Se você está lendo este artigo, provavelmente já ouviu falar sobre modelos de linguagem grandes (LLMs). Quem não tem? No final das contas, os LLMs estão por trás das ferramentas superpopulares que alimentam a revolução da IA geradora em andamento, incluindo ChatGPT, Google Bard e DALL-E.
Para realizar sua mágica, essas ferramentas contam com uma tecnologia avançada que permite processar dados e gerar conteúdo preciso em resposta à pergunta solicitada pelo usuário. É aqui que os LLMs entram em ação.
Este artigo tem o objetivo de apresentar a você os LLMs. Depois de ler as seções a seguir, você saberá o que são os LLMs, como eles funcionam, os diferentes tipos de LLMs com exemplos, bem como suas vantagens e limitações.
Para os novatos no assunto, nosso Curso de Conceitos de Modelos de Linguagem Grandes (LLMs) é o lugar perfeito para você ter uma visão geral dos LLMs. No entanto, se você já estiver familiarizado com o LLM e quiser dar um passo adiante, aprendendo a criar aplicativos com LLM, consulte nosso artigo Como criar aplicativos LLM com LangChain.
Vamos começar!
O que é um modelo de idioma grande?
Os LLMs são sistemas de IA usados para modelar e processar a linguagem humana. Eles são chamados de "grandes" porque esses tipos de modelos são normalmente compostos por centenas de milhões ou até bilhões de parâmetros que definem o comportamento do modelo, que são pré-treinados usando um corpus maciço de dados de texto.
A tecnologia subjacente dos LLMs é chamada de rede neural de transformador, simplesmente chamada de transformador. Como explicaremos em mais detalhes na próxima seção, um transformador é uma arquitetura neural inovadora no campo da aprendizagem profunda.
Apresentados pelos pesquisadores do Google no famoso artigo Attention is All You Need em 2017, os transformadores são capazes de realizar tarefas de linguagem natural (NLP) com precisão e velocidade sem precedentes. Com seus recursos exclusivos, os transformadores proporcionaram um salto significativo nos recursos dos LLMs. É justo dizer que, sem os transformadores, a atual revolução da IA generativa não seria possível.
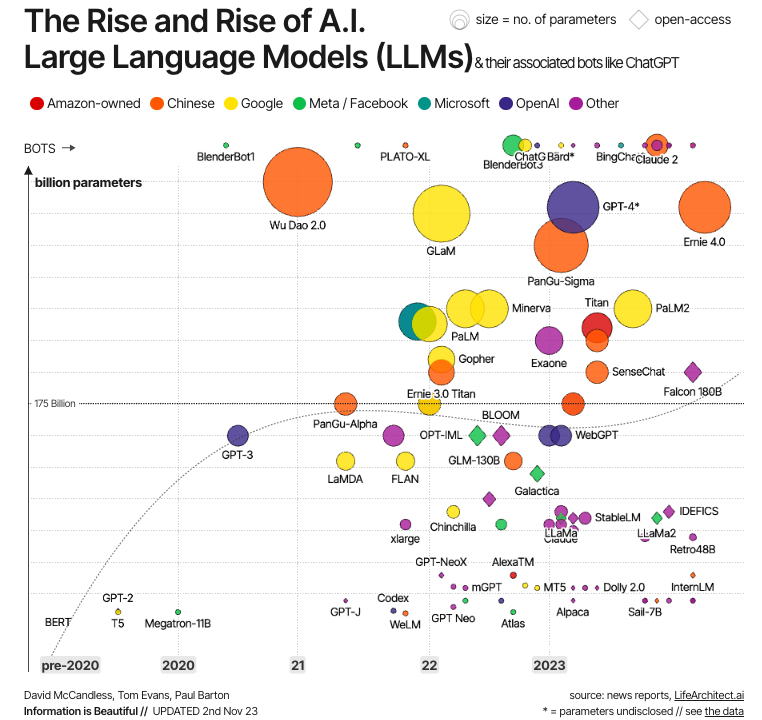
Fonte: A informação é bela
Essa evolução é ilustrada no gráfico acima. Como podemos ver, os primeiros LLMs modernos foram criados logo após o desenvolvimento dos transformadores, sendo os exemplos mais significativos o BERT - o primeiro LLM desenvolvido pelo Google para testar a potência dos transformadores -, bem como o GPT-1 e o GPT-2, os dois primeiros modelos da série GPT criados pela OpenAI. Mas foi somente na década de 2020 que os LLMs se tornaram comuns, cada vez maiores (em termos de parâmetros) e, portanto, mais potentes, com exemplos bem conhecidos como GPT-4 e LLaMa.
Como funcionam os LLMs?
A chave para o sucesso dos LLMs modernos é a arquitetura do transformador. Antes de os transformadores serem desenvolvidos pelos pesquisadores do Google, modelar a linguagem natural era uma tarefa muito desafiadora. Apesar do surgimento de redes neurais sofisticadas - ou seja, redes neurais recorrentes ou convolucionais - os resultados foram apenas parcialmente bem-sucedidos.
O principal desafio está na estratégia que essas redes neurais usam para prever a palavra que falta em uma frase. Antes dos transformadores, as redes neurais de última geração dependiam da arquitetura codificador-decodificador, um mecanismo poderoso, mas que consome tempo e recursos e não é adequado para computação paralela, limitando, portanto, as possibilidades de escalabilidade.
Os transformadores oferecem uma alternativa ao neural tradicional para lidar com dados sequenciais, ou seja, texto (embora os transformadores também tenham sido usados com outros tipos de dados, como imagens e áudio, com resultados igualmente bem-sucedidos).
Componentes dos LLMs
Os transformadores são baseados na mesma arquitetura de codificador-decodificador das redes neurais recorrentes e convolucionais. Essa arquitetura neural tem o objetivo de descobrir relações estatísticas entre tokens de texto.
Isso é feito por meio de uma combinação de técnicas de incorporação. Embeddings são as representações de tokens, como frases, parágrafos ou documentos, em um espaço vetorial de alta dimensão, em que cada dimensão corresponde a um recurso ou atributo aprendido do idioma.
O processo de incorporação ocorre no codificador. Devido ao grande tamanho dos LLMs, a criação de incorporação requer treinamento extensivo e recursos consideráveis. No entanto, o que torna os transformadores diferentes em comparação com as redes neurais anteriores é que o processo de incorporação é altamente paralelizável, permitindo um processamento mais eficiente. Isso é possível graças ao mecanismo de atenção.
As redes neurais recorrentes e convolucionais fazem suas previsões de palavras com base exclusivamente em palavras anteriores. Nesse sentido, eles podem ser considerados unidirecionais. Por outro lado, o mecanismo de atenção permite que os transformadores prevejam palavras de forma bidirecional, ou seja, com base nas palavras anteriores e posteriores. O objetivo da camada de atenção, que é incorporada tanto no codificador quanto no decodificador, é capturar as relações contextuais existentes entre diferentes palavras na frase de entrada.
Para saber em detalhes como a arquitetura do codificador-decodificador funciona nos transformadores, recomendamos que você leia nossa Introdução ao uso de transformadores e Hugging Face.
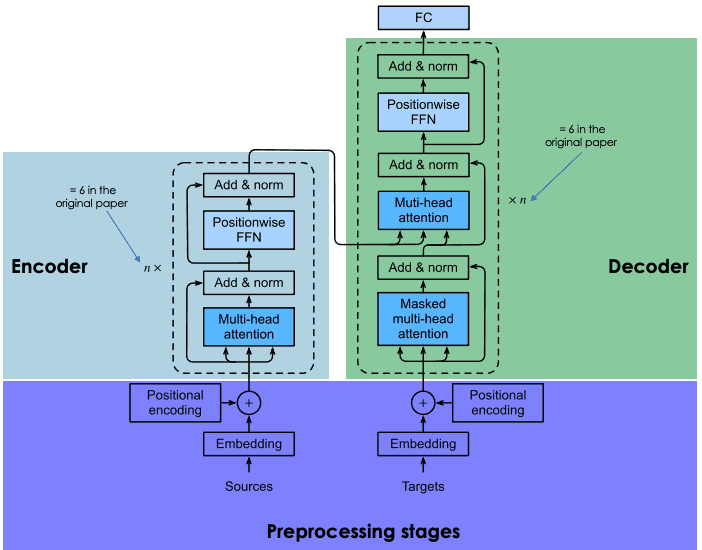
Uma explicação da arquitetura dos transformadores
Treinamento de LLMs
O treinamento de transformadores envolve duas etapas: pré-treinamento e ajuste fino.
Pré-treinamento
Nessa fase, os transformadores são treinados em grandes quantidades de dados de texto bruto. A Internet é a principal fonte de dados.
O treinamento é feito usando técnicas de aprendizado não supervisionado, um tipo inovador de treinamento que não exige ação humana para rotular os dados.
O objetivo do pré-treinamento é aprender os padrões estatísticos do idioma. A estratégia mais moderna para obter melhor precisão dos transformadores é aumentar o modelo (isso pode ser feito aumentando o número de parâmetros) e aumentar o tamanho dos dados de treinamento. Como resultado, os LLMs mais avançados vêm com bilhões de parâmetros (por exemplo, o PaLM 2 tem 340 bilhões de parâmetros e estima-se que o GPT-4 tenha cerca de 1,8 trilhão de parâmetros) e foram treinados em um corpus de dados enorme.
Essa tendência cria problemas de acessibilidade. Considerando o tamanho do modelo e os dados de treinamento, o processo de pré-treinamento normalmente consome muito tempo e é caro, o que somente um grupo reduzido de empresas pode pagar.
Ajuste fino
O pré-treinamento permite que um transformador adquira uma compreensão básica da linguagem, mas não é suficiente para realizar tarefas práticas específicas com alta precisão.
Para evitar iterações demoradas e caras no processo de treinamento, os transformadores aproveitam as técnicas de aprendizagem por transferência para separar a fase de (pré)treinamento da fase de ajuste fino. Isso permite que os desenvolvedores escolham modelos pré-treinados e os ajustem com base em um banco de dados mais restrito e específico do domínio. Em muitos casos, o processo de ajuste fino é conduzido com a ajuda de revisores humanos, usando uma técnica chamada Reinforcement Learning from Human Feedback.
O processo de treinamento em duas etapas permite a adaptação do LLM a uma ampla gama de tarefas de downstream. Em outras palavras, esse recurso faz dos LLMs o modelo de base de inúmeros aplicativos criados sobre eles.
Multimodalidade de LLMs
Os primeiros LLMs modernos eram modelos de texto para texto (ou seja, recebiam uma entrada de texto e geravam uma saída de texto). No entanto, nos últimos anos, os desenvolvedores criaram os chamados LLMs multimodais. Esses modelos combinam dados de texto com outros tipos de informações, incluindo imagens, áudio e vídeo. A combinação de diferentes tipos de dados permitiu a criação de modelos sofisticados específicos de tarefas, como o DALL-E. da OpenAI para geração de imagens e o AudioCraft da Meta para geração de música e áudio.
Para que são usados os LLMs?
Com a ajuda de transformadores, os LLMs modernos alcançaram um desempenho de última geração em várias tarefas de PNL. Aqui estão algumas das tarefas em que os LLMs forneceram resultados exclusivos:
- Geração de texto. LLMs como o ChatGPT são capazes de criar textos longos, complexos e semelhantes aos humanos em questão de segundos.
- Tradução. Quando os LLMs são treinados em vários idiomas, eles podem realizar operações de tradução de alto nível. Com a multimodalidade, as possibilidades são infinitas. Por exemplo, o modelo SeamlessM4T da Meta pode realizar traduções de fala para texto, fala para fala, texto para fala e texto para texto em até 100 idiomas, dependendo da tarefa.
- Análise de sentimento. Todos os tipos de análise de sentimento podem ser realizados com LLMs, desde previsões de críticas positivas e negativas de filmes até opiniões de campanhas de marketing.
- IA de conversação. Como a tecnologia subjacente dos chatbots modernos, os LLMs são ótimos para fazer perguntas, responder e manter conversas, mesmo em tarefas complexas.
- Autocompletar. Os LLMs podem ser usados para tarefas de preenchimento automático, por exemplo, em e-mails ou serviços de mensagens. Por exemplo, o BERT do Google alimenta a ferramenta de preenchimento automático no Gmail.
Vantagens dos LLMs
O LLM tem um imenso potencial para as organizações, conforme ilustrado pela ampla adoção do ChatGPT, que, apenas alguns meses após seu lançamento, tornou-se o aplicativo digital de crescimento mais rápido de todos os tempos.
Já existe um bom número de aplicações comerciais de LLMs, e o número de casos de uso só aumentará à medida que essas ferramentas se tornarem mais onipresentes em todos os setores e indústrias. Abaixo, você encontrará uma lista de alguns dos benefícios dos LLMs:
- Criação de conteúdo. Os LLMs são poderosos em todos os tipos de ferramentas de IA generativa. Com seus recursos, os LLMs são ótimas ferramentas para gerar conteúdo (principalmente texto, mas, em combinação com outros modelos, eles também podem gerar imagens, vídeos e áudio). Dependendo dos dados usados no processo de ajuste fino, os LLMs podem fornecer conteúdo preciso e específico de domínio em qualquer setor que você possa imaginar, desde jurídico e financeiro até saúde e marketing.
- Aumento da eficácia em tarefas de PNL. Conforme explicado na seção anterior, os LLMs oferecem desempenho exclusivo em muitas tarefas de PLN. Eles são capazes de compreender a linguagem humana e interagir com os seres humanos com uma precisão sem precedentes. No entanto, é importante observar que essas ferramentas não são perfeitas e ainda podem gerar resultados imprecisos ou até mesmo alucinações em geral,
- Aumento da eficiência. Um dos principais benefícios comerciais dos LLMs é que eles são perfeitos para concluir tarefas monótonas e demoradas em questão de segundos. Embora existam grandes perspectivas para as empresas que podem se beneficiar desse salto de eficiência, há implicações profundas para os trabalhadores e para o mercado de trabalho que precisam ser consideradas.
Desafios e limitações dos LLMs
Os LLMs estão na vanguarda da revolução da IA generativa. No entanto, como sempre ocorre com as tecnologias emergentes, com o poder vem a responsabilidade. Apesar dos recursos exclusivos do LLM, é importante considerar seus possíveis riscos e desafios.
Abaixo, você encontra uma lista de riscos e desafios associados à adoção generalizada de LLMs:
- Falta de transparência. A opacidade algorítmica é uma das principais preocupações associadas aos LLMs. Esses modos são frequentemente rotulados como modelos de "caixa preta" devido à sua complexidade, o que torna impossível monitorar seu raciocínio e funcionamento interno. Os fornecedores de IA de LLMs proprietários geralmente relutam em fornecer informações sobre seus modelos, o que dificulta muito o monitoramento e a responsabilidade.
- Monopólio do LLM. Considerando os recursos consideráveis necessários para desenvolver, treinar e operar LLMs, o mercado está altamente concentrado em um grupo de grandes empresas de tecnologia com o know-how e os recursos necessários. Felizmente, um número cada vez maior de LLMs de código aberto está chegando ao mercado, facilitando o entendimento e a operação dos LLMs pelos desenvolvedores, pesquisadores de IA e pela sociedade.
- Preconceito e discriminação. Modelos de LLM tendenciosos podem resultar em decisões injustas que muitas vezes exacerbam a discriminação, principalmente contra grupos minoritários. Mais uma vez, a transparência é essencial aqui para que você entenda melhor e aborde os possíveis vieses.
- Questões de privacidade. Os LLMs são treinados com grandes quantidades de dados, principalmente extraídos indiscriminadamente da Internet. Geralmente, ele contém dados pessoais. Isso pode levar a problemas e riscos relacionados à privacidade e à segurança dos dados.
- Considerações éticas. Às vezes, os LLMs podem levar a decisões que têm sérias implicações em nossas vidas, com impactos significativos em nossos direitos fundamentais. Exploramos a ética da IA generativa em uma publicação separada.
- Considerações ambientais. Pesquisadores e observadores ambientais estão levantando preocupações sobre a pegada ambiental associada ao treinamento e à operação de LLMs. Os LLMs proprietários raramente publicam informações sobre a energia e os recursos consumidos pelos LLMs, nem sobre a pegada ambiental associada, o que é extremamente problemático com a rápida adoção dessas ferramentas.
Diferentes tipos e exemplos de LLMs
O design dos LLMs os torna modelos extremamente flexíveis e adaptáveis. Essa modularidade se traduz em diferentes tipos de LLMs, em particular:
- LLMs de tiro zero. Esses modelos são capazes de concluir uma tarefa sem ter recebido nenhum exemplo de treinamento. Por exemplo, considere um LLM capaz de entender novas gírias com base nas relações semânticas e de posição dessas novas palavras com o restante do texto.
- LLMs ajustados. É muito comum que os desenvolvedores utilizem um LLM pré-treinado e o ajustem com novos dados para fins específicos. Para saber mais sobre o ajuste fino do LLM, leia nosso artigo Fine-Tuning LLaMA 2: Um guia passo a passo para você personalizar o Large Language Model.
- LLMs específicos de domínio. Esses modelos são projetados especificamente para capturar o jargão, o conhecimento e as particularidades de um determinado campo ou setor, como saúde ou jurídico. Ao desenvolver esses modelos, é importante escolher dados de treinamento com curadoria, para que o modelo atenda aos padrões do campo em questão.
Atualmente, o número de LLMs proprietários e de código aberto está crescendo rapidamente. Você já deve ter ouvido falar do ChatGPT, mas o ChatGPT não é um LLM, mas um aplicativo desenvolvido com base em um LLM. Em particular, o ChatGPT é alimentado pelo GPT-3.5, enquanto o ChatGPT-Plus é alimentado pelo GPT-4, atualmente o LLM mais avançado. Para saber mais sobre como usar os modelos GPT da OpenAI, leia nosso artigo Using GPT-3.5 and GPT-4 via the OpenAI API in Python.
Abaixo, você encontrará uma lista de alguns outros LLMs populares:
- BERT. Google em 2018 e lançado em código aberto, o BERT é um dos primeiros LLM modernos e um dos mais bem-sucedidos. Consulte nosso artigo O que é o BERT? para saber tudo sobre esse LLM clássico.
- PaLM 2. Um LLM mais avançado do que seu antecessor PaLM, o PaLM 2 é o LLM que alimenta o Google Bard, o chatbot mais ambicioso para competir com o ChatGPT.
- LLaMa 2. Desenvolvido pela Meta, o LLaMa 2 é um dos LLMs de código aberto mais avançados do mercado. Para saber mais sobre esse e outros LLMs de código aberto, recomendamos que você leia nosso artigo dedicado com os 8 principais LLMs de código aberto.
Conclusão
Os LLMs estão impulsionando o atual boom da IA generativa. As possíveis aplicações são tão vastas que todos os setores e indústrias, inclusive a ciência de dados, provavelmente serão afetados pela adoção de LLMs no futuro.
As possibilidades são infinitas, mas também os riscos e desafios. Com sua capacidade transformadora e, os LLMs geraram especulações sobre o futuro e como a IA afetará o mercado de trabalho e muitos outros aspectos de nossas sociedades. Esse é um debate importante que precisa ser abordado com firmeza e coletivamente, pois há muito em jogo.
O DataCamp está se esforçando para fornecer recursos abrangentes e acessíveis para que todos possam se manter atualizados com o desenvolvimento da IA. Dê uma olhada neles:
- Curso de Conceitos de Modelos de Linguagem Grandes (LLMs)
- Como criar aplicativos LLM com LangChain
- Como treinar um LLM com o PyTorch: Um guia passo a passo
- 8 principais LLMs de código aberto para 2024 e seus usos
- Llama.cpp Tutorial: Um guia completo para inferência e implementação eficientes de LLM
- Introdução ao LangChain para engenharia de dados e aplicativos de dados
- LlamaIndex: Uma estrutura de dados para aplicativos baseados em modelos de linguagem grandes (LLMs)
- Como aprender IA do zero em 2024: Um guia completo para especialistas

Série Code Along: Torne-se um desenvolvedor de IA
Crie sistemas de IA e desenvolva aplicativos de IA usando OpenAI, LangChain, Pinecone e Hugging Face!


