
Kurs
LangChain ile Retrieval Augmented Generation (RAG)
3 sa
18.8K
Erişimle zenginleştirilmiş üretim (RAG) sistemlerini ilk keşfetmeye başladığımda, performanslarını etkileyen en fazla göz ardı edilen ama en kritik faktörlerden birinin parçalama olduğunu hızla fark ettim.
Özünde parçalama, belgeler, deşifreler veya teknik kılavuzlar gibi büyük bilgi parçalarını daha küçük ve yönetilebilir segmentlere ayırma sürecidir. Bu segmentler daha sonra yapay zekâ sistemleri tarafından işlenebilir, gömülebilir ve geri çağrılabilir.
Modern dil modelleri ve onların bağlam sınırlamalarıyla çalışırken, etkili parçalama stratejilerini anlamanın ve uygulamanın RAG boru hatları, semantik arama sistemleri veya belge işleme uygulamaları kuran herkes için vazgeçilmez olduğunu görüyorum.
Bu rehberde parçalama kavramını anlatacak, yapay zekâ uygulamalarında neden önemli olduğunu açıklayacak, RAG boru hattındaki rolünü tanımlayacak ve farklı stratejilerin geri getirme doğruluğunu nasıl etkileyebileceğini tartışacağım. Ayrıca pratik uygulama hususları, değerlendirme yöntemleri, alana özgü kullanım örnekleri ve projeniz için doğru yaklaşımı seçmenize yardımcı olabilecek en iyi uygulamaları ele alacağım.
RAG ve yapay zekâ uygulamalarında yeniyseniz, Retrieval Augmented Generation (RAG) with LangChain, AI Fundamentals Certification veya Artificial Intelligence (AI) Strategy gibi kurslarımızdan birini almanızı öneririm.
Parçalamanın önemi basit veri organizasyonunun çok ötesine uzanır; yapay zekâ sistemlerinin bilgiyi nasıl anladığını ve geri getirdiğini temelden şekillendirir.
Büyük dil modelleri ve RAG boru hatları, bağlam pencereleri ve hesaplama kısıtları doğası gereği sınırlı olduğundan parçalamaya ihtiyaç duyar.
Büyük belgeleri uygun şekilde parçalara ayırmadan işlediğimde, sistem çoğu zaman önemli bağlamsal ilişkileri kaybediyor ve geri getirme sırasında ilgili bilgileri belirlemekte zorlanıyor. Etkili parçalama, sorgu kalıpları ve kullanıcı niyetiyle hizalı, anlamsal olarak tutarlı segmentler oluşturarak doğrudan geri getirme hassasiyetini artırır.
Deneyimlerime göre, iyi uygulanmış parçalama stratejileri, bilginin mantıksal akışını korurken her parçanın anlamlı gömme işlemleri için yeterli bağlam içermesini sağlayarak semantik arama yeteneklerini önemli ölçüde iyileştirir. Bu yaklaşım, gömme modellerinin nüanslı ilişkileri yakalamasına ve geri getirme sırasında daha doğru benzerlik eşleştirmesine imkân tanır.
Öte yandan, zayıf parçalama stratejileri yapay zekâ boru hattı boyunca zincirleme olumsuz etkiler yaratır. Keyfi bölmeler, kavramlar arasındaki kritik ilişkileri koparabilir; bu da eksik veya yanıltıcı yanıtlara yol açar. Parçalar çok büyük olduğunda, geri getirme sistemleri belirli ilgili pasajları tespit etmekte zorlanır; aşırı küçük parçalar ise doğru anlama için yeterli bağlamdan yoksundur. Bu sorunlar nihayetinde kullanıcı memnuniyetini azaltır ve sistem güvenilirliğini zedeler.
Parçalama, RAG boru hattında kritik bir konumdadır; ham belge alımı ile anlamlı bilgi geri getirme arasında köprü görevi görür. Uçtan uca RAG boru hattında, parçalama genellikle belge ön işleme sonrasında, ancak gömme oluşturulmadan önce gerçekleşir. Parçalama süreci doğrudan gömme adımını besler; burada her parça anlamsal anlamı yakalayan vektör temsillere dönüştürülür.
RAG Boru Hattı
Parçalama, gömme ve geri getirme arasındaki ilişki, her bileşenin etkinliğinin diğerlerinin performansına bağlı olduğu sıkı bağlı bir sistem oluşturur.
İyi yapılandırılmış parçalar oluşturduğumda, gömme modelleri daha zengin vektör temsilleri üretebilir; bu da bir kullanıcı sorgu yaptığında daha doğru geri getirme sonuçlarını mümkün kılar. Bu sinerji, parçalamadaki iyileştirmelerin genellikle tüm boru hattı genelinde ölçülebilir performans kazanımlarına dönüştüğü anlamına gelir.
Bununla birlikte, bazı yeni yaklaşımlar bu geleneksel sıralamaya meydan okuyor. Örneğin, sonradan parçalama yaklaşımı önce tüm belgeleri gömer ve yalnızca sorgu anında parçalara ayırır; sonuçları daha sonra daha hızlı erişim için önbelleğe alır. Bu yöntem, asla sorgulanmayabilecek belgelerin önceden işlenmesinden kaçınırken sorguya özgü parçalamaya imkân tanır; ancak ilk erişimde gecikme ekler ve ek altyapı gerektirir.
Benzer şekilde, geç parçalama ayrıntılı bölütlemeyi geri getirmeye erteler. Çok sayıda küçük parça için gömmeleri önceden hesaplamak yerine, sistem daha kaba temsilleri (ör. tüm belgeler veya bölümler) saklar ve bir sorgu geldiğinde dinamik olarak böler. Bu, daha geniş bağlamı korurken başlangıçtaki işlemeyi azaltır; ancak ilk sorguda gecikme ekler ve ek altyapı gerektirir.
Yaklaşımdan bağımsız olarak, parçalama stratejileri kullanılan dil modelinin bağlam penceresine—modelin bir seferde işleyip dikkate alabileceği azami metin miktarına—uyum sağlamalıdır.
Artık parçalamanın ne olduğuna ve boru hattında nereye oturduğuna dair bir fikir edindiğinize göre, etkili parçalama stratejilerine yön veren temel ilkelere bakma zamanı. Bu temelleri anlamak, parçalamayı geniş bir yapay zekâ ve RAG uygulamaları yelpazesinde uygulamak için zemin hazırlar.
Parçalama gereklidir; çünkü dil modellerinin bağlam penceresi sınırlıdır. Birincil hedef, modelin bağlam penceresi içinde, her biri bağımsız olarak anlamlı olan ve birlikte belgenin genel yapısını ve amacını koruyan parçalar oluşturmaktır.
Ancak, yalnızca bağlam penceresi dikkate alınmamalıdır. Parçalama stratejileri tasarlarken üç temel ilkeye odaklanırım:
Bu ilkeler birlikte, parçaları hem model için kullanışlı hem de geri getirme boru hatları için verimli kılar. Bu temeli oluşturduktan sonra, pratikte kullanılan en yaygın parçalama stratejilerini ele alabilirim.
Parçalama stratejileri yelpazesi, farklı içerik türlerine, uygulamalara ve performans gereksinimlerine uyarlanmış çeşitli yaklaşımlar sunar. Aşağıdaki görselde, sonraki bölümlerde daha ayrıntılı ele alacağım başlıca parçalama yöntemlerinin bir özetini görebilirsiniz.
Parçalama Stratejilerine Genel Bakış
Bu kapsamlı özet, basit kural tabanlı yaklaşımlardan sofistike yapay zekâ destekli tekniklere evrimi gösterir; her biri belirli uygulamalar ve performans gereksinimleri için farklı avantajlar sunar.
En yaygın kullanılan parçalama stratejilerine yakından bakalım. Her yöntemin benzersiz güçlü yönleri, sınırlamaları ve en uygun kullanım senaryoları vardır. Bu farkları anlayarak, tek boyuta uyan çözümlere varsayılan olarak gitmek yerine belirli bir proje için doğru yaklaşımı seçebilirim. En basit yaklaşımla başlayacağız: sabit boyutlu parçalama.
Sabit boyutlu parçalama en basit yöntemdir. Metni, anlam veya yapıyı dikkate almadan karakterlere, kelimelere veya token'lara göre parçalara böler.
Sabit boyutlu parçalamanın başlıca avantajı hesaplama verimliliğidir—hızlı, öngörülebilir ve uygulaması kolaydır. Dezavantajı ise çoğu zaman anlamsal yapıyı göz ardı etmesidir; bu da geri getirme doğruluğunu azaltabilir. Bu yöntemi genellikle basitlik ve hızın anlamsal hassasiyetten ağır bastığı ve belge yapısının önemli olmadığı durumlarda kullanırım. Performansı iyileştirmek için, sınırlar arasında bağlamı korumak üzere parçalara genellikle örtüşme eklerim.
Bu eksiklerin bir kısmını gidermenin bir yolu da, genellikle nokta veya soru işareti gibi noktalama işaretlerini tespit ederek doğal dil sınırlarına saygı duyan cümle tabanlı parçalamayı kullanmaktır.
Bu yaklaşım okunabilirliği korur ve her parçanın kendi içinde tutarlı kalmasını sağlar. Sabit boyutlu parçalamaya kıyasla, hem insanlar hem de modeller için yorumlaması daha kolay segmentler üretir. Ancak cümle uzunlukları değişkendir; bu nedenle parça boyutları düzensiz olabilir ve her zaman daha derin anlamsal ilişkileri yakalamayabilir.
Cümle tabanlı parçalamayı, makine çevirisi, duygu analizi veya özetleme gibi doğal dil akışına dayanan uygulamalarda en faydalı buluyorum. Ancak belgeler basit cümlelerden daha fazla yapıya sahipse, özyinelemeli parçalama esnek bir alternatif sunar.
Özyinelemeli parçalama, önceki yöntemlerden daha gelişmiş bir tekniktir. Her parça tanımlı bir boyut sınırına sığana kadar, bölme kurallarını adım adım uygular. Örneğin, önce bölüm başlıklarına göre, sonra paragraflara, en sonunda cümlelere göre bölebilirim. Süreç, her parça yönetilebilir ve önceden tanımlanmış boyut içinde kalana kadar devam eder.
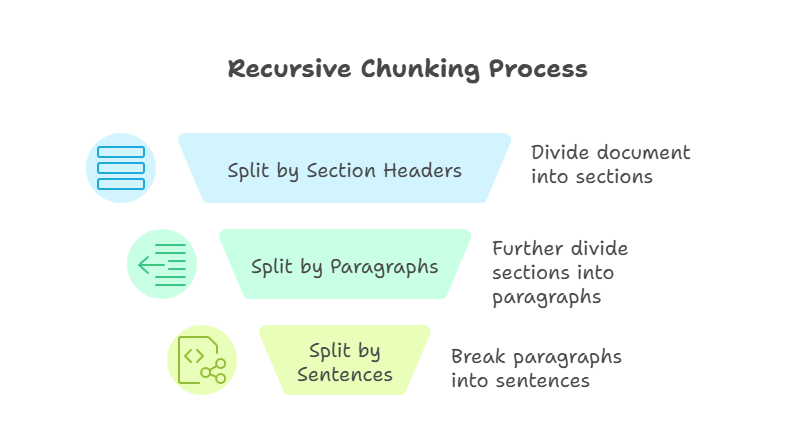
Özyinelemeli Parçalama
Bu yaklaşımın ana avantajı esnekliktir. Yukarıdan aşağıya çalışarak, özyinelemeli parçalama belge yapısını korurken model bağlam pencereleriyle uyumluluğu sağlar. Ancak, özyinelemeli parçalama uygulaması daha karmaşık olabilir ve sonuçların kalitesi, kaynak belgenin ne kadar iyi yapılandırıldığına bağlıdır.
Net hiyerarşilere sahip teknik kılavuzlar veya diğer belgelerle çalışırken sıklıkla özyinelemeli parçalamaya başvururum.
Özyinelemeli yöntemler yapıya dayanırken, anlamsal parçalama odağı anlama kaydırır; metni kavramsal sınırlara göre böler. Anlamsal parçalama, gömmeler veya anlamsal benzerlik kullanarak konu kaymalarının olduğu yerlerde metni bölen anlam farkında bir tekniktir. Keyfi sınırlar yerine, parçalar anlamla tanımlanır.
Bir yaklaşım, metni cümlelere bölmek ve aralarındaki anlamsal benzerliği ölçmektir (ör. gömmeler üzerinde kosinüs benzerliği); tutarlılık düştüğünde yeni parçaları işaretlemek. Daha gelişmiş uygulamalar, karmaşık belgelerde konu kaymalarını daha iyi yakalayan kümeleme yöntemlerini veya denetimli sınır tespit modellerini kullanır.
Anlamsal Parçalama
Bu yöntem anlamsal tutarlılığı korur ve her parçanın tek bir fikir veya temayı kapsamasını sağlar. Teknikler; doğal kırılma noktalarını tespit etmek için gömme benzerliği, kümeleme veya diğer anlamsal mesafe hesaplamalarını içerebilir.
En büyük avantajı hassasiyettir—anlamsal parçalama, geri getirme sırasında kullanıcı niyetiyle yakından hizalı parçalar oluşturur. Başlıca dezavantajı ise hesaplama maliyetidir; çünkü ön işleme sırasında metnin gömülmesini gerektirir. Doğruluğun hızdan önemli olduğu, hukuk veya tıp gibi alana özgü RAG sistemlerinde anlamsal parçalamayı kullanırım.
Anlamsal parçalamanın anlamsal tutarlılığa vurgu yapmasına karşılık, kayan pencere parçalama, örtüşen parçalarla bir pencereyi metin üzerinde kaydırarak sürekliliği vurgular. Örneğin, 500 token’lık bir parça boyutu (pencere) ve 250 adım (stride) kullanırsam, her parça bir öncekiyle yarı yarıya örtüşür.
Bu örtüşme, parça sınırları boyunca bağlamı korur ve kenarlarda önemli bilgilerin kaybolma riskini azaltır. Ayrıca, bir sorguya yanıt olarak birden fazla örtüşen parçanın yüzeye çıkabilmesi nedeniyle geri getirme doğruluğunu artırır. Taviz ise fazlalıktır—örtüşme, depolama ve işlem maliyetlerini artırır. Kayan pencereler, sohbet günlükleri veya podcast deşifreleri gibi yapılandırılmamış metinler için özellikle kullanışlıdır.
Kayan Pencere Parçalama
Bu stratejiyi uygularken, özellikle teknik veya konuşma metinlerinde sınırlar arasında bağlamı korumak için genellikle parçalar arasında %20–50 örtüşme kullanırım. LangChain gibi çerçevelerde 200–400 token’lık parça boyutları yaygın varsayılanlardır; ancak bu, model bağlam sınırları ve belge türüne göre ayarlanabilir. Depolama verimliliğinin daha az önemli, bağlamın korunmasının ise kritik olduğu uygulamalar için bu yaklaşımı öneririm.
Süreklilik tek başına yeterli olmadığında ve belge yapısının korunması gerektiğinde, hiyerarşik ve bağlamsal parçalama devreye girer.
Hiyerarşik parçalama bir belgenin yapısını, bölümlerden cümlelere kadar korur. Düz bir parça listesi üretmek yerine, orijinal hiyerarşiyi yansıtan bir ağaç oluşturur. Her parça, üstteki ve alttaki seviyelerle ebeveyn–çocuk ilişkisi içindedir. Örneğin, bir bölüm birden çok paragraf içerir (ebeveyn → çocuklar) ve her paragraf birden çok cümle içerebilir.
Geri getirme sırasında bu yapı esnek gezinmeyi mümkün kılar. Bir sorgu cümle düzeyindeki bir parçayla eşleşirse, sistem ebeveyn paragraftan veya hatta tüm bölümden ek bağlam sağlamak üzere yukarı doğru genişleyebilir. Tersine, geniş bir sorgu bölüm düzeyinde bir parçayla eşleşirse, sistem en ilgili alt paragrafa veya cümleye inebilir. Bu çok seviyeli geri getirme, döndürülen içeriğin kapsamını uyarlayabildiği için hem kesinliği hem de kapsayıcılığı (recall) iyileştirir.
Hiyerarşik Parçalama
Bağlamsal parçalama ise bir adım daha ileri giderek başlıklar, zaman damgaları veya kaynak referansları gibi üst verilerle (metadata) parçaları zenginleştirir. Bu ek bilgiler, geri getirme sistemlerinin sonuçları ayırt etmesine yardımcı olan önemli sinyaller sağlar. Örneğin, iki belge neredeyse özdeş cümleler içerebilir; ancak bölüm başlıkları veya zaman damgaları, bir sorgu için hangisinin daha ilgili olduğunu belirleyebilir. Üst veriler ayrıca yanıtları kaynağına geri izlemeyi kolaylaştırır; bu da özellikle düzenlemeye tabi veya uyumluluk odaklı alanlarda değerlidir.
Bağlamsal Parçalama
Hiyerarşik ve bağlamsal parçalamanın ana faydası doğruluk ve esnekliktir. Taviz ise hem ön işleme hem de geri getirme mantığında artan karmaşıklıktır; çünkü sistemin parçaları bağımsız birimler olarak ele almak yerine aralarındaki ilişkileri yönetmesi gerekir. Yapının ve izlenebilirliğin korunmasının zorunlu olduğu hukuk sözleşmeleri, finansal raporlar veya teknik şartnameler gibi alanlar için bu yaklaşımları öneririm.
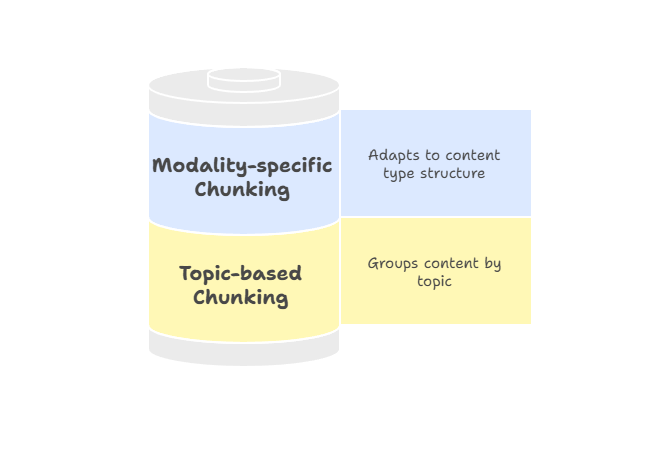
Tüm belgeler katı bir hiyerarşiyi takip etmez; bu nedenle konu tabanlı veya modaliteye özgü parçalama, ilgili içeriği gruplandırmak için daha esnek bir yol sunar.
Konu tabanlı parçalama, anlamsal sınırları belirlemek için konu modellemede Gizli Dirichlet Ayrımı (LDA) gibi algoritmalar veya gömme tabanlı kümeleme yöntemleri kullanarak metni tematik birimlere göre gruplar.
Sabit boyutlar veya yapısal işaretler yerine amaç, bir temayla ilgili tüm içeriği bir arada tutmaktır. Bu yaklaşım, farklı konular arasında geçiş yapan araştırma raporları veya makaleler gibi uzun biçimli içerikler için iyi çalışır. Her parça tek bir temaya odaklı kaldığından, geri getirme sonuçları kullanıcı niyetiyle daha uyumlu olur ve ilgisiz materyal içerme olasılığı azalır.
Modaliteye özgü parçalama, bilgilerin her ortamın yapısına saygı duyacak şekilde bölütlenmesini sağlayarak stratejileri farklı içerik türlerine uyarlar. Örneğin:
Konu Tabanlı ve Modaliteye Özgü Parçalama
Üst veriler, modaliteye özgü parçalamada özellikle önemli bir rol oynar. Örneğin, tablo satırlarına sütun başlıkları eklemek, altyazıları görsel bölgelerle ilişkilendirmek veya deşifrelere konuşmacı etiketleri ve zaman damgaları eklemek, geri getirme sistemlerinin hem doğru parçayı bulmasına hem de onu doğru yorumlamasına yardımcı olur. Bu zenginleştirme, sonuçların ilgililiklerini açıklayan bağlamsal sinyallerle birlikte gelmesi sayesinde hem kesinliği hem de kullanıcı güvenini artırır.
Modaliteye özgü parçalamayı, çok modlu boru hatları veya metin tabanlı stratejilere tam olarak uymayan geleneksel olmayan belgelerle çalışırken uygulamayı öneririm. Bu, her içerik türünün, geri getirme kalitesini ve kullanılabilirliğini en üst düzeye çıkaracak şekilde temsil edilmesini sağlar.
Bu kural ve anlam odaklı yöntemlerin ötesinde, yapay zekâ destekli dinamik parçalama ve etkenci parçalama gibi son teknoloji yaklaşımlar sınırları daha da zorluyor.
Yapay zekâ destekli dinamik parçalama, önceden tanımlanmış kurallara güvenmek yerine doğrudan büyük bir dil modelini kullanarak parça sınırlarını belirler. LLM belgeyi tarar, doğal kırılma noktalarını belirler ve parça boyutunu uyarlamalı olarak ayarlar.
Yoğun bölümler daha küçük parçalara ayrılabilirken, daha hafif bölümler gruplanabilir. Bu, geri getirme doğruluğunu artıran, tam kavramları yakalayan anlamsal olarak tutarlı parçalarla sonuçlanır. Bu yöntem, geri getirme hassasiyetinin işlem hacmi veya maliyetten daha önemli olduğu, hukuk sözleşmeleri, uyumluluk kılavuzları veya araştırma makaleleri gibi yüksek değerli, karmaşık belgelerle çalışırken uygundur.
Öte yandan, etkenci parçalama bu fikri daha üst düzeyde akıl yürütme ekleyerek geliştirir. Metni sadece LLM’e böldürmek yerine, bir yapay zekâ etkencisi belgeyi ve kullanıcı niyetini değerlendirir ve nasıl parçalara ayıracağına karar verir.
Etkenci, farklı bölümler için farklı stratejiler seçebilir. Örneğin, bir tıbbi raporu hasta geçmişi, laboratuvar sonuçları ve hekim notlarına göre ayırırken, anlatı betimlemelerine anlamsal segmentasyon uygulayabilir. Ayrıca belirli parçalara zaman damgaları, tanı kodları veya klinisyen tanımlayıcıları gibi üst veriler ekleyebilir.
Bu şekilde, etkenci parçalama bir orkestrasyon katmanı görevi görür: etkenci, tek bir yöntemi tüm belgeye uygulamak yerine parçalama yaklaşımlarını dinamik olarak seçer veya birleştirir. Sonuç, daha özel ve bağlam farkında bir parçalamadır; ancak maliyeti, artan karmaşıklık ve hesaplama gereksinimleridir.
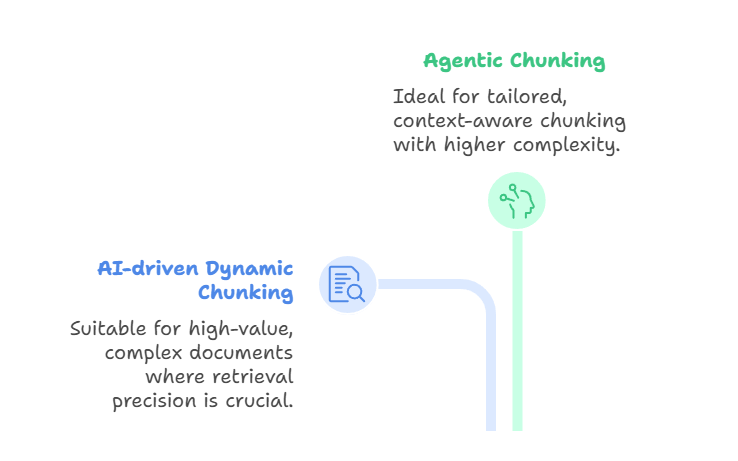
Etkenci ve Yapay Zekâ Destekli Dinamik Parçalama
Her iki yöntem de son teknoloji ve güçlüdür; ancak farklı sorunları ele alır. Yapay zekâ destekli dinamik parçalama, alma sırasında anlamsal olarak hizalı sınırlar üretmeye odaklanırken; etkenci parçalama, her benzersiz belge için parçalama stratejilerini akıllıca seçmeye ve birleştirmeye odaklanır. Yazının başında bahsedilen geç parçalama ile ilişkilidir; bu yaklaşım, uzun bağlamlı modelleri desteklemek için önce tüm belgeyi gömer ve ardından gömme düzeyinde parçalamayı uygular.
Bu yaklaşımlar son derece uyarlanabilir, anlamsal olarak farkında parçalar üretir. Tavizler önemlidir: yapay zekâ destekli parçalama pahalıdır ve yavaş olabilirken, etkenci parçalama ek bir karmaşıklık ve altyapı katmanı ekler. Yapay zekâ destekli dinamik parçalama, içeriğin anlık olarak anlamlı şekilde bölütlenmesi gereken senaryolara en uygundur; etkenci parçalama ise belgelerin büyük farklılık gösterdiği ve strateji düzeyinde akıl yürütme gerektirdiği durumlarda parıldar.
Bir parçalama stratejisi seçtikten sonra, sıradaki adım uygulama ayrıntılarını düşünmektir. Parça boyutu, örtüşme yönetimi ve token sayımı gibi pratik faktörler, sistemin ne kadar iyi performans göstereceğini doğrudan etkiler. Çok büyük olursa parçalar bağlam sınırlarını aşabilir; çok küçük olursa anlam kaybolur.
Uyumluluk bir diğer kilit konudur. Farklı modellerin ve gömme çözümlerinin kendine özgü tokenizasyon şemaları ve bağlam pencereleri vardır; bu nedenle parçalama sürecimin bu farklılıkları hesaba kattığından emin olurum.
Altyapı tarafında, bellek yönetimi ve hesaplama verimliliği göz ardı edilemez; örtüşme fazlalığı artırır ve özyinelemeli veya anlamsal yöntemler işlem yükü ekleyebilir. Parça genişletme veya üst veri zenginleştirme gibi son işlem adımları bağlamı geri kazanmaya yardımcı olabilir; ancak bunlar da karmaşıklık getirir.
Bu temeller kurulduktan sonra, parçalama stratejilerinin pratikte ne kadar iyi çalıştığını ölçmek önemlidir.
Parçalamanın etkinliği sadece teoriden ibaret değildir—açık metriklerle ölçülmesi gerekir.
Örneğin, Bağlam kesinliği (precision) geri getirilen parçaların kaç tanesinin gerçekten sorguyla ilgili olduğunu ölçerken; bağlam kapsayıcılığı (recall) bilgi tabanındaki ilgili parçaların kaçının başarıyla geri getirildiğini ölçer.
Birlikte, bir parçalama stratejisinin getiricinin doğru bilgiyi bulmasına yardımcı olup olmadığını ortaya koyarlar.
Yakından ilişkili bir diğer metrik bağlam ilgililiğidir; getirilen parçaların kullanıcı niyetiyle ne kadar iyi hizalandığına odaklanır ve top-K gibi geri getirme ayarları optimize edilirken özellikle kullanışlıdır.
Diğer parça özel metrikler olan parça kullanımı, modelin yanıtını üretmek için bir parçanın içeriğinin ne kadarını gerçekten kullandığını ölçer; eğer kullanım düşükse, parça çok geniş veya gürültülü olabilir.
Öte yandan, parça atfı (attribution), sistemin nihai cevaba hangi parçaların katkıda bulunduğunu doğru şekilde belirleyip belirlemediğini değerlendirir. Bu parça düzeyi değerlendirmeler, parçaların yalnızca geri getirilmediğini, aynı zamanda anlamlı şekilde uygulandığını da teyit etmeye yardımcı olur.
Optimizasyon da kilit rol oynar ve genellikle hız ile doğruluk arasında denge kurmak anlamına gelir. Hem hesaplama verimliliğini hem de anlamsal zenginliği geliştirmek için parça boyutları, örtüşme yüzdeleri ve geri getirme parametreleriyle denemeler yapmak kritiktir. Ek olarak, A/B testleri somut geri bildirim sağladığı için gereklidir; yinelemeli ayarlamalar ise stratejinin durağanlaşmak yerine zaman içinde gelişmesini güvence altına alır.
Performans ayarı genel amaçlı sistemleri iyileştirebilse de, alana özgü uygulamalar kendi benzersiz zorluklarını sunar.
Farklı sektörler, parçalama stratejilerinden farklı taleplerde bulunur. Finansta yıllık raporlar veya bildirimler gibi belgeler yoğun ve tekniktir; bu nedenle sayısal tabloların, başlıkların ve dipnotların korunmasını sağlayan bir parçalama stratejisi seçmek zorunludur. Hukuki ve teknik belgeler benzer zorluklar sunar—doğruluk ve yapı vazgeçilmezdir; bu da hiyerarşik veya bağlamla zenginleştirilmiş yaklaşımları özellikle değerli kılar.
Tıbbi ve çok modlu belgeler yeni ihtiyaçlar ortaya koyar. Bir hasta kaydı klinik notları, laboratuvar sonuçlarını ve görüntüleme verilerini birleştirebilir; çok modlu belgeler ise metni grafikler veya ses deşifreleriyle entegre edebilir. Burada, modaliteye özgü parçalama her veri türünün, anlamı koruyacak ve modaliteler arasında hizalamayı sürdürecek şekilde bölütlenmesini sağlar.
Alanın ne olduğundan bağımsız olarak, bir dizi en iyi uygulamayı takip etmek parçalama stratejilerini daha güvenilir ve bakımını daha kolay hâle getirir.
Doğru parçalama stratejisinin seçimi; içerik türü, sorgu karmaşıklığı, mevcut kaynaklar ve modelin bağlam penceresinin boyutu gibi çeşitli faktörlere bağlıdır. Nadiren tüm durumlar için tek bir yönteme güvenirim—bunun yerine yaklaşımı sistemin ihtiyaçlarına uyacak şekilde uyarlarım.
Yinelemeli optimizasyon, uzun vadeli başarının merkezindedir. Parçalamanın etkinliği sürekli test edilmeli, gerçek sorgularla doğrulanmalı ve geri bildirime dayanarak ayarlanmalıdır. Çapraz doğrulama, iyileştirmelerin tek seferlik başarılar olmadığından ve farklı kullanım durumlarında da geçerli olduğundan emin olmaya yardımcı olur.
Son olarak, parçalamayı gelişen bir sistem olarak ele almanızı öneririm. İyi dokümantasyon, düzenli testler ve sürekli bakım, sapmayı önlemeye ve hem veriler hem de modeller değiştikçe boru hatlarının sağlam kalmasını sağlamaya yardımcı olur.
Parçalama bir ön işleme detayı gibi görünebilir; ancak bu rehber boyunca gördüğünüz gibi, erişimle zenginleştirilmiş üretim sistemlerinin performansını temelden şekillendirir. Sabit boyutlu ve cümle tabanlı yöntemlerden gelişmiş anlamsal, etkenci ve yapay zekâ destekli stratejilere kadar her yaklaşım; sadelik, doğruluk, verimlilik ve uyarlanabilirlik arasında farklı tavizler sunar.
Tek bir yöntem her senaryoda işe yaramaz. Doğru parçalama stratejisi; içerik türüne, dil modelinin yeteneklerine ve uygulamanın hedeflerine bağlıdır. Anlamsal tutarlılık, bağlamsal korunma ve hesaplamalı verimlilik gibi ilkelere dikkat ederek; geri getirme hassasiyetini artıran, performansı optimize eden ve daha güvenilir çıktılar sağlayan parçalar tasarlayabilirsiniz.
İleriye baktığımızda, parçalama stratejilerinin daha da dinamik, uyarlanabilir ve modele duyarlı hâle gelmesi muhtemeldir. Uzun bağlamlı modeller geliştikçe ve değerlendirme araçları olgunlaştıkça, parçalamanın statik bir ön işleme adımı olmaktan çıkıp kullanımdan sürekli öğrenen, akıllı ve bağlam duyarlı bir sürece dönüşmesini bekliyorum.
RAG sistemleriyle geliştirme yapan herkes için, doğru ve verimli geri getirme boru hatları oluşturmak üzere parçalamaya hâkim olmak esastır.
Öğrenmeye devam etmek için şu kaynaklara göz atmayı unutmayın:
Öne Çıkan DataCamp Kursları
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
