Curso
Manipulação de dados em SQL
4 h
324.1K
Usaremos o Banco de Dados de Empresas Unicórnio, que está disponível no DataLab, o notebook de dados habilitado para IA do DataCamp. Essas empresas são chamadas de "Unicórnio" porque são empresas iniciantes com uma avaliação de mais de um bilhão de dólares. Portanto, esse banco de dados contém os dados dessas Empresas Unicórnio e é composto por sete tabelas. Para simplificar, vamos nos concentrar em três tabelas: companies, sales, e product_emissions.
GROUP BYGROUP BY é um comando SQL comumente usado para agregar os dados e obter insights a partir deles. Há três fases quando você agrupa dados:
GROUP BY Exemplo 1Podemos começar mostrando um exemplo simples de GROUP BY. Suponhamos que você queira encontrar os dez principais países com o maior número de empresas Unicórnio.
SELECT *
FROM companies
Também seria bom se você pudesse ordenar os resultados em ordem decrescente com base no número de empresas
SELECT country, COUNT(*) AS n_companies
FROM companies
GROUP BY country
ORDER BY n_companies DESC
LIMIT 10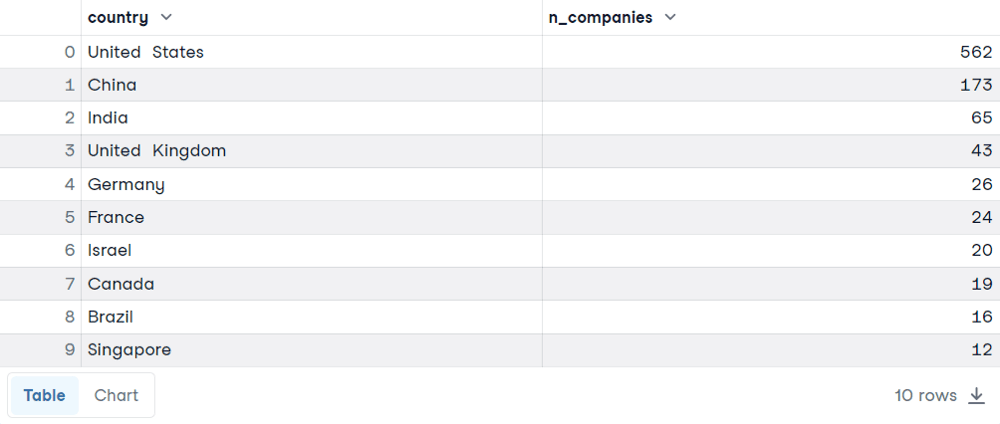
Aqui estão os resultados. Você provavelmente não ficará surpreso ao encontrar os EUA, a China e a Índia na classificação. Vamos explicar a decisão por trás dessa consulta:
COUNT(*) para contar as linhas de cada grupo, que corresponde ao país. Além disso, também usamos o alias SQL para renomear a coluna com um nome mais explicável. Você pode fazer isso usando a palavra-chave AS, seguida do novo nome. COUNT é abordado com mais detalhes no tutorial da FUNÇÃO SQL COUNT().GROUP BY para agregar os dados com base no país. ORDER BY é necessário para que você visualize os países na ordem correta, do maior número para o menor número de empresas. LIMIT, que é seguido pelo número de linhas que você deseja nos resultados.GROUP BY Exemplo 2 Agora, analisaremos a tabela com as vendas. Para cada número de pedido, temos o tipo de cliente, a linha de produtos, a quantidade, o preço unitário, o total, etc.
Desta vez, estamos interessados em encontrar o preço médio por unidade, o número total de pedidos e o ganho total para cada linha de produto:
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
ORDER BY total_gain DESC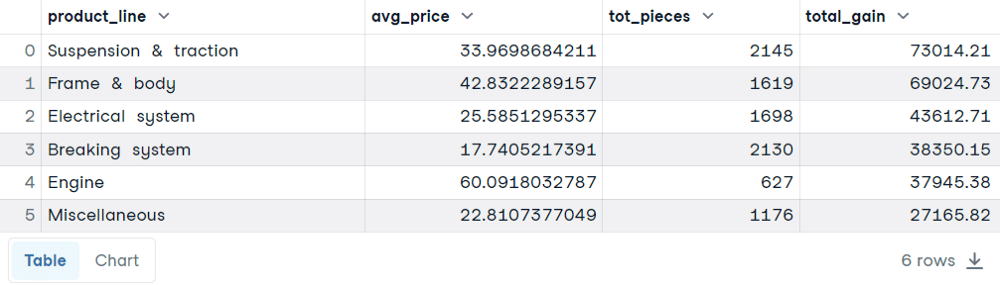
AVG() para obter o preço médio e a função SUM() para calcular o número total de pedidos e o ganho total para cada linha de produto. ORDER BY é opcional. Ela foi incluída para destacar como os ganhos totais mais altos nem sempre são proporcionais a preços médios ou peças totais mais altos. WHEREVejamos novamente o exemplo anterior. Agora, queremos colocar uma condição na consulta: queremos filtrar apenas o número total de pedidos superiores a 40.000. Vamos tentar a cláusula WHERE:
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
WHERE SUM(total) > 40000
GROUP BY product_line
ORDER BY total_gain DESCEssa consulta retornará o seguinte erro:

Esse erro não é possível passar funções agregadas na cláusula WHERE. Precisamos de um novo comando para resolver esse problema.
Assim como WHERE, a cláusula HAVING filtra as linhas de uma tabela. Enquanto o WHERE tentou filtrar a tabela inteira, o HAVING filtra as linhas em cada um dos grupos definidos por GROUP BY
Aqui está o exemplo anterior novamente, substituindo a palavra WHERE por HAVING.
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
HAVING SUM(total) > 40000
ORDER BY total_gain DESC
Dessa vez, você produzirá três linhas. As outras linhas de produtos não correspondiam ao critério, então passamos de seis resultados para três.
O que mais você observou na consulta? Não passamos o alias da coluna para HAVING, mas a agregação do campo original. Você está se perguntando por quê? Você desvendará o mistério no próximo exemplo.
Como último exemplo, usaremos a tabela chamada product_emissions, que contém a emissão dos produtos fornecidos pelas empresas.
Desta vez, estamos interessados em mostrar a pegada média de carbono do produto (pcf) para cada empresa que pertence ao grupo do setor "Tecnologia de Hardware e Equipamentos". Além disso, seria útil ver o número de produtos de cada empresa para entender se há alguma relação entre o número de produtos e a pegada de carbono. Também usamos novamente o site HAVING para extrair empresas com uma pegada média de carbono superior a 100.
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg_carbon_footprint_pcf>100
ORDER BY n_products
Um erro foi exibido após a tentativa de usar o alias. Para a cláusula HAVING, o nome da nova coluna não existe, portanto, você não poderá filtrar a consulta. Vamos corrigir a solicitação:
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg(carbon_footprint_pcf)>100
ORDER BY n_products
Dessa vez, a condição funcionou, e podemos visualizar os resultados na tabela. Acabamos de aprender que os aliases de coluna não podem ser usados em HAVING porque essa condição é aplicada antes de SELECT. Por esse motivo, ele não pode reconhecer os campos dos novos nomes.
Essa é a ordem dos comandos ao escrever a consulta:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BYMas há uma pergunta que você precisa fazer a si mesmo. Em que ordem os comandos SQL são executados? Como seres humanos, muitas vezes consideramos como certo que o computador lê e interpreta o SQL de cima para baixo. Mas a realidade é diferente do que pode parecer. Essa é a ordem correta de execução:
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
LIMIT Portanto, o processador de consultas não começa em SELECT, mas começa selecionando as tabelas a serem incluídas, e SELECT é executado depois de HAVING. Isso explica por que HAVING não permite o uso de ALIAS, enquanto ORDER BY não tem problemas com isso. Além desse aspecto, essa ordem de execução esclarece o motivo pelo qual HAVING é usado junto com GROUP BY para aplicar condições em dados agregados, enquanto WHERE não pode.
Depois de ler este tutorial, você deve ter uma ideia clara da diferença entre GROUP BY e HAVING. Você pode praticar no DataLab para dominar esses conceitos.
Se quiser passar para o próximo nível do caminho de aprendizado de SQL, você pode fazer nosso curso SQL Intermediário. Se ainda precisar fortalecer seus fundamentos de SQL, você pode voltar ao curso Introdução ao SQL para aprender sobre os fundamentos da linguagem.
Cursos de SQL
Curso
Curso
Tutorial
Allan Ouko
Tutorial
Travis Tang
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
Tutorial
DataCamp Team

