Kurs
Python für Fortgeschrittene
4 Std.
1.4M

Schauen wir uns zunächst einige der allgemeinen Kompetenzfragen an, die du in deinem Vorstellungsgespräch stellen könntest. Hier werden einige der Soft Skills getestet, die du als Datenwissenschaftler/in brauchst:
Diese Frage bewertet deine Kommunikationsfähigkeit und deine Fähigkeit, komplexe Themen zu vereinfachen. Hier ist eine Beispielantwort:
In meiner vorherigen Position musste ich unserem Marketingteam das Konzept des maschinellen Lernens erklären. Ich habe die Analogie verwendet, einem Kind beizubringen, verschiedene Obstsorten zu erkennen. Genauso wie du einem Kind viele Beispiele zeigen würdest, um ihm beim Lernen zu helfen, wird ein maschinelles Lernmodell mit Daten trainiert. Diese Analogie hat dazu beigetragen, ein komplexes Konzept leichter verständlich zu machen.
Dabei werden deine Fähigkeiten zur Zusammenarbeit im Team und zur Konfliktlösung getestet. Du könntest das mit etwas wie:
Bei einem Projekt habe ich mit einem Kollegen zusammengearbeitet, der einen ganz anderen Arbeitsstil hatte. Um unsere Differenzen beizulegen, habe ich ein Treffen vereinbart, um seine Sichtweise zu verstehen. Wir fanden eine gemeinsame Basis in unseren Projektzielen und einigten uns auf einen gemeinsamen Ansatz. Diese Erfahrung lehrte mich den Wert von offener Kommunikation und Empathie in der Teamarbeit.
Bei dieser Frage geht es um Zeitmanagement und Prioritätensetzung. Hier ist eine Beispielantwort:
Einmal musste ich eine Analyse innerhalb einer sehr knappen Frist abgeben. Ich habe die wichtigsten Teile des Projekts nach Prioritäten geordnet, dem Team meinen Plan mitgeteilt und mich auf eine effiziente Ausführung konzentriert. Durch die Aufteilung der Aufgabe und die Festlegung von Miniterminen gelang es mir, das Projekt rechtzeitig fertigzustellen, ohne die Qualität zu beeinträchtigen.
Hier geht es darum, ob du in der Lage bist, Fehler einzugestehen und aus ihnen zu lernen. Du könntest antworten mit:
In einem Fall habe ich die Ergebnisse eines Datenmodells falsch interpretiert. Als ich meinen Fehler bemerkte, informierte ich sofort mein Team und analysierte die Daten neu. Diese Erfahrung hat mich gelehrt, wie wichtig es ist, Ergebnisse doppelt zu überprüfen und wie wichtig Transparenz am Arbeitsplatz ist.
Das zeigt, dass du dich bemühst, ständig zu lernen und in deinem Bereich relevant zu bleiben. Hier ist ein Beispiel für eine Antwort:
Ich bleibe auf dem Laufenden, indem ich Fachzeitschriften lese, an Webinaren teilnehme und in Online-Foren mitmache. Außerdem nehme ich mir jede Woche Zeit, um mit neuen Werkzeugen und Techniken zu experimentieren. Das hilft mir nicht nur, auf dem Laufenden zu bleiben, sondern verbessert auch ständig meine Fähigkeiten.
Diese Frage bewertet die Anpassungsfähigkeit und die Problemlösungskompetenz. Du könntest zum Beispiel sagen:
Bei einem früheren Projekt haben sich die Anforderungen häufig geändert. Ich passte mich an, indem ich eine offene Kommunikation mit den Interessengruppen pflegte, um ihre Bedürfnisse zu verstehen. Ich habe auch agile Methoden eingesetzt, um flexibler vorzugehen, was mir geholfen hat, Änderungen effektiv zu berücksichtigen.
Damit wird deine Fähigkeit bewertet, verschiedene Aspekte zu berücksichtigen, die über die reinen Daten hinausgehen. Eine Beispielantwort könnte lauten:
In meiner letzten Position musste ich die Notwendigkeit datengestützter Entscheidungen mit ethischen Überlegungen in Einklang bringen. Ich habe dafür gesorgt, dass bei der Datennutzung die ethischen Standards und die Datenschutzgesetze eingehalten werden, und ich habe bei Bedarf Alternativen aufgezeigt. Dieser Ansatz half dabei, fundierte Entscheidungen zu treffen und gleichzeitig die ethischen Grenzen zu respektieren.
Die vier Annahmen für eine lineare Regression sind:
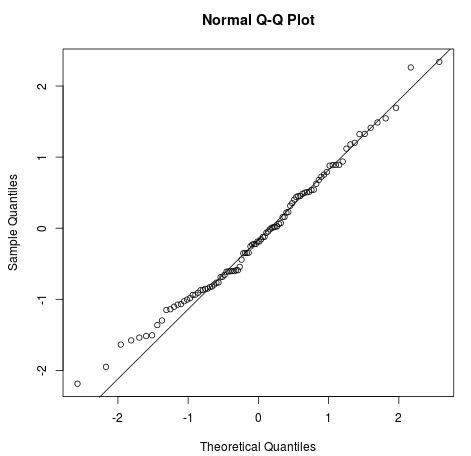
Bild von Statology
Du kannst die Konzepte und Anwendungen von linearen Modellen in unserem Kurs Einführung in die lineare Modellierung in Python kennenlernen.
Es gibt verschiedene Möglichkeiten, mit fehlenden Daten umzugehen. Das kannst du:
Lerne, wie du fehlende Daten diagnostizierst, visualisierst und behandelst, indem du den Kurs Handling Missing Data with Imputations in R abschließt.
Zuerst musst du mehr über den Hintergrund des Interessenvertreters erfahren und diese Informationen nutzen, um deine Formulierungen zu ändern. Wenn er einen Finanzhintergrund hat, lerne die gebräuchlichen Begriffe aus dem Finanzwesen und verwende sie, um die komplexe Methodik zu erklären.
Zweitens musst du viele Grafiken und Schaubilder verwenden. Menschen sind visuelle Lerner, da sie mit kreativen Kommunikationsmitteln viel besser lernen.
Bild vom Autor
Drittens: Sprich in Form von Ergebnissen. Versuche nicht, die Methoden oder Statistiken zu erklären. Versuche, dich darauf zu konzentrieren, wie sie die Informationen aus der Analyse nutzen können, um das Geschäft oder den Arbeitsablauf zu verbessern.
Ermutige sie schließlich dazu, dir Fragen zu stellen. Die Menschen haben Angst oder schämen sich sogar, Fragen zu unbekannten Themen zu stellen. Schaffe einen zweiseitigen Kommunikationskanal, indem du sie in die Diskussion einbeziehst.
In unserem Kurs Reporting in SQL lernst du, deine eigenen SQL-Berichte und Dashboards zu erstellen.
Es gibt drei Hauptmethoden für die Merkmalsauswahl: Filter-, Wrapper- und eingebettete Methoden.
Filter-Methoden
Filtermethoden werden in der Regel in Vorverarbeitungsschritten eingesetzt. Diese Methoden wählen unabhängig von den Algorithmen des maschinellen Lernens Merkmale aus einem Datensatz aus. Sie sind schnell, benötigen weniger Ressourcen und entfernen doppelte, korrelierte und redundante Merkmale.

Bild vom Autor
Einige der verwendeten Techniken sind:
Wrapper-Methoden
Bei Wrapper-Methoden trainieren wir das Modell iterativ mit einer Teilmenge von Merkmalen. Auf der Grundlage der Ergebnisse des trainierten Modells werden weitere Merkmale hinzugefügt oder entfernt. Sie sind rechenintensiver als Filtermethoden, bieten aber eine bessere Modellgenauigkeit.
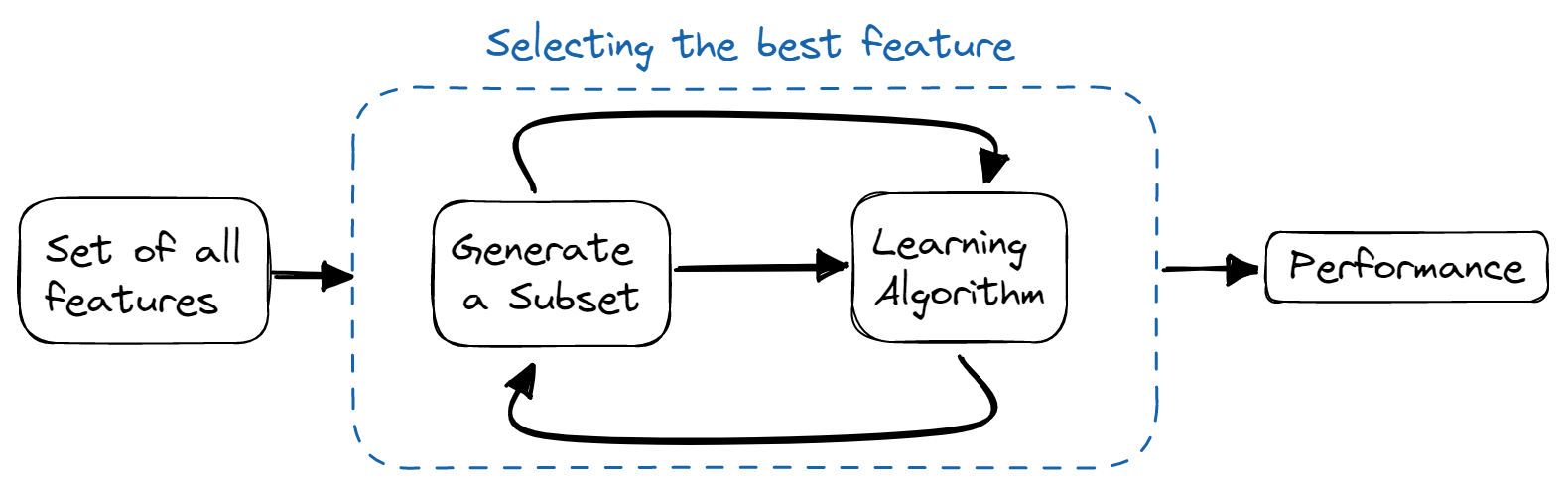
Bild vom Autor
Einige der verwendeten Techniken sind:
Eingebettete Methoden
Eingebettete Methoden kombinieren die Eigenschaften von Filter- und Wrapper-Methoden. Der Algorithmus für die Merkmalsauswahl ist Teil des Lernalgorithmus, sodass das Modell über eine integrierte Methode zur Merkmalsauswahl verfügt. Diese Methoden sind schneller, wie die Filtermethoden, genauer wie die Wrapper-Methoden und berücksichtigen auch eine Kombination von Merkmalen.
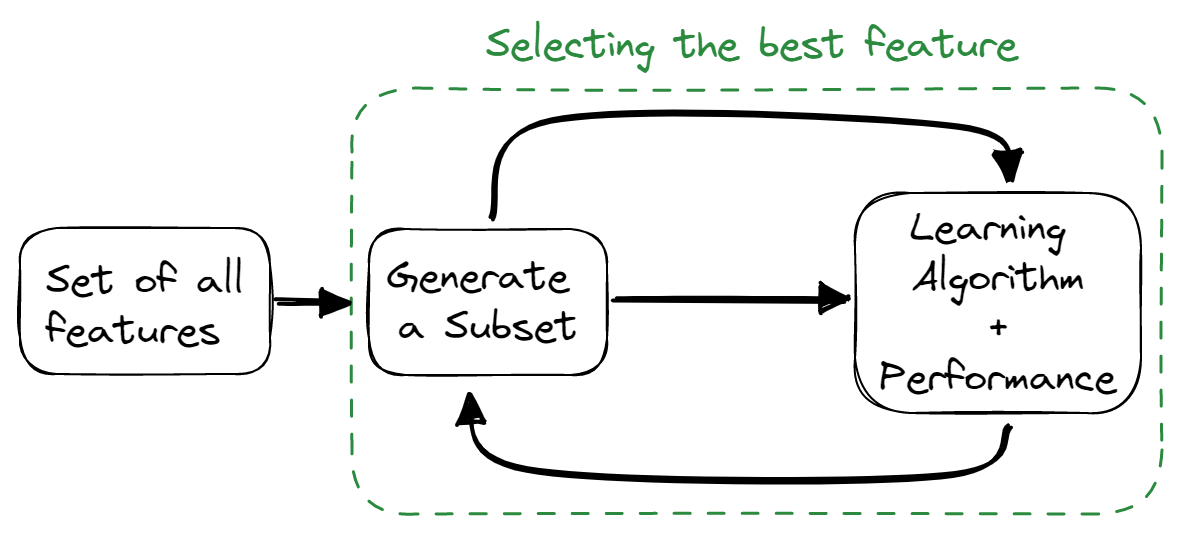
Bild vom Autor
Einige der verwendeten Techniken sind:
Überanpassung bezieht sich auf ein Modell, das in einem Trainingsdatensatz zu gut trainiert wurde, aber in einem Test- und Validierungsdatensatz versagt.
Du kannst eine Überanpassung vermeiden, indem du:
Es gibt vier Haupttypen von SQL-Beziehungen:
Lerne in unserem Kurs " Explorative Datenanalyse in SQL ", wie du die Tabellen, die Beziehungen zwischen ihnen und die in ihnen gespeicherten Daten untersuchen kannst.
Die Dimensionalitätsreduktion ist ein Prozess, der den Datensatz von mehreren Dimensionen in weniger Dimensionen umwandelt und dabei ähnliche Informationen beibehält.
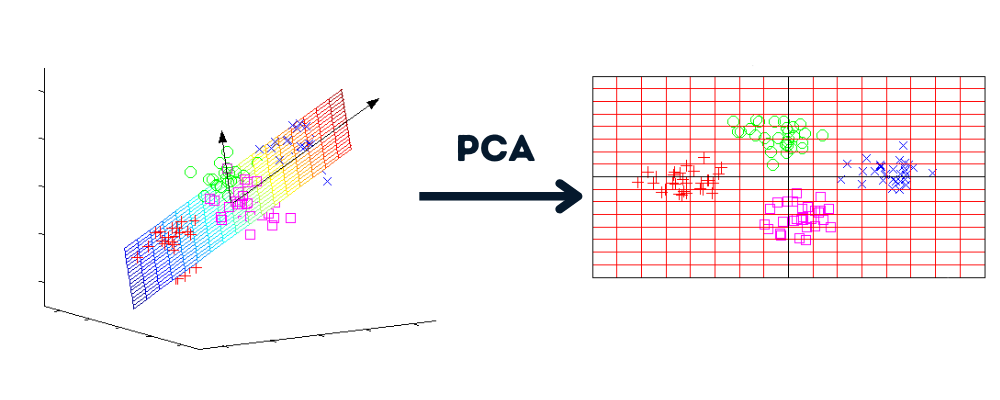
Bild vom Autor | Grafiken von howecoresearch
Vorteile der Dimensionalitätsreduktion:
Verstehe das Konzept der Dimensionalitätsreduktion und beherrsche die Techniken, indem du den Kurs Dimensionalitätsreduktion in Python übst.

Bild vom Autor
A/B-Tests machen das Rätselraten überflüssig und helfen uns, datengestützte Entscheidungen zu treffen, um das Produkt oder die Website zu optimieren. Dabei werden randomisierte Experimente durchgeführt, um zwei oder mehr Versionen von Variablen (Webseiten, App-Funktionen usw.) zu analysieren und herauszufinden, welche Version die meisten Besucher/innen und Geschäftskennzahlen bringt.
In unserem Kurs Kundenanalyse und A/B-Tests in Python lernst du, wie du A/B-Tests erstellst, durchführst und analysierst.
Stemming wird häufig in der Text- und Stimmungsanalyse verwendet. In dieser Frage sollst du eine Python-Funktion schreiben, die bestimmte Wörter aus der Liste in ihre Stammform umwandelt - Interview Query.
Eingabe:
Die Funktion nimmt zwei Argumente entgegen: eine Liste von Stammwörtern und einen Satz.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"Ausgabe:
Es wird den Satz mit den Stammwörtern zurückgeben.
"the cat was rat by the bat"Bevor du mit dem Schreiben des Codes beginnst, musst du verstehen, dass wir zwei Aufgaben durchführen: prüfen, ob das Wort einen Wortstamm hat und ihn ersetzen.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"
def replace_words(roots, sentence):
words = sentence.split(" ")
# looping over each word
for index, word in enumerate(words):
# looping over each root
for root in roots:
# checking if words start with root
if word.startswith(root):
# replacing the word with its root
words[index] = root
return " ".join(words)
replace_words(roots, sentence)
# 'the cat was rat by the bat'Bei der Zeichenkette text wird True zurückgegeben, wenn es ein Palindrom ist, sonst False.
Nachdem alle Buchstaben verkleinert und alle nicht alphanumerischen Zeichen entfernt wurden, sollte das Wort vorwärts und rückwärts gleich lauten.

Bild vom Autor
Python bietet einfache Möglichkeiten, diese Herausforderung zu lösen. Du kannst den String entweder als iterable behandeln und ihn mit text[::-1] umkehren oder die eingebaute Methode reversed(text) verwenden.
[::-1] um.import re
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing and comparing the string
return text == text[::-1]Bei der zweiten Methode ersetzt du einfach den umgekehrten Text durch ''.join(reversed(text)) und vergleichst ihn mit dem bereinigten Text.
Beide Methoden sind ganz einfach.
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing the string
rev = ''.join(reversed(text))
return text == revErgebnisse:
Wir geben die Liste des Wortes an die Funktion is_palindrome() weiter und drucken die Ergebnisse aus. Wie du siehst, hat die Funktion "Level" und "Radar" auch mit Sonderzeichen als Palindrome erkannt.
# Test cases
List = ['Anna', '**Radar****','Abid','(Level)', 'Data']
for text in List:
print(f"Is {text} a palindrome? {is_palindrome(text)}")
# Is Anna a palindrome? True
# Is **Radar**** a palindrome? True
# Is Abid a palindrome? False
# Is (Level) a palindrome? True
# Is Data a palindrome? FalseBereite dich auf deine nächsten Vorstellungsgespräche vor, indem du mit unserem interaktiven Kurs Fragen für Vorstellungsgespräche in Python übst.
Es ist leicht, den höchsten und den niedrigsten Wert zu finden, aber schwer, den zweithöchsten oder den n-ten höchsten Wert zu finden.
In der Frage wird dir eine Datenbanktabelle vorgelegt, die aus id und base_salary besteht. Du wirst die SQL-Abfrage schreiben, um das zweithöchste Gehalt zu finden.
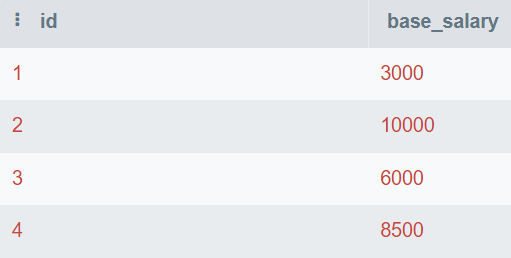
Bild vom Autor
In dieser Abfrage findest du die eindeutigen Werte und ordnest sie vom höchsten zum niedrigsten Wert. Dann benutzt du LIMIT 1, um nur den höchsten Wert anzuzeigen. Am Ende versetzt du den Wert um 1, um die zweithöchste Zahl anzuzeigen.
Du kannst auch den Wert OFFSET ändern, um das n-te höchste Gehalt zu erhalten.
SELECT DISTINCT base_salary AS "Second Highest Salary"
FROM employee
ORDER BY base_salary DESC
LIMIT 1
OFFSET 1;Das zweithöchste Grundgehalt beträgt 8.500.

In dieser Frage sollst du eine Abfrage schreiben, die alle doppelten E-Mails anzeigt.

Bild vom Autor
In dieser Abfrage wirst du eine email Spalte anzeigen und die Tabelle nach email gruppieren. Danach werden wir die HAVING Klausel verwenden, um E-Mails zu finden, die mehr als einmal erwähnt werden.
HAVING wird als Ersatz für die Anweisung WHERE in Verbindung mit Aggregationen verwendet.
SELECT email
FROM employee_email
GROUP BY email
HAVING COUNT(email) > 1;Nur "matt@hotmail.com" kommt mehr als einmal vor.
Schreibe wartbaren SQL-Code, um geschäftliche Fragen zu beantworten, indem du den Kurs "Applying SQL to Real-World Problems " belegst.
Bild vom Autor
Der Beitrag von vor einem Monat fiel von 3% auf 2,5% heute. Bevor du zu einer Schlussfolgerung kommst, musst du den Kontext des Problems klären.
Du musst Fragen stellen:
Im zweiten Teil musst du erläutern, was der Grund für den Rückgang ist. Ist die Zahl der Nutzer gestiegen oder die Zahl der Beiträge gesunken? Danach wird der/die Interviewer/in darum bitten, eine Diskussion mit einer oder beiden Begründungen zu beginnen.
Bei der Verteilung der Zeit, die pro Tag auf Facebook verbracht wird, kann man davon ausgehen, dass es zwei Gruppen geben könnte:
Für den zweiten Teil musst du statistisches Vokabular verwenden, um die Verteilung zu beschreiben, wie z. B.:
In dieser Frage schreibst du Pandas-Code, um die Punktzahl zunächst in verschiedene Bereiche zu unterteilen und dann den Prozentsatz der Schüler zu berechnen, die die Punktzahl in diesen Bereichen erreichen.
Eingabe:
Unser Datensatz hat die Spalten user_id, grade und test_score.
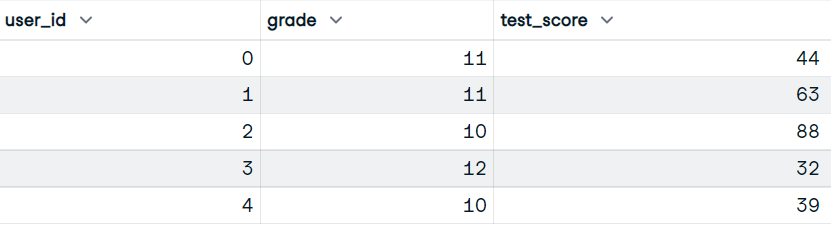
Bild vom Autor
Ausgabe:
Du wirst die Funktion schreiben, die die Spalten grade und test_score verwendet. Und zeige den Datenrahmen mit Noten, Bereichsnoten und dem kumulativen Prozentsatz der Schüler, die Bereichsnoten erhalten haben, an.
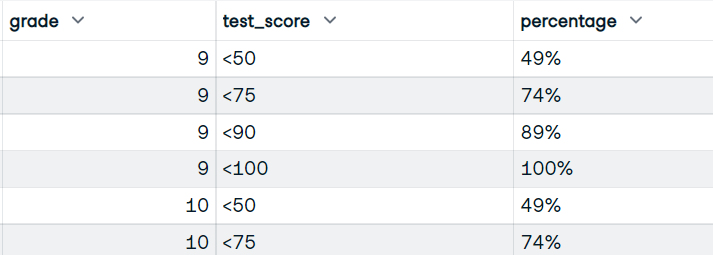
Bild vom Autor
pandas.cut() konvertierst du die Punktzahlen in Bucket Scores, indem du die Bins und Labels der Buckets verwendest. def bucket_test_scores(df):
bins = [0, 50, 75, 90, 100]
labels = ["<50", "<75", "<90", "<100"]
# converting the scores into buckets
df["test_score"] = pd.cut(df["test_score"], bins, labels=labels, right=False)
# Calculate size of each group, by grade and test score
df = df.groupby(["grade", "test_score"]).size()
# Calculate numerator and denominator for percentage
NUM = df.groupby("grade").cumsum()
DEN = df.groupby("grade").sum()
# Calculate percentage, multiply by 100, and add %
percentage = (NUM / DEN).map(lambda x: f"{int(100*x):d}%")
# reset the index
percentage = percntage.reset_index(name="percentage")
return percentage
bucket_test_scores(df)Du hast das perfekte Ergebnis mit einem Eimertestergebnis und dem Prozentsatz.
Lerne im Kurs Datenmanipulation mit Pandas, wie man Daten bereinigt, Statistiken berechnet und Visualisierungen erstellt.
Das Konfidenzintervall ist ein Bereich von Schätzungen für einen unbekannten Parameter, von dem du erwartest, dass er in einen bestimmten Prozentsatz der Zeit fällt, wenn du das Experiment noch einmal durchführst oder die Grundgesamtheit in ähnlicher Weise neu beprobst.
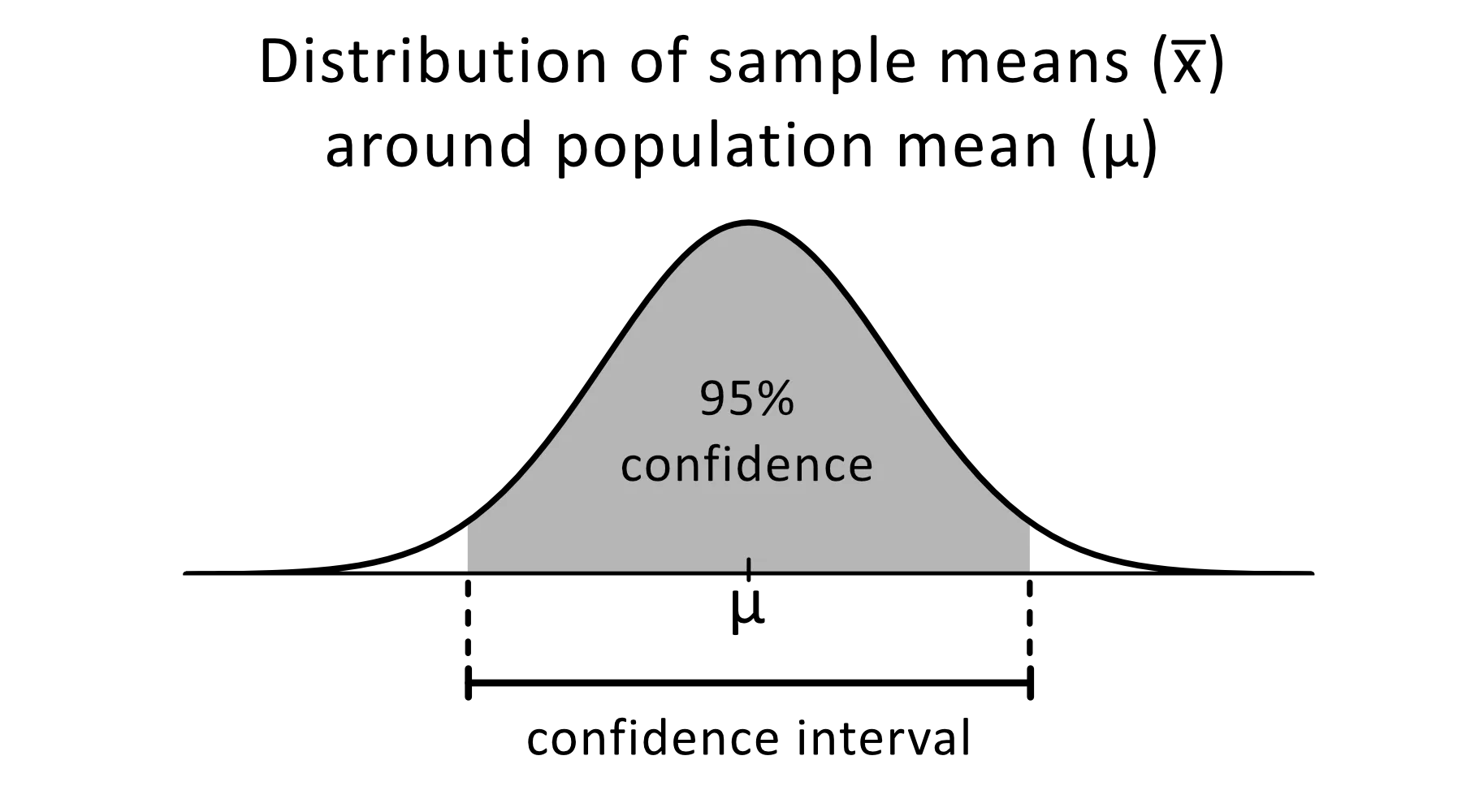
Bild von omnicalculator
Das Konfidenzniveau von 95 % wird häufig in statistischen Experimenten verwendet und gibt an, in wie viel Prozent der Fälle du erwartest, einen geschätzten Parameter zu reproduzieren. Die Konfidenzintervalle haben eine obere und untere Grenze, die durch den Alpha-Wert festgelegt wird.
Du kannst Konfidenzintervalle für verschiedene statistische Schätzungen verwenden, z. B. für Proportionen, Mittelwerte der Bevölkerung, Unterschiede zwischen Mittelwerten oder Proportionen der Bevölkerung und Schätzungen der Variation zwischen Gruppen.
Baue die Grundlagen der Statistik auf, indem du unseren Kurs Statistisches Denken in Python (Teil 1) absolvierst.
Im unausgewogenen Datensatz sind die Klassen ungleich verteilt. Im Datensatz zur Betrugserkennung gibt es zum Beispiel nur 400 Betrugsfälle im Vergleich zu 300.000 Nicht-Betrugsfällen. Die unausgewogenen Daten führen dazu, dass das Modell bei der Aufdeckung von Betrug schlechter abschneidet.
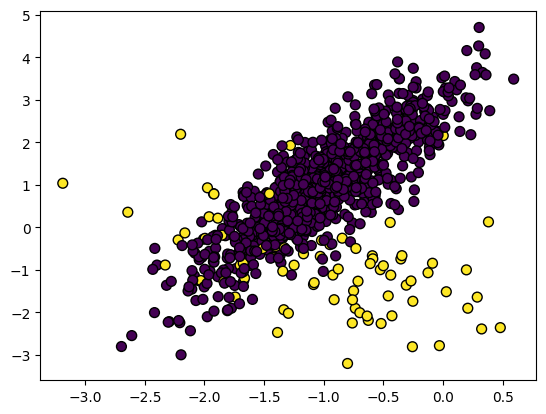
Bild vom Autor
Um mit unausgewogenen Daten umzugehen, kannst du verwenden:
Undersampling
Die Merkmale der Mehrheitsklasse werden neu gesampelt, damit sie den Merkmalen der Minderheitsklasse entsprechen.
Im Datensatz zur Aufdeckung von Betrug sind beide Klassen gleich groß, d.h. 400 Stichproben. Mit imblearn.under_sampling kannst du deinen Datensatz ganz einfach resampeln.
from imblearn.under_sampling import RandomUnderSampler
RUS = RandomUnderSampler(random_state=1)
X_US, y_US = RUS.fit_resample(X_train, y_train)Oversampling
Die Merkmale der Minderheitsklasse werden neu gesampelt, damit sie den Merkmalen der Mehrheitsklasse entsprechen. Die Wiederholung oder die gewichtete Wiederholung der Merkmale der Minderheitenklasse sind einige der üblichen Methoden, um die Daten auszugleichen. Kurz gesagt, beide Klassen werden 300K Proben haben.
from imblearn.over_sampling import RandomOverSampler
ROS = RandomOverSampler(random_state=0)
X_OS, y_OS = ROS.fit_resample(X_train, y_train)Synthetische Daten erstellen
Das Problem bei Wiederholungen ist, dass sie keine zusätzlichen Informationen liefern, was zu einer schlechten Leistung der Modelle führt. Um dem entgegenzuwirken, können wir SMOTE (Synthetic Minority Oversampling technique) verwenden, um synthetische Datenpunkte zu erstellen.
from imblearn.over_sampling import SMOTE
SM = SMOTE(random_state=1)
X_OS, y_OS = SM.fit_resample(X_train, y_train)Kombination aus Unter- und Überbeprobung
Um die Modellverzerrungen und die Leistung zu verbessern, kannst du eine Kombination aus Over- und Under-Sampling verwenden. Wir werden SMOTE für das Over-Sampling und EEN (Edited Nearest Neighbours) für die Bereinigung verwenden.
Die imblearn.combine stellt uns verschiedene Funktionen zur Verfügung, die automatisch beide Stichprobenfunktionen ausführen.
from imblearn.combine import SMOTEENN
SMTN = SMOTEENN(random_state=0)
X_OUS, y_OUS = SMTN.fit_resample(X_train, y_train)Als Data Scientist wirst du eine ähnliche Art von Abfrage schreiben, um die Daten zu extrahieren und eine Datenanalyse durchzuführen. In dieser Aufgabe verwendest du entweder die WHERE Klausel mit Vergleichszeichen oder WHERE mit BETWEEN Klausel, um eine Filterung durchzuführen.
Tabelle: Bestellungen
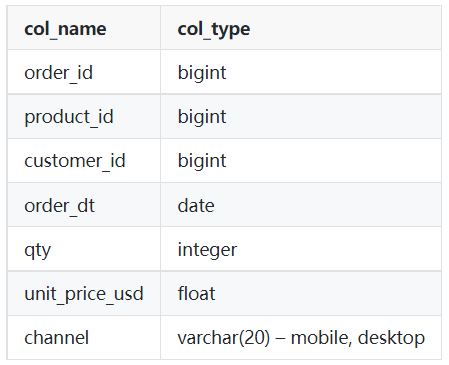
Bild vom Autor
Beispielhafte Ausgabe:
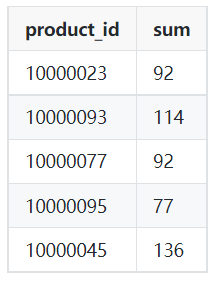
Bild vom Autor
SELECT product_id,
SUM(qty)
FROM orders
WHERE order_dt >= '2022-03-01'
AND order_dt < '2022-04-01'
GROUP BY product_id;Beim unüberwachten Lernen kann es schwierig sein, die Leistung des Clustering-Projekts zu ermitteln. Das Kriterium für ein gutes Clustering sind unterschiedliche Gruppen mit wenig Ähnlichkeit.
Da es bei Clustermodellen keine Genauigkeitsmetrik gibt, verwenden wir entweder die Ähnlichkeit oder die Unterscheidbarkeit der Gruppen, um die Leistung des Modells zu bewerten.
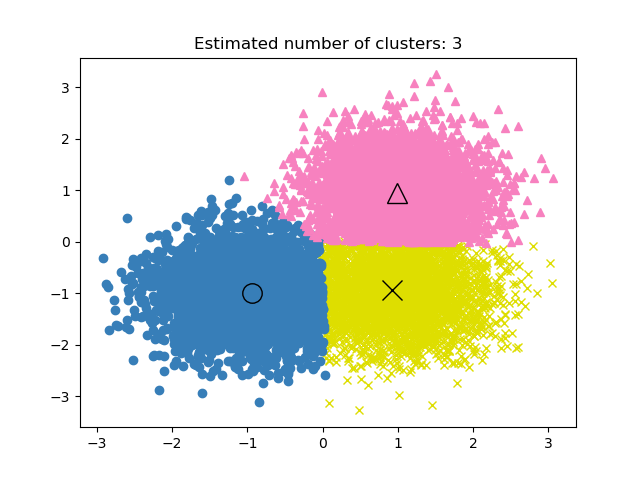
Bild aus der scikit-learn Dokumentation
Die drei am häufigsten verwendeten Kennzahlen sind:
Silhouette Score
Sie wird anhand des mittleren Intra-Cluster-Abstands und des mittleren Nearest-Cluster-Abstands berechnet.
Wir können Scikit-Learn verwenden, um die Metrik zu berechnen. Der Silhouette Score liegt zwischen -1 und 1, wobei höhere Werte eine geringere Ähnlichkeit zwischen Gruppen und unterschiedlichen Clustern bedeuten.
from sklearn import metrics
model = KMeans().fit(X)
labels = model.labels_
metrics.silhouette_score(X, labels)Calinski-Harabaz Index
Sie berechnet die Unterscheidbarkeit zwischen Gruppen anhand der Streuung zwischen den Clustern und der Streuung innerhalb der Cluster. Die Kennzahl hat keine Begrenzung und genau wie der Silhouette Score bedeutet eine höhere Punktzahl eine bessere Modellleistung.
metrics.calinski_harabasz_score(X, labels)Davies-Bouldin Index
Sie berechnet die durchschnittliche Ähnlichkeit jedes Clusters mit seinem ähnlichsten Cluster. Im Gegensatz zu anderen Metriken bedeutet eine niedrigere Punktzahl eine bessere Modellleistung und eine bessere Trennung zwischen den Clustern.
metrics.davies_bouldin_score(X, labels)
In unserem Kurs " Clusteranalyse in R" lernst du, wie du hierarchisches und k-means Clustering anwenden kannst.

Bild vom Autor
Wir werden sie benutzen:
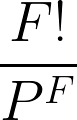
Um dieses Problem zu lösen, müssen wir zuerst die Gesamtzahl der Wege finden, um von den Böden herunterzukommen: 44 = 4x4x4x4 = 256 Möglichkeiten.
Berechne dann die Anzahl der Möglichkeiten, wie jede Person in einer anderen Etage aussteigen kann: 4! = 24.
Um die Wahrscheinlichkeit zu berechnen, dass jede Person in einer anderen Etage aussteigt, müssen wir die Anzahl der Möglichkeiten, wie jede Person in einer anderen Etage aussteigt, durch die Gesamtzahl der Möglichkeiten, die Etagen zu verlassen, teilen.
24/256 = 3/32
Lerne Strategien, um knifflige Wahrscheinlichkeitsfragen mit R zu beantworten, indem du unseren Kurs "Wahrscheinlichkeitsrätsel in R " belegst.
Um N Stichproben aus der Normalverteilung zu erzeugen, kannst du entweder Numpy (np.random.randn(N)) oder SciPy (sp.stats.norm.rvs(size=N)) verwenden.
Um ein Histogramm zu erstellen, kannst du entweder Matplotlib oder Seaborn verwenden.
Die Frage ist ganz einfach, wenn du die richtigen Werkzeuge kennst.
import numpy as np
import seaborn as sns
N = 10_000
def norm_dist_hist(N):
# Generating Random normal distribution samples
x = np.random.randn(N)
# Plotting histogram
sns.histplot(x, bins = 20, kde=True);
return x
X = norm_dist_hist(N)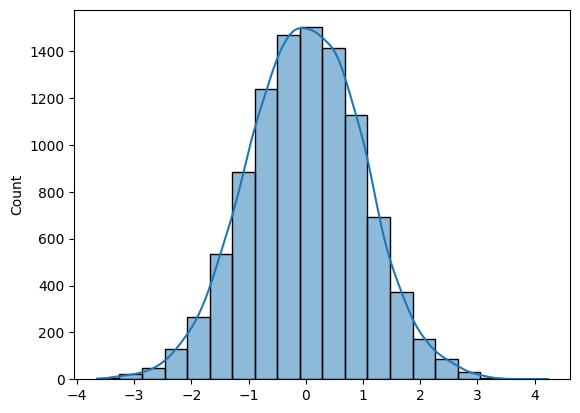
Lerne im Kurs Einführung in die Datenvisualisierung mit Seaborn, wie du in Sekundenschnelle informative und attraktive Visualisierungen erstellst.
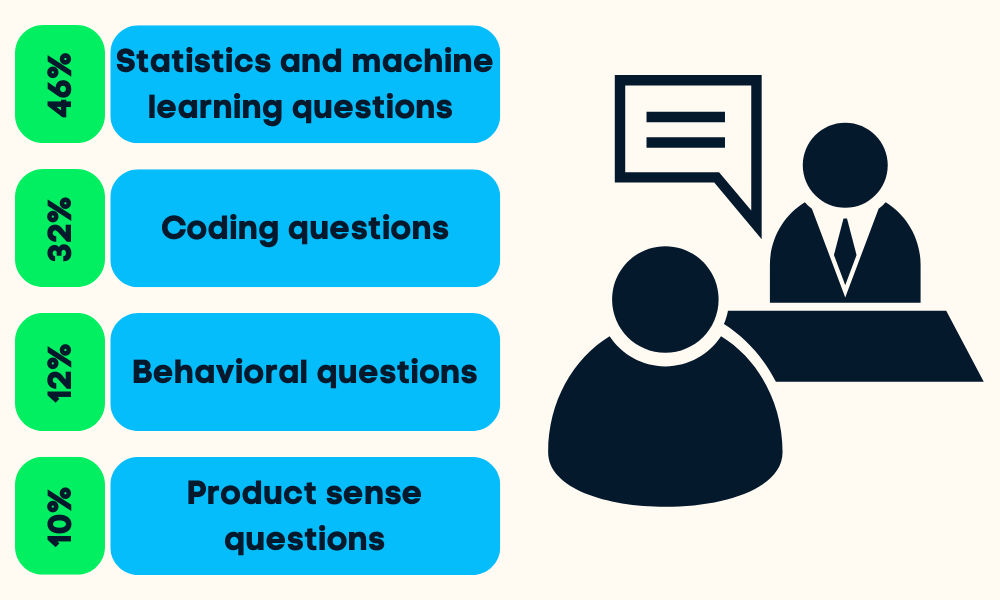
Bild vom Autor
Die Data Science Interviews sind in vier bis fünf Phasen unterteilt. Du wirst zu statistischem und maschinellem Lernen, Coding (Python, R, SQL), Verhalten, Produktverständnis und manchmal auch zu Führungsfragen befragt.
Du kannst dich auf alle Phasen vorbereiten, indem du:
Lies den Blog zur Vorbereitung auf das Data Science Interview, um zu erfahren, was dich erwartet und wie du das Interview angehst.
Datenwissenschaft Kurse
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
