
Curso
Retrieval Augmented Generation (RAG) com LangChain
3 h
17.8K
Quando comecei a explorar os sistemas de geração aumentada por recuperação (RAG), logo percebi que um dos fatores mais ignorados, mas essenciais, que influenciam o desempenho deles é o chunking.
Basicamente, chunking é o processo de dividir grandes quantidades de informação, como documentos, transcrições ou manuais técnicos, em partes menores e mais fáceis de lidar. Esses segmentos podem então ser processados, incorporados e recuperados por sistemas de IA.
Como eu trabalho com modelos de linguagem modernos e suas limitações de contexto, acho que entender e aplicar estratégias eficazes de chunking é essencial para quem está construindo pipelines RAG, sistemas de pesquisa semântica ou aplicativos de processamento de documentos.
Neste guia, vou te explicar o conceito de chunking, por que ele é importante nas aplicações de IA, descrever seu papel no pipeline RAG e discutir como diferentes estratégias podem afetar a precisão da recuperação. Também vou falar sobre considerações práticas de implementação, métodos de avaliação, casos de uso específicos do domínio e melhores práticas que podem te ajudar a escolher a abordagem certa para o seu projeto.
Se você é novo no RAG e em aplicativos de IA, recomendo fazer um dos nossos cursos, como o Retrieval Augmented Generation (RAG) com LangChain, Certificação em Fundamentos de IAou Estratégia de Inteligência Artificial (IA).
A importância do chunking vai muito além da simples organização de dados; ele molda de forma fundamental a maneira como os sistemas de IA entendem e recuperam informações.
Modelos de linguagem grandes e pipelines RAG precisam de chunking por causa das limitações que eles têm nas janelas de contexto e nas restrições computacionais.
Quando eu processo documentos grandes sem dividir em partes menores, o sistema muitas vezes perde relações contextuais importantes e tem dificuldade para identificar informações relevantes durante a recuperação. A divisão eficaz em partes melhora diretamente a precisão da recuperação, criando segmentos semanticamente coerentes que se alinham com os padrões de consulta e a intenção do usuário.
Pela minha experiência, estratégias de fragmentação bem implementadas melhoram bastante as capacidades de pesquisa semântica, mantendo o fluxo lógico das informações e garantindo que cada fragmento tenha contexto suficiente para incorporações significativas. Essa abordagem permite que os modelos incorporados capturem relações sutis e possibilita uma correspondência de similaridade mais precisa durante a recuperação.
Por outro lado, estratégias ruins de fragmentação criam impactos negativos em cascata em todo o pipeline de IA. Divisões arbitrárias podem cortar relações importantes entre conceitos, levando a respostas incompletas ou enganosas. Quando os trechos são muito grandes, os sistemas de recuperação têm dificuldade em identificar passagens específicas relevantes, enquanto trechos muito pequenos muitas vezes não têm contexto suficiente para uma compreensão precisa. Esses problemas acabam reduzindo a satisfação do usuário e comprometendo a confiabilidade do sistema.
O chunking é super importante no pipeline RAG, servindo como uma ponte entre a ingestão de documentos brutos e a recuperação de conhecimento significativo. No pipeline RAG de ponta a ponta, o chunking geralmente rola depois do pré-processamento do documento, mas antes da geração da incorporação. O processo de fragmentação alimenta diretamente a etapa de incorporação, na qual cada fragmento é convertido em representações vetoriais que capturam o significado semântico.altPipeline RAG doalt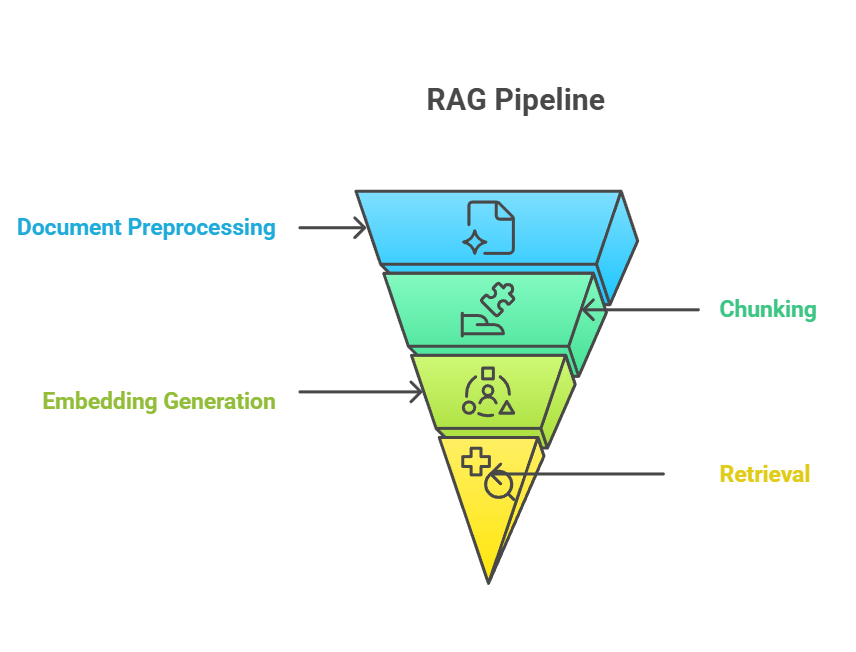
Pipeline RAG
A relação entre chunking, embedding e recuperação forma um sistema bem conectado, onde a eficácia de cada componente depende do desempenho dos outros.
Quando eu crio pedaços bem estruturados, os modelos de incorporação podem gerar representações vetoriais mais ricas, o que, por sua vez, permite resultados de recuperação mais precisos quando um usuário faz uma consulta. Essa sinergia significa que melhorias no chunking geralmente se traduzem em ganhos mensuráveis de desempenho em todo o pipeline.
Dito isso, algumas abordagens mais recentes desafiam essa ordem tradicional. Por exemplo, o pós-fragmentação primeiro incorpora documentos inteiros e só os fragmenta na hora da consulta, armazenando os resultados em cache para um acesso mais rápido depois. Esse método evita o pré-processamento de documentos que talvez nunca sejam consultados, ao mesmo tempo que permite o agrupamento específico por consulta, mas introduz latência no primeiro acesso e requer infraestrutura adicional.
Da mesma forma, o chunking tardio adiam a segmentação detalhada até a recuperação. Em vez de pré-calcular incorporações para muitos pequenos pedaços, o sistema armazena representações mais grosseiras (por exemplo, documentos ou seções inteiros) e as divide dinamicamente quando uma consulta chega. Isso mantém o contexto mais amplo e ainda reduz o processamento inicial, mas traz uma latência na primeira consulta e precisa de infraestrutura extra.
Não importa a abordagem, as estratégias de chunking precisam se adaptar à janela de contexto do modelo de linguagem que tá sendo usado — a quantidade máxima de texto que um modelo consegue processar e considerar de uma vez só.
Agora que você já tem uma ideia do que é chunking e onde ele se encaixa no pipeline, é hora de ver os princípios básicos que orientam estratégias eficazes de chunking. Entender esses fundamentos dá a base para usar o chunking em várias aplicações de IA e RAG.
O chunking é necessário porque os modelos de linguagem têm uma janela de contexto limitada. O principal objetivo é criar partes que façam sentido por si só, mas que, juntas, mantenham a estrutura e o sentido geral do documento, tudo isso dentro da janela de contexto do modelo.
Mas a janela de contexto não é a única coisa a se pensar. Quando eu penso em estratégias de chunking, eu me concentro em três princípios básicos:
Esses princípios funcionam juntos para tornar os blocos úteis para o modelo e eficientes para os pipelines de recuperação. Com essa base estabelecida, posso agora apresentar as estratégias de fragmentação mais comuns utilizadas na prática.
O panorama das estratégias de chunking oferece várias abordagens adaptadas a diferentes tipos de conteúdo, aplicações e requisitos de desempenho. Na imagem abaixo, você pode ver uma visão geral dos principais métodos de chunking, que abordarei com mais detalhes nas seções a seguir.
Visão geral das estratégias de chunking
Essa visão geral mostra como as coisas evoluíram, passando de abordagens simples baseadas em regras para técnicas sofisticadas com inteligência artificial, cada uma com suas vantagens para aplicações e requisitos de desempenho específicos.
Vamos dar uma olhada nas estratégias de chunking mais usadas. Cada método tem pontos fortes, limitações e cenários mais adequados. Ao entender essas diferenças, posso escolher a abordagem certa para um projeto específico, em vez de usar soluções genéricas. Vamos começar com a abordagem mais simples: fragmentação de tamanho fixo.
A divisão em blocos de tamanho fixo é o método mais simples. Ele divide o texto em pedaços com base em caracteres, palavras ou tokens, sem se importar com o significado ou a estrutura.
A principal vantagem do chunking de tamanho fixo é a eficiência computacional — é rápido, previsível e fácil de implementar. A desvantagem é que muitas vezes ignora a estrutura semântica, o que pode reduzir a precisão da recuperação. Normalmente uso esse método quando a simplicidade e a rapidez são mais importantes do que a precisão semântica e quando a estrutura do documento não é tão importante. Pra melhorar o desempenho, muitas vezes coloco sobreposição entre os blocos pra manter o contexto entre as fronteiras.
Uma maneira de resolver algumas dessas falhas é usar o chunking baseado em frases, que respeita os limites da linguagem natural, geralmente detectando pontuação como pontos finais ou pontos de interrogação.
Essa abordagem mantém a legibilidade e garante que cada parte continue independente. Comparado com o chunking de tamanho fixo, ele cria segmentos que são mais fáceis de entender para pessoas e modelos. Mas, como o tamanho das frases varia, os pedaços podem ficar desiguais e nem sempre mostram as relações semânticas mais profundas.
Acho que o chunking baseado em frases é mais útil para aplicações que dependem do fluxo natural da linguagem, como tradução automática, análise de sentimentos ou tarefas de resumo. Mas quando os documentos têm mais estrutura do que frases simples, o chunking recursivo oferece uma alternativa flexível.
O chunking recursivo é uma técnica mais avançada do que os métodos anteriores. Ele aplica regras de divisão passo a passo até que cada parte fique dentro de um limite de tamanho definido. Por exemplo, eu posso primeiro dividir por títulos de seção, depois por parágrafos e, por fim, por frases. O processo continua até que cada peça fique fácil de manusear e dentro do tamanho definido.
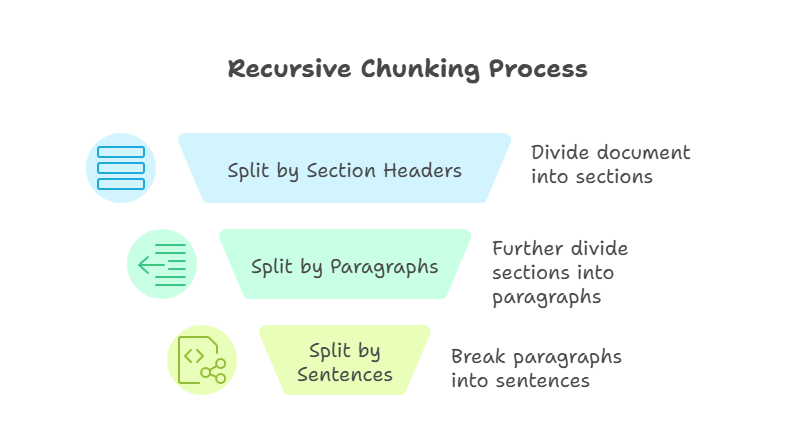
Fragmentação recursiva
A principal vantagem dessa abordagem é a flexibilidade. Ao trabalhar de cima para baixo, o chunking recursivo mantém a estrutura do documento e ainda garante a compatibilidade com as janelas de contexto do modelo. Mas, o chunking recursivo pode ser mais complicado de implementar, e a qualidade dos resultados depende de como o documento original está estruturado.
Costumo recorrer ao chunking recursivo quando trabalho com manuais técnicos ou outros documentos que têm hierarquias claras.
Enquanto os métodos recursivos dependem da estrutura, o chunking semântico muda o foco para o significado, dividindo o texto com base em limites conceituais. O chunking semântico é uma técnica que entende o significado e usa embeddings ou similaridade semântica para dividir o texto onde há mudanças de assunto. Em vez de limites aleatórios, os blocos são definidos pelo significado.
Uma abordagem é dividir o texto em frases e medir a semelhança semântica entre elas (por exemplo, semelhança coseno em embeddings), marcando novos trechos quando a coerência diminuir. Implementações mais avançadas usam métodos de agrupamento ou modelos supervisionados de detecção de limites, que capturam melhor as mudanças de tópico em documentos complexos.
Fragmentação semântica
Esse método mantém a coerência semântica, garantindo que cada trecho aborde uma única ideia ou tema. As técnicas podem incluir similaridade de incorporação, agrupamento ou outros cálculos de distância semântica para detectar pontos de interrupção naturais.
A maior vantagem é a precisão — o chunking semântico cria chunks que se alinham perfeitamente com a intenção do usuário durante a recuperação. A principal desvantagem é o custo computacional, já que precisa incorporar o texto durante o pré-processamento. Eu uso o chunking semântico quando a precisão é mais importante do que a velocidade, como em sistemas RAG específicos para áreas jurídicas ou médicas.
Ao contrário do chunking semântico, que dá ênfase à coerência semântica, o chunking de janela deslizante foca na continuidade, sobrepondo chunks e movendo uma janela pelo texto. Por exemplo, se eu usar um tamanho de bloco (janela) de 500 tokens com um intervalo de 250, cada bloco vai se sobrepor pela metade ao anterior.
Essa sobreposição mantém o contexto entre os limites dos blocos, diminuindo o risco de perder informações importantes nas bordas. Isso também melhora a precisão da recuperação, já que vários trechos sobrepostos podem aparecer em resposta a uma consulta. A desvantagem é a redundância — a sobreposição aumenta os custos de armazenamento e processamento. As janelas deslizantes são super úteis pra textos sem estrutura, tipo registros de bate-papo ou transcrições de podcasts.
Fragmentação por janela deslizante
Quando eu uso essa estratégia, geralmente deixo uma sobreposição de 20 a 50% entre os trechos para manter o contexto entre as fronteiras, principalmente em textos técnicos ou conversacionais. Tamanhos de blocos de 200 a 400 tokens são padrões comuns em estruturas como LangChain, embora isso possa ser ajustado com base nos limites do contexto do modelo e no tipo de documento. Eu recomendo essa abordagem para aplicativos em que a preservação do contexto é essencial e a eficiência do armazenamento é menos importante.
Quando a continuidade não é suficiente e a estrutura do documento precisa ser mantida, entram em cena o chunking hierárquico e contextual.
A fragmentação hierárquica mantém toda a estrutura de um documento, desde as seções até as frases. Em vez de criar uma lista simples de blocos, ele constrói uma árvore que reflete a hierarquia original. Cada bloco tem umarelação pai-filho com os níveis acima e abaixo dele. Por exemplo, uma seção tem vários parágrafos (pai → filhos), e cada parágrafo pode ter várias frases.
Durante a recuperação, essa estrutura permite uma navegação flexível. Se uma consulta corresponder a um trecho do nível da frase, o sistema pode expandir para cima para fornecer contexto adicional do parágrafo pai ou até mesmo de toda a seção. Por outro lado, se uma consulta ampla corresponder a um trecho no nível da seção, o sistema pode detalhar o parágrafo ou frase filho mais relevante. Essa recuperação em vários níveis melhora tanto a precisão quanto a recuperação, já que o modelo pode ajustar o escopo do conteúdo retornado.
Fragmentação hierárquica
A fragmentação contextual vai um pouco além, enriquecendo os fragmentos com metadados, como títulos, carimbos de data/hora ou referências de origem. Essas informações adicionais fornecem sinais importantes que ajudam os sistemas de recuperação a eliminar ambiguidades nos resultados. Por exemplo, dois documentos podem ter frases quase iguais, mas os títulos das seções ou os carimbos de data/hora podem ajudar a decidir qual deles é mais relevante para uma consulta. Os metadados também facilitam rastrear as respostas até sua fonte, o que é super importante em áreas regulamentadas ou que exigem conformidade.
Divisão contextual
A principal vantagem da fragmentação hierárquica e contextual é a precisão e a flexibilidade. A desvantagem é que fica mais complicado tanto no pré-processamento quanto na lógica de recuperação, já que o sistema precisa lidar com as relações entre os blocos em vez de tratá-los como unidades independentes. Eu recomendo essas abordagens para áreas como contratos legais, relatórios financeiros ou especificações técnicas, onde é essencial manter a estrutura e a rastreabilidade.
Nem todos os documentos seguem uma hierarquia rígida, então dividir em partes por assunto ou modalidade é uma maneira mais flexível de juntar conteúdos relacionados.
Divisão por tópicos agrupa o texto por unidades temáticas usando algoritmos como a Alocação Latente de Dirichlet (LDA) para modelagem de tópicos ou métodos de agrupamento baseados em incorporação para identificar limites semânticos.
Em vez de tamanhos fixos ou marcadores estruturais, o objetivo é manter todo o conteúdo relacionado a um tema em um único lugar. Essa abordagem funciona bem para conteúdos longos, como relatórios de pesquisa ou artigos que alternam entre assuntos distintos. Como cada parte se concentra em um único tema, os resultados da pesquisa ficam mais alinhados com o que o usuário quer e é menos provável que apareçam coisas que não têm nada a ver.
O chunking específico para cada modalidade adapta as estratégias a diferentes tipos de conteúdo, garantindo que as informações sejam segmentadas de forma a respeitar a estrutura de cada meio. Por exemplo:
Divisão em blocos com base no tema e na modalidade específica
Os metadados têm um papel super importante na divisão em blocos específicos por modalidade. Por exemplo, colocar cabeçalhos de coluna nas linhas da tabela, ligar legendas a partes da imagem ou adicionar rótulos de locutor e marcas de tempo às transcrições ajuda os sistemas de recuperação a encontrar o trecho certo e interpretá-lo corretamente. Esse enriquecimento melhora tanto a precisão quanto a confiança do usuário, já que os resultados vêm acompanhados de sinais contextuais que explicam sua relevância.
Recomendo usar o chunking específico para cada modalidade quando estiver trabalhando com pipelines multimodais ou documentos não tradicionais que não se encaixam perfeitamente nas estratégias baseadas em texto. Isso garante que cada tipo de conteúdo seja representado de forma a maximizar a qualidade da recuperação e a usabilidade.
Além desses métodos baseados em regras e significados, abordagens inovadoras, como o chunking dinâmico baseado em IA e o chunking agênico, vão ainda mais longe.
O chunking dinâmico baseado em IA usa um grande modelo de linguagem para determinar diretamente os limites dos chunks, em vez de depender de regras pré-definidas. O LLM faz a varredura do documento, identifica pontos de interrupção naturais e ajusta o tamanho dos blocos de forma adaptativa.
As seções densas podem ser divididas em partes menores, enquanto as seções mais leves podem ser agrupadas. Isso resulta em trechos semanticamente coerentes que capturam conceitos completos, melhorando a precisão da recuperação. Esse método é ideal pra trabalhar com documentos complexos e de alto valor, tipo contratos legais, manuais de conformidade ou trabalhos de pesquisa, onde a precisão na recuperação é mais importante do que a produtividade ou o custo.
Por outro lado, o chunking agênico se baseia nessa ideia, introduzindo um raciocínio em um nível mais elevado. Em vez de só deixar o LLM dividir o texto, um agente de IA dá uma olhada no documento e na intenção do usuário e decide como dividir.
O agente pode escolher estratégias diferentes para seções diferentes. Por exemplo, dividir um relatório médico por histórico do paciente, resultados laboratoriais e anotações do médico, enquanto aplica segmentação semântica às descrições narrativas. Também pode adicionar metadados a certos trechos, como carimbos de data/hora, códigos de diagnóstico ou identificadores de médicos.
Assim, o chunking agênico funciona como uma camada de orquestração: o agente escolhe ou combina abordagens de chunking de forma dinâmica, em vez de usar um único método em todo o documento. O resultado é uma divisão em blocos mais personalizada e sensível ao contexto, embora isso implique maior complexidade e requisitos computacionais.
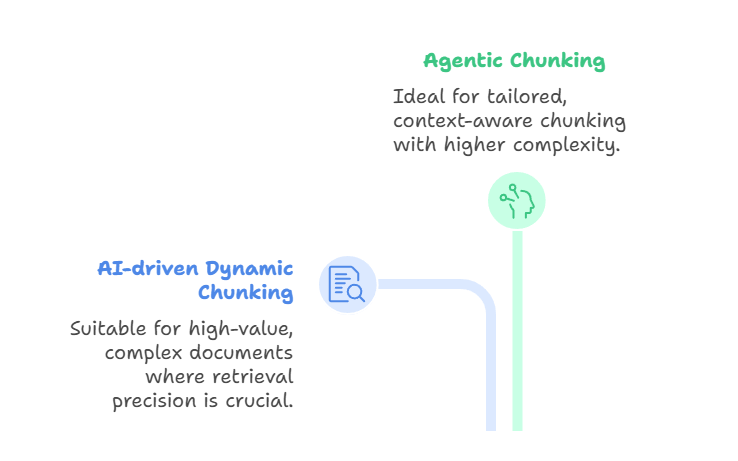
Fragmentação dinâmica orientada por agentes e IA
Os dois métodos são modernos e poderosos, mas resolvem problemas diferentes. O chunking dinâmico baseado em IA foca em criar limites alinhados semanticamente durante a ingestão, enquanto o chunking agênico foca em escolher e combinar de forma inteligente estratégias de chunking para cada documento único. Elas estão relacionadas aochunking tardio de , mencionado no início do artigo, que suporta modelos de contexto longo incorporando primeiro um documento inteiro e, em seguida, aplicando o chunking no nível da incorporação.
Essas abordagens geram blocos altamente adaptáveis e semanticamente conscientes. As desvantagens são significativas: O chunking baseado em IA é caro e pode ser mais lento, enquanto o chunking agênico adiciona outra camada de complexidade e infraestrutura. O chunking dinâmico baseado em IA é mais adequado para cenários em que o conteúdo precisa ser segmentado de forma significativa em tempo real, enquanto o chunking agênico se destaca quando os documentos variam muito e exigem raciocínio estratégico.
Depois de escolher uma estratégia de fragmentação, o próximo passo é pensar nos detalhes de implementação. Fatores práticos, como tamanho dos blocos, gerenciamento de sobreposição e contagem de tokens, influenciam diretamente o desempenho do sistema. Se forem muito grandes, os trechos podem ultrapassar os limites do contexto; se forem muito pequenos, eles perdem o sentido.
A compatibilidade é outra preocupação importante. Modelos e soluções de incorporação diferentes têm esquemas de tokenização e janelas de contexto únicos, então eu me certifico de que meu processo de fragmentação leve em conta essas diferenças.
No lado da infraestrutura, o gerenciamento de memória e a eficiência computacional não podem ser ignorados; a sobreposição aumenta a redundância, e métodos recursivos ou semânticos podem adicionar sobrecarga de processamento. Etapas de pós-processamento, como expansão de blocos ou enriquecimento de metadados, podem ajudar a recuperar o contexto, mas também trazem complexidade.
Com essas bases estabelecidas, é importante avaliar o quão eficazes as estratégias de fragmentação realmente são na prática.
A eficácia do chunking não é só teoria — é algo que precisa ser medido com métricas claras.
Por exemplo, Precisão do contexto mede quantos dos trechos recuperados são realmente relevantes para a consulta, enquanto a recuperação de contexto measures quantos trechos relevantes da base de conhecimento foram recuperados com sucesso.
Juntos, eles mostram se uma estratégia de fragmentação ajuda quem está procurando a informação certa.
Intimamente relacionado está relevância do contexto, que se concentra em como os trechos recuperados se alinham com a intenção do usuário, tornando-a especialmente útil ao ajustar configurações de recuperação, como valores top-K.
Outras métricas específicas do chunk, como utilização do chunk, medem quanto do conteúdo de um chunk o modelo realmente usou para gerar sua resposta; se a utilização for baixa, o chunk pode ser muito amplo ou ruidoso.
Por outro lado, a atribuição de trechos avalia se o sistema identifica corretamente quais trechos contribuíram para a resposta final. Essas avaliações em nível de blocos ajudam a confirmar se os blocos não só são recuperados, mas também aplicados de forma significativa.
A otimização também é super importante e, muitas vezes, significa equilibrar velocidade com precisão. É super importante testar tamanhos de blocos, porcentagens de sobreposição e parâmetros de recuperação para melhorar tanto a eficiência computacional quanto a riqueza semântica. Além disso, o teste A/B é necessário, pois fornece feedback concreto, enquanto ajustes iterativos garantem que a estratégia melhore ao longo do tempo, em vez de estagnar.
Embora o ajuste de desempenho possa melhorar os sistemas de uso geral, os aplicativos específicos de domínio apresentam seus próprios desafios.
Setores diferentes têm exigências diferentes em relação às estratégias de chunking. No mundo das finanças, documentos como relatórios anuais ou arquivamentos são densos e técnicos, então é essencial escolher uma estratégia de fragmentação que preserve tabelas numéricas, cabeçalhos e notas de rodapé. Documentos jurídicos e técnicos têm desafios parecidos — precisão e estrutura são essenciais, o que torna as abordagens hierárquicas ou ricas em contexto especialmente valiosas.
Documentos médicos e multimodais trazem novas necessidades. Um prontuário médico pode juntar notas clínicas, resultados de exames laboratoriais e dados de imagens, enquanto documentos multimodais podem integrar texto com gráficos ou transcrições de áudio. Aqui, o agrupamento específico por modalidade garante que cada tipo de dado seja segmentado de forma a preservar o significado, mantendo o alinhamento entre as modalidades.
Não importa o domínio, seguir um conjunto de práticas recomendadas torna as estratégias de fragmentação mais confiáveis e fáceis de manter.
Escolher a estratégia certa de chunking depende de vários fatores: tipo de conteúdo, complexidade da consulta, recursos disponíveis e tamanho da janela de contexto do modelo. Eu raramente uso só um jeito pra todos os casos — em vez disso, eu adapto a abordagem pra atender às necessidades do sistema.
A otimização iterativa é essencial para o sucesso a longo prazo. A eficácia do chunking precisa ser testada o tempo todo, validando os resultados com consultas reais e ajustando com base no feedback. A validação cruzada ajuda a garantir que as melhorias não sejam só sucessos pontuais, mas que funcionem em diferentes casos de uso.
Por fim, recomendo tratar o chunking como um sistema em evolução. Uma boa documentação, testes regulares e manutenção contínua ajudam a evitar desvios e garantem que os pipelines continuem robustos à medida que os dados e os modelos mudam.
O chunking pode parecer um detalhe do pré-processamento, mas, como você viu ao longo deste guia, ele molda fundamentalmente o desempenho dos sistemas de geração aumentada por recuperação. De métodos de tamanho fixo e baseados em frases a estratégias avançadas semânticas, agênicas e orientadas por IA, cada abordagem oferece compromissos entre simplicidade, precisão, eficiência e adaptabilidade.
Não existe um método único que funcione para todos os casos. A estratégia certa de chunking depende do tipo de conteúdo, das capacidades do modelo de linguagem e dos objetivos da aplicação. Prestando atenção a princípios como coerência semântica, preservação contextual e eficiência computacional, você pode criar blocos que melhoram a precisão da recuperação, otimizam o desempenho e garantem resultados mais confiáveis.
Olhando para o futuro, as estratégias de chunking provavelmente se tornarão ainda mais dinâmicas, adaptáveis e conscientes dos modelos. À medida que os modelos de contexto longo evoluem e as ferramentas de avaliação amadurecem, espero que o chunking passe de uma etapa de pré-processamento estática para um processo inteligente e sensível ao contexto, que aprende continuamente com o uso.
Pra quem tá construindo com sistemas RAG, dominar o chunking é essencial pra criar pipelines de recuperação que sejam precisos, eficientes e prontos pro futuro.
Para continuar aprendendo, não deixe de conferir os seguintes recursos:
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Natassha Selvaraj
10 min
blog
Nahla Davies
15 min
blog
blog
Maria Eugenia Inzaugarat
12 min
blog
Austin Chia
blog
Javier Canales Luna
9 min


