Kurs
Maschinelles Lernen mit baumbasierten Modellen in Python
5 Std.
116.4K
Maschinelles Lernen, oft abgekürzt als ML, ist ein Teilbereich der künstlichen Intelligenz (AI), der sich auf die Entwicklung von Computeralgorithmen konzentriert, die sich durch Erfahrung und die Nutzung von Daten automatisch verbessern. Einfacher ausgedrückt: Maschinelles Lernen ermöglicht es Computern, aus Daten zu lernen und Entscheidungen oder Vorhersagen zu treffen, ohne dass sie explizit dafür programmiert wurden.
Im Kern geht es beim maschinellen Lernen um die Entwicklung und Implementierung von Algorithmen, die diese Entscheidungen und Vorhersagen erleichtern. Diese Algorithmen sind so konzipiert, dass sie ihre Leistung im Laufe der Zeit verbessern und immer genauer und effektiver werden, je mehr Daten sie verarbeiten.
Bei der traditionellen Programmierung folgt ein Computer einer Reihe von vordefinierten Anweisungen, um eine Aufgabe zu erfüllen. Beim maschinellen Lernen hingegen erhält der Computer eine Reihe von Beispielen (Daten) und eine Aufgabe, die er erfüllen soll, aber es liegt an ihm, herauszufinden, wie er die Aufgabe auf der Grundlage der ihm gegebenen Beispiele bewältigen kann.
Wenn wir zum Beispiel wollen, dass ein Computer Bilder von Katzen erkennt, geben wir ihm keine genauen Anweisungen, wie eine Katze aussieht. Stattdessen geben wir ihm Tausende von Katzenbildern und lassen den maschinellen Lernalgorithmus die gemeinsamen Muster und Merkmale herausfinden, die eine Katze ausmachen. Im Laufe der Zeit, wenn der Algorithmus mehr Bilder verarbeitet, wird er immer besser darin, Katzen zu erkennen, selbst wenn ihm Bilder vorgelegt werden, die er noch nie gesehen hat.
Diese Fähigkeit, aus Daten zu lernen und sich mit der Zeit zu verbessern, macht maschinelles Lernen unglaublich leistungsfähig und vielseitig. Sie ist die treibende Kraft hinter vielen technologischen Fortschritten, die wir heute erleben, von Sprachassistenten und Empfehlungssystemen bis hin zu selbstfahrenden Autos und prädiktiven Analysen.
Maschinelles Lernen wird oft mit künstlicher Intelligenz oder Deep Learning verwechselt. Schauen wir uns an, wie sich diese Begriffe voneinander unterscheiden. Wenn du einen genaueren Blick darauf werfen willst, sieh dir unsere Vergleiche KI vs. maschinelles Lernen und maschinelles Lernen vs. Deep Learning an.
KI bezieht sich auf die Entwicklung von Programmen, die sich intelligent verhalten und die menschliche Intelligenz durch eine Reihe von Algorithmen nachahmen. Das Feld konzentriert sich auf drei Fähigkeiten: Lernen, Argumentieren und Selbstkorrektur, um maximale Effizienz zu erreichen. KI kann sich entweder auf Programme beziehen, die auf maschinellem Lernen basieren, oder sogar auf explizit programmierte Computerprogramme.
Maschinelles Lernen ist ein Teilbereich der KI, der Algorithmen verwendet, die aus Daten lernen, um Vorhersagen zu treffen. Diese Vorhersagen können durch überwachtes Lernen erstellt werden, bei dem Algorithmen Muster aus vorhandenen Daten lernen, oder durch unüberwachtes Lernen, bei dem sie allgemeine Muster in Daten entdecken. ML-Modelle können numerische Werte auf der Grundlage historischer Daten vorhersagen, Ereignisse als wahr oder falsch kategorisieren und Datenpunkte auf der Grundlage von Gemeinsamkeiten gruppieren.
Deep Learning hingegen ist ein Teilbereich des maschinellen Lernens, der sich mit Algorithmen beschäftigt, die im Wesentlichen auf mehrschichtigen künstlichen neuronalen Netzen (ANN) basieren, die von der Struktur des menschlichen Gehirns inspiriert sind.
Im Gegensatz zu herkömmlichen Algorithmen für maschinelles Lernen sind Deep Learning-Algorithmen weniger linear, komplexer und hierarchischer, sie können aus enormen Datenmengen lernen und sehr genaue Ergebnisse erzielen. Sprachübersetzung, Bilderkennung und personalisierte Medizin sind einige Beispiele für Deep Learning-Anwendungen.

Vergleich verschiedener Branchenbegriffe
Im 21. Jahrhundert sind Daten das neue Öl, und maschinelles Lernen ist der Motor, der diese datengetriebene Welt antreibt. Sie ist eine wichtige Technologie im heutigen digitalen Zeitalter, und ihre Bedeutung kann gar nicht hoch genug eingeschätzt werden. Das spiegelt sich auch im prognostizierten Wachstum der Branche wider: Das US Bureau of Labor Statistics prognostiziert zwischen 2021 und 2031 einen Anstieg der Arbeitsplätze um 21%.
Hier sind einige Gründe, warum sie in der modernen Welt so wichtig ist:
Um zu verstehen, wie maschinelles Lernen funktioniert, musst du einen schrittweisen Prozess durchlaufen, der Rohdaten in wertvolle Erkenntnisse umwandelt. Lasst uns diesen Prozess aufschlüsseln:
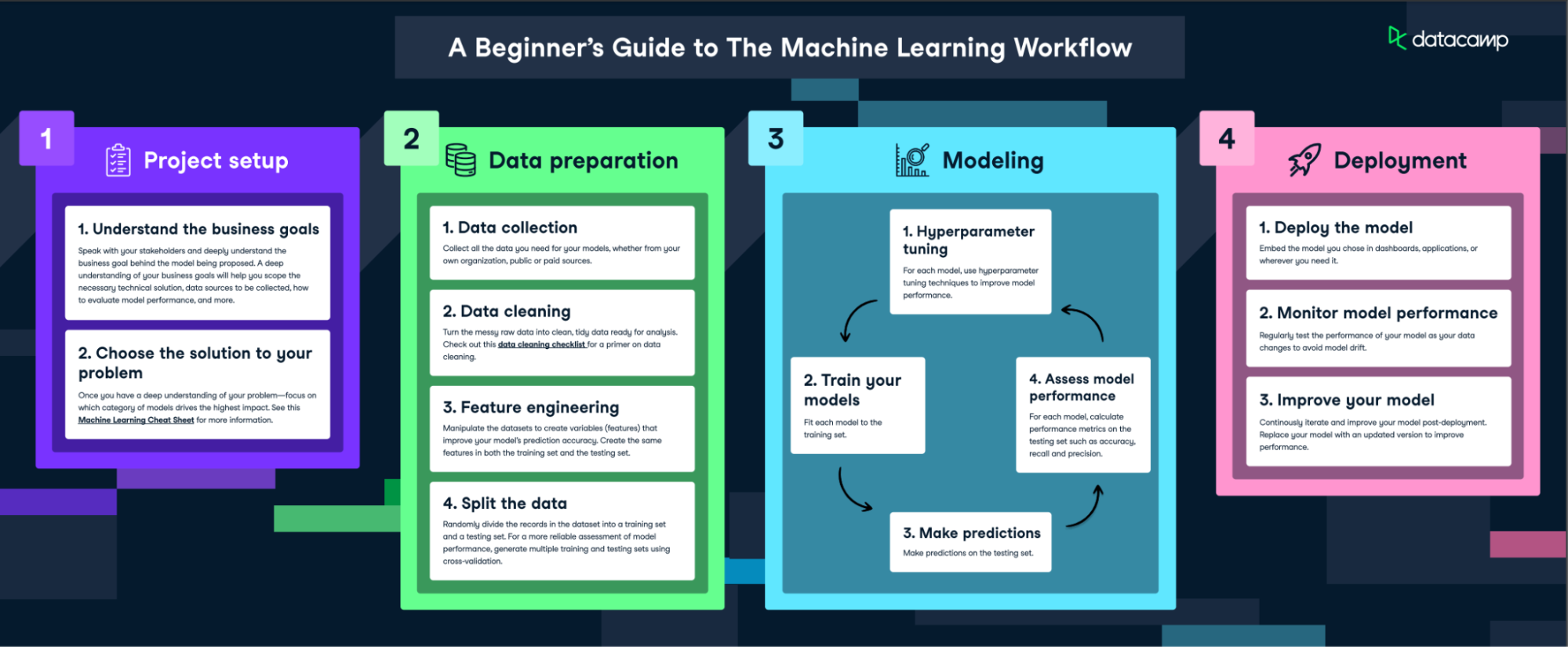
Hier kannst du den gesamten Arbeitsablauf sehen
Der erste Schritt im Prozess des maschinellen Lernens ist die Datensammlung. Daten sind das Lebenselixier des maschinellen Lernens - die Qualität und Quantität deiner Daten kann sich direkt auf die Leistung deines Modells auswirken. Daten können aus verschiedenen Quellen wie Datenbanken, Textdateien, Bildern, Audiodateien oder sogar aus dem Internet gesammelt werden.
Sobald die Daten gesammelt sind, müssen sie für das maschinelle Lernen aufbereitet werden. Dazu müssen die Daten in einem geeigneten Format organisiert werden, z. B. in einer CSV-Datei oder einer Datenbank, und es muss sichergestellt werden, dass die Daten für das Problem, das du zu lösen versuchst, relevant sind.
Die Datenvorverarbeitung ist ein wichtiger Schritt im Prozess des maschinellen Lernens. Dazu gehört das Bereinigen der Daten (Entfernen von Duplikaten, Korrigieren von Fehlern), der Umgang mit fehlenden Daten (entweder durch Entfernen oder Ergänzen) und die Normalisierung der Daten (Skalierung der Daten auf ein Standardformat).
Die Vorverarbeitung verbessert die Qualität deiner Daten und stellt sicher, dass dein maschinelles Lernmodell sie richtig interpretieren kann. Dieser Schritt kann die Genauigkeit deines Modells erheblich verbessern. In unserem Kurs " Vorverarbeitung für maschinelles Lernen in Python" lernst du, wie du deine Daten für die Modellierung vorbereitest.
Sobald die Daten aufbereitet sind, besteht der nächste Schritt darin, ein maschinelles Lernmodell auszuwählen. Es gibt viele verschiedene Modelle zur Auswahl, darunter lineare Regression, Entscheidungsbäume und neuronale Netze. Die Wahl des Modells hängt von der Art deiner Daten und dem Problem ab, das du zu lösen versuchst.
Zu den Faktoren, die du bei der Auswahl eines Modells berücksichtigen solltest, gehören die Größe und Art deiner Daten, die Komplexität des Problems und die verfügbaren Rechenressourcen. Du kannst mehr über die verschiedenen Modelle des maschinellen Lernens in einem separaten Artikel lesen.
Nachdem du ein Modell ausgewählt hast, musst du es mit den vorbereiteten Daten trainieren. Beim Training werden die Daten in das Modell eingespeist, damit es seine internen Parameter anpassen kann, um das Ergebnis besser vorherzusagen.
Beim Training ist es wichtig, eine Überanpassung (wenn das Modell bei den Trainingsdaten gut, bei den neuen Daten aber schlecht abschneidet) und eine Unteranpassung (wenn das Modell sowohl bei den Trainingsdaten als auch bei den neuen Daten schlecht abschneidet) zu vermeiden. Mehr über den gesamten Prozess des maschinellen Lernens erfährst du in unserem Kurs " Grundlagen des maschinellen Lernens mit Python", der sich mit den wichtigsten Konzepten und deren Anwendung beschäftigt.
Sobald das Modell trainiert ist, ist es wichtig, seine Leistung zu bewerten, bevor du es einsetzt. Dabei wird das Modell mit neuen Daten getestet, die es beim Training nicht gesehen hat.
Zu den gängigen Messgrößen für die Bewertung der Leistung eines Modells gehören die Genauigkeit (bei Klassifizierungsproblemen), die Präzision und der Rückruf (bei binären Klassifizierungsproblemen) sowie der mittlere quadratische Fehler (bei Regressionsproblemen). In unserem Webinar über verantwortungsvolle KI gehen wir näher auf diesen Bewertungsprozess ein.
Nach der Auswertung des Modells musst du eventuell die Hyperparameter anpassen, um seine Leistung zu verbessern. Dieser Prozess wird als Parameter-Tuning oder Hyperparameter-Optimierung bezeichnet.
Zu den Techniken für die Abstimmung von Hyperparametern gehören die Rastersuche (bei der du verschiedene Kombinationen von Parametern ausprobierst) und die Kreuzvalidierung (bei der du deine Daten in Teilmengen aufteilst und dein Modell auf jeder Teilmenge trainierst, um sicherzustellen, dass es auf verschiedenen Daten gut funktioniert).
Wir haben einen separaten Artikel über die Optimierung von Hyperparametern in maschinellen Lernmodellen, in dem das Thema ausführlicher behandelt wird.
Sobald das Modell trainiert und optimiert ist, ist es bereit, Vorhersagen für neue Daten zu treffen. Bei diesem Prozess werden neue Daten in das Modell eingespeist und die Ergebnisse des Modells für die Entscheidungsfindung oder weitere Analysen verwendet.
Der Einsatz des Modells bedeutet, dass es in eine Produktionsumgebung integriert wird, in der es reale Daten verarbeiten und Erkenntnisse in Echtzeit liefern kann. Dieser Prozess wird oft als MLOps bezeichnet. Mehr über MLOps erfährst du in einem separaten Lernprogramm.
Maschinelles Lernen lässt sich je nach Art des Lernsystems und der verfügbaren Daten grob in drei Typen einteilen: überwachtes Lernen, unüberwachtes Lernen und Verstärkungslernen. Schauen wir uns die einzelnen Punkte an:
Überwachtes Lernen ist die häufigste Form des maschinellen Lernens. Bei diesem Ansatz wird das Modell auf einem gelabelten Datensatz trainiert. Mit anderen Worten: Die Daten werden von einem Label begleitet, das das Modell vorherzusagen versucht. Das kann alles sein, von einer Kategoriebezeichnung bis hin zu einer reellen Zahl.
Das Modell lernt während des Trainingsprozesses eine Zuordnung zwischen dem Input (Merkmale) und dem Output (Label). Sobald das Modell trainiert ist, kann es den Output für neue, ungesehene Daten vorhersagen.
Gängige Beispiele für überwachte Lernalgorithmen sind die lineare Regression für Regressionsprobleme und die logistische Regression, Entscheidungsbäume und Support Vector Machines für Klassifikationsprobleme. In der Praxis könnte dies wie ein Bilderkennungsverfahren aussehen, bei dem ein Datensatz von Bildern, bei dem jedes Bild als "Katze", "Hund" usw. gekennzeichnet ist, von einem überwachten Modell erkannt und genau kategorisiert werden kann.
Beim unüberwachten Lernen hingegen wird das Modell auf einem unmarkierten Datensatz trainiert. Das Modell muss selbständig Muster und Beziehungen in den Daten finden.
Diese Art des Lernens wird oft für Clustering und Dimensionalitätsreduktion verwendet. Beim Clustering werden ähnliche Datenpunkte gruppiert, während bei der Dimensionalitätsreduktion die Anzahl der betrachteten Zufallsvariablen reduziert wird, indem ein Satz von Hauptvariablen ermittelt wird.
Gängige Beispiele für unüberwachte Lernalgorithmen sind k-means für Clustering-Probleme und die Hauptkomponentenanalyse (PCA) für Probleme der Dimensionalitätsreduktion. In der Praxis wird unüberwachtes Lernen im Bereich Marketing oft dazu verwendet, den Kundenstamm eines Unternehmens zu segmentieren. Durch die Untersuchung von Kaufmustern, demografischen Daten und anderen Informationen kann der Algorithmus Kunden in Segmente einteilen, die ein ähnliches Verhalten zeigen, ohne dass es bereits eine Kennzeichnung gibt.
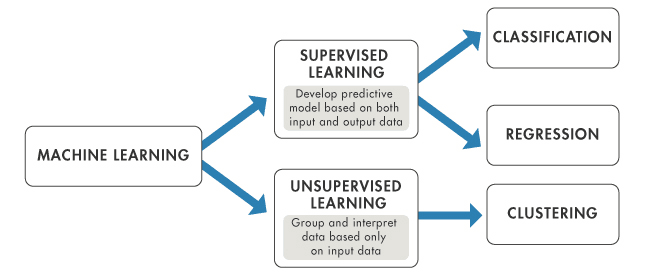
Überwachtes und unüberwachtes Lernen im Vergleich
Verstärkungslernen ist eine Art des maschinellen Lernens, bei dem ein Agent durch Interaktion mit seiner Umgebung lernt, Entscheidungen zu treffen. Der Agent wird für seine Aktionen belohnt oder bestraft (mit Punkten), und sein Ziel ist es, die Gesamtbelohnung zu maximieren.
Im Gegensatz zum überwachten und unüberwachten Lernen eignet sich das verstärkende Lernen besonders für Probleme, bei denen die Daten sequentiell sind und die in jedem Schritt getroffene Entscheidung zukünftige Ergebnisse beeinflussen kann.
Gängige Beispiele für Reinforcement Learning sind Spiele, Robotik, Ressourcenmanagement und viele mehr.
Maschinelles Lernen hat verschiedene Branchen verändert, traditionelle Prozesse revolutioniert und den Weg für Innovationen geebnet. Lass uns einige dieser Auswirkungen untersuchen:
"Maschinelles Lernen ist die transformativste Technologie unserer Zeit. Es wird jede einzelne Vertikale verändern."
- Satya Nadella, CEO von Microsoft
Im Gesundheitswesen wird maschinelles Lernen eingesetzt, um Krankheitsausbrüche vorherzusagen, Behandlungspläne für Patienten zu personalisieren und die Genauigkeit medizinischer Bildgebung zu verbessern. Googles DeepMind Health arbeitet zum Beispiel mit Ärzten zusammen, um maschinelle Lernmodelle zu entwickeln, die Krankheiten früher erkennen und die Patientenversorgung verbessern.
Auch der Finanzsektor hat stark vom maschinellen Lernen profitiert. Es wird für die Kreditwürdigkeitsprüfung, den algorithmischen Handel und die Betrugserkennung verwendet. Eine kürzlich durchgeführte Umfrage ergab, dass 56 % der Führungskräfte weltweit angaben, dass künstliche Intelligenz (KI) und maschinelles Lernen in Compliance-Programme für Finanzkriminalität implementiert wurden.
Maschinelles Lernen ist das Herzstück der Revolution des selbstfahrenden Autos. Unternehmen wie Tesla und Waymo nutzen Algorithmen des maschinellen Lernens, um Sensordaten in Echtzeit zu interpretieren, damit ihre Fahrzeuge Objekte erkennen, Entscheidungen treffen und autonom durch die Straßen navigieren können. Auch die schwedische Verkehrsbehörde arbeitet seit kurzem mit Spezialisten für Computer Vision und maschinelles Lernen zusammen, um die Verwaltung der Straßeninfrastruktur des Landes zu optimieren.
Anwendungen des maschinellen Lernens sind überall um uns herum und arbeiten oft im Verborgenen, um unser tägliches Leben zu verbessern. Hier sind einige Beispiele aus der Praxis:
Empfehlungssysteme sind eine der sichtbarsten Anwendungen des maschinellen Lernens. Unternehmen wie Netflix und Amazon nutzen maschinelles Lernen, um dein bisheriges Verhalten zu analysieren und dir Produkte oder Filme zu empfehlen, die dir gefallen könnten. Lerne in unserem Online-Kurs, wie man eine Empfehlungsmaschine in Python erstellt.
Sprachassistenten wie Siri, Alexa und Google Assistant nutzen maschinelles Lernen, um deine Sprachbefehle zu verstehen und relevante Antworten zu geben. Sie lernen ständig aus deinen Interaktionen, um ihre Leistung zu verbessern.
Banken und Kreditkartenunternehmen nutzen maschinelles Lernen, um betrügerische Transaktionen zu erkennen. Durch die Analyse von normalen und abnormalen Verhaltensmustern können sie verdächtige Aktivitäten in Echtzeit erkennen. Wir haben einen Kurs über Betrugserkennung in Python, in dem wir das Konzept genauer untersuchen.
Social Media-Plattformen nutzen maschinelles Lernen für eine Vielzahl von Aufgaben, von der Personalisierung deines Feeds bis zum Herausfiltern unangemessener Inhalte.

Unser Spickzettel zum maschinellen Lernen behandelt verschiedene Algorithmen und ihre Anwendungen
In der Welt des maschinellen Lernens ist es genauso wichtig, die richtigen Werkzeuge zu haben, wie die Konzepte zu verstehen. Diese Tools, zu denen Programmiersprachen und Bibliotheken gehören, liefern die Bausteine für die Implementierung und den Einsatz von Algorithmen für maschinelles Lernen. Lass uns einige der beliebtesten Tools für maschinelles Lernen kennenlernen:
Python ist aufgrund seiner Einfachheit und Lesbarkeit eine beliebte Sprache für maschinelles Lernen, was sie zu einer guten Wahl für Anfänger macht. Außerdem verfügt es über ein starkes Ökosystem von Bibliotheken, die auf maschinelles Lernen zugeschnitten sind.
Bibliotheken wie NumPy und Pandas werden für die Datenmanipulation und -analyse verwendet, während Matplotlib für die Datenvisualisierung eingesetzt wird. Scikit-learn bietet eine breite Palette von Algorithmen für maschinelles Lernen, und TensorFlow und PyTorch werden für den Aufbau und das Training neuronaler Netze verwendet.
R ist eine weitere Sprache, die im Bereich des maschinellen Lernens weit verbreitet ist, insbesondere für statistische Analysen. Es verfügt über ein reichhaltiges Ökosystem von Paketen, mit denen sich maschinelle Lernalgorithmen leicht implementieren lassen.
Pakete wie caret, mlr und randomForest bieten eine Vielzahl von Algorithmen für maschinelles Lernen, von Regression und Klassifizierung bis hin zu Clustering und Dimensionalitätsreduktion.
TensorFlow ist eine leistungsstarke Open-Source-Bibliothek für numerische Berechnungen, die sich besonders gut für maschinelles Lernen in großem Maßstab eignet. Es wurde vom Google Brain Team entwickelt und unterstützt sowohl CPUs als auch GPUs.
Mit TensorFlow kannst du komplexe neuronale Netze aufbauen und trainieren, was es zu einer beliebten Wahl für Deep Learning-Anwendungen macht.
Scikit-learn ist eine Python-Bibliothek, die eine breite Palette von Algorithmen für maschinelles Lernen bietet, sowohl für überwachtes als auch für unüberwachtes Lernen. Es ist bekannt für seine klare API und seine ausführliche Dokumentation.
Scikit-learn wird häufig für Data Mining und Datenanalyse verwendet und lässt sich gut mit anderen Python-Bibliotheken wie NumPy und Pandas integrieren.
Keras ist eine High-Level-API für neuronale Netze, die in Python geschrieben wurde und auf TensorFlow, CNTK oder Theano aufsetzen kann. Es wurde mit dem Ziel entwickelt, schnelles Experimentieren zu ermöglichen.
Keras bietet eine benutzerfreundliche Oberfläche für den Aufbau und das Training von neuronalen Netzen, was es zu einer guten Wahl für Anfänger im Bereich Deep Learning macht.
PyTorch ist eine Open-Source-Bibliothek für maschinelles Lernen, die auf der Torch-Bibliothek basiert. Sie ist für ihre Flexibilität und Effizienz bekannt, was sie bei Forschern beliebt macht.
PyTorch unterstützt eine breite Palette von Anwendungen, von Computer Vision bis zur Verarbeitung natürlicher Sprache. Eines der wichtigsten Merkmale ist der dynamische Berechnungsgraph, der flexible und optimierte Berechnungen ermöglicht.
Das maschinelle Lernen hat eine breite Palette an Karrieremöglichkeiten eröffnet. Von Data Science bis hin zu KI-Engineering - Fachkräfte mit Kenntnissen im Bereich maschinelles Lernen sind sehr gefragt. Lass uns einige dieser Karrierewege erkunden:
Ein Datenwissenschaftler nutzt wissenschaftliche Methoden, Prozesse, Algorithmen und Systeme, um Wissen und Erkenntnisse aus strukturierten und unstrukturierten Daten zu gewinnen. Maschinelles Lernen ist ein wichtiges Werkzeug im Arsenal eines Datenwissenschaftlers, mit dem er Vorhersagen treffen und Muster in Daten aufdecken kann.
Schlüsselqualifikationen:
Unverzichtbare Werkzeuge:
Ein Ingenieur für maschinelles Lernen entwirft und implementiert Systeme für maschinelles Lernen. Sie führen Experimente zum maschinellen Lernen mit Programmiersprachen wie Python und R durch, arbeiten mit Datensätzen und wenden Algorithmen und Bibliotheken zum maschinellen Lernen an.
Schlüsselqualifikationen:
Unverzichtbare Werkzeuge:
Ein Forscher im Bereich maschinelles Lernen betreibt Forschung, um das Feld des maschinellen Lernens voranzubringen. Sie arbeiten sowohl im akademischen als auch im industriellen Umfeld und entwickeln neue Algorithmen und Techniken.
Schlüsselqualifikationen:
Unverzichtbare Werkzeuge:
|
Karriere |
Schlüsselqualifikationen |
Unverzichtbare Werkzeuge |
|
Datenwissenschaftler/in |
Statistische Analyse, Programmierung (Python, R), Maschinelles Lernen, Datenvisualisierung, Problemlösung |
Python, R, SQL, Hadoop, Spark, Tableau |
|
Ingenieur für maschinelles Lernen |
Programmierung (Python, Java, R), Algorithmen für maschinelles Lernen, Statistik, Systemdesign |
Python, TensorFlow, Scikit-learn, PyTorch, Keras |
|
Forschungswissenschaftler |
Tiefes Verständnis von Algorithmen des maschinellen Lernens, Programmierung (Python, R), Forschungsmethodik, starke mathematische Fähigkeiten |
Python, R, TensorFlow, PyTorch, MATLAB |
Der Einstieg in das maschinelle Lernen kann entmutigend erscheinen, aber mit der richtigen Herangehensweise und den richtigen Ressourcen kann jeder dieses spannende Feld erlernen. Hier sind einige Schritte, die dir den Einstieg erleichtern:
Bevor du dich mit maschinellem Lernen beschäftigst, solltest du eine solide Grundlage in Mathematik (insbesondere Statistik und lineare Algebra) und Programmierung haben (Python ist aufgrund seiner Einfachheit und der Verfügbarkeit von Bibliotheken für maschinelles Lernen eine beliebte Wahl).
Es gibt viele Ressourcen, um diese Grundlagen zu lernen. Online-Plattformen wie Khan Academy und Coursera bieten Kurse in Mathematik und Programmierung an. Bücher wie "Think Stats" und "Python Crash Course" sind ebenfalls gute Ausgangspunkte.
Die Wahl der richtigen Werkzeuge ist beim maschinellen Lernen entscheidend. Python und Bibliotheken wie NumPy, Pandas und Scikit-learn sind aufgrund ihrer Einfachheit und Vielseitigkeit eine beliebte Wahl.
Um den Einstieg in diese Tools zu finden, kannst du Online-Tutorials folgen oder Kurse auf Plattformen wie DataCamp besuchen. Unser Machine Learning Fundamentals Skills Track ist der ideale Einstieg.
Sobald du mit den Grundlagen vertraut bist, kannst du anfangen, dich mit den Algorithmen des maschinellen Lernens zu beschäftigen. Beginne mit einfachen Algorithmen wie der linearen Regression und Entscheidungsbäumen, bevor du zu komplexeren Algorithmen wie neuronalen Netzen übergehst.
Die Arbeit an Projekten ist eine gute Möglichkeit, praktische Erfahrungen zu sammeln und das Gelernte zu vertiefen. Beginne mit einfachen Projekten wie der Vorhersage von Hauspreisen oder der Klassifizierung von Irisarten und nimm nach und nach komplexere Projekte in Angriff. Wir haben einen Artikel über 25 Projekte zum maschinellen Lernen für alle Niveaus, der dir helfen kann, etwas Passendes zu finden.
Maschinelles Lernen ist ein sich schnell entwickelndes Feld, deshalb ist es wichtig, mit den neuesten Entwicklungen Schritt zu halten. Wenn du relevante Blogs verfolgst, Konferenzen besuchst und an Online-Communities teilnimmst, kannst du dich auf dem Laufenden halten. Der DataFramed-Podcast und unsere Webinare und Live-Schulungen sind eine gute Möglichkeit, um über aktuelle Themen in der Branche auf dem Laufenden zu bleiben.
Vom Gesundheitswesen über das Finanzwesen bis hin zum Transportwesen und der Unterhaltung treiben Algorithmen des maschinellen Lernens Innovationen und Effizienz in verschiedenen Sektoren voran. Wie wir gesehen haben, braucht man für den Einstieg in das maschinelle Lernen eine solide Grundlage in Mathematik und Programmierung, ein gutes Verständnis der Algorithmen des maschinellen Lernens und praktische Erfahrung bei der Arbeit an Projekten.
Egal, ob du Datenwissenschaftler/in, Ingenieur/in für maschinelles Lernen, KI-Spezialist/in oder Forscher/in werden möchtest, es gibt eine Vielzahl von Möglichkeiten im Bereich des maschinellen Lernens. Mit den richtigen Tools und Ressourcen kann jeder das maschinelle Lernen erlernen und einen Beitrag zu diesem spannenden Feld leisten.
Denke daran, dass das Erlernen von maschinellem Lernen eine Reise ist. Es ist ein Bereich, der sich ständig weiterentwickelt, deshalb ist es wichtig, mit den neuesten Entwicklungen Schritt zu halten. Verfolge relevante Blogs, besuche Konferenzen und nimm an Online-Communities teil, um weiter zu lernen und zu wachsen.
Maschinelles Lernen ist nicht nur ein Schlagwort - es ist ein mächtiges Werkzeug, das die Art und Weise, wie wir leben und arbeiten, verändert. Wenn du verstehst, was maschinelles Lernen ist, wie es funktioniert und wie du einsteigst, machst du den ersten Schritt in eine Zukunft, in der du die Macht des maschinellen Lernens nutzen kannst, um komplexe Probleme zu lösen und etwas zu bewirken.
Kurse zum maschinellen Lernen bei DataCamp
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko

