
Kursus
Retrieval Augmented Generation (RAG) dengan LangChain
3 Hr
18.8K
Saat pertama kali saya mengeksplorasi sistem retrieval-augmented generation (RAG), saya cepat menyadari bahwa salah satu faktor yang sering diabaikan namun krusial dalam memengaruhi kinerjanya adalah chunking.
Intinya, chunking adalah proses membagi informasi besar, seperti dokumen, transkrip, atau manual teknis, menjadi segmen yang lebih kecil dan lebih mudah dikelola. Segmen ini kemudian dapat diproses, di-embed, dan diambil kembali oleh sistem AI.
Saat bekerja dengan model bahasa modern dan keterbatasan konteksnya, saya mendapati bahwa memahami dan menerapkan strategi chunking yang efektif sangat penting bagi siapa pun yang membangun pipeline RAG, sistem pencarian semantik, atau aplikasi pemrosesan dokumen.
Dalam panduan ini, saya akan memaparkan konsep chunking, menjelaskan mengapa hal ini penting dalam aplikasi AI, menggambarkan perannya dalam pipeline RAG, dan membahas bagaimana strategi yang berbeda dapat memengaruhi akurasi pengambilan informasi. Saya juga akan membahas pertimbangan implementasi praktis, metode evaluasi, use case spesifik domain, serta praktik terbaik yang dapat membantu Anda memilih pendekatan yang tepat untuk proyek Anda.
Jika Anda baru mengenal RAG dan aplikasi AI, saya merekomendasikan untuk mengikuti salah satu kursus kami, seperti Retrieval Augmented Generation (RAG) with LangChain, AI Fundamentals Certification, atau Artificial Intelligence (AI) Strategy.
Pentingnya chunking jauh melampaui sekadar pengorganisasian data; ini secara fundamental membentuk bagaimana sistem AI memahami dan mengambil informasi.
Model bahasa besar dan pipeline RAG memerlukan chunking karena keterbatasan bawaan pada jendela konteks dan kendala komputasi.
Saat saya memproses dokumen besar tanpa chunking yang tepat, sistem sering kehilangan hubungan kontekstual penting dan kesulitan mengidentifikasi informasi yang relevan saat pengambilan. Chunking yang efektif secara langsung meningkatkan presisi pengambilan dengan menciptakan segmen koheren secara semantik yang selaras dengan pola kueri dan maksud pengguna.
Berdasarkan pengalaman saya, strategi chunking yang diterapkan dengan baik secara signifikan meningkatkan kemampuan pencarian semantik dengan menjaga alur logis informasi sekaligus memastikan setiap chunk memuat konteks yang cukup untuk embedding yang bermakna. Pendekatan ini memungkinkan model embedding menangkap hubungan yang bernuansa dan menghasilkan pencocokan kemiripan yang lebih akurat saat pengambilan.
Sebaliknya, strategi chunking yang buruk menimbulkan dampak negatif berantai di seluruh pipeline AI. Pemisahan sembarang dapat memutus hubungan kritis antarkonsep, sehingga menghasilkan jawaban yang tidak lengkap atau menyesatkan. Ketika chunk terlalu besar, sistem pengambilan kesulitan mengidentifikasi bagian spesifik yang relevan, sementara chunk yang terlalu kecil sering kali kekurangan konteks yang memadai untuk pemahaman yang akurat. Masalah-masalah ini pada akhirnya menurunkan kepuasan pengguna dan mengurangi keandalan sistem.
Chunking menempati posisi kritis dalam pipeline RAG, berfungsi sebagai jembatan antara pemasukan dokumen mentah dan pengambilan pengetahuan yang bermakna. Dalam pipeline RAG end-to-end, chunking biasanya terjadi setelah prapemrosesan dokumen tetapi sebelum pembuatan embedding. Proses chunking langsung memberi masukan ke langkah embedding, di mana setiap chunk diubah menjadi representasi vektor yang menangkap makna semantik.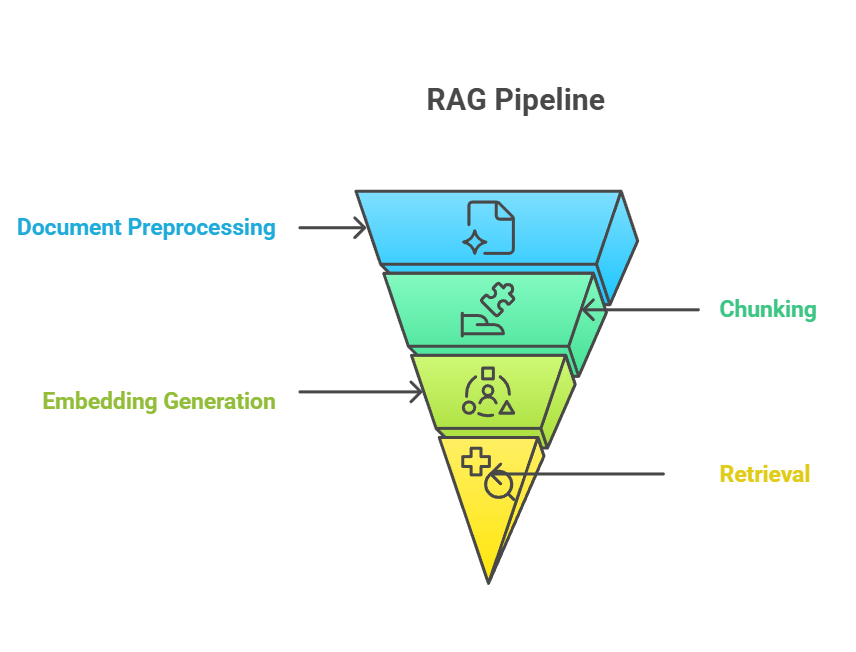
Pipeline RAG
Hubungan antara chunking, embedding, dan retrieval membentuk sistem yang sangat terpadu, di mana efektivitas setiap komponen bergantung pada kinerja komponen lainnya.
Ketika saya membuat chunk yang terstruktur dengan baik, model embedding dapat menghasilkan representasi vektor yang lebih kaya, yang pada gilirannya memungkinkan hasil pengambilan yang lebih akurat saat pengguna melakukan kueri. Sinergi ini berarti peningkatan dalam chunking sering kali diterjemahkan menjadi peningkatan kinerja yang terukur di seluruh pipeline.
Meski demikian, beberapa pendekatan baru menantang urutan tradisional ini. Misalnya, post-chunking terlebih dahulu membuat embedding seluruh dokumen dan hanya melakukan chunking saat waktu kueri, lalu melakukan caching hasil untuk akses yang lebih cepat di kemudian hari. Metode ini menghindari prapemrosesan dokumen yang mungkin tidak pernah dikueri sekaligus memungkinkan chunking spesifik kueri, namun memperkenalkan latensi pada akses pertama dan memerlukan infrastruktur tambahan.
Demikian pula, late chunking menunda segmentasi terperinci hingga tahap retrieval. Alih-alih menghitung embedding untuk banyak chunk kecil, sistem menyimpan representasi yang lebih kasar (misalnya seluruh dokumen atau bagian) dan membaginya secara dinamis saat kueri tiba. Ini mempertahankan konteks yang lebih luas sambil mengurangi pemrosesan awal, meski memperkenalkan latensi pada kueri pertama dan memerlukan infrastruktur tambahan.
Terlepas dari pendekatannya, strategi chunking harus menyesuaikan dengan jendela konteks model bahasa yang digunakan—jumlah maksimum teks yang dapat diproses dan dipertimbangkan model pada satu waktu.
Sekarang Anda sudah memahami apa itu chunking dan posisinya dalam pipeline, saatnya melihat prinsip inti yang memandu strategi chunking yang efektif. Memahami dasar-dasar ini menjadi landasan untuk menerapkan chunking di berbagai aplikasi AI dan RAG.
Chunking diperlukan karena model bahasa memiliki jendela konteks yang terbatas. Tujuan utamanya adalah membuat chunk yang secara mandiri bermakna namun secara kolektif tetap mempertahankan struktur dan maksud keseluruhan dokumen, semuanya dalam batas jendela konteks model.
Namun, jendela konteks bukan satu-satunya hal yang perlu dipertimbangkan. Saat saya merancang strategi chunking, saya fokus pada tiga prinsip inti:
Prinsip-prinsip ini bekerja bersama untuk membuat chunk bermanfaat bagi model dan efisien untuk pipeline retrieval. Dengan fondasi ini, saya dapat membahas strategi chunking paling umum yang digunakan dalam praktik.
Lanskap strategi chunking menawarkan berbagai pendekatan yang disesuaikan dengan jenis konten, aplikasi, dan kebutuhan kinerja yang berbeda. Pada gambar di bawah, Anda dapat melihat gambaran umum metode chunking utama, yang akan saya bahas lebih mendalam di bagian berikutnya.
Gambaran Umum Strategi Chunking
Gambaran komprehensif ini menunjukkan evolusi dari pendekatan berbasis aturan sederhana ke teknik canggih yang didorong AI, masing-masing menawarkan keunggulan berbeda untuk aplikasi dan kebutuhan kinerja spesifik.
Mari kita lihat lebih dekat strategi chunking yang paling banyak digunakan. Setiap metode memiliki kekuatan, keterbatasan, dan skenario penggunaan terbaik yang unik. Dengan memahami perbedaan ini, saya dapat memilih pendekatan yang tepat untuk proyek tertentu daripada menerapkan solusi serba cocok. Kita mulai dari pendekatan paling sederhana: chunking berukuran tetap.
Chunking berukuran tetap adalah metode paling sederhana. Ini membagi teks menjadi chunk berdasarkan karakter, kata, atau token—tanpa memperhatikan makna atau struktur.
Keunggulan utama chunking berukuran tetap adalah efisiensi komputasi—cepat, prediktabel, dan mudah diterapkan. Kekurangannya, sering mengabaikan struktur semantik, yang dapat menurunkan akurasi retrieval. Saya biasanya menggunakan metode ini ketika kesederhanaan dan kecepatan lebih penting daripada presisi semantik, serta ketika struktur dokumen tidak penting. Untuk meningkatkan kinerja, saya sering menambahkan overlap antarchunk guna mempertahankan konteks di batas-batasnya.
Salah satu cara untuk mengatasi sebagian kekurangan ini adalah menggunakan chunking berbasis kalimat, yang menghormati batasan bahasa alami, biasanya dengan mendeteksi tanda baca seperti titik atau tanda tanya.
Pendekatan ini menjaga keterbacaan dan memastikan setiap chunk tetap berdiri sendiri. Dibanding chunking berukuran tetap, metode ini menghasilkan segmen yang lebih mudah ditafsirkan oleh manusia dan model. Namun, panjang kalimat bervariasi, sehingga ukuran chunk bisa tidak merata, dan tidak selalu menangkap hubungan semantik yang lebih dalam.
Saya menemukan chunking berbasis kalimat paling berguna untuk aplikasi yang bergantung pada alur bahasa alami, seperti penerjemahan mesin, analisis sentimen, atau tugas peringkasan. Namun ketika dokumen memiliki struktur lebih dari sekadar kalimat, chunking rekursif memberikan alternatif yang fleksibel.
Chunking rekursif merupakan teknik yang lebih canggih dibanding metode sebelumnya. Ia menerapkan aturan pemisahan secara bertahap hingga setiap chunk sesuai dengan batas ukuran yang ditentukan. Misalnya, saya mungkin terlebih dulu membagi berdasarkan header bagian, lalu paragraf, dan akhirnya kalimat. Proses berlanjut hingga setiap bagian dapat dikelola dan berada dalam ukuran yang telah ditentukan.
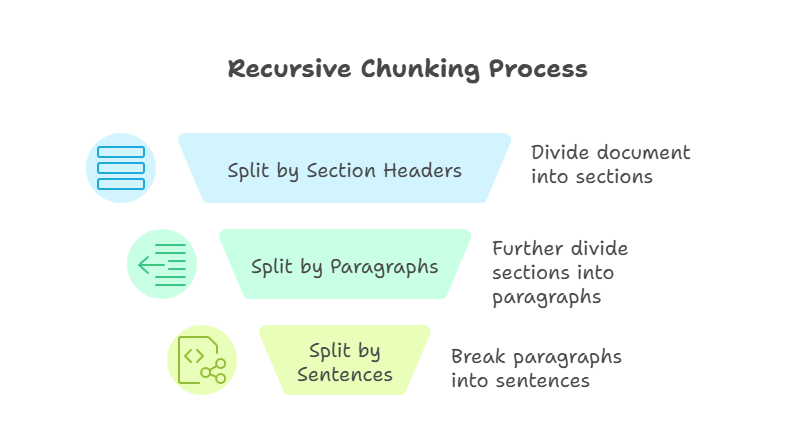
Chunking Rekursif
Keunggulan utama pendekatan ini adalah fleksibilitas. Dengan bekerja dari atas ke bawah, chunking rekursif mempertahankan struktur dokumen sekaligus memastikan kompatibilitas dengan jendela konteks model. Namun, chunking rekursif bisa lebih kompleks untuk diimplementasikan, dan kualitas hasilnya bergantung pada seberapa baik struktur dokumen sumber.
Saya sering menggunakan chunking rekursif saat bekerja dengan manual teknis atau dokumen lain yang memiliki hierarki jelas.
Sementara metode rekursif mengandalkan struktur, chunking semantik menggeser fokus ke makna, membagi teks berdasarkan batas konseptual. Chunking semantik adalah teknik yang peka makna yang menggunakan embedding atau kemiripan semantik untuk memecah teks ketika terjadi pergeseran topik. Alih-alih batas sembarang, chunk didefinisikan oleh makna.
Salah satu pendekatannya adalah memecah teks menjadi kalimat dan mengukur kemiripan semantik antar kalimat (misalnya, cosine similarity pada embedding), menandai chunk baru ketika koherensi menurun. Implementasi yang lebih maju menggunakan metode klasterisasi atau model deteksi batas tersupervisi, yang lebih baik dalam menangkap pergeseran topik pada dokumen kompleks.
Chunking Semantik
Metode ini mempertahankan koherensi semantik, memastikan setiap chunk mencakup satu gagasan atau tema. Tekniknya dapat mencakup kemiripan embedding, klasterisasi, atau perhitungan jarak semantik lain untuk mendeteksi titik pisah alami.
Keunggulan terbesar adalah presisi—chunking semantik menciptakan chunk yang sangat selaras dengan maksud pengguna saat retrieval. Kekurangan utamanya adalah biaya komputasi, karena memerlukan embedding teks saat prapemrosesan. Saya menggunakan chunking semantik ketika akurasi lebih penting daripada kecepatan, seperti pada sistem RAG spesifik domain untuk ranah hukum atau medis.
Berlawanan dengan chunking semantik yang menekankan koherensi semantik, chunking jendela geser menekankan kontinuitas dengan menumpang-tindihkan chunk, menggeser sebuah jendela melintasi teks. Misalnya, jika saya menggunakan ukuran chunk (jendela) 500 token dengan stride 250, setiap chunk tumpang-tindih setengah dengan chunk sebelumnya.
Tumpang tindih ini mempertahankan konteks di batas chunk, mengurangi risiko hilangnya informasi penting di tepi. Ini juga meningkatkan akurasi retrieval, karena beberapa chunk yang saling tumpang tindih dapat muncul sebagai respons terhadap sebuah kueri. Konsekuensinya adalah redundansi—tumpang tindih meningkatkan biaya penyimpanan dan pemrosesan. Jendela geser sangat berguna untuk teks tidak terstruktur seperti log obrolan atau transkrip podcast.
Chunking Jendela Geser
Saat menerapkan strategi ini, saya biasanya menggunakan overlap 20–50% antar chunk untuk mempertahankan konteks di batas, terutama pada teks teknis atau percakapan. Ukuran chunk 200–400 token merupakan default umum dalam framework seperti LangChain, meskipun ini dapat disetel berdasarkan batas konteks model dan jenis dokumen. Saya merekomendasikan pendekatan ini untuk aplikasi di mana pelestarian konteks sangat penting dan efisiensi penyimpanan kurang prioritas.
Ketika kontinuitas saja tidak cukup dan struktur dokumen harus dipertahankan, chunking hierarkis dan kontekstual berperan.
Chunking hierarkis mempertahankan struktur penuh dokumen, dari bagian hingga kalimat. Alih-alih menghasilkan daftar chunk datar, ia membangun pohon yang mencerminkan hierarki asli. Setiap chunk memiliki hubungan induk–anak dengan level di atas dan di bawahnya. Misalnya, sebuah bagian memuat beberapa paragraf (induk → anak), dan setiap paragraf mungkin berisi beberapa kalimat.
Selama retrieval, struktur ini memungkinkan navigasi yang fleksibel. Jika sebuah kueri cocok dengan chunk level kalimat, sistem dapat memperluas ke atas untuk memberikan konteks tambahan dari paragraf induknya atau bahkan seluruh bagian. Sebaliknya, jika kueri luas cocok dengan chunk level bagian, sistem dapat menelusuri ke bawah ke paragraf atau kalimat anak yang paling relevan. Retrieval multilevel ini meningkatkan presisi dan recall, karena model dapat menyesuaikan cakupan konten yang dikembalikan.
Chunking Hierarkis
Chunking kontekstual melangkah lebih jauh dengan memperkaya chunk menggunakan metadata seperti judul bagian, timestamp, atau referensi sumber. Informasi tambahan ini memberikan sinyal penting yang membantu sistem retrieval membedakan hasil. Misalnya, dua dokumen mungkin berisi kalimat yang hampir identik, tetapi judul bagian atau timestamp-nya dapat menentukan mana yang lebih relevan dengan kueri. Metadata juga memudahkan pelacakan jawaban ke sumbernya, yang sangat berharga di domain teregulasi atau berorientasi kepatuhan.
Chunking Kontekstual
Manfaat utama chunking hierarkis dan kontekstual adalah akurasi dan fleksibilitas. Konsekuensinya adalah kompleksitas tambahan baik pada prapemrosesan maupun logika retrieval, karena sistem harus mengelola hubungan antarchunk alih-alih memperlakukannya sebagai unit independen. Saya merekomendasikan pendekatan ini untuk domain seperti kontrak hukum, laporan keuangan, atau spesifikasi teknis, di mana pelestarian struktur dan keterlacakan sangat penting.
Tidak semua dokumen mengikuti hierarki ketat, sehingga chunking berbasis topik atau spesifik modalitas menawarkan cara yang lebih fleksibel untuk mengelompokkan konten terkait.
Chunking berbasis topik mengelompokkan teks berdasarkan unit tematik menggunakan algoritma seperti Latent Dirichlet Allocation (LDA) untuk pemodelan topik atau metode klasterisasi berbasis embedding untuk mengidentifikasi batas semantik.
Alih-alih ukuran tetap atau penanda struktural, tujuannya adalah menjaga semua konten terkait suatu tema dalam satu tempat. Pendekatan ini cocok untuk konten bentuk panjang seperti laporan riset atau artikel yang bergeser antar subjek berbeda. Karena setiap chunk tetap fokus pada satu tema, hasil retrieval lebih selaras dengan maksud pengguna dan kecil kemungkinan menyertakan materi yang tidak terkait.
Chunking spesifik modalitas menyesuaikan strategi dengan jenis konten yang berbeda, memastikan informasi disegmentasi dengan cara yang menghormati struktur setiap medium. Contohnya:
Chunking Berbasis Topik dan Spesifik Modalitas
Metadata memainkan peran yang sangat penting dalam chunking spesifik modalitas. Misalnya, melampirkan header kolom pada baris tabel, mengaitkan keterangan dengan wilayah gambar, atau menambahkan label pembicara dan timestamp pada transkrip membantu sistem retrieval menemukan chunk yang tepat dan menafsirkannya dengan benar. Pengayaan ini meningkatkan presisi dan kepercayaan pengguna, karena hasil disertai sinyal kontekstual yang menjelaskan relevansinya.
Saya merekomendasikan menerapkan chunking spesifik modalitas saat bekerja dengan pipeline multimodal atau dokumen non-tradisional yang tidak pas dengan strategi berbasis teks. Ini memastikan setiap jenis konten direpresentasikan dengan cara yang memaksimalkan kualitas dan kegunaan retrieval.
Di luar metode berbasis aturan dan makna ini, pendekatan mutakhir seperti chunking dinamis didukung AI dan chunking berbasis agen mendorong batas lebih jauh lagi.
Chunking dinamis didukung AI menggunakan model bahasa besar untuk menentukan batas chunk secara langsung, alih-alih mengandalkan aturan yang telah ditentukan. LLM memindai dokumen, mengidentifikasi titik pisah alami, dan menyesuaikan ukuran chunk secara adaptif.
Bagian yang padat dapat dipecah menjadi chunk lebih kecil, sementara bagian yang ringan dapat digabungkan. Ini menghasilkan chunk yang koheren secara semantik dan menangkap konsep secara utuh, sehingga meningkatkan akurasi retrieval. Metode ini cocok saat bekerja dengan dokumen kompleks bernilai tinggi—seperti kontrak hukum, manual kepatuhan, atau makalah riset—di mana presisi retrieval lebih penting daripada throughput atau biaya.
Di sisi lain, chunking berbasis agen membangun gagasan ini dengan memperkenalkan penalaran pada tingkat yang lebih tinggi. Alih-alih sekadar membiarkan LLM membagi teks, agen AI mengevaluasi dokumen dan maksud pengguna lalu memutuskan bagaimana melakukan chunking.
Agen dapat memilih strategi berbeda untuk bagian yang berbeda. Misalnya, memecah laporan medis berdasarkan riwayat pasien, hasil lab, dan catatan dokter, sembari menerapkan segmentasi semantik pada deskripsi naratif. Agen juga bisa memperkaya chunk tertentu dengan metadata seperti timestamp, kode diagnosis, atau identitas klinisi.
Dengan cara ini, chunking berbasis agen bertindak sebagai lapisan orkestrasi: agen memilih atau menggabungkan pendekatan chunking secara dinamis, bukan menerapkan satu metode di seluruh dokumen. Hasilnya adalah chunking yang lebih terarah dan sadar konteks, meski dengan konsekuensi berupa kompleksitas dan kebutuhan komputasi yang lebih besar.
Chunking Dinamis Didukung AI dan Berbasis Agen
Kedua metode ini canggih dan kuat, namun menangani masalah yang berbeda. Chunking dinamis didukung AI berfokus pada pembuatan batas yang selaras secara semantik saat ingestion, sementara chunking berbasis agen berfokus pada pemilihan dan penggabungan strategi chunking secara cerdas untuk setiap dokumen. Keduanya terkait dengan late chunking, yang disebutkan di awal artikel, yang mendukung model berkonteks panjang dengan terlebih dulu membuat embedding seluruh dokumen lalu menerapkan chunking pada level embedding.
Pendekatan-pendekatan ini menghasilkan chunk yang sangat adaptif dan sadar semantik. Konsekuensi yang perlu dipertimbangkan: chunking didukung AI mahal dan mungkin lebih lambat, sementara chunking berbasis agen menambah lapisan kompleksitas dan infrastruktur. Chunking dinamis didukung AI paling cocok untuk skenario di mana konten perlu disegmentasi secara bermakna secara langsung, sementara chunking berbasis agen unggul saat dokumen sangat bervariasi dan menuntut penalaran pada tingkat strategi.
Setelah saya memilih strategi chunking, langkah berikutnya adalah memikirkan detail implementasinya. Faktor praktis seperti ukuran chunk, pengelolaan overlap, dan penghitungan token secara langsung memengaruhi kinerja sistem. Terlalu besar, chunk mungkin melebihi batas konteks; terlalu kecil, maknanya hilang.
Kompatibilitas juga menjadi perhatian utama. Model dan solusi embedding yang berbeda memiliki skema tokenisasi dan jendela konteks yang unik, sehingga saya memastikan proses chunking saya memperhitungkan perbedaan ini.
Di sisi infrastruktur, manajemen memori dan efisiensi komputasi tidak boleh diabaikan; overlap meningkatkan redundansi, dan metode rekursif atau semantik dapat menambah beban pemrosesan. Langkah pascaproses seperti perluasan chunk atau pengayaan metadata dapat membantu memulihkan konteks, namun juga menambah kompleksitas.
Dengan fondasi ini, penting untuk mengukur sejauh mana strategi chunking benar-benar bekerja dalam praktik.
Efektivitas chunking bukan sekadar teori—ini harus diukur dengan metrik yang jelas.
Sebagai contoh, presisi konteks mengukur berapa banyak chunk yang diambil benar-benar relevan dengan kueri, sementara recall konteks mengukur berapa banyak chunk relevan dari basis pengetahuan yang berhasil diambil.
Keduanya menunjukkan apakah strategi chunking membantu retriever menemukan informasi yang tepat.
Terkait erat adalah relevansi konteks, yang berfokus pada seberapa baik chunk yang diambil selaras dengan maksud pengguna, sehingga sangat berguna saat menyetel parameter retrieval seperti nilai top-K.
Metrik spesifik chunk lainnya, seperti utilisasi chunk, mengukur seberapa banyak konten dalam sebuah chunk yang benar-benar digunakan model untuk menghasilkan jawabannya; jika utilisasi rendah, chunk mungkin terlalu luas atau berisik.
Di sisi lain, atribusi chunk mengevaluasi apakah sistem dengan benar mengidentifikasi chunk mana yang berkontribusi pada jawaban akhir. Evaluasi tingkat chunk ini membantu memastikan bahwa chunk tidak hanya diambil, tetapi juga diterapkan secara bermakna.
Optimasi juga berperan penting dan sering kali berarti menyeimbangkan kecepatan dengan akurasi. Bereksperimen dengan ukuran chunk, persentase overlap, dan parameter retrieval untuk meningkatkan efisiensi komputasi sekaligus kekayaan semantik adalah hal yang kritis. Selain itu, A/B testing diperlukan karena memberikan umpan balik konkret, sementara penyesuaian iteratif memastikan strategi terus membaik alih-alih stagnan.
Walau penyetelan kinerja dapat meningkatkan sistem tujuan umum, aplikasi spesifik domain menghadirkan tantangan uniknya sendiri.
Berbagai industri menuntut strategi chunking yang berbeda. Di bidang keuangan, dokumen seperti laporan tahunan atau pengajuan bersifat padat dan teknis, sehingga memilih strategi chunking yang mempertahankan tabel numerik, header, dan catatan kaki adalah suatu keharusan. Dokumen hukum dan teknis menghadirkan tantangan serupa—akurasi dan struktur tidak bisa ditawar, sehingga pendekatan hierarkis atau diperkaya konteks sangat berharga.
Dokumen medis dan multimodal memperkenalkan kebutuhan baru. Rekam medis mungkin menggabungkan catatan klinis, hasil lab, dan data pencitraan, sementara dokumen multimodal dapat mengintegrasikan teks dengan bagan atau transkrip audio. Di sini, chunking spesifik modalitas memastikan setiap tipe data disegmentasi dengan cara yang mempertahankan makna sekaligus menjaga keselarasan lintas modalitas.
Terlepas dari domainnya, mengikuti serangkaian praktik terbaik membuat strategi chunking lebih andal dan mudah dipelihara.
Memilih strategi chunking yang tepat bergantung pada beberapa faktor: jenis konten, kompleksitas kueri, sumber daya yang tersedia, dan ukuran jendela konteks model. Saya jarang mengandalkan satu metode untuk semua kasus—sebaliknya, saya menyesuaikan pendekatan agar sesuai dengan kebutuhan sistem.
Optimasi iteratif adalah kunci kesuksesan jangka panjang. Efektivitas chunking harus diuji secara berkelanjutan, memvalidasi hasil dengan kueri nyata dan menyesuaikan berdasarkan umpan balik. Validasi silang membantu memastikan bahwa perbaikan bukan sekadar keberhasilan sesaat, melainkan bertahan di berbagai use case.
Terakhir, saya merekomendasikan memperlakukan chunking sebagai sistem yang terus berkembang. Dokumentasi yang baik, pengujian rutin, dan pemeliharaan berkelanjutan membantu mencegah drift dan memastikan pipeline tetap andal seiring perubahan data dan model.
Chunking mungkin tampak seperti detail prapemrosesan, tetapi seperti yang Anda lihat di sepanjang panduan ini, ia secara fundamental membentuk kinerja sistem retrieval-augmented generation. Dari metode berukuran tetap dan berbasis kalimat hingga strategi semantik, berbasis agen, dan didukung AI yang canggih, setiap pendekatan menawarkan trade-off antara kesederhanaan, akurasi, efisiensi, dan adaptabilitas.
Tidak ada satu metode yang cocok untuk setiap skenario. Strategi chunking yang tepat bergantung pada jenis konten, kemampuan model bahasa, dan tujuan aplikasi. Dengan memperhatikan prinsip seperti koherensi semantik, pelestarian konteks, dan efisiensi komputasional, Anda dapat merancang chunk yang meningkatkan presisi retrieval, mengoptimalkan kinerja, dan memastikan keluaran yang lebih tepercaya.
Ke depan, strategi chunking kemungkinan akan menjadi semakin dinamis, adaptif, dan sadar model. Seiring berkembangnya model berkonteks panjang dan matangnya alat evaluasi, saya memperkirakan chunking akan beralih dari langkah prapemrosesan statis menjadi proses cerdas dan peka konteks yang terus belajar dari penggunaan.
Bagi siapa pun yang membangun dengan sistem RAG, menguasai chunking sangat penting untuk menciptakan pipeline retrieval yang akurat, efisien, dan siap menghadapi masa depan.
Untuk terus belajar, pastikan mengecek sumber berikut:
Kursus Teratas di DataCamp
Kursus
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
