
Cursus
Retrieval Augmented Generation (RAG) met LangChain
3 Hr
18.9K
Toen ik voor het eerst retrieval-augmented generation (RAG)-systemen ging verkennen, merkte ik al snel dat een van de meest over het hoofd geziene, maar cruciale factoren voor de prestaties chunking is.
In de kern is chunking het proces waarbij grote brokken informatie, zoals documenten, transcripties of technische handleidingen, worden opgedeeld in kleinere, beter hanteerbare segmenten. Deze segmenten kunnen vervolgens door AI-systemen worden verwerkt, geëncodeerd en opgehaald.
Omdat ik werk met moderne taalmodellen en hun contextbeperkingen, vind ik dat het begrijpen en toepassen van effectieve chunking-strategieën essentieel is voor iedereen die RAG-pijplijnen, semantische zoeksystemen of documentverwerkingstoepassingen bouwt.
In deze gids neem ik je mee door het concept van chunking, leg ik uit waarom het belangrijk is in AI-toepassingen, beschrijf ik de rol in de RAG-pijplijn en bespreek ik hoe verschillende strategieën de retrieval-nauwkeurigheid beïnvloeden. Ik behandel ook praktische implementatie-overwegingen, evaluatiemethoden, domeinspecifieke use-cases en best practices die je helpen de juiste aanpak voor jouw project te kiezen.
Als je nieuw bent met RAG en AI-toepassingen, raad ik aan een van onze cursussen te volgen, zoals Retrieval Augmented Generation (RAG) with LangChain, AI Fundamentals Certification, of Artificial Intelligence (AI) Strategy.
Het belang van chunking gaat veel verder dan eenvoudige gegevensorganisatie; het bepaalt in essentie hoe AI-systemen informatie begrijpen en ophalen.
Grote taalmodellen en RAG-pijplijnen hebben chunking nodig vanwege hun inherente beperkingen in contextvensters en rekenkracht.
Wanneer ik grote documenten zonder goede chunking verwerk, verliest het systeem vaak belangrijke contextuele relaties en heeft het moeite om tijdens retrieval relevante informatie te identificeren. Effectieve chunking verhoogt de precisie van retrieval direct door semantisch samenhangende segmenten te creëren die aansluiten op zoekpatronen en gebruikersintentie.
Uit mijn ervaring verbeteren goed geïmplementeerde chunking-strategieën de mogelijkheden voor semantisch zoeken aanzienlijk doordat de logische informatiestroom behouden blijft, terwijl elk chunk voldoende context bevat voor betekenisvolle embeddings. Deze aanpak stelt embedding-modellen in staat om genuanceerde relaties vast te leggen en maakt nauwkeuriger similariteitsmatching mogelijk tijdens retrieval.
Slechte chunking-strategieën hebben daarentegen een kettingreactie van negatieve effecten in de hele AI-pijplijn. Willekeurige splitsingen kunnen kritieke relaties tussen concepten doorsnijden, wat leidt tot onvolledige of misleidende antwoorden. Als chunks te groot zijn, hebben retrievalsystemen moeite om specifieke relevante passages te identificeren, terwijl te kleine chunks vaak onvoldoende context hebben voor een juiste interpretatie. Dit resulteert uiteindelijk in lagere gebruikerstevredenheid en verminderde systeembedrijfszekerheid.
Chunking neemt een cruciale positie in de RAG-pijplijn in, als brug tussen de ruwe documentinname en betekenisvolle kennisophaling. In de end-to-end RAG-pijplijn vindt chunking meestal plaats na documentvoorbewerking maar vóór het genereren van embeddings. Het chunkingproces gaat direct over in de embedding-stap, waarin elk chunk wordt omgezet in vectorrepresentaties die semantische betekenis vastleggen.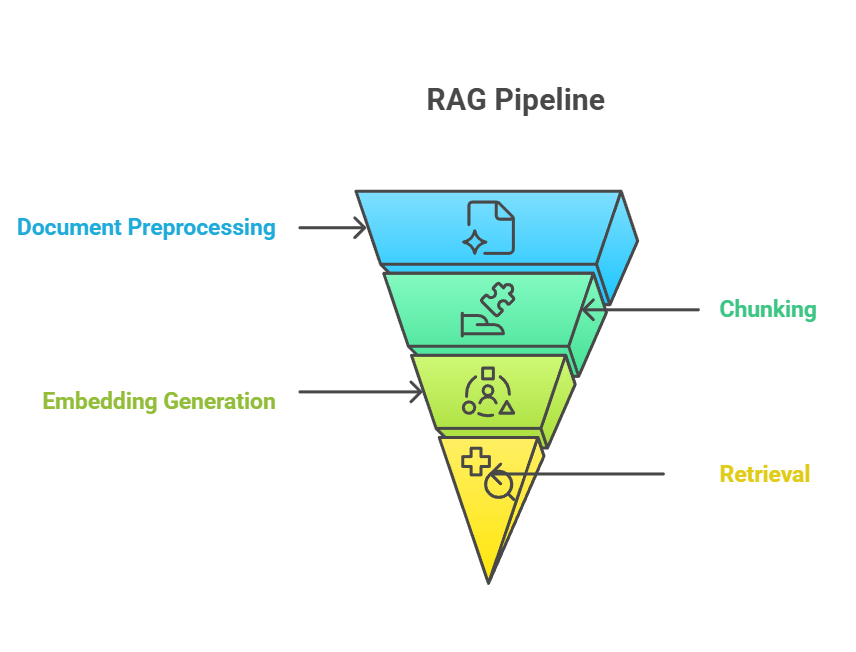
RAG-pijplijn
De relatie tussen chunking, embedding en retrieval vormt een nauw gekoppeld systeem waarbij de effectiviteit van elk onderdeel afhangt van de prestaties van de andere.
Wanneer ik goed gestructureerde chunks maak, kunnen embedding-modellen rijkere vectorrepresentaties genereren, wat op zijn beurt zorgt voor nauwkeurigere retrievalresultaten wanneer een gebruiker een query uitvoert. Deze synergie betekent dat verbeteringen in chunking vaak vertaald worden naar meetbare prestatieverbeteringen in de hele pijplijn.
Dat gezegd hebbende, dagen sommige nieuwere benaderingen deze traditionele volgorde uit. Post-chunking bijvoorbeeld embedt eerst volledige documenten en hakt ze pas tijdens querytijd in stukken, waarbij resultaten in de cache worden opgeslagen voor snellere toegang later. Deze methode voorkomt voorbewerking van documenten die mogelijk nooit worden bevraagd en maakt queryspecifieke chunking mogelijk, maar introduceert latency bij eerste toegang en vereist extra infrastructuur.
Evenzo stelt late chunking fijnmazige segmentatie uit tot aan retrieval. In plaats van embeddings vooraf te berekenen voor veel kleine chunks, slaat het systeem grovere representaties op (bijv. volledige documenten of secties) en splitst deze dynamisch wanneer er een query binnenkomt. Dit behoudt bredere context en vermindert de initiële verwerking, maar introduceert latency bij de eerste query en vereist aanvullende infrastructuur.
Ongeacht de aanpak moeten chunking-strategieën zich aanpassen aan het contextvenster van het gebruikte taalmodel—de maximale hoeveelheid tekst die een model in één keer kan verwerken en in beschouwing nemen.
Nu je een idee hebt wat chunking is en waar het in de pijplijn past, is het tijd om te kijken naar de kernprincipes die effectieve chunking-strategieën sturen. Inzicht in deze basis vormt het fundament om chunking toe te passen in een breed scala aan AI- en RAG-toepassingen.
Chunking is nodig omdat taalmodellen een beperkt contextvenster hebben. Het primaire doel is om chunks te creëren die op zichzelf betekenisvol zijn, terwijl ze gezamenlijk de algehele structuur en intentie van het document behouden, en dat alles binnen het contextvenster van het model.
Het contextvenster is echter niet het enige om rekening mee te houden. Wanneer ik chunking-strategieën ontwerp, focus ik op drie kernprincipes:
Deze principes werken samen om chunks zowel nuttig te maken voor het model als efficiënt voor retrievalpijplijnen. Met dit fundament kan ik nu de meest gangbare chunking-strategieën in de praktijk doornemen.
Het landschap van chunking-strategieën biedt diverse benaderingen, afgestemd op verschillende contenttypen, toepassingen en prestatie-eisen. In de afbeelding hieronder zie je een overzicht van de belangrijkste chunkingmethoden, die ik in de volgende secties uitgebreider behandel.
Overzicht van chunking-strategieën
Dit uitgebreide overzicht toont de evolutie van eenvoudige regelgebaseerde benaderingen naar geavanceerde AI-gestuurde technieken, die elk specifieke voordelen bieden voor bepaalde toepassingen en prestatie-eisen.
Laten we de meest gebruikte chunking-strategieën van dichterbij bekijken. Elke methode heeft unieke sterke punten, beperkingen en beste toepassingsscenario’s. Door deze verschillen te begrijpen, kan ik de juiste aanpak kiezen voor een specifiek project in plaats van te vervallen in one-size-fits-all-oplossingen. We beginnen met de meest eenvoudige aanpak: fixed-size chunking.
Fixed-size chunking is de eenvoudigste methode. Het splitst tekst in chunks op basis van tekens, woorden of tokens—zonder rekening te houden met betekenis of structuur.
Het belangrijkste voordeel van fixed-size chunking is computationele efficiëntie—het is snel, voorspelbaar en eenvoudig te implementeren. Het nadeel is dat semantische structuur vaak wordt genegeerd, wat de retrieval-nauwkeurigheid kan verminderen. Ik gebruik deze methode doorgaans wanneer eenvoud en snelheid zwaarder wegen dan semantische precisie, en wanneer de documentstructuur niet belangrijk is. Om de prestaties te verbeteren, voeg ik vaak overlap toe tussen chunks om context over grenzen heen te behouden.
Een manier om enkele van deze tekortkomingen aan te pakken is zin-gebaseerde chunking, die natuurlijke taalgrenzen respecteert, meestal door interpunctie zoals punten of vraagtekens te detecteren.
Deze aanpak behoudt de leesbaarheid en zorgt ervoor dat elk chunk op zichzelf blijft staan. Vergeleken met fixed-size chunking levert dit segmenten op die voor mensen en modellen makkelijker te interpreteren zijn. Zinslengtes variëren echter, dus chunkgroottes kunnen ongelijkmatig zijn en ze vangen niet altijd diepere semantische relaties.
Ik vind zin-gebaseerde chunking vooral nuttig voor toepassingen die afhankelijk zijn van natuurlijke taalstroom, zoals machinevertaling, sentimentanalyse of samenvattingstaken. Maar wanneer documenten meer structuur hebben dan losse zinnen, biedt recursieve chunking een flexibel alternatief.
Recursieve chunking is geavanceerder dan de voorgaande methoden. Het past splitsingsregels stapsgewijs toe totdat elk chunk binnen een gedefinieerde groottelimiet valt. Ik kan bijvoorbeeld eerst splitsen op sectiekoppen, daarna op alinea’s en tot slot op zinnen. Het proces gaat door totdat elk onderdeel hanteerbaar is en binnen de vooraf bepaalde grootte past.
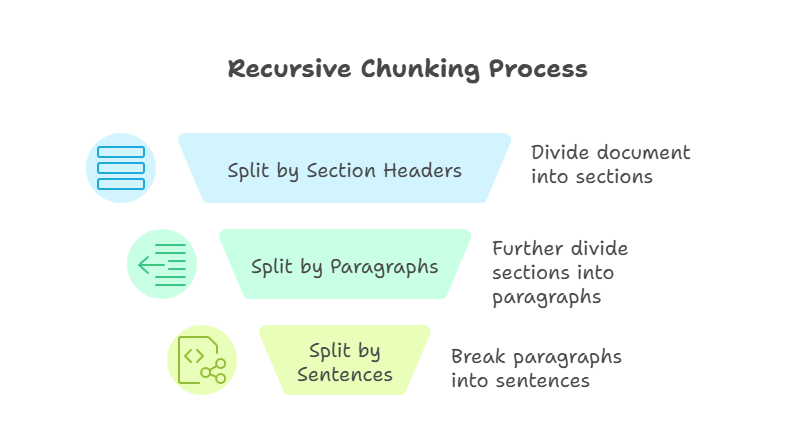
Recursieve chunking
Het belangrijkste voordeel van deze aanpak is flexibiliteit. Door top-down te werken, behoudt recursieve chunking de documentstructuur en blijft het compatibel met de contextvensters van modellen. Wel kan recursieve chunking complexer zijn om te implementeren, en de kwaliteit hangt af van hoe goed het brondocument is gestructureerd.
Ik grijp vaak naar recursieve chunking bij technische handleidingen of andere documenten met duidelijke hiërarchieën.
Waar recursieve methoden op structuur leunen, verschuift semantische chunking de focus naar betekenis en splitst tekst op basis van conceptuele grenzen. Semantische chunking is een betekenisbewuste techniek die embeddings of semantische similariteit gebruikt om tekst te splitsen waar topics verschuiven. In plaats van willekeurige grenzen worden chunks door betekenis bepaald.
Een aanpak is de tekst op te delen in zinnen en de semantische similariteit ertussen te meten (bijv. cosinus-similariteit op embeddings), en nieuwe chunks te markeren wanneer de samenhang afneemt. Geavanceerdere implementaties gebruiken clusteringmethoden of gesuperviseerde grensdetectiemodellen, die topicverschuivingen in complexe documenten beter vastleggen.
Semantische chunking
Deze methode bewaart semantische samenhang, zodat elk chunk één idee of thema dekt. Technieken kunnen embedding-similariteit, clustering of andere semantische-afstandsbepalingen omvatten om natuurlijke breekpunten te detecteren.
Het grootste voordeel is precisie—semantische chunking creëert chunks die nauw aansluiten op gebruikersintentie tijdens retrieval. Het belangrijkste nadeel zijn de rekenkosten, omdat het vereist dat tekst vooraf wordt ge-embed. Ik gebruik semantische chunking wanneer nauwkeurigheid belangrijker is dan snelheid, zoals in domeinspecifieke RAG-systemen voor juridische of medische domeinen.
In tegenstelling tot semantische chunking, die semantische samenhang benadrukt, legt sliding-window chunking de nadruk op continuïteit door chunks te laten overlappen en een venster over de tekst te schuiven. Als ik bijvoorbeeld een chunkgrootte (venster) van 500 tokens met een stride van 250 gebruik, overlapt elk chunk voor de helft met het vorige.
Deze overlap bewaart context over chunkgrenzen heen en verkleint het risico dat belangrijke informatie aan de randen verloren gaat. Het verbetert ook de retrieval-nauwkeurigheid, omdat meerdere overlappende chunks kunnen opduiken als reactie op een query. De keerzijde is redundantie—overlap verhoogt opslag- en verwerkingskosten. Sliding windows zijn vooral nuttig voor ongestructureerde tekst zoals chatlogs of podcasttranscripten.
Sliding-window chunking
Wanneer ik deze strategie implementeer, gebruik ik doorgaans 20–50% overlap tussen chunks om context over grenzen heen te behouden, vooral in technische of conversatietekst. Chunkgroottes van 200–400 tokens zijn gangbare defaults in frameworks zoals LangChain, al kun je dit afstemmen op de contextlimieten van het model en het documenttype. Ik raad deze aanpak aan voor toepassingen waarbij contextbehoud cruciaal is en opslag efficiëntie minder belangrijk is.
Wanneer continuïteit niet volstaat en documentstructuur behouden moet blijven, komen hiërarchische en contextuele chunking in beeld.
Hiërarchische chunking behoudt de volledige structuur van een document, van secties tot op zinsniveau. In plaats van een platte lijst met chunks te produceren, bouwt het een boom die de oorspronkelijke hiërarchie weerspiegelt. Elk chunk heeft een ouder-kindrelatie met de niveaus erboven en eronder. Een sectie bevat bijvoorbeeld meerdere alinea’s (ouder → kinderen) en elke alinea kan meerdere zinnen bevatten.
Tijdens retrieval maakt deze structuur flexibele navigatie mogelijk. Als een query overeenkomt met een chunk op zinsniveau, kan het systeem omhoog uitbreiden om extra context te geven uit de bovenliggende alinea of zelfs de hele sectie. Omgekeerd kan het systeem, als een brede query overeenkomt met een chunk op sectieniveau, inzoomen op de meest relevante onderliggende alinea of zin. Deze meerlagige retrieval verbetert zowel precisie als recall, omdat het model de reikwijdte van de teruggegeven content kan aanpassen.
Hiërarchische chunking
Contextuele chunking gaat nog een stap verder door chunks te verrijken met metadata zoals koppen, tijdstempels of bronverwijzingen. Deze extra informatie levert belangrijke signalen die retrievalsystemen helpen resultaten te disambigueren. Zo kunnen twee documenten bijna identieke zinnen bevatten, maar hun sectietitels of tijdstempels kunnen bepalen welke relevanter is voor een query. Metadata maakt het ook makkelijker om antwoorden naar de bron te herleiden, wat bijzonder waardevol is in gereguleerde of compliance-gedreven domeinen.
Contextuele chunking
Het belangrijkste voordeel van hiërarchische en contextuele chunking is nauwkeurigheid en flexibiliteit. De keerzijde is extra complexiteit in zowel voorbewerking als retrievallogica, omdat het systeem relaties tussen chunks moet beheren in plaats van ze als onafhankelijke eenheden te behandelen. Ik raad deze benaderingen aan voor domeinen zoals juridische contracten, financiële rapporten of technische specificaties, waar het behouden van structuur en traceerbaarheid essentieel is.
Niet alle documenten volgen een strikte hiërarchie, dus topic-gebaseerde of modaliteit-specifieke chunking biedt een flexibelere manier om gerelateerde content te groeperen.
Topic-gebaseerde chunking groepeert tekst in thematische eenheden met behulp van algoritmen zoals Latent Dirichlet Allocation (LDA) voor topicmodellering of embedding-gebaseerde clusteringmethoden om semantische grenzen te identificeren.
In plaats van vaste groottes of structurele markers is het doel om alle content die bij een thema hoort bij elkaar te houden. Deze aanpak werkt goed voor lange content zoals onderzoeksrapporten of artikelen die tussen verschillende onderwerpen schakelen. Omdat elk chunk op één thema gefocust blijft, sluiten retrievalresultaten beter aan op de gebruikersintentie en bevatten ze minder snel irrelevante informatie.
Modaliteit-specifieke chunking past strategieën aan op verschillende contenttypen, zodat informatie wordt gesegmenteerd op een manier die de structuur van elk medium respecteert. Bijvoorbeeld:
Topic-gebaseerde en modaliteit-specifieke chunking
Metadata speelt een bijzonder belangrijke rol in modaliteit-specifieke chunking. Het koppelen van kolomkoppen aan tabelrijen, bijschriften aan afbeeldingsregio’s of sprekerslabels en tijdstempels aan transcripties helpt retrievalsystemen zowel het juiste chunk te lokaliseren als het correct te interpreteren. Deze verrijking verbetert zowel de precisie als het vertrouwen van gebruikers, omdat resultaten worden geleverd met contextuele signalen die hun relevantie verklaren.
Ik raad modaliteit-specifieke chunking aan bij multimodale pijplijnen of niet-traditionele documenten die niet netjes in tekstgebaseerde strategieën passen. Zo wordt elk contenttype vertegenwoordigd op een manier die de kwaliteit en bruikbaarheid van retrieval maximaliseert.
Naast deze regel- en betekenisgestuurde methoden gaan geavanceerde benaderingen zoals AI-gedreven dynamische chunking en agentische chunking nog een stap verder.
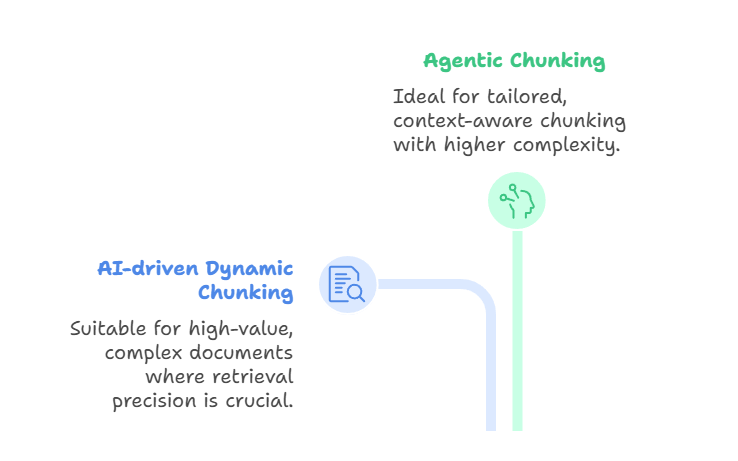
AI-gedreven dynamische chunking gebruikt een groot taalmodel om chunkgrenzen direct te bepalen, in plaats van te vertrouwen op vooraf gedefinieerde regels. Het LLM scant het document, identificeert natuurlijke breekpunten en past chunkgrootte adaptief aan.
Dichte secties kunnen worden opgesplitst in kleinere chunks, terwijl lichtere secties kunnen worden samengevoegd. Dit resulteert in semantisch coherente chunks die complete concepten vangen en de retrieval-nauwkeurigheid verbeteren. Deze methode is geschikt voor werk met waardevolle, complexe documenten—zoals juridische contracten, compliance-handleidingen of onderzoeksartikelen—waar precisie bij retrieval belangrijker is dan doorvoer of kosten.
Agentische chunking bouwt hierop voort door redeneren op een hoger niveau te introduceren. In plaats van het LLM simpelweg tekst te laten splitsen, beoordeelt een AI-agent het document en de gebruikersintentie en beslist hoe te chunken.
De agent kan verschillende strategieën voor verschillende secties kiezen. Bijvoorbeeld een medisch rapport opsplitsen naar patiëntgeschiedenis, laboratoriumresultaten en artsenrapporten, terwijl op narratieve beschrijvingen semantische segmentatie wordt toegepast. Ook kan de agent bepaalde chunks verrijken met metadata zoals tijdstempels, diagnosecodes of zorgverlener-ID’s.
Op deze manier fungeert agentische chunking als een orkestratielaag: de agent selecteert of combineert chunking-benaderingen dynamisch, in plaats van één methode op het hele document toe te passen. Het resultaat is meer op maat gemaakte en contextbewuste chunking, wel ten koste van meer complexiteit en rekenvereisten.
Agentische en AI-gedreven dynamische chunking
Beide methoden zijn geavanceerd en krachtig, maar ze lossen verschillende problemen op. AI-gedreven dynamische chunking richt zich op het produceren van semantisch uitgelijnde grenzen tijdens intake, terwijl agentische chunking zich richt op het intelligent selecteren en combineren van chunking-strategieën voor elk uniek document. Ze zijn verwant aan late chunking, aan het begin van het artikel genoemd, dat long-contextmodellen ondersteunt door eerst een volledig document te embedden en vervolgens chunking toe te passen op embedding-niveau.
Deze benaderingen leveren zeer adaptieve, semantisch bewuste chunks op. De trade-offs zijn aanzienlijk: AI-gedreven chunking is kostbaar en mogelijk trager, terwijl agentische chunking een extra laag complexiteit en infrastructuur toevoegt. AI-gedreven dynamische chunking is het meest geschikt wanneer content on-the-fly betekenisvol moet worden gesegmenteerd, terwijl agentische chunking uitblinkt wanneer documenten sterk variëren en strategie-niveau redenering vragen.
Zodra ik een chunking-strategie heb gekozen, is de volgende stap nadenken over implementatiedetails. Praktische factoren zoals chunkgrootte, overlapbeheer en token-telling beïnvloeden direct hoe goed het systeem presteert. Te groot, en chunks kunnen contextlimieten overschrijden; te klein, en ze verliezen betekenis.
Compatibiliteit is een andere belangrijke zorg. Verschillende modellen en embedding-oplossingen hebben unieke tokenisatieschema’s en contextvensters, dus ik zorg dat mijn chunkingproces met deze verschillen rekening houdt.
Aan de infrastructuurkant mogen geheugenbeheer en computationele efficiëntie niet worden vergeten; overlap vergroot redundantie en recursieve of semantische methoden kunnen extra verwerking vragen. Nabewerking, zoals chunk-expansie of metadata-verrijking, kan helpen context te herstellen, maar introduceert ook complexiteit.
Met deze fundamenten op orde is het belangrijk om te meten hoe goed chunking-strategieën in de praktijk werken.
De effectiviteit van chunking gaat niet alleen over theorie—je moet het meten met duidelijke metrics.
Zo meet context-precisie hoeveel van de opgehaalde chunks daadwerkelijk relevant zijn voor de query, terwijl context-recall meet hoeveel relevante chunks uit de kennisbasis succesvol zijn opgehaald.
Samen laten ze zien of een chunking-strategie de retriever helpt de juiste informatie te vinden.
Hiermee verwant is context-relevantie, dat zich richt op hoe goed de opgehaalde chunks aansluiten op de gebruikersintentie, wat vooral nuttig is bij het afstellen van retrieval-instellingen zoals top-K-waarden.
Andere chunk-specifieke metrics, zoals chunk-benutting, meten hoeveel van de inhoud van een chunk het model daadwerkelijk gebruikte om zijn antwoord te genereren; als de benutting laag is, is het chunk mogelijk te breed of te ruiserig.
Aan de andere kant beoordeelt chunk-attributie of het systeem correct identificeert welke chunks hebben bijgedragen aan het uiteindelijke antwoord. Deze evaluaties op chunk-niveau helpen bevestigen of chunks niet alleen worden opgehaald maar ook betekenisvol worden toegepast.
Optimalisatie speelt ook een sleutelrol en betekent vaak een balans vinden tussen snelheid en nauwkeurigheid. Experimenteren met chunkgroottes, overlappercentages en retrievalparameters om zowel de computationele efficiëntie als de semantische rijkdom te verbeteren is cruciaal. Daarnaast is A/B-testen noodzakelijk omdat het concrete feedback geeft, terwijl iteratieve aanpassingen ervoor zorgen dat de strategie in de tijd verbetert in plaats van stagneert.
Hoewel prestatie-afstelling algemene systemen kan verbeteren, brengen domeinspecifieke toepassingen hun eigen unieke uitdagingen met zich mee.
Verschillende sectoren stellen verschillende eisen aan chunking-strategieën. In de financiële sector zijn documenten zoals jaarverslagen of aangiften dicht en technisch; het kiezen van een chunking-strategie die numerieke tabellen, koppen en voetnoten behoudt is verplicht. Juridische en technische documenten leveren vergelijkbare uitdagingen op—nauwkeurigheid en structuur zijn niet-onderhandelbaar, wat hiërarchische of context-verrijkte benaderingen extra waardevol maakt.
Medische en multimodale documenten introduceren nieuwe behoeften. Een patiëntendossier kan klinische notities, labresultaten en beeldvorming combineren, terwijl multimodale documenten tekst kunnen integreren met grafieken of audiotranscripten. Hier zorgt modaliteit-specifieke chunking ervoor dat elk datatype wordt gesegmenteerd op een manier die betekenis bewaart en tegelijkertijd de afstemming tussen modaliteiten behoudt.
Ongeacht het domein maakt het volgen van een set best practices chunking-strategieën betrouwbaarder en makkelijker te onderhouden.
De juiste chunking-strategie kiezen hangt af van verschillende factoren: contenttype, querycomplexiteit, beschikbare resources en de grootte van het contextvenster van het model. Ik vertrouw zelden op één methode voor alle gevallen—in plaats daarvan pas ik de aanpak aan op de behoeften van het systeem.
Iteratieve optimalisatie is cruciaal voor langetermijnsucces. De effectiviteit van chunking moet continu worden getest, met validatie op basis van echte queries en aanpassing op basis van feedback. Cross-validatie helpt ervoor te zorgen dat verbeteringen geen eenmalige successen zijn maar standhouden over verschillende use-cases.
Tot slot raad ik aan chunking te benaderen als een evoluerend systeem. Goede documentatie, regelmatige tests en doorlopend onderhoud helpen drift te voorkomen en zorgen ervoor dat pijplijnen robuust blijven naarmate data en modellen veranderen.
Chunking lijkt misschien een detail in de voorbewerking, maar zoals je in deze gids hebt gezien, bepaalt het fundamenteel hoe retrieval-augmented generation-systemen presteren. Van fixed-size en zin-gebaseerde methoden tot geavanceerde semantische, agentische en AI-gedreven strategieën: elke aanpak biedt afwegingen tussen eenvoud, nauwkeurigheid, efficiëntie en aanpasbaarheid.
Geen enkele methode werkt in elke situatie. De juiste chunking-strategie hangt af van het contenttype, de mogelijkheden van het taalmodel en de doelen van de toepassing. Door aandacht te besteden aan principes zoals semantische samenhang, contextbehoud en computationele efficiëntie kun je chunks ontwerpen die de precisie van retrieval verbeteren, prestaties optimaliseren en zorgen voor betrouwbaardere outputs.
Vooruitkijkend zullen chunking-strategieën waarschijnlijk nog dynamischer, adaptiever en modelbewuster worden. Naarmate long-contextmodellen evolueren en evaluatietools volwassen worden, verwacht ik dat chunking verschuift van een statische voorbewerking naar een intelligente, contextgevoelige procedure die continu leert van gebruik.
Voor iedereen die met RAG-systemen bouwt, is chunking beheersen essentieel om retrievalpijplijnen te creëren die nauwkeurig, efficiënt en toekomstbestendig zijn.
Blijf leren en bekijk zeker de volgende bronnen:
Topcursussen bij DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
