Programa
Fundamentos da IA
10 h
Se você tem acompanhado o mundo da tecnologia, já deve ter ouvido o termo "Large Language Models (LLMs)" sendo usado por aí. Os LLMs são atualmente o termo tecnológico mais popular, e sua importância no mundo da inteligência artificial (IA) está se tornando maior a cada dia. Os LLMs continuam a alimentar a revolução da IA generativa, pois esses modelos aprendem a processar idiomas humanos, como o ChatGPT e o Bard.
Os LLMs se tornaram um participante importante no mercado em evolução atual devido à sua capacidade de espelhar conversas humanas por meio de seus sistemas detalhados de processamento de linguagem natural (NLP). Naturalmente, tudo tem suas limitações, e os assistentes com tecnologia de IA têm seus desafios específicos.
Esse desafio único é o potencial de viés do LLM, que está arraigado nos dados usados para treinar os modelos.
Vamos dar um passo atrás. O que são LLMs?
Os LLMs são sistemas de IA, como o ChatGPT, que são usados para modelar e processar a linguagem humana. É um tipo de algoritmo de IA que usa técnicas de aprendizagem profunda para resumir, gerar e prever novos conteúdos. O motivo pelo qual eles são chamados de "grandes" é que o modelo requer milhões ou até bilhões de parâmetros, que são usados para treinar o modelo usando um corpus "grande" de dados de texto.
Os LLMs e a PNL trabalham lado a lado, pois têm como objetivo ter uma alta compreensão da linguagem humana e de seus padrões e aprender conhecimentos usando grandes conjuntos de dados.
Se você é um novato no mundo dos LLMs, o artigo a seguir é recomendado para que você se familiarize com o assunto:
O que é um LLM? Um guia sobre modelos de idiomas grandes e como eles funcionam. Ou faça nosso Curso de Conceitos de Modelos de Linguagem Grande (LLMs), que também é perfeito para aprender sobre LLMs.
Os LLMs têm sido amplamente utilizados em diferentes tipos de aplicativos de IA. Eles estão se tornando mais populares a cada dia, e as empresas estão buscando diferentes maneiras de integrá-los aos seus sistemas e ferramentas atuais para melhorar a produtividade do fluxo de trabalho.
Os LLMs podem ser usados nos seguintes casos de uso:
Os LLMs usam modelos Transformer, uma arquitetura de aprendizagem profunda que aprende o contexto e compreende por meio da análise de dados sequenciais.
A tokenização é quando o texto de entrada é dividido em unidades menores chamadas tokens para que o modelo processe e analise por meio de equações matemáticas para descobrir as relações entre os diferentes tokens. O processo matemático consiste em adotar uma abordagem probabilística para prever a próxima sequência de palavras durante a fase de treinamento do modelo.
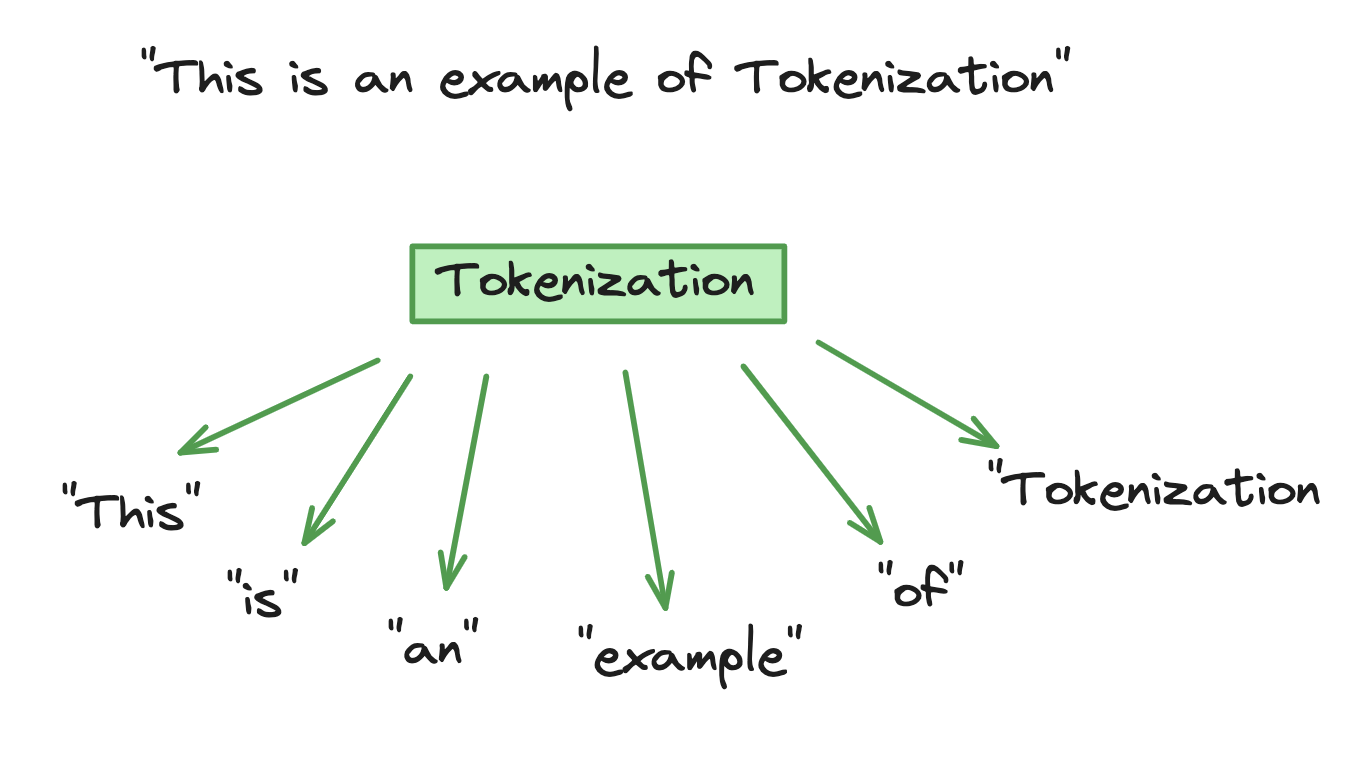
Exemplo de tokenização
A fase de treinamento consiste em inserir o modelo com conjuntos massivos de dados de texto para ajudar o modelo a entender vários contextos, nuances e estilos linguísticos. Os LLMs criarão uma base de conhecimento na qual poderão imitar efetivamente a linguagem humana.
A versatilidade e a compreensão de idiomas que os LLMs possuem é uma prova de sua capacidade avançada de IA. O treinamento em conjuntos de dados extensos de vários gêneros e estilos, como documentos jurídicos e narrativas ficcionais, proporcionou aos LLMs a capacidade de se adaptar a diferentes cenários e contextos.
No entanto, a versatilidade dos LLMs vai além da previsão de texto. Ser capaz de lidar com tarefas em diferentes idiomas, diferentes contextos e diferentes resultados é um tipo de versatilidade que é demonstrada em uma variedade de aplicativos de adaptabilidade, como o atendimento ao cliente. Isso se deve ao treinamento extensivo em grandes conjuntos de dados específicos e ao processo de ajuste fino, que aumentou sua eficácia em diversos campos.
No entanto, devemos nos lembrar do desafio único do LLM: o preconceito.
Como sabemos, os LLMs são treinados em uma variedade de dados de texto de várias fontes. Quando os dados são inseridos no modelo, ele usa esses dados como sua única base de conhecimento e os interpreta como factuais. No entanto, os dados podem estar enraizados em preconceitos e informações incorretas, o que pode fazer com que os resultados do LLM reflitam preconceitos.
Uma ferramenta conhecida por aumentar a produtividade e ajudar nas tarefas cotidianas está mostrando áreas de preocupação ética. Você pode saber mais sobre a ética da IA em nosso curso.
Quanto mais dados você tiver, melhor. Se os dados de treinamento usados para LLMs contiverem amostras não representativas ou vieses, naturalmente, o modelo herdará e aprenderá esses vieses. Exemplos de preconceito no LLM são os preconceitos de gênero, raça e cultura.
Por exemplo, os LLMs podem ser tendenciosos em relação aos gêneros se a maioria de seus dados mostrar que as mulheres trabalham predominantemente como faxineiras ou enfermeiras, e os homens são tipicamente engenheiros ou CEOs. O LLM herdou os estereótipos da sociedade devido aos dados de treinamento que estão sendo inseridos nele. Outro exemplo é o preconceito racial, no qual os LLMs podem refletir determinados grupos étnicos entre estereótipos, bem como o preconceito cultural de super-representação para se adequar ao estereótipo.
As duas principais origens dos vieses nos LLMs são:
Embora os LLMs sejam muito versáteis, esse desafio mostra como o modelo é menos eficaz quando se trata de conteúdo multicultural. A preocupação com relação aos LLMs e vieses se resume ao uso de LLMs no processo de tomada de decisão, o que naturalmente levanta preocupações éticas.
Os impactos do preconceito nos LLMs afetam tanto os usuários do modelo quanto a sociedade em geral.
Como mencionamos acima, há diferentes tipos de estereótipos, como cultura e gênero. Os preconceitos nos dados de treinamento dos LLMs continuam a reforçar esses estereótipos prejudiciais, fazendo com que a sociedade permaneça no ciclo do preconceito e impedindo efetivamente o progresso da sociedade.
Se os LLMs continuarem a digerir dados tendenciosos, eles continuarão a promover a divisão cultural e a desigualdade de gênero.
Discriminação é o tratamento prejudicial de diferentes categorias de pessoas com base em seu sexo, etnia, idade ou deficiência. Os dados de treinamento podem ser altamente sub-representados, o que significa que os dados não mostram uma representação verdadeira de diferentes grupos.
Os resultados dos LLMs que contêm respostas tendenciosas que continuam a conservar e manter a discriminação racial, de gênero e de idade ajudam a causar um impacto negativo na vida diária das pessoas de comunidades marginalizadas, como o processo de recrutamento e contratação e as oportunidades de educação. Isso leva a uma falta de diversidade e inclusão nos resultados dos LLMs, levantando preocupações éticas, pois esses resultados podem ser usados posteriormente no processo de tomada de decisões.
Se houver preocupações de que os dados de treinamento usados para LLMs contenham amostras não representativas ou vieses, isso também levanta a questão de saber se os dados contêm as informações corretas. A disseminação de informações errôneas ou desinformações por meio de LLMs pode ter efeitos consequentes.
Por exemplo, no departamento de saúde, o uso de LLMs que contêm informações tendenciosas pode levar a decisões de saúde perigosas. Outro exemplo são os LLMs que contêm dados politicamente tendenciosos e promovem essa narrativa que pode levar à desinformação política.
As preocupações éticas em relação aos LLMs não são o principal motivo pelo qual parte da sociedade não aceitou bem a implementação de sistemas de IA em nossa vida cotidiana. Algumas ou muitas pessoas estão preocupadas com o uso de sistemas de IA e como eles afetarão nossa sociedade, por exemplo, a perda de empregos e a instabilidade econômica.
Já existe uma falta de confiança quando se trata de sistemas de IA. Portanto, o viés produzido pelos LLMs pode diminuir completamente qualquer confiança que a sociedade tenha nos sistemas de IA em geral. Para que a tecnologia LLM seja aceita com segurança, a sociedade precisa confiar nela.
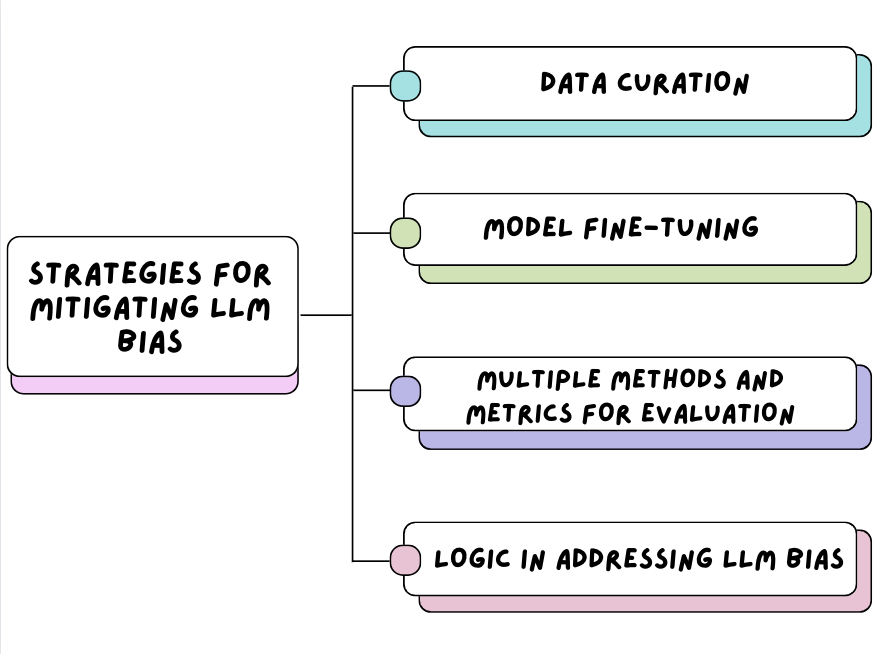
Estratégias para atenuar o preconceito em relação ao LLM
Vamos começar do início, com os dados envolvidos. As empresas precisam ser altamente responsáveis pelo tipo de dados que inserem nos modelos.
Garantir que os dados de treinamento usados para LLMs tenham sido selecionados a partir de uma gama diversificada de fontes de dados. Os conjuntos de dados de texto provenientes de diferentes dados demográficos, idiomas e culturas equilibrarão a representação da linguagem humana. Isso garante que os dados de treinamento não contenham amostras não representativas e orienta os esforços de ajuste fino do modelo direcionado, o que pode reduzir o impacto do viés quando usado pela comunidade em geral.
Depois que uma variedade de fontes de dados tiver sido coletada e inserida no modelo, as organizações poderão continuar a melhorar a precisão e reduzir os vieses por meio do ajuste fino do modelo. Há várias abordagens de ajuste fino, como:
Você pode saber mais sobre o processo de ajuste fino em nosso tutorial Fine-Tuning LLaMA 2, que contém um guia passo a passo para ajustar o modelo pré-treinado.
Para desenvolver continuamente sistemas de IA que possam ser integrados com segurança à sociedade atual, as organizações precisam ter vários métodos e métricas usados em seu processo de avaliação. Antes que os sistemas de IA, como os LLMs, sejam abertos à comunidade em geral, os métodos e as métricas corretos devem ser implementados para garantir que as diferentes dimensões da parcialidade sejam capturadas nos resultados dos LLMs.
Exemplos de métodos incluem avaliação humana, avaliação automática ou avaliação híbrida. Todos esses métodos são usados para detectar, estimar ou filtrar tendências em LLMs. Exemplos de métricas incluem precisão, sentimento, imparcialidade e muito mais. Essas métricas podem fornecer feedback sobre a tendência nos resultados do LLM e ajudar a melhorar continuamente as tendências detectadas nos LLMs.
Se você quiser saber mais sobre as diferentes avaliações usadas para melhorar a qualidade do LLM, confira nosso code-along sobre Avaliação de respostas do LLM.
Um estudo do CSAIL (Computer Science and Artificial Intelligence Laboratory, Laboratório de Ciência da Computação e Inteligência Artificial) do MIT fez avanços significativos nos LLMs ao integrar o raciocínio lógico: Os modelos de linguagem grandes são tendenciosos. A lógica pode ajudar a salvá-los?
A importância do pensamento lógico e estruturado nos LLMs permite que os modelos sejam capazes de processar e gerar resultados com a aplicação do raciocínio lógico e do pensamento crítico, de modo que os LLMs possam fornecer respostas mais precisas usando o raciocínio por trás deles.
O processo consiste em criar um modelo de linguagem neutro no qual as relações entre os tokens são consideradas "neutras", pois não há lógica que afirme que existe uma relação entre os dois. A CSAIL treinou esse método em um modelo de linguagem e descobriu que o modelo recém-treinado era menos tendencioso sem a necessidade de mais dados e treinamento adicional do algoritmo.
Os modelos de linguagem com reconhecimento lógico poderão evitar a produção de estereótipos prejudiciais.
O Google Research continua aprimorando seu LLM BERT, expandindo seus dados de treinamento para garantir que ele seja mais inclusivo e diversificado. O uso de grandes conjuntos de dados que contêm texto não anotado para a fase de pré-treinamento permitiu que o modelo fosse ajustado posteriormente para se adaptar a tarefas específicas. O objetivo é criar um LLM que seja menos tendencioso e produza resultados mais robustos. O Google Research declarou que esse método demonstrou uma redução nos resultados estereotipados gerados pelo modelo e continua a melhorar seu desempenho na compreensão de diferentes dialetos e contextos culturais.
A equipe do Google Research criou várias ferramentas chamadas "Fairness Indicators" (Indicadores de justiça), que têm como objetivo detectar preconceitos nos modelos de aprendizado de máquina e passar por um processo de atenuação. Esses indicadores usam métricas como falsos positivos e falsos negativos para avaliar o desempenho e identificar lacunas que podem ser ocultadas por métricas gerais.
A OpenAI garantiu à comunidade em geral que a segurança, a privacidade e as preocupações éticas estão na vanguarda de suas metas. Suas atenuações pré-treinamento para DALL-E 2 incluíram a filtragem de imagens violentas e sexuais do conjunto de dados de treinamento, removendo imagens que são visualmente semelhantes entre si e, em seguida, ensinar o modelo a atenuar os efeitos da filtragem do conjunto de dados.
Conseguir realizar uma coisa sem sacrificar a outra pode ser impossível às vezes. Isso se aplica ao tentar obter um equilíbrio entre a redução da tendência do LLM e a possibilidade de manter ou até mesmo melhorar o desempenho do modelo. Os modelos de desvalorização são essenciais para alcançar a justiça. Entretanto, o desempenho e a precisão do modelo não devem ser comprometidos.
Uma abordagem estratégica precisa ser implementada para garantir que os métodos de mitigação para reduzir o viés, como a curadoria de dados, o ajuste fino do modelo e o uso de vários métodos, não afetem a capacidade do modelo de entender e gerar resultados linguísticos. É necessário fazer melhorias; no entanto, o desempenho do modelo não deve ser uma desvantagem.
É uma questão de tentativa e erro, monitoramento e ajuste, desbaste e aprimoramento.
Neste artigo, abordamos o assunto:
O viés do LLM é um desafio complexo e multifacetado que precisa ser priorizado para que a sociedade tenha mais confiança nele e aceite livremente sua integração nas tarefas cotidianas. As organizações precisam entender o impacto negativo duradouro que os estereótipos têm sobre os indivíduos e a sociedade e usar isso para garantir que o caminho para mitigar os vieses do LLM por meio da curadoria de dados, do ajuste fino do modelo e da modelagem lógica seja estabelecido.
Para saber mais sobre LLMs, confira nosso curso Conceitos de modelos de linguagem grandes, que aborda como essas ferramentas avançadas estão remodelando o cenário da IA.
Comece sua jornada de IA hoje mesmo!
Programa
Curso
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
8 min
blog
Bhavishya Pandit
8 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
