
Course
Retrieval Augmented Generation (RAG) with LangChain
3 hr
17.8K
When I first started exploring retrieval-augmented generation (RAG) systems, I quickly realized that one of the most overlooked but critical factors influencing their performance is chunking.
At its core, chunking is the process of dividing large pieces of information, such as documents, transcripts, or technical manuals, into smaller, more manageable segments. These segments can then be processed, embedded, and retrieved by AI systems.
As I work with modern language models and their context limitations, I find that understanding and applying effective chunking strategies is essential for anyone building RAG pipelines, semantic search systems, or document processing applications.
In this guide, I will walk you through the concept of chunking, explain why it matters in AI applications, describe its role in the RAG pipeline, and discuss how different strategies can impact retrieval accuracy. I will also cover practical implementation considerations, evaluation methods, domain-specific use cases, and best practices that can help you select the right approach for your project.
If you are new to RAG and AI applications, I recommend taking one of our courses, such as Retrieval Augmented Generation (RAG) with LangChain, AI Fundamentals Certification, or Artificial Intelligence (AI) Strategy.
The importance of chunking extends far beyond simple data organization; it fundamentally shapes how AI systems understand and retrieve information.
Large language models and RAG pipelines require chunking due to their inherent limitations in context windows and computational constraints.
When I process large documents without proper chunking, the system often loses important contextual relationships and struggles to identify relevant information during retrieval. Effective chunking directly enhances retrieval precision by creating semantically coherent segments that align with query patterns and user intent.
In my experience, well-implemented chunking strategies significantly improve semantic search capabilities by maintaining the logical flow of information while ensuring each chunk contains sufficient context for meaningful embeddings. This approach allows embedding models to capture nuanced relationships and enables more accurate similarity matching during retrieval.
On the other hand, poor chunking strategies create cascading negative impacts throughout the AI pipeline. Arbitrary splits can sever critical relationships between concepts, leading to incomplete or misleading responses. When chunks are too large, retrieval systems struggle to identify specific relevant passages, while overly small chunks often lack sufficient context for accurate understanding. These issues ultimately result in reduced user satisfaction and compromised system reliability.
Chunking occupies a critical position in the RAG pipeline, serving as the bridge between raw document ingestion and meaningful knowledge retrieval. In the end-to-end RAG pipeline, chunking usually occurs after document preprocessing but before embedding generation. The chunking process directly feeds into the embedding step, where each chunk is converted into vector representations that capture semantic meaning.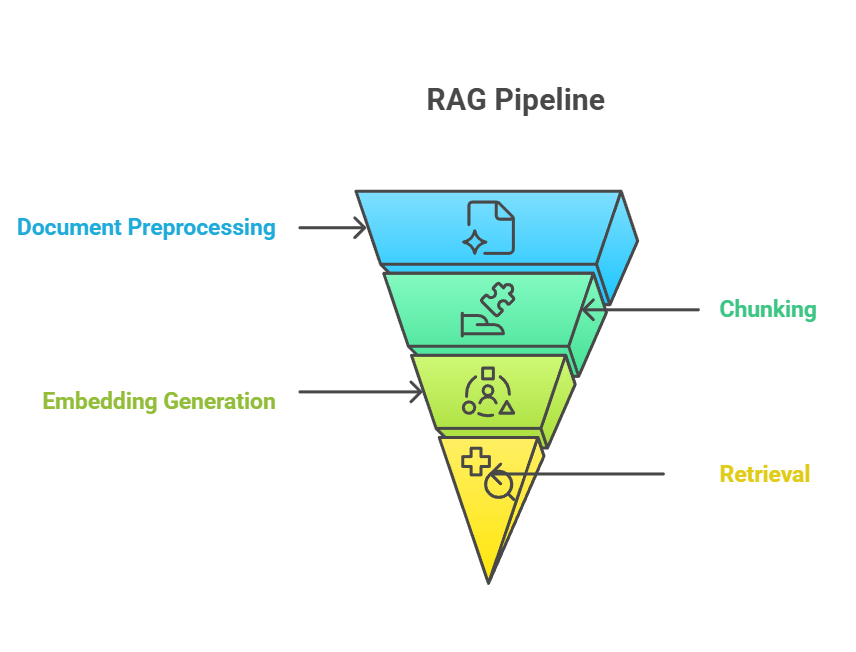
RAG Pipeline
The relationship between chunking, embedding, and retrieval forms a tightly coupled system where each component's effectiveness depends on the performance of the others.
When I create well-structured chunks, embedding models can generate richer vector representations, which in turn enable more accurate retrieval results when a user performs a query. This synergy means that improvements in chunking often translate into measurable performance gains across the entire pipeline.
That said, some newer approaches challenge this traditional order. For example, post-chunking embeds entire documents first and only chunks them at query time, caching results for faster access later. This method avoids pre-processing documents that may never be queried while allowing query-specific chunking, but it introduces latency on first access and requires additional infrastructure.
Similarly, late chunking defers fine-grained segmentation until retrieval. Instead of precomputing embeddings for many small chunks, the system stores coarser representations (e.g., entire documents or sections) and dynamically splits them when a query arrives. This preserves broader context while reducing upfront processing, though it introduces first-query latency and requires additional infrastructure.
Regardless of the approach, chunking strategies must adapt to the context window of the language model in use—the maximum amount of text that a model can process and consider at one time.
Now that you have an idea of what chunking is and where it fits in the pipeline, it’s time to look at the core principles that guide effective chunking strategies. Understanding these fundamentals provides the foundation for applying chunking across a wide range of AI and RAG applications.
Chunking is necessary because language models have a limited context window. The primary objective is to create chunks that are independently meaningful while collectively preserving the document’s overall structure and intent, all within the model’s context window.
However, the context window is not the only thing to consider. When I design chunking strategies, I focus on three core principles:
These principles work together to make chunks both useful to the model and efficient for retrieval pipelines. With this foundation in place, I can now walk through the most common chunking strategies used in practice.
The landscape of chunking strategies offers diverse approaches tailored to different content types, applications, and performance requirements. In the image below, you can see an overview of the main chunking methods, which I will cover in more depth in the following sections.
Overview of Chunking Strategies
This comprehensive overview demonstrates the evolution from simple rule-based approaches to sophisticated AI-driven techniques, each offering distinct advantages for specific applications and performance requirements.
Let’s take a closer look at the most widely used chunking strategies. Each method has unique strengths, limitations, and best-fit scenarios. By understanding these differences, I can choose the right approach for a specific project instead of defaulting to one-size-fits-all solutions. We’ll start with the most straightforward approach: fixed-size chunking.
Fixed-size chunking is the simplest method. It splits text into chunks based on characters, words, or tokens—without regard for meaning or structure.
The main advantage of fixed-size chunking is computational efficiency—it’s fast, predictable, and easy to implement. The drawback is that it often ignores semantic structure, which can reduce retrieval accuracy. I typically use this method when simplicity and speed outweigh semantic precision, and when document structure is not important. To improve performance, I often add overlap between chunks to preserve context across boundaries.
One way to address some of these shortcomings is to use sentence-based chunking, which respects natural language boundaries, usually by detecting punctuation such as periods or question marks.
This approach preserves readability and ensures that each chunk remains self-contained. Compared to fixed-size chunking, it produces segments that are easier for humans and models to interpret. However, sentence lengths vary, so chunk sizes can be uneven, and they may not always capture deeper semantic relationships.
I find sentence-based chunking most useful for applications that rely on natural language flow, such as machine translation, sentiment analysis, or summarization tasks. But when documents have more structure than simple sentences, recursive chunking provides a flexible alternative.
Recursive chunking is a more advanced technique than the previous methods. It applies splitting rules in a stepwise fashion until each chunk fits within a defined size limit. For example, I might first split by section headers, then by paragraphs, and finally by sentences. The process continues until each piece is manageable and within the predefined size.
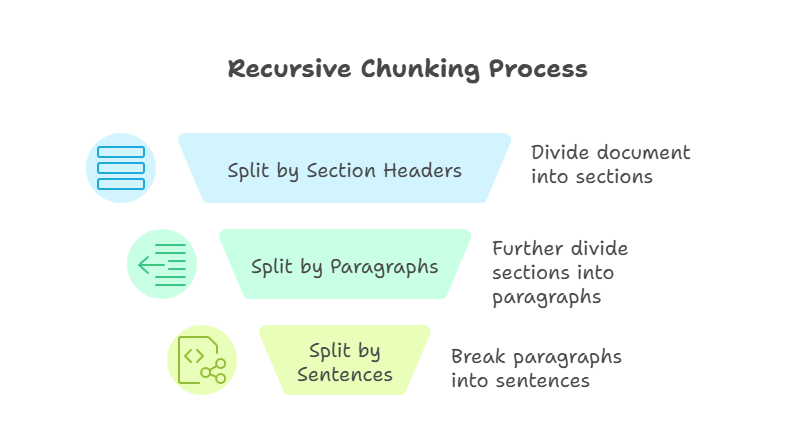
Recursive Chunking
The main advantage of this approach is flexibility. By working top-down, recursive chunking preserves document structure while ensuring compatibility with model context windows. However, recursive chunking can be more complex to implement, and the quality of the results depends on how well the source document is structured.
I often turn to recursive chunking when working with technical manuals or other documents that have clear hierarchies.
While recursive methods rely on structure, semantic chunking shifts the focus to meaning, splitting text based on conceptual boundaries. Semantic chunking is a meaning-aware technique that uses embeddings or semantic similarity to split text where topic shifts occur. Instead of arbitrary boundaries, chunks are defined by meaning.
One approach is to break the text into sentences and measure semantic similarity between them (e.g., cosine similarity on embeddings), marking new chunks when coherence drops. More advanced implementations use clustering methods or supervised boundary-detection models, which better capture topic shifts in complex documents.
Semantic Chunking
This method maintains semantic coherence, ensuring that each chunk covers a single idea or theme. Techniques may include embedding similarity, clustering, or other semantic-distance calculations to detect natural breakpoints.
The biggest advantage is precision—semantic chunking creates chunks that align closely with user intent during retrieval. The main drawback is computational cost, since it requires embedding text during preprocessing. I use semantic chunking when accuracy is more important than speed, such as in domain-specific RAG systems for legal or medical domains.
In contrast to semantic chunking, which emphasizes semantic coherence, sliding-window chunking emphasizes continuity by overlapping chunks, shifting a window across the text. For example, if I use a chunk size (window) of 500 tokens with a stride of 250, each chunk overlaps halfway with the previous one.
This overlap preserves context across chunk boundaries, reducing the risk of losing important information at the edges. It also improves retrieval accuracy, since multiple overlapping chunks may surface in response to a query. The trade-off is redundancy—overlap increases storage and processing costs. Sliding windows are especially useful for unstructured text such as chat logs or podcast transcripts.
Sliding-Window Chunking
When I implement this strategy, I typically use 20–50% overlap between chunks to preserve context across boundaries, especially in technical or conversational text. Chunk sizes of 200–400 tokens are common defaults in frameworks like LangChain, though this can be tuned based on model context limits and document type.. I recommend this approach for applications where context preservation is critical and storage efficiency is less important.
When continuity isn’t enough and document structure must be preserved, hierarchical and contextual chunking come into play.
Hierarchical chunking preserves the full structure of a document, from sections down to sentences. Instead of producing a flat list of chunks, it builds a tree that reflects the original hierarchy. Each chunk has a parent–child relationship with the levels above and below it. For example, a section contains multiple paragraphs (parent → children), and each paragraph may contain multiple sentences.
During retrieval, this structure enables flexible navigation. If a query matches a sentence-level chunk, the system can expand upward to provide additional context from its parent paragraph or even the entire section. Conversely, if a broad query matches a section-level chunk, the system can drill down into the most relevant child paragraph or sentence. This multi-level retrieval improves both precision and recall, since the model can adapt the scope of the returned content.
Hierarchical Chunking
Contextual chunking goes a step further by enriching chunks with metadata such as headings, timestamps, or source references. This additional information provides important signals that help retrieval systems disambiguate results. For instance, two documents may contain nearly identical sentences, but their section titles or timestamps can determine which one is more relevant to a query. Metadata also makes it easier to trace answers back to their source, which is particularly valuable in regulated or compliance-driven domains.
Contextual Chunking
The main benefit of hierarchical and contextual chunking is accuracy and flexibility. The trade-off is added complexity in both preprocessing and retrieval logic, since the system must manage relationships between chunks instead of treating them as independent units. I recommend these approaches for domains like legal contracts, financial reports, or technical specifications, where preserving structure and traceability is essential.
Not all documents follow a strict hierarchy, so topic-based or modality-specific chunking offers a more flexible way to group related content.
Topic-based chunking groups text by thematic units using algorithms such as Latent Dirichlet Allocation (LDA) for topic modeling or embedding-based clustering methods to identify semantic boundaries.
Instead of fixed sizes or structural markers, the goal is to keep all content related to a theme in one place. This approach works well for long-form content such as research reports or articles that shift between distinct subjects. Because each chunk stays focused on a single theme, retrieval results are more aligned with user intent and less likely to include unrelated material.
Modality-specific chunking adapts strategies to different content types, ensuring that information is segmented in a way that respects the structure of each medium. For example:
Topic-Based and Modality-Specific Chunking
Metadata plays a particularly important role in modality-specific chunking. For instance, attaching column headers to table rows, linking captions to image regions, or adding speaker labels and timestamps to transcripts helps retrieval systems both locate the right chunk and interpret it correctly. This enrichment improves both precision and user trust, since results come packaged with contextual signals that explain their relevance.
I recommend applying modality-specific chunking when working with multimodal pipelines or non-traditional documents that don’t fit neatly into text-based strategies. It ensures that every content type is represented in a way that maximizes retrieval quality and usability.
Beyond these rule- and meaning-driven methods, cutting-edge approaches such as AI-driven dynamic chunking and agentic chunking push the boundaries even further.
AI-driven dynamic chunking uses a large language model to determine chunk boundaries directly, rather than relying on predefined rules. The LLM scans the document, identifies natural breakpoints, and adjusts chunk size adaptively.
Dense sections may be split into smaller chunks, while lighter sections can be grouped. This results in semantically coherent chunks that capture complete concepts, improving retrieval accuracy. This method is suitable when working with high-value, complex documents—such as legal contracts, compliance manuals, or research papers—where retrieval precision is more important than throughput or cost.
On the other hand, agentic chunking builds on this idea by introducing reasoning at a higher level. Instead of simply letting the LLM split text, an AI agent evaluates the document and user intent and decides how to chunk it.
The agent may choose different strategies for different sections. For example, breaking down a medical report by patient history, lab results, and physician notes, while applying semantic segmentation to narrative descriptions. It might also enrich certain chunks with metadata such as timestamps, diagnosis codes, or clinician identifiers.
In this way, agentic chunking acts as an orchestration layer: the agent selects or combines chunking approaches dynamically, rather than applying a single method across the entire document. The result is more tailored and context-aware chunking, though at the expense of greater complexity and computational requirements.
Agentic and AI-Driven Dynamic Chunking
Both methods are cutting-edge and powerful, but they address different problems. AI-driven dynamic chunking focuses on producing semantically aligned boundaries during ingestion, while agentic chunking focuses on intelligently selecting and combining chunking strategies for each unique document. They are related to late chunking, mentioned at the beginning of the article, which supports long-context models by embedding an entire document first and then applying chunking at the embedding level.
These approaches deliver highly adaptive, semantically aware chunks. The trade-offs are significant: AI-driven chunking is expensive and may be slower, while agentic chunking adds another layer of complexity and infrastructure. AI-driven dynamic chunking is best suited for scenarios where content needs to be segmented meaningfully on the fly, while agentic chunking shines when documents vary widely and demand strategy-level reasoning.
Once I’ve chosen a chunking strategy, the next step is to think about implementation details. Practical factors such as chunk size, overlap management, and token counting directly influence how well the system performs. Too large, and chunks may exceed context limits; too small, and they lose meaning.
Compatibility is another key concern. Different models and embedding solutions have unique tokenization schemes and context windows, so I make sure my chunking process accounts for these differences.
On the infrastructure side, memory management and computational efficiency can’t be overlooked; overlap increases redundancy, and recursive or semantic methods can add processing overhead. Post-processing steps such as chunk expansion or metadata enrichment can help recover context, but they also introduce complexity.
With these foundations in place, it’s important to measure how well chunking strategies actually work in practice.
Chunking effectiveness isn’t just about theory—it’s something that must be measured with clear metrics.
For instance, Context precision measures how many of the retrieved chunks are actually relevant to the query, while context recall measures how many relevant chunks from the knowledge base were successfully retrieved.
Together, they reveal whether a chunking strategy helps the retriever find the right information.
Closely related is context relevancy, which focuses on how well the retrieved chunks align with the user’s intent, making it especially useful when tuning retrieval settings like top-K values.
Other chunk-specific metrics, such as chunk utilization, measure how much of a chunk’s content the model actually used to generate its response; if utilization is low, the chunk may be too broad or noisy.
On the other hand, chunk attribution evaluates whether the system correctly identifies which chunks contributed to the final answer.. These chunk-level evaluations help confirm whether chunks are not only retrieved but also meaningfully applied.
Optimization also plays a key role and often means balancing speed with accuracy. Experimenting with chunk sizes, overlap percentages, and retrieval parameters to improve both computational efficiency and semantic richness is critical. Additionally, A/B testing is necessary as it provides concrete feedback, while iterative adjustments ensure the strategy improves over time instead of stagnating.
While performance tuning can improve general-purpose systems, domain-specific applications present their own unique challenges.
Different industries place different demands on chunking strategies. In finance, documents like annual reports or filings are dense and technical, so choosing a chunking strategy that preserves numeric tables, headers, and footnotes is mandatory. Legal and technical documents present similar challenges—accuracy and structure are non-negotiable, which makes hierarchical or context-enriched approaches especially valuable.
Medical and multimodal documents introduce emerging needs. A patient record might combine clinical notes, lab results, and imaging data, while multimodal documents could integrate text with charts or audio transcripts. Here, modality-specific chunking ensures that each data type is segmented in a way that preserves meaning while maintaining alignment across modalities.
Regardless of the domain, following a set of best practices makes chunking strategies more reliable and easier to maintain.
Selecting the right chunking strategy depends on several factors: content type, query complexity, available resources, and the size of the model’s context window. I rarely rely on a single method for all cases—instead, I adapt the approach to match the system’s needs.
Iterative optimization is central to long-term success. Chunking effectiveness must be tested continuously, validating results with real queries and adjusting based on feedback. Cross-validation helps ensure that improvements aren’t just one-off successes but hold up across different use cases.
Finally, I recommend treating chunking as an evolving system. Good documentation, regular testing, and ongoing maintenance help prevent drift and ensure that pipelines remain robust as both data and models change.
Chunking may seem like a preprocessing detail, but as you’ve seen throughout this guide, it fundamentally shapes how retrieval-augmented generation systems perform. From fixed-size and sentence-based methods to advanced semantic, agentic, and AI-driven strategies, each approach offers trade-offs between simplicity, accuracy, efficiency, and adaptability.
No single method works for every scenario. The right chunking strategy depends on the content type, the capabilities of the language model, and the goals of the application. By paying attention to principles like semantic coherence, contextual preservation, and computational efficiency, you can design chunks that improve retrieval precision, optimize performance, and ensure more trustworthy outputs.
Looking ahead, chunking strategies will likely become even more dynamic, adaptive, and model-aware. As long-context models evolve and evaluation tools mature, I expect chunking to move from being a static preprocessing step to an intelligent, context-sensitive process that continuously learns from usage.
For anyone building with RAG systems, mastering chunking is essential for creating retrieval pipelines that are accurate, efficient, and future-ready.
To keep learning, be sure to check out the following resources:
Top DataCamp Courses
Course
Course
Course
blog
Stanislav Karzhev
12 min
Tutorial
Eugenia Anello
Tutorial
Ryan Ong
Tutorial
Bex Tuychiev
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Josep Ferrer

