
Corso
Extreme Gradient Boosting con XGBoost
4 h
61.1K
Python è uno dei linguaggi di programmazione più popolari usati in varie discipline tecnologiche, soprattutto in data science e machine learning. Python offre un linguaggio di alto livello, orientato agli oggetti e facile da codificare, con un'ampia raccolta di librerie per una moltitudine di casi d'uso. Conta oltre 200.000 librerie.
Uno dei motivi per cui Python è così prezioso per la data science è la sua enorme raccolta di librerie per la manipolazione dei dati, la visualizzazione dei dati, il machine learning e il deep learning. Poiché Python ha un ecosistema così ricco di librerie per la data science, è quasi impossibile coprire tutto in un unico articolo. L'elenco delle librerie principali qui riportato è focalizzato su cinque aree chiave:
Ci sono molte altre aree non coperte in questo elenco; per esempio, MLOps, Big Data e Computer Vision. La lista in questo blog non segue un ordine particolare e non va interpretata in alcun modo come una classifica.
NumPy è una delle librerie open source Python più ampiamente utilizzate ed è impiegata principalmente per il calcolo scientifico. Le sue funzioni matematiche integrate consentono calcoli fulminei e supportano dati multidimensionali e matrici di grandi dimensioni. È usata anche in algebra lineare. Gli array NumPy sono spesso preferiti alle liste perché usano meno memoria e sono più comodi ed efficienti.
Secondo il sito di NumPy, è un progetto open source che punta ad abilitare il calcolo numerico con Python. È stata creata nel 2005 e costruita sul lavoro iniziale delle librerie Numeric e Numarray. Uno dei grandi vantaggi di NumPy è che è stata rilasciata sotto licenza BSD modificata e, di conseguenza, sarà sempre gratuita per tutti.
NumPy è sviluppata apertamente su GitHub con il consenso della comunità di NumPy e della più ampia comunità scientifica Python. Puoi saperne di più nel nostro corso introduttivo su Numpy.
⭐ Stelle GitHub: 25K | Download totali: 2,4 miliardi
Pandas è una libreria open source comunemente usata in data science. È impiegata principalmente per analisi, manipolazione e pulizia dei dati. Pandas consente semplici operazioni di modellazione e analisi dei dati senza dover scrivere molto codice. Come dichiarato sul loro sito, pandas è uno strumento open source per l'analisi e la manipolazione dei dati veloce, potente, flessibile e facile da usare. Alcune caratteristiche chiave di questa libreria includono:
Iniziare con pandas è semplice e diretto. Puoi dare un'occhiata a Analyzing Police Activity with pandas di DataCamp per imparare a usare pandas su set di dati reali.
⭐ Stelle GitHub: 41K | Download totali: 1,6 miliardi
Sebbene Pandas resti il default per i piccoli dati, Polars è diventato lo standard per l'elaborazione dati ad alte prestazioni. Scritto in Rust, utilizza un motore a "valutazione pigra" per processare dataset (10GB–100GB+) che normalmente manderebbero in crash macchine con RAM limitata. A differenza di Pandas, che esegue le operazioni in sequenza, Polars ottimizza le query end-to-end e le esegue in parallelo su tutti i core CPU disponibili.
È progettato per essere un upgrade immediato per carichi pesanti, offrendo una sintassi spesso più leggibile e prestazioni 10–50 volte superiori rispetto ai DataFrame tradizionali.
Ecco un esempio di codice che effettua una selezione filtrata, raggruppata e aggregata da un enorme dataset CSV:
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ Stelle GitHub: 40K+ | Stato: Standard ad alte prestazioni
Matplotlib è una libreria completa per creare visualizzazioni Python statiche, interattive e animate. Un gran numero di pacchetti di terze parti estendono e ampliano la funzionalità di Matplotlib, inclusi diverse interfacce di plotting di livello superiore (Seaborn, HoloViews, ggplot, ecc.)
Matplotlib è progettata per essere funzionale quanto MATLAB, con il vantaggio aggiuntivo di poter usare Python. Ha inoltre il pregio di essere gratuita e open source. Consente di visualizzare i dati utilizzando vari tipi di grafici, tra cui, ma non solo, scatterplot, istogrammi, grafici a barre, grafici di errore e boxplot. Inoltre, tutte le visualizzazioni possono essere implementate con poche righe di codice.
Esempi di grafici sviluppati con Matplotlib
Inizia con Matplotlib con questo tutorial passo passo.
⭐ Stelle GitHub: 18,7K | Download totali: 653 milioni
Un altro popolare framework di visualizzazione dati in Python basato su Matplotlib, Seaborn è un'interfaccia di alto livello per creare visualizzazioni statistiche esteticamente gradevoli e utili, fondamentali per studiare e comprendere i dati. Questa libreria Python è strettamente connessa alle strutture dati di NumPy e pandas. Il principio guida di Seaborn è rendere la visualizzazione una componente essenziale dell'analisi e dell'esplorazione dei dati; per questo, i suoi algoritmi di plotting utilizzano data frame che comprendono interi dataset.
Galleria di esempi Seaborn
Questo tutorial su Seaborn per principianti è un'ottima risorsa per prendere confidenza con questa dinamica libreria di visualizzazione.
⭐ Stelle GitHub: 11,6K | Download totali: 180 milioni
L'apprezzatissima libreria open source Plotly può essere usata per creare visualizzazioni dati interattive. Plotly è costruita sopra la libreria JavaScript Plotly (plotly.js) e può essere utilizzata per creare visualizzazioni web che possono essere salvate come file HTML o visualizzate in Jupyter notebook e applicazioni web tramite Dash.
Offre oltre 40 tipi di grafici unici, come scatter plot, istogrammi, line chart, bar chart, grafici a torta, barre di errore, box plot, assi multipli, sparklines, dendrogrammi e grafici 3D. Plotly offre anche i grafici di contorno, non così comuni in altre librerie di visualizzazione.
Se desideri visualizzazioni interattive o grafici in stile dashboard, Plotly è una buona alternativa a Matplotlib e Seaborn. Attualmente è disponibile sotto licenza MIT.
Puoi iniziare a padroneggiare Plotly oggi stesso con questo corso di visualizzazione Plotly.
⭐ Stelle GitHub: 14,7K | Download totali: 190 milioni
I termini machine learning e scikit-learn sono inseparabili. Scikit-learn è una delle librerie di machine learning più usate in Python. Costruita su NumPy, SciPy e Matplotlib, è una libreria Python open source utilizzabile commercialmente sotto licenza BSD. È uno strumento semplice ed efficiente per compiti di analisi predittiva dei dati.
Lanciata inizialmente nel 2007 come progetto Google Summer of Code, Scikit-learn è un progetto guidato dalla comunità; tuttavia, grant istituzionali e privati contribuiscono a garantirne la sostenibilità.
Il bello di scikit-learn è che è davvero facile da usare.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Crediti: Codice riprodotto dalla documentazione ufficiale di scikit-learn.
Puoi provare scikit-learn in prima persona con questo tutorial introduttivo su scikit-learn.
⭐ Stelle GitHub: 57K | Download totali: 703 milioni
Sono finiti i tempi in cui i data scientist consegnavano solo report PDF statici. Streamlit trasforma gli script Python in applicazioni web interattive e condivisibili in pochi minuti. Non richiede conoscenze di HTML, CSS o JavaScript. Nel 2025 è ampiamente usato per creare strumenti interni, prototipi di dashboard e demo interattive di modelli per gli stakeholder.
Con semplici chiamate API come st.write() e st.slider(), puoi costruire un frontend che reagisce ai cambiamenti dei dati in tempo reale, colmando il divario tra analisi e ingegneria.
⭐ Stelle GitHub: 42K+ | Stato: Essenziale per la delivery
Originariamente uno strumento per lo sviluppo web, Pydantic è oggi un pilastro dello stack AI. Esegue validazione dei dati e gestione delle impostazioni usando le annotazioni di tipo di Python. Nell'era degli LLM, garantire che i dati (e gli output dei modelli) aderiscano rigorosamente a uno schema specifico è fondamentale.
Pydantic è il motore che alimenta librerie come LangChain e Hugging Face, assicurando che gli output JSON disordinati dei modelli AI vengano forzati in oggetti Python strutturati e validi che non manderanno in errore il tuo codice a valle.
⭐ Stelle GitHub: 26K+ | Stato: Infrastruttura critica
LightGBM è una libreria open source per il gradient boosting estremamente popolare che impiega algoritmi basati su alberi. Offre i seguenti vantaggi:
Può essere utilizzata sia per compiti di classificazione supervisionata che di regressione. Puoi consultare la documentazione ufficiale o il loro GitHub per saperne di più su questo straordinario framework.
⭐ Stelle GitHub: 15,8K | Download totali: 162 milioni
XGBoost è un'altra libreria di gradient boosting distribuito ampiamente utilizzata, creata per essere portabile, flessibile ed efficiente. Consente l'implementazione di algoritmi di machine learning all'interno del framework del gradient boosting. XGBoost offre (GBDT) alberi di decisione potenziati dal gradiente, un boosting ad albero parallelo che fornisce soluzioni rapide e accurate a molti problemi di data science. Lo stesso codice gira sui principali ambienti distribuiti (Hadoop, SGE, MPI) e può risolvere innumerevoli problemi.
XGBoost ha guadagnato notevole popolarità negli ultimi anni grazie al fatto di aver aiutato individui e team a vincere praticamente ogni competizione Kaggle su dati strutturati. I vantaggi di XGBoost includono:
XGBoost è sviluppata e mantenuta da membri attivi della comunità ed è concessa in licenza d'uso sotto licenza Apache. Questo tutorial su XGBoost è un'ottima risorsa se vuoi saperne di più.
⭐ Stelle GitHub: 25,2K | Download totali: 179 milioni
Catboost è una libreria di gradient boosting su alberi di decisione veloce, scalabile e ad alte prestazioni, usata per ranking, classificazione, regressione e altri compiti di machine learning per Python, R, Java e C++. Supporta il calcolo su CPU e GPU.
Come successore dell'algoritmo MatrixNet, è ampiamente usata per compiti di ranking, previsione e raccomandazione. Grazie al suo carattere universale, può essere applicata in un'ampia gamma di aree e a una varietà di problemi.
I vantaggi di CatBoost secondo il loro repository sono:
⭐ Stelle GitHub: 7,5K | Download totali: 53 milioni
Statsmodels fornisce classi e funzioni che permettono agli utenti di stimare vari modelli statistici, condurre test statistici ed effettuare esplorazione statistica dei dati. Per ciascun stimatore viene poi fornito un elenco esaustivo di statistiche di risultato. L'accuratezza dei risultati può quindi essere testata rispetto a pacchetti statistici esistenti.
La maggior parte dei risultati dei test nella libreria è stata verificata con almeno un altro pacchetto statistico: R, Stata o SAS. Alcune caratteristiche di statsmodels sono:
Questo corso introduttivo su statsmodels è un ottimo punto di partenza se vuoi saperne di più.
⭐ Stelle GitHub: 9,2K | Download totali: 161 milioni
La suite RAPIDS di librerie software open source esegue pipeline end-to-end di data science e analytics interamente su GPU. Si scala senza soluzione di continuità da workstation GPU a server multi-GPU e cluster multi-nodo con Dask. Il progetto è supportato da NVIDIA e si basa anche su Numba, Apache Arrow e molti altri progetti open source.
cuDF è una libreria DataFrame su GPU utilizzata per caricare, unire, aggregare, filtrare e, in generale, manipolare i dati. È stata sviluppata basandosi sul formato di memoria colonnare di Apache Arrow. Fornisce una API in stile pandas familiare a data engineer e data scientist, consentendo loro di accelerare facilmente i workflow senza entrare nei dettagli della programmazione CUDA.
cuML è una suite di librerie che implementa algoritmi di machine learning e funzioni primitive matematiche con API compatibili con altri progetti RAPIDS. Consente a data scientist, ricercatori e ingegneri del software di eseguire compiti di ML tabellare tradizionale su GPU senza entrare nei dettagli della programmazione CUDA. L'API Python di cuML in genere corrisponde a quella di scikit-learn.
Questo framework open source per l'ottimizzazione degli iperparametri è utilizzato principalmente per automatizzare le ricerche di iperparametri. Usa loop, costrutti condizionali e sintassi Python per cercare automaticamente gli iperparametri ottimali e può esplorare spazi ampi e potare gli esperimenti poco promettenti per ottenere risultati più rapidi. Il meglio è che è facile da parallelizzare e scalare su grandi dataset.
Caratteristiche chiave secondo il loro repository GitHub:
⭐ Stelle GitHub: 9,1K | Download totali: 18 milioni
Questa popolarissima libreria open source di machine learning automatizza i workflow di machine learning in Python usando pochissimo codice. È uno strumento end-to-end per la gestione dei modelli e il machine learning che può accelerare notevolmente il ciclo di sperimentazione.
Rispetto ad altre librerie open source di machine learning, PyCaret offre una soluzione low-code che può sostituire centinaia di righe di codice con poche istruzioni. Questo rende gli esperimenti esponenzialmente più rapidi ed efficienti.
PyCaret è attualmente disponibile sotto licenza MIT. Per saperne di più su PyCaret, puoi consultare la documentazione ufficiale o il loro repository GitHub o dare un'occhiata a questo tutorial introduttivo su PyCaret.
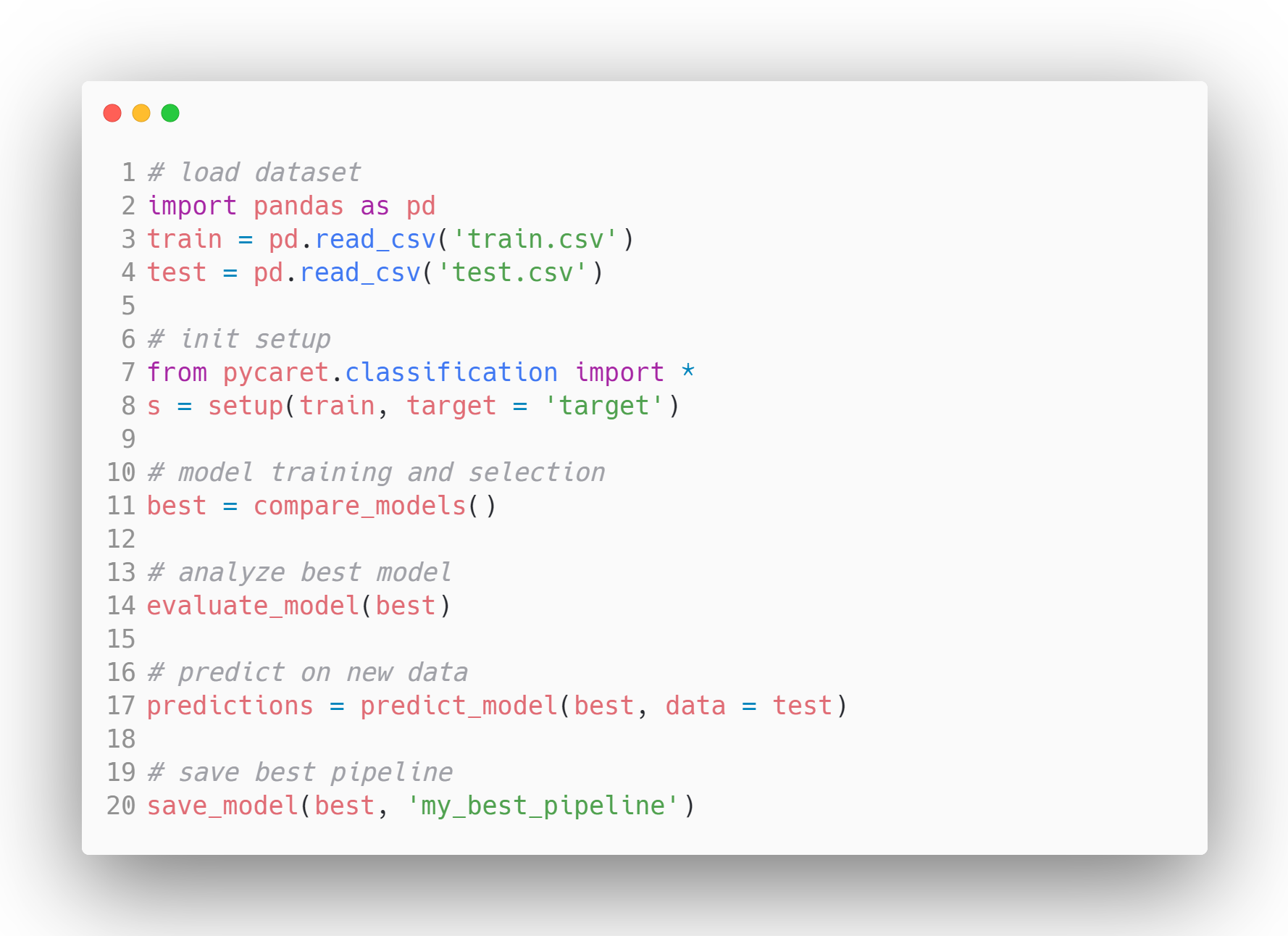
Esempio di workflow di modello in PyCaret - Fonte
⭐ Stelle GitHub: 8,1K | Download totali: 3,9 milioni
H2O è una piattaforma di machine learning e predictive analytics che consente di costruire modelli di machine learning su big data. Offre anche una facile messa in produzione di tali modelli in un ambiente enterprise.
Il core di H2O è scritto in Java. Gli algoritmi usano il framework Java Fork/Join per il multithreading e sono implementati sopra il framework Map/Reduce distribuito di H2O.
H2O è concesso sotto Apache License, Versione 2.0, ed è disponibile per i linguaggi Python, R e Java. Per saperne di più su H2O AutoML, consulta la loro documentazione ufficiale.
⭐ Stelle GitHub: 10,6K | Download totali: 15,1 milioni
Auto-sklearn è un toolkit di machine learning automatizzato e un sostituto adatto a un modello scikit-learn. Esegue automaticamente tuning degli iperparametri e selezione degli algoritmi, facendo risparmiare molto tempo ai professionisti del machine learning. Il suo design riflette i recenti progressi in meta-learning, costruzione di ensemble e ottimizzazione bayesiana.
Costruito come estensione di scikit-learn, auto-sklearn utilizza una procedura di ricerca a Ottimizzazione Bayesiana per identificare la pipeline di modelli con le migliori prestazioni per un dato dataset.
Auto-sklearn è estremamente facile da usare e può essere impiegato sia per compiti di classificazione supervisionata che di regressione.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Fonte: Esempio riprodotto dalla documentazione ufficiale di auto-sklearn.
Per saperne di più su auto-sklearn, consulta il loro repository GitHub.
⭐ Stelle GitHub: 7,3K | Download totali: 675K
FLAML è una libreria Python leggera che identifica automaticamente modelli di machine learning accurati. Seleziona automaticamente learner e iperparametri, facendo risparmiare tempo e fatica ai professionisti del machine learning. Secondo il loro repository GitHub, alcune caratteristiche di FLAML sono:
Con solo tre righe di codice, puoi ottenere un estimatore in stile scikit-learn con questo motore AutoML veloce.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Fonte: Esempio riprodotto dal repository GitHub ufficiale
⭐ Stelle GitHub: 3,5K | Download totali: 456K
Mentre altre librerie AutoML puntano sulla velocità, AutoGluon (sviluppata da Amazon) punta su robustezza e accuratezza allo stato dell'arte. È famosa per la sua strategia di "multi-layer stack ensembling", che spesso le consente di superare modelli ottimizzati manualmente nei benchmark su dati tabellari.
Supporta non solo i dati tabellari, ma anche problemi multimodali. Ciò significa che ti permette di addestrare un singolo predictor su un dataset contenente contemporaneamente colonne di testo, immagini e numeri senza complessa feature engineering.
Il seguente snippet di codice mostra la sintassi di AutoGluon:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ Stelle GitHub: 10K+ | Stato: Accuratezza best-in-class
TensorFlow è una popolare libreria open source per il calcolo numerico ad alte prestazioni sviluppata dal team Google Brain di Google, e un pilastro nel campo della ricerca sul deep learning.
Come dichiarato sul sito ufficiale, TensorFlow è una piattaforma open source end-to-end per il machine learning. Offre un'ampia e versatile dotazione di strumenti, librerie e risorse della community per ricercatori e sviluppatori di machine learning.
Alcune caratteristiche di TensorFlow che l'hanno resa una libreria di deep learning popolare e ampiamente utilizzata:
Per saperne di più su TensorFlow, consulta la loro guida ufficiale o il repository GitHub o prova a usarlo tu stesso seguendo questo tutorial su TensorFlow passo passo.
⭐ Stelle GitHub: 180K | Download totali: 384 milioni
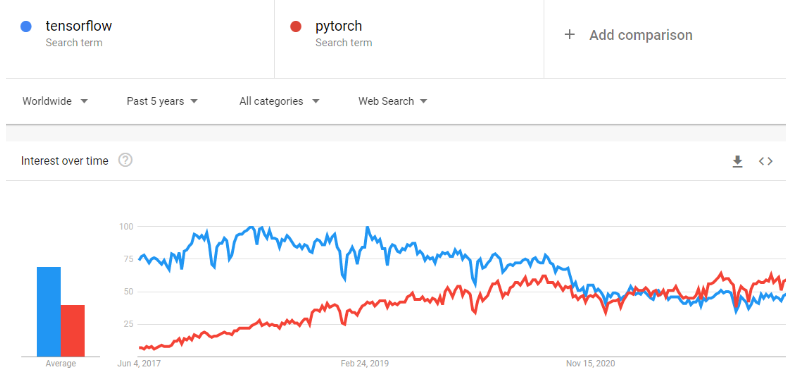
PyTorch è un framework di machine learning che accelera notevolmente il passaggio dal prototipo di ricerca alla messa in produzione. È una libreria di tensori ottimizzata per il deep learning su GPU e CPU, ed è considerata un'alternativa a TensorFlow. Nel tempo, la popolarità di PyTorch è cresciuta fino a superare TensorFlow su Google Trends.
È stato sviluppato e viene mantenuto da Facebook ed è attualmente disponibile sotto licenza BSD.
Secondo il sito ufficiale, le caratteristiche chiave di PyTorch sono:
⭐ Stelle GitHub: 74K | Download totali: 119 milioni
FastAI è una libreria di deep learning che offre componenti di alto livello in grado di generare facilmente risultati allo stato dell'arte. Include anche componenti di basso livello intercambiabili per sviluppare nuovi approcci. Punta a fare entrambe le cose senza compromettere in modo sostanziale facilità d'uso, flessibilità o prestazioni.
Caratteristiche:
Per saperne di più sul progetto, consulta la loro documentazione ufficiale.
⭐ Stelle GitHub: 25,1K | Download totali: 6,1 milioni
Keras è un'API di deep learning progettata per gli esseri umani, non per le macchine. Keras segue le best practice per ridurre il carico cognitivo: offre API coerenti e semplici, minimizza il numero di azioni richieste all'utente per i casi d'uso comuni e fornisce messaggi di errore chiari e azionabili. Keras è così intuitiva che TensorFlow l'ha adottata come API predefinita nella release TF 2.0.
Keras offre un meccanismo più semplice per esprimere le reti neurali e include anche alcuni dei migliori strumenti per lo sviluppo di modelli, l'elaborazione di dataset, la visualizzazione di grafi e altro.
Caratteristiche:
Per saperne di più su Keras, consulta la loro documentazione ufficiale o segui questo corso introduttivo: Deep Learning con Keras.
⭐ Stelle GitHub: 60,2K | Download totali: 163 milioni
PyTorch Lightning offre un'interfaccia di alto livello per PyTorch. Il suo framework leggero e ad alte prestazioni può organizzare il codice PyTorch per separare la ricerca dall'ingegneria, rendendo gli esperimenti di deep learning più semplici da comprendere e riprodurre. È stato sviluppato per creare modelli di deep learning scalabili che possano girare senza sforzo su hardware distribuito.
Secondo il sito ufficiale, PyTorch Lightning è progettato per farti dedicare più tempo alla ricerca e meno all'ingegneria. Una rapida rifattorizzazione ti permetterà di:
Per saperne di più su questa libreria, consulta il suo sito ufficiale.
⭐ Stelle GitHub: 25,6K | Download totali: 18,2 milioni
JAX è una libreria di calcolo numerico ad alte prestazioni sviluppata da Google. Se PyTorch è lo standard user-friendly, JAX è la "Formula 1" usata dai ricercatori (inclusa DeepMind) che hanno bisogno di velocità estrema. Consente di compilare automaticamente il codice NumPy per l'esecuzione su acceleratori (GPU/TPU) tramite XLA (Accelerated Linear Algebra).
La sua capacità di eseguire la differenziazione automatica su funzioni Python native lo rende un favorito per sviluppare da zero nuovi algoritmi, in particolare nel modeling generativo e nelle simulazioni fisiche.
⭐ Stelle GitHub: 35K+ | Stato: Standard di ricerca
spaCy è una libreria open source per l'elaborazione del linguaggio naturale in Python di livello industriale. spaCy eccelle nei compiti di estrazione di informazioni su larga scala. È scritta da zero in Cython con una gestione attenta della memoria. spaCy è la libreria ideale se la tua applicazione deve processare enormi dump del web.
Caratteristiche:
Per saperne di più su spaCy, consulta il sito ufficiale o il repository GitHub. Puoi anche familiarizzare rapidamente con le sue funzionalità usando questo pratico cheat sheet su spaCY.
⭐ Stelle GitHub: 28K | Download totali: 81 milioni
Hugging Face Transformers è una libreria open source di Hugging Face. I Transformer consentono di scaricare e addestrare facilmente, tramite API, modelli pre-addestrati allo stato dell'arte. Usare modelli pre-addestrati può ridurre i costi computazionali, l'impronta di carbonio e farti risparmiare il tempo necessario per addestrare un modello da zero. I modelli sono adatti a diverse modalità, tra cui:
La libreria transformers supporta un'integrazione fluida tra tre delle librerie di deep learning più popolari: PyTorch, TensorFlow e JAX. Puoi addestrare il tuo modello in tre righe di codice in un framework e caricarlo per l'inferenza con un altro. L'architettura di ciascun transformer è definita all'interno di un modulo Python standalone, rendendoli facilmente personalizzabili per esperimenti e ricerca.
La libreria è attualmente disponibile sotto Apache License 2.0.
Per saperne di più sui transformer, consulta il sito ufficiale o il repository GitHub e dai un'occhiata al nostro tutorial su come usare Transformers e Hugging Face.
⭐ Stelle GitHub: 119K | Download totali: 62 milioni
LangChain è il framework di orchestrazione standard del settore per i Large Language Model (LLM). Consente agli sviluppatori di "concatenare" diversi componenti, ad esempio collegando un LLM (come GPT 5.2) ad altre fonti di calcolo o conoscenza.
Astrae la complessità del lavoro con i prompt, permettendoti di creare facilmente "Agent" che possono usare strumenti (come una calcolatrice, Google Search o una REPL Python) per risolvere problemi di ragionamento multi-step.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ Stelle GitHub: 123K+ | Stato: Essenziale per la GenAI
Mentre LangChain gestisce il reasoning, LlamaIndex gestisce i dati. È il framework leader per la RAG (Retrieval-Augmented Generation). È specializzato nell'ingestione, indicizzazione e recupero dei tuoi dati privati (PDF, database SQL, fogli Excel) così che gli LLM possano rispondere con precisione alle domande su di essi.
Nel 2025, "chattare con i tuoi documenti" è un requisito aziendale standard, e LlamaIndex fornisce le strutture dati ottimizzate per renderlo efficiente e privo di allucinazioni.
⭐ Stelle GitHub: 35K+ | Stato: Standard RAG
Per far "ricordare" informazioni agli LLM, serve un database vettoriale. ChromaDB è il database vettoriale open source, AI-native, che è diventato il default per gli sviluppatori Python. Gestisce la complessità dell'embedding del testo (convertire le parole in liste di numeri) e il loro salvataggio per la ricerca semantica.
A differenza dei database SQL tradizionali che fanno combaciare parole chiave esatte, ChromaDB ti permette di interrogare per significato, diventando il backend di memoria a lungo termine per le moderne applicazioni di AI.
⭐ Stelle GitHub: 25K+ | Stato: Standard per i vector store
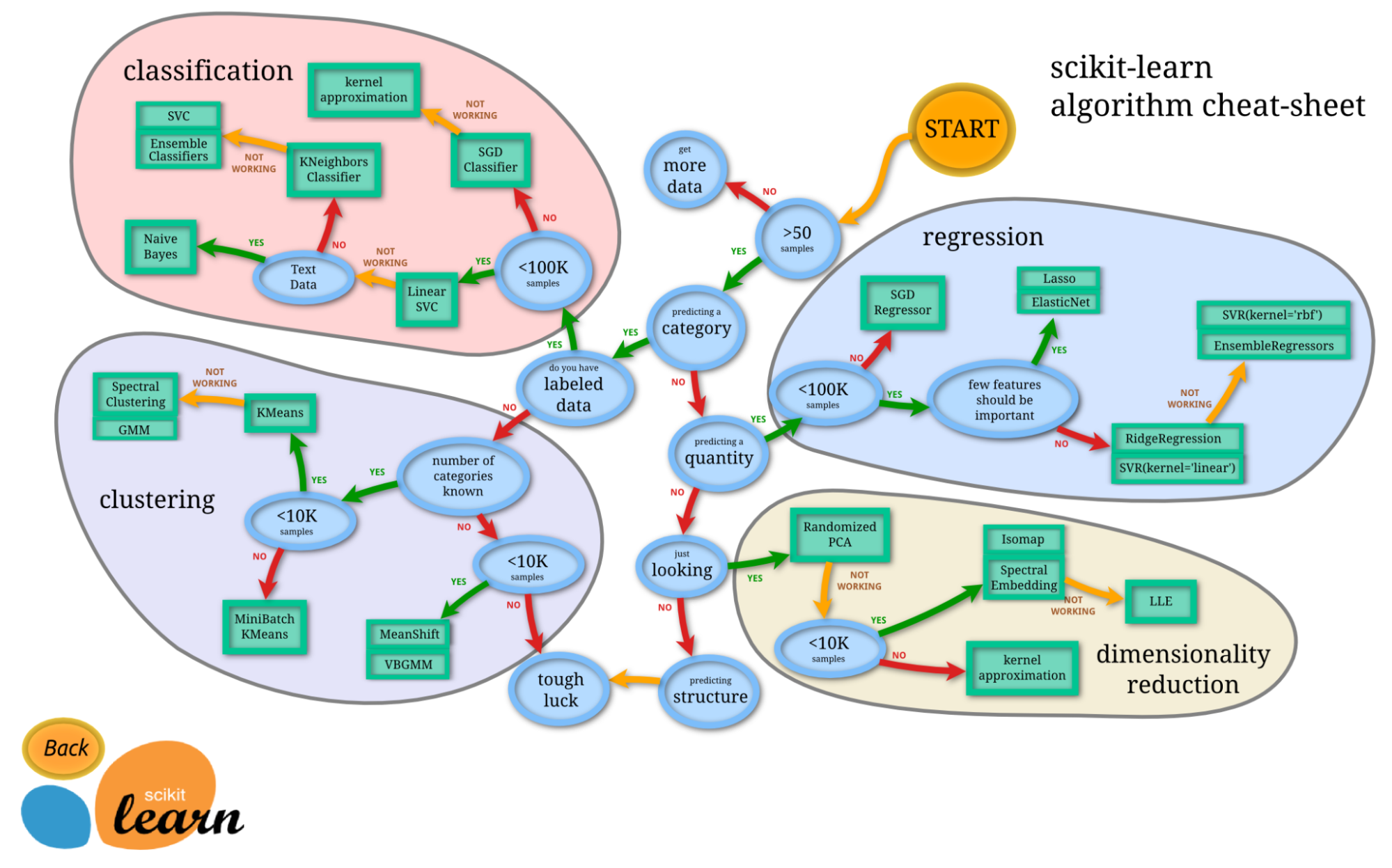
La scelta della libreria Python giusta per i tuoi compiti di data science, machine learning o natural language processing è una decisione cruciale che può influenzare in modo significativo il successo dei tuoi progetti. Con l'ampia gamma di librerie disponibili, è essenziale considerare vari fattori per fare una scelta informata. Ecco alcune considerazioni chiave che possono guidarti:
Valutando con attenzione questi fattori, potrai prendere una decisione informata nella selezione delle librerie Python per i tuoi progetti di data science o machine learning. Ricorda che la libreria migliore per il tuo progetto dipende dai requisiti specifici e dagli obiettivi che intendi raggiungere.
Per dare slancio alla tua carriera in data science, segui il career track Data Scientist in Python.
Corsi sulle librerie Python su DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

