
Cursus
Gegevens manipuleren in SQL
4 Hr
328.2K
In het SQL-universum is de mogelijkheid om data uit meerdere queries te combineren een basisvereiste. SQL biedt hiervoor krachtige functies zoals UNION en UNION ALL.
Zoals je zult zien, is het begrijpen van de subtiele verschillen tussen UNION en UNION ALL essentieel voor efficiënte dataquery’s en -beheer. Deze tutorial legt hun belangrijkste overeenkomsten, verschillen en gebruiksscenario’s uit met voorbeelddatasets, zodat je je SQL-queries kunt optimaliseren.
Het belangrijkste verschil is dat UNION dubbele records verwijdert, terwijl UNION ALL alle duplicaten behoudt. Dit beïnvloedt niet alleen het aantal rijen in het queryresultaat, maar ook de performance.
| Eigenschap | UNION | UNION ALL |
|---|---|---|
| Duplicaten | Verwijdert dubbele records | Behoudt alle records (inclusief duplicaten) |
| Performance | Trager (moet data sorteren/hashen om duplicaten te vinden) | Sneller (voegt data simpelweg toe aan het resultaat) |
| Bewerking | Verzamelingenleer (wiskundige unie) | Aan elkaar plakken / stapelen van resultaten |
Laten we twee voorbeeldtabellen bekijken, employees_2023 en employees_2024, die personeelsgegevens voor twee verschillende jaren weergeven.
SELECT *
FROM employees_2023|
employee_id |
name |
department |
|
1 |
Alice |
HR |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finance |
SELECT *
FROM employees_2024|
employee_id |
name |
department |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finance |
|
4 |
David |
Marketing |
Laten we onze twee tabellen nu samenvoegen met de functie UNION.
SELECT employee_id, name, department FROM employees_2023
UNION
SELECT employee_id, name, department FROM employees_2024;|
employee_id |
name |
department |
|
1 |
Alice |
HR |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finance |
|
4 |
David |
Marketing |
In dit resultaat zijn dubbele records verwijderd. Vergelijken we dit met het resultaat na gebruik van UNION ALL.
SELECT employee_id, name, department FROM employees_2023
UNION ALL
SELECT employee_id, name, department FROM employees_2024;|
employee_id |
name |
department |
|
1 |
Alive |
HR |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finance |
|
2 |
Bob |
IT |
|
3 |
Charlie |
Finance |
|
4 |
David |
Marketing |
In dit resultaat zijn alle records opgenomen, en duplicaten worden niet verwijderd.
De functie UNION combineert de resultaten van twee of meer SELECT-queries tot één resultaatset en verwijdert dubbele rijen. Elke SELECT-instructie binnen de UNION moet hetzelfde aantal kolommen hebben. Ook moeten de datatypen vergelijkbaar zijn en moeten de kolommen in dezelfde volgorde staan. Om de functie te begrijpen, maken we hieronder twee voorbeeldtabellen.
CREATE TABLE sales_team (
employee_id INT,
employee_name VARCHAR(50)
);
INSERT INTO sales_team (employee_id, employee_name) VALUES
(1, 'Alice'),
(2, 'Bob'),
(3, 'Charlie');
CREATE TABLE support_team (
employee_id INT,
employee_name VARCHAR(50)
);
INSERT INTO support_team (employee_id, employee_name) VALUES
(3, 'Charlie'),
(4, 'David'),
(5, 'Eve');Met bovenstaande code worden de twee tabellen gemaakt die we in deze tutorial gebruiken: sales_team en support_team. Je kunt de tabellen bekijken met de onderstaande code.
SELECT *
FROM sales_team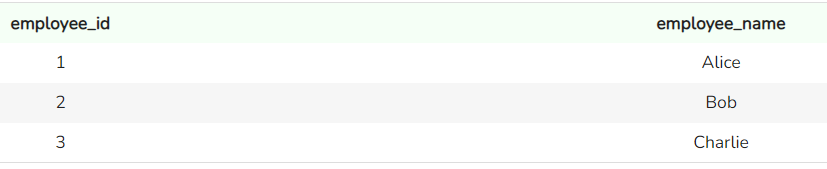
Records in de tabel sales_team. Afbeelding door de auteur
SELECT *
FROM support_team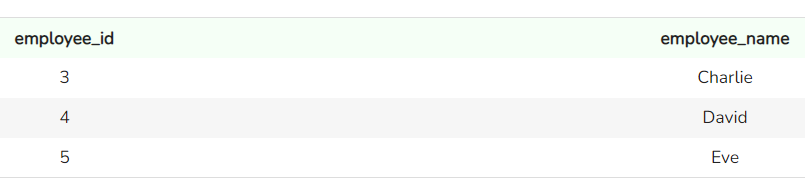
Records in de tabel support_team. Afbeelding door de auteur
Dit zijn kleine tabellen met elk drie records, en de kolomnamen spreken voor zich. Nu we onze twee tabellen hebben, passen we de functie UNION toe.
SELECT employee_id, employee_name
FROM sales_team
UNION
SELECT employee_id, employee_name
FROM support_team;
Output van de functie UNION. Afbeelding door de auteur
Je ziet dat de dubbele invoer van employee_id met de waarde 3 is verwijderd.
Hier zijn enkele veelvoorkomende use-cases voor de functie UNION.
Resultaten uit verschillende tabellen combineren: Wanneer je data uit meerdere tabellen wilt combineren en zeker wilt zijn dat er geen dubbele records zijn, is UNION de aangewezen functie.
Met verschillende databronnen werken: UNION is handig bij het combineren van tabellen uit verschillende bronnen.
Duplicaten over queries heen verwijderen: Gebruik UNION wanneer je de uniciteit van de gecombineerde resultaatset wilt garanderen.
De functie UNION ALL combineert de resultaten van twee of meer SELECT-queries en neemt alle dubbele rijen op. Deze functie is sneller dan UNION omdat er geen duplicaten worden verwijderd.
SELECT employee_id, employee_name
FROM sales_team
UNION ALL
SELECT employee_id, employee_name
FROM support_team;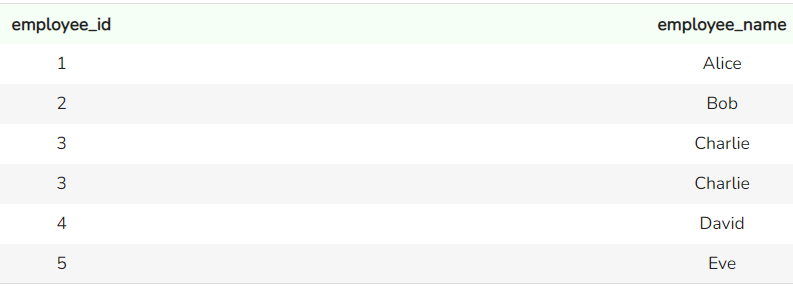
Output van de functie UNION ALL. Afbeelding door de auteur
Je ziet dat in dit geval de dubbele waarden herhaald worden en niet worden verwijderd.
Hier zijn enkele veelvoorkomende use-cases voor de functie UNION ALL.
UNION ALL wanneer je resultaten uit meerdere queries wilt combineren en alle duplicaten wilt behouden.UNION ALL is efficiënter in tijd dan de functie UNION, omdat de extra stap om duplicaten te verwijderen niet nodig is.UNION ALL de voorkeur.UNION ALL geschikt.Laten we een samenvattingstabel maken van de overeenkomsten en verschillen.
|
Eigenschap |
UNION |
UNION ALL |
|
Dubbele rijen |
Verwijderd |
Opgenomen |
|
Performance |
Trager |
Sneller |
|
Use-case |
Wanneer je unieke records nodig hebt |
Wanneer je alle records nodig hebt |
|
Resultaatgrootte |
Kleiner |
Groter |
Hoewel de basis-syntax hetzelfde blijft tussen verschillende SQL-dialecten, zijn er kleine variaties per platform. In de meeste platforms, zoals SQL Server, Oracle, MySQL, PostgreSQL of BigQuery, ziet de code er grotendeels uit zoals hieronder.
SELECT employee_id, employee_name
FROM sales_team
UNION ALL
SELECT employee_id, employee_name
FROM support_team;De basiscommando’s in deze SQL-dialecten blijven gelijk, met enkele nuances en verschillen:
NULL-waarden en tekenreeks-collatie.UNION en UNION ALL kunt gebruiken voor complexere scenario’s.Het commando is aanzienlijk anders in het geval van PySpark, dat in een gedistribueerde omgeving werkt. De code staat hieronder, ervan uitgaande dat df1 en df2 de namen zijn van de twee dataframes met de tabellen die we hierboven hebben gemaakt:
df1.union(df2)Hoewel UNION en UNION ALL krachtig zijn, zijn ze strikt qua syntax. Als je query een fout geeft, overtreedt hij waarschijnlijk een van deze drie gouden regels.
De meest voorkomende fout is een mismatch in het aantal kolommen. Om twee datasets te combineren, moet de “vorm” van de tabellen identiek zijn. Je kunt geen tabel met 3 kolommen boven op een tabel met 2 kolommen stapelen.
De fout:
-- This will fail because the column counts do not match
SELECT employee_id, name, department
FROM employees_2023
UNION
SELECT employee_id, name
FROM employees_2024;De oplossing: Zorg dat beide SELECT-instructies exact hetzelfde aantal kolommen opvragen. Als in de tweede tabel data ontbreekt (zoals department), kun je NULL selecteren als placeholder om de aantallen gelijk te maken:
SELECT employee_id, name, department FROM employees_2023
UNION
SELECT employee_id, name, NULL as department FROM employees_2024;SQL combineert resultaten op basis van positie, niet op kolomnaam. Het datatype van de eerste kolom in je eerste query moet overeenkomen (of compatibel zijn) met het datatype van de eerste kolom in je tweede query.
De fout: Als je per ongeluk de volgorde van kolommen verwisselt, probeert SQL een getal (ID) op een tekenreeks (Naam) te stapelen, wat een conversiefout veroorzaakt.
-- This fails because Column 1 (ID - INT) cannot combine with Column 1 (Name - VARCHAR)
SELECT employee_id, name FROM employees_2023
UNION
SELECT name, employee_id FROM employees_2024;De oplossing: Controleer altijd dat je kolommen in exact dezelfde volgorde staan in elke SELECT-instructie binnen de UNION.
Een veelvoorkomende bron van verwarring is waar je de ORDER BY-clausule plaatst. Je kunt de individuele subqueries binnen een UNION-bewerking niet sorteren; je kunt alleen het uiteindelijke gecombineerde resultaat sorteren.
De fout: Het gebruik van ORDER BY vóór de laatste query levert een syntaxfout op.
-- INCORRECT SYNTAX
SELECT employee_id, name FROM employees_2023
ORDER BY employee_id -- You cannot sort here!
UNION
SELECT employee_id, name FROM employees_2024;De oplossing: Plaats de ORDER BY-clausule helemaal aan het einde van je query. Zo pas je de sortering toe op de volledige gecombineerde resultaatset.
-- CORRECT SYNTAX
SELECT employee_id, name FROM employees_2023
UNION
SELECT employee_id, name FROM employees_2024
ORDER BY employee_id; -- Sorts the final resultHet is belangrijk om het verschil in toepassing tussen UNION en UNION ALL te begrijpen voor efficiënt databeheer met SQL. Waar UNION alleen unieke records selecteert, selecteert UNION ALL ze allemaal, wat impact heeft op performance en de grootte van de resultaatset. Gebruik deze kennis om de juiste functie te kiezen voor jouw specifieke behoeften.
Wil je verder leren? Bekijk dan deze bronnen:
Leer SQL met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
