Cours
Introduction au Deep Learning en Python
4 h
263.6K
Vous avez peut-être déjà entendu parler de la reconnaissance d'images ou de visages, ou encore des voitures autonomes. Il s'agit d'implémentations réelles de réseaux neuronaux convolutifs (CNN). Dans cet article de blog, vous apprendrez et comprendrez comment mettre en œuvre ces réseaux neuronaux artificiels profonds et feed-forward dans Keras et comment surmonter l'overfitting avec la technique de régularisation appelée "dropout".
Plus précisément, vous aborderez les sujets suivants dans le tutoriel d'aujourd'hui :
Vous souhaitez suivre une formation sur Keras et l'apprentissage profond en Python ? Pensez à suivre la formation Deep Learning in Python de DataCamp !
Ne manquez pas non plus notre antisèche Keras, qui vous présente les six étapes à franchir pour construire des réseaux neuronaux en Python, avec des exemples de code !
Vous connaissez peut-être déjà l'apprentissage automatique et l'apprentissage profond, une branche de l'informatique qui étudie la conception d'algorithmes capables d'apprendre. L'apprentissage profond est un sous-domaine de l'apprentissage automatique qui s'inspire des réseaux neuronaux artificiels, eux-mêmes inspirés des réseaux neuronaux biologiques.
Un type particulier de réseau neuronal profond est le réseau convolutionnel, communément appelé CNN ou ConvNet. Il s'agit d'un réseau neuronal artificiel profond et évolutif. Rappelez-vous que les réseaux neuronaux feed-forward sont également appelés perceptrons multicouches (MLP), qui sont la quintessence des modèles d'apprentissage profond. Les modèles sont appelés "feed-forward" parce que l'information passe directement par le modèle. Il n'y a pas de connexions de rétroaction dans lesquelles les sorties du modèle sont renvoyées vers lui-même.
Les CNN s'inspirent en particulier du cortex visuel biologique. Le cortex comporte de petites régions de cellules sensibles aux zones spécifiques du champ visuel. Cette idée a été développée par une expérience captivante réalisée par Hubel et Wiesel en 1962 (si vous voulez en savoir plus, voici une vidéo). Dans cette expérience, les chercheurs ont montré que certains neurones du cerveau ne s'activaient ou ne se déclenchaient qu'en présence d'arêtes d'une orientation particulière, comme des arêtes verticales ou horizontales. Par exemple, certains neurones ont réagi lorsqu'ils ont été exposés à des côtés verticaux et d'autres lorsqu'ils ont été exposés à un bord horizontal. Hubel et Wiesel ont constaté que tous ces neurones étaient bien ordonnés en colonnes et qu'ensemble, ils étaient capables de produire une perception visuelle. Cette idée de composants spécialisés à l'intérieur d'un système ayant des tâches spécifiques est une idée que les machines utilisent également et que vous pouvez retrouver dans les CNN.
Les réseaux neuronaux convolutifs ont été l'une des innovations les plus influentes dans le domaine de la vision par ordinateur. Ils ont obtenu de bien meilleurs résultats que les systèmes traditionnels de vision par ordinateur et ont produit des résultats à la pointe de la technologie. Ces réseaux neuronaux ont fait leurs preuves dans de nombreuses études de cas et applications réelles, comme par exemple :
Pour comprendre ce succès, il faut remonter à 2012, année où Alex Krizhevsky a utilisé des réseaux neuronaux convolutifs pour remporter la compétition ImageNet de cette année-là, en réduisant l'erreur de classification de 26 % à 15 %.
Notez que le concours ImageNet Large Scale Visual Recognition Challenge (ILSVRC), lancé en 2010, est une compétition annuelle au cours de laquelle des équipes de recherche évaluent leurs algorithmes sur un ensemble de données donné et s'affrontent pour atteindre une plus grande précision dans plusieurs tâches de reconnaissance visuelle.
C'est à cette époque que les réseaux neuronaux ont retrouvé leur importance après un certain temps. C'est ce que l'on appelle souvent la "troisième vague de réseaux neuronaux". Les deux autres vagues ont eu lieu entre les années 1940 et 1960 et entre les années 1970 et 1980.
D'accord, vous savez que vous travaillerez avec des réseaux de type "feed-forward" inspirés du cortex visuel biologique, mais qu'est-ce que cela signifie au juste ?
Regardez l'image ci-dessous :
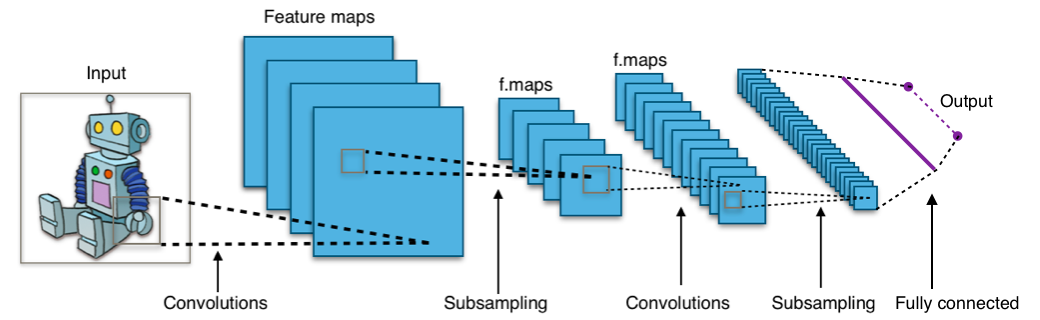
L'image vous montre que vous donnez une image en entrée au réseau, qui passe par de multiples convolutions, un sous-échantillonnage, une couche entièrement connectée et finalement produit quelque chose.
Mais qu'est-ce que tous ces concepts ?
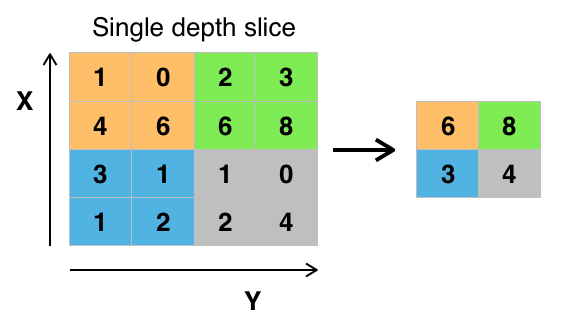
Pour plus d'informations, vous pouvez cliquer ici.
Avant de charger les données, il est bon de jeter un coup d'œil sur ce avec quoi vous travaillerez exactement ! L'ensemble de données Fashion-MNIST est un ensemble d'images d'articles de Zalando, avec des images en niveaux de gris 28x28 de 70 000 produits de mode de 10 catégories, et 7 000 images par catégorie. L'ensemble d'apprentissage comprend 60 000 images et l'ensemble de test 10 000 images. Vous pourrez revérifier cela plus tard, lorsque vous aurez chargé vos données !)
Fashion-MNIST est similaire à l'ensemble de données MNIST que vous connaissez peut-être déjà et que vous utilisez pour classer des chiffres écrits à la main. Cela signifie que les dimensions de l'image, les divisions de formation et de test sont similaires à l'ensemble de données MNIST. Conseil: si vous souhaitez apprendre à mettre en œuvre un perceptron multicouche (MLP) pour les tâches de classification avec ce dernier jeu de données, consultez ce tutoriel sur l'apprentissage profond avec Keras.
Vous pouvez trouver l'ensemble de données Fashion-MNIST ici, mais vous pouvez également le charger à l'aide de modules TensorFlow et Keras spécifiques. Vous verrez comment cela fonctionne dans la section suivante !
Keras est livré avec une bibliothèque appelée datasets, que vous pouvez utiliser pour charger des ensembles de données dès le départ : vous téléchargez les données à partir du serveur, ce qui accélère le processus puisque vous n'avez plus à télécharger les données sur votre ordinateur. Les images de formation et de test ainsi que les étiquettes sont chargées et stockées dans les variables train_X, train_Y, test_X, test_Y, respectivement.
from keras.datasets import fashion_mnist
(train_X,train_Y), (test_X,test_Y) = fashion_mnist.load_data()
Using TensorFlow backend.
Excellent ! C'était assez simple, n'est-ce pas ?
Vous l'avez probablement déjà fait un million de fois, mais c'est toujours une étape essentielle pour commencer. Vous êtes maintenant prêt à analyser, traiter et modéliser vos données !
Analysons maintenant à quoi ressemblent les images de l'ensemble de données. Même si vous connaissez maintenant la dimension des images, cela vaut la peine de l'analyser par programme : il se peut que vous deviez redimensionner les pixels de l'image et redimensionner les images.
import numpy as np
from keras.utils import to_categorical
import matplotlib.pyplot as plt
%matplotlib inline
print('Training data shape : ', train_X.shape, train_Y.shape)
print('Testing data shape : ', test_X.shape, test_Y.shape)
('Training data shape : ', (60000, 28, 28), (60000,))
('Testing data shape : ', (10000, 28, 28), (10000,))
Le résultat ci-dessus montre que les données d'apprentissage ont une forme de 60000 x 28 x 28 puisqu'il y a 60 000 échantillons d'apprentissage de 28 x 28 chacun. De même, les données de test ont une forme de 10000 x 28 x 28 puisqu'il y a 10 000 échantillons de test.
# Find the unique numbers from the train labels
classes = np.unique(train_Y)
nClasses = len(classes)
print('Total number of outputs : ', nClasses)
print('Output classes : ', classes)
('Total number of outputs : ', 10)
('Output classes : ', array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8))
Il y a également un total de dix classes de sortie qui vont de 0 à 9.
N'oubliez pas non plus d'examiner les images de votre ensemble de données :
plt.figure(figsize=[5,5])
# Display the first image in training data
plt.subplot(121)
plt.imshow(train_X[0,:,:], cmap='gray')
plt.title("Ground Truth : {}".format(train_Y[0]))
# Display the first image in testing data
plt.subplot(122)
plt.imshow(test_X[0,:,:], cmap='gray')
plt.title("Ground Truth : {}".format(test_Y[0]))
Text(0.5,1,u'Ground Truth : 9')
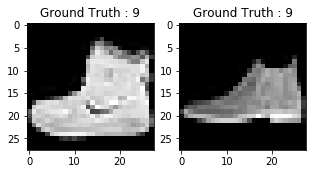
Le résultat des deux tracés ci-dessus ressemble à une botte de cheville, et l'étiquette de classe 9 est attribuée à cette classe. De même, d'autres produits de mode auront des étiquettes différentes, mais des produits similaires auront les mêmes étiquettes. Cela signifie que les 7 000 images de bottes de cheville auront une étiquette de classe de 9.
Comme vous pouvez le voir dans le graphique ci-dessus, les images sont des images en niveaux de gris dont les valeurs de pixels sont comprises entre 0 et 255. De plus, ces images ont une dimension de 28 x 28. Par conséquent, vous devrez prétraiter les données avant de les introduire dans le modèle.
train_X = train_X.reshape(-1, 28,28, 1)
test_X = test_X.reshape(-1, 28,28, 1)
train_X.shape, test_X.shape
((60000, 28, 28, 1), (10000, 28, 28, 1))
train_X = train_X.astype('float32')
test_X = test_X.astype('float32')
train_X = train_X / 255.
test_X = test_X / 255.
Dans le cas du codage à une touche, vous convertissez les données catégorielles en un vecteur de nombres. La raison pour laquelle vous convertissez les données catégorielles en un encodage chaud est que les algorithmes d'apprentissage automatique ne peuvent pas travailler directement avec des données catégorielles. Vous générez une colonne booléenne pour chaque catégorie ou classe. Une seule de ces colonnes peut prendre la valeur 1 pour chaque échantillon. D'où le terme d'encodage à un coup.
Pour l'énoncé de votre problème, l'encodage à chaud unique sera un vecteur de ligne, et pour chaque image, il aura une dimension de 1 x 10. La chose importante à noter ici est que le vecteur est composé de tous les zéros sauf pour la classe qu'il représente, et pour celle-ci, il vaut 1. Par exemple, l'image de bottes de cheville que vous avez représentée ci-dessus a une étiquette de 9. Pour toutes les images de bottes de cheville, le seul vecteur d'encodage chaud serait [0 0 0 0 0 0 0 0 1 0].
Convertissons donc les étiquettes d'apprentissage et de test en vecteurs d'encodage à un coup :
# Change the labels from categorical to one-hot encoding
train_Y_one_hot = to_categorical(train_Y)
test_Y_one_hot = to_categorical(test_Y)
# Display the change for category label using one-hot encoding
print('Original label:', train_Y[0])
print('After conversion to one-hot:', train_Y_one_hot[0])
('Original label:', 9)
('After conversion to one-hot:', array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]))
C'est assez clair, n'est-ce pas ? Notez que vous pouvez également imprimer le site train_Y_one_hot, qui affichera une matrice de taille 60000 x 10 dans laquelle chaque ligne représente le codage d'une image en une seule fois.
from sklearn.model_selection import train_test_split
train_X,valid_X,train_label,valid_label = train_test_split(train_X, train_Y_one_hot, test_size=0.2, random_state=13)
Pour la dernière fois, vérifions la forme des ensembles de formation et de validation.
train_X.shape,valid_X.shape,train_label.shape,valid_label.shape
((48000, 28, 28, 1), (12000, 28, 28, 1), (48000, 10), (12000, 10))
Les images sont de taille 28 x 28. Vous convertissez la matrice de l'image en un tableau, vous la rééchelonnez entre 0 et 1, vous la remodèlez pour qu'elle ait une taille de 28 x 28 x 1, et vous l'introduisez comme entrée dans le réseau.
Vous utiliserez trois couches convolutives :
En outre, il existe trois couches de mise en commun maximale, chacune de taille 2 x 2.
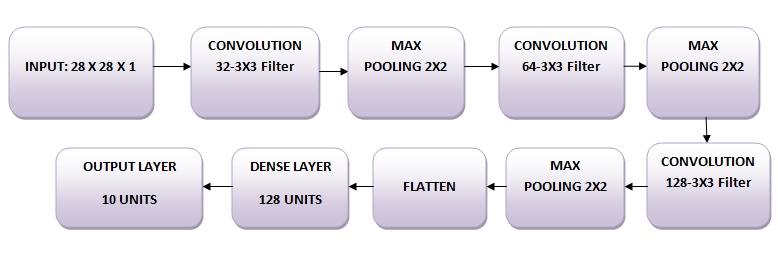
Tout d'abord, importons tous les modules nécessaires à l'entraînement du modèle.
import keras
from keras.models import Sequential,Input,Model
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.layers.advanced_activations import LeakyReLU
Vous utiliserez une taille de lot de 64, mais une taille de lot plus élevée de 128 ou 256 est également préférable, tout dépend de la mémoire. Il contribue massivement à la détermination des paramètres d'apprentissage et affecte la précision de la prédiction. Vous entraînerez le réseau pendant 20 époques.
batch_size = 64
epochs = 20
num_classes = 10
Dans Keras, vous pouvez simplement empiler des couches en ajoutant une à une les couches souhaitées. C'est exactement ce que vous allez faire ici : vous allez d'abord ajouter une première couche convolutive avec Conv2D(). Notez que vous utilisez cette fonction parce que vous travaillez avec des images ! Ensuite, vous ajoutez la fonction d'activation Leaky ReLU qui aide le réseau à apprendre les limites de décision non linéaires. Comme vous avez dix classes différentes, vous aurez besoin d'une frontière de décision non linéaire qui puisse séparer ces dix classes qui ne sont pas linéairement séparables.
Plus précisément, vous ajoutez les Leaky ReLU parce qu'elles tentent de résoudre le problème des unités linéaires rectifiées (ReLU) mourantes. La fonction d'activation ReLU est très utilisée dans les architectures de réseaux neuronaux et plus particulièrement dans les réseaux convolutifs, où elle s'est avérée plus efficace que la fonction sigmoïde logistique largement utilisée. En 2017, cette fonction d'activation est la plus populaire pour les réseaux neuronaux profonds. La fonction ReLU permet de fixer le seuil d'activation à zéro. Cependant, au cours de la formation, les unités ReLU peuvent "mourir". Cela peut se produire lorsqu'un gradient important traverse un neurone ReLU : il peut entraîner une mise à jour des poids telle que le neurone ne s'activera plus jamais sur aucun point de données. Si cela se produit, le gradient qui traverse l'unité sera toujours nul à partir de ce point. Les Leaky ReLUs tentent de résoudre ce problème : la fonction n'est pas nulle, mais présente une légère pente négative.
Ensuite, vous ajouterez la couche de mise en commun maximale avec MaxPooling2D() et ainsi de suite. La dernière couche est une couche dense qui comporte une fonction d'activation softmax de 10 unités, nécessaire pour ce problème de classification multi-classes.
fashion_model = Sequential()
fashion_model.add(Conv2D(32, kernel_size=(3, 3),activation='linear',input_shape=(28,28,1),padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D((2, 2),padding='same'))
fashion_model.add(Conv2D(64, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Conv2D(128, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Flatten())
fashion_model.add(Dense(128, activation='linear'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(Dense(num_classes, activation='softmax'))
Une fois le modèle créé, vous le compilez à l'aide de l'optimiseur Adam, l'un des algorithmes d'optimisation les plus populaires. Pour en savoir plus sur cet optimiseur , cliquez ici. En outre, vous spécifiez le type de perte, à savoir l'entropie croisée catégorielle, utilisée pour la classification multi-classes. Vous pouvez également utiliser l'entropie croisée binaire comme fonction de perte. Enfin, vous indiquez les mesures de précision que vous souhaitez analyser pendant l'apprentissage du modèle.
fashion_model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(),metrics=['accuracy'])
Visualisons les couches que vous avez créées à l'étape précédente en utilisant la fonction de résumé. Vous verrez ainsi apparaître certains paramètres (poids et biais) dans chaque couche ainsi que le total des paramètres de votre modèle.
fashion_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_51 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
leaky_re_lu_57 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
max_pooling2d_49 (MaxPooling (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_52 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
leaky_re_lu_58 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_50 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_53 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
leaky_re_lu_59 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
max_pooling2d_51 (MaxPooling (None, 4, 4, 128) 0
_________________________________________________________________
flatten_17 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_33 (Dense) (None, 128) 262272
_________________________________________________________________
leaky_re_lu_60 (LeakyReLU) (None, 128) 0
_________________________________________________________________
dense_34 (Dense) (None, 10) 1290
=================================================================
Total params: 356,234
Trainable params: 356,234
Non-trainable params: 0
_________________________________________________________________
Il est enfin temps d'entraîner le modèle avec la fonction fit() de Keras ! Le modèle s'entraîne pendant 20 époques. La fonction fit() renvoie un objet history; en enregistrant le résultat de cette fonction dans fashion_train, vous pourrez l'utiliser ultérieurement pour tracer les courbes de précision et de fonction de perte entre l'entraînement et la validation, ce qui vous aidera à analyser visuellement les performances de votre modèle.
fashion_train = fashion_model.fit(train_X, train_label, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(valid_X, valid_label))
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.4661 - acc: 0.8311 - val_loss: 0.3320 - val_acc: 0.8809
Epoch 2/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.2874 - acc: 0.8951 - val_loss: 0.2781 - val_acc: 0.8963
Epoch 3/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.2420 - acc: 0.9111 - val_loss: 0.2501 - val_acc: 0.9077
Epoch 4/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.2088 - acc: 0.9226 - val_loss: 0.2369 - val_acc: 0.9147
Epoch 5/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1838 - acc: 0.9324 - val_loss: 0.2602 - val_acc: 0.9070
Epoch 6/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1605 - acc: 0.9396 - val_loss: 0.2264 - val_acc: 0.9193
Epoch 7/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1356 - acc: 0.9488 - val_loss: 0.2566 - val_acc: 0.9180
Epoch 8/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1186 - acc: 0.9553 - val_loss: 0.2556 - val_acc: 0.9149
Epoch 9/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0985 - acc: 0.9634 - val_loss: 0.2681 - val_acc: 0.9204
Epoch 10/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0873 - acc: 0.9670 - val_loss: 0.2712 - val_acc: 0.9221
Epoch 11/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0739 - acc: 0.9721 - val_loss: 0.2757 - val_acc: 0.9202
Epoch 12/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0628 - acc: 0.9767 - val_loss: 0.3126 - val_acc: 0.9132
Epoch 13/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0569 - acc: 0.9789 - val_loss: 0.3556 - val_acc: 0.9081
Epoch 14/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0452 - acc: 0.9833 - val_loss: 0.3441 - val_acc: 0.9189
Epoch 15/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0421 - acc: 0.9847 - val_loss: 0.3400 - val_acc: 0.9165
Epoch 16/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0379 - acc: 0.9861 - val_loss: 0.3876 - val_acc: 0.9195
Epoch 17/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0405 - acc: 0.9855 - val_loss: 0.4112 - val_acc: 0.9164
Epoch 18/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0285 - acc: 0.9897 - val_loss: 0.4150 - val_acc: 0.9181
Epoch 19/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0322 - acc: 0.9877 - val_loss: 0.4584 - val_acc: 0.9196
Epoch 20/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0262 - acc: 0.9906 - val_loss: 0.4396 - val_acc: 0.9205
Enfin ! Vous avez entraîné le modèle sur fashion-MNIST pendant 20 époques, et en observant la précision et la perte d'entraînement, vous pouvez dire que le modèle a fait du bon travail puisqu'après 20 époques, la précision d'entraînement est de 99 % et la perte d'entraînement est assez faible.
Cependant, il semble que le modèle soit surajusté, car la perte de validation est de 0,4396 et la précision de validation est de 92 %. Le surajustement donne l'impression que le réseau a très bien mémorisé les données d'apprentissage, mais qu'il n'est pas garanti qu'il fonctionne sur des données inédites, ce qui explique la différence entre la précision de l'apprentissage et celle de la validation.
Vous devez probablement vous en occuper. Dans les sections suivantes, vous apprendrez comment améliorer les performances de votre modèle en ajoutant une couche Dropout dans le réseau et en conservant toutes les autres couches inchangées.
Mais d'abord, évaluons la performance de votre modèle sur l'ensemble de tests avant de tirer une conclusion.
test_eval = fashion_model.evaluate(test_X, test_Y_one_hot, verbose=0)
print('Test loss:', test_eval[0])
print('Test accuracy:', test_eval[1])
('Test loss:', 0.46366268818555401)
('Test accuracy:', 0.91839999999999999)
La précision des tests est impressionnante. Il s'avère que votre classificateur fait mieux que la référence qui a été rapportée ici, qui est un classificateur SVM avec une précision moyenne de 0,897. En outre, le modèle se comporte bien par rapport à certains des modèles d'apprentissage profond mentionnés sur le profil GitHub des créateurs de l'ensemble de données Fashion-MNIST.
Cependant, vous avez constaté que le modèle semblait surajouté. Ces résultats sont-ils vraiment si bons que cela ?
Mettons l'évaluation de votre modèle en perspective et traçons les courbes de précision et de perte entre les données de formation et de validation :
accuracy = fashion_train.history['acc']
val_accuracy = fashion_train.history['val_acc']
loss = fashion_train.history['loss']
val_loss = fashion_train.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
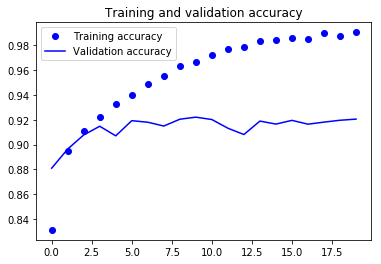
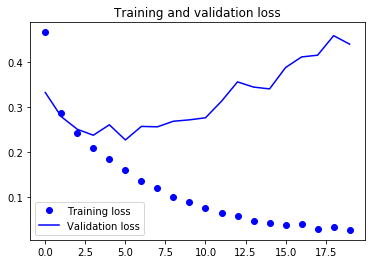
Les deux graphiques ci-dessus montrent que la précision de la validation stagne pratiquement après 4-5 époques et augmente rarement à certaines époques. Au début, la précision de la validation augmentait linéairement avec la perte, mais ensuite elle n'a pas beaucoup augmenté.
La perte de validation montre qu'il s'agit d'un signe de surajustement. Comme la précision de validation, elle diminue linéairement, mais après 4-5 époques, elle commence à augmenter. Cela signifie que le modèle a essayé de mémoriser les données et y est parvenu.
En gardant cela à l'esprit, il est temps d'introduire un peu de dropout dans notre modèle et de voir si cela permet de réduire l'overfitting.
Vous pouvez ajouter une couche d'exclusion pour surmonter le problème de l'ajustement excessif dans une certaine mesure. L'exclusion désactive de manière aléatoire une fraction des neurones au cours du processus de formation, réduisant ainsi la dépendance à l'égard de l'ensemble de formation dans une certaine mesure. Le nombre de fractions de neurones que vous souhaitez désactiver est déterminé par un hyperparamètre, qui peut être réglé en conséquence. Ainsi, la désactivation de certains neurones ne permettra pas au réseau de mémoriser les données d'apprentissage puisque tous les neurones ne seront pas actifs en même temps et que les neurones inactifs ne seront pas en mesure d'apprendre quoi que ce soit.
Créons, compilons et entraînons à nouveau le réseau, mais cette fois-ci avec l'abandon. Et exécutez-le pendant 20 époques avec une taille de lot de 64.
batch_size = 64
epochs = 20
num_classes = 10
fashion_model = Sequential()
fashion_model.add(Conv2D(32, kernel_size=(3, 3),activation='linear',padding='same',input_shape=(28,28,1)))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D((2, 2),padding='same'))
fashion_model.add(Dropout(0.25))
fashion_model.add(Conv2D(64, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Dropout(0.25))
fashion_model.add(Conv2D(128, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Dropout(0.4))
fashion_model.add(Flatten())
fashion_model.add(Dense(128, activation='linear'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(Dropout(0.3))
fashion_model.add(Dense(num_classes, activation='softmax'))
fashion_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_54 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
leaky_re_lu_61 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
max_pooling2d_52 (MaxPooling (None, 14, 14, 32) 0
_________________________________________________________________
dropout_29 (Dropout) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_55 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
leaky_re_lu_62 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_53 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
dropout_30 (Dropout) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_56 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
leaky_re_lu_63 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
max_pooling2d_54 (MaxPooling (None, 4, 4, 128) 0
_________________________________________________________________
dropout_31 (Dropout) (None, 4, 4, 128) 0
_________________________________________________________________
flatten_18 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_35 (Dense) (None, 128) 262272
_________________________________________________________________
leaky_re_lu_64 (LeakyReLU) (None, 128) 0
_________________________________________________________________
dropout_32 (Dropout) (None, 128) 0
_________________________________________________________________
dense_36 (Dense) (None, 10) 1290
=================================================================
Total params: 356,234
Trainable params: 356,234
Non-trainable params: 0
_________________________________________________________________
fashion_model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(),metrics=['accuracy'])
fashion_train_dropout = fashion_model.fit(train_X, train_label, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(valid_X, valid_label))
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
48000/48000 [==============================] - 66s 1ms/step - loss: 0.5954 - acc: 0.7789 - val_loss: 0.3788 - val_acc: 0.8586
Epoch 2/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3797 - acc: 0.8591 - val_loss: 0.3150 - val_acc: 0.8832
Epoch 3/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3302 - acc: 0.8787 - val_loss: 0.2836 - val_acc: 0.8961
Epoch 4/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3034 - acc: 0.8868 - val_loss: 0.2663 - val_acc: 0.9002
Epoch 5/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2843 - acc: 0.8936 - val_loss: 0.2481 - val_acc: 0.9083
Epoch 6/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2699 - acc: 0.9002 - val_loss: 0.2469 - val_acc: 0.9032
Epoch 7/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2561 - acc: 0.9049 - val_loss: 0.2422 - val_acc: 0.9095
Epoch 8/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2503 - acc: 0.9068 - val_loss: 0.2429 - val_acc: 0.9098
Epoch 9/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2437 - acc: 0.9096 - val_loss: 0.2230 - val_acc: 0.9173
Epoch 10/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2307 - acc: 0.9126 - val_loss: 0.2170 - val_acc: 0.9187
Epoch 11/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2307 - acc: 0.9135 - val_loss: 0.2265 - val_acc: 0.9193
Epoch 12/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2229 - acc: 0.9160 - val_loss: 0.2136 - val_acc: 0.9229
Epoch 13/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2202 - acc: 0.9162 - val_loss: 0.2173 - val_acc: 0.9187
Epoch 14/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2161 - acc: 0.9188 - val_loss: 0.2142 - val_acc: 0.9211
Epoch 15/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2119 - acc: 0.9196 - val_loss: 0.2133 - val_acc: 0.9233
Epoch 16/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2073 - acc: 0.9222 - val_loss: 0.2159 - val_acc: 0.9213
Epoch 17/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2050 - acc: 0.9231 - val_loss: 0.2123 - val_acc: 0.9233
Epoch 18/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2016 - acc: 0.9238 - val_loss: 0.2191 - val_acc: 0.9235
Epoch 19/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2001 - acc: 0.9244 - val_loss: 0.2110 - val_acc: 0.9258
Epoch 20/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.1972 - acc: 0.9255 - val_loss: 0.2092 - val_acc: 0.9269
Sauvegardons le modèle afin de pouvoir le charger directement et de ne pas avoir à l'entraîner à nouveau pendant 20 époques. De cette façon, vous pouvez charger le modèle plus tard si vous en avez besoin et modifier l'architecture. Vous pouvez également lancer le processus de formation sur ce modèle sauvegardé. C'est toujours une bonne idée de sauvegarder le modèle - et même les poids du modèle - car cela vous permet de gagner du temps. Notez que vous pouvez également sauvegarder le modèle après chaque époque, de sorte que si un problème survient et interrompt l'apprentissage à une époque, vous n'aurez pas à recommencer l'apprentissage depuis le début.
fashion_model.save("fashion_model_dropout.h5py")
Enfin, évaluons également votre nouveau modèle et voyons comment il se comporte !
test_eval = fashion_model.evaluate(test_X, test_Y_one_hot, verbose=1)
10000/10000 [==============================] - 5s 461us/step
print('Test loss:', test_eval[0])
print('Test accuracy:', test_eval[1])
('Test loss:', 0.21460009642243386)
('Test accuracy:', 0.92300000000000004)
Ouah ! On dirait que l'ajout de Dropout dans notre modèle a fonctionné, même si la précision du test ne s'est pas améliorée de manière significative mais que la perte du test a diminué par rapport aux résultats précédents.
Maintenant, traçons les courbes de précision et de perte entre les données d'entraînement et de validation pour la dernière fois.
accuracy = fashion_train_dropout.history['acc']
val_accuracy = fashion_train_dropout.history['val_acc']
loss = fashion_train_dropout.history['loss']
val_loss = fashion_train_dropout.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
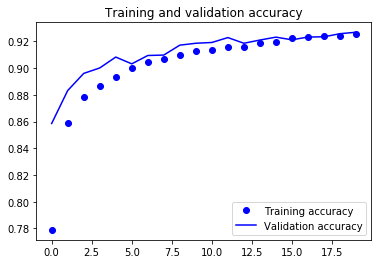
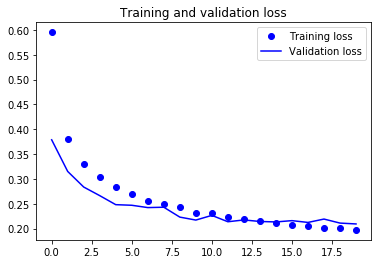
Enfin, vous pouvez constater que la perte de validation et la précision de validation sont toutes deux en phase avec la perte d'entraînement et la précision d'entraînement. Même si la perte de validation et la ligne de précision ne sont pas linéaires, cela montre que votre modèle n'est pas surajusté : la perte de validation diminue et n'augmente pas, et il n'y a pas beaucoup d'écart entre la précision de l'entraînement et celle de la validation.
Vous pouvez donc dire que la capacité de généralisation de votre modèle s'est nettement améliorée puisque la perte sur l'ensemble de test et l'ensemble de validation n'est que légèrement supérieure à la perte d'apprentissage.
predicted_classes = fashion_model.predict(test_X)
Comme les prédictions que vous obtenez sont des valeurs à virgule flottante, il ne sera pas possible de comparer les étiquettes prédites avec les vraies étiquettes de test. Vous arrondirez donc la sortie, ce qui convertira les valeurs flottantes en nombres entiers. En outre, vous utiliserez np.argmax() pour sélectionner le numéro d'index qui a une valeur supérieure dans une ligne.
Par exemple, supposons qu'une prédiction pour une image test soit 0 1 0 0 0 0 0 0 0 0, le résultat devrait être une étiquette de classe 1.
predicted_classes = np.argmax(np.round(predicted_classes),axis=1)
predicted_classes.shape, test_Y.shape
((10000,), (10000,))
correct = np.where(predicted_classes==test_Y)[0]
print "Found %d correct labels" % len(correct)
for i, correct in enumerate(correct[:9]):
plt.subplot(3,3,i+1)
plt.imshow(test_X[correct].reshape(28,28), cmap='gray', interpolation='none')
plt.title("Predicted {}, Class {}".format(predicted_classes[correct], test_Y[correct]))
plt.tight_layout()
Found 9188 correct labels

incorrect = np.where(predicted_classes!=test_Y)[0]
print "Found %d incorrect labels" % len(incorrect)
for i, incorrect in enumerate(incorrect[:9]):
plt.subplot(3,3,i+1)
plt.imshow(test_X[incorrect].reshape(28,28), cmap='gray', interpolation='none')
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], test_Y[incorrect]))
plt.tight_layout()
Found 812 incorrect labels

En examinant quelques images, vous ne pouvez pas savoir avec certitude pourquoi votre modèle n'est pas en mesure de classer correctement les images ci-dessus, mais il semble qu'une variété de motifs similaires présents dans plusieurs classes affecte les performances du classificateur, bien que le CNN soit une architecture robuste. Par exemple, les images 5 et 6 appartiennent toutes deux à des classes différentes mais se ressemblent, peut-être une veste ou une chemise à manches longues.
Le rapport de classification nous aidera à identifier les classes mal classées de manière plus détaillée. Vous pourrez observer pour quelle classe le modèle s'est mal comporté parmi les dix classes données.
from sklearn.metrics import classification_report
target_names = ["Class {}".format(i) for i in range(num_classes)]
print(classification_report(test_Y, predicted_classes, target_names=target_names))
precision recall f1-score support
Class 0 0.77 0.90 0.83 1000
Class 1 0.99 0.98 0.99 1000
Class 2 0.88 0.88 0.88 1000
Class 3 0.94 0.92 0.93 1000
Class 4 0.88 0.87 0.88 1000
Class 5 0.99 0.98 0.98 1000
Class 6 0.82 0.72 0.77 1000
Class 7 0.94 0.99 0.97 1000
Class 8 0.99 0.98 0.99 1000
Class 9 0.98 0.96 0.97 1000
avg / total 0.92 0.92 0.92 10000
Vous pouvez constater que le classificateur est moins performant pour la classe 6 en termes de précision et de rappel. Pour les classes 0 et 2, le classificateur manque de précision. De même, pour la classe 4, le classificateur manque légèrement de précision et de rappel.
Allez plus loin !
Ce tutoriel était un bon début pour les réseaux de neurones convolutifs en Python avec Keras. Si vous avez pu suivre facilement ou même avec un peu plus d'efforts, bravo ! Essayez de faire quelques expériences, peut-être avec la même architecture de modèle, mais en utilisant différents types d'ensembles de données publiques disponibles.
Il y a encore beaucoup de choses à couvrir, alors pourquoi ne pas suivre la formation Deep Learning in Python de DataCamp ? En attendant, n'oubliez pas de consulter la documentation Keras, si vous ne l'avez pas encore fait. Vous y trouverez plus d'exemples et d'informations sur toutes les fonctions, les arguments, plus de couches, etc. Il sera sans aucun doute une ressource indispensable lorsque vous apprendrez à travailler avec des réseaux de neurones en Python !
Si vous avez plutôt envie de lire un livre qui explique les fondamentaux du deep learning (avec Keras) en même temps que son utilisation en pratique, vous devriez absolument lire le livre Deep Learning in Python de François Chollet.
En savoir plus sur Python et l'apprentissage en profondeur.
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min