
Programa
Cientista de dados Em Python
26 h
Seja você um estudante, um aspirante a cientista de dados ou um profissional querendo mudar de carreira, se quiser se tornar um cientista de dados experiente, precisa seguir um caminho. Isso nem sempre é fácil, já que o cenário da ciência de dados ficou bem amplo e, por isso, tem diferentes tipos de profissionais de ciência de dados com diferentes atividades e conjuntos de habilidades.
Para te ajudar a entender melhor a área de ciência de dados, esse artigo dá uma visão geral do que rola nesse mundo, pra você ver quais funções combinam com suas ambições. Além disso, dá dicas sobre como entrar ou crescer em diferentes funções dentro desse cenário, respondendo a perguntas como: Que habilidades você deve desenvolver e com quais métodos deve se familiarizar?
Vamos começar com nosso roteiro de ciência de dados.
Neste artigo, vamos dar uma olhada em todos os detalhes do roteiro. Mas, se você quer um resumo rápido do esboço, dá uma olhada aqui embaixo:
Seguindo esse roteiro, você pode navegar com eficácia pelo cenário da ciência de dados, desenvolver habilidades essenciais e seguir uma carreira gratificante na área.
Pra entender o contexto de um roteiro de ciência de dados, é essencial ter uma ideia do que é Ciência de Dados. Temos um guia completo com definições e explicações sobre ciência de dados, mas, para os fins deste artigo, vamos considerar a ciência de dados como o conjunto de atividades que buscam resolver problemas usando dados.
Um problema que rola bastante é “Tenho uma pergunta, mas não sei a resposta”. Então, se você fizer uma consulta SQL em um banco de dados de vendas pra descobrir quanto a empresa faturou no mês passado, você é um cientista de dados!
Muitas vezes, os problemas/soluções são mais complexos e exigem um conjunto mais diversificado de habilidades. Pra poder falar sobre essa variedade de funções e habilidades em ciência de dados ao longo deste roteiro, vamos usar o ciclo de vida de um projeto de ciência de dados como base. Isso vai nos ajudar a mapear as diferentes atividades e funções e vai servir de base para definir o terreno da ciência de dados.
Os projetos de ciência de dados geralmente começam com uma questão ou problema de negócios. Um problema dá início a uma fase inicial, na qual um conjunto de possíveis soluções é definido e a viabilidade inicial é avaliada. A coleta inicial de dados ou uma análise exploratória dos dados disponíveis é feita para ver o que é possível e o que não é. Os dados são suficientes? Tem recursos suficientes?
Quando tudo estiver ok, começamos a criar um modelo de previsão. O modelo vai usar os dados que você colocar para prever os resultados. No começo, esse modelo pode ser só um modelo único, treinado, testado e validado em um conjunto de validação cruzada k-fold (uma técnica de machine learning pra avaliar o desempenho provável de um modelo em dados não vistos). Esse é o trabalho que geralmente os cientistas de dados clássicos fazem. Quando o modelo estiver funcionando bem, é hora de começar a colocá-lo em produção e integrá-lo à infraestrutura existente, onde o desempenho será monitorado e o modelo será retreinado quando necessário.
Cada uma dessas fases precisa de habilidades diferentes. Na fase inicial, as pessoas precisam ter visão para os negócios, saber sobre transformação de dados, limpeza, estatística descritiva e estatística inferencial básica. Esse é um trabalho que pode ser feito por um analista de dados e/ou um cientista de dados.
Na fase de modelagem, é preciso criar modelos preditivos. Modelos simples, como regressões, podem ser criados por um analista de dados, mas se ficarem mais complexos, você vai precisar de um cientista de dados para criar um modelo usando um algoritmo já existente ou até mesmo de um engenheiro de machine learning para alterar os algoritmos atuais ou criar novos.
Ao implementar e colocar o modelo em produção, você entra no mundo do engenheiro de machine learning ou do engenheiro de dados. Ao contrário das etapas anteriores, não há necessariamente uma ligação estreita com os negócios, e a tarefa em questão girava em torno da criação e monitoramento de um pipeline em torno do modelo preditivo para fornecer resultados confiáveis aos sistemas de destino corretos.
Durante todo o processo, todos os dados devem estar disponíveis nos locais certos, com as metainformações corretas, o que é função do arquiteto de dados. À medida que novos dados são inseridos ou os dados existentes são transformados em novas informações, eles também garantem que os dados acabem no lugar certo.
A forma como as diferentes funções contribuem ao longo das diferentes fases do ciclo de vida é ilustrada na imagem abaixo. Como cada função tem um papel diferente em cada etapa, elas exigem habilidades diferentes.
As funções no começo do ciclo de vida exigem mais perspicácia nos negócios e menos engenharia, enquanto as fases posteriores exigem menos perspicácia nos negócios e mais engenharia e otimização de algoritmos. Pra mostrar isso, como cientista de dados, você pode se virar com um desempenho computacional abaixo do ideal pra mostrar o valor e o desempenho do seu modelo. Mas assim que você se torna responsável pela produção de modelos, precisa ser capaz de otimizar a complexidade computacional para garantir que seu pipeline seja (custo-)eficiente.
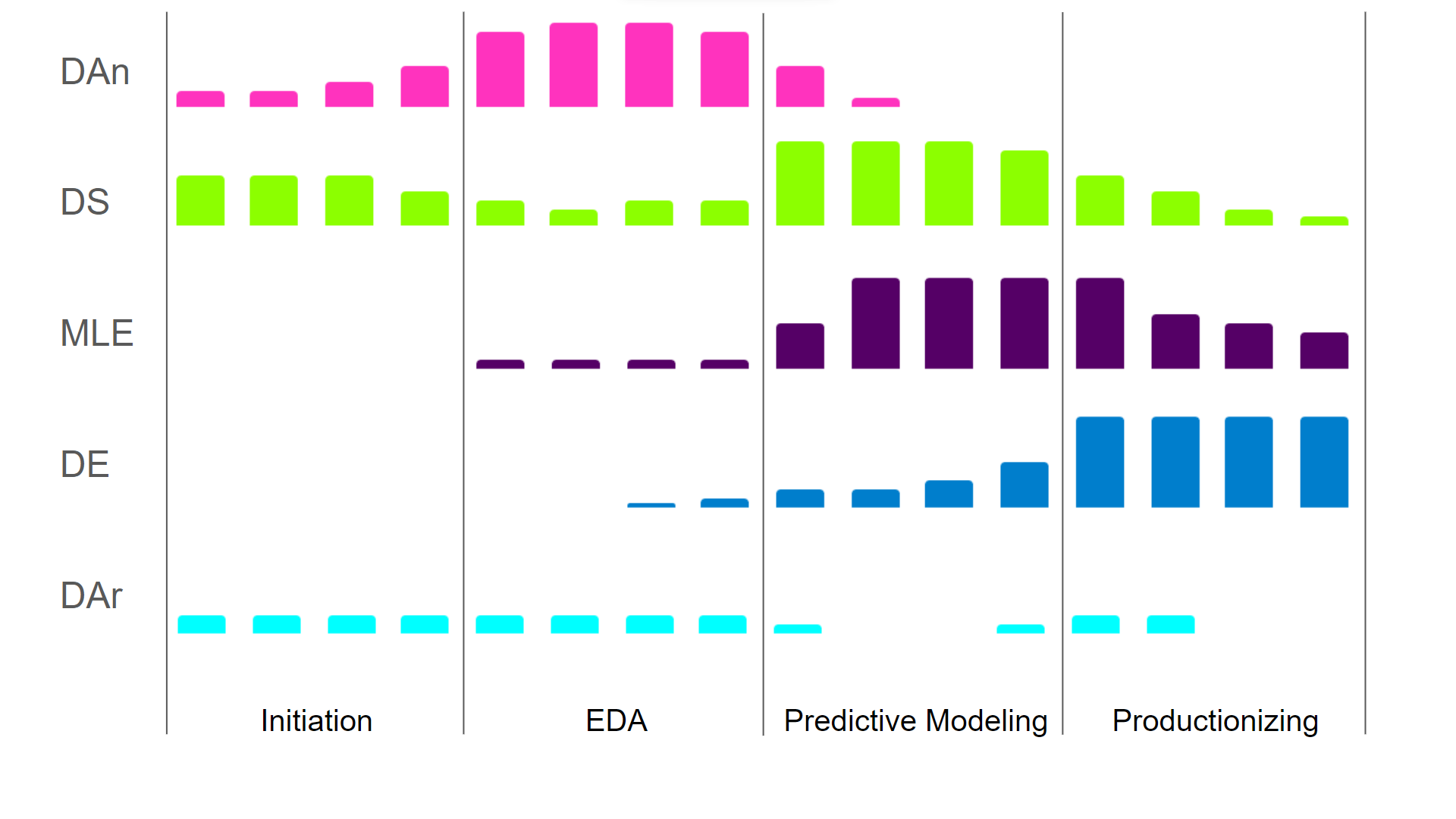
O nível de contribuição das diferentes funções da ciência de dados ao longo de um projeto de ciência de dados (DAn - Analista de Dados, DS - Cientista de Dados, MLE - Engenheiro de machine learning, DE - Engenheiro de Dados, DAr - Arquiteto de Dados - Imagem do autor
É importante saber que as delimitações entre as funções não são rígidas. Muitos cientistas de dados já pensam nos sistemas de origem/destino certos e na eficiência computacional e levam isso em conta no seu código. Um engenheiro de machine learning pode perceber que certas abordagens de geração de recursos podem melhorar o desempenho do modelo. Um analista de dados pode dar uma boa dica sobre onde, no catálogo de dados, guardar as funcionalidades criadas para o arquiteto de dados. Ou seja, todos os papéis devem, até certo ponto, estar cientes do trabalho dos outros papéis, mas não precisam entender em profundidade as responsabilidades uns dos outros.
No que diz respeito às habilidades e ferramentas necessárias, existe uma base clara. Não importa em que parte do ciclo de vida de um projeto de ciência de dados você contribui, você vai precisar ter um conhecimento básico de matemática e estatística, desenvolvimento colaborativo de software e manipulação de dados. Em geral, o começo de qualquer plano de ação em ciência de dados envolve:
Existem diferentes tipos de funções na área de ciência de dados, com diferentes requisitos de habilidades: um analista de dados precisará de um conhecimento mais profundo de SQL do que um engenheiro de dados. Um cientista de dados precisa saber mais sobre machine learning do que um arquiteto de dados. Então é aqui que o roteiro da ciência de dados se divide: dependendo de onde estão suas ambições no cenário da ciência de dados, você precisará aprender habilidades diferentes. As seções a seguir descrevem os diferentes ramos do roteiro que você pode imaginar.
Não importa em que ponto você está no seu caminho na ciência de dados, seja você um veterano experiente ou alguém que está começando, todos os projetos de ciência de dados começam com a compreensão dos seus dados.
Entender bem seus dados é essencial pra avaliar se seu projeto dá pra fazer. Começando com perguntas básicas como “quais variáveis eu tenho?” e “quantas observações eu tenho?” e terminando com perguntas mais complexas como “quais são as relações entre as variáveis?”
Muitas vezes, os resultados de uma EDA podem ser a resposta para as perguntas dos seus stakeholders. Quando bem visualizados e apresentados de forma coerente, tipo num painel de controle, os resultados de uma análise de dados simples podem ser usados para responder a perguntas complexas. Isso, no entanto, depende da habilidade de visualização de dados.
Mas só de mostrar através da sua EDA que, por exemplo, existem diferentes segmentos de visitantes do site, você já contribuiu com valor como um cientista de dados.
Tem várias maneiras de visualizar seus resultados. Seja em bibliotecas/pacotes de visualização na linguagem que você usa (como ggplot2 do R e matplotlib do Python) ou em ferramentas dedicadas à visualização de dados (como PowerBI, Tableau ou até mesmo Excel) .
Principalmente quando a gente se concentra mais nas tarefas de um Analista de Dados, ter uma compreensão mais profunda da visualização de dados ajuda bastante.
Na maioria das funções de ciência de dados, as visualizações podem servir para verificar suposições por meio de gráficos de dispersão e histogramas, mas quando a análise em si é o resultado final, como no caso de um analista de dados, você vai se deparar com situações em que vai querer tornar os resultados da análise fáceis de entender.
Pense em estilos personalizados, novas visualizações ou infográficos para servir como contribuição para uma unidade de tomada de decisão. Nessas situações, é legal poder criar uma visualização de dados que é praticamente uma obra de arte. Compreender a Visualização de Dados é um curso que ajuda muito a aprofundar suas competências em visualização de dados.
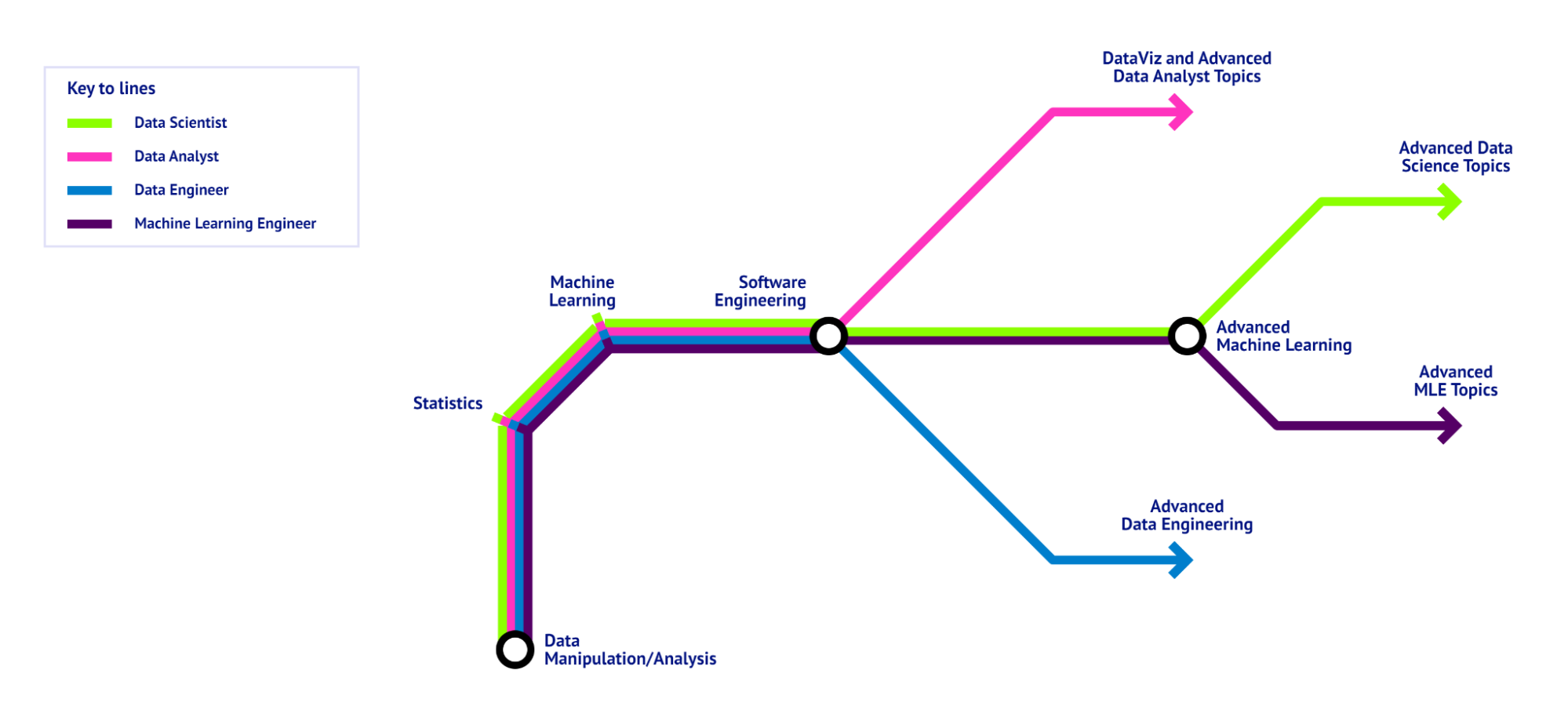
Um roteiro de ciência de dados, visualizado como um mapa do metrô, mostrando a base que todas as funções de ciência de dados têm em comum e as habilidades específicas para as diferentes funções. - Imagem do autor
Outra das primeiras etapas no caminho da ciência de dados é a estatística. Alguns conceitos básicos de estatística devem ser algo natural para qualquer tipo de cientista de dados.
A qualquer momento, você vai precisar descrever seus dados e subgrupos nos seus dados. Qual é a renda média no seu conjunto de dados? Quais são os rendimentos mínimo e máximo? Qual é o desvio padrão ou quais são outras medidas de dispersão? E se você tiver valores categóricos, quantos valores únicos existem? Qual é o mais comum? Todos os valores aparecem com a mesma frequência ou estão distribuídos de forma menos uniforme?
Responder perguntas com análises descritivas sobre grupos/subgrupos já pode dar insights valiosos, mas, na maioria das vezes, você precisa ver a relação entre as variáveis no seu conjunto de dados e partir para estatísticas inferenciais.
A parte desafiadora e interessante da estatística inferencial são os diferentes tipos de valores categóricos e numéricos e as relações entre eles. Alguns exemplos são:
Pra responder essas perguntas, você precisa conhecer os diferentes tipos de testes estatísticos, desde o mais simples, o Teste T, até métodos mais complexos, como regressões lineares multivariadas ou análise de séries temporais.
Você pode fazer cursos relevantes para entender melhor de estatística em: Python, R e até mesmo independente de ferramentas. Esses cursos oferecem uma base adequada para começar a trabalhar com machine learning. Ao entender estatisticamente a relação entre os preditores e as variáveis-alvo, você compreende os princípios dos algoritmos usados para criar modelos de aprendizado supervisionado.
O quanto você quer se aprofundar nessa área depende, mais uma vez, de onde você quer chegar no seu plano de ação em ciência de dados. Se você quer ser analista de dados, entender o básico de estatística pode ser suficiente. Os arquitetos de dados podem não precisar de nenhum conhecimento estatístico. Mas os cientistas de dados e os engenheiros de machine learning vão, com certeza, se deparar com situações em que vão precisar contar com seus conhecimentos estatísticos.
A ciência de dados gira em torno de números e cálculos e, por isso, a matemática tem um papel importante. Embora um diploma avançado em matemática não seja uma parada obrigatória no caminho da ciência de dados, entender álgebra e cálculo vai te ajudar a entender conceitualmente vários métodos usados na ciência de dados. A maioria das abordagens de redução de dimensionalidade (como PCA e Fatoração de Matrizes) se baseia na Álgebra Linear, e muitos algoritmos de otimização (como o gradiente descendente) se baseiam no Cálculo.
E, assim como acontece com estatísticas e análise de dados, esse conhecimento não é necessariamente relevante para todas as funções da ciência de dados. Se você quer ser engenheiro de machine learning, não tem jeito, você precisa saber matemática. Mas a maioria das outras funções — até mesmo um cientista de dados — pode dar certo sem saber álgebra e cálculo.
Para saber mais e entender os conceitos algébricos, dá uma olhada no nosso curso sobre Álgebra Linear para Ciência de Dados em R.
Machine learning é a arte de criar softwares que aprendem com os dados. É realmente o pão com manteiga para cientistas de dados, engenheiros de machine learning e até mesmo engenheiros de dados. A parte da sua solução que dá a receita de vendas esperada para a sua empresa, com base no seu estoque e preços? Isso é feito com machine learning!
O mínimo que você precisa saber como cientista de dados é como treinar e avaliar modelos. Em certas situações, você pode querer se aprofundar e aprender como alterar algoritmos existentes ou até mesmo escrever novos algoritmos, entrando no mundo dos engenheiros de machine learning.
Você tem bastante liberdade na forma como faz seu machine learning. Você pode programar tudo sozinho (em Python, R, C# ou Java, com bibliotecas relevantes), usar pacotes de software locais (como Weka e RapidMiner) ou usar soluções em nuvem (como Databricks e AWS SageMaker). Embora isso torne difícil decidir o que aprender, o conhecimento que você desenvolve é facilmente transferível. Uma boa ideia para decidir qual kit de ferramentas de machine learning começar a usar seria partir de uma linguagem que você já conhece ou verificar quais ferramentas as pessoas usam no setor em que você está interessado.
Você pode começar com nosso programa de Cientista de Machine Learning com Python, que cobre muitos dos fundamentos necessários para iniciar sua carreira.
A relação entre machine learning, aprendizado profundo e IA é discutível.
Quando eu dava aulas de machine learning, minha primeira aula era sempre um debate animado sobre a afirmação: “O machine learning é uma forma de IA”. Embora às vezes sejam usados de forma intercambiável, acredito firmemente que o machine learning possibilita a IA, mas isso não significa que, se você usar o machine learning, terá criado IA.
Para que um aplicativo de dados se torne IA, é essencial que exista um ciclo de feedback no qual o aplicativo ou modelo aprenda com seus resultados. Nesse caso, um algoritmo de aprendizado supervisionado único não é necessariamente IA. Se você enviar o resultado do modelo de volta para ele (como no aprendizado por reforço), você vai ter IA, porque você tem um sistema que fica aprendendo automaticamente com suas previsões certas e erradas.
O aprendizado profundo não é muito mais do que redes neurais turbinadas. O que torna as aplicações interessantes é que o Deep Learning permite resultados super tangíveis, já que esses modelos podem produzir texto, imagens e fala. Se você trabalha em um projeto de ciência de dados onde é essencial que os modelos produzam algo que possa ser percebido ou experimentado pelos usuários finais humanos, entender o aprendizado profundo pode ser uma grande vantagem. Um curso que é ótimo pra começar é Introdução ao Deep Learning em Python.
Nenhum trabalho de ciência de dados acontece no vácuo. À medida que você avança em sua jornada, é importante guardar e mostrar os artefatos que você produz. Parte do trabalho de um cientista de dados é mostrar o que você sabe fazer.
Pra mim, a parte mais legal da ciência de dados é que você não precisa de muita coisa. Você só precisa de um conjunto de dados públicos e um pouco de criatividade para pensar numa pergunta interessante e, em seguida, responder a essa pergunta usando os dados. Ou você pode simplesmente acessar o DataLabou o Kaggle e começar a trabalhar nas tarefas e/ou concursos, inspirando-se em outros trabalhos enviados.
Como alternativa, você pode coletar e usar seus próprios dados. Analisei meus dados de ciclismo baixados do Strava e coletei dados imobiliários para me ajudar na minha pesquisa sobre o mercado imobiliário.
O mais importante é que você documente o que faz. Tente fazer seu trabalho de um jeito que dá pra reproduzir, explique os passos que você deu, compartilhe seu código e compartilhe o resultado da sua análise ou sistema. Quem sabe? Talvez o seu exercício prático seja a solução exata para o problema de alguém.

Na minha opinião, os projetos mais legais são aqueles que vêm da sua própria paixão e dos seus interesses. Se você usar um conjunto de dados de algum lugar que conhece bem, é provável que consiga pensar em perguntas únicas e interessantes. Você conhece o domínio e conhece os dados... Mas se você realmente começar do zero, tem várias coisas para começar a trabalhar, incluindo aplicativos de namoro, comércio, esportes.
Você também pode encontrar uma grande variedade de projetos de ciência de dados no DataCamp, que permitem que você se familiarize com o tipo de trabalho. Seja começando com alguns projetos de análise de dados ou trabalhando em projetos específicos em Python, você pode chegar até projetos de machine learning e até mesmo de inteligência artificial. Tem várias opções pra te ajudar a começar.
Se, mesmo com tudo isso, você não consegue encontrar um jeito de começar, outra opção legal pode ser participar de hackathons. Muitos institutos de pesquisa e grandes empresas organizam hackathons de vez em quando.
Esses hackathons geralmente têm como objetivo fazer com que equipes de cientistas de dados contribuam com um problema relevante e, assim, oferecem uma chance de colaborar e aprender com outros profissionais da área de ciência de dados. Isso permite que você construa uma rede de contatos e seja notado por possíveis empregadores enquanto ganha experiência útil.
Hoje em dia, é difícil imaginar um cientista de dados que não tenha um GitHub, um portfólio no DataCamp, uma página no Medium ou um blog com código. Um portfólio é algo super importante na ciência de dados, assim como em outras áreas criativas.
Mostrar projetos anteriores é uma ótima maneira de convencer as pessoas de que você tem o que é preciso. É por isso que vale a pena começar a documentar seu trabalho em um portfólio. Como alternativa, você pode documentar seu trabalho e pontos de vista em posts de blog ou até mesmo em publicações acadêmicas. Dá uma olhada no nosso post sobre como mostrar sua experiência em dados com um portfólio para se inspirar.
Não importa o que você escolher, certifique-se de manter uma visão geral apresentável dos projetos em que trabalhou.
Este artigo destacou as diferentes habilidades, conhecimentos e ferramentas disponíveis para um cientista de dados. Mas por onde começar quando se trata de escolher uma carreira?
Na minha opinião, isso depende mesmo de onde estão suas ambições. Até agora, este post deve ter deixado claro que eu não acredito que exista um roteiro único para a ciência de dados.
Claro, toda função de ciência de dados se baseia em estatística, manipulação de dados, machine learning e engenharia de software. Mas, fora isso, depende muito.
Um cientista de dados usa algoritmos, enquanto um engenheiro de machine learning altera ou cria algoritmos. O cientista de dados pode, portanto, se contentar em conhecer muitos algoritmos e saber quando aplicá-los, enquanto o engenheiro de machine learning precisa realmente entender os conceitos matemáticos por trás dos algoritmos.
Da mesma forma, se você se anima compartilhando resultados de análises, como um cientista de dados ou analista de dados, provavelmente vai se dar melhor com um conhecimento profundo de visualização de dados e EDA do que sendo muito bom em modelagem de dados.
Então, o caminho da ciência de dados tem várias bifurcações, e você pode decidir por si mesmo até onde quer ir nos diferentes ramos da ciência de dados.
Mesmo com as diferenças entre as funções, em qualquer entrevista você vai ser testado em habilidades técnicas e interpessoais. Esses testes vão variar de acordo com a função que você está buscando.
Se você não está procurando um cargo como engenheiro de machine learning ou engenheiro de dados, provavelmente não lhe farão perguntas como “Como você otimizaria o algoritmo A ou B?”. Então, é importante focar nas habilidades e, por isso, nas questões que você espera e está disposto a trabalhar. Receber perguntas sobre assuntos que você não conhece pode ser um sinal de que o cargo não é pra você.
Porque nesse campo relativamente novo, principalmente em empresas onde os dados são relativamente novos, tem muitos equívocos sobre o que são os cientistas de dados ou o que eles fazem.
Eu sei que me candidatei para o cargo de cientista de dados, onde o entrevistador usou os termos “cientista de dados” e “engenheiro de machine learning” de forma intercambiável. Então, é bem possível que o gerente de contratação tenha se atrapalhado se você receber perguntas que não consegue responder. Quase nunca se deve perguntar a um engenheiro de dados como ele faria a gestão das partes interessadas em um projeto, por exemplo.
Felizmente, existem vários recursos disponíveis para ajudar na preparação para entrevistas na área, dependendo da função a que você está se candidatando:
A área de ciência de dados é super dinâmica, e é essencial ficar por dentro das últimas tendências. Com o chatGPT, a IA generativa virou tendência, e agora é difícil imaginar um cientista de dados que não tenha pelo menos uma noção de incorporação de tokens e/ou modelos de atenção. Da mesma forma, com a chegada do MLOps, fica difícil imaginar um engenheiro de dados checando manualmente o desempenho e o desvio do modelo.
Com esse crescimento dinâmico, diferentes aspectos da IA se tornam importantes. Atualmente, muita atenção é dada aos aspectos éticos e legais da IA, como demonstrado por vários debates acadêmicos e políticos que, entre outros, resultaram em novas regras e regulamentações.
Não importa o que os governos decidam sobre a IA, ninguém quer ser o responsável pelo próximo escândalo na ciência de dados. A única maneira de evitar isso é ficar atento aos limites éticos e legais. Ou melhor ainda, como profissional de ciência de dados, você pode começar a contribuir para esses desenvolvimentos usando sua experiência e formando e expressando uma opinião.
Tem várias maneiras de ficar por dentro das novidades. Claro, tem o DataCamp como plataforma, mas você também pode começar a procurar e seguir profissionais inspiradores da área de ciência de dados no seu campo. Dá uma olhada se eles têm blogs, posts no X ou no Medium, ou qualquer outra coisa onde você possa ter uma ideia de como eles veem o cenário dinâmico e em constante mudança.

Como destacamos ao longo deste artigo, existem muitos recursos disponíveis para quem quer começar ou crescer na área de ciência de dados. Se você quiser ficar bem por dentro do assunto, pode dar uma olhada em conferências técnicas como NeurIPS, ICML ou KDD. Dá uma olhada nessas e em outras conferências na nossa lista das Principais Conferências de Ciência de Dados para 2026.
Embora existam muitas etapas no roteiro da ciência de dados, não existe um único caminho para a ciência de dados. Para se orientar no mundo da ciência de dados, você precisa ter 1) uma ideia geral do cenário (que espero que você tenha obtido com este post) e 2) uma ideia dos seus pontos fortes, pontos fracos e interesses, para poder decidir o que quer seguir.
Se você tem isso, pode contar com este artigo para te ajudar a seguir na direção certa e saber em quais habilidades você deve focar durante o seu treinamento. Felizmente, existem alguns recursos úteis para você começar, como os programas de carreira do DataCamp, que te dão as habilidades necessárias para começar a explorar diferentes profissões:
Comece hoje mesmo sua jornada na ciência de dados!
Programa
Curso
Curso
blog
Javier Canales Luna
13 min
blog
Elena Kosourova
15 min
