
Programa
Fundamentos da IA
10 h
Após o lançamento da primeira versão do LLaMA pela Meta, houve uma nova corrida armamentista para criar melhores modelos de linguagem grande (LLMs) que pudessem competir com modelos como o GPT-3.5 (ChatGPT). A comunidade de código aberto lançou rapidamente modelos cada vez mais avançados. Parecia Natal para os entusiastas da IA, com novos desenvolvimentos anunciados com frequência.
No entanto, esses avanços tiveram suas desvantagens. A maioria dos modelos de código aberto tem licenciamento restrito, o que significa que só podem ser usados para fins de pesquisa. Em segundo lugar, somente grandes empresas ou institutos de pesquisa com orçamentos consideráveis poderiam se dar ao luxo de ajustar ou treinar os modelos. Por fim, a implantação e a manutenção de modelos de última geração de grande porte eram caras.
A nova versão dos modelos LLaMA tem como objetivo abordar esses problemas. Ele possui uma licença comercial, o que o torna acessível a mais organizações. Além disso, novas metodologias agora permitem o ajuste fino em GPUs de consumo com memória limitada.
Essa democratização da IA é fundamental para a adoção generalizada. Ao superar as barreiras de entrada, até mesmo as pequenas empresas podem criar modelos personalizados adequados às suas necessidades e orçamentos.
Neste tutorial, exploraremos o Llama-2 e demonstraremos como ajustá-lo em um novo conjunto de dados usando o Google Colab. Além disso, abordaremos novas metodologias e técnicas de ajuste fino que podem ajudar a reduzir o uso da memória e acelerar o processo de treinamento.

Imagem gerada pelo autor usando o DALL-E 3
O Llama 2 é uma coleção de LLMs de código aberto de segunda geração da Meta que vem com uma licença comercial. Ele foi projetado para lidar com uma ampla gama de tarefas de processamento de linguagem natural, com modelos que variam em escala de 7 bilhões a 70 bilhões de parâmetros. Para saber mais sobre os modelos LLaMA, leia nosso artigo, Introdução ao LLaMA da Meta AI: Capacitação da inovação em IA.
O Llama-2-Chat, que é otimizado para diálogo, apresentou desempenho semelhante aos modelos populares de código fechado, como o ChatGPT e o PaLM. Podemos até melhorar o desempenho do modelo ajustando-o em um conjunto de dados de conversação de alta qualidade.
O ajuste fino no aprendizado de máquina é o processo de ajustar os pesos e os parâmetros de um modelo pré-treinado em novos dados para melhorar seu desempenho em uma tarefa específica. Isso envolve o treinamento do modelo em um novo conjunto de dados específico para a tarefa em questão e a atualização dos pesos do modelo para se adaptar aos novos dados. Leia mais sobre o ajuste fino seguindo nosso guia de ajuste fino do GPT 3.5.
É impossível fazer o ajuste fino dos LLMs no hardware do consumidor devido à inadequação das VRAMs e da computação. No entanto, neste tutorial, superaremos esses desafios de memória e computação e treinaremos nosso modelo usando uma versão gratuita do Google Colab Notebook.
Nesta parte, conheceremos todas as etapas necessárias para fazer o ajuste fino do modelo Llama 2 com 7 bilhões de parâmetros em uma GPU T4. Você tem a opção de usar uma GPU gratuita no Google Colab ou no Kaggle. O código é executado em ambas as plataformas.
A GPU Colab T4 tem um limite de 16 GB de VRAM. Isso mal é suficiente para armazenar os pesos da Llama 2-7b, o que significa que não é possível fazer um ajuste fino completo, e precisamos usar técnicas de ajuste fino eficientes em termos de parâmetros, como LoRA ou QLoRA.
Usaremos a técnica QLoRA para ajustar o modelo com precisão de 4 bits e otimizar o uso da VRAM. Para isso, usaremos o ecossistema Hugging Face das bibliotecas LLM: transformers accelerate , peft, trl, e bitsandbytes.
Começaremos instalando as bibliotecas necessárias.
%%capture
%pip install accelerate peft bitsandbytes transformers trlDepois disso, carregaremos os módulos necessários a partir dessas bibliotecas.
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig
from trl import SFTTrainerVocê pode acessar o modelo oficial do Llama-2 da Meta na Hugging Face, mas precisa solicitar um pedido e aguardar alguns dias para obter a confirmação. Em vez de esperar, usaremos o Llama-2-7b-chat-hf da NousResearch como nosso modelo básico. É o mesmo que o original, mas de fácil acesso.
Imagem de Hugging Face
Faremos o ajuste fino do nosso modelo básico usando um conjunto de dados menor chamado mlabonne/guanaco-llama2-1k e escreveremos o nome do modelo ajustado.
# Model from Hugging Face hub
base_model = "NousResearch/Llama-2-7b-chat-hf"
# New instruction dataset
guanaco_dataset = "mlabonne/guanaco-llama2-1k"
# Fine-tuned model
new_model = "llama-2-7b-chat-guanaco"
Conjunto de dados em Hugging Face
Carregaremos o conjunto de dados "guanaco-llama2-1k" do hub Hugging Face. O conjunto de dados contém 1.000 amostras e foi processado para corresponder ao formato de prompt do Llama 2, e é um subconjunto do excelente conjunto de dados timdettmers/openassistant-guanaco.
dataset = load_dataset(guanaco_dataset, split="train")Dataset parquet downloaded and prepared to /root/.cache/huggingface/datasets/parquet/mlabonne--guanaco-llama2-1k-f1f1134768f90029/0.0.0/0b6d5799bb726b24ad7fc7be720c170d8e497f575d02d47537de9a5bac074901. Subsequent calls will reuse this data.A quantização de 4 bits por meio do QLoRA permite o ajuste fino eficiente de modelos LLM enormes no hardware do consumidor, mantendo o alto desempenho. Isso melhora drasticamente a acessibilidade e a usabilidade para aplicativos do mundo real.
O QLoRA quantiza um modelo de linguagem pré-treinado para 4 bits e congela os parâmetros. Em seguida, um pequeno número de camadas de adaptador de classificação baixa treináveis é adicionado ao modelo.
Durante o ajuste fino, os gradientes são retropropagados por meio do modelo quantizado de 4 bits congelado apenas nas camadas do adaptador de classificação baixa. Assim, todo o modelo pré-treinado permanece fixo em 4 bits, enquanto apenas os adaptadores são atualizados. Além disso, a quantização de 4 bits não prejudica o desempenho do modelo.
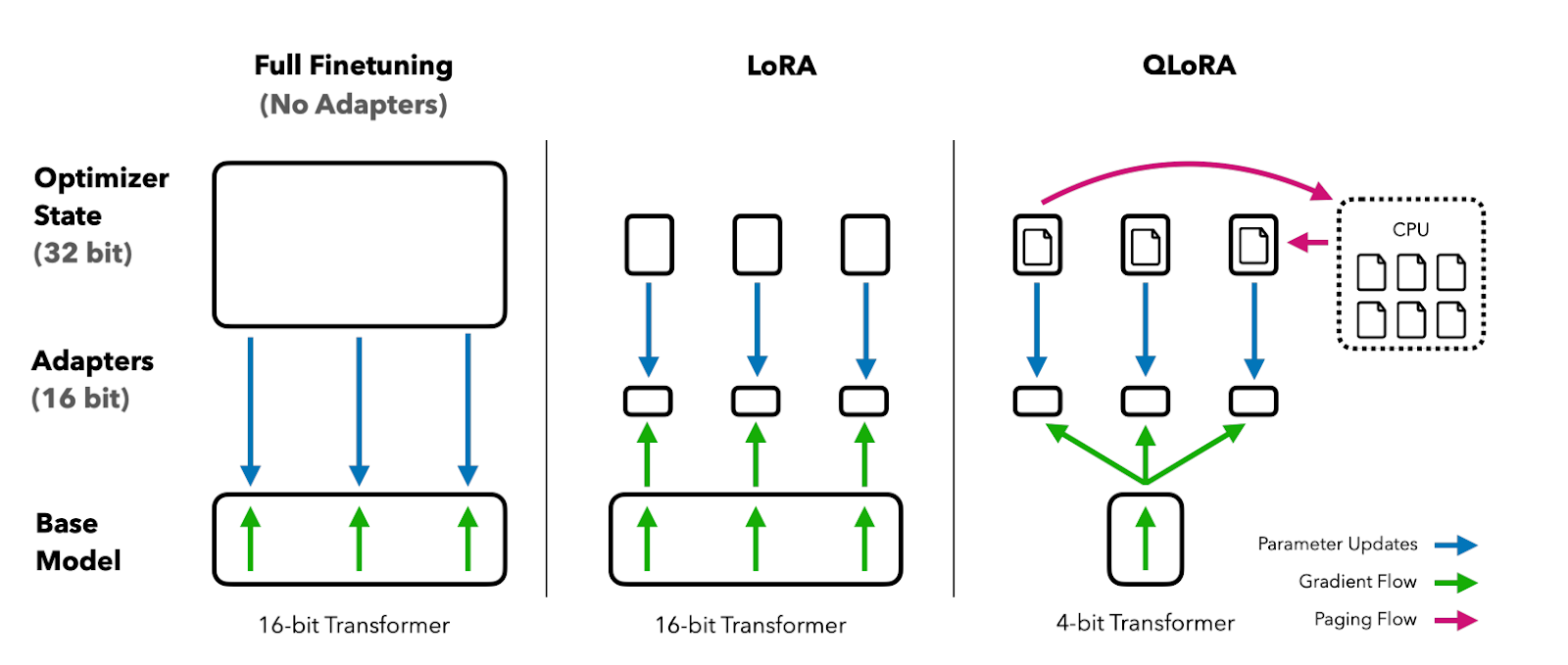
Imagem do documento QLoRA
Você pode ler o documento para entendê-lo melhor.
No nosso caso, criamos uma quantização de 4 bits com configuração do tipo NF4 usando BitsAndBytes.
compute_dtype = getattr(torch, "float16")
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)Agora, carregaremos um modelo usando precisão de 4 bits com o tipo de computação "float16" do Hugging Face para um treinamento mais rápido.
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=quant_config,
device_map={"": 0}
)
model.config.use_cache = False
model.config.pretraining_tp = 1Em seguida, carregaremos o tokenizador do Hugginface e definiremos padding_side como "right" para corrigir o problema com fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"O ajuste fino tradicional de modelos de linguagem (PLMs) pré-treinados exige a atualização de todos os parâmetros do modelo, o que é computacionalmente caro e requer grandes quantidades de dados.
O Parameter-Efficient Fine-Tuning (PEFT) funciona atualizando apenas um pequeno subconjunto dos parâmetros mais influentes do modelo, o que o torna muito mais eficiente. Para saber mais sobre os parâmetros, leia a documentação oficial do PEFT.
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)Abaixo está uma lista de hiperparâmetros que podem ser usados para otimizar o processo de treinamento:
training_params = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="tensorboard"
)O ajuste fino supervisionado (SFT) é uma etapa fundamental do aprendizado por reforço a partir de feedback humano (RLHF). A biblioteca TRL da HuggingFace fornece uma API fácil de usar para criar modelos SFT e treiná-los em seu conjunto de dados com apenas algumas linhas de código. Ele vem com ferramentas para treinar modelos de linguagem usando o aprendizado por reforço, começando com o ajuste fino supervisionado, depois com a modelagem de recompensa e, por fim, com a otimização de política proximal (PPO).
Forneceremos ao SFT Trainer o modelo, o conjunto de dados, a configuração do Lora, o tokenizador e os parâmetros de treinamento.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_params,
dataset_text_field="text",
max_seq_length=None,
tokenizer=tokenizer,
args=training_params,
packing=False,
)Usaremos o site .train() para fazer o ajuste fino do modelo Llama 2 em um novo conjunto de dados. O modelo levou uma hora e meia para concluir uma época.

Depois de treinar o modelo, salvaremos o adotador do modelo e os tokenizadores. Você também pode carregar o modelo no Hugging Face usando uma API semelhante.
trainer.model.save_pretrained(new_model)
trainer.tokenizer.save_pretrained(new_model)
Agora podemos analisar os resultados do treinamento na sessão interativa do Tensorboard.
from tensorboard import notebook
log_dir = "results/runs"
notebook.start("--logdir {} --port 4000".format(log_dir))
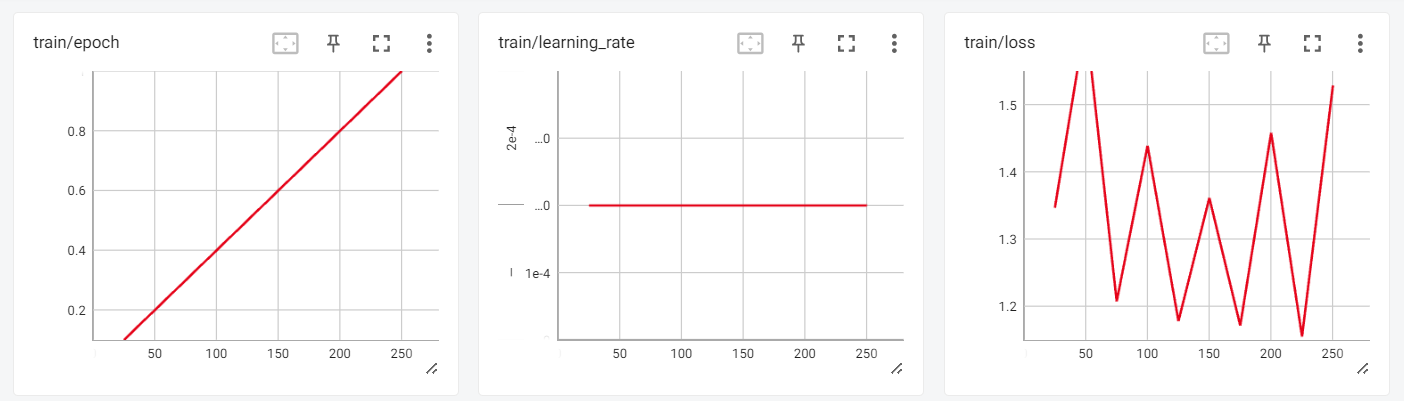
Para testar nosso modelo ajustado, usaremos o pipeline de geração de texto transformers e faremos perguntas simples como "Quem é Leonardo Da Vinci?".
logging.set_verbosity(logging.CRITICAL)
prompt = "Who is Leonardo Da Vinci?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Saída:
Como você pode ver, obtivemos resultados surpreendentes.
<s>[INST] Who is Leonardo Da Vinci? [/INST] Leonardo da Vinci (1452-1519) was an Italian polymath, artist, inventor, and engineer.
Da Vinci is widely considered one of the greatest painters of all time, and his works include the famous Mona Lisa. He was also an accomplished engineer, inventor, and anatomist, and his designs for machines and flight were centuries ahead of his time.
Da Vinci was born in the town of Vinci, Italy, and he was the illegitimate son of a local notary. Despite his humble origins, he was able to study art and engineering in Florence, and he became a renowned artist and inventor.
Da Vinci's work had a profound impact on the Renaissance, and his legacy continues to inspire artists, engineers, and inventors to this day. He
Vamos fazer outra pergunta.
prompt = "What is Datacamp Career track?"
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Saída:
O Guanaco é um conjunto de dados de alta qualidade que foi usado para ajustar os LLMs de última geração no passado. Todo o conjunto de dados Guanaco está disponível no Hugging Face e tem o potencial de alcançar um desempenho ainda maior em uma variedade de tarefas de linguagem natural.
<s>[INST] What is Datacamp Career track? [/INST] DataCamp Career Track is a program that offers a comprehensive learning experience to help you build your skills and prepare for a career in data science.
The program includes a range of courses, projects, and assessments that are designed to help you build your skills in data science. You will learn how to work with data, create visualizations, and build predictive models.
In addition to the technical skills, you will also learn how to communicate your findings to stakeholders and how to work with a team to solve complex problems.
The program is designed to be flexible, so you can learn at your own pace and on your own schedule. You will also have access to a community of learners and mentors who can provide support and guidance throughout the program.
Overall, DataCamp Career Track is a great way to build your skills and prepare for a career inAqui está o Colab Notebook com o código e os resultados para ajudar você em sua jornada de codificação.
Em seguida, você pode usar o LlamaIndex e criar seu próprio aplicativo de IA usando seu novo modelo de treinamento seguindo o site LlamaIndex: Adicionando dados pessoais aos LLMs tutorial. Você pode se inspirar para o seu projeto conferindo 5 projetos criados com modelos generativos e ferramentas de código aberto.
O tutorial forneceu um guia abrangente sobre o ajuste fino do modelo LLaMA 2 usando técnicas como QLoRA, PEFT e SFT para superar as limitações de memória e computação. Aproveitando as bibliotecas Hugging Face, como transformers, accelerate, peft, trl e bitsandbytes, conseguimos fazer o ajuste fino do modelo LLaMA 2 de 7B parâmetros em uma GPU de consumo.
De modo geral, esse tutorial exemplificou como os avanços recentes possibilitaram a democratização e a acessibilidade de grandes modelos de linguagem, permitindo que até mesmo amadores criem IA de última geração com recursos limitados.
Se você não tem experiência com modelos de linguagem grandes, considere fazer o curso Master LLMs Concepts. E se você quiser começar sua carreira em inteligência artificial, deve se inscrever no curso de habilidades AI Fundamentals.
Comece sua jornada de IA hoje mesmo!
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali


