Curso
Introdução a Deep Learning em Python
4 h
263.5K
Talvez você já tenha ouvido falar de reconhecimento facial ou de imagem ou de carros autônomos. Essas são implementações reais de redes neurais convolucionais (CNNs). Nesta postagem do blog, você aprenderá e entenderá como implementar essas redes neurais artificiais profundas e feed-forward no Keras e também como superar o overfitting com a técnica de regularização chamada "dropout".
Mais especificamente, você abordará os seguintes tópicos no tutorial de hoje:
Você gostaria de fazer um curso sobre Keras e aprendizagem profunda em Python? Considere fazer o curso Aprendizado profundo em Python da DataCamp!
Além disso, não perca nossa folha de dicas sobre o Keras, que mostra as seis etapas que você precisa seguir para criar redes neurais em Python com exemplos de código!
A esta altura, você já deve conhecer o aprendizado de máquina e o aprendizado profundo, um ramo da ciência da computação que estuda o design de algoritmos que podem aprender. A aprendizagem profunda é um subcampo da aprendizagem automática inspirado em redes neurais artificiais, que, por sua vez, são inspiradas em redes neurais biológicas.
Um tipo específico de rede neural profunda é a rede convolucional, comumente chamada de CNN ou ConvNet. Trata-se de uma rede neural artificial profunda e de avanço. Lembre-se de que as redes neurais feed-forward também são chamadas de perceptrons multicamadas (MLPs), que são os modelos de aprendizagem profunda por excelência. Os modelos são chamados de "feed-forward" porque as informações fluem diretamente pelo modelo. Não há conexões de feedback nas quais os resultados do modelo são realimentados para ele mesmo.
As CNNs são inspiradas especificamente no córtex visual biológico. O córtex tem pequenas regiões de células que são sensíveis a áreas específicas do campo visual. Essa ideia foi expandida por um experimento cativante feito por Hubel e Wiesel em 1962 (se você quiser saber mais, aqui está um vídeo). Nesse experimento, os pesquisadores mostraram que alguns neurônios individuais no cérebro eram ativados ou disparados somente na presença de bordas de uma orientação específica, como bordas verticais ou horizontais. Por exemplo, alguns neurônios dispararam quando expostos a lados verticais e outros quando lhes foi mostrada uma borda horizontal. Hubel e Wiesel descobriram que todos esses neurônios estavam bem ordenados de forma colunar e que, juntos, eram capazes de produzir a percepção visual. Essa ideia de componentes especializados dentro de um sistema com tarefas específicas é uma ideia que as máquinas também usam e que você também pode encontrar nas CNNs.
As redes neurais convolucionais têm sido uma das inovações mais influentes no campo da visão computacional. Eles tiveram um desempenho muito melhor do que a visão computacional tradicional e produziram resultados de última geração. Essas redes neurais provaram ser bem-sucedidas em muitos estudos de caso e aplicações reais diferentes, como:
Para entender esse sucesso, você terá que voltar a 2012, o ano em que Alex Krizhevsky usou redes neurais convolucionais para vencer a competição ImageNet daquele ano, reduzindo o erro de classificação de 26% para 15%.
Observe que o ImageNet Large Scale Visual Recognition Challenge (ILSVRC), iniciado no ano de 2010, é uma competição anual em que as equipes de pesquisa avaliam seus algoritmos no conjunto de dados fornecido e competem para obter maior precisão em várias tarefas de reconhecimento visual.
Foi nessa época que as redes neurais voltaram a ganhar destaque depois de um bom tempo. Isso costuma ser chamado de "terceira onda das redes neurais". As outras duas ondas ocorreram entre as décadas de 1940 e 1960 e entre as décadas de 1970 e 1980.
Tudo bem, você sabe que trabalhará com redes feed-forward inspiradas no córtex visual biológico, mas o que isso realmente significa?
Dê uma olhada na imagem abaixo:
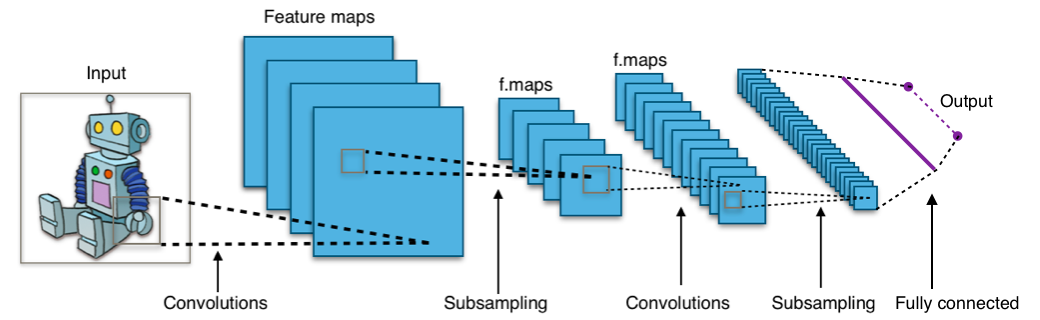
A imagem mostra que você alimenta uma imagem como entrada para a rede, que passa por várias convoluções, subamostragem, uma camada totalmente conectada e, por fim, produz algo.
Mas o que são todos esses conceitos?
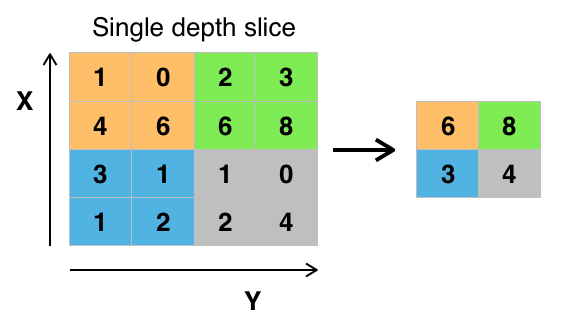
Para obter mais informações, você pode acessar aqui.
Antes de ir em frente e carregar os dados, é bom dar uma olhada no que você vai fazer exatamente! O conjunto de dados Fashion-MNIST é um conjunto de dados de imagens de artigos da Zalando, com imagens em escala de cinza 28x28 de 70.000 produtos de moda de 10 categorias e 7.000 imagens por categoria. O conjunto de treinamento tem 60.000 imagens e o conjunto de teste tem 10.000 imagens. Você pode verificar isso mais tarde, quando tiver carregado seus dados!)
O Fashion-MNIST é semelhante ao conjunto de dados MNIST que você talvez já conheça e que é usado para classificar dígitos manuscritos. Isso significa que as dimensões da imagem e as divisões de treinamento e teste são semelhantes às do conjunto de dados MNIST. Dica: se você quiser saber como implementar um MLP (Multi-Layer Perceptron) para tarefas de classificação com esse último conjunto de dados, acesse este tutorial de aprendizagem profunda com o Keras.
Você pode encontrar o conjunto de dados Fashion-MNIST aqui, mas também pode carregá-lo com a ajuda de módulos específicos do TensorFlow e do Keras. Você verá como isso funciona na próxima seção!
O Keras vem com uma biblioteca chamada datasets, que pode ser usada para carregar conjuntos de dados imediatamente: você baixa os dados do servidor e acelera o processo, pois não precisa mais fazer o download dos dados para o seu computador. As imagens de treinamento e teste, juntamente com os rótulos, são carregadas e armazenadas nas variáveis train_X, train_Y, test_X, test_Y, respectivamente.
from keras.datasets import fashion_mnist
(train_X,train_Y), (test_X,test_Y) = fashion_mnist.load_data()
Using TensorFlow backend.
Ótimo! Isso foi muito simples, não foi?
Você provavelmente já fez isso um milhão de vezes, mas é sempre uma etapa essencial para começar. Agora você está totalmente pronto para começar a analisar, processar e modelar seus dados!
Vamos agora analisar a aparência das imagens no conjunto de dados. Mesmo que você já saiba a dimensão das imagens, ainda vale a pena analisá-las programaticamente: talvez seja necessário redimensionar os pixels da imagem e redimensionar as imagens.
import numpy as np
from keras.utils import to_categorical
import matplotlib.pyplot as plt
%matplotlib inline
print('Training data shape : ', train_X.shape, train_Y.shape)
print('Testing data shape : ', test_X.shape, test_Y.shape)
('Training data shape : ', (60000, 28, 28), (60000,))
('Testing data shape : ', (10000, 28, 28), (10000,))
Na saída acima, você pode ver que os dados de treinamento têm um formato de 60000 x 28 x 28, pois há 60.000 amostras de treinamento, cada uma com dimensão de 28 x 28. Da mesma forma, os dados de teste têm um formato de 10.000 x 28 x 28, pois há 10.000 amostras de teste.
# Find the unique numbers from the train labels
classes = np.unique(train_Y)
nClasses = len(classes)
print('Total number of outputs : ', nClasses)
print('Output classes : ', classes)
('Total number of outputs : ', 10)
('Output classes : ', array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8))
Há também um total de dez classes de saída que variam de 0 a 9.
Além disso, não se esqueça de dar uma olhada nas imagens do seu conjunto de dados:
plt.figure(figsize=[5,5])
# Display the first image in training data
plt.subplot(121)
plt.imshow(train_X[0,:,:], cmap='gray')
plt.title("Ground Truth : {}".format(train_Y[0]))
# Display the first image in testing data
plt.subplot(122)
plt.imshow(test_X[0,:,:], cmap='gray')
plt.title("Ground Truth : {}".format(test_Y[0]))
Text(0.5,1,u'Ground Truth : 9')
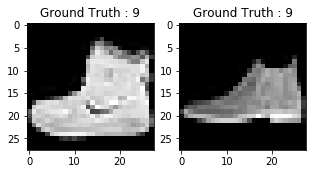
A saída dos dois gráficos acima se parece com uma bota de cano alto, e essa classe recebe um rótulo de classe 9. Da mesma forma, outros produtos de moda terão etiquetas diferentes, mas produtos semelhantes terão as mesmas etiquetas. Isso significa que todas as 7.000 imagens de botas de tornozelo terão um rótulo de classe 9.
Como você pode ver no gráfico acima, as imagens são em escala de cinza e têm valores de pixel que variam de 0 a 255. Além disso, essas imagens têm uma dimensão de 28 x 28. Como resultado, você precisará pré-processar os dados antes de alimentá-los no modelo.
train_X = train_X.reshape(-1, 28,28, 1)
test_X = test_X.reshape(-1, 28,28, 1)
train_X.shape, test_X.shape
((60000, 28, 28, 1), (10000, 28, 28, 1))
train_X = train_X.astype('float32')
test_X = test_X.astype('float32')
train_X = train_X / 255.
test_X = test_X / 255.
Na codificação one-hot, você converte os dados categóricos em um vetor de números. O motivo pelo qual você converte os dados categóricos em uma codificação quente é que os algoritmos de aprendizado de máquina não podem trabalhar diretamente com dados categóricos. Você gera uma coluna booleana para cada categoria ou classe. Apenas uma dessas colunas poderia assumir o valor 1 para cada amostra. Por isso, o termo codificação one-hot.
Para o enunciado do seu problema, a codificação a quente será um vetor de linhas e, para cada imagem, terá uma dimensão de 1 x 10. O importante a ser observado aqui é que o vetor consiste em todos os zeros, exceto para a classe que ele representa e, para isso, é 1. Por exemplo, a imagem da bota de tornozelo que você plotou acima tem um rótulo de 9, portanto, para todas as imagens de bota de tornozelo, o único vetor de codificação quente seria [0 0 0 0 0 0 0 0 1 0].
Portanto, vamos converter os rótulos de treinamento e teste em vetores de codificação de um único disparo:
# Change the labels from categorical to one-hot encoding
train_Y_one_hot = to_categorical(train_Y)
test_Y_one_hot = to_categorical(test_Y)
# Display the change for category label using one-hot encoding
print('Original label:', train_Y[0])
print('After conversion to one-hot:', train_Y_one_hot[0])
('Original label:', 9)
('After conversion to one-hot:', array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]))
Isso está bem claro, certo? Observe que você também pode imprimir o site train_Y_one_hot, que exibirá uma matriz de tamanho 60000 x 10, na qual cada linha representa a codificação de uma imagem em um único disparo.
from sklearn.model_selection import train_test_split
train_X,valid_X,train_label,valid_label = train_test_split(train_X, train_Y_one_hot, test_size=0.2, random_state=13)
Pela última vez, vamos verificar a forma do conjunto de treinamento e validação.
train_X.shape,valid_X.shape,train_label.shape,valid_label.shape
((48000, 28, 28, 1), (12000, 28, 28, 1), (48000, 10), (12000, 10))
As imagens são de tamanho 28 x 28. Você converte a matriz da imagem em uma matriz, redimensiona-a entre 0 e 1, remodela-a de modo que ela tenha o tamanho 28 x 28 x 1 e a alimenta como entrada para a rede.
Você usará três camadas convolucionais:
Além disso, há três camadas de pooling máximo, cada uma com tamanho 2 x 2.
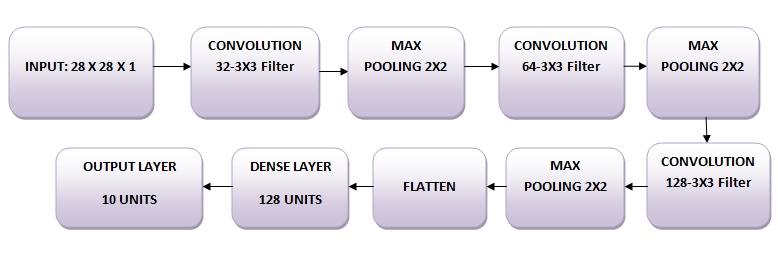
Primeiro, vamos importar todos os módulos necessários para treinar o modelo.
import keras
from keras.models import Sequential,Input,Model
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.layers.advanced_activations import LeakyReLU
Você usará um tamanho de lote de 64, mas também é preferível usar um tamanho de lote maior, de 128 ou 256, tudo depende da memória. Isso contribui enormemente para determinar os parâmetros de aprendizado e afeta a precisão da previsão. Você treinará a rede por 20 épocas.
batch_size = 64
epochs = 20
num_classes = 10
No Keras, você pode simplesmente empilhar camadas adicionando a camada desejada uma a uma. É exatamente isso que você fará aqui: primeiro você adicionará uma primeira camada convolucional com Conv2D(). Observe que você usa essa função porque está trabalhando com imagens! Em seguida, você adiciona a função de ativação Leaky ReLU, que ajuda a rede a aprender limites de decisão não lineares. Como você tem dez classes diferentes, precisará de um limite de decisão não linear que possa separar essas dez classes que não são linearmente separáveis.
Mais especificamente, você adiciona ReLUs com vazamento porque elas tentam corrigir o problema das ReLUs (Rectified Linear Units) que estão morrendo. A função de ativação ReLU é muito usada em arquiteturas de redes neurais e, mais especificamente, em redes convolucionais, onde se provou ser mais eficaz do que a função sigmoide logística amplamente usada. A partir de 2017, essa função de ativação é a mais popular para redes neurais profundas. A função ReLU permite que a ativação seja limitada a zero. No entanto, durante o treinamento, as unidades ReLU podem "morrer". Isso pode acontecer quando um grande gradiente flui por um neurônio ReLU: ele pode fazer com que os pesos sejam atualizados de tal forma que o neurônio nunca mais será ativado em nenhum ponto de dados. Se isso acontecer, o gradiente que flui pela unidade será sempre zero a partir desse ponto. As ReLUs com vazamento tentam resolver isso: a função não será zero, mas terá uma pequena inclinação negativa.
Em seguida, você adicionará a camada de pooling máximo com MaxPooling2D() e assim por diante. A última camada é uma camada densa que tem uma função de ativação softmax com 10 unidades, que é necessária para esse problema de classificação multiclasse.
fashion_model = Sequential()
fashion_model.add(Conv2D(32, kernel_size=(3, 3),activation='linear',input_shape=(28,28,1),padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D((2, 2),padding='same'))
fashion_model.add(Conv2D(64, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Conv2D(128, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Flatten())
fashion_model.add(Dense(128, activation='linear'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(Dense(num_classes, activation='softmax'))
Depois que o modelo for criado, você o compilará usando o otimizador Adam, um dos algoritmos de otimização mais populares. Você pode ler mais sobre esse otimizador aqui. Além disso, você especifica o tipo de perda, que é a entropia cruzada categórica, usada para classificação multiclasse; você também pode usar a entropia cruzada binária como função de perda. Por fim, você especifica as métricas de precisão que deseja analisar enquanto o modelo está sendo treinado.
fashion_model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(),metrics=['accuracy'])
Vamos visualizar as camadas que você criou na etapa acima usando a função de resumo. Isso mostrará alguns parâmetros (pesos e polarizações) em cada camada e também o total de parâmetros em seu modelo.
fashion_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_51 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
leaky_re_lu_57 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
max_pooling2d_49 (MaxPooling (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_52 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
leaky_re_lu_58 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_50 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_53 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
leaky_re_lu_59 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
max_pooling2d_51 (MaxPooling (None, 4, 4, 128) 0
_________________________________________________________________
flatten_17 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_33 (Dense) (None, 128) 262272
_________________________________________________________________
leaky_re_lu_60 (LeakyReLU) (None, 128) 0
_________________________________________________________________
dense_34 (Dense) (None, 10) 1290
=================================================================
Total params: 356,234
Trainable params: 356,234
Non-trainable params: 0
_________________________________________________________________
Finalmente, chegou a hora de treinar o modelo com a função fit() do Keras! O modelo é treinado por 20 épocas. A função fit() retornará um objeto history. Ao armazenar o resultado dessa função em fashion_train, você poderá usá-lo posteriormente para traçar os gráficos de precisão e de função de perda entre o treinamento e a validação, o que o ajudará a analisar visualmente o desempenho do seu modelo.
fashion_train = fashion_model.fit(train_X, train_label, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(valid_X, valid_label))
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.4661 - acc: 0.8311 - val_loss: 0.3320 - val_acc: 0.8809
Epoch 2/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.2874 - acc: 0.8951 - val_loss: 0.2781 - val_acc: 0.8963
Epoch 3/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.2420 - acc: 0.9111 - val_loss: 0.2501 - val_acc: 0.9077
Epoch 4/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.2088 - acc: 0.9226 - val_loss: 0.2369 - val_acc: 0.9147
Epoch 5/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1838 - acc: 0.9324 - val_loss: 0.2602 - val_acc: 0.9070
Epoch 6/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1605 - acc: 0.9396 - val_loss: 0.2264 - val_acc: 0.9193
Epoch 7/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1356 - acc: 0.9488 - val_loss: 0.2566 - val_acc: 0.9180
Epoch 8/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1186 - acc: 0.9553 - val_loss: 0.2556 - val_acc: 0.9149
Epoch 9/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0985 - acc: 0.9634 - val_loss: 0.2681 - val_acc: 0.9204
Epoch 10/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0873 - acc: 0.9670 - val_loss: 0.2712 - val_acc: 0.9221
Epoch 11/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0739 - acc: 0.9721 - val_loss: 0.2757 - val_acc: 0.9202
Epoch 12/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0628 - acc: 0.9767 - val_loss: 0.3126 - val_acc: 0.9132
Epoch 13/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0569 - acc: 0.9789 - val_loss: 0.3556 - val_acc: 0.9081
Epoch 14/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0452 - acc: 0.9833 - val_loss: 0.3441 - val_acc: 0.9189
Epoch 15/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0421 - acc: 0.9847 - val_loss: 0.3400 - val_acc: 0.9165
Epoch 16/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0379 - acc: 0.9861 - val_loss: 0.3876 - val_acc: 0.9195
Epoch 17/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0405 - acc: 0.9855 - val_loss: 0.4112 - val_acc: 0.9164
Epoch 18/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0285 - acc: 0.9897 - val_loss: 0.4150 - val_acc: 0.9181
Epoch 19/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0322 - acc: 0.9877 - val_loss: 0.4584 - val_acc: 0.9196
Epoch 20/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0262 - acc: 0.9906 - val_loss: 0.4396 - val_acc: 0.9205
Finalmente! Você treinou o modelo no fashion-MNIST por 20 épocas e, observando a precisão e a perda do treinamento, pode dizer que o modelo fez um bom trabalho, pois após 20 épocas a precisão do treinamento é de 99% e a perda do treinamento é bastante baixa.
No entanto, parece que o modelo está se ajustando demais, pois a perda de validação é de 0,4396 e a precisão da validação é de 92%. O ajuste excessivo dá a intuição de que a rede memorizou muito bem os dados de treinamento, mas não tem garantia de funcionar em dados não vistos, e é por isso que há uma diferença na precisão do treinamento e da validação.
Você provavelmente precisará lidar com isso. Nas próximas seções, você aprenderá como fazer com que seu modelo tenha um desempenho muito melhor adicionando uma camada de Dropout à rede e mantendo todas as outras camadas inalteradas.
Mas, primeiro, vamos avaliar o desempenho do seu modelo no conjunto de testes antes de você chegar a uma conclusão.
test_eval = fashion_model.evaluate(test_X, test_Y_one_hot, verbose=0)
print('Test loss:', test_eval[0])
print('Test accuracy:', test_eval[1])
('Test loss:', 0.46366268818555401)
('Test accuracy:', 0.91839999999999999)
A precisão do teste parece impressionante. Acontece que o seu classificador se sai melhor do que o benchmark relatado aqui, que é um classificador SVM com precisão média de 0,897. Além disso, o modelo se sai bem em comparação com alguns dos modelos de aprendizagem profunda mencionados no perfil do GitHub dos criadores do conjunto de dados fashion-MNIST.
No entanto, você viu que o modelo parecia estar se ajustando demais. Esses resultados são realmente tão bons assim?
Vamos colocar a avaliação do seu modelo em perspectiva e traçar os gráficos de precisão e perda entre os dados de treinamento e validação:
accuracy = fashion_train.history['acc']
val_accuracy = fashion_train.history['val_acc']
loss = fashion_train.history['loss']
val_loss = fashion_train.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
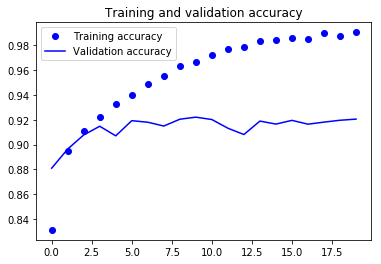
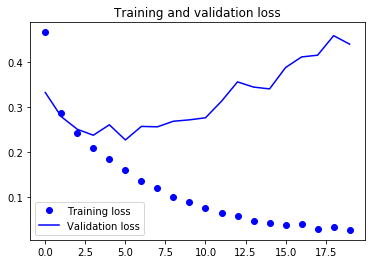
Nos dois gráficos acima, você pode ver que a precisão da validação quase estagnou após 4-5 épocas e raramente aumentou em determinadas épocas. No início, a precisão da validação estava aumentando linearmente com a perda, mas depois não aumentou muito.
A perda de validação mostra que esse é um sinal de ajuste excessivo, semelhante à precisão da validação, que diminuiu linearmente, mas depois de 4-5 épocas, começou a aumentar. Isso significa que o modelo tentou memorizar os dados e conseguiu.
Com isso em mente, é hora de introduzir um pouco de dropout em nosso modelo e ver se isso ajuda a reduzir o ajuste excessivo.
Você pode adicionar uma camada de abandono para superar o problema de sobreajuste até certo ponto. O abandono desliga aleatoriamente uma fração dos neurônios durante o processo de treinamento, reduzindo a dependência do conjunto de treinamento em algum valor. A quantidade de frações de neurônios que você deseja desativar é decidida por um hiperparâmetro, que pode ser ajustado de acordo. Dessa forma, o desligamento de alguns neurônios não permitirá que a rede memorize os dados de treinamento, pois nem todos os neurônios estarão ativos ao mesmo tempo e os neurônios inativos não poderão aprender nada.
Então, vamos criar, compilar e treinar a rede novamente, mas, desta vez, com o abandono. E execute-o por 20 épocas com um tamanho de lote de 64.
batch_size = 64
epochs = 20
num_classes = 10
fashion_model = Sequential()
fashion_model.add(Conv2D(32, kernel_size=(3, 3),activation='linear',padding='same',input_shape=(28,28,1)))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D((2, 2),padding='same'))
fashion_model.add(Dropout(0.25))
fashion_model.add(Conv2D(64, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Dropout(0.25))
fashion_model.add(Conv2D(128, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Dropout(0.4))
fashion_model.add(Flatten())
fashion_model.add(Dense(128, activation='linear'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(Dropout(0.3))
fashion_model.add(Dense(num_classes, activation='softmax'))
fashion_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_54 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
leaky_re_lu_61 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
max_pooling2d_52 (MaxPooling (None, 14, 14, 32) 0
_________________________________________________________________
dropout_29 (Dropout) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_55 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
leaky_re_lu_62 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_53 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
dropout_30 (Dropout) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_56 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
leaky_re_lu_63 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
max_pooling2d_54 (MaxPooling (None, 4, 4, 128) 0
_________________________________________________________________
dropout_31 (Dropout) (None, 4, 4, 128) 0
_________________________________________________________________
flatten_18 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_35 (Dense) (None, 128) 262272
_________________________________________________________________
leaky_re_lu_64 (LeakyReLU) (None, 128) 0
_________________________________________________________________
dropout_32 (Dropout) (None, 128) 0
_________________________________________________________________
dense_36 (Dense) (None, 10) 1290
=================================================================
Total params: 356,234
Trainable params: 356,234
Non-trainable params: 0
_________________________________________________________________
fashion_model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(),metrics=['accuracy'])
fashion_train_dropout = fashion_model.fit(train_X, train_label, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(valid_X, valid_label))
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
48000/48000 [==============================] - 66s 1ms/step - loss: 0.5954 - acc: 0.7789 - val_loss: 0.3788 - val_acc: 0.8586
Epoch 2/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3797 - acc: 0.8591 - val_loss: 0.3150 - val_acc: 0.8832
Epoch 3/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3302 - acc: 0.8787 - val_loss: 0.2836 - val_acc: 0.8961
Epoch 4/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3034 - acc: 0.8868 - val_loss: 0.2663 - val_acc: 0.9002
Epoch 5/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2843 - acc: 0.8936 - val_loss: 0.2481 - val_acc: 0.9083
Epoch 6/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2699 - acc: 0.9002 - val_loss: 0.2469 - val_acc: 0.9032
Epoch 7/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2561 - acc: 0.9049 - val_loss: 0.2422 - val_acc: 0.9095
Epoch 8/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2503 - acc: 0.9068 - val_loss: 0.2429 - val_acc: 0.9098
Epoch 9/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2437 - acc: 0.9096 - val_loss: 0.2230 - val_acc: 0.9173
Epoch 10/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2307 - acc: 0.9126 - val_loss: 0.2170 - val_acc: 0.9187
Epoch 11/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2307 - acc: 0.9135 - val_loss: 0.2265 - val_acc: 0.9193
Epoch 12/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2229 - acc: 0.9160 - val_loss: 0.2136 - val_acc: 0.9229
Epoch 13/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2202 - acc: 0.9162 - val_loss: 0.2173 - val_acc: 0.9187
Epoch 14/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2161 - acc: 0.9188 - val_loss: 0.2142 - val_acc: 0.9211
Epoch 15/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2119 - acc: 0.9196 - val_loss: 0.2133 - val_acc: 0.9233
Epoch 16/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2073 - acc: 0.9222 - val_loss: 0.2159 - val_acc: 0.9213
Epoch 17/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2050 - acc: 0.9231 - val_loss: 0.2123 - val_acc: 0.9233
Epoch 18/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2016 - acc: 0.9238 - val_loss: 0.2191 - val_acc: 0.9235
Epoch 19/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2001 - acc: 0.9244 - val_loss: 0.2110 - val_acc: 0.9258
Epoch 20/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.1972 - acc: 0.9255 - val_loss: 0.2092 - val_acc: 0.9269
Vamos salvar o modelo para que você possa carregá-lo diretamente e não precise treiná-lo novamente por 20 épocas. Dessa forma, você pode carregar o modelo mais tarde, se precisar dele, e modificar a arquitetura; como alternativa, você pode iniciar o processo de treinamento com esse modelo salvo. É sempre uma boa ideia salvar o modelo - e até mesmo os pesos do modelo - porque isso economiza tempo para você. Observe que você também pode salvar o modelo após cada época, de modo que, se ocorrer algum problema que interrompa o treinamento em uma época, não será necessário iniciar o treinamento desde o início.
fashion_model.save("fashion_model_dropout.h5py")
Por fim, vamos também avaliar seu novo modelo e ver como ele se comporta!
test_eval = fashion_model.evaluate(test_X, test_Y_one_hot, verbose=1)
10000/10000 [==============================] - 5s 461us/step
print('Test loss:', test_eval[0])
print('Test accuracy:', test_eval[1])
('Test loss:', 0.21460009642243386)
('Test accuracy:', 0.92300000000000004)
Uau! Parece que a inclusão do Dropout em nosso modelo funcionou, embora a precisão do teste não tenha melhorado significativamente, mas a perda do teste tenha diminuído em comparação com os resultados anteriores.
Agora, vamos traçar os gráficos de precisão e perda entre os dados de treinamento e validação pela última vez.
accuracy = fashion_train_dropout.history['acc']
val_accuracy = fashion_train_dropout.history['val_acc']
loss = fashion_train_dropout.history['loss']
val_loss = fashion_train_dropout.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
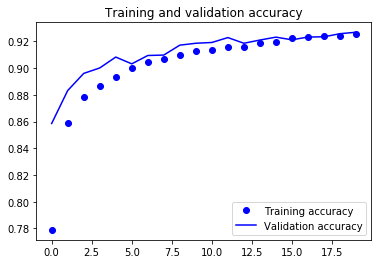
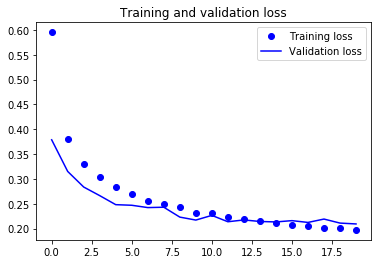
Por fim, você pode ver que a perda de validação e a precisão da validação estão em sincronia com a perda e a precisão do treinamento. Embora a perda de validação e a linha de precisão não sejam lineares, isso mostra que seu modelo não está se ajustando demais: a perda de validação está diminuindo e não aumentando, e não há muita diferença entre a precisão do treinamento e da validação.
Portanto, você pode dizer que a capacidade de generalização do seu modelo ficou muito melhor, pois a perda no conjunto de teste e no conjunto de validação foi apenas um pouco maior em comparação com a perda de treinamento.
predicted_classes = fashion_model.predict(test_X)
Como as previsões que você obtém são valores de ponto flutuante, não será possível comparar os rótulos previstos com os rótulos de teste verdadeiros. Portanto, você arredondará a saída, o que converterá os valores float em um número inteiro. Além disso, você usará o site np.argmax() para selecionar o número de índice que tem um valor mais alto em uma linha.
Por exemplo, vamos supor que uma previsão para uma imagem de teste seja 0 1 0 0 0 0 0 0 0 0, a saída para isso deve ser um rótulo de classe 1.
predicted_classes = np.argmax(np.round(predicted_classes),axis=1)
predicted_classes.shape, test_Y.shape
((10000,), (10000,))
correct = np.where(predicted_classes==test_Y)[0]
print "Found %d correct labels" % len(correct)
for i, correct in enumerate(correct[:9]):
plt.subplot(3,3,i+1)
plt.imshow(test_X[correct].reshape(28,28), cmap='gray', interpolation='none')
plt.title("Predicted {}, Class {}".format(predicted_classes[correct], test_Y[correct]))
plt.tight_layout()
Found 9188 correct labels

incorrect = np.where(predicted_classes!=test_Y)[0]
print "Found %d incorrect labels" % len(incorrect)
for i, incorrect in enumerate(incorrect[:9]):
plt.subplot(3,3,i+1)
plt.imshow(test_X[incorrect].reshape(28,28), cmap='gray', interpolation='none')
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], test_Y[incorrect]))
plt.tight_layout()
Found 812 incorrect labels

Observando algumas imagens, você não pode ter certeza do motivo pelo qual o modelo não consegue classificar corretamente as imagens acima, mas parece que uma variedade de padrões semelhantes presentes em várias classes afeta o desempenho do classificador, embora a CNN seja uma arquitetura robusta. Por exemplo, as imagens 5 e 6 pertencem a classes diferentes, mas são parecidas, talvez uma jaqueta ou uma camisa de manga longa.
O relatório de classificação nos ajudará a identificar as classes classificadas incorretamente com mais detalhes. Você poderá observar em qual classe o modelo teve um desempenho ruim entre as dez classes fornecidas.
from sklearn.metrics import classification_report
target_names = ["Class {}".format(i) for i in range(num_classes)]
print(classification_report(test_Y, predicted_classes, target_names=target_names))
precision recall f1-score support
Class 0 0.77 0.90 0.83 1000
Class 1 0.99 0.98 0.99 1000
Class 2 0.88 0.88 0.88 1000
Class 3 0.94 0.92 0.93 1000
Class 4 0.88 0.87 0.88 1000
Class 5 0.99 0.98 0.98 1000
Class 6 0.82 0.72 0.77 1000
Class 7 0.94 0.99 0.97 1000
Class 8 0.99 0.98 0.99 1000
Class 9 0.98 0.96 0.97 1000
avg / total 0.92 0.92 0.92 10000
Você pode ver que o classificador tem um desempenho inferior para a classe 6 em relação à precisão e à recuperação. Para a classe 0 e a classe 2, o classificador não tem precisão. Além disso, para a classe 4, o classificador está ligeiramente aquém da precisão e da recuperação.
Vá além!
Esse tutorial foi um bom começo para você aprender sobre redes neurais convolucionais em Python com o Keras. Se você conseguiu acompanhar facilmente ou até mesmo com um pouco mais de esforço, muito bem! Tente fazer alguns experimentos, talvez com a mesma arquitetura de modelo, mas usando diferentes tipos de conjuntos de dados públicos disponíveis.
Ainda há muito a ser abordado, então por que você não faz o curso Deep Learning in Python da DataCamp? Enquanto isso, não deixe de conferir a documentação do Keras, caso você ainda não tenha feito isso. Você encontrará mais exemplos e informações sobre todas as funções, argumentos, mais camadas, etc. Sem dúvida, ele será um recurso indispensável quando você estiver aprendendo a trabalhar com redes neurais em Python!
Se você preferir ler um livro que explique os fundamentos da aprendizagem profunda (com o Keras) e como ela é usada na prática, leia o livro Deep Learning in Python, de François Chollet.
Saiba mais sobre Python e Deep Learning
Curso
Curso