Cours
Python intermédiaire
4 h
1.4M

Commençons par examiner quelques-unes des questions générales sur les compétences auxquelles vous pourriez être confronté lors de votre entretien. Voici quelques-unes des compétences non techniques dont vous aurez besoin en tant que scientifique des données :
Cette question évalue vos compétences en matière de communication et votre capacité à simplifier des sujets complexes. Voici un exemple de réponse :
Dans mes fonctions précédentes, je devais expliquer le concept d'apprentissage automatique à notre équipe de marketing. J'ai utilisé l'analogie d'apprendre à un enfant à reconnaître les différents types de fruits. Tout comme vous montrez à un enfant de nombreux exemples pour l'aider à apprendre, un modèle d'apprentissage automatique est formé à partir de données. Cette analogie a permis de rendre un concept complexe plus compréhensible et plus facile à comprendre.
Cela permet d'explorer vos compétences en matière de collaboration au sein d'une équipe et de résolution des conflits. Vous pourriez répondre à cette question par quelque chose comme :
Dans le cadre d'un projet, j'ai travaillé avec un collègue qui avait un style de travail très différent. Pour résoudre nos différends, j'ai organisé une réunion afin de comprendre son point de vue. Nous avons trouvé un terrain d'entente sur les objectifs de nos projets et avons convenu d'une approche commune. Cette expérience m'a appris la valeur d'une communication ouverte et de l'empathie dans le travail d'équipe.
Cette question porte sur la gestion du temps et l'établissement de priorités. Voici un exemple de réponse :
Une fois, j'ai dû livrer une analyse dans un délai très court. J'ai donné la priorité aux parties les plus critiques du projet, j'ai communiqué mon plan à l'équipe et je me suis concentré sur une exécution efficace. En décomposant la tâche et en fixant des mini-délais, j'ai réussi à terminer le projet dans les temps sans compromettre la qualité.
L'examinateur s'intéresse ici à votre capacité à assumer vos erreurs et à en tirer les leçons. Vous pourriez répondre par :
Dans un cas, j'ai mal interprété les résultats d'un modèle de données. Lorsque j'ai réalisé mon erreur, j'ai immédiatement informé mon équipe et réanalysé les données. Cette expérience m'a appris l'importance de la double vérification des résultats et la valeur de la transparence sur le lieu de travail.
Vous démontrez ainsi votre volonté d'apprendre en permanence et de rester pertinent dans votre domaine. Voici un exemple de réponse :
Je me tiens au courant en lisant des revues spécialisées, en assistant à des séminaires en ligne et en participant à des forums en ligne. Je réserve également du temps chaque semaine pour expérimenter de nouveaux outils et de nouvelles techniques. Cela me permet non seulement de rester à jour, mais aussi d'améliorer continuellement mes compétences.
Cette question évalue les capacités d'adaptation et de résolution de problèmes. A titre d'exemple, vous pouvez dire :
Lors d'un précédent projet, les exigences changeaient fréquemment. Je me suis adapté en maintenant une communication ouverte avec les parties prenantes afin de comprendre leurs besoins. J'ai également utilisé des méthodologies agiles pour être plus flexible dans mon approche, ce qui m'a permis de m'adapter efficacement aux changements.
Cela permet d'évaluer votre capacité à prendre en compte différents aspects au-delà des seules données. Voici un exemple de réponse :
Dans mes dernières fonctions, je devais trouver un équilibre entre la nécessité de prendre des décisions fondées sur des données et les considérations éthiques. J'ai veillé à ce que l'utilisation des données soit conforme aux normes éthiques et aux lois sur la protection de la vie privée, et j'ai présenté des alternatives si nécessaire. Cette approche a permis de prendre des décisions éclairées tout en respectant les limites éthiques.
Les quatre hypothèses d'une régression linéaire sont les suivantes :
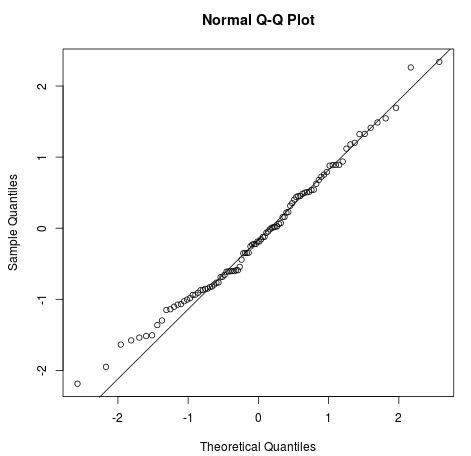
Image de Statology
Vous pouvez explorer les concepts et les applications des modèles linéaires en suivant notre cours Introduction à la modélisation linéaire en Python.
Il existe plusieurs façons de traiter les données manquantes. Vous pouvez le faire :
Apprenez à diagnostiquer, visualiser et traiter les données manquantes en suivant le cours Handling Missing Data with Imputations in R.
Tout d'abord, vous devez en savoir plus sur les antécédents de la partie prenante et utiliser ces informations pour modifier votre formulation. S'il a une formation en finance, apprenez les termes couramment utilisés en finance et utilisez-les pour expliquer la méthodologie complexe.
Deuxièmement, vous devez utiliser beaucoup de visuels et de graphiques. Les gens sont des apprenants visuels, et ils apprennent beaucoup mieux en utilisant des outils de communication créatifs.
Image par l'auteur
Troisièmement, parlez en termes de résultats. N'essayez pas d'expliquer les méthodologies ou les statistiques. Essayez de vous concentrer sur la manière dont ils peuvent utiliser les informations de l'analyse pour améliorer l'entreprise ou le flux de travail.
Enfin, encouragez-les à vous poser des questions. Les gens ont peur ou sont même gênés de poser des questions sur des sujets inconnus. Créez un canal de communication à double sens en les faisant participer à la discussion.
Apprenez à créer vos propres rapports et tableaux de bord SQL en suivant notre cours Reporting in SQL.
Il existe trois méthodes principales pour la sélection des caractéristiques : le filtre, l'enveloppe et les méthodes intégrées.
Méthodes de filtrage
Les méthodes de filtrage sont généralement utilisées dans les étapes de prétraitement. Ces méthodes sélectionnent des caractéristiques à partir d'un ensemble de données indépendamment de tout algorithme d'apprentissage automatique. Ils sont rapides, nécessitent moins de ressources et suppriment les fonctions dupliquées, corrélées et redondantes.

Image par l'auteur
Voici quelques techniques utilisées :
Méthodes d'enrobage
Dans les méthodes de type "wrapper", nous formons le modèle de manière itérative à l'aide d'un sous-ensemble de caractéristiques. En fonction des résultats du modèle formé, d'autres caractéristiques sont ajoutées ou supprimées. Elles sont plus coûteuses en termes de calcul que les méthodes de filtrage, mais offrent une meilleure précision du modèle.
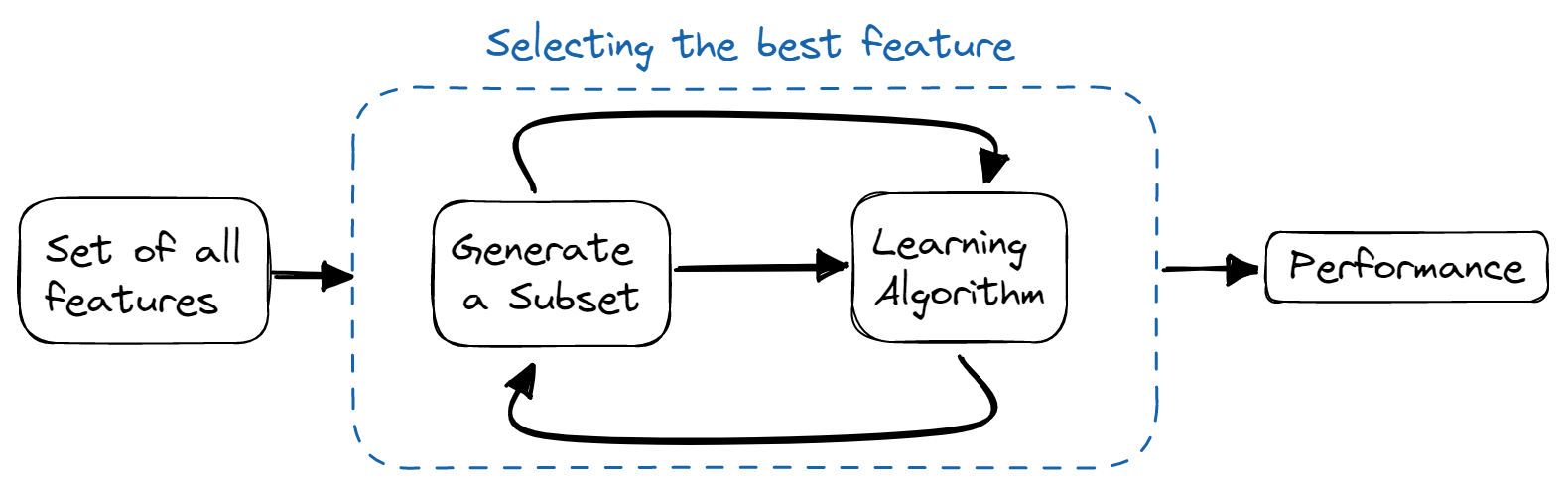
Image par l'auteur
Voici quelques techniques utilisées :
Méthodes intégrées
Les méthodes intégrées combinent les qualités des méthodes de filtrage et d'enveloppement. L'algorithme de sélection des caractéristiques est intégré à l'algorithme d'apprentissage, ce qui permet au modèle de disposer d'une méthode de sélection des caractéristiques intégrée. Ces méthodes sont plus rapides, comme les méthodes de filtrage, plus précises, comme les méthodes d'enveloppement, et prennent également en considération une combinaison de caractéristiques.
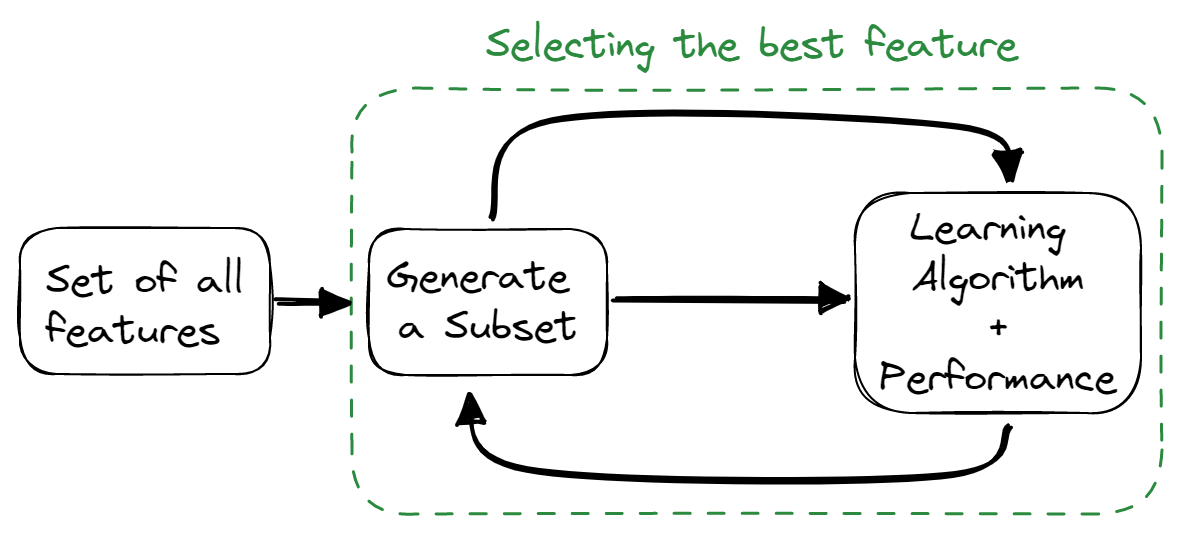
Image par l'auteur
Voici quelques techniques utilisées :
Le surajustement fait référence à un modèle qui est trop bien formé sur un ensemble de données d'apprentissage mais qui échoue sur les ensembles de données de test et de validation.
Vous pouvez éviter l'ajustement excessif en
Il existe quatre types principaux de relations SQL :
Apprenez à explorer les tables, les relations entre elles et les données qui y sont stockées en suivant notre cours sur l 'analyse exploratoire des données en SQL.
La réduction de la dimensionnalité est un processus qui convertit l'ensemble de données de plusieurs dimensions en moins de dimensions tout en conservant des informations similaires.
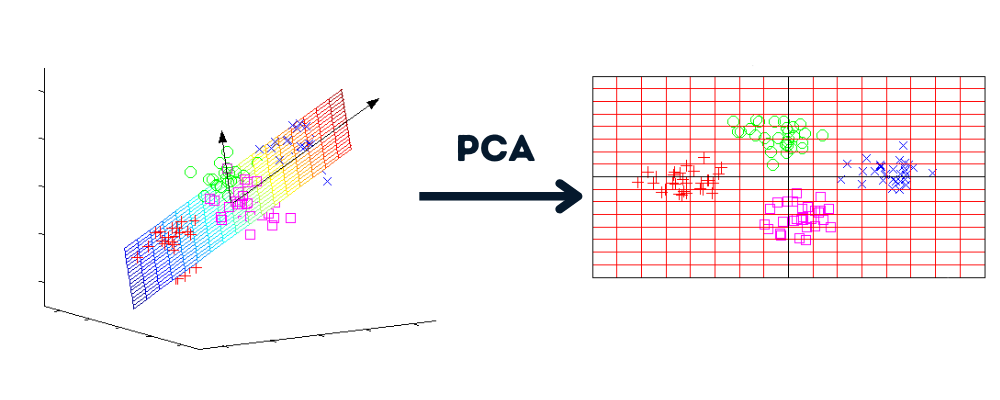
Image par l'auteur | Graphiques par howecoresearch
Avantages de la réduction de la dimensionnalité :
Comprenez le concept de réduction de la dimensionnalité et maîtrisez les techniques en vous exerçant grâce au cours Réduction de la dimensionnalité en Python.

Image par l'auteur
Les tests A/B éliminent les conjectures et nous aident à prendre des décisions fondées sur des données afin d'optimiser le produit ou le site web. Il s'agit d'expériences randomisées visant à analyser deux ou plusieurs versions de variables (page web, fonctionnalité d'application, etc.) et à déterminer quelle version génère le plus de trafic et de mesures commerciales.
Apprenez à créer, exécuter et analyser des tests A/B en suivant notre cours Customer Analytics and A/B Testing in Python.
Le stemming est couramment utilisé dans l'analyse de textes et de sentiments. Dans cette question, vous écrirez une fonction Python qui convertira certains mots de la liste en leur forme racine - Interview Query.
Entrée:
La fonction prend deux arguments : la liste des mots racines et la phrase.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"Sortie:
Vous obtiendrez la phrase avec les mots racines.
"the cat was rat by the bat"Avant de vous lancer dans l'écriture du code, vous devez comprendre que nous allons effectuer deux tâches : vérifier si le mot a une racine et la remplacer.
roots = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"
def replace_words(roots, sentence):
words = sentence.split(" ")
# looping over each word
for index, word in enumerate(words):
# looping over each root
for root in roots:
# checking if words start with root
if word.startswith(root):
# replacing the word with its root
words[index] = root
return " ".join(words)
replace_words(roots, sentence)
# 'the cat was rat by the bat'Étant donné la chaîne text, retournez True si c'est un palindrome, sinon False.
Après avoir abaissé toutes les lettres et supprimé tous les caractères non alphanumériques, le mot doit se lire de la même manière à l'endroit et à l'envers.

Image par l'auteur
Python permet de résoudre facilement ce problème. Vous pouvez soit traiter la chaîne comme un itérable et l'inverser à l'aide de text[::-1], soit utiliser la méthode intégrée reversed(text).
[::-1].import re
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing and comparing the string
return text == text[::-1]Dans la deuxième méthode, vous remplacerez simplement l'inversion du texte par ''.join(reversed(text)) et vous le comparerez au texte nettoyé.
Les deux méthodes sont simples.
def is_palindrome(text):
# lowering the string
text = text.lower()
# Cleaning the string
rx = re.compile('\W+')
text = rx.sub('',text).strip()
# Reversing the string
rev = ''.join(reversed(text))
return text == revRésultats:
Nous fournirons la liste des mots à la fonction is_palindrome() et imprimerons les résultats. Comme vous pouvez le constater, même avec les caractères spéciaux, la fonction a identifié "Level" et "Radar" comme des palindromes.
# Test cases
List = ['Anna', '**Radar****','Abid','(Level)', 'Data']
for text in List:
print(f"Is {text} a palindrome? {is_palindrome(text)}")
# Is Anna a palindrome? True
# Is **Radar**** a palindrome? True
# Is Abid a palindrome? False
# Is (Level) a palindrome? True
# Is Data a palindrome? FalsePréparez-vous à vos prochains entretiens de codage en pratiquant les questions d'entretien de codage en Python avec notre cours interactif.
Il est facile de trouver la valeur la plus élevée et la plus basse, mais il est difficile de trouver la deuxième valeur la plus élevée ou la nième valeur la plus élevée.
Dans la question, on vous fournit la table de la base de données qui se compose de id et base_salary. Vous écrirez la requête SQL pour trouver le deuxième salaire le plus élevé.
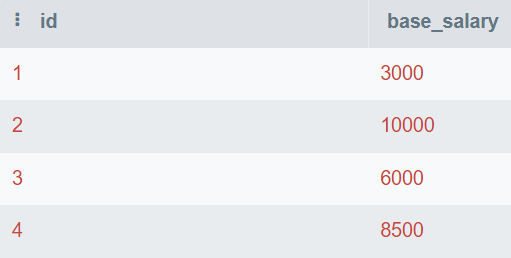
Image par l'auteur
Dans cette requête, vous trouverez les valeurs uniques et les classerez de la plus élevée à la plus basse. Ensuite, vous utiliserez LIMIT 1 pour n'afficher que la valeur la plus élevée. Au final, vous décalez la valeur de 1 pour afficher le deuxième chiffre le plus élevé.
Vous pouvez également modifier la valeur OFFSET pour obtenir le nième salaire le plus élevé.
SELECT DISTINCT base_salary AS "Second Highest Salary"
FROM employee
ORDER BY base_salary DESC
LIMIT 1
OFFSET 1;Le deuxième salaire de base le plus élevé est de 8 500.

Dans cette question, vous écrirez une requête pour afficher tous les courriels dupliqués.

Image par l'auteur
Dans cette requête, vous allez afficher une colonne email et grouper la table par email. Ensuite, nous utiliserons la clause HAVING pour trouver les courriels qui sont mentionnés plus d'une fois.
HAVING est utilisé en remplacement de l'instruction WHERE en liaison avec les agrégations.
SELECT email
FROM employee_email
GROUP BY email
HAVING COUNT(email) > 1;Seul "matt@hotmail.com" apparaît plus d'une fois.
Ecrivez un code SQL facile à maintenir pour répondre à des questions professionnelles en suivant le cours Applying SQL to Real-World Problems (Application du langage SQL à des problèmes réels).
Image par l'auteur
Le poste d'il y a un mois est passé de 3 % à 2,5 % aujourd'hui. Avant de tirer des conclusions hâtives, vous devez clarifier le contexte du problème.
Vous devez poser des questions :
Dans la deuxième partie, vous devez expliquer les raisons de cette diminution. Le nombre d'utilisateurs a-t-il augmenté ou le nombre de messages a-t-il diminué ? Ensuite, l'enquêteur vous demandera d'entamer une discussion en utilisant l'un ou les deux raisonnements.
En ce qui concerne la répartition du temps passé par jour sur Facebook, on peut supposer qu'il existe deux groupes :
Pour la deuxième partie, vous devez utiliser un vocabulaire statistique pour décrire la distribution, comme par exemple :
Dans cette question, vous écrirez un code pandas qui divisera d'abord le score en plusieurs tranches et calculera ensuite le pourcentage d'étudiants ayant obtenu le score dans ces tranches.
Entrée:
Notre ensemble de données comprend les colonnes user_id, grade et test_score.
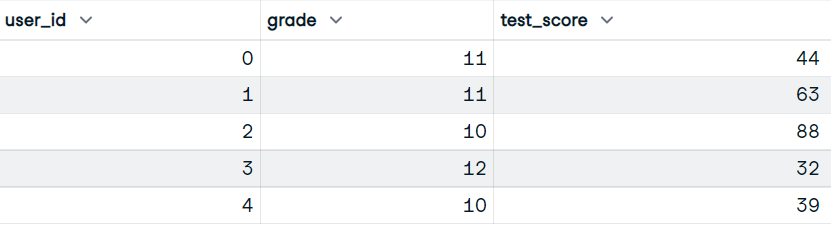
Image par l'auteur
Sortie:
Vous écrirez la fonction qui utilisera les colonnes grade et test_score. Et affichez l'image de données avec les notes, les scores et le pourcentage cumulé d'étudiants ayant obtenu des scores.
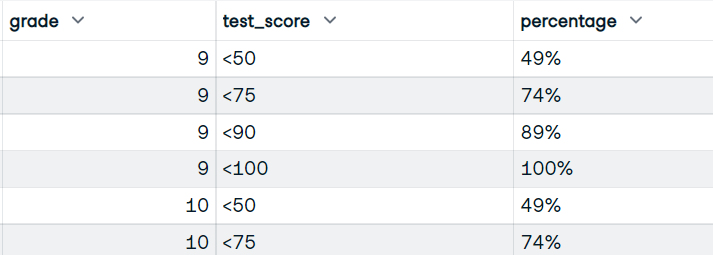
Image par l'auteur
pandas.cut() pour convertir les scores en scores de godets à l'aide de bacs et d'étiquettes de godets. def bucket_test_scores(df):
bins = [0, 50, 75, 90, 100]
labels = ["<50", "<75", "<90", "<100"]
# converting the scores into buckets
df["test_score"] = pd.cut(df["test_score"], bins, labels=labels, right=False)
# Calculate size of each group, by grade and test score
df = df.groupby(["grade", "test_score"]).size()
# Calculate numerator and denominator for percentage
NUM = df.groupby("grade").cumsum()
DEN = df.groupby("grade").sum()
# Calculate percentage, multiply by 100, and add %
percentage = (NUM / DEN).map(lambda x: f"{int(100*x):d}%")
# reset the index
percentage = percntage.reset_index(name="percentage")
return percentage
bucket_test_scores(df)Vous avez obtenu le résultat parfait avec une note au test du seau et le pourcentage.
Apprenez à nettoyer les données, à calculer des statistiques et à créer des visualisations avec le cours Manipulation de données avec pandas.
L'intervalle de confiance est une fourchette d'estimations d'un paramètre inconnu qui devrait se situer entre un certain pourcentage de temps lorsque vous refaites l'expérience ou que vous rééchantillonnez la population de la même manière.
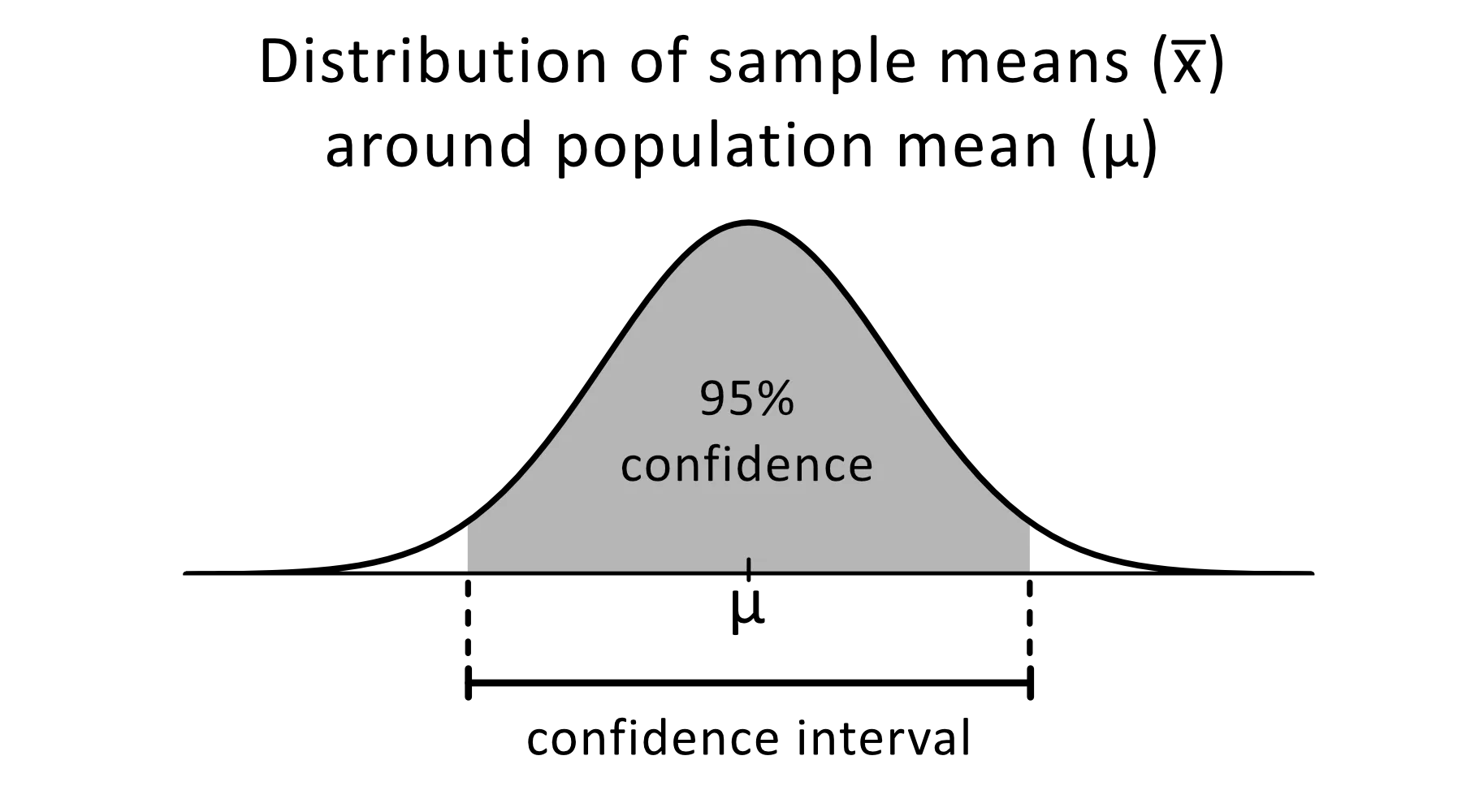
Image de omnicalculator
Le niveau de confiance de 95 % est couramment utilisé dans les expériences statistiques. Il s'agit du pourcentage de fois où vous vous attendez à ce qu'un paramètre estimé soit reproduit. Les intervalles de confiance ont une limite supérieure et une limite inférieure qui sont fixées par la valeur alpha.
Vous pouvez utiliser des intervalles de confiance pour diverses estimations statistiques, telles que les proportions, les moyennes de population, les différences entre les moyennes de population ou les proportions, et les estimations de la variation entre les groupes.
Construisez les bases de la statistique en complétant notre cours Pensée statistique en Python (Partie 1).
Dans l'ensemble de données déséquilibré, les classes sont réparties de manière inégale. Par exemple, dans l'ensemble de données sur la détection des fraudes, il n'y a que 400 cas de fraude contre 300 000 cas de non-fraude. Les données déséquilibrées rendront le modèle moins performant dans la détection de la fraude.
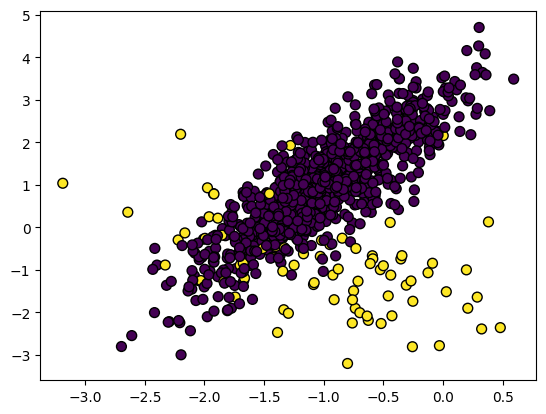
Image par l'auteur
Pour traiter les données déséquilibrées, vous pouvez utiliser :
Sous-échantillonnage
Il rééchantillonne les caractéristiques de la classe majoritaire pour les rendre égales à celles de la classe minoritaire.
Dans l'ensemble de données sur la détection des fraudes, les deux classes seront égales à 400 échantillons. Vous pouvez utiliser imblearn.under_sampling pour rééchantillonner facilement votre ensemble de données.
from imblearn.under_sampling import RandomUnderSampler
RUS = RandomUnderSampler(random_state=1)
X_US, y_US = RUS.fit_resample(X_train, y_train)Suréchantillonnage
Il rééchantillonne les caractéristiques de la classe minoritaire pour les rendre égales à celles de la classe majoritaire. La répétition ou la répétition pondérée des caractéristiques de la classe minoritaire sont quelques-unes des méthodes couramment utilisées pour équilibrer les données. En bref, les deux classes auront 300 000 échantillons.
from imblearn.over_sampling import RandomOverSampler
ROS = RandomOverSampler(random_state=0)
X_OS, y_OS = ROS.fit_resample(X_train, y_train)Créer des données synthétiques
Le problème de la répétition est qu'elle n'apporte pas d'informations supplémentaires, ce qui se traduira par une mauvaise performance des modèles. Pour y remédier, nous pouvons utiliser la technique SMOTE (Synthetic Minority Oversampling technique) pour créer des points de données synthétiques.
from imblearn.over_sampling import SMOTE
SM = SMOTE(random_state=1)
X_OS, y_OS = SM.fit_resample(X_train, y_train)Combinaison de sous-échantillonnage et de suréchantillonnage
Pour améliorer les biais et les performances du modèle, vous pouvez utiliser une combinaison de suréchantillonnage et de sous-échantillonnage. Nous utiliserons SMOTE pour le suréchantillonnage et EEN (Edited Nearest Neighbours) pour le nettoyage.
Le site imblearn.combine met à notre disposition diverses fonctions qui assurent automatiquement les deux fonctions d'échantillonnage.
from imblearn.combine import SMOTEENN
SMTN = SMOTEENN(random_state=0)
X_OUS, y_OUS = SMTN.fit_resample(X_train, y_train)En tant que data scientist, vous écrirez un type de requête similaire pour extraire les données et les analyser. Dans ce défi, vous utiliserez soit la clause WHERE avec des signes de comparaison, soit la clause WHERE avec BETWEEN pour effectuer un filtrage.
Tableau: commandes
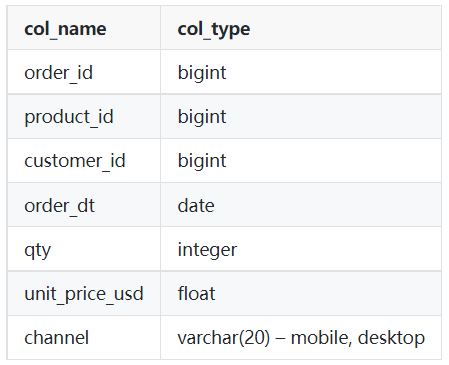
Image par l'auteur
Exemple de sortie:
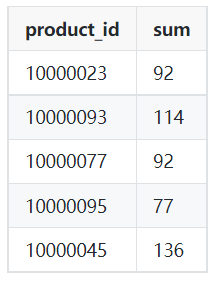
Image par l'auteur
SELECT product_id,
SUM(qty)
FROM orders
WHERE order_dt >= '2022-03-01'
AND order_dt < '2022-04-01'
GROUP BY product_id;Dans le cadre de l'apprentissage non supervisé, il peut être difficile de déterminer les performances du projet de regroupement. Les critères d'un bon regroupement sont des groupes distincts présentant peu de similitudes.
Il n'y a pas de mesure de précision dans les modèles de regroupement, nous utiliserons donc la similarité ou la distinction entre les groupes pour évaluer les performances du modèle.
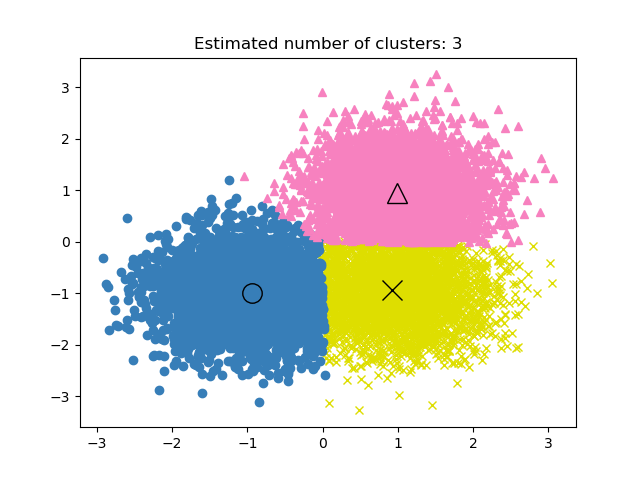
Image tirée de la documentation scikit-learn
Les trois mesures les plus couramment utilisées sont les suivantes :
Silhouette Score
Elle est calculée à partir de la distance moyenne intra-groupe et de la distance moyenne entre les groupes les plus proches.
Nous pouvons utiliser scikit-learn pour calculer la métrique. Le score de silhouette est compris entre -1 et 1, les scores les plus élevés signifiant une plus faible similarité entre les groupes et les grappes distinctes.
from sklearn import metrics
model = KMeans().fit(X)
labels = model.labels_
metrics.silhouette_score(X, labels)Calinski-Harabaz Index
Il calcule le caractère distinctif entre les groupes à l'aide de la dispersion entre les groupes et de la dispersion à l'intérieur des groupes. La mesure n'a pas de limite et, tout comme le score de Silhouette, un score plus élevé signifie une meilleure performance du modèle.
metrics.calinski_harabasz_score(X, labels)Davies-Bouldin Index
Il calcule la similarité moyenne de chaque grappe avec la grappe la plus similaire. Contrairement à d'autres mesures, un score plus faible signifie une meilleure performance du modèle et une meilleure séparation entre les grappes.
metrics.davies_bouldin_score(X, labels)
Apprenez à appliquer le clustering hiérarchique et k-means en suivant notre cours Cluster Analysis in R.

Image par l'auteur
Nous utiliserons:
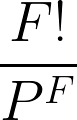
Pour résoudre ce problème, nous devons d'abord trouver le nombre total de façons de descendre des étages : 44 = 4x4x4x4 = 256 façons.
Ensuite, calculez le nombre de façons dont chaque personne peut descendre à un étage différent : 4! = 24.
Pour calculer la probabilité que chaque personne descende à un étage différent, nous devons diviser le nombre de façons dont chaque personne descend à un étage différent par le nombre total de façons de descendre des étages.
24/256 = 3/32
Apprenez des stratégies pour répondre à des questions délicates sur les probabilités avec R en suivant notre cours Probability Puzzles in R.
Pour générer N échantillons à partir de la distribution normale, vous pouvez utiliser Numpy (np.random.randn(N)) ou SciPy (sp.stats.norm.rvs(size=N)).
Pour tracer un histogramme, vous pouvez utiliser Matplotlib ou Seaborn.
La question est assez simple si vous connaissez les bons outils.
import numpy as np
import seaborn as sns
N = 10_000
def norm_dist_hist(N):
# Generating Random normal distribution samples
x = np.random.randn(N)
# Plotting histogram
sns.histplot(x, bins = 20, kde=True);
return x
X = norm_dist_hist(N)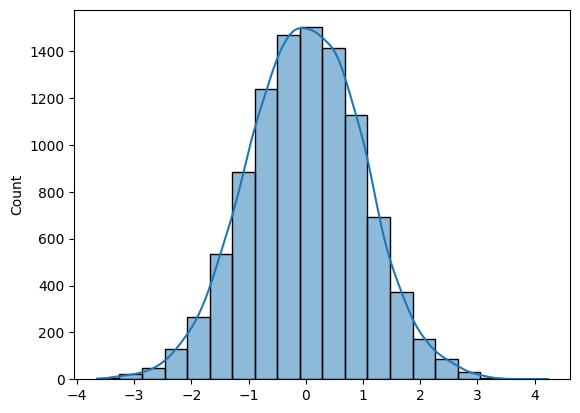
Apprenez à créer des visualisations informatives et attrayantes en quelques secondes en suivant le cours Introduction à la visualisation de données avec Seaborn.
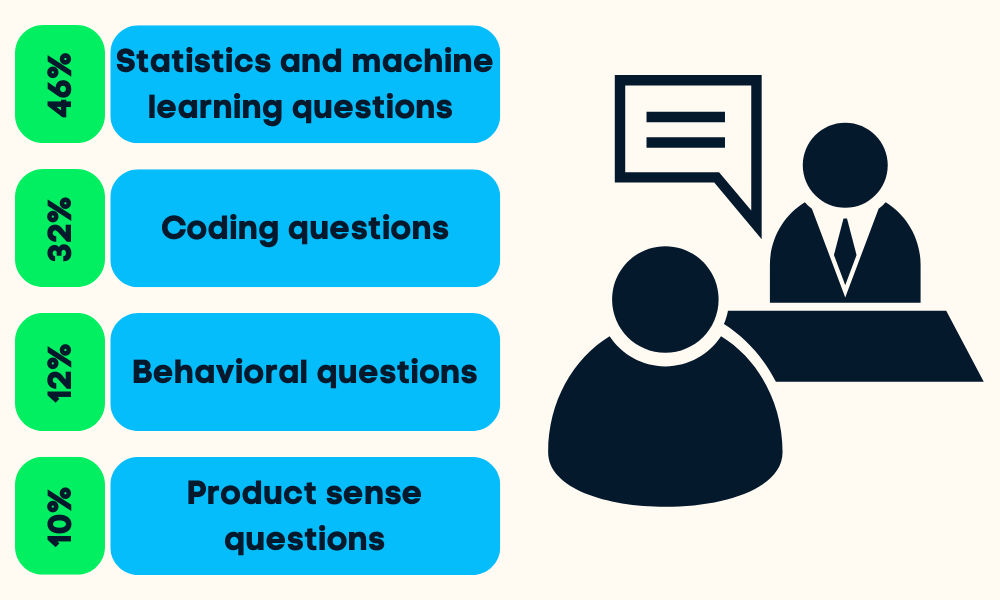
Image par l'auteur
Les entretiens sur la science des données sont divisés en quatre ou cinq étapes. On vous posera des questions sur les statistiques et l'apprentissage automatique, le codage (Python, R, SQL), le comportement, le sens du produit et parfois des questions sur le leadership.
Vous pouvez vous préparer à toutes les étapes en
Lisez le blog Préparation à l'entretien en science des données pour savoir à quoi vous attendre et comment aborder l'entretien.
Cours de science des données
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min