
Kurs
XGBoost ile Aşırı Gradyan Artırma
4 sa
61.1K
Python, özellikle veri bilimi ve makine öğrenmesi alanlarında, çeşitli teknoloji disiplinlerinde en popüler programlama dillerinden biridir. Python; çok sayıda kullanım durumu için geniş bir kütüphane koleksiyonuna sahip, nesne yönelimli, yüksek seviyeli ve kolay kodlanabilir bir dil sunar. 200.000’in üzerinde kütüphanesi vardır.
Python’ın veri bilimi için bu kadar değerli olmasının nedenlerinden biri, veri işleme, veri görselleştirme, makine öğrenmesi ve derin öğrenme kütüphanelerinin geniş yelpazesidir. Python’ın veri bilimi kütüphaneleri ekosistemi bu kadar zengin olduğundan, her şeyi tek bir yazıda kapsamaya çalışmak neredeyse imkânsızdır. Buradaki en iyi kütüphaneler listesi yalnızca beş ana alana odaklanır:
Bu listede yer verilmeyen başka pek çok alan vardır; örneğin MLOps, Büyük Veri ve Bilgisayarla Görü. Bu blogdaki liste belirli bir sırayı takip etmez ve herhangi bir şekilde bir sıralama olarak görülmesi amaçlanmamıştır.
NumPy, en yaygın kullanılan açık kaynaklı Python kütüphanelerinden biridir ve ağırlıklı olarak bilimsel hesaplama için kullanılır. Yerleşik matematiksel işlevleri sayesinde son derece hızlı hesaplama yapabilir; çok boyutlu verileri ve büyük matrisleri destekler. Doğrusal cebirde de kullanılır. NumPy Array’ler, daha az bellek kullanmaları ve daha kullanışlı ve verimli olmaları nedeniyle çoğu zaman listelere tercih edilir.
NumPy’nin web sitesine göre, Python ile sayısal hesaplamayı mümkün kılmayı amaçlayan bir açık kaynak projedir. 2005’te oluşturulmuştur ve Numeric ile Numarray kütüphanelerinin erken dönem çalışmalarının üzerine inşa edilmiştir. NumPy’nin büyük avantajlarından biri, değiştirilmiş BSD lisansı altında yayımlanmış olması ve bu sayede herkes için daima ücretsiz kalacak olmasıdır.
NumPy, GitHub üzerinde, NumPy ve geniş bilimsel Python topluluğunun mutabakatıyla açık şekilde geliştirilir. Hakkında daha fazla bilgiyi giriş niteliğindeki Numpy kursumuzda bulabilirsiniz.
⭐ GitHub Yıldızı: 25K | Toplam İndirme: 2,4 milyar
Pandas, veri biliminde yaygın olarak kullanılan açık kaynaklı bir kütüphanedir. Başlıca veri analizi, veri işleme ve veri temizleme için kullanılır. Pandas, çok fazla kod yazma ihtiyacı olmadan basit veri modelleme ve veri analizi işlemlerine olanak tanır. Web sitelerinde belirtildiği üzere, pandas hızlı, güçlü, esnek ve kullanımı kolay bir açık kaynak veri analizi ve işleme aracıdır. Bu kütüphanenin bazı temel özellikleri şunlardır:
pandas ile başlamak oldukça basit ve doğrudandır. Pandas’ı gerçek dünya veri kümelerinde nasıl kullanacağınızı öğrenmek için DataCamp’in Pandas ile Polis Faaliyetlerini Analiz Etme kursuna göz atabilirsiniz.
⭐ GitHub Yıldızı: 41K | Toplam İndirme: 1,6 milyar
Pandas küçük veride varsayılan tercih olmaya devam ederken, Polars yüksek performanslı veri işleme için standart hâline gelmiştir. Rust ile yazılmıştır; "tembel değerlendirme" motoru kullanarak normalde RAM kısıtlı makineleri çökertme eğilimindeki veri kümelerini (10GB–100GB+) işler. İşlemleri ardışık olarak yürüten Pandas’ın aksine Polars, sorguları uçtan uca optimize eder ve mevcut tüm CPU çekirdekleri arasında paralel olarak çalıştırır.
Ağır iş yükleri için tak-çalıştır bir yükseltme olacak şekilde tasarlanmıştır; çoğu zaman daha okunabilir bir sözdizimi sunar ve geleneksel DataFrame’lere göre 10–50 kat daha hızlıdır.
İşte dev bir CSV veri kümesinden filtrelenmiş, gruplanmış ve toplulaştırılmış bir seçimi yükleyen örnek bir kod:
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ GitHub Yıldızı: 40K+ | Durum: Yüksek Performans Standardı
Matplotlib, sabit, etkileşimli ve animasyonlu Python görselleştirmeleri oluşturmak için kapsamlı bir kütüphanedir. Çok sayıda üçüncü taraf paket, Matplotlib’in işlevselliğini genişletir ve üzerine inşa eder; bunlara çeşitli üst seviye çizim arayüzleri (Seaborn, HoloViews, ggplot vb.) dahildir.
Matplotlib, MATLAB kadar işlevsel olacak şekilde tasarlanmıştır; üstelik Python kullanmanın avantajını sunar. Ücretsiz ve açık kaynak olması da bir artıdır. Kullanıcının, saçılım grafikleri, histogramlar, çubuk grafikler, hata grafikleri ve kutu grafikleriyle sınırlı olmamak üzere çeşitli grafik türleriyle veriyi görselleştirmesine imkân tanır. Dahası, tüm görselleştirmeler sadece birkaç satır kodla uygulanabilir.
Matplotlib kullanılarak geliştirilen örnek grafikler
Bu adım adım öğreticiyle Matplotlib’e başlayın.
⭐ GitHub Yıldızı: 18,7K | Toplam İndirme: 653 milyon
Bir diğer popüler, Matplotlib tabanlı Python veri görselleştirme çerçevesi olan Seaborn, veriyi incelemek ve anlamak için kritik öneme sahip, estetik ve faydalı istatistiksel görseller oluşturmaya yönelik üst düzey bir arayüzdür. Bu Python kütüphanesi, hem NumPy hem de pandas veri yapılarıyla yakından bağlantılıdır. Seaborn’un itici ilkesi, görselleştirmeyi veri analizinin ve keşfin temel bir bileşeni hâline getirmektir; bu nedenle çizim algoritmaları, tüm veri kümelerini kapsayan veri çerçevelerini kullanır.
Seaborn Örnek Galerisi
Yeni başlayanlar için bu Seaborn öğreticisi, bu dinamik görselleştirme kütüphanesine aşina olmanıza yardımcı olacak harika bir kaynaktır.
⭐ GitHub Yıldızı: 11,6K | Toplam İndirme: 180 milyon
Son derece popüler açık kaynaklı grafik kütüphanesi Plotly, etkileşimli veri görselleştirmeleri oluşturmak için kullanılabilir. Plotly, Plotly JavaScript kütüphanesi (plotly.js) üzerine inşa edilmiştir ve HTML dosyaları olarak kaydedilebilen veya Jupyter notebook’larda ve Dash kullanan web uygulamalarında görüntülenebilen web tabanlı veri görselleştirmeleri oluşturmak için kullanılabilir.
Saçılım grafikleri, histogramlar, çizgi grafikler, çubuk grafikler, pasta grafikler, hata çubukları, kutu grafikleri, çoklu eksenler, kıvılcım çizgileri, dendrogramlar ve 3B grafikler gibi 40’tan fazla benzersiz grafik türü sunar. Plotly ayrıca, diğer veri görselleştirme kütüphanelerinde pek yaygın olmayan kontur grafikleri de sağlar.
Etkileşimli görselleştirmeler veya gösterge paneli benzeri grafikler istiyorsanız, Plotly Matplotlib ve Seaborn’a iyi bir alternatiftir. Şu anda MIT lisansı kapsamında kullanılabilir.
Bugün Plotly görselleştirme kursu ile Plotly’yi öğrenmeye başlayabilirsiniz.
⭐ GitHub Yıldızı: 14,7K | Toplam İndirme: 190 milyon
Makine öğrenmesi ve scikit-learn ayrılmaz bir ikilidir. Scikit-learn, Python’daki en çok kullanılan makine öğrenmesi kütüphanelerinden biridir. NumPy, SciPy ve Matplotlib üzerine inşa edilmiş olup BSD lisansı altında ticari kullanım için uygun bir açık kaynak Python kütüphanesidir. Öngörücü veri analizi görevleri için basit ve etkilidir.
İlk olarak 2007’de bir Google Summer of Code projesi olarak başlatılan scikit-learn, topluluk tarafından yürütülen bir projedir; ancak kurumsal ve özel hibeler sürdürülebilirliğini sağlamaya yardımcı olur.
scikit-learn’ün en iyi yanlarından biri, kullanımının çok kolay olmasıdır.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Kredi: Kod scikit-learn’ün resmi belgelerinden alınmıştır.
scikit-learn’e başlangıç öğreticisi ile kendiniz deneyebilirsiniz.
⭐ GitHub Yıldızı: 57K | Toplam İndirme: 703 milyon
Veri Bilimcilerin yalnızca statik PDF raporlar teslim ettiği günler geride kaldı. Streamlit, Python betiklerini dakikalar içinde etkileşimli, paylaşılabilir web uygulamalarına dönüştürür. HTML, CSS veya JavaScript bilgisi gerektirmez. 2025’te paydaşlar için dahili araçlar, gösterge paneli prototipleri ve etkileşimli model demoları geliştirmek için yaygın olarak kullanılır.
st.write() ve st.slider() gibi basit API çağrılarıyla, gerçek zamanlı veri değişimlerine tepki veren bir arayüz inşa ederek analiz ile mühendislik arasındaki boşluğu kapatabilirsiniz.
⭐ GitHub Yıldızı: 42K+ | Durum: Teslimat için Vazgeçilmez
Aslen bir web geliştirme aracı olan Pydantic artık yapay zeka yığınının temel taşlarından biridir. Python tür açıklamalarını kullanarak veri doğrulama ve ayar yönetimi yapar. LLM çağında, verinin (ve model çıktılarının) belirli bir şemayla kesin biçimde eşleşmesini sağlamak kritiktir.
Pydantic, LangChain ve Hugging Face gibi kütüphanelerin motorudur; AI modellerinden gelen dağınık JSON çıktılarının aşağı akış kodunuzu bozmayacak, yapılandırılmış ve geçerli Python nesnelerine dönüştürülmesini sağlar.
⭐ GitHub Yıldızı: 26K+ | Durum: Kritik Altyapı
LightGBM, ağaç tabanlı algoritmalar kullanan, son derece popüler bir açık kaynak gradyan arttırma kütüphanesidir. Şu avantajları sunar:
Hem denetimli sınıflandırma hem de regresyon görevleri için kullanılabilir. Bu harika çerçeve hakkında daha fazla bilgi edinmek için resmî belgelerine veya GitHub sayfalarına göz atabilirsiniz.
⭐ GitHub Yıldızı: 15,8K | Toplam İndirme: 162 milyon
XGBoost, taşınabilir, esnek ve verimli olacak şekilde oluşturulmuş, yaygın olarak kullanılan bir dağıtık gradyan arttırma kütüphanesidir. Gradyan arttırma çerçevesi içinde makine öğrenmesi algoritmalarının uygulanmasını sağlar. XGBoost, birçok veri bilimi problemine hızlı ve doğru çözümler sunan (GBDT) gradyanla güçlendirilmiş karar ağaçları ve paralel ağaç arttırma olanağı sağlar. Aynı kod, başlıca dağıtık ortamlarda (Hadoop, SGE, MPI) çalışır ve sayısız problemi çözebilir.
Son birkaç yılda, neredeyse tüm Kaggle yapılandırılmış veri yarışmalarının kazanılmasına yardımcı olması sayesinde XGBoost büyük bir popülerlik kazanmıştır. XGBoost’un avantajları şunlardır:
XGBoost, aktif topluluk üyeleri tarafından geliştirilmiş ve sürdürülmüştür; Apache lisansı kapsamında kullanım için lisanslanmıştır. Daha fazla bilgi edinmek isterseniz şu XGBoost öğreticisi harika bir kaynaktır.
⭐ GitHub Yıldızı: 25,2K | Toplam İndirme: 179 milyon
CatBoost, Python, R, Java ve C++ için sıralama, sınıflandırma, regresyon ve diğer makine öğrenmesi görevlerinde kullanılan, hızlı, ölçeklenebilir ve yüksek performanslı bir karar ağaçları üzerinde gradyan arttırma kütüphanesidir. CPU ve GPU üzerinde hesaplamayı destekler.
MatrixNet algoritmasının halefi olarak, sıralama görevleri, tahminleme ve öneriler için yaygın biçimde kullanılır. Evrensel karakteri sayesinde, çok geniş bir alanda ve çeşitli problemler için uygulanabilir.
Depolarına göre CatBoost’un avantajları şunlardır:
⭐ GitHub Yıldızı: 7,5K | Toplam İndirme: 53 milyon
Statsmodels, kullanıcıların çeşitli istatistiksel modelleri tahmin etmesine, istatistiksel testler yürütmesine ve istatistiksel veri keşfi yapmasına olanak tanıyan sınıflar ve işlevler sağlar. Ardından her tahminleyici için kapsamlı bir sonuç istatistikleri listesi sunulur. Sonuçların doğruluğu mevcut istatistik paketlerine karşı test edilebilir.
Kitaplıktaki çoğu test sonucu en az bir başka istatistik paketi (R, Stata veya SAS) ile doğrulanmıştır. statsmodels’ın bazı özellikleri şunlardır:
Daha fazlasını öğrenmek isterseniz, başlangıç statsmodels kursu mükemmel bir başlangıç noktasıdır.
⭐ GitHub Yıldızı: 9,2K | Toplam İndirme: 161 milyon
Açık kaynaklı RAPIDS yazılım kütüphaneleri paketi, uçtan uca veri bilimi ve analitik veri işlem hatlarını tamamen GPU’larda yürütür. Dask ile GPU iş istasyonlarından çok GPU’lu sunuculara ve çok düğümlü kümelere sorunsuz biçimde ölçeklenir. Proje NVIDIA tarafından desteklenir ve ayrıca Numba, Apache Arrow ve diğer birçok açık kaynak projeye dayanır.
cuDF, veri yüklemek, birleştirmek, toplulaştırmak, filtrelemek ve veriyi başka yollarla işlemek için kullanılan bir GPU DataFrame kütüphanesidir. Apache Arrow’daki sütun bazlı bellek formatına dayanarak geliştirilmiştir. Veri mühendisleri ve veri bilimcilere tanıdık gelecek pandas benzeri bir API sağlar; böylece CUDA programlamanın ayrıntılarına girmeden iş akışlarını kolayca hızlandırabilirler.
cuML, diğer RAPIDS projeleriyle uyumlu API’leri paylaşan makine öğrenmesi algoritmalarını ve matematiksel temel işlevleri uygulayan kütüphaneler paketidir. Veri bilimcilerin, araştırmacıların ve yazılım mühendislerinin geleneksel tablo tabanlı ML görevlerini CUDA programlama ayrıntılarına girmeden GPU’larda çalıştırmasına imkân tanır. cuML’nin Python API’si genellikle scikit-learn API’siyle uyumludur.
Bu açık kaynaklı hiperparametre optimizasyon çerçevesi, ağırlıklı olarak hiperparametre aramalarını otomatikleştirmek için kullanılır. Python döngüleri, koşulları ve sözdizimini kullanarak otomatik biçimde en iyi hiperparametreleri arar; geniş uzaylarda arama yapabilir ve vaat etmeyen denemeleri budayarak daha hızlı sonuç verir. En güzeli de, büyük veri kümelerinde paralelleştirmesi ve ölçeklendirmesi kolaydır.
GitHub depolarına göre temel özellikleri:
⭐ GitHub Yıldızı: 9,1K | Toplam İndirme: 18 milyon
Bu son derece popüler, açık kaynak makine öğrenmesi kütüphanesi, çok az kodla Python’da makine öğrenmesi iş akışlarını otomatikleştirir. Deney döngüsünü dramatik biçimde hızlandırabilen uçtan uca bir model yönetimi ve makine öğrenmesi aracıdır.
Diğer açık kaynak makine öğrenmesi kütüphaneleriyle karşılaştırıldığında PyCaret, yüzlerce satır kodu yalnızca birkaç satırla değiştirebilen düşük kodlu bir çözüm sunar. Bu da deneyleri katbekat hızlı ve verimli hâle getirir.
PyCaret şu anda MIT lisansı kapsamında kullanılabilir. Daha fazla bilgi için resmî belgelerine veya GitHub deposuna göz atabilir ya da giriş niteliğindeki PyCaret öğreticisini inceleyebilirsiniz.
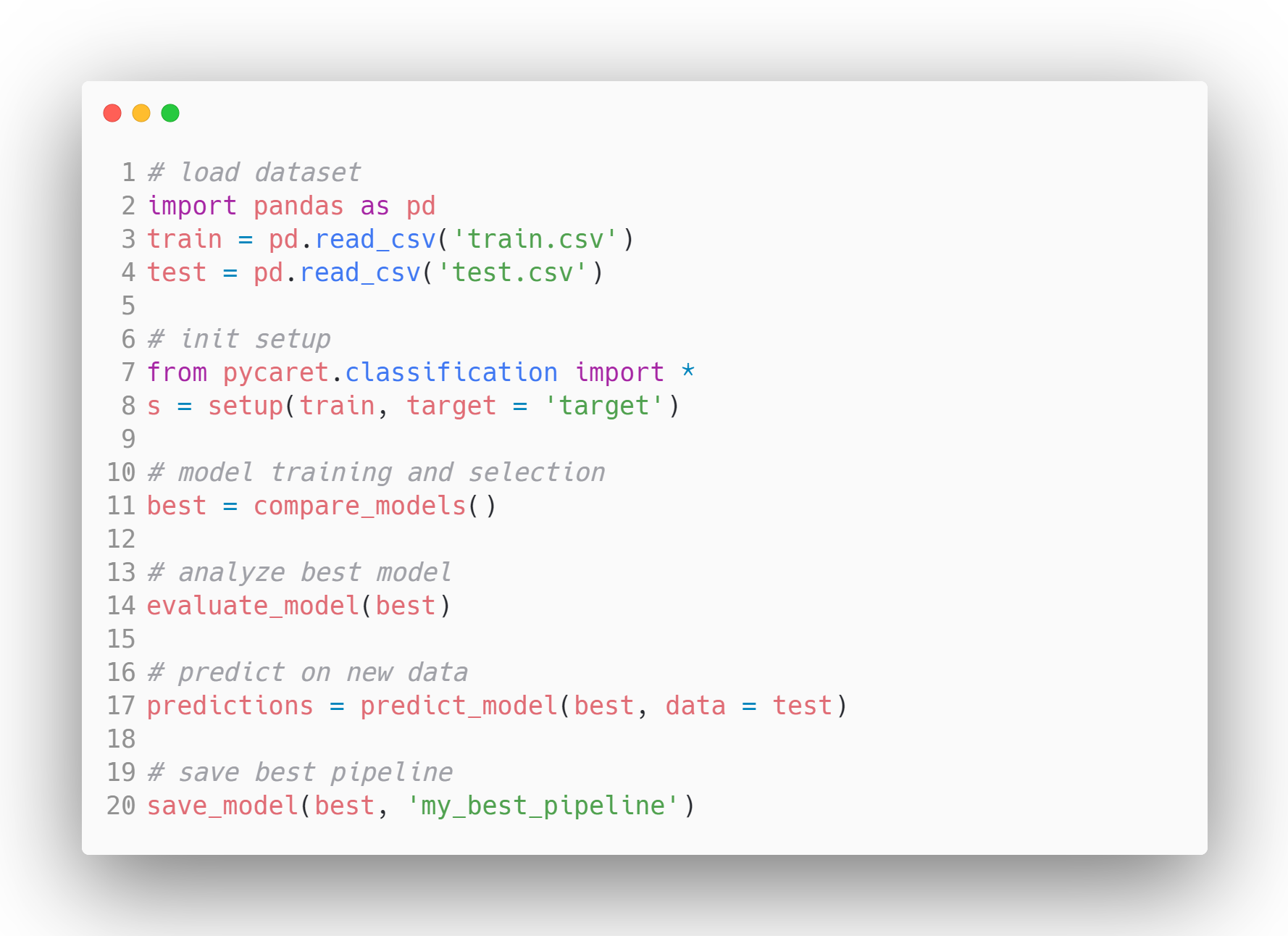
PyCaret’te Örnek Model İş Akışı - Kaynak
⭐ GitHub Yıldızı: 8,1K | Toplam İndirme: 3,9 milyon
H2O, büyük veri üzerinde makine öğrenmesi modellerinin oluşturulmasını sağlayan bir makine öğrenmesi ve öngörücü analitik platformudur. Ayrıca bu modellerin kurumsal ortamda kolayca üretime alınmasını sağlar.
H2O’nun çekirdek kodu Java ile yazılmıştır. Algoritmalar çoklu iş parçacığı için Java Fork/Join çerçevesini kullanır ve H2O’nun dağıtık Map/Reduce çerçevesi üzerinde uygulanır.
H2O, Apache Lisansı Sürüm 2.0 kapsamında lisanslanmıştır; Python, R ve Java dilleri için kullanılabilir. H2O AutoML hakkında daha fazla bilgi için resmî belgelerine bakın.
⭐ GitHub Yıldızı: 10,6K | Toplam İndirme: 15,1 milyon
Auto-sklearn, otomatik bir makine öğrenmesi araç takımıdır ve bir scikit-learn modeline uygun bir ikamedir. Hiperparametre ayarlama ve algoritma seçimini otomatik olarak gerçekleştirerek makine öğrenmesi uygulayıcılarına ciddi zaman kazandırır. Tasarımı, meta-öğrenme, topluluk oluşturma ve Bayesçi optimizasyondaki son gelişmeleri yansıtır.
scikit-learn’e bir eklenti olarak inşa edilen auto-sklearn, belirli bir veri kümesi için en iyi performans gösteren model hattını belirlemek üzere Bayesçi Optimizasyon arama prosedürü kullanır.
auto-sklearn’ü kullanmak son derece kolaydır ve hem denetimli sınıflandırma hem de regresyon görevleri için kullanılabilir.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Kaynak: Örnek, auto-sklearn’ün resmî belgelerinden alınmıştır.
auto-sklearn hakkında daha fazla bilgi için GitHub depolarına göz atın.
⭐ GitHub Yıldızı: 7,3K | Toplam İndirme: 675B
FLAML, doğru makine öğrenmesi modellerini otomatik olarak belirleyen hafif bir Python kütüphanesidir. Öğrenicileri ve hiperparametreleri otomatik seçerek makine öğrenmesi uygulayıcılarına ciddi zaman ve emek tasarrufu sağlar. GitHub depolarına göre FLAML’in bazı özellikleri şunlardır:
Yalnızca üç satır kodla, bu hızlı AutoML motoruyla scikit-learn tarzında bir tahminleyici elde edebilirsiniz.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Kaynak: Örnek, resmî GitHub deposundan alınmıştır
⭐ GitHub Yıldızı: 3,5K | Toplam İndirme: 456B
Diğer AutoML kütüphaneleri hız odaklıyken, Amazon tarafından geliştirilen AutoGluon sağlamlık ve son teknoloji doğruluk üzerine odaklanır. "Çok katmanlı yığın toplulaştırma" stratejisiyle ünlüdür; bu strateji, tablo verisi kıyaslamalarında çoğu zaman insan tarafından ayarlanmış modellerin üstesinden gelmesini sağlar.
Sadece tablo verisini değil, çok modlu problemleri de destekler. Bu, metin, görseller ve sayılardan oluşan sütunlar içeren bir veri kümesi üzerinde, karmaşık öznitelik mühendisliği olmadan tek bir tahminleyici eğitmenize olanak tanıdığı anlamına gelir.
Aşağıdaki kod parçacığı AutoGluon sözdizimini gösterir:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ GitHub Yıldızı: 10K+ | Durum: Sınıfının En İyisi Doğruluk
TensorFlow, Google’daki Google Brain ekibi tarafından geliştirilen, yüksek performanslı sayısal hesaplama için popüler bir açık kaynak kütüphanedir ve derin öğrenme araştırmalarında temel taşlardan biridir.
Resmî web sitesinde belirtildiği üzere TensorFlow, uçtan uca bir açık kaynak makine öğrenmesi platformudur. Makine öğrenmesi araştırmacılarına ve geliştiricilerine yönelik kapsamlı ve esnek bir araç, kütüphane ve topluluk kaynakları yelpazesi sunar.
TensorFlow’u popüler ve yaygın kullanılan bir derin öğrenme kütüphanesi yapan bazı özellikler:
TensorFlow hakkında daha fazla bilgi için resmî rehberlerini veya GitHub deposunu inceleyebilir ya da adım adım TensorFlow öğreticisini takip ederek kendiniz deneyebilirsiniz.
⭐ GitHub Yıldızı: 180K | Toplam İndirme: 384 milyon
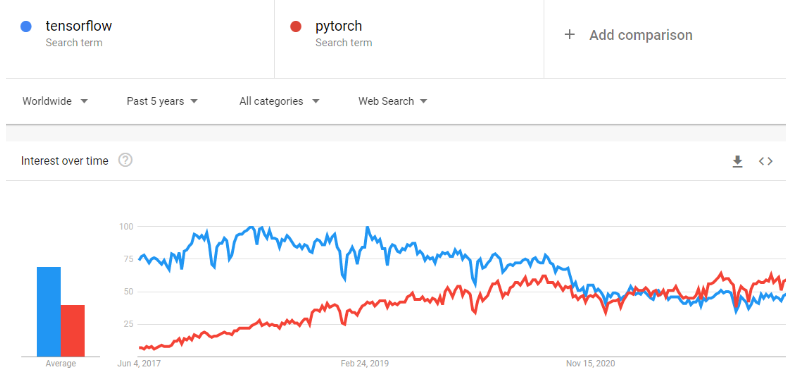
PyTorch, araştırma prototiplemesinden üretim dağıtımına giden yolu büyük ölçüde hızlandıran bir makine öğrenmesi çerçevesidir. GPU’lar ve CPU’lar kullanarak derin öğrenme için optimize edilmiş bir tensör kütüphanesidir ve TensorFlow’a bir alternatif olarak görülür. Zaman içinde PyTorch’un popülaritesi Google trendlerinde TensorFlow’u geride bırakacak düzeye gelmiştir.
Facebook tarafından geliştirilmiş ve sürdürülmektedir; şu anda BSD kapsamında kullanılabilir.
Resmî web sitesine göre PyTorch’un temel özellikleri şunlardır:
⭐ GitHub Yıldızı: 74K | Toplam İndirme: 119 milyon
FastAI, kullanıcılarına en son teknolojiyi zahmetsizce elde edebilecekleri üst düzey bileşenler sunan bir derin öğrenme kütüphanesidir. Ayrıca, yeni yaklaşımlar geliştirmek için değiştirilebilir düşük seviyeli bileşenler de içerir. Tüm bunları kullanım kolaylığı, esneklik veya performanstan kayda değer biçimde ödün vermeden yapmayı amaçlar.
Özellikler:
Proje hakkında daha fazla bilgi için resmî belgelerine göz atın.
⭐ GitHub Yıldızı: 25,1K | Toplam İndirme: 6,1 milyon
Keras, insanlar için tasarlanmış bir derin öğrenme API’sidir; makineler için değil. Keras, bilişsel yükü azaltmaya yönelik en iyi uygulamaları takip eder: tutarlı ve basit API’ler sunar, yaygın kullanım durumları için gereken kullanıcı eylemlerinin sayısını en aza indirir ve net, uygulanabilir hata mesajları sağlar. Keras o kadar sezgiseldir ki TensorFlow, TF 2.0 sürümünde Keras’ı varsayılan API olarak benimsemiştir.
Keras, sinir ağlarını ifade etmek için daha basit bir mekanizma sunar; ayrıca model geliştirme, veri kümesi işleme, grafik görselleştirme ve daha fazlası için en iyi araçlardan bazılarını içerir.
Özellikler:
Keras hakkında daha fazla bilgi için resmî belgelerine bakın veya şu giriş kursunu alın: Keras ile Derin Öğrenmeye Giriş.
⭐ GitHub Yıldızı: 60,2K | Toplam İndirme: 163 milyon
PyTorch Lightning, PyTorch için üst düzey bir arayüz sunar. Yüksek performanslı ve hafif çerçevesi, PyTorch kodunu araştırmayı mühendislikten ayıracak şekilde düzenleyebilir; bu da derin öğrenme deneylerini anlamayı ve çoğaltmayı kolaylaştırır. Dağıtık donanımda sorunsuz çalışan ölçeklenebilir derin öğrenme modelleri oluşturmak için geliştirilmiştir.
Resmî web sitesine göre PyTorch Lightning, daha az mühendislik, daha çok araştırma yapabilmeniz için tasarlanmıştır. Hızlı bir yeniden düzenleme ile şunları yapabilirsiniz:
Bu kütüphane hakkında daha fazla bilgi için resmî web sitesine bakın.
⭐ GitHub Yıldızı: 25,6K | Toplam İndirme: 18,2 milyon
JAX, Google tarafından geliştirilen yüksek performanslı bir sayısal hesaplama kütüphanesidir. PyTorch kullanıcı dostu standart ise, JAX aşırı hıza ihtiyaç duyan araştırmacıların (DeepMind dâhil) kullandığı "Formula 1 arabasıdır". NumPy kodunun, XLA (Hızlandırılmış Lineer Cebir) aracılığıyla hızlandırıcılarda (GPU/TPU) çalışacak şekilde otomatik derlenmesini sağlar.
Yerel Python işlevleri üzerinde otomatik türev alma yeteneği, özellikle üretici modelleme ve fizik simülasyonlarında sıfırdan yeni algoritmalar geliştirmek için onu favori yapar.
⭐ GitHub Yıldızı: 35K+ | Durum: Araştırma Standardı
spaCy, endüstriyel ölçekte, açık kaynaklı bir Python doğal dil işleme kütüphanesidir. spaCy, büyük ölçekli bilgi çıkarımı görevlerinde mükemmeldir. Baştan ayağa, dikkatli bellek yönetimiyle Cython’da yazılmıştır. Uygulamanızın devasa web dökümlerini işlemesi gerekiyorsa spaCy ideal kütüphanedir.
Özellikler:
spaCy hakkında daha fazla bilgi için resmî web sitesine veya GitHub deposuna bakın. Ayrıca, bu kullanışlı spaCY kopya kâğıdı ile işlevlerine hızla aşina olabilirsiniz.
⭐ GitHub Yıldızı: 28K | Toplam İndirme: 81 milyon
Hugging Face Transformers, Hugging Face tarafından geliştirilen açık kaynaklı bir kütüphanedir. Transformers, en son teknolojiye sahip önceden eğitilmiş modelleri kolayca indirip eğitmek için API’ler sunar. Önceden eğitilmiş modellerin kullanımı, hesaplama maliyetlerinizi ve karbon ayak izinizi azaltabilir; bir modeli sıfırdan eğitme zahmetinden de sizi kurtarır. Modeller aşağıdaki türlerdeki görevler için uygundur:
transformers kütüphanesi, en popüler üç derin öğrenme kütüphanesi olan PyTorch, TensorFlow ve JAX arasında sorunsuz entegrasyonu destekler. Bir çerçevede yalnızca üç satır kodla modelinizi eğitebilir, başka bir çerçevede çıkarım için yükleyebilirsiniz. Her dönüştürücünün mimarisi bağımsız bir Python modülünde tanımlanır; bu da onları deney ve araştırmalar için kolayca özelleştirilebilir kılar.
Kütüphane şu anda Apache Lisansı 2.0 kapsamında kullanılabilir.
transformers hakkında daha fazla bilgi için resmî web sitesine veya GitHub deposuna bakın ve Transformers ve Hugging Face kullanımı üzerine hazırladığımız öğreticiyi inceleyin.
⭐ GitHub Yıldızı: 119K | Toplam İndirme: 62 milyon
LangChain, Büyük Dil Modelleri (LLM’ler) için endüstri standardı orkestrasyon çerçevesidir. Geliştiricilerin, bir LLM’yi (ör. GPT 5.2) diğer hesaplama veya bilgi kaynaklarına bağlamak gibi, farklı bileşenleri birbirine "zincirlemesine" olanak tanır.
İstemlerle çalışmanın karmaşıklığını soyutlar; böylece bir hesap makinesi, Google Arama veya bir Python REPL gibi araçları kullanarak çok adımlı akıl yürütme problemlerini çözebilen "Ajanlar"ı kolayca oluşturabilirsiniz.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ GitHub Yıldızı: 123K+ | Durum: GenAI için Vazgeçilmez
LangChain akıl yürütmeyi ele alırken, LlamaIndex veriyi ele alır. RAG (Geri Getirmeyle Zenginleştirilmiş Üretim) için önde gelen çerçevedir. PDF’ler, SQL veritabanları, Excel sayfaları gibi özel verilerinizi içeri almak, indekslemek ve geri getirmek konusunda uzmanlaşmıştır; böylece LLM’ler bu veriler hakkında doğru şekilde soruları yanıtlayabilir.
2025’te "belgelerinizle sohbet etmek" standart bir iş gereksinimi hâline geldi ve LlamaIndex, bunun verimli ve halüsinasyonsuz olmasını sağlayan optimize edilmiş veri yapıları sunar.
⭐ GitHub Yıldızı: 35K+ | Durum: RAG Standardı
LLM’lerin bilgiyi "hatırlamasını" sağlamak için bir Vektör Veritabanına ihtiyacınız vardır. ChromaDB, Python geliştiricileri için varsayılan hâle gelmiş, açık kaynaklı, yapay zekâ yerli vektör veritabanıdır. Metni gömme (kelimeleri sayı listelerine dönüştürme) ve bunları anlamsal arama için depolama karmaşıklığını ele alır.
Tam anahtar sözcük eşleştiren geleneksel SQL veritabanlarının aksine, ChromaDB anlama göre sorgulama yapmanıza olanak tanır; bu da onu modern yapay zekâ uygulamalarının uzun süreli bellek arka ucu yapar.
⭐ GitHub Yıldızı: 25K+ | Durum: Vektör Mağazası Standardı
Veri bilimi, makine öğrenmesi veya doğal dil işleme görevleriniz için doğru Python kütüphanesini seçmek, projelerinizin başarısını önemli ölçüde etkileyebilecek kritik bir karardır. Çok sayıda kütüphane mevcutken, bilinçli bir seçim yapmak için çeşitli faktörleri göz önünde bulundurmak gerekir. İşte sizi yönlendirecek temel hususlar:
Bu faktörleri dikkatlice değerlendirerek, veri bilimi veya makine öğrenimi çalışmaları için Python kütüphanelerini seçerken bilinçli bir karar verebilirsiniz. Unutmayın: Projeniz için en iyi kütüphane, ulaşmayı hedeflediğiniz özgül gereksinimlere ve amaçlara bağlıdır.
Veri bilimi kariyerinize hızlı bir başlangıç yapmak için Python ile Veri Bilimci kariyer yolunu alın.
DataCamp’te Python Kütüphaneleri için Kurslar
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
