Kurs
Einführung in Deep Learning mit Python
4 Std.
263.5K
Du hast vielleicht schon von Bild- oder Gesichtserkennung oder selbstfahrenden Autos gehört. Dies sind reale Implementierungen von Convolutional Neural Networks (CNNs). In diesem Blogbeitrag erfährst du, wie du diese tiefen, vorwärtsgerichteten künstlichen neuronalen Netze in Keras implementieren kannst und wie du mit der Regularisierungstechnik "Dropout" das Overfitting überwinden kannst.
Genauer gesagt, wirst du in der heutigen Schulung die folgenden Themen behandeln:
Möchtest du einen Kurs über Keras und Deep Learning in Python belegen? Überlege dir, ob du den Kurs Deep Learning in Python von DataCamp besuchen willst!
Verpasse auch nicht unseren Keras-Spickzettel, der dir die sechs Schritte zeigt, die du durchlaufen musst, um neuronale Netze in Python zu bauen, mit Codebeispielen!
Du kennst dich vielleicht schon mit maschinellem Lernen und Deep Learning aus, einem Zweig der Informatik, der sich mit der Entwicklung von lernfähigen Algorithmen beschäftigt. Deep Learning ist ein Teilbereich des maschinellen Lernens, der von künstlichen neuronalen Netzen inspiriert ist, die wiederum von biologischen neuronalen Netzen inspiriert sind.
Eine spezielle Art eines solchen tiefen neuronalen Netzes ist das Faltungsnetz, das allgemein als CNN oder ConvNet bezeichnet wird. Es ist ein tiefes künstliches neuronales Netzwerk mit Vorwärtssteuerung. Erinnere dich daran, dass neuronale Netze mit Vorwärtskopplung auch mehrschichtige Perzeptronen (MLPs) genannt werden, die die Quintessenz der Deep-Learning-Modelle sind. Die Modelle werden "feed-forward" genannt, weil die Informationen direkt durch das Modell fließen. Es gibt keine Rückkopplungsverbindungen, bei denen die Ausgaben des Modells in sich selbst zurückgeführt werden.
CNNs sind speziell vom biologischen visuellen Kortex inspiriert. Die Hirnrinde hat kleine Zellregionen, die für bestimmte Bereiche des Gesichtsfeldes empfindlich sind. Diese Idee wurde durch ein fesselndes Experiment von Hubel und Wiesel im Jahr 1962 erweitert (wenn du mehr wissen willst, findest du hier ein Video). In diesem Experiment zeigten die Forscherinnen und Forscher, dass einzelne Neuronen im Gehirn nur in Gegenwart von Kanten mit einer bestimmten Ausrichtung wie vertikalen oder horizontalen Kanten aktiviert oder gefeuert wurden. Zum Beispiel feuerten einige Neuronen, wenn sie vertikalen Seiten ausgesetzt waren, und andere, wenn sie eine horizontale Kante sahen. Hubel und Wiesel fanden heraus, dass alle diese Neuronen säulenförmig angeordnet waren und dass sie zusammen die visuelle Wahrnehmung erzeugen konnten. Diese Idee, dass spezialisierte Komponenten innerhalb eines Systems bestimmte Aufgaben haben, wird auch von Maschinen verwendet und findet sich auch in CNNs wieder.
Faltungsneuronale Netze sind eine der einflussreichsten Innovationen auf dem Gebiet der Computer Vision. Sie haben viel besser abgeschnitten als die traditionelle Computer Vision und haben modernste Ergebnisse geliefert. Diese neuronalen Netze haben sich in vielen verschiedenen realen Fallstudien und Anwendungen bewährt, z. B:
Um diesen Erfolg zu verstehen, musst du ins Jahr 2012 zurückgehen, in dem Alex Krizhevsky mit Faltungsneuronalen Netzen den diesjährigen ImageNet-Wettbewerb gewann und den Klassifizierungsfehler von 26% auf 15% reduzierte.
Die ImageNet Large Scale Visual Recognition Challenge (ILSVRC) wurde im Jahr 2010 ins Leben gerufen und ist ein jährlicher Wettbewerb, bei dem Forschungsteams ihre Algorithmen anhand eines vorgegebenen Datensatzes bewerten und um eine höhere Genauigkeit bei verschiedenen visuellen Erkennungsaufgaben konkurrieren.
Dies war die Zeit, in der neuronale Netze nach langer Zeit wieder an Bedeutung gewannen. Dies wird oft als die "dritte Welle der neuronalen Netze" bezeichnet. Die beiden anderen Wellen fanden in den 1940er bis 1960er Jahren und in den 1970er bis 1980er Jahren statt.
Gut, du weißt, dass du mit Feed-Forward-Netzwerken arbeiten wirst, die vom biologischen visuellen Kortex inspiriert sind, aber was bedeutet das eigentlich?
Sieh dir das Bild unten an:
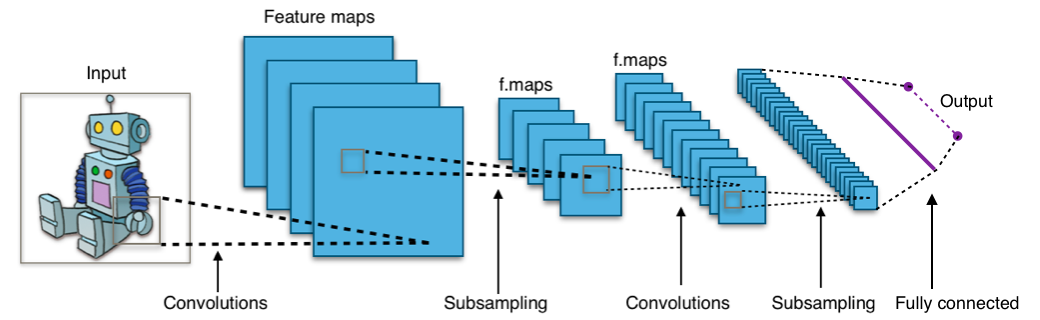
Das Bild zeigt dir, dass du ein Bild als Eingabe in das Netzwerk einspeist, das mehrere Faltungen, Unterabtastungen und eine voll verknüpfte Schicht durchläuft und schließlich etwas ausgibt.
Aber was sind all diese Konzepte?
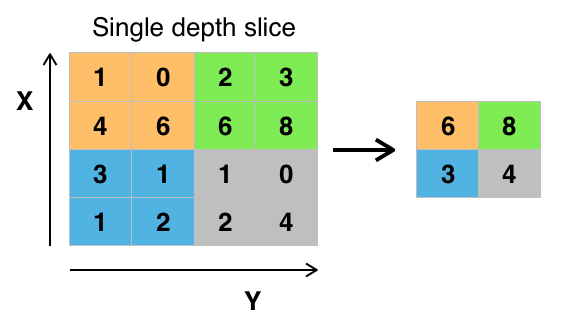
Weitere Informationen erhältst du hier.
Bevor du die Daten einträgst, ist es gut, einen Blick darauf zu werfen, womit du genau arbeiten wirst! Der Fashion-MNIST-Datensatz ist ein Datensatz von Zalando-Artikelbildern mit 28x28 Graustufenbildern von 70.000 Modeprodukten aus 10 Kategorien und 7.000 Bildern pro Kategorie. Die Trainingsmenge besteht aus 60.000 Bildern und die Testmenge aus 10.000 Bildern. Du kannst das später noch einmal überprüfen, wenn du deine Daten geladen hast! ;)
Fashion-MNIST ist ähnlich wie der MNIST-Datensatz, den du vielleicht schon kennst und mit dem du handgeschriebene Ziffern klassifizieren kannst. Das bedeutet, dass die Bilddimensionen sowie die Trainings- und Testaufteilung dem MNIST-Datensatz ähnlich sind. Tipp: Wenn du lernen willst, wie man ein Multi-Layer Perceptron (MLP) für Klassifizierungsaufgaben mit diesem Datensatz implementiert, schau dir dieses Tutorial zum Thema Deep Learning mit Keras an.
Du kannst den Fashion-MNIST-Datensatz hier finden, aber du kannst ihn auch mit Hilfe von speziellen TensorFlow- und Keras-Modulen laden. Wie das funktioniert, erfährst du im nächsten Abschnitt!
Keras wird mit einer Bibliothek namens datasets geliefert, die du zum Laden von Datensätzen verwenden kannst: Du lädst die Daten vom Server herunter und beschleunigst den Prozess, da du die Daten nicht mehr auf deinen Computer herunterladen musst. Die Trainings- und Testbilder werden zusammen mit den Labels in die Variablen train_X, train_Y, test_X, test_Y geladen und gespeichert.
from keras.datasets import fashion_mnist
(train_X,train_Y), (test_X,test_Y) = fashion_mnist.load_data()
Using TensorFlow backend.
Toll! Das war doch ganz einfach, oder?
Du hast das wahrscheinlich schon eine Million Mal gemacht, aber es ist immer ein wichtiger Schritt, um anzufangen. Jetzt bist du bereit, deine Daten zu analysieren, zu verarbeiten und zu modellieren!
Analysieren wir nun, wie die Bilder im Datensatz aussehen. Auch wenn du die Abmessungen der Bilder inzwischen kennst, lohnt es sich, sie programmatisch zu analysieren: Du musst die Bildpixel eventuell neu skalieren und die Größe der Bilder ändern.
import numpy as np
from keras.utils import to_categorical
import matplotlib.pyplot as plt
%matplotlib inline
print('Training data shape : ', train_X.shape, train_Y.shape)
print('Testing data shape : ', test_X.shape, test_Y.shape)
('Training data shape : ', (60000, 28, 28), (60000,))
('Testing data shape : ', (10000, 28, 28), (10000,))
Aus der obigen Ausgabe kannst du ersehen, dass die Trainingsdaten eine Form von 60000 x 28 x 28 haben, da es 60.000 Trainingsbeispiele mit jeweils 28 x 28 Dimensionen gibt. Ebenso haben die Testdaten die Form 10000 x 28 x 28, da es 10.000 Testproben gibt.
# Find the unique numbers from the train labels
classes = np.unique(train_Y)
nClasses = len(classes)
print('Total number of outputs : ', nClasses)
print('Output classes : ', classes)
('Total number of outputs : ', 10)
('Output classes : ', array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8))
Außerdem gibt es insgesamt zehn Leistungsklassen, die von 0 bis 9 reichen.
Vergiss auch nicht, einen Blick auf die Bilder in deinem Datensatz zu werfen:
plt.figure(figsize=[5,5])
# Display the first image in training data
plt.subplot(121)
plt.imshow(train_X[0,:,:], cmap='gray')
plt.title("Ground Truth : {}".format(train_Y[0]))
# Display the first image in testing data
plt.subplot(122)
plt.imshow(test_X[0,:,:], cmap='gray')
plt.title("Ground Truth : {}".format(test_Y[0]))
Text(0.5,1,u'Ground Truth : 9')
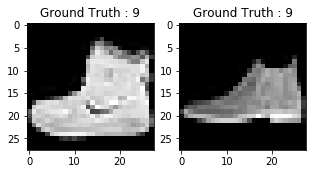
Die Ausgabe der beiden obigen Diagramme sieht aus wie eine Stiefelette, und dieser Klasse wird das Klassenlabel 9 zugewiesen. Ebenso werden andere Modeprodukte unterschiedliche Etiketten haben, aber ähnliche Produkte werden die gleichen Etiketten haben. Das bedeutet, dass alle 7.000 Bilder der Stiefelette die Klassenbezeichnung 9 haben.
Wie du in der obigen Grafik sehen kannst, sind die Bilder Graustufenbilder mit Pixelwerten zwischen 0 und 255. Außerdem haben diese Bilder eine Größe von 28 x 28. Daher musst du die Daten vorverarbeiten, bevor du sie in das Modell einspeisen kannst.
train_X = train_X.reshape(-1, 28,28, 1)
test_X = test_X.reshape(-1, 28,28, 1)
train_X.shape, test_X.shape
((60000, 28, 28, 1), (10000, 28, 28, 1))
train_X = train_X.astype('float32')
test_X = test_X.astype('float32')
train_X = train_X / 255.
test_X = test_X / 255.
Bei der One-Hot-Codierung wandelst du die kategorialen Daten in einen Zahlenvektor um. Der Grund, warum du die kategorialen Daten in eine heiße Kodierung umwandelst, ist, dass Algorithmen für maschinelles Lernen nicht direkt mit kategorialen Daten arbeiten können. Du erstellst eine boolesche Spalte für jede Kategorie oder Klasse. Für jede Stichprobe konnte nur eine dieser Spalten den Wert 1 annehmen. Daher auch der Begriff One-Hot-Codierung.
Für deine Problemstellung wird die One-Hot-Codierung ein Zeilenvektor sein, der für jedes Bild eine Dimension von 1 x 10 hat. Wichtig ist dabei, dass der Vektor aus lauter Nullen besteht, außer für die Klasse, die er repräsentiert, und für die ist er 1. Das Bild der Stiefelette, das du oben gezeichnet hast, hat zum Beispiel ein Label von 9. Für alle Bilder der Stiefelette wäre also der eine heiße Kodierungsvektor [0 0 0 0 0 0 0 0 1 0].
Konvertieren wir also die Trainings- und Testkennungen in One-Hot-Codierungsvektoren:
# Change the labels from categorical to one-hot encoding
train_Y_one_hot = to_categorical(train_Y)
test_Y_one_hot = to_categorical(test_Y)
# Display the change for category label using one-hot encoding
print('Original label:', train_Y[0])
print('After conversion to one-hot:', train_Y_one_hot[0])
('Original label:', 9)
('After conversion to one-hot:', array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]))
Das ist doch ziemlich klar, oder? Beachte, dass du auch die train_Y_one_hot ausdrucken kannst, die eine Matrix der Größe 60000 x 10 anzeigt, in der jede Zeile die One-Hot-Codierung eines Bildes darstellt.
from sklearn.model_selection import train_test_split
train_X,valid_X,train_label,valid_label = train_test_split(train_X, train_Y_one_hot, test_size=0.2, random_state=13)
Lass uns ein letztes Mal die Form der Trainings- und Validierungsmenge überprüfen.
train_X.shape,valid_X.shape,train_label.shape,valid_label.shape
((48000, 28, 28, 1), (12000, 28, 28, 1), (48000, 10), (12000, 10))
Die Bilder haben die Größe 28 x 28. Du wandelst die Bildmatrix in ein Array um, skalierst sie zwischen 0 und 1, formst sie so um, dass sie die Größe 28 x 28 x 1 hat, und gibst sie als Eingabe in das Netzwerk ein.
Du wirst drei Faltungsschichten verwenden:
Außerdem gibt es drei Max-Pooling-Schichten mit einer Größe von jeweils 2 x 2.
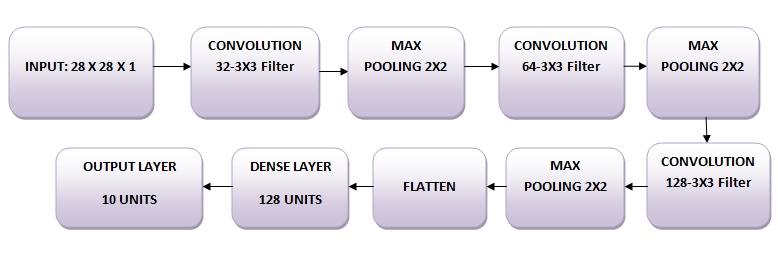
Zunächst importieren wir alle notwendigen Module, die zum Trainieren des Modells benötigt werden.
import keras
from keras.models import Sequential,Input,Model
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.layers.advanced_activations import LeakyReLU
Du wirst eine Stapelgröße von 64 verwenden. Eine höhere Stapelgröße von 128 oder 256 ist ebenfalls vorzuziehen - alles hängt vom Speicher ab. Sie trägt massiv zur Bestimmung der Lernparameter bei und beeinflusst die Vorhersagegenauigkeit. Du wirst das Netzwerk 20 Epochen lang trainieren.
batch_size = 64
epochs = 20
num_classes = 10
In Keras kannst du Ebenen einfach stapeln, indem du die gewünschte Ebene nacheinander hinzufügst. Das ist genau das, was du hier tun wirst: Du fügst zunächst eine erste Faltungsschicht mit Conv2D() hinzu. Beachte, dass du diese Funktion verwendest, weil du mit Bildern arbeitest! Als Nächstes fügst du die Leaky ReLU Aktivierungsfunktion hinzu, die dem Netz hilft, nichtlineare Entscheidungsgrenzen zu lernen. Da du zehn verschiedene Klassen hast, brauchst du eine nichtlineare Entscheidungsgrenze, die diese zehn Klassen, die nicht linear trennbar sind, voneinander trennen kann.
Genauer gesagt, fügst du Leaky ReLUs hinzu, weil sie versuchen, das Problem sterbender Rectified Linear Units (ReLUs) zu beheben. Die ReLU-Aktivierungsfunktion wird häufig in neuronalen Netzwerken und insbesondere in Faltungsnetzwerken verwendet, wo sie sich als effektiver erwiesen hat als die weit verbreitete logistische Sigmoidfunktion. Im Jahr 2017 ist diese Aktivierungsfunktion die beliebteste für tiefe neuronale Netze. Die ReLU-Funktion ermöglicht es, die Aktivierung auf Null zu begrenzen. Während der Ausbildung können die ReLU-Einheiten jedoch "sterben". Das kann passieren, wenn ein großer Gradient durch ein ReLU-Neuron fließt: Er kann dazu führen, dass die Gewichte so aktualisiert werden, dass das Neuron bei keinem Datenpunkt mehr aktiviert wird. Wenn das passiert, ist das Gefälle, das durch die Einheit fließt, von diesem Punkt an für immer gleich null. Leaky ReLUs versuchen, dieses Problem zu lösen: Die Funktion wird nicht null sein, sondern eine kleine negative Steigung haben.
Als Nächstes fügst du die Max-Pooling-Ebene mit MaxPooling2D() und so weiter hinzu. Die letzte Schicht ist eine dichte Schicht mit einer Softmax-Aktivierungsfunktion mit 10 Einheiten, die für dieses Mehrklassen-Klassifizierungsproblem benötigt wird.
fashion_model = Sequential()
fashion_model.add(Conv2D(32, kernel_size=(3, 3),activation='linear',input_shape=(28,28,1),padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D((2, 2),padding='same'))
fashion_model.add(Conv2D(64, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Conv2D(128, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Flatten())
fashion_model.add(Dense(128, activation='linear'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(Dense(num_classes, activation='softmax'))
Nachdem du das Modell erstellt hast, kompilierst du es mit dem Adam-Optimierer, einem der beliebtesten Optimierungsalgorithmen. Du kannst hier mehr über diesen Optimierer lesen. Außerdem gibst du den Verlusttyp an, d.h. die kategoriale Kreuzentropie, die für die Klassifizierung von mehreren Klassen verwendet wird. Du kannst auch die binäre Kreuzentropie als Verlustfunktion verwenden. Schließlich gibst du die Metriken für die Genauigkeit an, die du analysieren möchtest, während das Modell trainiert wird.
fashion_model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(),metrics=['accuracy'])
Lass uns die Ebenen, die du im obigen Schritt erstellt hast, mit der Zusammenfassungsfunktion visualisieren. Dies zeigt einige Parameter (Gewichte und Verzerrungen) in jeder Schicht und auch die Gesamtparameter in deinem Modell.
fashion_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_51 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
leaky_re_lu_57 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
max_pooling2d_49 (MaxPooling (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_52 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
leaky_re_lu_58 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_50 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_53 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
leaky_re_lu_59 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
max_pooling2d_51 (MaxPooling (None, 4, 4, 128) 0
_________________________________________________________________
flatten_17 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_33 (Dense) (None, 128) 262272
_________________________________________________________________
leaky_re_lu_60 (LeakyReLU) (None, 128) 0
_________________________________________________________________
dense_34 (Dense) (None, 10) 1290
=================================================================
Total params: 356,234
Trainable params: 356,234
Non-trainable params: 0
_________________________________________________________________
Jetzt ist es endlich an der Zeit, das Modell mit der Keras-Funktion fit() zu trainieren! Das Modell trainiert 20 Epochen lang. Die Funktion fit() gibt ein history Objekt zurück. Wenn du das Ergebnis dieser Funktion in fashion_train speicherst, kannst du es später verwenden, um die Genauigkeit und die Verlustfunktion zwischen Training und Validierung darzustellen, was dir hilft, die Leistung deines Modells visuell zu analysieren.
fashion_train = fashion_model.fit(train_X, train_label, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(valid_X, valid_label))
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.4661 - acc: 0.8311 - val_loss: 0.3320 - val_acc: 0.8809
Epoch 2/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.2874 - acc: 0.8951 - val_loss: 0.2781 - val_acc: 0.8963
Epoch 3/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.2420 - acc: 0.9111 - val_loss: 0.2501 - val_acc: 0.9077
Epoch 4/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.2088 - acc: 0.9226 - val_loss: 0.2369 - val_acc: 0.9147
Epoch 5/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1838 - acc: 0.9324 - val_loss: 0.2602 - val_acc: 0.9070
Epoch 6/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1605 - acc: 0.9396 - val_loss: 0.2264 - val_acc: 0.9193
Epoch 7/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1356 - acc: 0.9488 - val_loss: 0.2566 - val_acc: 0.9180
Epoch 8/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.1186 - acc: 0.9553 - val_loss: 0.2556 - val_acc: 0.9149
Epoch 9/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0985 - acc: 0.9634 - val_loss: 0.2681 - val_acc: 0.9204
Epoch 10/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0873 - acc: 0.9670 - val_loss: 0.2712 - val_acc: 0.9221
Epoch 11/20
48000/48000 [==============================] - 59s 1ms/step - loss: 0.0739 - acc: 0.9721 - val_loss: 0.2757 - val_acc: 0.9202
Epoch 12/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0628 - acc: 0.9767 - val_loss: 0.3126 - val_acc: 0.9132
Epoch 13/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0569 - acc: 0.9789 - val_loss: 0.3556 - val_acc: 0.9081
Epoch 14/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0452 - acc: 0.9833 - val_loss: 0.3441 - val_acc: 0.9189
Epoch 15/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0421 - acc: 0.9847 - val_loss: 0.3400 - val_acc: 0.9165
Epoch 16/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0379 - acc: 0.9861 - val_loss: 0.3876 - val_acc: 0.9195
Epoch 17/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0405 - acc: 0.9855 - val_loss: 0.4112 - val_acc: 0.9164
Epoch 18/20
48000/48000 [==============================] - 60s 1ms/step - loss: 0.0285 - acc: 0.9897 - val_loss: 0.4150 - val_acc: 0.9181
Epoch 19/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0322 - acc: 0.9877 - val_loss: 0.4584 - val_acc: 0.9196
Epoch 20/20
48000/48000 [==============================] - 61s 1ms/step - loss: 0.0262 - acc: 0.9906 - val_loss: 0.4396 - val_acc: 0.9205
Endlich! Du hast das Modell 20 Epochen lang auf Fashion-MNIST trainiert. Wenn du die Trainingsgenauigkeit und den Trainingsverlust beobachtest, kannst du sagen, dass das Modell gute Arbeit geleistet hat, denn nach 20 Epochen liegt die Trainingsgenauigkeit bei 99 % und der Trainingsverlust ist recht niedrig.
Es sieht jedoch so aus, als ob das Modell überangepasst ist, da der Validierungsverlust 0,4396 und die Validierungsgenauigkeit 92 % beträgt. Die Überanpassung zeigt, dass sich das Netzwerk die Trainingsdaten sehr gut gemerkt hat, aber nicht sicher ist, dass es auch bei ungesehenen Daten funktioniert, weshalb es einen Unterschied in der Trainings- und Validierungsgenauigkeit gibt.
Wahrscheinlich musst du das selbst in die Hand nehmen. In den nächsten Abschnitten erfährst du, wie du die Leistung deines Modells verbessern kannst, indem du eine Dropout-Schicht in das Netz einfügst und alle anderen Schichten unverändert lässt.
Aber lass uns zunächst die Leistung deines Modells auf dem Testset bewerten, bevor du zu einer Schlussfolgerung kommst.
test_eval = fashion_model.evaluate(test_X, test_Y_one_hot, verbose=0)
print('Test loss:', test_eval[0])
print('Test accuracy:', test_eval[1])
('Test loss:', 0.46366268818555401)
('Test accuracy:', 0.91839999999999999)
Die Testgenauigkeit sieht beeindruckend aus. Es stellt sich heraus, dass dein Klassifikator besser abschneidet als der Benchmark, über den hier berichtet wurde, nämlich ein SVM-Klassifikator mit einer mittleren Genauigkeit von 0,897. Außerdem schneidet das Modell im Vergleich zu einigen der Deep-Learning-Modelle, die auf dem GitHub-Profil der Ersteller des Fashion-MNIST-Datensatzes erwähnt werden, gut ab.
Du hast aber gesehen, dass das Modell überangepasst war. Sind diese Ergebnisse wirklich so gut?
Lass uns deine Modellbewertung ins rechte Licht rücken und die Genauigkeits- und Verlustdiagramme zwischen Trainings- und Validierungsdaten darstellen:
accuracy = fashion_train.history['acc']
val_accuracy = fashion_train.history['val_acc']
loss = fashion_train.history['loss']
val_loss = fashion_train.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
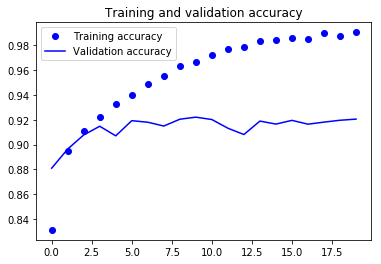
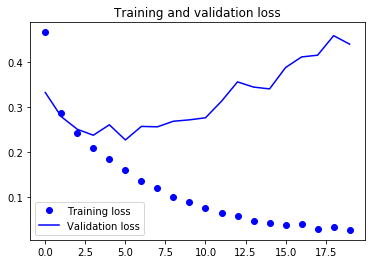
Anhand der beiden obigen Diagramme kannst du sehen, dass die Validierungsgenauigkeit nach 4-5 Epochen fast stagniert und bei bestimmten Epochen kaum noch ansteigt. Zu Beginn stieg die Validierungsgenauigkeit linear mit dem Verlust an, aber dann nahm sie nicht mehr so stark zu.
Der Validierungsverlust zeigt, dass dies ein Zeichen für Overfitting ist. Ähnlich wie die Validierungsgenauigkeit nahm er linear ab, aber nach 4-5 Epochen begann er zu steigen. Das bedeutet, dass das Modell versucht hat, sich die Daten zu merken, und es ist ihm gelungen.
Vor diesem Hintergrund ist es an der Zeit, etwas Dropout in unser Modell einzubauen und zu sehen, ob es hilft, das Overfitting zu reduzieren.
Du kannst eine Dropout-Schicht hinzufügen, um das Problem der Überanpassung bis zu einem gewissen Grad zu lösen. Dropout schaltet zufällig einen Teil der Neuronen während des Trainings aus, wodurch die Abhängigkeit von der Trainingsmenge um einen bestimmten Betrag reduziert wird. Wie viele Bruchteile der Neuronen du ausschalten willst, wird durch einen Hyperparameter bestimmt, der entsprechend eingestellt werden kann. Wenn du also einige Neuronen ausschaltest, kann sich das Netzwerk die Trainingsdaten nicht merken, da nicht alle Neuronen gleichzeitig aktiv sind und die inaktiven Neuronen nichts lernen können.
Erstellen, kompilieren und trainieren wir das Netz also erneut, aber diesmal mit Dropout. Und lass es für 20 Epochen mit einer Stapelgröße von 64 laufen.
batch_size = 64
epochs = 20
num_classes = 10
fashion_model = Sequential()
fashion_model.add(Conv2D(32, kernel_size=(3, 3),activation='linear',padding='same',input_shape=(28,28,1)))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D((2, 2),padding='same'))
fashion_model.add(Dropout(0.25))
fashion_model.add(Conv2D(64, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Dropout(0.25))
fashion_model.add(Conv2D(128, (3, 3), activation='linear',padding='same'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(MaxPooling2D(pool_size=(2, 2),padding='same'))
fashion_model.add(Dropout(0.4))
fashion_model.add(Flatten())
fashion_model.add(Dense(128, activation='linear'))
fashion_model.add(LeakyReLU(alpha=0.1))
fashion_model.add(Dropout(0.3))
fashion_model.add(Dense(num_classes, activation='softmax'))
fashion_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_54 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
leaky_re_lu_61 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
max_pooling2d_52 (MaxPooling (None, 14, 14, 32) 0
_________________________________________________________________
dropout_29 (Dropout) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_55 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
leaky_re_lu_62 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_53 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
dropout_30 (Dropout) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_56 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
leaky_re_lu_63 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
max_pooling2d_54 (MaxPooling (None, 4, 4, 128) 0
_________________________________________________________________
dropout_31 (Dropout) (None, 4, 4, 128) 0
_________________________________________________________________
flatten_18 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_35 (Dense) (None, 128) 262272
_________________________________________________________________
leaky_re_lu_64 (LeakyReLU) (None, 128) 0
_________________________________________________________________
dropout_32 (Dropout) (None, 128) 0
_________________________________________________________________
dense_36 (Dense) (None, 10) 1290
=================================================================
Total params: 356,234
Trainable params: 356,234
Non-trainable params: 0
_________________________________________________________________
fashion_model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(),metrics=['accuracy'])
fashion_train_dropout = fashion_model.fit(train_X, train_label, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(valid_X, valid_label))
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
48000/48000 [==============================] - 66s 1ms/step - loss: 0.5954 - acc: 0.7789 - val_loss: 0.3788 - val_acc: 0.8586
Epoch 2/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3797 - acc: 0.8591 - val_loss: 0.3150 - val_acc: 0.8832
Epoch 3/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3302 - acc: 0.8787 - val_loss: 0.2836 - val_acc: 0.8961
Epoch 4/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.3034 - acc: 0.8868 - val_loss: 0.2663 - val_acc: 0.9002
Epoch 5/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2843 - acc: 0.8936 - val_loss: 0.2481 - val_acc: 0.9083
Epoch 6/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2699 - acc: 0.9002 - val_loss: 0.2469 - val_acc: 0.9032
Epoch 7/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2561 - acc: 0.9049 - val_loss: 0.2422 - val_acc: 0.9095
Epoch 8/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2503 - acc: 0.9068 - val_loss: 0.2429 - val_acc: 0.9098
Epoch 9/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2437 - acc: 0.9096 - val_loss: 0.2230 - val_acc: 0.9173
Epoch 10/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2307 - acc: 0.9126 - val_loss: 0.2170 - val_acc: 0.9187
Epoch 11/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2307 - acc: 0.9135 - val_loss: 0.2265 - val_acc: 0.9193
Epoch 12/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2229 - acc: 0.9160 - val_loss: 0.2136 - val_acc: 0.9229
Epoch 13/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2202 - acc: 0.9162 - val_loss: 0.2173 - val_acc: 0.9187
Epoch 14/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2161 - acc: 0.9188 - val_loss: 0.2142 - val_acc: 0.9211
Epoch 15/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2119 - acc: 0.9196 - val_loss: 0.2133 - val_acc: 0.9233
Epoch 16/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2073 - acc: 0.9222 - val_loss: 0.2159 - val_acc: 0.9213
Epoch 17/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2050 - acc: 0.9231 - val_loss: 0.2123 - val_acc: 0.9233
Epoch 18/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.2016 - acc: 0.9238 - val_loss: 0.2191 - val_acc: 0.9235
Epoch 19/20
48000/48000 [==============================] - 65s 1ms/step - loss: 0.2001 - acc: 0.9244 - val_loss: 0.2110 - val_acc: 0.9258
Epoch 20/20
48000/48000 [==============================] - 64s 1ms/step - loss: 0.1972 - acc: 0.9255 - val_loss: 0.2092 - val_acc: 0.9269
Lass uns das Modell speichern, damit du es direkt laden kannst und es nicht 20 Epochen lang neu trainieren musst. Auf diese Weise kannst du das Modell später laden, wenn du es brauchst, und die Architektur ändern; alternativ kannst du den Trainingsprozess mit diesem gespeicherten Modell starten. Es ist immer eine gute Idee, das Modell - und sogar die Gewichte des Modells - zu speichern, denn das spart dir Zeit. Beachte, dass du das Modell auch nach jeder Epoche speichern kannst, damit du das Training nicht wieder von vorne beginnen musst, wenn ein Problem auftritt, das das Training bei einer Epoche stoppt.
fashion_model.save("fashion_model_dropout.h5py")
Lass uns schließlich auch dein neues Modell bewerten und sehen, wie es sich schlägt!
test_eval = fashion_model.evaluate(test_X, test_Y_one_hot, verbose=1)
10000/10000 [==============================] - 5s 461us/step
print('Test loss:', test_eval[0])
print('Test accuracy:', test_eval[1])
('Test loss:', 0.21460009642243386)
('Test accuracy:', 0.92300000000000004)
Wow! Es sieht so aus, als ob das Hinzufügen von Dropout zu unserem Modell funktioniert hat, auch wenn sich die Testgenauigkeit nicht signifikant verbessert hat, aber der Testverlust im Vergleich zu den vorherigen Ergebnissen gesunken ist.
Jetzt wollen wir ein letztes Mal die Genauigkeit und den Verlust zwischen Trainings- und Validierungsdaten aufzeichnen.
accuracy = fashion_train_dropout.history['acc']
val_accuracy = fashion_train_dropout.history['val_acc']
loss = fashion_train_dropout.history['loss']
val_loss = fashion_train_dropout.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
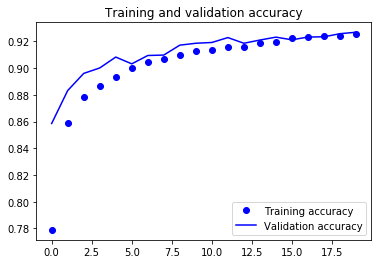
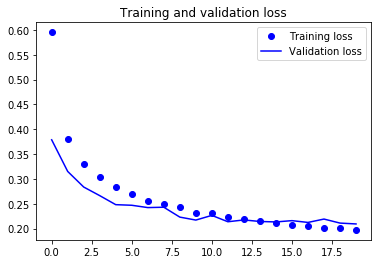
Schließlich kannst du sehen, dass der Validierungsverlust und die Validierungsgenauigkeit beide mit dem Trainingsverlust und der Trainingsgenauigkeit übereinstimmen. Auch wenn der Validierungsverlust und die Genauigkeitslinie nicht linear verlaufen, zeigt dies, dass dein Modell nicht überangepasst ist: Der Validierungsverlust nimmt ab und nicht zu, und zwischen der Trainings- und der Validierungsgenauigkeit besteht keine große Lücke.
Du kannst also sagen, dass die Generalisierungsfähigkeit deines Modells viel besser geworden ist, da der Verlust sowohl im Test- als auch im Validierungsset nur geringfügig höher war als der Trainingsverlust.
predicted_classes = fashion_model.predict(test_X)
Da die Vorhersagen, die du erhältst, Fließkommazahlen sind, ist es nicht möglich, die vorhergesagten Bezeichnungen mit den echten Testbezeichnungen zu vergleichen. Du rundest also die Ausgabe ab, wodurch die Float-Werte in eine Ganzzahl umgewandelt werden. Außerdem verwendest du np.argmax(), um die Indexnummer auszuwählen, die einen höheren Wert in einer Reihe hat.
Nehmen wir zum Beispiel an, dass die Vorhersage für ein Testbild 0 1 0 0 0 0 0 0 0 0 lautet. Die Ausgabe dafür sollte ein Klassenlabel 1 sein.
predicted_classes = np.argmax(np.round(predicted_classes),axis=1)
predicted_classes.shape, test_Y.shape
((10000,), (10000,))
correct = np.where(predicted_classes==test_Y)[0]
print "Found %d correct labels" % len(correct)
for i, correct in enumerate(correct[:9]):
plt.subplot(3,3,i+1)
plt.imshow(test_X[correct].reshape(28,28), cmap='gray', interpolation='none')
plt.title("Predicted {}, Class {}".format(predicted_classes[correct], test_Y[correct]))
plt.tight_layout()
Found 9188 correct labels

incorrect = np.where(predicted_classes!=test_Y)[0]
print "Found %d incorrect labels" % len(incorrect)
for i, incorrect in enumerate(incorrect[:9]):
plt.subplot(3,3,i+1)
plt.imshow(test_X[incorrect].reshape(28,28), cmap='gray', interpolation='none')
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], test_Y[incorrect]))
plt.tight_layout()
Found 812 incorrect labels

Wenn du dir nur ein paar Bilder ansiehst, kannst du nicht mit Sicherheit sagen, warum dein Modell die oben genannten Bilder nicht richtig klassifizieren kann, aber es scheint, dass eine Vielzahl von ähnlichen Mustern in mehreren Klassen die Leistung des Klassifizierers beeinträchtigt, obwohl CNN eine robuste Architektur ist. Zum Beispiel gehören die Bilder 5 und 6 zu verschiedenen Klassen, sehen aber ähnlich aus, vielleicht eine Jacke oder ein langärmeliges Hemd.
Der Klassifizierungsbericht wird uns dabei helfen, die falsch klassifizierten Klassen genauer zu identifizieren. Du kannst beobachten, bei welcher Klasse das Modell von den zehn vorgegebenen Klassen schlecht abgeschnitten hat.
from sklearn.metrics import classification_report
target_names = ["Class {}".format(i) for i in range(num_classes)]
print(classification_report(test_Y, predicted_classes, target_names=target_names))
precision recall f1-score support
Class 0 0.77 0.90 0.83 1000
Class 1 0.99 0.98 0.99 1000
Class 2 0.88 0.88 0.88 1000
Class 3 0.94 0.92 0.93 1000
Class 4 0.88 0.87 0.88 1000
Class 5 0.99 0.98 0.98 1000
Class 6 0.82 0.72 0.77 1000
Class 7 0.94 0.99 0.97 1000
Class 8 0.99 0.98 0.99 1000
Class 9 0.98 0.96 0.97 1000
avg / total 0.92 0.92 0.92 10000
Du kannst sehen, dass der Klassifikator für die Klasse 6 sowohl bei der Genauigkeit als auch beim Recall unterdurchschnittlich abschneidet. Für die Klassen 0 und 2 fehlt es dem Klassifikator an Präzision. Auch bei Klasse 4 ist der Klassifikator sowohl bei der Genauigkeit als auch bei der Wiedererkennung leicht unterlegen.
Geh weiter!
Dieses Tutorial war ein guter Einstieg in Faltungsneuronale Netze in Python mit Keras. Wenn du leicht oder sogar mit etwas mehr Mühe folgen konntest, gut gemacht! Versuche einige Experimente, vielleicht mit derselben Modellarchitektur, aber mit verschiedenen Arten von öffentlichen Datensätzen.
Es gibt noch viel zu lernen, warum also nicht den Kurs Deep Learning in Python von DataCamp besuchen? In der Zwischenzeit solltest du dir auch die Keras-Dokumentation ansehen, falls du das noch nicht getan hast. Hier findest du weitere Beispiele und Informationen zu allen Funktionen, Argumenten, weiteren Ebenen usw. Es wird zweifellos eine unverzichtbare Ressource sein, wenn du lernst, wie man mit neuronalen Netzen in Python arbeitet!
Wenn du lieber ein Buch lesen möchtest, in dem die Grundlagen des Deep Learning (mit Keras) erklärt werden und wie es in der Praxis eingesetzt wird, solltest du unbedingt das Buch Deep Learning in Python von François Chollet lesen.
Erfahre mehr über Python und Deep Learning
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
