
Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
100K
Os transformadores foram desenvolvidos inicialmente para solucionar o problema de transdução de sequências ou tradução automática neural, o que significa que eles se destinam a solucionar qualquer tarefa que transforme uma sequência de entrada em uma sequência de saída. É por isso que eles são chamados de "Transformers".
Mas vamos começar do início.
Um modelo de transformador é uma rede neural que aprende o contexto de dados sequenciais e gera novos dados a partir deles.
Para simplificar:
Um transformador é um tipo de modelo de inteligência artificial que aprende a entender e gerar texto semelhante ao humano analisando padrões em grandes quantidades de dados de texto.
Os transformadores são um modelo de PNL atual de última geração e são considerados a evolução da arquitetura do codificador-decodificador. No entanto, enquanto a arquitetura do codificador-decodificador se baseia principalmente em redes neurais recorrentes (RNNs) para extrair informações sequenciais, os transformadores não têm essa recorrência.
Então, como eles fazem isso?
Eles são projetados especificamente para compreender o contexto e o significado por meio da análise da relação entre diferentes elementos e, para isso, dependem quase inteiramente de uma técnica matemática chamada atenção.

Imagem do autor.
Originados de um artigo de pesquisa de 2017 do Google, os modelos de transformadores são um dos desenvolvimentos mais recentes e influentes no campo do aprendizado de máquina. O primeiro modelo Transformer foi explicado no influente artigo "Attention is All You Need".
Esse conceito pioneiro não foi apenas um avanço teórico, mas também encontrou uma implementação prática, principalmente no pacote Tensor2Tensor do TensorFlow. Além disso, o grupo de PNL de Harvard contribuiu para esse campo em expansão oferecendo um guia anotado para o artigo, complementado com uma implementação do PyTorch. Você pode saber mais sobre como implementar um Transformer do zero em nosso tutorial separado.
Sua introdução estimulou um aumento significativo no campo, geralmente chamado de Transformer AI. Esse modelo revolucionário lançou as bases para os avanços subsequentes no campo dos modelos de linguagem de grande porte, incluindo o BERT. Em 2018, esses desenvolvimentos já estavam sendo aclamados como um momento decisivo na PNL.
Em 2020, os pesquisadores da OpenAI anunciaram o GPT-3. Em poucas semanas, a versatilidade do GPT-3 foi rapidamente demonstrada quando as pessoas o usaram para criar poemas, programas, músicas, sites e muito mais, cativando a imaginação dos usuários em todo o mundo.
Em um artigo de 2021, os acadêmicos de Stanford denominaram adequadamente essas inovações como modelos de fundação, destacando seu papel fundamental na reformulação da IA. Seu trabalho destaca como os modelos transformadores não apenas revolucionaram o campo, mas também ampliaram as fronteiras do que é possível alcançar em inteligência artificial, anunciando uma nova era de possibilidades.
"Estamos em uma época em que métodos simples, como as redes neurais, estão nos proporcionando uma explosão de novos recursos", disseAshish Vaswani, empresário e ex-cientista sênior de pesquisa da equipe do Google
Na época da introdução do modelo Transformer, os RNNs eram a abordagem preferida para lidar com dados sequenciais, que são caracterizados por uma ordem específica em sua entrada.
As RNNs funcionam de forma semelhante a uma rede neural feed-forward, mas processam a entrada sequencialmente, um elemento de cada vez.
Os transformadores foram inspirados na arquitetura codificador-decodificador encontrada nos RNNs. No entanto, em vez de usar recorrência, o modelo Transformer é totalmente baseado no mecanismo de atenção.
Além de melhorar o desempenho da RNN, os Transformers forneceram uma nova arquitetura para resolver muitas outras tarefas, como resumo de textos, legendas de imagens e reconhecimento de fala.
Então, quais são os principais problemas dos RNNs? Eles são bastante ineficazes para tarefas de PNL por dois motivos principais:
A mudança das redes neurais recorrentes (RNNs), como a LSTM, para os Transformers na PNL é motivada por esses dois problemas principais e pela capacidade dos Transformers de avaliar ambos, aproveitando os aprimoramentos do mecanismo de atenção:
Assim, os Transformers se tornaram um aprimoramento natural dos RNNs.
A seguir, vamos dar uma olhada em como os transformadores funcionam.
Originalmente concebidos para transdução de sequências ou tradução automática neural, os transformadores são excelentes na conversão de sequências de entrada em sequências de saída. É o primeiro modelo de transdução que depende inteiramente da autoatenção para computar representações de sua entrada e saída sem usar RNNs alinhados à sequência ou convolução. A principal característica central da arquitetura dos Transformers é que eles mantêm o modelo codificador-decodificador.
Se começarmos a considerar um Transformer para tradução de idiomas como uma simples caixa preta, ele receberia uma frase em um idioma, por exemplo, inglês, como entrada e produziria sua tradução em inglês.

Imagem do autor.
Se você se aprofundar um pouco mais, verá que essa caixa preta é composta de duas partes principais:
Imagem do autor. Estrutura global do codificador-decodificador.
No entanto, tanto o codificador quanto o decodificador são, na verdade, uma pilha com várias camadas (o mesmo número para cada uma). Todos os codificadores apresentam a mesma estrutura, e a entrada entra em cada um deles e é passada para o próximo. Todos os decodificadores também apresentam a mesma estrutura e recebem a entrada do último codificador e do decodificador anterior.
A arquitetura original consistia em 6 codificadores e 6 decodificadores, mas podemos replicar quantas camadas quisermos. Portanto, vamos supor que você tenha N camadas de cada.
Imagem do autor. Estrutura global do codificador-decodificador. Múltiplas camadas.
Agora que temos uma ideia genérica da arquitetura geral do Transformer, vamos nos concentrar nos codificadores e decodificadores para entender melhor seu fluxo de trabalho:
O codificador é um componente fundamental da arquitetura do Transformer. A principal função do codificador é transformar os tokens de entrada em representações contextualizadas. Diferentemente dos modelos anteriores que processavam tokens independentemente, o codificador Transformer captura o contexto de cada token em relação à sequência inteira.
A composição de sua estrutura é a seguinte:
Imagem do autor. Estrutura global dos codificadores.
Portanto, vamos dividir o fluxo de trabalho em suas etapas mais básicas:
A incorporação só ocorre no codificador mais baixo. O codificador começa convertendo tokens de entrada - palavras ou subpalavras - em vetores usando camadas de incorporação. Esses embeddings capturam o significado semântico dos tokens e os convertem em vetores numéricos.
Todos os codificadores recebem uma lista de vetores, cada um com tamanho 512 (tamanho fixo). No codificador inferior, seriam os embeddings de palavras, mas em outros codificadores, seria a saída do codificador que está diretamente abaixo deles.
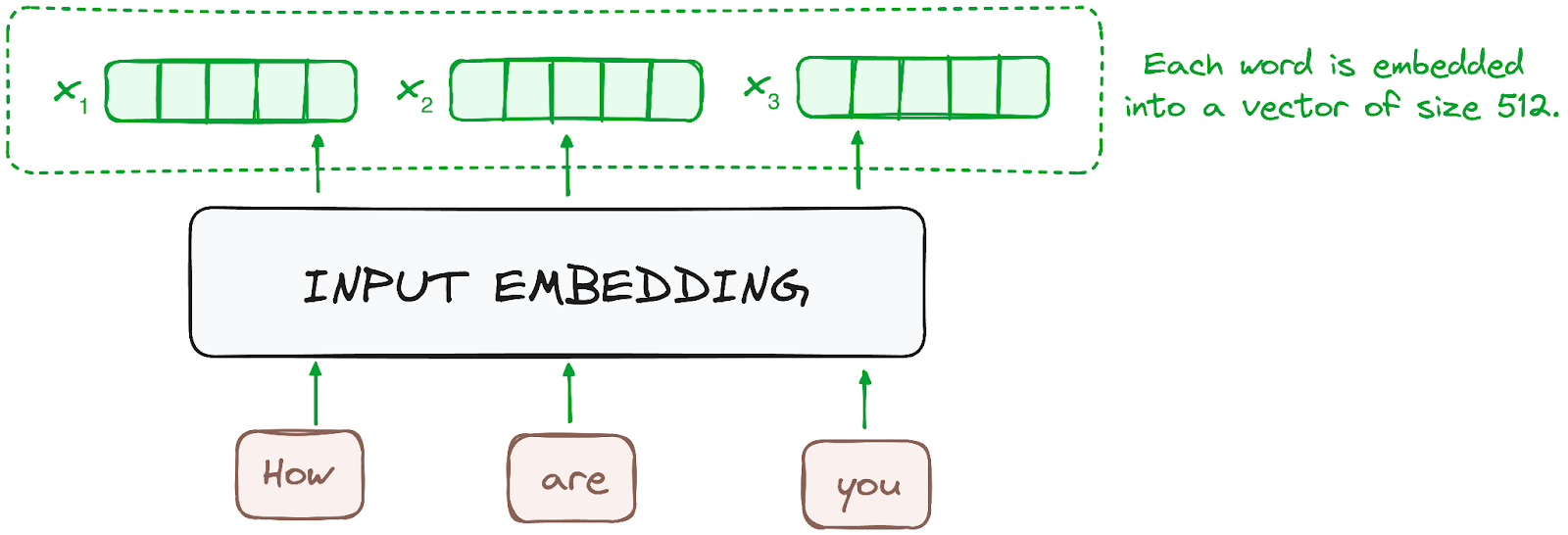
Imagem do autor. Fluxo de trabalho do codificador. Incorporação de entrada.
Como os Transformers não têm um mecanismo de recorrência como os RNNs, eles usam codificações posicionais adicionadas aos embeddings de entrada para fornecer informações sobre a posição de cada token na sequência. Isso permite que eles entendam a posição de cada palavra na frase.
Para isso, os pesquisadores sugeriram o emprego de uma combinação de várias funções de seno e cosseno para criar vetores posicionais, permitindo o uso desse codificador posicional para frases de qualquer tamanho.
Nessa abordagem, cada dimensão é representada por frequências e deslocamentos exclusivos da onda, com os valores variando de -1 a 1, representando efetivamente cada posição.
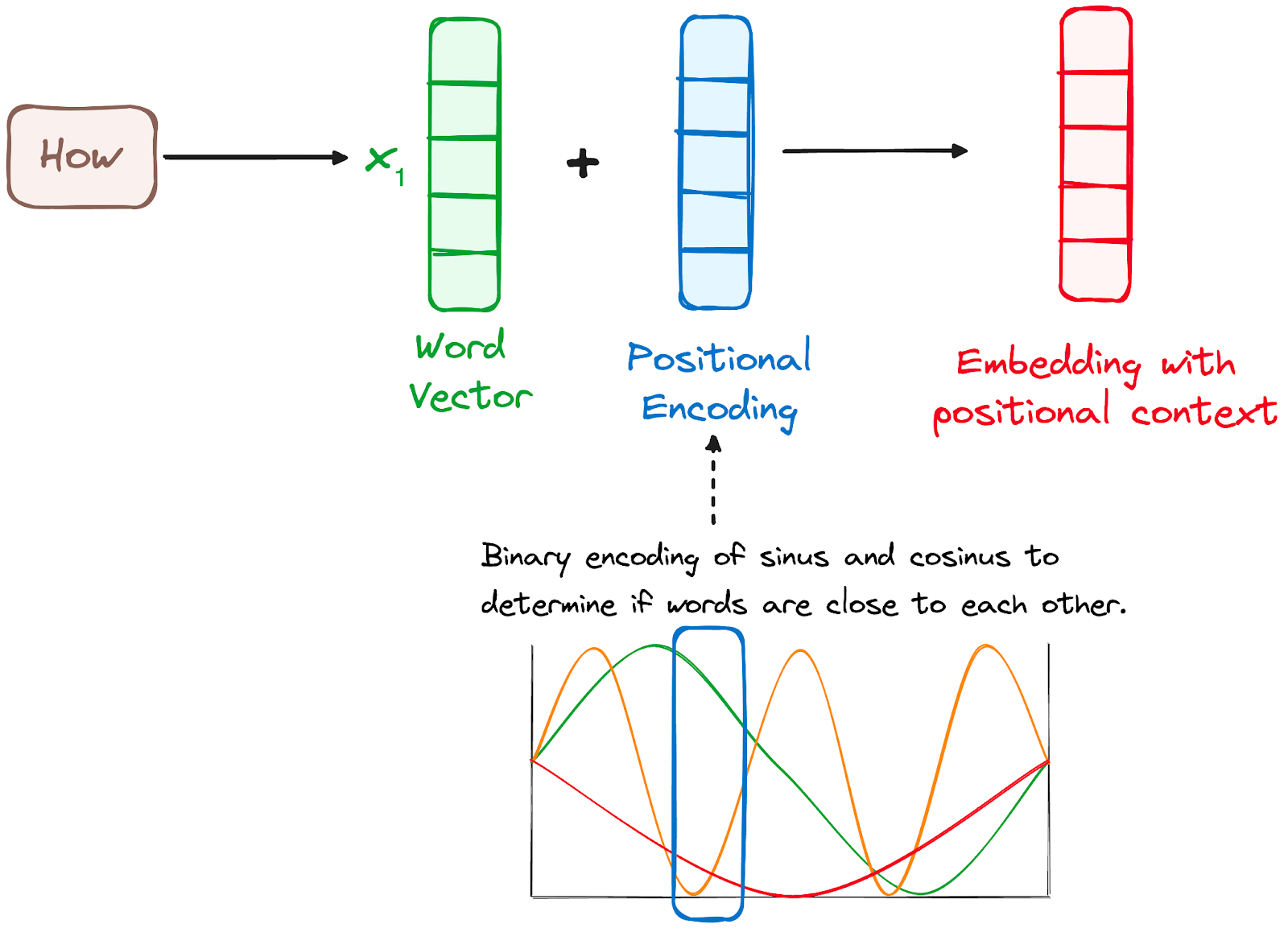
Imagem do autor. Fluxo de trabalho do codificador. Codificação posicional.
O codificador do Transformer consiste em uma pilha de camadas idênticas (6 no modelo original do Transformer).
A camada do codificador serve para transformar todas as sequências de entrada em uma representação contínua e abstrata que encapsula as informações aprendidas de toda a sequência. Essa camada é composta por dois submódulos:
Além disso, ele incorpora conexões residuais em cada subcamada, que são seguidas pela normalização da camada.
Imagem do autor. Fluxo de trabalho do codificador. Pilha de camadas do codificador
No codificador, a atenção com várias cabeças utiliza um mecanismo de atenção especializado conhecido como autoatenção. Essa abordagem permite que os modelos relacionem cada palavra na entrada com outras palavras. Por exemplo, em um determinado exemplo, o modelo pode aprender a conectar a palavra "are" (são) com "you" (você).
Esse mecanismo permite que o codificador se concentre em diferentes partes da sequência de entrada à medida que processa cada token. Ele calcula as pontuações de atenção com base em:
Esse primeiro módulo de autoatenção permite que o modelo capture informações contextuais de toda a sequência. Em vez de executar uma única função de atenção, as consultas, as chaves e os valores são projetados linearmente h vezes. Em cada uma dessas versões projetadas de consultas, chaves e valores, o mecanismo de atenção é executado em paralelo, produzindo valores de saída h-dimensionais.
A arquitetura detalhada é a seguinte:
Depois que os vetores de consulta, chave e valor são passados por uma camada linear, uma multiplicação de matriz de produto escalar é realizada entre as consultas e as chaves, resultando na criação de uma matriz de pontuação.
A matriz de pontuação estabelece o grau de ênfase que cada palavra deve dar a outras palavras. Portanto, a cada palavra é atribuída uma pontuação em relação a outras palavras na mesma etapa de tempo. Uma pontuação mais alta indica maior foco.
Esse processo mapeia efetivamente as consultas para suas chaves correspondentes.
Imagem do autor. Fluxo de trabalho do codificador. Mecanismo de atenção - Multiplicação de matrizes.
As pontuações são então reduzidas dividindo-as pela raiz quadrada da dimensão da consulta e dos vetores-chave. Essa etapa é implementada para garantir gradientes mais estáveis, pois a multiplicação de valores pode levar a efeitos excessivamente grandes.
Imagem do autor. Fluxo de trabalho do codificador. Reduzir os escores de atenção.
Posteriormente, uma função softmax é aplicada às pontuações ajustadas para obter os pesos de atenção. Isso resulta em valores de probabilidade que variam de 0 a 1. A função softmax enfatiza as pontuações mais altas e diminui as mais baixas, aumentando assim a capacidade do modelo de determinar efetivamente quais palavras devem receber mais atenção.
Imagem do autor. Fluxo de trabalho do codificador. Pontuações ajustadas da Softmax.
A etapa seguinte do mecanismo de atenção é que os pesos derivados da função softmax são multiplicados pelo vetor de valores, resultando em um vetor de saída.
Nesse processo, somente as palavras que apresentam pontuações softmax altas são preservadas. Por fim, esse vetor de saída é alimentado em uma camada linear para processamento adicional.
Imagem do autor. Fluxo de trabalho do codificador. Combinação dos resultados do Softmax com o vetor de valores.
E finalmente temos o resultado do mecanismo de atenção!
Então, você deve estar se perguntando por que ele se chama Multi-Head Attention?
Lembre-se de que, antes de todo o processo começar, dividimos nossas consultas, chaves e valores h vezes. Esse processo, conhecido como autoatenção, ocorre separadamente em cada um desses estágios menores ou "cabeças". Cada cabeçote faz sua mágica de forma independente, criando um vetor de saída.
Esse conjunto passa por uma camada linear final, como se fosse um filtro que afina seu desempenho coletivo. A beleza aqui está na diversidade de aprendizado em cada cabeça, enriquecendo o modelo do codificador com um entendimento robusto e multifacetado.
Cada subcamada em uma camada de codificador é seguida por uma etapa de normalização. Além disso, a saída de cada subcamada é adicionada à sua entrada (conexão residual) para ajudar a atenuar o problema do gradiente de desaparecimento, permitindo modelos mais profundos. Esse processo também será repetido após a rede neural Feed-Forward.
Imagem do autor. Fluxo de trabalho do codificador. Normalização e conexão residual após a atenção de várias cabeças.
A jornada da saída residual normalizada continua enquanto ela navega por uma rede de alimentação pontual, uma fase crucial para refinamento adicional.
Imagine essa rede como uma dupla de camadas lineares, com uma ativação ReLU aninhada entre elas, atuando como uma ponte. Depois de processada, a saída segue um caminho conhecido: ela volta em loop e se funde com a entrada da rede de avanço pontual.
Essa reunião é seguida por outra rodada de normalização, garantindo que tudo esteja bem ajustado e em sincronia para as próximas etapas.
Imagem do autor. Fluxo de trabalho do codificador. Subcamada da rede neural Feed-Forward.
A saída da camada final do codificador é um conjunto de vetores, cada um representando a sequência de entrada com um rico entendimento contextual. Essa saída é então usada como entrada para o decodificador em um modelo Transformer.
Essa codificação cuidadosa prepara o caminho para o decodificador, orientando-o a prestar atenção às palavras certas na entrada quando for a hora de decodificar.
Pense nisso como a construção de uma torre, na qual você pode empilhar N camadas de codificadores. Cada camada dessa pilha tem a chance de explorar e aprender diferentes facetas da atenção, assim como as camadas de conhecimento. Isso não apenas diversifica o entendimento, mas também pode ampliar significativamente os recursos de previsão da rede de transformadores.
A função do decodificador está centrada na criação de sequências de texto. Assim como o codificador, o decodificador é equipado com um conjunto semelhante de subcamadas. Ele possui duas camadas de atenção com várias cabeças, uma camada de avanço pontual e incorpora conexões residuais e normalização de camadas após cada subcamada.
Imagem do autor. Estrutura global dos codificadores.
Esses componentes funcionam de forma semelhante às camadas do codificador, mas com uma diferença: cada camada de atenção com várias cabeças no decodificador tem sua missão exclusiva.
A parte final do processo do decodificador envolve uma camada linear, que funciona como um classificador, complementada por uma função softmax para calcular as probabilidades de palavras diferentes.
O decodificador Transformer tem uma estrutura projetada especificamente para gerar essa saída, decodificando as informações codificadas passo a passo.
É importante observar que o decodificador opera de forma autorregressiva, iniciando seu processo com um token de início. De forma inteligente, ele usa uma lista de saídas geradas anteriormente como suas entradas, em conjunto com as saídas do codificador que são ricas em informações de atenção da entrada inicial.
Essa dança sequencial de decodificação continua até que o decodificador chegue a um momento crucial: a geração de um token que sinaliza o fim da criação de sua saída.
Na linha de partida do decodificador, o processo espelha o do codificador. Aqui, a entrada passa primeiro por uma camada de incorporação
Após a incorporação, novamente como no decodificador, a entrada passa pela camada de codificação posicional. Essa sequência foi projetada para produzir embeddings posicionais.
Essas incorporações posicionais são então canalizadas para a primeira camada de atenção de várias cabeças do decodificador, onde as pontuações de atenção específicas da entrada do decodificador são meticulosamente computadas.
O decodificador consiste em uma pilha de camadas idênticas (6 no modelo original do Transformer). Cada camada tem três subcomponentes principais:
Isso é semelhante ao mecanismo de autoatenção no codificador, mas com uma diferença crucial: ele impede que as posições atendam às posições subsequentes, o que significa que cada palavra na sequência não é influenciada por tokens futuros.
Por exemplo, quando as pontuações de atenção para a palavra "are" estão sendo computadas, é importante que "are" não dê uma olhada em "you", que é uma palavra subsequente na sequência.
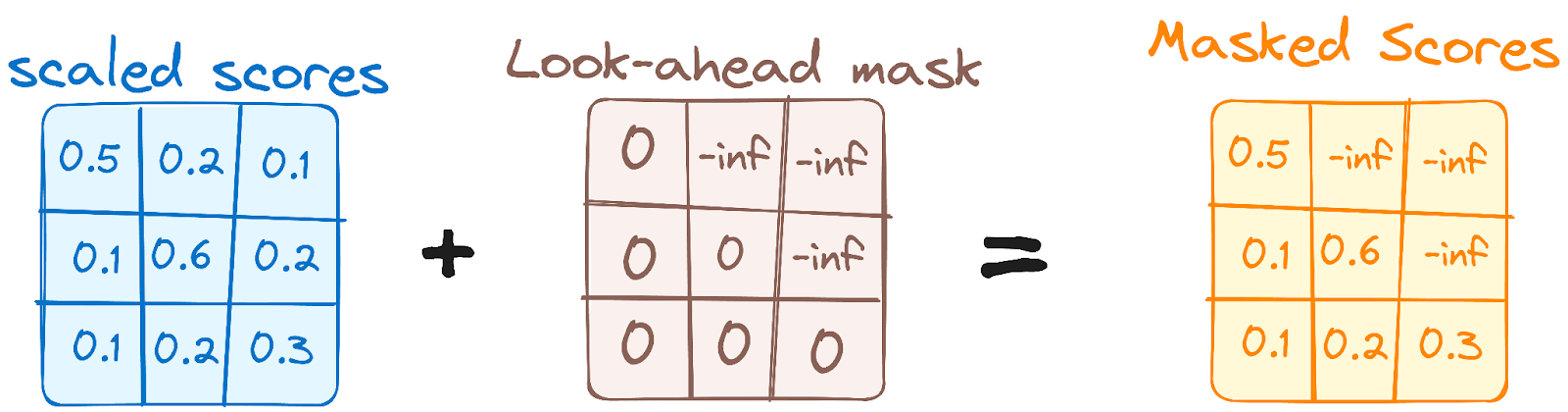
Imagem do autor. Fluxo de trabalho do decodificador. Primeira máscara de atenção com várias cabeças.
Esse mascaramento garante que as previsões para uma determinada posição dependam apenas de resultados conhecidos em posições anteriores a ela.
Na segunda camada de atenção com várias cabeças do decodificador, vemos uma interação exclusiva entre os componentes do codificador e do decodificador. Aqui, as saídas do codificador assumem as funções de consultas e chaves, enquanto as saídas da primeira camada de atenção com várias cabeças do decodificador servem como valores.
Essa configuração alinha efetivamente a entrada do codificador com a do decodificador, permitindo que o decodificador identifique e enfatize as partes mais relevantes da entrada do codificador.
Em seguida, a saída dessa segunda camada de atenção com várias cabeças é refinada por meio de uma camada de alimentação pontual, aprimorando ainda mais o processamento.
Imagem do autor. Fluxo de trabalho do decodificador. Codificador-Decodificador Atenção.
Nessa subcamada, as consultas vêm da camada anterior do decodificador, e as chaves e os valores vêm da saída do codificador. Isso permite que cada posição no decodificador atenda a todas as posições na sequência de entrada, integrando efetivamente as informações do codificador com as informações do decodificador.
Da mesma forma que o codificador, cada camada do decodificador inclui uma rede feed-forward totalmente conectada, aplicada a cada posição separadamente e de forma idêntica.
A jornada dos dados pelo modelo de transformador culmina com sua passagem por uma camada linear final, que funciona como um classificador.
O tamanho desse classificador corresponde ao número total de classes envolvidas (número de palavras contidas no vocabulário). Por exemplo, em um cenário com 1.000 classes distintas que representam 1.000 palavras diferentes, a saída do classificador será uma matriz com 1.000 elementos.
Essa saída é então introduzida em uma camada softmax, que a transforma em um intervalo de pontuações de probabilidade, cada uma entre 0 e 1. A maior dessas pontuações de probabilidade é a chave, e seu índice correspondente aponta diretamente para a palavra que o modelo prevê como a próxima na sequência.
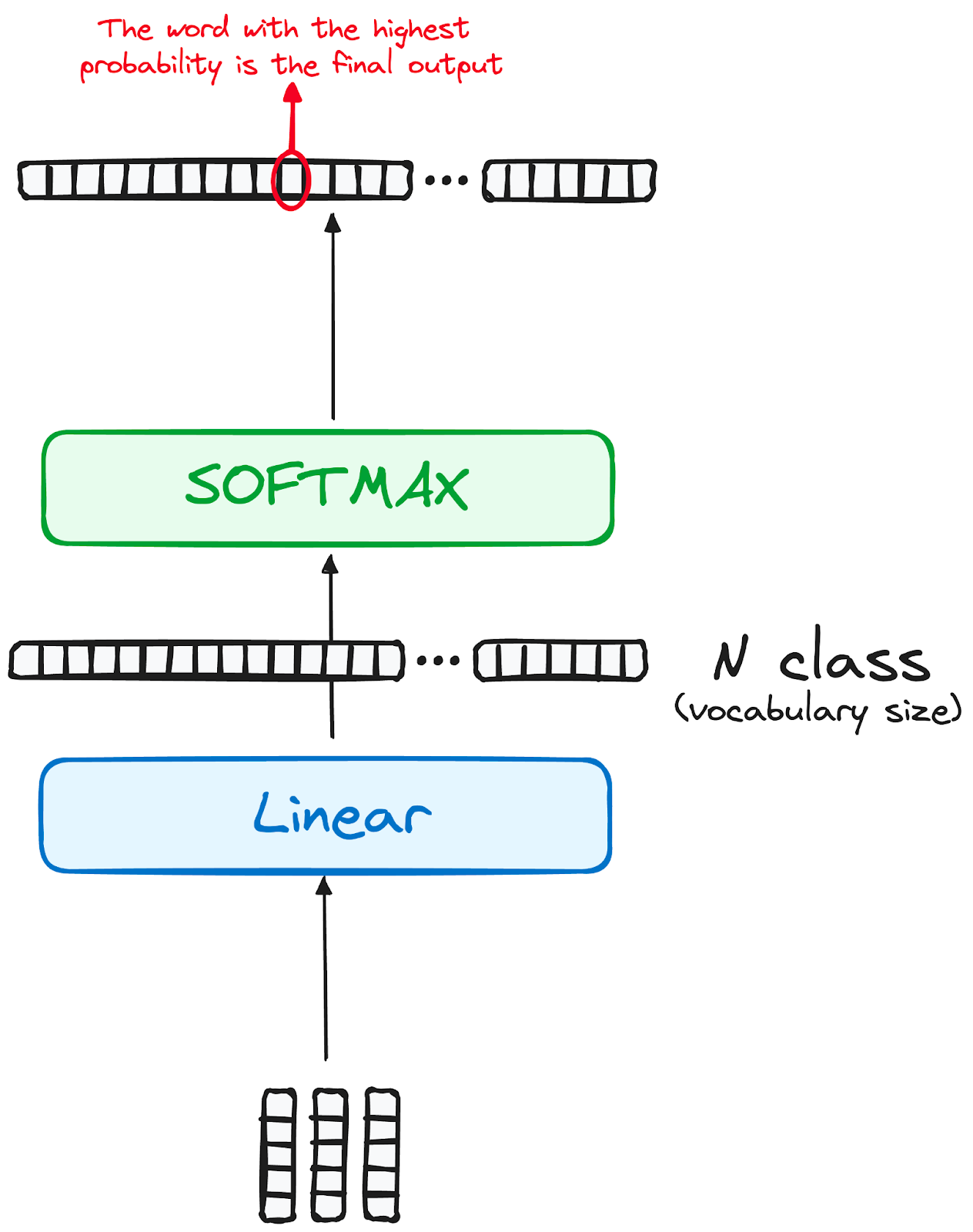
Imagem do autor. Fluxo de trabalho do decodificador. Saída final do transformador.
Cada subcamada (autoatenção mascarada, atenção do codificador-decodificador, rede feed-forward) é seguida por uma etapa de normalização, e cada uma também inclui uma conexão residual ao seu redor.
A saída da camada final é transformada em uma sequência prevista, normalmente por meio de uma camada linear seguida por um softmax para gerar probabilidades sobre o vocabulário.
O decodificador, em seu fluxo operacional, incorpora a saída recém-gerada em sua lista crescente de entradas e, em seguida, prossegue com o processo de decodificação. Esse ciclo se repete até que o modelo preveja um token específico, sinalizando a conclusão.
O token previsto com a maior probabilidade é atribuído como a classe de conclusão, geralmente representada pelo token final.
Novamente, lembre-se de que o decodificador não está limitado a uma única camada. Ele pode ser estruturado com N camadas, cada uma delas baseada na entrada recebida do codificador e de suas camadas anteriores. Essa arquitetura em camadas permite que o modelo diversifique seu foco e extraia padrões de atenção variados em suas cabeças de atenção.
Essa abordagem em várias camadas pode aumentar significativamente a capacidade de previsão do modelo, pois desenvolve uma compreensão mais detalhada das diferentes combinações de atenção.
E a arquitetura final é algo semelhante a isto (do artigo original)
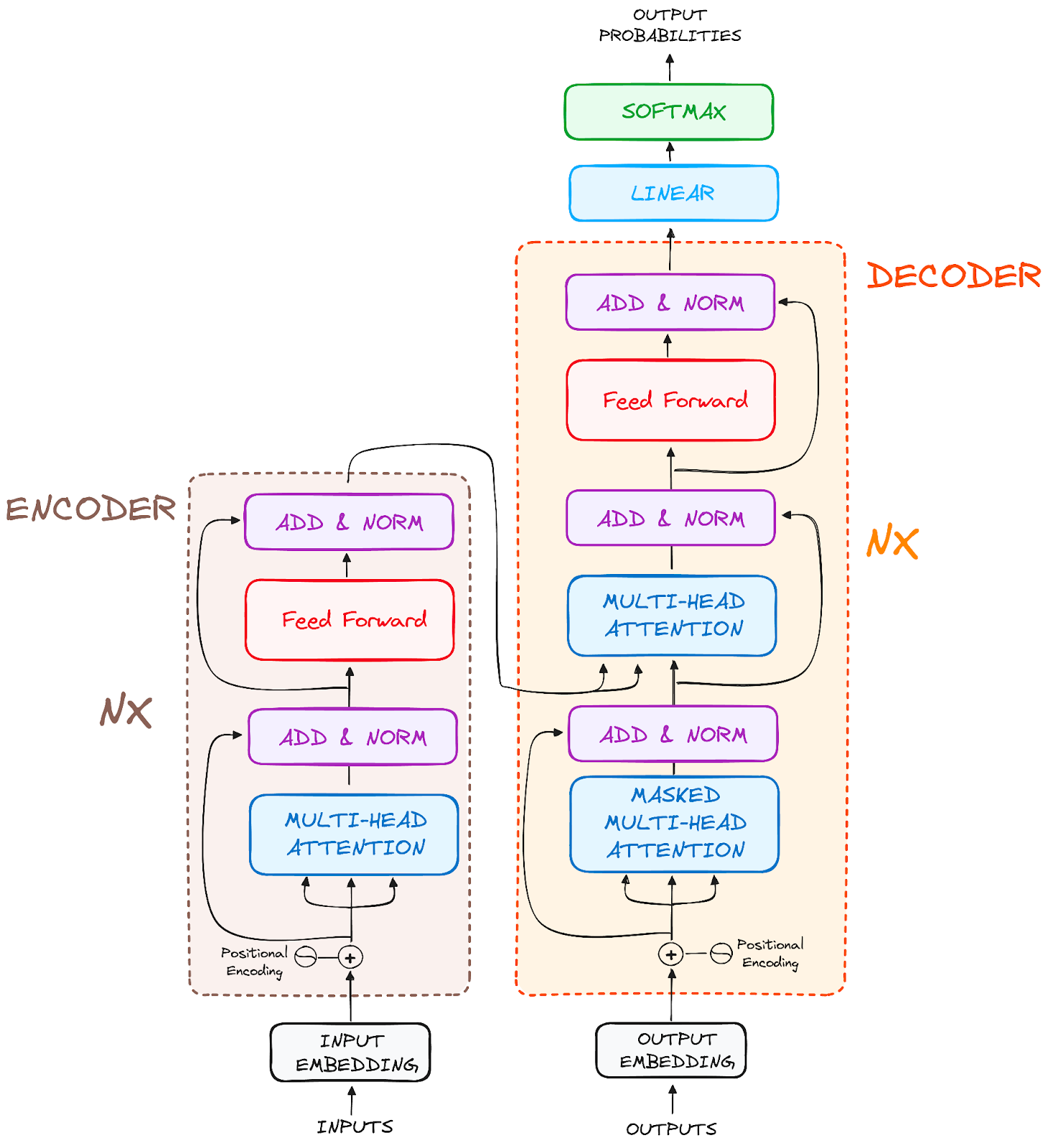
Imagem do autor. Estrutura original de Transformers.
Para entender melhor essa arquitetura, recomendo que você tente aplicar um Transformer do zero seguindo este tutorial para criar um transformer com o PyTorch.
O lançamento do BERT em 2018 pelo Google, uma estrutura de processamento de linguagem natural de código aberto, revolucionou o PLN com seu treinamento bidirecional exclusivo, que permite que o modelo tenha previsões mais informadas sobre o contexto da próxima palavra.
Ao compreender o contexto de todos os lados de uma palavra, o BERT superou os modelos anteriores em tarefas como responder a perguntas e compreender linguagem ambígua. Seu núcleo usa transformadores, conectando cada elemento de saída e entrada dinamicamente.
O BERT, pré-treinado na Wikipédia, foi excelente em várias tarefas de PNL, o que levou o Google a integrá-lo ao seu mecanismo de pesquisa para obter consultas mais naturais. Essa inovação provocou uma corrida para desenvolver modelos avançados de linguagem e aumentou significativamente a capacidade do campo de lidar com a compreensão de linguagem complexa.
Para saber mais sobre o BERT, você pode consultar nosso artigo separado que apresenta o modelo BERT.
O LaMDA (Modelo de linguagem para aplicativos de diálogo) é um modelo baseado no Transformer desenvolvido pelo Google, projetado especificamente para tarefas de conversação e lançado durante a apresentação do Google I/O de 2021. Eles são projetados para gerar respostas mais naturais e contextualmente relevantes, aprimorando as interações do usuário em vários aplicativos.
O design do LaMDA permite que ele compreenda e responda a uma ampla variedade de tópicos e intenções do usuário, o que o torna ideal para aplicações em chatbots, assistentes virtuais e outros sistemas interativos de IA em que uma conversa dinâmica é fundamental.
Esse foco na compreensão e na resposta de conversação marca o LaMDA como um avanço significativo no campo do processamento de linguagem natural e da comunicação orientada por IA.
Se estiver interessado em entender melhor os modelos LaMDA, você pode obter uma melhor compreensão com o artigo sobre LaMDA.
O GPT e o ChatGPT, desenvolvidos pela OpenAI, são modelos geradores avançados conhecidos por sua capacidade de produzir textos coerentes e contextualmente relevantes. O GPT-1 foi seu primeiro modelo lançado em junho de 2018 e o GPT-3, um dos modelos mais impactantes, foi lançado dois anos depois, em 2020.
Esses modelos são hábeis em uma ampla gama de tarefas, incluindo criação de conteúdo, conversação, tradução de idiomas e muito mais. A arquitetura do GPT permite que ele gere textos que se assemelham à escrita humana, o que o torna útil em aplicativos como escrita criativa, suporte ao cliente e até mesmo assistência de codificação. O ChatGPT, uma variante otimizada para contextos de conversação, é excelente na geração de diálogos semelhantes aos humanos, aprimorando sua aplicação em chatbots e assistentes virtuais.
O cenário dos modelos de fundação, especialmente os modelos de transformadores, está se expandindo rapidamente. Um estudo identificou mais de 50 modelos de transformadores importantes, enquanto o grupo de Stanford avaliou 30 deles, reconhecendo o crescimento acelerado do campo. O NLP Cloud, uma startup inovadora que faz parte do programa Inception da NVIDIA, utiliza cerca de 25 grandes modelos de linguagem comercialmente para vários setores, como companhias aéreas e farmácias.
Há uma tendência crescente de tornar esses modelos de código aberto, com plataformas como o hub de modelos da Hugging Face liderando o caminho. Além disso, foram desenvolvidos vários modelos baseados no Transformer, cada um especializado em diferentes tarefas de PNL, demonstrando a versatilidade e a eficiência do modelo em diversas aplicações.
Você pode saber mais sobre todos os modelos de fundação existentes em um artigo separado que fala sobre o que eles são e quais são os mais usados.
O benchmarking e a avaliação do desempenho dos modelos Transformer na PNL envolvem uma abordagem sistemática para avaliar sua eficácia e eficiência.
Dependendo da natureza da tarefa, há diferentes maneiras e recursos para fazer isso:
Ao lidar com tarefas de tradução automática, você pode aproveitar os conjuntos de dados padrão, como o WMT (Workshop on Machine Translation), em que os sistemas de tradução automática encontram uma tapeçaria de pares de idiomas, cada um oferecendo seus desafios exclusivos.
Métricas como BLEU, METEOR, TER e chrF servem como ferramentas de navegação, orientando-nos em direção à precisão e à fluência.
Além disso, os testes em diversos domínios, como notícias, literatura e textos técnicos, garantem a adaptabilidade e a versatilidade de um sistema de MT, tornando-o um verdadeiro poliglota no mundo digital.
Para avaliar os modelos de controle de qualidade, usamos coleções especiais de perguntas e respostas, como SQuAD (Stanford Question Answering Dataset), Natural Questions ou TriviaQA.
Cada um deles é como um jogo diferente com suas próprias regras. Por exemplo, o SQuAD trata de encontrar respostas em um determinado texto, enquanto outros são mais parecidos com um jogo de perguntas e respostas com perguntas de qualquer lugar.
Para ver o desempenho desses programas, usamos pontuações como Precision, Recall, F1 e, às vezes, até mesmo pontuações de correspondência exata.
Ao lidar com a inferência de linguagem natural (NLI), usamos conjuntos de dados especiais como SNLI (Stanford Natural Language Inference), MultiNLI e ANLI.
Essas são como grandes bibliotecas de variações de linguagem e casos complicados, que nos ajudam a ver como nossos computadores entendem diferentes tipos de frases. Verificamos principalmente a precisão dos computadores para entender se as declarações concordam, contradizem ou não estão relacionadas.
Também é importante observar como o computador descobre coisas complicadas do idioma, como quando uma palavra se refere a algo mencionado anteriormente, ou como você entende "não", "todos" e "alguns".
No mundo das redes neurais, duas estruturas importantes são geralmente comparadas a transformadores. Cada uma delas oferece benefícios e desafios distintos, adaptados a tipos específicos de processamento de dados. RNNs, que já apareceu várias vezes no artigo, e Camadas de Convulsão.
As camadas recorrentes, uma pedra angular das redes neurais recorrentes (RNNs), são excelentes para lidar com dados sequenciais. O ponto forte dessa arquitetura está em sua capacidade de realizar operações sequenciais, essenciais para tarefas como processamento de linguagem ou análise de séries temporais. Em uma camada recorrente, o resultado de uma etapa anterior é realimentado na rede como entrada para a próxima etapa. Esse mecanismo de looping permite que a rede se lembre de informações anteriores, o que é vital para a compreensão do contexto em uma sequência.
Entretanto, como já discutimos, esse processamento sequencial tem duas implicações principais:
Os modelos de transformadores diferem significativamente das arquiteturas que usam camadas recorrentes, pois não têm recorrência. Como vimos anteriormente, a camada de atenção do Transformer avalia ambos os problemas, tornando-os a evolução natural dos RNNs para aplicações de NLP.
Por outro lado, as camadas convolucionais, os blocos de construção das redes neurais convolucionais (CNNs), são conhecidas por sua eficiência no processamento de dados espaciais, como imagens.
Essas camadas usam kernels (filtros) que examinam os dados de entrada para extrair recursos. A largura desses núcleos pode ser ajustada, permitindo que a rede se concentre em recursos pequenos ou grandes, dependendo da tarefa em questão.
Embora as camadas convolucionais sejam excepcionalmente boas na captura de hierarquias e padrões espaciais nos dados, elas enfrentam desafios com dependências de longo prazo. Eles não consideram inerentemente as informações sequenciais, o que os torna menos adequados para tarefas que exigem a compreensão da ordem ou do contexto de uma sequência.
É por isso que as CNNs e os Transformers são adaptados para diferentes tipos de dados e tarefas. As CNNs dominam o campo da visão computacional devido à sua eficiência no processamento de informações espaciais, enquanto os Transformers são a opção ideal para tarefas sequenciais complexas, especialmente em PNL, devido à sua capacidade de entender dependências de longo alcance.
Em conclusão, os Transformers surgiram como um avanço monumental no campo da inteligência artificial e da PNL.
Ao gerenciar com eficiência os dados sequenciais por meio de seu mecanismo exclusivo de autoatenção, esses modelos superaram os RNNs tradicionais. Sua capacidade de lidar com sequências longas de forma mais eficiente e paralelizar o processamento de dados acelera significativamente o treinamento.
Modelos pioneiros como o BERT do Google e a série GPT da OpenAI exemplificam o impacto transformador dos Transformers no aprimoramento dos mecanismos de pesquisa e na geração de textos semelhantes aos humanos.
Como resultado, eles se tornaram indispensáveis no aprendizado de máquina moderno, impulsionando os limites da IA e abrindo novos caminhos para os avanços tecnológicos.
Se você quiser se aprofundar nos Transformers e em seu uso, nosso artigo sobre Transformers e Hugging Face é o começo perfeito! Você também pode aprender a criar um Transformer com o PyTorch com o nosso guia detalhado.
Saiba mais sobre transformadores e LLMs!
Curso
Curso
Curso
blog
Abid Ali Awan
11 min
blog
Natassha Selvaraj
15 min
blog
Moez Ali
11 min
Tutorial
Arjun Sarkar
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita



