Curso
Python intermediário
4 h
1.4M

Vamos começar analisando algumas das perguntas sobre competências gerais que você poderá enfrentar na entrevista. Estas são algumas das habilidades sociais de que você precisará como cientista de dados:
Esta pergunta avalia suas habilidades de comunicação e sua capacidade de simplificar tópicos complexos. Aqui está um exemplo de resposta:
Em minha função anterior, eu tinha que explicar o conceito de aprendizado de máquina para nossa equipe de marketing. Usei a analogia de ensinar uma criança a reconhecer diferentes tipos de frutas. Assim como você mostraria a uma criança muitos exemplos para ajudá-la a aprender, um modelo de aprendizado de máquina é treinado com dados. Essa analogia ajudou a tornar um conceito complexo mais relacionável e fácil de entender.
Isso explora suas habilidades de colaboração em equipe e de resolução de conflitos. Você poderia responder a isso com algo como:
Em um projeto, trabalhei com um colega que tinha um estilo de trabalho muito diferente. Para resolver nossas diferenças, agendei uma reunião para entender a perspectiva dele. Encontramos pontos em comum em nossas metas de projeto e concordamos com uma abordagem compartilhada. Essa experiência me ensinou o valor da comunicação aberta e da empatia no trabalho em equipe.
Esta pergunta é sobre gerenciamento de tempo e priorização. Aqui está um exemplo de resposta:
Certa vez, tive que entregar uma análise em um prazo muito curto. Priorizei as partes mais importantes do projeto, comuniquei meu plano à equipe e me concentrei na execução eficiente. Ao dividir a tarefa e definir pequenos prazos, consegui concluir o projeto no prazo sem comprometer a qualidade.
Aqui, o entrevistador está avaliando sua capacidade de assumir os erros e aprender com eles. Você poderia responder com:
Em um caso, interpretei erroneamente os resultados de um modelo de dados. Ao perceber meu erro, informei imediatamente minha equipe e reanalisei os dados. Essa experiência me ensinou a importância de verificar novamente os resultados e o valor da transparência no local de trabalho.
Isso mostra que você está comprometido com o aprendizado contínuo e com a relevância em sua área. Aqui está um exemplo de resposta:
Mantenho-me atualizado lendo revistas do setor, assistindo a webinars e participando de fóruns on-line. Também separo um tempo toda semana para experimentar novas ferramentas e técnicas. Isso não apenas me ajuda a me manter atualizado, mas também aprimora continuamente minhas habilidades.
Essa pergunta avalia a adaptabilidade e as habilidades de resolução de problemas. Como exemplo, você poderia dizer:
Em um projeto anterior, os requisitos mudavam com frequência. Eu me adaptei mantendo uma comunicação aberta com as partes interessadas para entender suas necessidades. Também usei metodologias ágeis para ser mais flexível em minha abordagem, o que ajudou a acomodar as mudanças de forma eficaz.
Isso avalia sua capacidade de considerar vários aspectos além dos dados. Um exemplo de resposta poderia ser:
Em minha última função, tive que equilibrar a necessidade de decisões baseadas em dados com considerações éticas. Assegurei que todo o uso de dados estivesse em conformidade com os padrões éticos e as leis de privacidade, e apresentei alternativas quando necessário. Essa abordagem ajudou a tomar decisões informadas, respeitando os limites éticos.
As quatro premissas de uma regressão linear são:
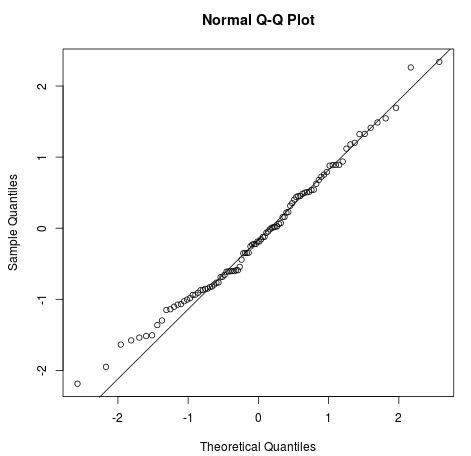
Imagem da Statology
Você pode explorar os conceitos e as aplicações dos modelos lineares fazendo nosso curso Introduction to Linear Modeling in Python.
Há várias maneiras de lidar com dados ausentes. Você pode:
Saiba como diagnosticar, visualizar e tratar dados ausentes ao concluir o curso Handling Missing Data with Imputations in R.
Primeiro, você precisa saber mais sobre o histórico do interessado e usar essas informações para modificar seu texto. Se ele tiver formação em finanças, aprenda sobre os termos comumente usados em finanças e use-os para explicar a metodologia complexa.
Em segundo lugar, você precisa usar muitos recursos visuais e gráficos. As pessoas aprendem visualmente, pois aprendem muito melhor com o uso de ferramentas de comunicação criativas.
Imagem do autor
Terceiro, fale em termos de resultados. Não tente explicar as metodologias ou estatísticas. Tente se concentrar em como eles podem usar as informações da análise para melhorar o negócio ou o fluxo de trabalho.
Por fim, incentive-os a fazer perguntas a você. As pessoas têm medo ou até mesmo vergonha de fazer perguntas sobre assuntos desconhecidos. Crie um canal de comunicação bidirecional, envolvendo-os na discussão.
Aprenda a criar seus próprios relatórios e painéis SQL fazendo nosso curso Reporting in SQL.
Há três métodos principais para a seleção de recursos: filtro, invólucro e métodos incorporados.
Métodos de filtro
Os métodos de filtro são geralmente usados nas etapas de pré-processamento. Esses métodos selecionam recursos de um conjunto de dados independentemente de qualquer algoritmo de aprendizado de máquina. Eles são rápidos, exigem menos recursos e removem recursos duplicados, correlacionados e redundantes.

Imagem do autor
Algumas técnicas usadas são:
Métodos de wrapper
Nos métodos de wrapper, treinamos o modelo iterativamente usando um subconjunto de recursos. Com base nos resultados do modelo treinado, mais recursos são adicionados ou removidos. Eles são computacionalmente mais caros do que os métodos de filtro, mas oferecem melhor precisão do modelo.
Imagem do autor
Algumas técnicas usadas são:
Métodos incorporados
Os métodos incorporados combinam as qualidades dos métodos de filtro e de invólucro. O algoritmo de seleção de recursos é combinado como parte do algoritmo de aprendizado, fornecendo ao modelo um método de seleção de recursos incorporado. Esses métodos são mais rápidos, como os métodos de filtro, precisos, como os métodos de wrapper, e também levam em consideração uma combinação de recursos.
Imagem do autor
Algumas técnicas usadas são:
Overfitting refere-se a um modelo que é treinado muito bem em um conjunto de dados de treinamento, mas falha no conjunto de dados de teste e validação.
Você pode evitar o ajuste excessivo:
Há quatro tipos principais de relacionamentos SQL:
Saiba como explorar as tabelas, os relacionamentos entre elas e os dados armazenados nelas, concluindo nosso curso Exploratory Data Analysis in SQL.
A redução da dimensionalidade é um processo que converte o conjunto de dados de várias dimensões em menos dimensões, mantendo informações semelhantes.
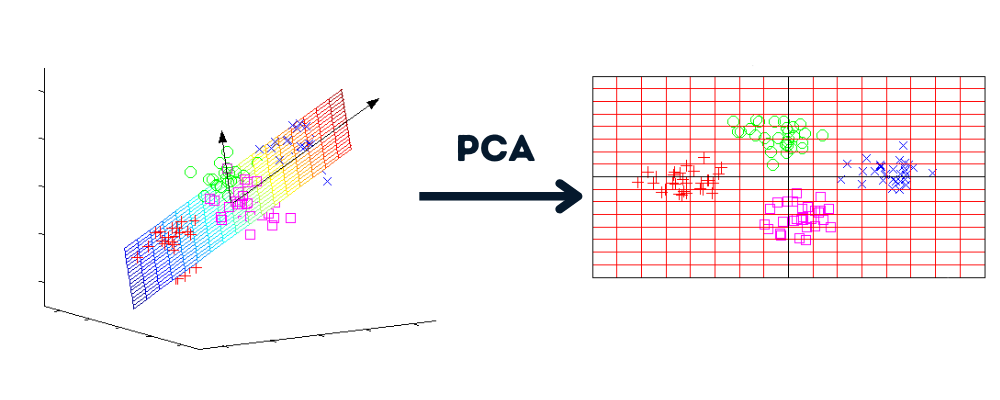
Imagem do autor | Gráficos de howecoresearch
Benefícios da redução da dimensionalidade:
Entenda o conceito de redução de dimensionalidade e domine as técnicas praticando o curso Redução de Dimensionalidade em Python.

Imagem do autor
Os testes A/B eliminam as suposições e nos ajudam a tomar decisões baseadas em dados para otimizar o produto ou o site. Também éconhecido como teste de divisão, em que são realizados experimentos aleatórios para analisar duas ou mais versões de variáveis (página da Web, recurso de aplicativo etc.) e determinar qual versão gera o máximo de tráfego e métricas de negócios.
Saiba como criar, executar e analisar testes A/B fazendo nosso curso Customer Analytics and A/B Testing in Python.
O stemming é comumente usado na análise de texto e de sentimentos. Nesta pergunta, você escreverá uma função Python que converterá determinadas palavras da lista em sua forma de raiz - Interview Query.
Entrada:
A função receberá dois argumentos: lista de palavras-raiz e sentença.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"Saída:
Ele retornará a frase com as palavras-raiz.
"the cat was rat by the bat"Antes de começar a escrever o código, você precisa entender que realizaremos duas tarefas: verificar se a palavra tem uma raiz e substituí-la.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"
def replace_words(roots, sentence):
words = sentence.split(" ")
# looping over each word
for index, word in enumerate(words):
# looping over each root
for root in roots:
# checking if words start with root
if word.startswith(root):
# replacing the word with its root
words[index] = root
return " ".join(words)
replace_words(roots, sentence)
# 'the cat was rat by the bat'Dada a cadeia de caracteres text, retorne True se for um palíndromo, caso contrário, False.
Depois de diminuir todas as letras e remover todos os caracteres não alfanuméricos, a palavra deve ser lida da mesma forma para frente e para trás.

Imagem do autor
O Python oferece maneiras fáceis de resolver esse desafio. Você pode tratar a cadeia de caracteres como iterável e invertê-la usando text[::-1] ou usar o método reversed(text) incorporado.
[::-1].import re
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing and comparing the string
return text == text[::-1]No segundo método, você apenas substituirá a inversão do texto por ''.join(reversed(text)) e o comparará com o texto limpo.
Ambos os métodos são simples.
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing the string
rev = ''.join(reversed(text))
return text == revResultados:
Forneceremos a lista de palavras à função is_palindrome() e imprimiremos os resultados. Como você pode ver, mesmo com caracteres especiais, a função identificou "Level" e "Radar" como palíndromos.
# Test cases
List = ['Anna', '**Radar****','Abid','(Level)', 'Data']
for text in List:
print(f"Is {text} a palindrome? {is_palindrome(text)}")
# Is Anna a palindrome? True
# Is **Radar**** a palindrome? True
# Is Abid a palindrome? False
# Is (Level) a palindrome? True
# Is Data a palindrome? FalsePrepare-se para suas próximas entrevistas de codificação praticando perguntas de codificação para entrevistas em Python com nosso curso interativo.
É fácil encontrar o maior e o menor valor, mas é difícil encontrar o segundo maior ou o enésimo maior valor.
Na pergunta, você recebe a tabela do banco de dados que consiste em id e base_salary. Você escreverá a consulta SQL para encontrar o segundo salário mais alto.
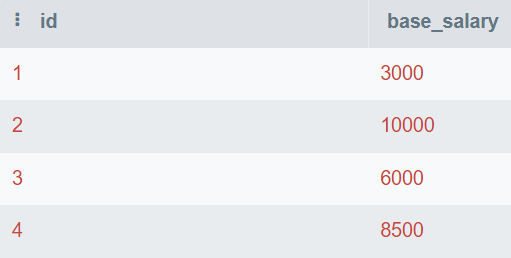
Imagem do autor
Nessa consulta, você encontrará os valores exclusivos e os ordenará do maior para o menor. Em seguida, você usará o site LIMIT 1 para exibir apenas o valor mais alto. No final, você compensará o valor por 1 para exibir o segundo maior número.
Você também pode alterar o valor OFFSET para obter o enésimo salário mais alto.
SELECT DISTINCT base_salary AS "Second Highest Salary"
FROM employee
ORDER BY base_salary DESC
LIMIT 1
OFFSET 1;O segundo maior salário-base é de 8.500.

Nesta pergunta, você escreverá uma consulta para exibir todos os e-mails duplicados.

Imagem do autor
Nesta consulta, você exibirá uma coluna email e agrupará a tabela por email. Depois disso, usaremos a cláusula HAVING para localizar e-mails que são mencionados mais de uma vez.
HAVING é usado como um substituto para a declaração WHERE em conjunto com agregações.
SELECT email
FROM employee_email
GROUP BY email
HAVING COUNT(email) > 1;Somente "matt@hotmail.com" ocorre mais de uma vez.
Escreva código SQL de fácil manutenção para responder a perguntas comerciais fazendo o curso Applying SQL to Real-World Problems (Aplicando SQL a problemas do mundo real ).
Imagem do autor
A postagem de um mês atrás caiu de 3% para 2,5% hoje. Antes de chegar a uma conclusão, você precisa esclarecer o contexto do problema.
Você precisa fazer perguntas:
Na segunda parte, você precisa explicar o que motivou a redução. O número de usuários aumentou ou o número de publicações diminuiu? Depois disso, o entrevistador pedirá que você inicie uma discussão usando um ou ambos os raciocínios.
Em termos de distribuição do tempo gasto por dia no Facebook, pode-se supor que existam dois grupos:
Na segunda parte, você deve usar o vocabulário estatístico para descrever a distribuição, por exemplo:
Nesta pergunta, você escreverá o código do pandas para primeiro dividir a pontuação em vários intervalos e, em seguida, calcular a porcentagem de alunos que obtiveram a pontuação nesses intervalos.
Entrada:
Nosso conjunto de dados tem as colunas user_id, grade e test_score.
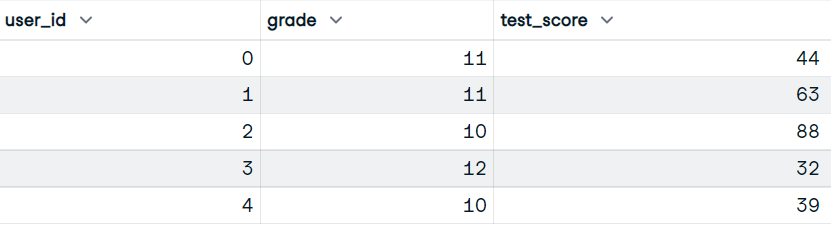
Imagem do autor
Saída:
Você escreverá a função que usará as colunas grade e test_score. E exiba o dataframe com as notas, as pontuações por bloco e a porcentagem cumulativa de alunos que obtiveram pontuações por bloco.
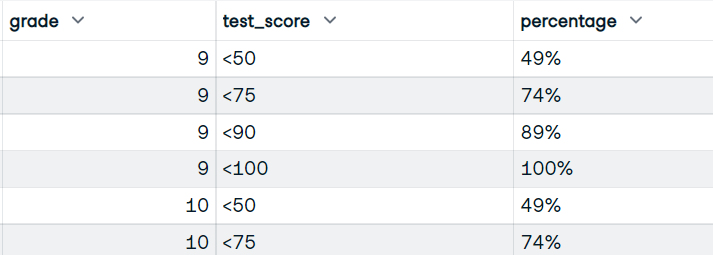
Imagem do autor
pandas.cut() para converter pontuações em pontuações de compartimento usando compartimentos e rótulos de compartimentos. def bucket_test_scores(df):
bins = [0, 50, 75, 90, 100]
labels = ["<50", "<75", "<90", "<100"]
# converting the scores into buckets
df["test_score"] = pd.cut(df["test_score"], bins, labels=labels, right=False)
# Calculate size of each group, by grade and test score
df = df.groupby(["grade", "test_score"]).size()
# Calculate numerator and denominator for percentage
NUM = df.groupby("grade").cumsum()
DEN = df.groupby("grade").sum()
# Calculate percentage, multiply by 100, and add %
percentage = (NUM / DEN).map(lambda x: f"{int(100*x):d}%")
# reset the index
percentage = percntage.reset_index(name="percentage")
return percentage
bucket_test_scores(df)Você obteve o resultado perfeito com uma pontuação de teste de balde e a porcentagem.
Saiba como limpar dados, calcular estatísticas e criar visualizações com o curso Manipulação de dados com pandas.
O intervalo de confiança é um intervalo de estimativas para um parâmetro desconhecido que você espera que fique entre uma determinada porcentagem do tempo quando você executar o experimento novamente ou, de forma semelhante, reamostrar a população.
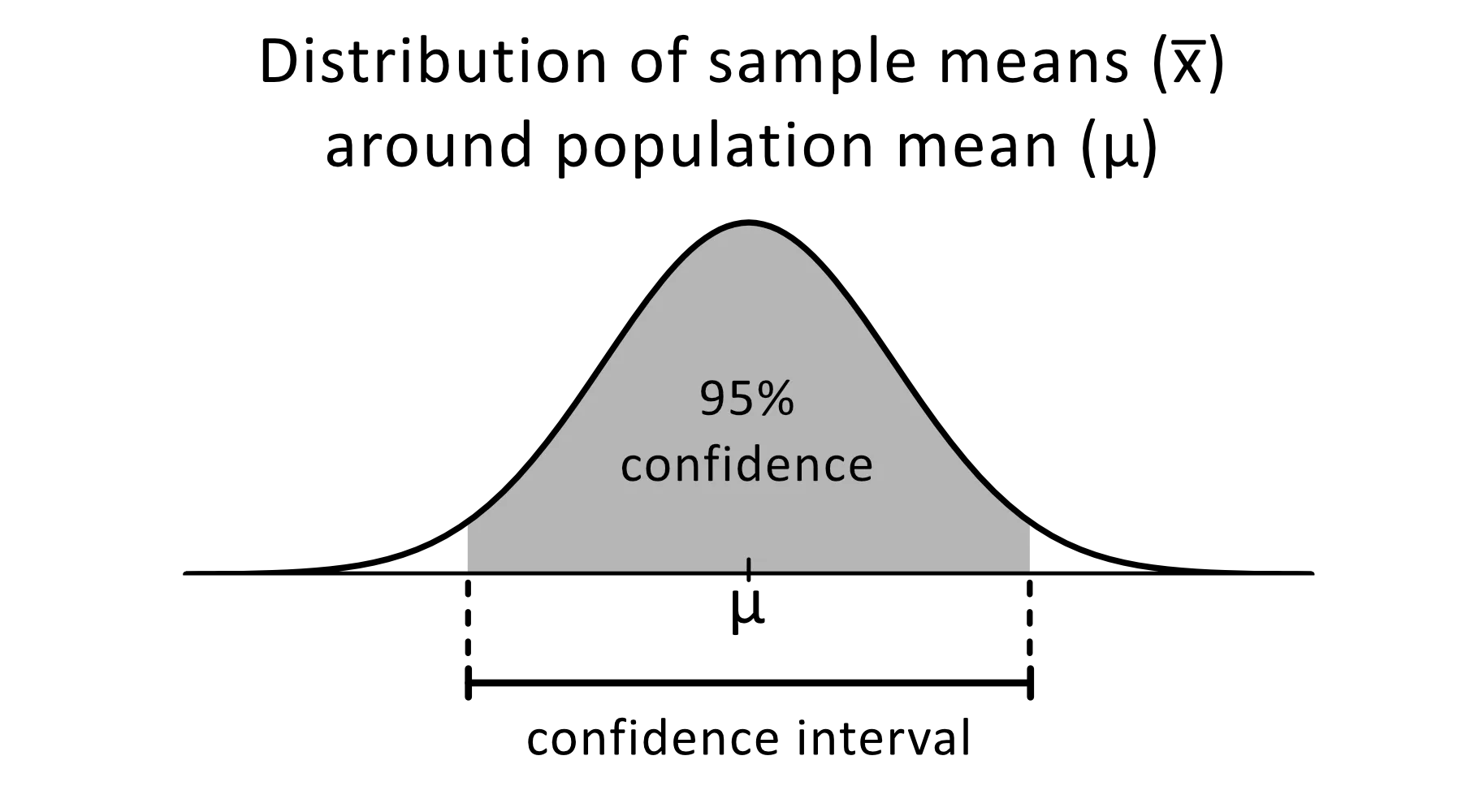
Imagem de omnicalculator
O nível de confiança de 95% é comumente usado em experimentos estatísticos e é a porcentagem de vezes que você espera reproduzir um parâmetro estimado. Os intervalos de confiança têm um limite superior e um limite inferior que é definido pelo valor alfa.
Você pode usar intervalos de confiança para várias estimativas estatísticas, como proporções, médias populacionais, diferenças entre médias ou proporções populacionais e estimativas de variação entre grupos.
Para desenvolver a base estatística, conclua nosso curso Statistical Thinking in Python (Parte 1).
No conjunto de dados não balanceado, as classes são distribuídas de forma desigual. Por exemplo, no conjunto de dados de detecção de fraude, há apenas 400 casos de fraude em comparação com 300.000 casos de não fraude. Os dados não balanceados farão com que o modelo tenha um desempenho pior na detecção de fraudes.
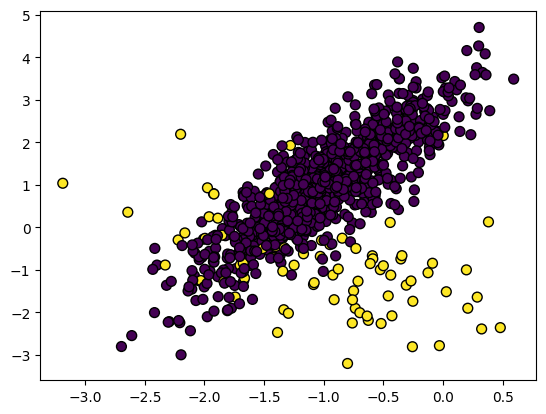
Imagem do autor
Para lidar com dados desequilibrados, você pode usar:
Subamostragem
Ele faz uma nova amostragem dos recursos da classe majoritária para torná-los iguais aos recursos da classe minoritária.
No conjunto de dados de detecção de fraude, ambas as classes serão iguais a 400 amostras. Você pode usar o site imblearn.under_sampling para fazer uma nova amostragem do conjunto de dados com facilidade.
from imblearn.under_sampling import RandomUnderSampler
RUS = RandomUnderSampler(random_state=1)
X_US, y_US = RUS.fit_resample(X_train, y_train)Amostragem excessiva
Ele faz uma nova amostragem dos recursos da classe minoritária para torná-los iguais aos recursos da classe majoritária. A repetição ou a repetição da ponderação dos recursos da classe minoritária são alguns dos métodos comuns usados para equilibrar os dados. Em resumo, ambas as classes terão 300 mil amostras.
from imblearn.over_sampling import RandomOverSampler
ROS = RandomOverSampler(random_state=0)
X_OS, y_OS = ROS.fit_resample(X_train, y_train)Criação de dados sintéticos
O problema da repetição é que ela não fornece informações adicionais, o que resultará em um desempenho ruim dos modelos. Para combatê-la, podemos usar a técnica SMOTE (Synthetic Minority Oversampling) para criar pontos de dados sintéticos.
from imblearn.over_sampling import SMOTE
SM = SMOTE(random_state=1)
X_OS, y_OS = SM.fit_resample(X_train, y_train)Combinação de amostragem insuficiente e excessiva
Para melhorar as tendências e o desempenho do modelo, você pode usar uma combinação de sobreamostragem e subamostragem. Usaremos o SMOTE para superamostragem e o EEN (Edited Nearest Neighbours) para limpeza.
O site imblearn.combine nos fornece várias funções que executam automaticamente ambas as funções de amostragem.
from imblearn.combine import SMOTEENN
SMTN = SMOTEENN(random_state=0)
X_OUS, y_OUS = SMTN.fit_resample(X_train, y_train)Como cientista de dados, você escreverá um tipo semelhante de consulta para extrair os dados e realizar a análise de dados. Neste desafio, você usará a cláusula WHERE com sinais de comparação ou WHERE com a cláusula BETWEEN para realizar a filtragem.
Tabela: pedidos
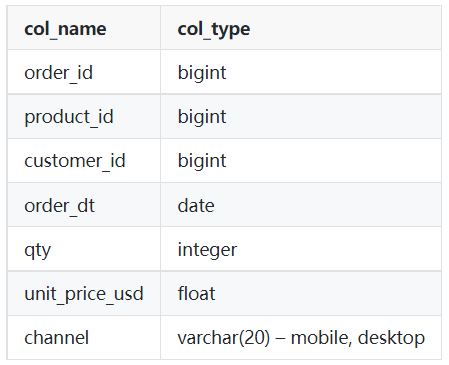
Imagem do autor
Exemplo de saída:
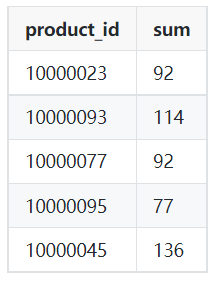
Imagem do autor
SELECT product_id,
SUM(qty)
FROM orders
WHERE order_dt >= '2022-03-01'
AND order_dt < '2022-04-01'
GROUP BY product_id;No aprendizado não supervisionado, encontrar o desempenho do projeto de agrupamento pode ser complicado. Os critérios de um bom agrupamento são grupos distintos com pouca similaridade.
Não há métrica de precisão nos modelos de agrupamento, portanto, usaremos a similaridade ou a distinção entre os grupos para avaliar o desempenho do modelo.
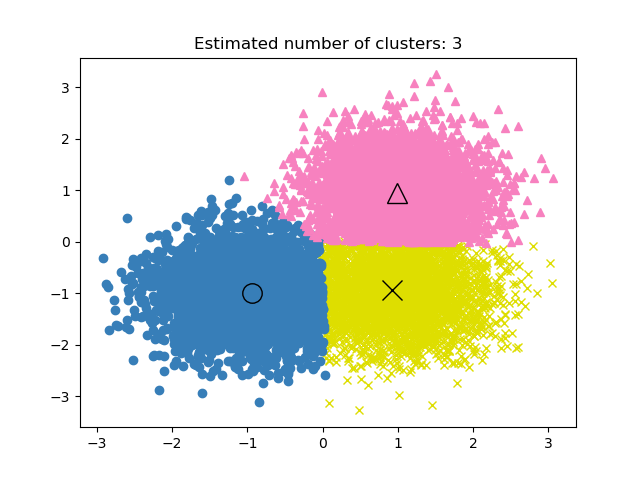
Imagem da documentação do scikit-learn
As três métricas comumente usadas são:
Silhouette Score
Ela é calculada usando a distância média intra-cluster e a distância média do cluster mais próximo.
Podemos usar o scikit-learn para calcular a métrica. A pontuação de silhueta varia de -1 a 1, em que pontuações mais altas significam menor similaridade entre grupos e clusters distintos.
from sklearn import metrics
model = KMeans().fit(X)
labels = model.labels_
metrics.silhouette_score(X, labels)Índice Calinski-Harabaz
Ele calcula a distinção entre grupos usando a dispersão entre clusters e a dispersão dentro do cluster. A métrica não tem limite e, assim como o Silhouette Score, uma pontuação mais alta significa melhor desempenho do modelo.
metrics.calinski_harabasz_score(X, labels)Índice Davies-Bouldin
Ele calcula a semelhança média de cada cluster com seu cluster mais semelhante. Diferentemente de outras métricas, uma pontuação mais baixa significa melhor desempenho do modelo e melhor separação entre os clusters.
metrics.davies_bouldin_score(X, labels)
Saiba como aplicar clustering hierárquico e k-means fazendo nosso curso Cluster Analysis in R.

Imagem do autor
Nós usaremos:
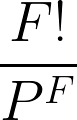
Para resolver esse problema, precisamos primeiro encontrar o número total de maneiras de sair dos pisos: 44 = 4x4x4x4 = 256 maneiras.
Depois disso, calcule o número de maneiras pelas quais cada pessoa pode descer em um andar diferente: 4! = 24.
Para calcular a probabilidade de cada pessoa descer em um andar diferente, precisamos dividir o número de maneiras pelas quais cada pessoa desce em um andar diferente pelo número total de maneiras de descer dos andares.
24/256 = 3/32
Aprenda estratégias para responder a perguntas complicadas sobre probabilidade com o R fazendo nosso curso Probability Puzzles in R.
Para gerar N amostras da distribuição normal, você pode usar o Numpy (np.random.randn(N)) ou o SciPy (sp.stats.norm.rvs(size=N)).
Para desenhar um histograma, você pode usar o Matplotlib ou o Seaborn.
A pergunta é bastante simples se você conhecer as ferramentas certas.
import numpy as np
import seaborn as sns
N = 10_000
def norm_dist_hist(N):
# Generating Random normal distribution samples
x = np.random.randn(N)
# Plotting histogram
sns.histplot(x, bins = 20, kde=True);
return x
X = norm_dist_hist(N)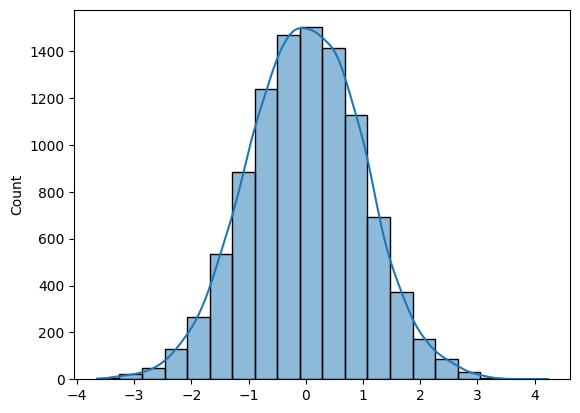
Você aprenderá a criar visualizações informativas e atraentes em segundos ao concluir o curso Introduction to Data Visualization with Seaborn.
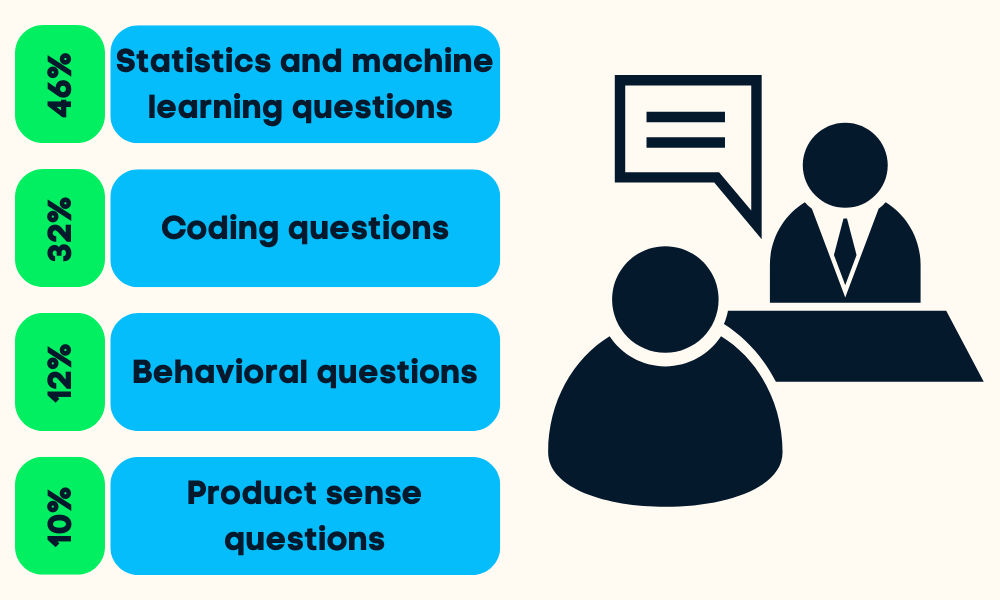
Imagem do autor
As entrevistas de ciência de dados são divididas em quatro ou cinco etapas. Você será questionado sobre estatística e aprendizado de máquina, codificação (Python, R, SQL), comportamento, senso de produto e, às vezes, perguntas sobre liderança.
Você pode se preparar para todos os estágios:
Leia o blog Preparação para a entrevista de ciência de dados para saber o que você deve esperar e como abordar a entrevista.
Cursos de ciência de dados
Curso
Curso
Curso
blog
Austin Chia
15 min
blog
Artur Sannikov
12 min
blog
Tim Lu
9 min
blog
Nisha Arya Ahmed
15 min
blog
Srujana Maddula
15 min