Kurs
Orta Seviye Python
4 sa
1.4M

Önce mülakatta karşınıza çıkabilecek genel yetkinlik sorularına bakalım. Bunlar, bir veri bilimci olarak ihtiyaç duyacağınız bazı yumuşak becerileri test eder:
Bu soru, iletişim becerilerinizi ve karmaşık konuları sadeleştirme yeteneğinizi ölçer. İşte örnek bir yanıt:
Önceki görevimde, pazarlama ekibimize makine öğrenmesi kavramını açıklamam gerekti. Farklı meyve türlerini tanımayı öğrenen bir çocuğa öğretme benzetmesini kullandım. Bir çocuğa öğrenmesi için birçok örnek gösterdiğimiz gibi, bir makine öğrenmesi modeli de verilerle eğitilir. Bu benzetme, karmaşık bir kavramı daha ilişkilenebilir ve anlaşılır hale getirdi.
Bu soru, ekip çalışması ve çatışma çözme becerilerinizi araştırır. Şöyle bir yanıt verebilirsiniz:
Bir projede, çalışma tarzı benden çok farklı olan bir meslektaşımla çalıştım. Farklılıklarımızı çözmek için onun bakış açısını anlamak üzere bir toplantı ayarladım. Proje hedeflerinde ortak bir zemin bulduk ve ortak bir yaklaşım üzerinde anlaştık. Bu deneyim, ekip çalışmasında açık iletişimin ve empati kurmanın değerini öğretti.
Bu soru zaman yönetimi ve önceliklendirme ile ilgilidir. Örnek bir yanıt:
Bir keresinde çok sıkı bir teslim tarihi olan bir analiz sunmam gerekiyordu. Projenin en kritik kısımlarına öncelik verdim, planımı ekiple paylaştım ve verimli yürütmeye odaklandım. Görevi parçalara ayırarak ve mini teslim tarihleri belirleyerek projeyi kaliteyi düşürmeden zamanında tamamladım.
Burada mülakatçı, hataları üstlenme ve onlardan ders çıkarma becerinizi görmek ister. Şöyle yanıtlayabilirsiniz:
Bir seferinde, bir veri modelinin sonuçlarını yanlış yorumladım. Hata yaptığımı fark eder etmez ekibimi bilgilendirdim ve verileri yeniden analiz ettim. Bu deneyim, sonuçları iki kez kontrol etmenin ve işyerinde şeffaflığın önemini öğretti.
Bu, sürekli öğrenmeye ve alanda güncel kalmaya olan bağlılığınızı gösterir. Örnek yanıt:
Sektör dergilerini okuyarak, web seminerlerine katılarak ve çevrimiçi forumlara iştirak ederek güncel kalıyorum. Ayrıca her hafta yeni araç ve teknikleri denemek için zaman ayırıyorum. Bu, sadece güncel kalmama değil, aynı zamanda becerilerimi sürekli geliştirmeme de yardımcı oluyor.
Bu soru, uyum sağlama ve problem çözme becerilerinizi ölçer. Örnek olarak şöyle diyebilirsiniz:
Önceki bir projede gereksinimler sık sık değişiyordu. Paydaşlarla açık iletişimi sürdürerek ihtiyaçlarını anlamaya çalıştım. Ayrıca yaklaşımımda daha esnek olmak için çevik metodolojiler kullandım; bu da değişiklikleri etkili şekilde karşılamama yardımcı oldu.
Bu, verinin ötesindeki farklı boyutları da gözetebilme becerinizi değerlendirir. Örnek bir yanıt:
Son görevimde, veriye dayalı karar alma ihtiyacını etik kaygılarla dengelemem gerekti. Tüm veri kullanımının etik standartlara ve gizlilik yasalarına uyduğundan emin oldum ve gerektiğinde alternatifler sundum. Bu yaklaşım, etik sınırları gözetirken bilinçli kararlar almaya yardımcı oldu.
Doğrusal regresyondaki dört varsayım şunlardır:
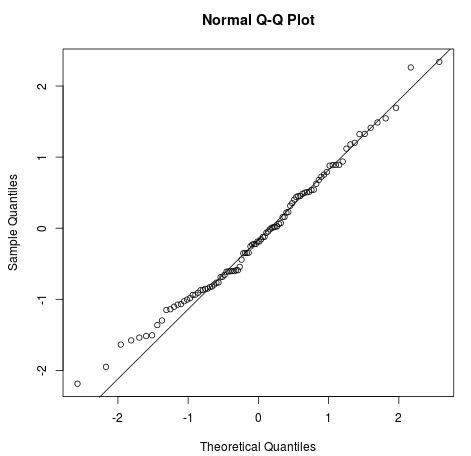
Görsel: Statology
Doğrusal modellerin kavramlarını ve uygulamalarını Python ile Doğrusal Modellemede Giriş kursumuzu alarak keşfedebilirsiniz.
Eksik veriyi ele almanın çeşitli yolları vardır. Şunları yapabilirsiniz:
Eksik veriyi teşhis etmeyi, görselleştirmeyi ve çözmeyi R ile Atama Yöntemleriyle Eksik Veri Yönetimi kursunu tamamlayarak öğrenin.
Öncelikle paydaşın geçmişini öğrenmeli ve buna göre dilinizi uyarlamalısınız. Örneğin finans geçmişi varsa, finansta yaygın kullanılan terimleri öğrenip karmaşık metodolojiyi bu terimlerle açıklayın.
İkinci olarak, bolca görsel ve grafik kullanın. İnsanlar görsel öğrenir; yaratıcı iletişim araçlarıyla çok daha iyi kavrarlar.
Görsel: Yazar
Üçüncü olarak, sonuçlar üzerinden konuşun. Metodolojileri veya istatistikleri anlatmaya çalışmayın. Analizden elde edilen bilgiyi işin ya da iş akışının nasıl iyileştirileceğine odaklanarak aktarın.
Son olarak, soru sormaları için cesaretlendirin. İnsanlar bilmedikleri konularda soru sormaktan çekinebilir. Onları diyaloğa dahil ederek iki yönlü bir iletişim kanalı oluşturun.
Kendi SQL raporlarınızı ve panolarınızı oluşturmayı SQL’de Raporlama kursunu alarak öğrenin.
p-değeri, yokluk hipotezinin doğru olduğu varsayımı altında, toplanan veriler kadar veya ondan daha uç sonuçları gözlemleme olasılığını ölçer.
p-değeri anlamlılık düzeyinizin (genellikle 0,05) altındaysa yokluk hipotezini reddetmenize yönelik kanıt sunar. Örneğin p-değeri 0,03 olan bir A/B testinde, yokluk hipotezi doğruyken bu sonucun görülme olasılığı yalnızca %3’tür; bu da varyantın gerçek bir etki yarattığını düşündürür.
Yaygın bir yanlış anlama: p-değeri, yokluk hipotezinin doğru olma olasılığını ölçmez; yalnızca verilerin bu hipotezle ne kadar uyumlu olduğunu gösterir.
Bunlar, hipotez testinde iki tür hatadır:
α’yı düşürmek Tip I hataları azaltır ancak Tip II hataları artırır. Doğru denge, kullanım durumunuzda her hatanın maliyetine bağlıdır—özellikle dolandırıcılık tespiti, tıbbi teşhis veya A/B test kararlarında kritiktir.
Daha fazlası için Hipotez Testi Kolaylaştırıldı eğitimimize göz atın.
Özellik seçimi için üç ana yöntem vardır: filtre, sarmalayıcı ve gömülü yöntemler.
Filtre Yöntemleri
Filtre yöntemleri genellikle ön işleme adımlarında kullanılır. Bu yöntemler, herhangi bir makine öğrenmesi algoritmasından bağımsız olarak veri setinden özellik seçer. Hızlıdırlar, daha az kaynak gerektirirler ve yinelenen, ilişkili ve gereksiz özellikleri kaldırırlar.

Görsel: Yazar
Kullanılan bazı teknikler:
Sarmalayıcı Yöntemler
Sarmalayıcı yöntemlerde, model özelliklerin bir alt kümesiyle yinelemeli olarak eğitilir. Eğitilen modelin sonuçlarına göre daha fazla özellik eklenir veya çıkarılır. Filtre yöntemlerinden daha hesaplamalı maliyetlidirler ancak daha iyi model doğruluğu sağlarlar.
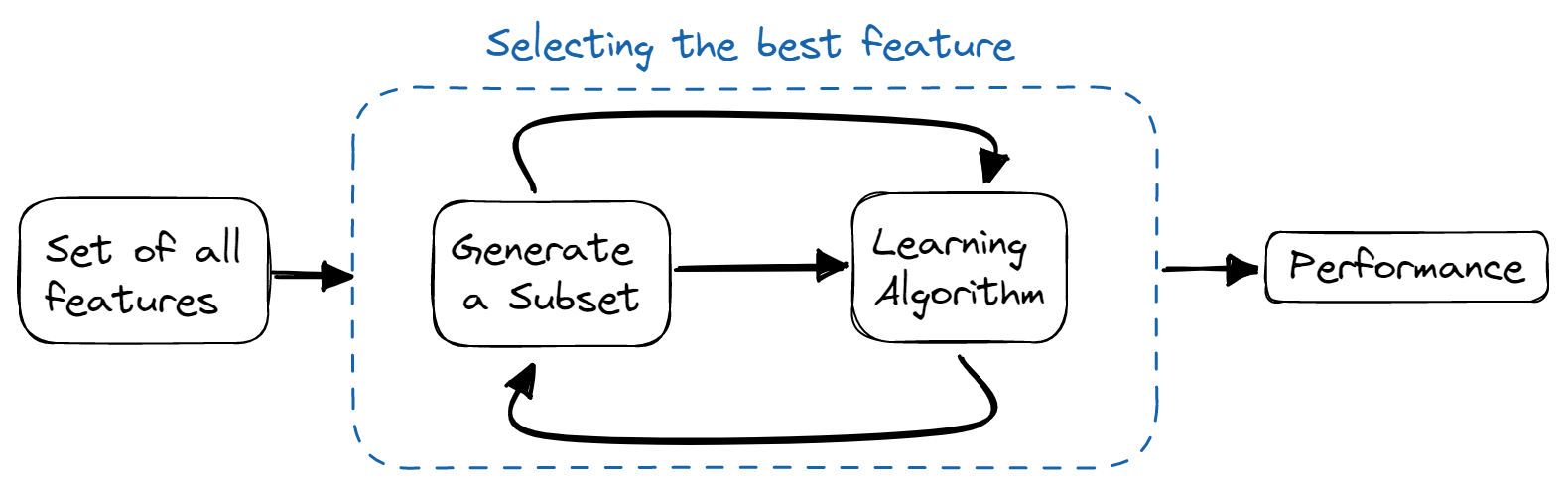
Görsel: Yazar
Kullanılan bazı teknikler:
Gömülü Yöntemler
Gömülü yöntemler, filtre ve sarmalayıcı yöntemlerin niteliklerini birleştirir. Özellik seçimi algoritması, öğrenme algoritmasının bir parçası olarak harmanlanır ve modele yerleşik bir özellik seçimi yöntemi sağlar. Bu yöntemler, filtre yöntemleri gibi hızlı, sarmalayıcı yöntemler gibi doğru ve ayrıca özellik kombinasyonlarını da dikkate alır.
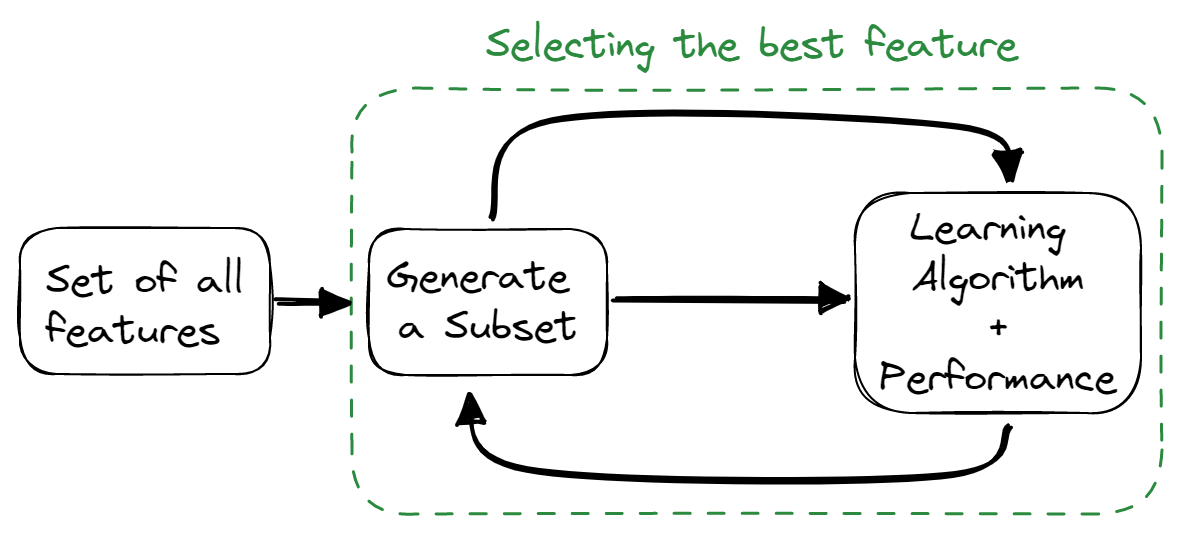
Görsel: Yazar
Kullanılan bazı teknikler:
En sık test edilen özellik seçimi tekniklerini Python Özellik Seçimi Eğitimi içeriğimizde öğrenin.
Aşırı öğrenme, bir modelin eğitim veri setinde aşırı iyi öğrenmesi ancak test ve doğrulama veri setlerinde başarısız olması durumudur.
Aşırı öğrenmeyi şu yollarla önleyebilirsiniz:
Aşırı öğrenmeyi önlemeye dair daha kapsamlı bir rehber için Aşırı Öğrenme Nedir? ve Makine Öğrenmesinde Düzenlileştirme yazılarımıza göz atın.
SQL ilişkilerinin dört ana türü vardır:
Tabloları, aralarındaki ilişkileri ve depolanan verileri keşfetmeyi SQL’de Keşifsel Veri Analizi kursumuzu tamamlayarak öğrenin.
Boyut indirgeme, veri setini birçok boyuttan daha az sayıda boyuta dönüştürürken benzer bilgiyi koruma sürecidir.
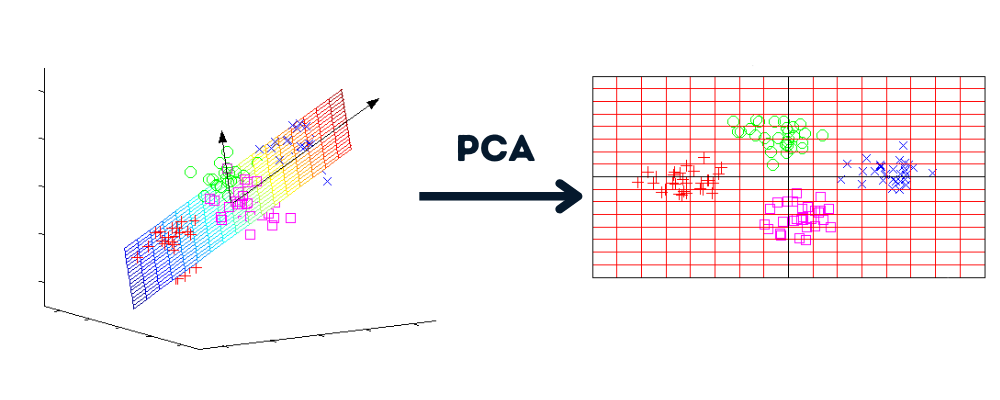
Görsel: Yazar | Grafikler: howecoresearch
Boyut indirgeme faydaları:
Boyut indirgeme kavramını anlayıp tekniklerde ustalaşmak için Python ile Boyut İndirgeme kursunda pratik yapın.

Görsel: Yazar
A/B testleri, tahmine dayalı yaklaşımları ortadan kaldırır ve ürün veya web sitesini optimize etmek için veriye dayalı kararlar almamıza yardımcı olur. Aynı zamanda bölünmüş test olarak da bilinir; burada rastgeleleştirilmiş deneyler yürütülerek iki veya daha fazla değişkenin (web sayfası, uygulama özelliği vb.) sürümü analiz edilir ve hangi sürümün en fazla trafiği ve iş metriğini sağladığı belirlenir.
A/B testlerini oluşturmayı, yürütmeyi ve analiz etmeyi Python ile Müşteri Analitiği ve A/B Testleri kursunu alarak öğrenin.
Gövdeleme, metin ve duygu analizinde yaygın olarak kullanılır. Bu soruda, listedeki belirli kelimeleri kök biçimine dönüştürecek bir Python fonksiyonu yazacaksınız - Interview Query.
Girdi:
Fonksiyon iki argüman alacaktır: kök kelimeler listesi ve cümle.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"Çıktı:
Kök kelimelerle dönüştürülmüş cümleyi döndürecektir.
"the cat was rat by the bat"Kod yazmaya başlamadan önce iki işlem yapacağımızı anlamanız gerekir: kelimenin bir kökü olup olmadığını kontrol etmek ve onu değiştirmek.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"
def replace_words(roots, sentence):
words = sentence.split(" ")
# looping over each word
for index, word in enumerate(words):
# looping over each root
for root in roots:
# checking if words start with root
if word.startswith(root):
# replacing the word with its root
words[index] = root
return " ".join(words)
replace_words(roots, sentence)
# 'the cat was rat by the bat'text dizgesi verildiğinde, palindrom ise True, değilse False döndürün.
Tüm harfleri küçülttükten ve alfasayısal olmayan karakterleri kaldırdıktan sonra, kelime önden ve arkadan aynı şekilde okunmalıdır.

Görsel: Yazar
Python bu meydan okumayı çözmek için kolay yollar sunar. Dizgeyi yinelenebilir kabul edip text[::-1] ile tersine çevirebilir veya yerleşik reversed(text) yöntemini kullanabilirsiniz.
[::-1] ile metni tersine çevireceksiniz.import re
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing and comparing the string
return text == text[::-1]İkinci yöntemde, metni tersine çevirmeyi yalnızca ''.join(reversed(text)) ile değiştirip temizlenmiş metinle karşılaştıracaksınız.
Her iki yöntem de basittir.
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing the string
rev = ''.join(reversed(text))
return text == revSonuçlar:
Kelime listesini is_palindrome() fonksiyonuna verip sonuçları yazdıracağız. Gördüğünüz gibi, özel karakterler olsa bile fonksiyon “Level” ve “Radar” kelimelerini palindrom olarak tanımladı.
# Test cases
test_words = ['Anna', '**Radar****', 'Abid', '(Level)', 'Data']
for text in test_words:
print(f"Is {text} a palindrome? {is_palindrome(text)}")
# Is Anna a palindrome? True
# Is **Radar**** a palindrome? True
# Is Abid a palindrome? False
# Is (Level) a palindrome? True
# Is Data a palindrome? FalseBir sonraki kodlama mülakatlarınıza Python’da Kodlama Mülakat Soruları Pratiği interaktif kursumuzla hazırlanın. Daha derin Python kodlama hazırlığı için 2026 İçin 41 Önemli Python Mülakat Sorusu & Yanıtı yazımıza bakın.
En yüksek ve en düşük değeri bulmak kolaydır; ancak ikinci en yüksek veya n’inci en yüksek değeri bulmak zordur.
Bu soruda, id ve base_salary içeren bir veritabanı tablosu verilmektedir. İkinci en yüksek maaşı bulmak için SQL sorgusu yazacaksınız.
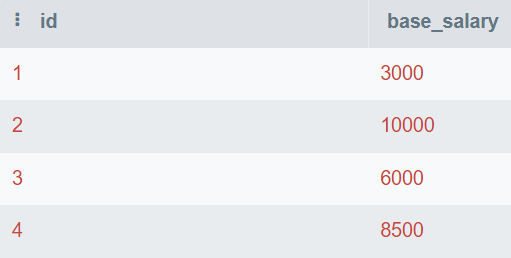
Görsel: Yazar
Bu sorguda, benzersiz değerleri bulup en yüksekgden en düşüğe doğru sıralayacaksınız. Ardından yalnızca en yüksek değeri göstermek için LIMIT 1 kullanacaksınız. Son olarak, ikinci en yüksek sayıyı göstermek için değeri 1 kaydıracaksınız (OFFSET 1).
OFFSET değerini değiştirerek n’inci en yüksek maaşı da alabilirsiniz.
SELECT DISTINCT base_salary AS "Second Highest Salary"
FROM employee
ORDER BY base_salary DESC
LIMIT 1
OFFSET 1;İkinci en yüksek temel maaş 8.500’dür.

Bu soruda, yinelenen tüm e-postaları gösterecek bir sorgu yazacaksınız.

Görsel: Yazar
Bu sorguda, bir email sütunu gösterecek ve tabloyu email’e göre gruplayacaksınız. Ardından HAVING ifadesini kullanarak birden fazla kez geçen e-postaları bulacağız.
HAVING, toplulaştırmalarla birlikte WHERE ifadesinin yerine kullanılır.
SELECT email
FROM employee_email
GROUP BY email
HAVING COUNT(email) > 1;Yalnızca “matt@hotmail.com” birden fazla kez geçmektedir.
İş sorularını yanıtlamak için sürdürülebilir SQL kodu yazmayı Gerçek Dünya Problemlerine SQL Uygulamak kursunu alarak öğrenin.
Görsel: Yazar
Bir ay önceki gönderi oranı %3’ten bugün %2,5’e düştü. Sonuca atlamadan önce, sorunun bağlamını netleştirmeniz gerekir.
Şu soruları sormalısınız:
İkinci bölümde, düşüşe neyin yol açtığını ayrıntılandırmalısınız. Kullanıcı sayısı mı arttı yoksa gönderi sayısı mı azaldı? Ardından mülakatçı bu iki gerekçeden biri veya ikisi üzerinden bir tartışma başlatmanızı isteyecektir.
Facebook’ta günde geçirilen zamanın dağılımı açısından, iki grup olabileceği varsayılabilir:
İkinci bölüm için dağılımı şu istatistiksel kavramlarla tanımlamalısınız:
Bu soruda, önce puanları çeşitli dilimlere ayıracak, ardından bu aralıklarda puan alan öğrencilerin yüzdesini hesaplayacak pandas kodu yazacaksınız.
Girdi:
Veri setimizde user_id, grade ve test_score sütunları var.
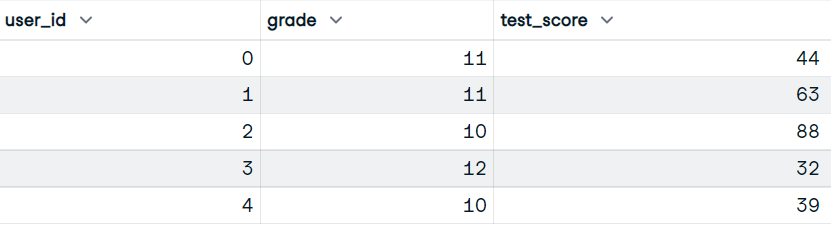
Görsel: Yazar
Çıktı:
grade ve test_score sütunlarını kullanacak bir fonksiyon yazacaksınız. Ve notları, dilim puanlarını ve dilim puanlarını alan öğrencilerin kümülatif yüzdesini gösteren veri çerçevesini görüntüleyeceksiniz.
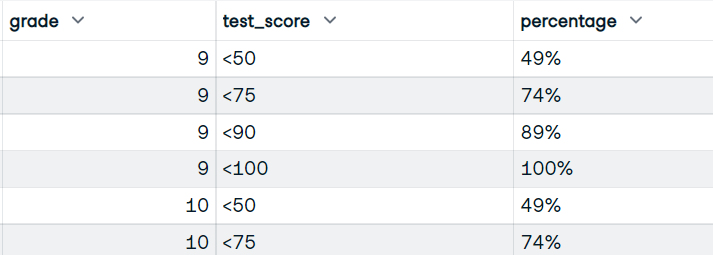
Görsel: Yazar
pandas.cut() fonksiyonunu kullanarak puanları, kutuların (bins) ve etiketlerin (labels) yardımıyla dilim puanlarına dönüştüreceksiniz. def bucket_test_scores(df):
bins = [0, 50, 75, 90, 100]
labels = ["<50", "<75", "<90", "<100"]
# converting the scores into buckets
df["test_score"] = pd.cut(df["test_score"], bins, labels=labels, right=False)
# Calculate size of each group, by grade and test score
df = df.groupby(["grade", "test_score"]).size()
# Calculate numerator and denominator for percentage
NUM = df.groupby("grade").cumsum()
DEN = df.groupby("grade").sum()
# Calculate percentage, multiply by 100, and add %
percentage = (NUM / DEN).map(lambda x: f"{int(100*x):d}%")
# reset the index
percentage = percentage.reset_index(name="percentage")
return percentage
bucket_test_scores(df)Dilim puanları ve yüzdeleriyle mükemmel sonucu elde ettiniz.
Verileri temizlemeyi, istatistik hesaplamayı ve görselleştirme oluşturmayı pandas ile Veri Manipülasyonu kursunda öğrenin. Daha derinlemesine bir inceleme için 2026 İçin En İyi 35 Makine Öğrenmesi Mülakat Sorusu rehberimize bakın.
Güven aralığı, deneyi tekrar yürüttüğünüzde veya benzer şekilde popülasyonu yeniden örneklediğinizde, belirli bir yüzde oranında düşmesini beklediğiniz, bilinmeyen bir parametre için tahmin aralığıdır.
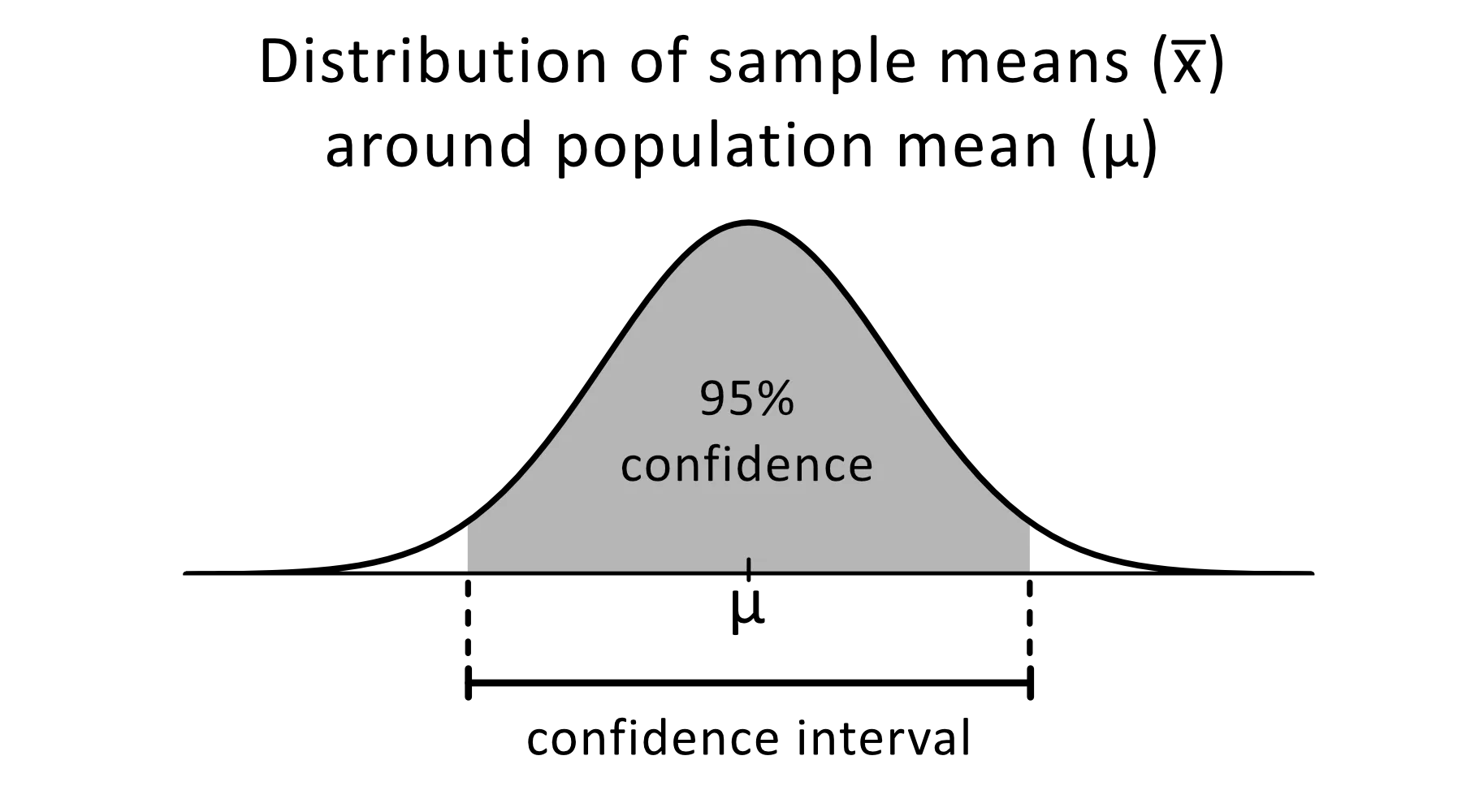
Görsel: omnicalculator
İstatistiksel deneylerde yaygın olarak %95 güven düzeyi kullanılır ve bu, tahmini parametreyi yeniden üretmeyi beklediğiniz zamanların yüzdesidir. Güven aralıklarının, alfa değeriyle belirlenen bir alt ve üst sınırı vardır.
Güven aralıklarını; oranlar, popülasyon ortalamaları, popülasyon ortalamaları veya oranları arasındaki farklar ve gruplar arasındaki varyasyon tahminleri gibi çeşitli istatistiksel tahminler için kullanabilirsiniz.
İstatistik temelinizi Python’da İstatistiksel Düşünme (Bölüm 1) kursunu tamamlayarak oluşturun.
Dengesiz veri setinde sınıflar eşit olmayan şekilde dağılmıştır. Örneğin, dolandırıcılık tespit verisinde 300.000 sahte olmayan vakaya kıyasla yalnızca 400 sahte vaka olabilir. Dengesiz veri, modelin dolandırıcılığı tespit etme performansını düşürür.
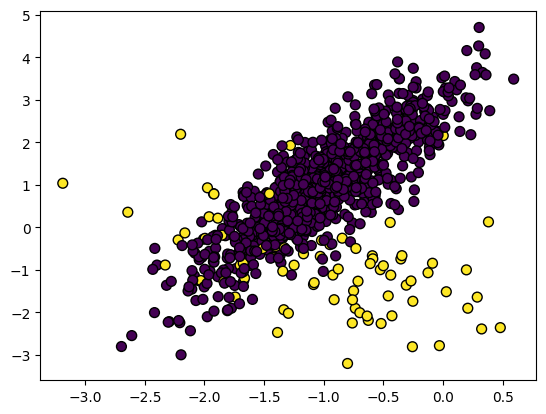
Görsel: Yazar
Dengesiz veriyi ele almak için şunları kullanabilirsiniz:
Eksik örnekleme
Çoğunluk sınıfı örneklerini, azınlık sınıfı örneklerine eşit olacak şekilde yeniden örnekler.
Dolandırıcılık verisinde her iki sınıf da 400 örneğe eşitlenir. Veri setinizi kolayca yeniden örneklemek için imblearn.under_sampling kullanabilirsiniz.
from imblearn.under_sampling import RandomUnderSampler
RUS = RandomUnderSampler(random_state=1)
X_US, y_US = RUS.fit_resample(X_train, y_train)Aşırı örnekleme
Azınlık sınıfı örneklerini, çoğunluk sınıfı örneklerine eşit olacak şekilde yeniden örnekler. Tekrar (repetition) veya ağırlıklı tekrar, veriyi dengelemede kullanılan yaygın yöntemlerdir. Kısacası her iki sınıf da 300K örneğe sahip olur.
from imblearn.over_sampling import RandomOverSampler
ROS = RandomOverSampler(random_state=0)
X_OS, y_OS = ROS.fit_resample(X_train, y_train)Sentetik veri oluşturma
Tekrarın sorunu, ek bilgi sağlamamasıdır; bu da modellerin zayıf performans göstermesine yol açabilir. Bunu aşmak için SMOTE (Synthetic Minority Oversampling Technique) ile sentetik veri noktaları oluşturabiliriz.
from imblearn.over_sampling import SMOTE
SM = SMOTE(random_state=1)
X_OS, y_OS = SM.fit_resample(X_train, y_train)Az ve çok örneklemenin kombinasyonu
Model önyargılarını ve performansını iyileştirmek için aşırı ve eksik örneklemenin bir kombinasyonunu kullanabilirsiniz. Aşırı örnekleme için SMOTE, temizlik için EEN (Edited Nearest Neighbours) kullanacağız.
imblearn.combine, her iki örneklemeyi de otomatik olarak gerçekleştiren çeşitli fonksiyonlar sağlar.
from imblearn.combine import SMOTEENN
SMTN = SMOTEENN(random_state=0)
X_OUS, y_OUS = SMTN.fit_resample(X_train, y_train)Bir veri bilimci olarak, veriyi çıkarmak ve analiz yapmak için buna benzer sorgular yazarsınız. Bu görevde, filtreleme yapmak için karşılaştırma işaretleriyle WHERE ifadesini veya BETWEEN ile WHERE ifadesini kullanacaksınız.
Tablo: orders
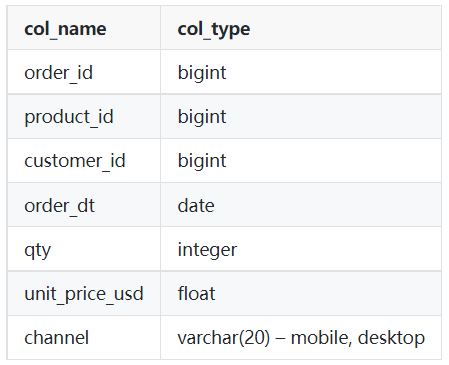
Görsel: Yazar
Örnek çıktı:
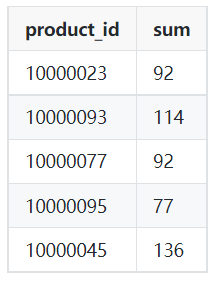
Görsel: Yazar
WHERE ve AND ile filtreleyin. Benzer işlemi BETWEEN ile de yapabilirsiniz. SELECT product_id,
SUM(qty)
FROM orders
WHERE order_dt >= '2022-03-01'
AND order_dt < '2022-04-01'
GROUP BY product_id;Denetimsiz öğrenmede, kümeleme projesinin performansını değerlendirmek zor olabilir. İyi bir kümelemenin ölçütü, benzerliğin az olduğu belirgin gruplardır.
Kümeleme modellerinde doğruluk metriği yoktur; bu nedenle model performansını değerlendirmek için ya gruplar arasındaki benzerliği ya da ayrışmayı kullanırız.
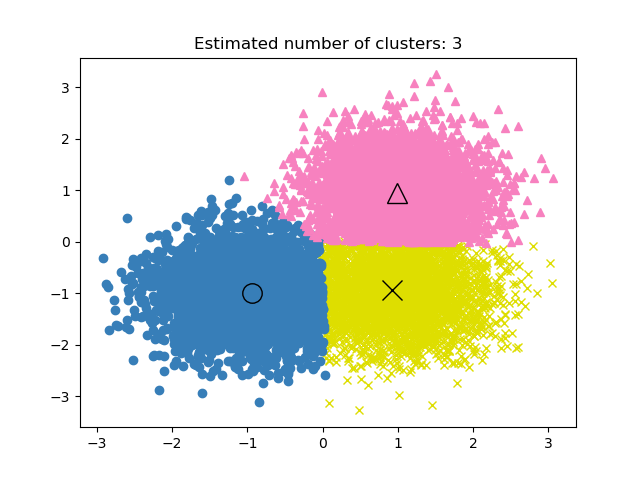
Görsel: scikit-learn dokümantasyonu
Yaygın olarak kullanılan üç metrik şunlardır:
Silhouette Skoru
Ortalama küme içi mesafe ile ortalama en yakın komşu küme mesafesi kullanılarak hesaplanır.
Metriği scikit-learn ile hesaplayabiliriz. Silhouette Skoru -1 ile 1 arasındadır; daha yüksek skorlar, gruplar arası benzerliğin düşük ve kümelerin belirgin olduğunu gösterir.
from sklearn import metrics
model = KMeans().fit(X)
labels = model.labels_
metrics.silhouette_score(X, labels)Calinski-Harabaz İndeksi
Gruplar arasındaki ayrışmayı, küme dışı saçılma ve küme içi saçılmayı kullanarak hesaplar. Metriğin bir sınırı yoktur ve Silhouette Skoru gibi daha yüksek skor daha iyi model performansı demektir.
metrics.calinski_harabasz_score(X, labels)Davies-Bouldin İndeksi
Her kümenin en benzer kümesiyle ortalama benzerliğini hesaplar. Diğer metriklerin aksine, daha düşük skor daha iyi model performansı ve kümeler arasında daha iyi ayrışma anlamına gelir.
metrics.davies_bouldin_score(X, labels)
Hiyerarşik ve k-ortalama (k-means) kümelemeyi uygulamayı R ile Küme Analizi kursunu alarak öğrenin.

Görsel: Yazar
Kullanacağımız gösterimler:
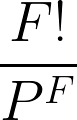
Bu problemi çözmek için önce katlarda inmenin toplam kaç şekilde olabileceğini bulmalıyız: 44 = 4x4x4x4 = 256 yol.
Ardından her kişinin farklı bir katta inebileceği durumların sayısını hesaplayın: 4! = 24.
Her kişinin farklı bir katta inme olasılığını hesaplamak için, her kişinin farklı katta inme sayısını toplam inme sayısına bölmemiz gerekir.
24/256 = 3/32
Zorlayıcı olasılık sorularını R ile yanıtlama stratejilerini R ile Olasılık Bulmacaları kursunu alarak öğrenin.
Normal dağılımdan N örnek üretmek için Numpy (np.random.randn(N)) veya SciPy (sp.stats.norm.rvs(size=N)) kullanabilirsiniz.
Histogram çizmek için Matplotlib veya Seaborn kullanabilirsiniz.
import numpy as np
import seaborn as sns
N = 10_000
def norm_dist_hist(N):
# Generating Random normal distribution samples
x = np.random.randn(N)
# Plotting histogram
sns.histplot(x, bins = 20, kde=True);
return x
X = norm_dist_hist(N)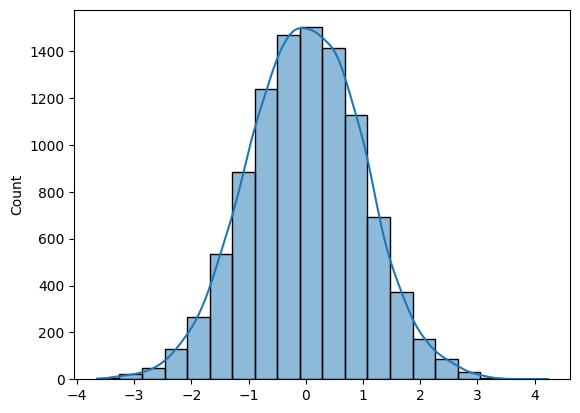
Bilgilendirici ve çekici görselleştirmeleri saniyeler içinde oluşturmayı Seaborn ile Veri Görselleştirmeye Giriş kursunu tamamlayarak öğrenin.
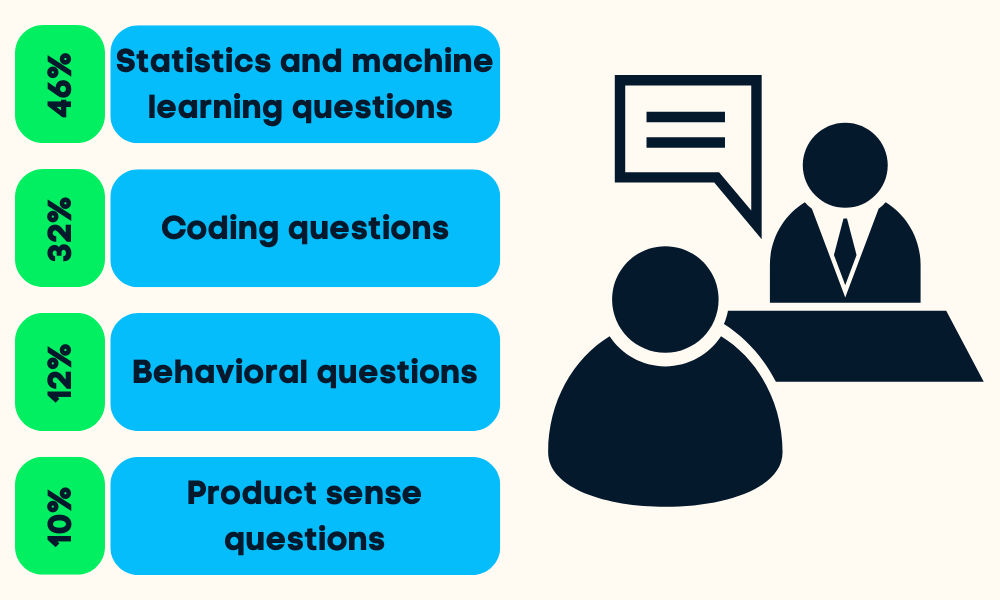
Görsel: Yazar
Veri bilimi mülakatları dört ila beş aşamaya ayrılır. İstatistik ve makine öğrenmesi, kodlama (Python, R, SQL), davranışsal, ürün sezgisi ve bazen liderlik soruları sorulur.
Tüm aşamalara şu şekilde hazırlanabilirsiniz:
Veri Bilimi Mülakat Hazırlığı blog yazımızı okuyarak neler beklemeniz gerektiğini ve mülakata nasıl yaklaşacağınızı öğrenin.
Veri Bilimi Kursları
Kurs
Kurs
Kurs