
Cursus
Extreme Gradient Boosting met XGBoost
4 Hr
61.1K
Python is een van de populairste programmeertalen in uiteenlopende techdisciplines, vooral in data science en machine learning. Python biedt een eenvoudig te coderen, objectgeoriënteerde, high-level taal met een brede verzameling bibliotheken voor talloze use-cases. Er zijn meer dan 200.000 bibliotheken.
Een van de redenen waarom Python zo waardevol is voor data science, is de enorme hoeveelheid bibliotheken voor datamanipulatie, datavisualisatie, machine learning en deep learning. Omdat het Python-ecosysteem voor data science zo rijk is, is het bijna onmogelijk om alles in één artikel te behandelen. De lijst met topbibliotheken hier richt zich op slechts vijf hoofdgebieden:
Er zijn veel andere gebieden die niet aan bod komen in deze lijst; bijvoorbeeld MLOps, Big Data en Computer Vision. De lijst in deze blog volgt geen specifieke volgorde en is op geen enkele manier bedoeld als ranglijst.
NumPy is een van de meest gebruikte open-source Python-bibliotheken en wordt vooral ingezet voor wetenschappelijke berekeningen. De ingebouwde wiskundige functies maken razendsnelle berekeningen mogelijk en ondersteunen multidimensionale data en grote matrices. Het wordt ook gebruikt in lineaire algebra. NumPy-array wordt vaak verkozen boven lijsten omdat het minder geheugen gebruikt en handiger en efficiënter is.
Volgens de website van NumPy is het een open-sourceproject met als doel numerieke computing met Python mogelijk te maken. Het werd gecreëerd in 2005 en gebouwd op het vroege werk van de Numeric- en Numarray-bibliotheken. Een van de grote voordelen van NumPy is dat het is uitgebracht onder de gewijzigde BSD-licentie en dus altijd gratis te gebruiken zal zijn.
NumPy wordt openlijk ontwikkeld op GitHub met consensus van de NumPy- en bredere wetenschappelijke Python-community. Je kunt er meer over leren in onze introductiecursus Numpy.
⭐ GitHub-sterren: 25K | Totaal aantal downloads: 2,4 miljard
Pandas is een open-sourcebibliotheek die vaak wordt gebruikt in data science. Het wordt primair ingezet voor data-analyse, datamanipulatie en opschonen van data. Met pandas kun je eenvoudig datamodellering en data-analyse uitvoeren zonder veel code te hoeven schrijven. Zoals op hun website staat, is pandas een snelle, krachtige, flexibele en eenvoudige open-source tool voor data-analyse en -manipulatie. Enkele kernfuncties van deze bibliotheek zijn:
Aan de slag met pandas is eenvoudig en rechttoe rechtaan. Bekijk DataCamps Analyzing Police Activity with pandas om te leren hoe je pandas gebruikt op datasets uit de echte wereld.
⭐ GitHub-sterren: 41K | Totaal aantal downloads: 1,6 miljard
Hoewel Pandas de standaard blijft voor kleine data, is Polars de norm geworden voor high-performance dataverwerking. Geschreven in Rust, gebruikt het een "lazy evaluation"-engine om datasets (10GB–100GB+) te verwerken die normaal gesproken zouden crashen op machines met beperkt RAM. In tegenstelling tot Pandas, dat bewerkingen sequentieel uitvoert, optimaliseert Polars queries end-to-end en voert ze parallel uit over alle beschikbare CPU-cores.
Het is ontworpen als een drop-in upgrade voor zware workloads, met een syntaxis die vaak leesbaarder is en 10–50x sneller dan traditionele DataFrames.
Hier is een codevoorbeeld voor het laden van een gefilterde, gegroepeerde en geaggregeerde selectie uit een gigantische CSV-dataset:
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ GitHub-sterren: 40K+ | Status: High-Performance Standard
Matplotlib is een uitgebreide bibliotheek voor het maken van statische, interactieve en geanimeerde Python-visualisaties. Veel third-party pakketten breiden de functionaliteit van Matplotlib uit en bouwen daarop voort, waaronder verschillende interfaces op hoger niveau (Seaborn, HoloViews, ggplot, enz.)
Matplotlib is ontworpen om net zo functioneel te zijn als MATLAB, met het extra voordeel dat je Python kunt gebruiken. Het is bovendien gratis en open source. Je kunt data visualiseren met allerlei soorten grafieken, waaronder maar niet beperkt tot scatterplots, histogrammen, staafdiagrammen, foutendiagrammen en boxplots. En het mooiste: alle visualisaties zijn te maken met slechts een paar regels code.
Voorbeeldplots gemaakt met Matplotlib
Ga aan de slag met Matplotlib met deze stapsgewijze tutorial.
⭐ GitHub-sterren: 18,7K | Totaal aantal downloads: 653 miljoen
Nog een populair, op Matplotlib gebaseerd Python-framework voor datavisualisatie: Seaborn is een interface op hoog niveau voor het maken van esthetisch aantrekkelijke en nuttige statistische visuals, cruciaal voor het bestuderen en begrijpen van data. Deze Python-bibliotheek is nauw verbonden met zowel NumPy- als pandas-datastructuren. Het onderliggende principe achter Seaborn is om visualisatie een essentieel onderdeel te maken van data-analyse en -verkenning; daarom gebruiken de plotalgoritmen dataframes die volledige datasets omvatten.
Seaborn-voorbeeldgalerij
Deze Seaborn-tutorial voor beginners is een geweldige bron om je wegwijs te maken in deze dynamische visualisatiebibliotheek.
⭐ GitHub-sterren: 11,6K | Totaal aantal downloads: 180 miljoen
De enorm populaire open-source grafiekbibliotheek Plotly kan worden gebruikt om interactieve datavisualisaties te maken. Plotly is gebouwd boven op de Plotly JavaScript-bibliotheek (plotly.js) en kan worden gebruikt om webgebaseerde datavisualisaties te maken die kunnen worden opgeslagen als HTML-bestanden of weergegeven in Jupyter-notebooks en webapplicaties met Dash.
Het biedt meer dan 40 unieke grafiektypen, zoals scatterplots, histogrammen, lijngrafieken, staafdiagrammen, cirkeldiagrammen, foutbalken, boxplots, meerdere assen, sparklines, dendrogrammen en 3D-grafieken. Plotly biedt ook contourplots, die minder gebruikelijk zijn in andere datavisualisatiebibliotheken.
Als je interactieve visualisaties of dashboardachtige graphics wilt, is Plotly een goed alternatief voor Matplotlib en Seaborn. Het is momenteel beschikbaar onder de MIT-licentie.
Je kunt vandaag nog beginnen met het onder de knie krijgen van Plotly met deze Plotly-visualisatiecursus.
⭐ GitHub-sterren: 14,7K | Totaal aantal downloads: 190 miljoen
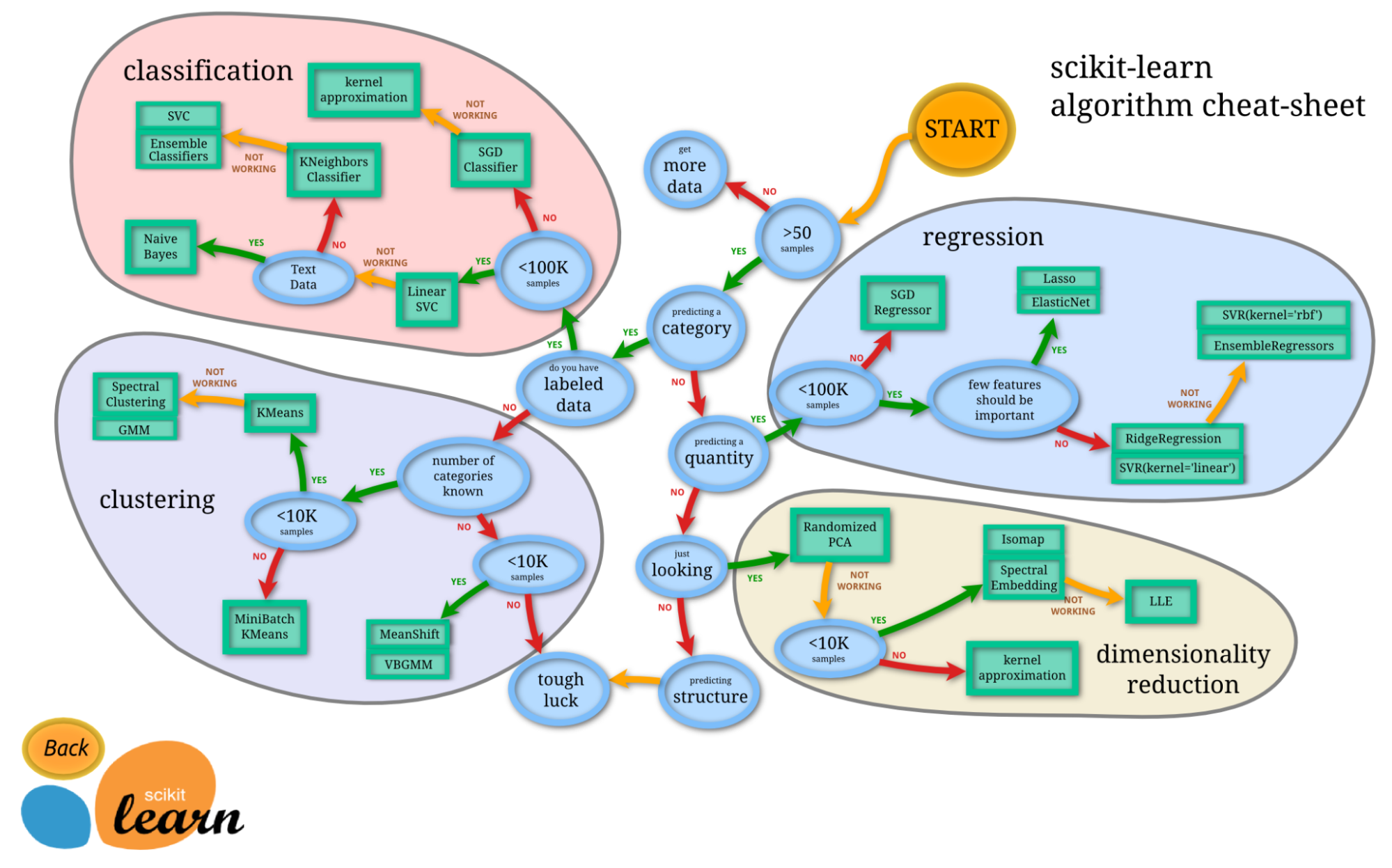
De termen machine learning en scikit-learn zijn onlosmakelijk met elkaar verbonden. Scikit-learn is een van de meest gebruikte machine learning-bibliotheken in Python. Gebouwd op NumPy, SciPy en Matplotlib, is het een open-source Python-bibliotheek die commercieel bruikbaar is onder de BSD-licentie. Het is een eenvoudige en efficiënte tool voor voorspellende data-analysetaken.
Scikit-learn werd in 2007 gelanceerd als een Google Summer of Code-project en is een communitygedreven project; institutionele en private subsidies helpen echter de duurzaamheid te waarborgen.
Het beste aan scikit-learn is dat het heel gemakkelijk te gebruiken is.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Bron: Code overgenomen uit de officiële documentatie van scikit-learn.
Je kunt scikit-learn zelf uitproberen met deze scikit-learn-tutorial voor beginners.
⭐ GitHub-sterren: 57K | Totaal aantal downloads: 703 miljoen
De tijd dat dataspecialisten alleen statische PDF-rapporten opleverden, is voorbij. Streamlit verandert Python-scripts in interactieve, deelbare webapplicaties in enkele minuten. Je hebt geen kennis nodig van HTML, CSS of JavaScript. Het wordt in 2025 veel gebruikt om interne tools, dashboardprototypes en interactieve modeldemo’s voor stakeholders te bouwen.
Met eenvoudige API-calls zoals st.write() en st.slider() bouw je een frontend die in realtime reageert op dataveranderingen en zo de kloof tussen analyse en engineering overbrugt.
⭐ GitHub-sterren: 42K+ | Status: Essentieel voor oplevering
Oorspronkelijk een webontwikkelingstool, is Pydantic nu een hoeksteen van de AI-stack. Het voert datavalidatie en configuratiebeheer uit met behulp van type-annotaties in Python. In het tijdperk van LLM’s is het cruciaal om ervoor te zorgen dat data (en modeluitvoer) strikt overeenkomt met een specifiek schema.
Pydantic is de motor achter bibliotheken als LangChain en Hugging Face, die ervoor zorgt dat rommelige JSON-uitvoer van AI-modellen wordt omgezet in gestructureerde, geldige Python-objecten die je downstream-code niet laten crashen.
⭐ GitHub-sterren: 26K+ | Status: Kritieke infrastructuur
LightGBM is een enorm populaire open-source gradient boosting-bibliotheek die boomgebaseerde algoritmen gebruikt. Het biedt de volgende voordelen:
Het kan worden gebruikt voor zowel supervised classificatie- als regressietaken. Bekijk de officiële documentatie of hun GitHub om meer te leren over dit geweldige framework.
⭐ GitHub-sterren: 15,8K | Totaal aantal downloads: 162 miljoen
XGBoost is een andere veelgebruikte gedistribueerde gradient boosting-bibliotheek die is gemaakt om draagbaar, flexibel en efficiënt te zijn. Het maakt de implementatie mogelijk van machine learning-algoritmen binnen het gradient boosting-framework. XGBoost biedt (GBDT) gradient boosted decision trees, een parallelle boosten van bomen die snel en nauwkeurig oplossingen biedt voor veel data science-problemen. Dezelfde code draait op grote gedistribueerde omgevingen (Hadoop, SGE, MPI) en kan talloze problemen oplossen.
XGBoost heeft de afgelopen jaren veel aan populariteit gewonnen doordat het individuen en teams hielp vrijwel elke Kaggle-wedstrijd met gestructureerde data te winnen. De voordelen van XGBoost zijn onder andere:
XGBoost is ontwikkeld en onderhouden door actieve communityleden en is gelicenseerd onder de Apache-licentie. Deze XGBoost-tutorial is een geweldige bron als je meer wilt leren.
⭐ GitHub-sterren: 25,2K | Totaal aantal downloads: 179 miljoen
CatBoost is een snelle, schaalbare, high-performance gradient boosting-bibliotheek op beslissingsbomen die wordt gebruikt voor ranking, classificatie, regressie en andere ML-taken voor Python, R, Java en C++. Het ondersteunt berekeningen op CPU en GPU.
Als opvolger van het MatrixNet-algoritme wordt het veel gebruikt voor rankingtaken, forecasting en het doen van aanbevelingen. Dankzij het universele karakter kan het in uiteenlopende domeinen en op verschillende problemen worden toegepast.
De voordelen van CatBoost volgens hun repository zijn:
⭐ GitHub-sterren: 7,5K | Totaal aantal downloads: 53 miljoen
Statsmodels biedt klassen en functies waarmee gebruikers verschillende statistische modellen kunnen schatten, statistische toetsen kunnen uitvoeren en statistische data-exploratie kunnen doen. Voor elke schatter wordt vervolgens een uitgebreide lijst met resultaatstaatstieken gegeven. De nauwkeurigheid van de resultaten kan vervolgens worden getest tegen bestaande statistische pakketten.
De meeste testresultaten in de bibliotheek zijn geverifieerd met ten minste één ander statistisch pakket: R, Stata of SAS. Enkele kenmerken van statsmodels zijn:
Deze introductiecursus statsmodels is een uitstekende start als je meer wilt leren.
⭐ GitHub-sterren: 9,2K | Totaal aantal downloads: 161 miljoen
De RAPIDS-suite met open-source softwarebibliotheken voert end-to-end data science- en analysepijplijnen volledig uit op GPU’s. Het schaalt naadloos van GPU-werkstations naar multi-GPU-servers en multinodeclusters met Dask. Het project wordt ondersteund door NVIDIA en steunt ook op Numba, Apache Arrow en veel andere open-sourceprojecten.
cuDF is een GPU-DataFrame-bibliotheek die wordt gebruikt om data te laden, te joinen, aggregeren, filteren en verder te manipuleren. Het is ontwikkeld op basis van het kolomgeheugenformaat van Apache Arrow. Het biedt een pandas-achtige API die vertrouwd zal zijn voor data engineers & data scientists, waardoor ze hun workflows eenvoudig kunnen versnellen zonder in te gaan op de details van CUDA-programmering.
cuML is een suite van bibliotheken die machine learning-algoritmen en wiskundige primitieve functies implementeert met API’s die compatibel zijn met andere RAPIDS-projecten. Het stelt data scientists, onderzoekers en software-engineers in staat om traditionele tabulaire ML-taken op GPU’s uit te voeren zonder in de details van CUDA-programmering te duiken. De Python-API van cuML komt doorgaans overeen met de scikit-learn-API.
Dit open-source framework voor hyperparameteroptimalisatie wordt primair gebruikt om hyperparameterzoektochten te automatiseren. Het gebruikt Python-lussen, conditionals en syntaxis om automatisch naar optimale hyperparameters te zoeken en kan grote ruimtes verkennen en onbelovende trials vroegtijdig stoppen voor snellere resultaten. Het mooiste is dat het eenvoudig te paralleliseren en te schalen is op grote datasets.
Belangrijkste features volgens hun GitHub-repository:
⭐ GitHub-sterren: 9,1K | Totaal aantal downloads: 18 miljoen
Deze enorm populaire, open-source machine learning-bibliotheek automatiseert ML-workflows in Python met heel weinig code. Het is een end-to-end tool voor modelbeheer en machine learning die de experimentcyclus drastisch kan versnellen.
Vergeleken met andere open-source ML-bibliotheken biedt PyCaret een low-codeoplossing die honderden regels code kan vervangen door slechts een paar. Dit maakt experimenten exponentieel sneller en efficiënter.
PyCaret is momenteel beschikbaar onder de MIT-licentie. Wil je meer leren over PyCaret, bekijk dan de officiële documentatie of hun GitHub-repository of bekijk deze introductietutorial PyCaret.
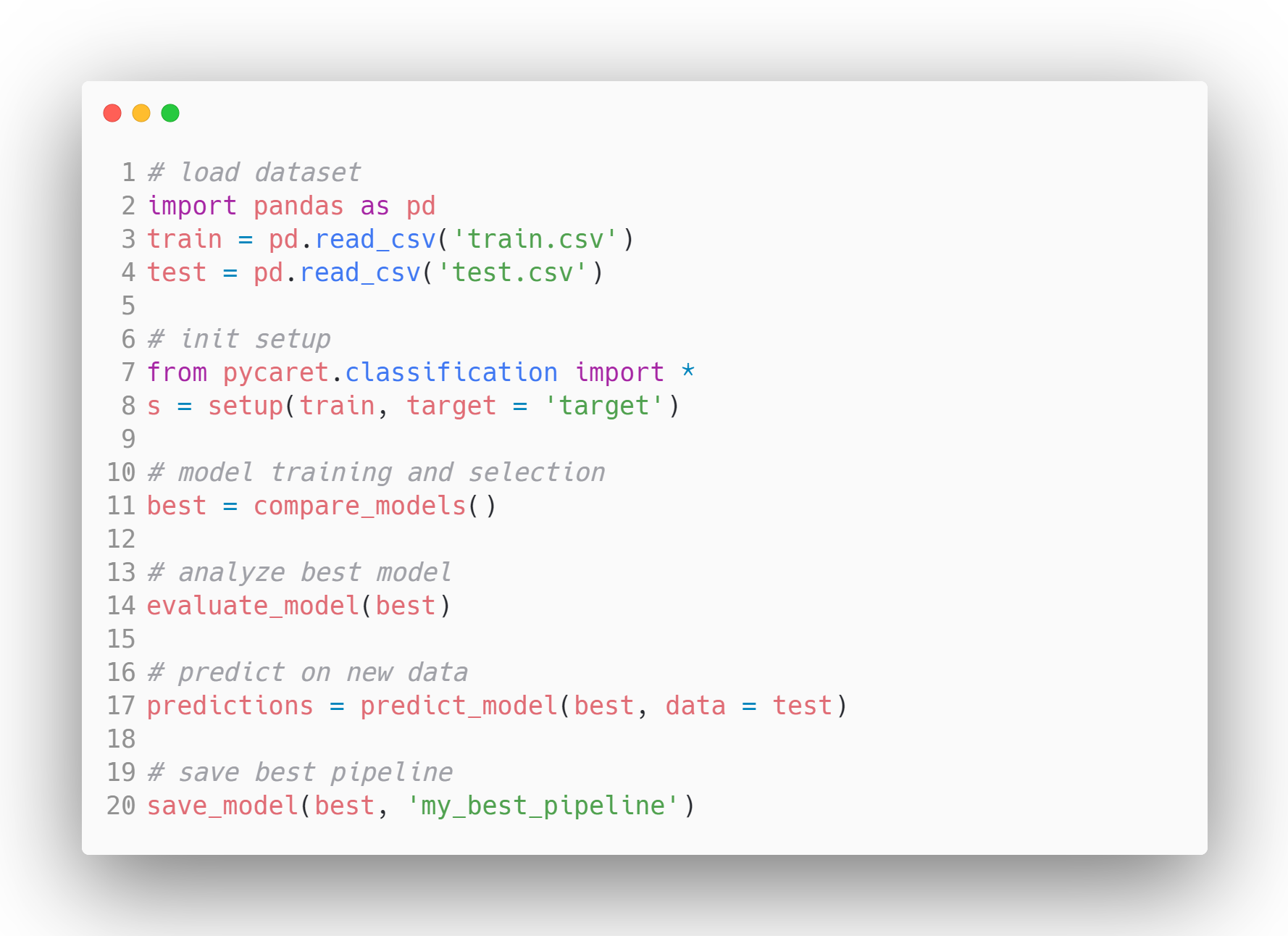
Voorbeeld van een modelworkflow in PyCaret - Bron
⭐ GitHub-sterren: 8,1K | Totaal aantal downloads: 3,9 miljoen
H2O is een machine learning- en predictieve analytics-omgeving die het bouwen van ML-modellen op big data mogelijk maakt. Het biedt ook eenvoudige productiesetting van die modellen in een enterprise-omgeving.
De kerncode van H2O is geschreven in Java. De algoritmen gebruiken het Java Fork/Join-framework voor multithreading en zijn geïmplementeerd boven op H2O’s gedistribueerde Map/Reduce-framework.
H2O is gelicenseerd onder de Apache License, Version 2.0, en is beschikbaar voor de talen Python, R en Java. Wil je meer leren over H2O AutoML, bekijk dan hun officiële documentatie.
⭐ GitHub-sterren: 10,6K | Totaal aantal downloads: 15,1 miljoen
Auto-sklearn is een toolkit voor geautomatiseerde machine learning en een geschikt alternatief voor een scikit-learn-model. Het voert automatisch hyperparameterafstemming en algoritmeselectie uit, wat ML-practitioners veel tijd bespaart. Het ontwerp weerspiegelt recente vorderingen in meta-learning, ensembleconstructie en Bayesiaanse optimalisatie.
Gebouwd als add-on voor scikit-learn, gebruikt auto-sklearn een Bayesiaanse optimalisatieprocedure om de best presterende modelpipeline voor een gegeven dataset te identificeren.
Auto-sklearn is extreem eenvoudig te gebruiken en kan worden ingezet voor zowel supervised classificatie- als regressietaken.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Bron: Voorbeeld overgenomen uit de officiële documentatie van auto-sklearn.
Wil je meer leren over auto-sklearn, bekijk dan hun GitHub-repository.
⭐ GitHub-sterren: 7,3K | Totaal aantal downloads: 675K
FLAML is een lichtgewicht Python-bibliotheek die automatisch nauwkeurige ML-modellen identificeert. Het selecteert learners en hyperparameters automatisch, wat ML-practitioners veel tijd en moeite bespaart. Volgens hun GitHub-repository zijn enkele features van FLAML:
Met slechts drie regels code krijg je een scikit-learn-achtige estimator met deze snelle AutoML-engine.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Bron: Voorbeeld overgenomen uit de officiële GitHub-repository
⭐ GitHub-sterren: 3,5K | Totaal aantal downloads: 456K
Terwijl andere AutoML-bibliotheken focussen op snelheid, richt AutoGluon (ontwikkeld door Amazon) zich op robuustheid en state-of-the-art nauwkeurigheid. Het staat bekend om zijn "multi-layer stack ensembling"-strategie, waardoor het vaak beter presteert dan door mensen getunede modellen op benchmarks met tabeldata.
Het ondersteunt niet alleen tabulaire data, maar ook multimodale problemen. Dat betekent dat je één predictor kunt trainen op een dataset met kolommen van tekst, afbeeldingen en cijfers tegelijk, zonder complexe feature engineering.
Onderstaande code snippet laat de AutoGluon-syntaxis zien:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ GitHub-sterren: 10K+ | Status: Best-in-Class Accuracy
TensorFlow is een populaire open-sourcebibliotheek voor high-performance numerieke berekeningen, ontwikkeld door het Google Brain-team bij Google, en een vaste waarde in deep learning-onderzoek.
Zoals op de officiële website staat, is TensorFlow een end-to-end open-sourceplatform voor machine learning. Het biedt een uitgebreide, veelzijdige set tools, bibliotheken en communityresources voor ML-onderzoekers en -ontwikkelaars.
Enkele features van TensorFlow die het tot een populaire en veelgebruikte deep learning-bibliotheek maken:
Wil je meer leren over TensorFlow, bekijk dan hun officiële gids of de GitHub-repository of probeer het zelf met deze stapsgewijze TensorFlow-tutorial.
⭐ GitHub-sterren: 180K | Totaal aantal downloads: 384 miljoen
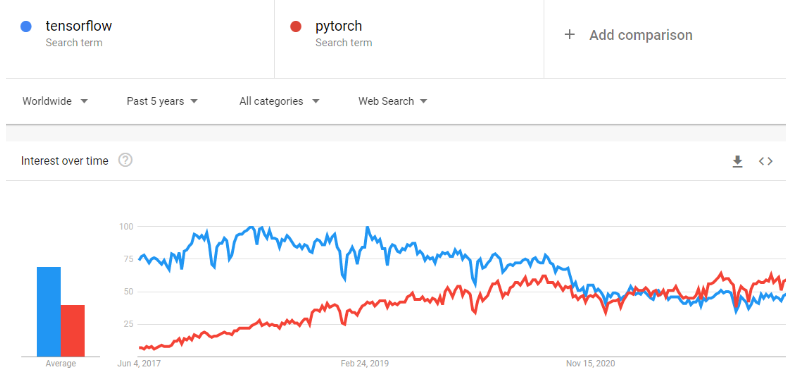
PyTorch is een machine learning-framework dat de weg van onderzoeksprototyping naar productie-implementatie sterk versnelt. Het is een geoptimaliseerde tensorbibliotheek voor deep learning met gebruik van GPU’s en CPU’s, en wordt gezien als alternatief voor TensorFlow. In de loop der tijd is de populariteit van PyTorch op Google Trends die van TensorFlow voorbijgestreefd.
Het is ontwikkeld en wordt onderhouden door Facebook en is momenteel beschikbaar onder BSD.
Volgens de officiële website zijn de belangrijkste kenmerken van PyTorch:
⭐ GitHub-sterren: 74K | Totaal aantal downloads: 119 miljoen
FastAI is een deep learning-bibliotheek die gebruikers high-level componenten biedt waarmee je moeiteloos state-of-the-art resultaten kunt behalen. Het bevat ook low-level componenten die je kunt uitwisselen om nieuwe benaderingen te ontwikkelen. Het doel is om beide te doen zonder noemenswaardige concessies aan gebruiksgemak, flexibiliteit of performance.
Features:
Bekijk voor meer informatie over het project hun officiële documentatie.
⭐ GitHub-sterren: 25,1K | Totaal aantal downloads: 6,1 miljoen
Keras is een deep learning-API ontworpen voor mensen, niet voor machines. Keras volgt best practices om de cognitieve belasting te verlagen: het biedt consistente en eenvoudige API’s, minimaliseert het aantal handelingen dat nodig is voor veelvoorkomende use-cases en geeft duidelijke, actiegerichte foutmeldingen. Keras is zo intuïtief dat TensorFlow Keras heeft overgenomen als hun standaard-API in de TF 2.0-release.
Keras biedt een eenvoudigere manier om neurale netwerken uit te drukken en bevat ook enkele van de beste tools voor het ontwikkelen van modellen, datasetverwerking, grafiekvisualisatie en meer.
Features:
Wil je meer leren over Keras, bekijk dan de officiële documentatie of volg deze introductiecursus: Deep Learning met Keras.
⭐ GitHub-sterren: 60,2K | Totaal aantal downloads: 163 miljoen
PyTorch Lightning biedt een interface op hoog niveau voor PyTorch. Het high-performance en lichtgewicht framework kan PyTorch-code organiseren om onderzoek los te koppelen van engineering, waardoor deep learning-experimenten eenvoudiger te begrijpen en te reproduceren zijn. Het is ontwikkeld om schaalbare deep learning-modellen te maken die naadloos kunnen draaien op gedistribueerde hardware.
Volgens de officiële website is PyTorch Lightning zo ontworpen dat je meer tijd kunt besteden aan onderzoek en minder aan engineering. Een snelle refactor stelt je in staat om:
Bekijk voor meer informatie over deze bibliotheek de officiële website.
⭐ GitHub-sterren: 25,6K | Totaal aantal downloads: 18,2 miljoen
JAX is een high-performance numerieke computebibliotheek ontwikkeld door Google. Terwijl PyTorch de gebruiksvriendelijke standaard is, is JAX de "Formule 1-wagen" voor onderzoekers (waaronder DeepMind) die extreme snelheid nodig hebben. Het stelt NumPy-code in staat automatisch gecompileerd te worden om te draaien op accelerators (GPU’s/TPU’s) via XLA (Accelerated Linear Algebra).
De mogelijkheid om automatische differentiatie uit te voeren op native Python-functies maakt het favoriet voor het vanaf nul ontwikkelen van nieuwe algoritmen, met name in generatieve modellering en fysicasimulaties.
⭐ GitHub-sterren: 35K+ | Status: Onderzoeksstandaard
spaCy is een industriële, open-source NLP-bibliotheek in Python. spaCy blinkt uit in grootschalige informatie-extractietaken. Het is vanaf de grond opgebouwd in zorgvuldig geheugengebeheer met Cython. spaCy is de ideale bibliotheek als je applicatie enorme webdumps moet verwerken.
Features:
Wil je meer leren over spaCy, bekijk dan de officiële website of de GitHub-repository. Je kunt je ook snel vertrouwd maken met de functionaliteiten met dit handige spaCY-cheat sheet.
⭐ GitHub-sterren: 28K | Totaal aantal downloads: 81 miljoen
Hugging Face Transformers is een open-sourcebibliotheek van Hugging Face. Transformers stellen API’s in staat om eenvoudig state-of-the-art voorgetrainde modellen te downloaden en te trainen. Het gebruik van voorgetrainde modellen kan je rekenkosten en CO₂-voetafdruk verlagen en je tijd besparen doordat je niet vanaf nul hoeft te trainen. De modellen zijn geschikt voor diverse modaliteiten, waaronder:
De transformers-bibliotheek ondersteunt naadloze integratie tussen drie van de populairste deep learning-bibliotheken: PyTorch, TensorFlow en JAX. Je kunt je model in drie regels code trainen in het ene framework en het vervolgens laden voor inferentie met een ander. De architectuur van elke transformer is gedefinieerd in een losstaande Python-module, waardoor ze eenvoudig aan te passen zijn voor experimenten en onderzoek.
De bibliotheek is momenteel beschikbaar onder de Apache License 2.0.
Wil je meer leren over transformers, bekijk dan de officiële website of de GitHub-repository en lees onze tutorial over het gebruik van Transformers en Hugging Face.
⭐ GitHub-sterren: 119K | Totaal aantal downloads: 62 miljoen
LangChain is het industriestandaard orkestratieframework voor Large Language Models (LLM’s). Het stelt ontwikkelaars in staat om verschillende componenten aan elkaar te "ketenen", bijvoorbeeld een LLM (zoals GPT 5.2) te verbinden met andere bronnen van rekenkracht of kennis.
Het abstraheert de complexiteit van werken met prompts, zodat je eenvoudig "Agents" kunt bouwen die tools (zoals een rekenmachine, Google Zoeken of een Python REPL) kunnen gebruiken om meerstaps redeneringsproblemen op te lossen.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ GitHub-sterren: 123K+ | Status: GenAI Essential
Waar LangChain zich richt op redeneren, richt LlamaIndex zich op data. Het is het toonaangevende framework voor RAG (Retrieval-Augmented Generation). Het is gespecialiseerd in het inladen, indexeren en ophalen van je privédata (PDF’s, SQL-databases, Excel-sheets), zodat LLM’s er nauwkeurig vragen over kunnen beantwoorden.
In 2025 is "chatten met je documenten" een standaard bedrijfsvereiste en LlamaIndex levert de geoptimaliseerde datastructuren om dat efficiënt en zonder hallucinaties te doen.
⭐ GitHub-sterren: 35K+ | Status: RAG-standaard
Om LLM’s informatie te laten "onthouden", heb je een Vector Database nodig. ChromaDB is de open-source, AI-native vector database die de standaard is geworden voor Python-ontwikkelaars. Het handelt de complexiteit af van het embedden van tekst (woorden omzetten naar lijsten met getallen) en het opslaan ervan voor semantisch zoeken.
In tegenstelling tot traditionele SQL-databases die exacte zoekwoorden matchen, kun je met ChromaDB zoeken op betekenis, waardoor het de back-end voor langetermijngeheugen is in moderne AI-toepassingen.
⭐ GitHub-sterren: 25K+ | Status: Vector Store Standard
Het kiezen van de juiste Python-bibliotheek voor je data science-, machine learning- of NLP-taken is een cruciale beslissing die een significante impact kan hebben op het succes van je projecten. Met een enorme hoeveelheid beschikbare bibliotheken is het essentieel om verschillende factoren te overwegen om een weloverwogen keuze te maken. Hier zijn belangrijke overwegingen die je kunnen helpen:
Door deze factoren zorgvuldig te evalueren, kun je een weloverwogen beslissing nemen bij het selecteren van Python-bibliotheken voor je data science- of machine learning-werk. Onthoud dat de beste bibliotheek voor je project afhangt van de specifieke vereisten en doelen die je wilt bereiken.
Wil je je carrière in data science een vliegende start geven? Volg de Data Scientist in Python career track.
Cursussen voor Python-bibliotheken bij DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
