
Corso
Retrieval Augmented Generation (RAG) con LangChain
3 h
18.8K
Quando ho iniziato a esplorare i sistemi di retrieval-augmented generation (RAG), mi sono subito reso conto che uno dei fattori più trascurati ma cruciali che ne influenzano le prestazioni è il chunking.
Alla base, il chunking è il processo di suddividere grandi quantità di informazioni, come documenti, trascrizioni o manuali tecnici, in segmenti più piccoli e gestibili. Questi segmenti possono poi essere elaborati, incorporati (embedded) e recuperati dai sistemi di IA.
Lavorando con i moderni modelli linguistici e le loro limitazioni di contesto, trovo che comprendere e applicare strategie di chunking efficaci sia essenziale per chiunque costruisca pipeline RAG, sistemi di ricerca semantica o applicazioni di elaborazione documentale.
In questa guida ti accompagnerò nel concetto di chunking, spiegherò perché è importante nelle applicazioni di IA, descriverò il suo ruolo nella pipeline RAG e discuterò di come strategie diverse possano influenzare l’accuratezza del recupero. Coprirò anche considerazioni pratiche di implementazione, metodi di valutazione, casi d’uso specifici per dominio e best practice che possono aiutarti a scegliere l’approccio giusto per il tuo progetto.
Se sei alle prime armi con RAG e le applicazioni di IA, ti consiglio di seguire uno dei nostri corsi, come Retrieval Augmented Generation (RAG) with LangChain, AI Fundamentals Certification o Artificial Intelligence (AI) Strategy.
L’importanza del chunking va ben oltre la semplice organizzazione dei dati; plasma in modo fondamentale come i sistemi di IA comprendono e recuperano le informazioni.
I grandi modelli linguistici e le pipeline RAG richiedono il chunking a causa delle loro limitazioni intrinseche nelle finestre di contesto e nei vincoli computazionali.
Quando elaboro documenti di grandi dimensioni senza un chunking adeguato, il sistema spesso perde importanti relazioni contestuali e fatica a identificare le informazioni rilevanti durante il recupero. Un chunking efficace migliora direttamente la precisione del recupero creando segmenti semanticamente coerenti che si allineano ai pattern delle query e all’intento dell’utente.
Per mia esperienza, strategie di chunking ben implementate migliorano sensibilmente le capacità di ricerca semantica mantenendo il flusso logico delle informazioni e assicurando che ogni chunk contenga contesto sufficiente per embedding significativi. Questo consente ai modelli di embedding di catturare relazioni sottili e rende più accurato il matching per similarità durante il recupero.
Al contrario, strategie di chunking scadenti generano effetti negativi a cascata lungo tutta la pipeline di IA. Suddivisioni arbitrarie possono recidere relazioni critiche tra concetti, portando a risposte incomplete o fuorvianti. Quando i chunk sono troppo grandi, i sistemi di recupero faticano a identificare i passaggi specifici rilevanti, mentre chunk troppo piccoli spesso mancano del contesto necessario per una comprensione accurata. Questi problemi portano in definitiva a una minore soddisfazione degli utenti e a un’affidabilità compromessa del sistema.
Il chunking occupa una posizione critica nella pipeline RAG, fungendo da ponte tra l’ingestione di documenti grezzi e il recupero di conoscenza significativo. Nella pipeline RAG end-to-end, il chunking avviene di solito dopo il preprocessing dei documenti ma prima della generazione degli embedding. Il processo di chunking alimenta direttamente la fase di embedding, in cui ogni chunk viene convertito in rappresentazioni vettoriali che catturano il significato semantico.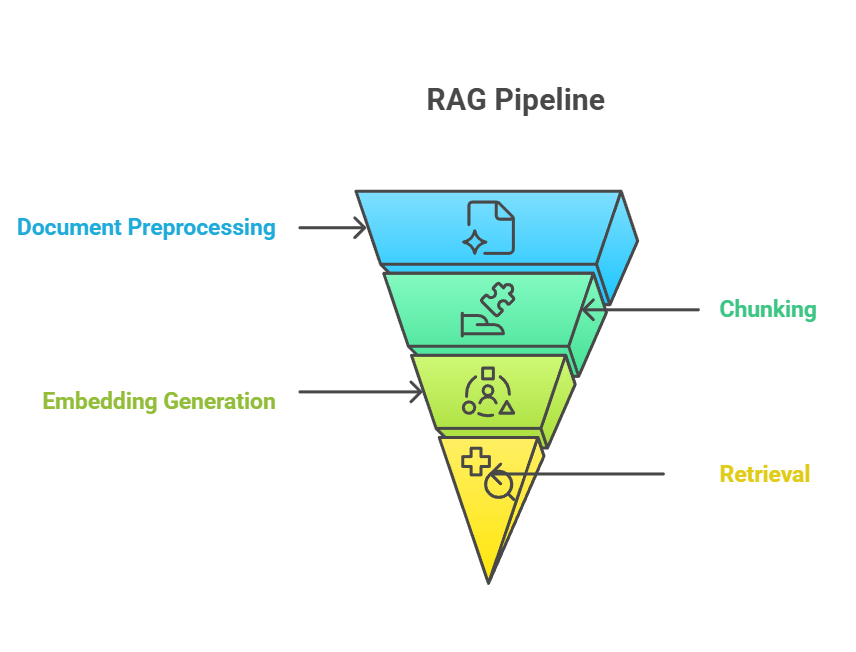
Pipeline RAG
La relazione tra chunking, embedding e retrieval forma un sistema strettamente accoppiato in cui l’efficacia di ciascun componente dipende dalle prestazioni degli altri.
Quando creo chunk ben strutturati, i modelli di embedding possono generare rappresentazioni vettoriali più ricche, che a loro volta consentono risultati di recupero più accurati quando un utente effettua una query. Questa sinergia significa che i miglioramenti nel chunking spesso si traducono in guadagni di prestazioni misurabili lungo l’intera pipeline.
Detto ciò, alcuni approcci più recenti mettono in discussione quest’ordine tradizionale. Ad esempio, il post-chunking incorpora prima i documenti interi e li suddivide solo al momento della query, memorizzando i risultati in cache per un accesso più rapido in seguito. Questo metodo evita di pre-processare documenti che potrebbero non essere mai interrogati e consente un chunking specifico per la query, ma introduce latenza al primo accesso e richiede ulteriore infrastruttura.
Allo stesso modo, late chunking rinvia la segmentazione fine al momento del recupero. Invece di precomputare gli embedding per molti chunk piccoli, il sistema conserva rappresentazioni più grossolane (ad esempio, interi documenti o sezioni) e li suddivide dinamicamente quando arriva una query. Questo preserva un contesto più ampio riducendo l’elaborazione iniziale, ma introduce latenza alla prima query e richiede ulteriore infrastruttura.
Indipendentemente dall’approccio, le strategie di chunking devono adattarsi alla finestra di contesto del modello linguistico in uso, ovvero la quantità massima di testo che un modello può elaborare e considerare in una sola volta.
Ora che hai un’idea di cosa sia il chunking e dove si inserisca nella pipeline, è il momento di guardare ai principi di base che guidano strategie di chunking efficaci. Comprendere questi fondamenti fornisce la base per applicare il chunking in un’ampia gamma di applicazioni AI e RAG.
Il chunking è necessario perché i modelli linguistici hanno una finestra di contesto limitata. L’obiettivo principale è creare chunk che siano significativi in modo indipendente pur preservando collettivamente la struttura e l’intento complessivo del documento, il tutto entro la finestra di contesto del modello.
Tuttavia, la finestra di contesto non è l’unico aspetto da considerare. Quando progetto strategie di chunking, mi concentro su tre principi fondamentali:
Questi principi lavorano insieme per rendere i chunk utili per il modello ed efficienti per le pipeline di recupero. Con queste basi, posso ora passare in rassegna le strategie di chunking più comuni usate in pratica.
Il panorama delle strategie di chunking offre approcci diversi, su misura per vari tipi di contenuti, applicazioni e requisiti di prestazioni. Nell’immagine qui sotto puoi vedere una panoramica dei principali metodi di chunking, che tratterò più in dettaglio nelle sezioni successive.
Panoramica delle strategie di chunking
Questa panoramica completa mostra l’evoluzione dagli approcci semplici basati su regole a tecniche sofisticate guidate dall’IA, ciascuna con vantaggi distinti per specifiche applicazioni ed esigenze prestazionali.
Diamo uno sguardo più da vicino alle strategie di chunking più diffuse. Ogni metodo ha punti di forza, limiti e scenari di utilizzo ideali. Comprendendo queste differenze, posso scegliere l’approccio giusto per un progetto specifico invece di ricorrere a soluzioni universali. Inizieremo con l’approccio più semplice: il chunking a dimensione fissa.
Il chunking a dimensione fissa è il metodo più semplice. Divide il testo in chunk in base a caratteri, parole o token, senza considerare significato o struttura.
Il principale vantaggio del chunking a dimensione fissa è l’efficienza computazionale: è veloce, prevedibile e facile da implementare. Lo svantaggio è che spesso ignora la struttura semantica, riducendo l’accuratezza del recupero. Tendo a usare questo metodo quando semplicità e velocità prevalgono sulla precisione semantica e quando la struttura del documento non è importante. Per migliorare le prestazioni, aggiungo spesso sovrapposizione tra i chunk per preservare il contesto ai confini.
Un modo per superare alcune di queste carenze è usare il chunking basato sulle frasi, che rispetta i confini naturali del linguaggio, di solito rilevando la punteggiatura come punti o punti interrogativi.
Questo approccio preserva la leggibilità e assicura che ogni chunk resti autonomo. Rispetto al chunking a dimensione fissa, produce segmenti più facili da interpretare per esseri umani e modelli. Tuttavia, la lunghezza delle frasi varia, quindi le dimensioni dei chunk possono essere irregolari e non sempre catturano relazioni semantiche più profonde.
Trovo il chunking basato sulle frasi più utile per applicazioni che si basano sul flusso del linguaggio naturale, come traduzione automatica, analisi del sentiment o attività di sintesi. Ma quando i documenti hanno una struttura più articolata delle semplici frasi, il chunking ricorsivo offre un’alternativa flessibile.
Il chunking ricorsivo è una tecnica più avanzata rispetto ai metodi precedenti. Applica regole di suddivisione in modo graduale finché ogni chunk rientra in un limite di dimensione definito. Per esempio, potrei prima dividere per intestazioni di sezione, poi per paragrafi e infine per frasi. Il processo continua finché ogni parte è gestibile e entro la dimensione predefinita.
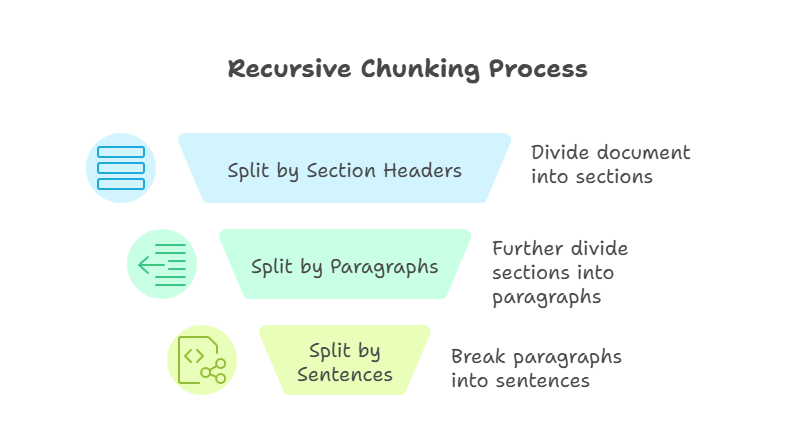
Chunking ricorsivo
Il principale vantaggio di questo approccio è la flessibilità. Lavorando dall’alto verso il basso, il chunking ricorsivo preserva la struttura del documento garantendo la compatibilità con le finestre di contesto del modello. Tuttavia, può essere più complesso da implementare e la qualità dei risultati dipende da quanto è ben strutturato il documento di partenza.
Ricorro spesso al chunking ricorsivo quando lavoro con manuali tecnici o altri documenti che hanno gerarchie chiare.
Mentre i metodi ricorsivi si basano sulla struttura, il chunking semantico sposta l’attenzione sul significato, suddividendo il testo in base a confini concettuali. Il chunking semantico è una tecnica consapevole del significato che usa embedding o similarità semantica per dividere il testo dove avvengono cambi di argomento. Invece di confini arbitrari, i chunk sono definiti dal significato.
Un approccio consiste nel suddividere il testo in frasi e misurare la similarità semantica tra di esse (ad es., similarità coseno sugli embedding), marcando nuovi chunk quando la coerenza cala. Implementazioni più avanzate usano metodi di clustering o modelli supervisionati di rilevamento dei confini, che catturano meglio i cambi di argomento in documenti complessi.
Chunking semantico
Questo metodo mantiene la coerenza semantica, assicurando che ogni chunk copra una singola idea o tema. Le tecniche possono includere similarità tra embedding, clustering o altri calcoli di distanza semantica per rilevare punti di interruzione naturali.
Il vantaggio principale è la precisione: il chunking semantico crea chunk che si allineano strettamente all’intento dell’utente durante il recupero. Lo svantaggio principale è il costo computazionale, poiché richiede l’embedding del testo durante il preprocessing. Uso il chunking semantico quando l’accuratezza è più importante della velocità, ad esempio in sistemi RAG specifici di dominio in ambito legale o medico.
In contrasto con il chunking semantico, che enfatizza la coerenza semantica, il chunking a finestra scorrevole enfatizza la continuità sovrapponendo i chunk e facendo scorrere una finestra sul testo. Per esempio, se uso una dimensione del chunk (finestra) di 500 token con uno stride di 250, ogni chunk si sovrappone per metà al precedente.
Questa sovrapposizione preserva il contesto ai confini dei chunk, riducendo il rischio di perdere informazioni importanti ai margini. Migliora anche l’accuratezza del recupero, poiché più chunk sovrapposti possono emergere in risposta a una query. Il compromesso è la ridondanza: la sovrapposizione aumenta i costi di archiviazione ed elaborazione. Le finestre scorrevoli sono particolarmente utili per testi non strutturati come log di chat o trascrizioni di podcast.
Chunking a finestra scorrevole
Quando implemento questa strategia, in genere uso una sovrapposizione del 20–50% tra i chunk per preservare il contesto ai confini, soprattutto in testi tecnici o conversazionali. Dimensioni dei chunk di 200–400 token sono predefinite comuni in framework come LangChain, anche se possono essere regolate in base ai limiti di contesto del modello e al tipo di documento. Consiglio questo approccio per applicazioni in cui la preservazione del contesto è critica e l’efficienza di archiviazione è meno importante.
Quando la continuità non basta e la struttura del documento deve essere preservata, entrano in gioco chunking gerarchico e contestuale.
Il chunking gerarchico preserva l’intera struttura di un documento, dalle sezioni fino alle frasi. Invece di produrre un elenco piatto di chunk, costruisce un albero che riflette la gerarchia originale. Ogni chunk ha una relazione genitore–figlio con i livelli sopra e sotto. Ad esempio, una sezione contiene più paragrafi (genitore → figli) e ogni paragrafo può contenere più frasi.
Durante il recupero, questa struttura abilita una navigazione flessibile. Se una query corrisponde a un chunk a livello di frase, il sistema può espandersi verso l’alto per fornire ulteriore contesto dal paragrafo genitore o persino dall’intera sezione. Al contrario, se una query ampia corrisponde a un chunk a livello di sezione, il sistema può approfondire il paragrafo o la frase figlia più rilevante. Questo recupero multilivello migliora sia la precisione sia la copertura, poiché il modello può adattare l’ampiezza del contenuto restituito.
Chunking gerarchico
Il chunking contestuale fa un passo oltre arricchendo i chunk con metadati come intestazioni, timestamp o riferimenti alla fonte. Queste informazioni aggiuntive forniscono segnali importanti che aiutano i sistemi di recupero a disambiguare i risultati. Ad esempio, due documenti possono contenere frasi quasi identiche, ma i loro titoli di sezione o i timestamp possono determinare quale sia più rilevante per una query. I metadati facilitano anche il tracciamento delle risposte alla loro fonte, particolarmente prezioso in domini regolamentati o orientati alla conformità.
Chunking contestuale
Il principale beneficio del chunking gerarchico e contestuale è l’accuratezza e la flessibilità. Il compromesso è una maggiore complessità sia nel preprocessing sia nella logica di recupero, poiché il sistema deve gestire le relazioni tra i chunk invece di trattarli come unità indipendenti. Consiglio questi approcci per domini come contratti legali, report finanziari o specifiche tecniche, dove preservare struttura e tracciabilità è essenziale.
Non tutti i documenti seguono una gerarchia rigorosa, quindi il chunking basato su argomenti o specifico per modalità offre un modo più flessibile di raggruppare contenuti correlati.
Il chunking basato su argomenti raggruppa il testo per unità tematiche usando algoritmi come Latent Dirichlet Allocation (LDA) per il topic modeling o metodi di clustering basati su embedding per identificare confini semantici.
Invece di dimensioni fisse o marcatori strutturali, l’obiettivo è mantenere in un unico posto tutti i contenuti legati a un tema. Questo approccio funziona bene per contenuti lunghi come report di ricerca o articoli che passano tra argomenti distinti. Poiché ogni chunk resta focalizzato su un singolo tema, i risultati del recupero sono più allineati all’intento dell’utente e meno inclini a includere materiale non correlato.
Il chunking specifico per modalità adatta le strategie ai diversi tipi di contenuto, assicurando che le informazioni siano segmentate in modo rispettoso della struttura di ciascun medium. Ad esempio:
Chunking basato su argomenti e specifico per modalità
I metadati giocano un ruolo particolarmente importante nel chunking specifico per modalità. Per esempio, associare le intestazioni di colonna alle righe di tabella, collegare le didascalie alle regioni dell’immagine o aggiungere etichette dei parlanti e timestamp alle trascrizioni aiuta i sistemi di recupero sia a individuare il chunk giusto sia a interpretarlo correttamente. Questo arricchimento migliora sia la precisione sia la fiducia dell’utente, poiché i risultati arrivano corredati di segnali contestuali che ne spiegano la pertinenza.
Consiglio di applicare il chunking specifico per modalità quando si lavora con pipeline multimodali o documenti non tradizionali che non si adattano bene alle strategie basate sul testo. Garantisce che ogni tipo di contenuto sia rappresentato in un modo che massimizza la qualità e l’usabilità del recupero.
Oltre a questi metodi basati su regole e significato, approcci all’avanguardia come il chunking dinamico guidato dall’IA e l’agentic chunking spingono ancora più in là i confini.
Il chunking dinamico guidato dall’IA usa un grande modello linguistico per determinare direttamente i confini dei chunk, invece di basarsi su regole predefinite. L’LLM scansiona il documento, identifica punti di interruzione naturali e adatta la dimensione dei chunk in modo dinamico.
Le sezioni dense possono essere suddivise in chunk più piccoli, mentre quelle più leggere possono essere raggruppate. Ne risultano chunk semanticamente coerenti che catturano concetti completi, migliorando l’accuratezza del recupero. Questo metodo è adatto quando si lavora con documenti complessi e di alto valore—come contratti legali, manuali di conformità o articoli scientifici—dove la precisione del recupero è più importante della velocità o del costo.
Dall’altro lato, l’agentic chunking si basa su questa idea introducendo un livello superiore di ragionamento. Invece di limitarsi a far dividere il testo all’LLM, un agente di IA valuta il documento e l’intento dell’utente e decide come effettuare il chunking.
L’agente può scegliere strategie diverse per sezioni diverse. Per esempio, suddividere un referto medico per anamnesi del paziente, risultati di laboratorio e note del medico, applicando al contempo una segmentazione semantica alle descrizioni narrative. Potrebbe anche arricchire alcuni chunk con metadati come timestamp, codici diagnostici o identificativi del clinico.
In questo modo, l’agentic chunking agisce come livello di orchestrazione: l’agente seleziona o combina dinamicamente approcci di chunking, invece di applicare un unico metodo a tutto il documento. Il risultato è un chunking più mirato e consapevole del contesto, a scapito però di maggiore complessità e requisiti computazionali.
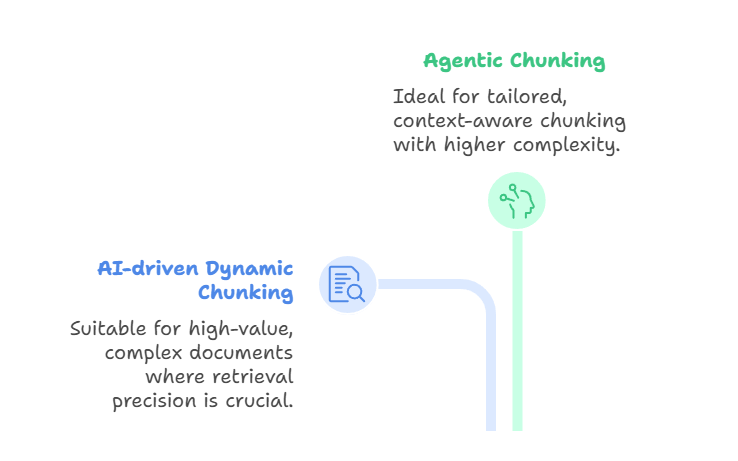
Agentic e chunking dinamico guidato dall’IA
Entrambi i metodi sono all’avanguardia e potenti, ma risolvono problemi diversi. Il chunking dinamico guidato dall’IA si concentra sulla produzione di confini semanticamente allineati durante l’ingestione, mentre l’agentic chunking si concentra sulla selezione e combinazione intelligente di strategie di chunking per ciascun documento. Sono correlati al late chunking, menzionato all’inizio dell’articolo, che supporta i modelli con contesti lunghi incorporando prima l’intero documento e applicando poi il chunking a livello di embedding.
Questi approcci producono chunk altamente adattivi e consapevoli del significato. I compromessi sono significativi: il chunking guidato dall’IA è costoso e può essere più lento, mentre l’agentic chunking aggiunge un ulteriore livello di complessità e infrastruttura. Il chunking dinamico guidato dall’IA è ideale quando è necessario segmentare in modo significativo i contenuti al volo, mentre l’agentic chunking dà il meglio quando i documenti variano molto e richiedono ragionamento a livello di strategia.
Una volta scelta una strategia di chunking, il passo successivo è pensare ai dettagli di implementazione. Fattori pratici come dimensione dei chunk, gestione della sovrapposizione e conteggio dei token influenzano direttamente le prestazioni del sistema. Se i chunk sono troppo grandi, possono superare i limiti di contesto; se sono troppo piccoli, perdono significato.
Un’altra preoccupazione chiave è la compatibilità. Modelli e soluzioni di embedding diversi hanno schemi di tokenizzazione e finestre di contesto uniche, quindi mi assicuro che il processo di chunking tenga conto di queste differenze.
Dal lato dell’infrastruttura, non si possono trascurare gestione della memoria ed efficienza computazionale; la sovrapposizione aumenta la ridondanza e i metodi ricorsivi o semantici possono aggiungere overhead di elaborazione. Fasi di post-processing come l’espansione dei chunk o l’arricchimento con metadati possono aiutare a recuperare contesto, ma introducono anche complessità.
Con queste basi in atto, è importante misurare quanto le strategie di chunking funzionino effettivamente nella pratica.
L’efficacia del chunking non è solo teoria—va misurata con metriche chiare.
Per esempio, la precisione del contesto misura quanti dei chunk recuperati sono effettivamente rilevanti per la query, mentre il richiamo del contesto misura quanti chunk rilevanti nella base di conoscenza sono stati effettivamente recuperati.
Insieme, rivelano se una strategia di chunking aiuta il retriever a trovare le informazioni giuste.
Strettamente correlata è la rilevanza del contesto, che si concentra su quanto bene i chunk recuperati si allineano all’intento dell’utente, risultando particolarmente utile quando si calibrano impostazioni di recupero come i valori top-K.
Altre metriche specifiche per i chunk, come l’utilizzo del chunk, misurano quanto del contenuto di un chunk il modello ha effettivamente usato per generare la risposta; se l’utilizzo è basso, il chunk può essere troppo ampio o rumoroso.
D’altra parte, l’attribuzione del chunk valuta se il sistema identifica correttamente quali chunk hanno contribuito alla risposta finale. Queste valutazioni a livello di chunk aiutano a confermare se i chunk non solo vengono recuperati, ma anche applicati in modo significativo.
L’ottimizzazione gioca anche un ruolo chiave e spesso significa bilanciare velocità e accuratezza. Sperimentare con dimensioni dei chunk, percentuali di sovrapposizione e parametri di recupero per migliorare sia l’efficienza computazionale sia la ricchezza semantica è fondamentale. Inoltre, l’A/B testing è necessario perché fornisce riscontri concreti, mentre aggiustamenti iterativi assicurano che la strategia migliori nel tempo invece di stagnare.
Mentre la messa a punto delle prestazioni può migliorare i sistemi generici, le applicazioni specifiche di dominio presentano sfide loro proprie.
Settori diversi impongono esigenze diverse alle strategie di chunking. In finanza, documenti come bilanci annuali o filing sono densi e tecnici, quindi scegliere una strategia che preservi tabelle numeriche, intestazioni e note a piè di pagina è obbligatorio. Documenti legali e tecnici presentano sfide simili: accuratezza e struttura sono non negoziabili, il che rende gli approcci gerarchici o arricchiti di contesto particolarmente preziosi.
I documenti medici e multimodali introducono esigenze emergenti. Una cartella clinica può combinare note cliniche, risultati di laboratorio e dati di imaging, mentre documenti multimodali possono integrare testo con grafici o trascrizioni audio. Qui, il chunking specifico per modalità assicura che ogni tipo di dato sia segmentato in un modo che preservi il significato mantenendo l’allineamento tra modalità.
Indipendentemente dal dominio, seguire un insieme di best practice rende le strategie di chunking più affidabili e facili da mantenere.
Selezionare la giusta strategia di chunking dipende da diversi fattori: tipo di contenuto, complessità delle query, risorse disponibili e dimensione della finestra di contesto del modello. Raramente mi affido a un unico metodo per tutti i casi; al contrario, adatto l’approccio alle esigenze del sistema.
L’ottimizzazione iterativa è centrale per il successo a lungo termine. L’efficacia del chunking deve essere testata continuamente, convalidando i risultati con query reali e regolando sulla base dei feedback. La validazione incrociata aiuta a garantire che i miglioramenti non siano successi isolati ma si mantengano in casi d’uso diversi.
Infine, consiglio di trattare il chunking come un sistema in evoluzione. Buona documentazione, test regolari e manutenzione continua aiutano a prevenire il drift e assicurano che le pipeline rimangano robuste man mano che dati e modelli cambiano.
Il chunking può sembrare un dettaglio di preprocessing, ma come hai visto in questa guida, plasma in modo fondamentale le prestazioni dei sistemi di retrieval-augmented generation. Dai metodi a dimensione fissa e basati sulle frasi fino alle strategie avanzate semantiche, agentiche e guidate dall’IA, ogni approccio offre compromessi tra semplicità, accuratezza, efficienza e adattabilità.
Nessun metodo è valido per ogni scenario. La strategia di chunking giusta dipende dal tipo di contenuto, dalle capacità del modello linguistico e dagli obiettivi dell’applicazione. Prestando attenzione a principi come coerenza semantica, preservazione del contesto ed efficienza computazionale, puoi progettare chunk che migliorano la precisione del recupero, ottimizzano le prestazioni e garantiscono output più affidabili.
Guardando avanti, le strategie di chunking diventeranno probabilmente ancora più dinamiche, adattive e consapevoli del modello. Man mano che i modelli con contesti lunghi evolvono e gli strumenti di valutazione maturano, mi aspetto che il chunking passi dall’essere un passo statico di preprocessing a un processo intelligente e sensibile al contesto che apprende continuamente dall’uso.
Per chiunque costruisca sistemi RAG, padroneggiare il chunking è essenziale per creare pipeline di recupero accurate, efficienti e pronte per il futuro.
Per continuare a imparare, dai un’occhiata alle seguenti risorse:
I migliori corsi DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

