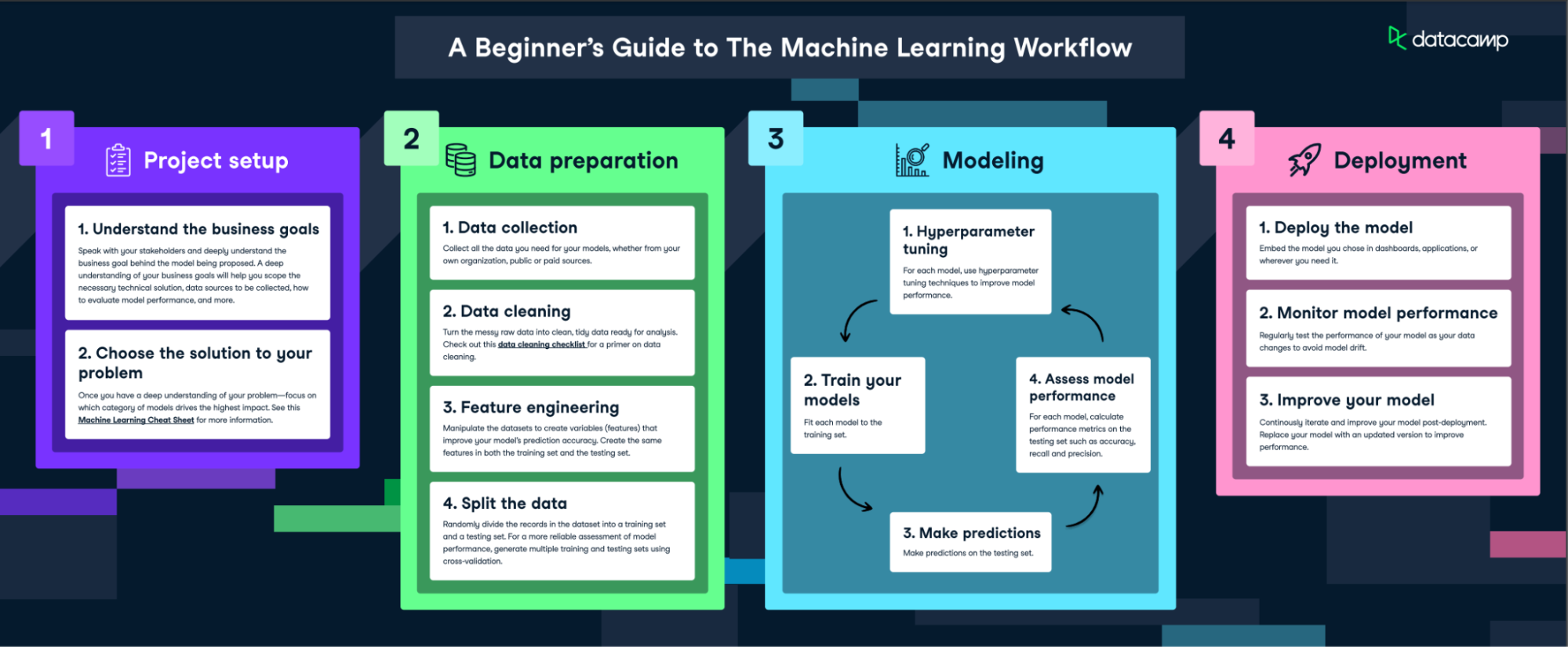
Guarda qui il workflow completo
Il primo passo nel processo di machine learning è la raccolta dei dati. I dati sono il carburante del machine learning: qualità e quantità dei dati possono influire direttamente sulle prestazioni del tuo modello. I dati possono essere raccolti da varie fonti come database, file di testo, immagini, file audio o anche estratti dal web.
Una volta raccolti, i dati devono essere preparati per il machine learning. Questo processo implica organizzare i dati in un formato adatto, come un file CSV o un database, e assicurarsi che siano pertinenti al problema che stai cercando di risolvere.
Il preprocessing dei dati è una fase cruciale nel processo di machine learning. Include la pulizia dei dati (rimozione dei duplicati, correzione degli errori), la gestione dei dati mancanti (rimuovendoli o imputandoli) e la normalizzazione dei dati (scalare i dati a un formato standard).
Il preprocessing migliora la qualità dei tuoi dati e garantisce che il tuo modello di machine learning possa interpretarli correttamente. Questo passaggio può migliorare in modo significativo l'accuratezza del modello. Il nostro corso Preprocessing for Machine Learning in Python esplora come preparare i dati puliti per il modeling.
Una volta preparati i dati, il passo successivo è scegliere un modello di machine learning. Esistono molti tipi di modelli tra cui scegliere, tra cui regressione lineare, alberi decisionali e reti neurali. La scelta del modello dipende dalla natura dei tuoi dati e dal problema che stai cercando di risolvere.
I fattori da considerare nella scelta di un modello includono dimensioni e tipo dei dati, complessità del problema e risorse computazionali disponibili. Puoi leggere di più sui diversi modelli di machine learning in un articolo separato.
Dopo aver scelto un modello, il passo successivo è addestrarlo utilizzando i dati preparati. L'addestramento consiste nel fornire i dati al modello e consentirgli di regolare i propri parametri interni per prevedere meglio l'output.
Durante l'addestramento, è importante evitare l'overfitting (quando il modello va bene sui dati di training ma male su nuovi dati) e l'underfitting (quando il modello va male sia sui dati di training sia su nuovi dati). Puoi approfondire l'intero processo di machine learning nel nostro percorso di competenze Machine Learning Fundamentals with Python, che esplora i concetti essenziali e come applicarli.
Una volta addestrato un modello, è essenziale valutarne le prestazioni su dati non visti prima della messa in produzione. Con l'MLOps, il monitoraggio non si ferma a questa fase iniziale; prevede una valutazione continua per rilevare il model drift (quando le prestazioni del modello calano a causa di cambiamenti nei pattern dei dati) e mantenere la qualità del modello nel tempo. Workflow di monitoraggio e riaddestramento continui aiutano le organizzazioni a garantire che i loro modelli rimangano efficaci e affidabili in ambienti di produzione.
Metriche comuni per valutare le prestazioni di un modello includono accuracy (per problemi di classificazione), precision e recall (per problemi di classificazione binaria) ed errore quadratico medio (per problemi di regressione). Trattiamo questo processo di valutazione più nel dettaglio nel nostro webinar sulla Responsible AI.
Oltre a ottimizzare per l'accuratezza, l'ottimizzazione degli iperparametri all'interno di una pipeline MLOps include strumenti per ricerche automatiche degli iperparametri, garantendo efficienza e riproducibilità. Molti team impiegano piattaforme MLOps che supportano il tuning degli iperparametri, così gli esperimenti sono ripetibili e ben documentati, consentendo un'ottimizzazione coerente nel tempo.
Le tecniche per il tuning degli iperparametri includono la grid search (in cui si provano diverse combinazioni di parametri) e la cross validation (in cui si divide il dataset in sottoinsiemi e si addestra il modello su ciascun sottoinsieme per assicurarsi che si comporti bene su dati diversi).
Abbiamo un articolo dedicato all'ottimizzazione degli iperparametri nei modelli di machine learning, che tratta l'argomento in modo più approfondito.
Mettere in produzione un modello di machine learning significa integrarlo in un ambiente produttivo, dove può fornire previsioni o insight in tempo reale. L'MLOps (Machine Learning Operations) è emerso come pratica standard per snellire questo processo. Comprende controllo di versione, monitoraggio e test automatizzati per garantire che i modelli siano riproducibili, affidabili e robusti. Framework MLOps come MLflow o Kubeflow supportano questi obiettivi fornendo workflow fluidi per deployment, riaddestramento e rollback del modello in caso di problemi.
Scopri di più sull'MLOps in un tutorial separato.
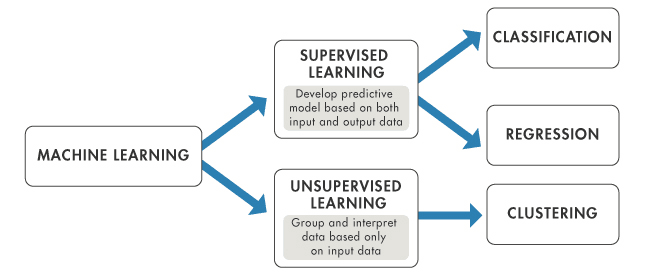
Il machine learning può essere ampiamente classificato in tre tipi in base alla natura del sistema di apprendimento e ai dati disponibili: apprendimento supervisionato, apprendimento non supervisionato e apprendimento per rinforzo. Esploriamoli nel dettaglio:
L'apprendimento supervisionato è il tipo più comune di machine learning. In questo approccio, il modello viene addestrato su un dataset etichettato. In altre parole, i dati sono accompagnati da un'etichetta che il modello cerca di prevedere. Può essere qualsiasi cosa, da una categoria a un numero reale.
Durante l'addestramento, il modello apprende una mappatura tra input (feature) e output (etichetta). Una volta addestrato, può prevedere l'output per nuovi dati mai visti.
Esempi comuni di algoritmi di apprendimento supervisionato includono la regressione lineare per i problemi di regressione e la regressione logistica, gli alberi decisionali e le support vector machine per i problemi di classificazione. In termini pratici, questo può tradursi in un processo di riconoscimento delle immagini: dato un dataset di immagini in cui ogni foto è etichettata come "gatto", "cane", ecc., un modello supervisionato può riconoscere e categorizzare con precisione nuove immagini.
L'apprendimento non supervisionato, invece, prevede l'addestramento del modello su un dataset non etichettato. Il modello deve trovare da solo pattern e relazioni nei dati.
Questo tipo di apprendimento è spesso utilizzato per clustering e riduzione della dimensionalità. Il clustering consiste nel raggruppare insieme punti dati simili, mentre la riduzione della dimensionalità consiste nel ridurre il numero di variabili casuali considerate ottenendo un insieme di variabili principali.
Esempi comuni di algoritmi di apprendimento non supervisionato includono il k-means per problemi di clustering e la Principal Component Analysis (PCA) per problemi di riduzione della dimensionalità. Di nuovo in termini pratici, nel marketing l'apprendimento non supervisionato è spesso utilizzato per segmentare la base clienti di un'azienda. Esaminando modelli di acquisto, dati demografici e altre informazioni, l'algoritmo può raggruppare i clienti in segmenti che mostrano comportamenti simili senza alcuna etichetta preesistente.
Confronto tra apprendimento supervisionato e non supervisionato
L'apprendimento per rinforzo è un tipo di machine learning in cui un agente impara a prendere decisioni interagendo con il proprio ambiente. L'agente viene premiato o penalizzato (con punti) per le azioni che compie e il suo obiettivo è massimizzare il premio totale.
A differenza dell'apprendimento supervisionato e non supervisionato, l'apprendimento per rinforzo è particolarmente adatto a problemi in cui i dati sono sequenziali e la decisione presa a ogni passo può influenzare gli esiti futuri.
Esempi comuni di apprendimento per rinforzo includono giochi, robotica, gestione delle risorse e molto altro.
Nel 2024, il machine learning è un motore chiave in campi diversi come sanità, finanza e scienze del clima. Con l'ascesa della generative AI, i team marketing possono creare contenuti personalizzati su larga scala, mentre i professionisti della sanità usano l'ML per la diagnosi precoce delle malattie e la personalizzazione dei trattamenti. In mezzo a questi progressi, gli enti regolatori si concentrano sempre più su standard etici e privacy dei dati, garantendo che l'ML continui a evolversi in modo responsabile.
Esploriamo alcuni di questi impatti:
«Il machine learning è la tecnologia più trasformativa del nostro tempo. Trasformerà ogni singolo settore.»
- Satya Nadella, CEO di Microsoft
Il machine learning sta rivoluzionando la sanità migliorando l'accuratezza diagnostica e personalizzando i piani di trattamento. Per esempio, Med-PaLM 2 di Google, un large language model ottimizzato per applicazioni mediche, assiste i clinici nell'interpretazione di informazioni mediche complesse, migliorando così l'assistenza ai pazienti. Puoi leggere di più sull'AI in sanità nella nostra guida dedicata.
Nel settore finanziario, il machine learning è fondamentale per il rilevamento delle frodi e la gestione del rischio. Grandi banche come JPMorgan hanno sviluppato chatbot basati su AI per assistere i dipendenti della gestione patrimoniale e degli investimenti, snellendo le operazioni e migliorando le interazioni con i clienti. Abbiamo una guida separata sull'AI in finanza che esplora il potenziale in maggior dettaglio.
Il machine learning è al cuore della rivoluzione delle auto a guida autonoma. Aziende come Tesla e Waymo utilizzano algoritmi di machine learning per interpretare i dati dei sensori in tempo reale, permettendo ai veicoli di riconoscere oggetti, prendere decisioni e percorrere le strade in modo autonomo. Allo stesso modo, l'Amministrazione svedese dei trasporti ha recentemente iniziato a collaborare con specialisti di computer vision e machine learning per ottimizzare la gestione dell'infrastruttura stradale del Paese.
Le applicazioni del machine learning sono ovunque intorno a noi, spesso lavorano dietro le quinte per migliorare la nostra vita quotidiana. Ecco alcuni esempi reali:
I sistemi di raccomandazione sono una delle applicazioni più visibili del machine learning. Aziende come Netflix e Amazon utilizzano il machine learning per analizzare i tuoi comportamenti passati e consigliarti prodotti o film che potrebbero piacerti. Impara a costruire un motore di raccomandazione in Python con il nostro corso online.
Assistenti vocali come Siri, Alexa e Google Assistant usano il machine learning per capire i tuoi comandi vocali e fornire risposte pertinenti. Imparano continuamente dalle tue interazioni per migliorare le loro prestazioni.
Banche e società di carte di credito usano il machine learning per rilevare transazioni fraudolente. Analizzando i pattern di comportamento normale e anomalo, possono segnalare attività sospette in tempo reale. Abbiamo un corso sul rilevamento delle frodi in Python che esplora l'argomento in maggior dettaglio.
Le piattaforme social utilizzano il machine learning per diversi compiti, dalla personalizzazione del feed al filtraggio dei contenuti inappropriati.

La nostra cheat sheet di machine learning copre diversi algoritmi e i loro utilizzi
Nel mondo del machine learning, avere gli strumenti giusti è importante quanto comprendere i concetti. Questi strumenti, che includono linguaggi di programmazione e librerie, forniscono i mattoni per implementare e distribuire algoritmi di machine learning. Esploriamo alcuni degli strumenti più popolari:
Python è un linguaggio popolare per il machine learning grazie alla sua semplicità e leggibilità, che lo rendono una scelta ottima per i principianti. Ha anche un forte ecosistema di librerie pensate per il machine learning.
Librerie come NumPy e Pandas sono utilizzate per la manipolazione e l'analisi dei dati, mentre Matplotlib è usata per la visualizzazione. Scikit-learn offre un'ampia gamma di algoritmi di machine learning, mentre TensorFlow e PyTorch sono utilizzati per costruire e addestrare reti neurali. PyTorch è particolarmente popolare tra i ricercatori e il nuovo PyTorch 2.0 introduce nuove funzionalità per maggiore velocità e facilità d'uso
Python rimane il linguaggio dominante nel machine learning, ma vale la pena sottolinearne la versatilità nei vari campi con librerie come:
R è un altro linguaggio ampiamente utilizzato nel machine learning, in particolare per l'analisi statistica. Ha un ricco ecosistema di pacchetti che facilitano l'implementazione degli algoritmi di machine learning.
Pacchetti come caret, mlr e randomForest offrono una varietà di algoritmi di machine learning, dalla regressione e classificazione al clustering e alla riduzione della dimensionalità.
TensorFlow è una potente libreria open-source per il calcolo numerico, particolarmente adatta al machine learning su larga scala. È stata sviluppata dal team Google Brain e supporta sia CPU che GPU.
TensorFlow ti consente di costruire e addestrare reti neurali complesse, rendendola una scelta popolare per le applicazioni di deep learning.
Scikit-learn è una libreria Python che offre un'ampia gamma di algoritmi di machine learning per apprendimento supervisionato e non supervisionato. È nota per la sua API chiara e la documentazione dettagliata.
Scikit-learn è spesso utilizzata per data mining e analisi dei dati e si integra bene con altre librerie Python come NumPy e Pandas.
Keras è un'API di alto livello per reti neurali, scritta in Python e in grado di funzionare sopra TensorFlow, CNTK o Theano. È stata sviluppata con l'obiettivo di favorire una sperimentazione rapida.
Keras offre un'interfaccia intuitiva per costruire e addestrare reti neurali, rendendola una scelta eccellente per chi inizia con il deep learning.
PyTorch è una libreria open-source di machine learning basata sulla libreria Torch. È nota per la sua flessibilità ed efficienza, che la rendono popolare tra i ricercatori.
PyTorch supporta un'ampia gamma di applicazioni, dalla computer vision all'elaborazione del linguaggio naturale. Una delle sue caratteristiche chiave è il grafo computazionale dinamico, che consente un calcolo flessibile e ottimizzato.
Il machine learning ha aperto un'ampia gamma di opportunità di carriera. Dalla data science all'ingegneria AI, i professionisti con competenze di machine learning sono molto richiesti. Esploriamo alcuni di questi percorsi:
Un data scientist utilizza metodi scientifici, processi, algoritmi e sistemi per estrarre conoscenza e insight da dati strutturati e non strutturati. Il machine learning è uno strumento chiave nell'arsenale di un data scientist, che gli consente di fare previsioni e scoprire pattern nei dati.
Competenze chiave:
Strumenti essenziali:
Un machine learning engineer progetta e implementa sistemi di machine learning. Conduce esperimenti usando linguaggi di programmazione come Python e R, lavora con dataset e applica algoritmi e librerie di machine learning.
Competenze chiave:
Strumenti essenziali:
Un research scientist nel machine learning conduce ricerca per far progredire il campo. Lavora sia in ambito accademico sia industriale, sviluppando nuovi algoritmi e tecniche.
Competenze chiave:
Strumenti essenziali:
|
Carriera |
Competenze chiave |
Strumenti essenziali |
|
Data Scientist |
Analisi statistica, Programmazione (Python, R), Machine learning, Data visualization, Problem solving |
Python, R, SQL, Hadoop, Spark, Tableau, |
|
Machine Learning Engineer |
Programmazione (Python, Java, R), Algoritmi di machine learning, Statistica, Progettazione di sistemi |
Python, TensorFlow, Scikit-learn, PyTorch, Keras, MLflow, Kubeflow, Docker, Kubernetes |
|
Research Scientist |
Profonda comprensione degli algoritmi di machine learning, Programmazione (Python, R), Metodologia della ricerca, Solide competenze matematiche |
Python, R, TensorFlow, PyTorch, MATLAB, Hugging Face Model Hub |
Iniziare un percorso nel machine learning può sembrare impegnativo, ma con l'approccio e le risorse giuste chiunque può imparare questo campo entusiasmante. Ecco alcuni passi per partire:
Prima di tuffarti nel machine learning, è importante avere una solida base in matematica (soprattutto statistica e algebra lineare) e programmazione (Python è una scelta popolare per la sua semplicità e per la disponibilità di librerie di machine learning).
Sono disponibili molte risorse per imparare queste basi. Piattaforme online come Khan Academy e Coursera offrono corsi di matematica e programmazione. Libri come "Think Stats" e "Python Crash Course" sono anche ottimi punti di partenza.
Scegliere gli strumenti giusti è fondamentale nel machine learning. Python, insieme a librerie come NumPy, Pandas e Scikit-learn, è una scelta popolare per la sua semplicità e versatilità.
Per iniziare con questi strumenti, puoi seguire tutorial online o seguire corsi su piattaforme come DataCamp. Il nostro percorso di competenze Machine Learning Fundamentals è il posto ideale da cui cominciare.
Quando ti senti a tuo agio con le basi, puoi iniziare a studiare gli algoritmi di machine learning. Parti da algoritmi semplici come la regressione lineare e gli alberi decisionali prima di passare a quelli più complessi come le reti neurali.
Lavorare su progetti è un ottimo modo per acquisire esperienza pratica e consolidare ciò che hai imparato. Inizia con progetti semplici come prevedere i prezzi delle case o classificare le specie di iris e affronta gradualmente progetti più complessi. Abbiamo un articolo che esplora 25 progetti di machine learning per tutti i livelli, che può aiutarti a trovare qualcosa di adatto.
Il machine learning è un campo in rapida evoluzione, quindi è importante rimanere aggiornato sugli ultimi sviluppi. Seguire blog rilevanti, partecipare a conferenze e a community online può aiutarti a restare informato. Il podcast DataFramed e i nostri webinar e live training sono un ottimo modo per tenere il passo con i trend del settore.
Dalla sanità e finanza ai trasporti e all'intrattenimento, gli algoritmi di machine learning stanno guidando innovazione ed efficienza in vari settori. Come abbiamo visto, iniziare con il machine learning richiede una solida base in matematica e programmazione, una buona comprensione degli algoritmi di machine learning ed esperienza pratica su progetti.
Che tu sia interessato a diventare data scientist, machine learning engineer, specialista AI o research scientist, il campo del machine learning offre un mare di opportunità. Con gli strumenti e le risorse giuste, chiunque può imparare il machine learning e contribuire a questo settore entusiasmante.
Ricorda, imparare il machine learning è un percorso. È un campo in continua evoluzione, quindi è importante rimanere aggiornato sugli ultimi sviluppi. Segui blog rilevanti, partecipa a conferenze e alle community online per continuare a imparare e crescere.
Il machine learning non è solo una parola alla moda: è uno strumento potente che sta cambiando il modo in cui viviamo e lavoriamo. Capendo cos'è il machine learning, come funziona e come iniziare, stai facendo il primo passo verso un futuro in cui puoi sfruttarne la potenza per risolvere problemi complessi e avere un impatto reale.
Inizia oggi con il machine learning con il nostro percorso di competenze Machine Learning Fundamentals in Python!
Corsi di Machine Learning su DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

