
Course
Extreme Gradient Boosting with XGBoost
4 hr
60.7K
Python is one of the most popular programming languages used across various tech disciplines, especially in data science and machine learning. Python offers an easy-to-code, object-oriented, high-level language with a broad collection of libraries for a multitude of use cases. It has over 200,000 libraries.
One of the reasons Python is so valuable to data science is its vast collection of data manipulation, data visualization, machine learning, and deep learning libraries. Since Python has such a rich ecosystem of data science libraries, it is almost impossible to cover everything in one article. The list of top libraries here is focused on only five main areas:
There are many other areas that are not covered in this list; for example, MLOps, Big Data, and Computer Vision. The list in this blog follows no particular order and is not intended to be seen in any way as a type of ranking.
NumPy is one of the most broadly used open-source Python libraries and is mainly used for scientific computation. Its built-in mathematical functions enable lightning-speed computation and can support multidimensional data and large matrices. It is also used in linear algebra. NumPy Array is often used preferentially over lists as they use less memory and are more convenient and efficient.
According to NumPy’s website, it is an open-source project aiming to enable numerical computing with Python. It was created in 2005 and built on the early work of the Numeric and Numarray libraries. One of NumPy’s great advantages is that it has been released under the modified BSD license, and thus it will always be free for all to use.
NumPy is developed openly on GitHub with the consensus of the NumPy and wider scientific Python community. You can learn more about it in our introductory Numpy course.
⭐ GitHub Stars: 25K | Total Downloads: 2.4 billion
Pandas is an open-source library commonly used in data science. It is primarily used for data analysis, data manipulation, and data cleaning. Pandas allow for simple data modeling and data analysis operations without needing to write a lot of code. As stated on their website, pandas is a fast, powerful, flexible, and easy-to-use open-source data analysis and manipulation tool. Some key features of this library include:
Getting started with pandas is simple and straightforward. You can check out DataCamp's Analyzing Police Activity with pandas to learn how to use pandas on real-world data sets.
⭐ GitHub Stars: 41K | Total Downloads: 1.6 billion
While Pandas remains the default for small data, Polars has become the standard for high-performance data processing. Written in Rust, it uses a "lazy evaluation" engine to process datasets (10GB–100GB+) that would normally crash RAM-limited machines. Unlike Pandas, which executes operations sequentially, Polars optimizes queries end-to-end and runs them in parallel across all available CPU cores.
It is designed to be a drop-in upgrade for heavy workloads, offering syntax that is often more readable and 10–50x faster than traditional DataFrames.
Here's one code example of leading a filtered, grouped, and aggregated selection from a giant CSV dataset:
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ GitHub Stars: 40K+ | Status: High-Performance Standard
Matplotlib is an extensive library for creating fixed, interactive, and animated Python visualizations. A large number of third-party packages extend and build on Matplotlib’s functionality, including several higher-level plotting interfaces (Seaborn, HoloViews, ggplot, etc.)
Matplotlib is designed to be as functional as MATLAB, with the additional benefit of being able to use Python. It also has the advantage of being free and open source. It allows the user to visualize data using a variety of different types of plots, including but not limited to scatterplots, histograms, bar charts, error charts, and boxplots. What's more, all visualizations can be implemented with just a few lines of code.
Example Plots Developed using Matplotlib
Get started in Matplotlib with this step-by-step tutorial.
⭐ GitHub Stars: 18.7K | Total Downloads: 653 million
Another popular Matplotlib-based Python data visualization framework, Seaborn is a high-level interface for creating aesthetically appealing and valuable statistical visuals which are crucial for studying and comprehending data. This Python library is closely connected with both NumPy and pandas data structures. The driving principle behind Seaborn is to make visualization an essential component of data analysis and exploration; thus, its plotting algorithms use data frames that encompass entire datasets.
Seaborn Example Gallery
This Seaborn tutorial for beginners is a great resource to help you get acquainted with this dynamic visualization library.
⭐ GitHub Stars: 11.6K | Total Downloads: 180 million
The hugely popular open-source graphing library Plotly can be used to create interactive data visualizations. Plotly is built on top of the Plotly JavaScript library (plotly.js) and can be used to create web-based data visualizations that can be saved as HTML files or displayed in Jupyter notebooks and web applications using Dash.
It provides more than 40 unique chart types, such as scatter plots, histograms, line charts, bar charts, pie charts, error bars, box plots, multiple axes, sparklines, dendrograms, and 3-D charts. Plotly also offers contour plots, which are not that common in other data visualization libraries.
If you want interactive visualizations or dashboard-like graphics, Plotly is a good alternative to Matplotlib and Seaborn. It is currently available for use under the MIT license.
You can start mastering Plotly today with this Plotly visualization course.
⭐ GitHub Stars: 14.7K | Total Downloads: 190 million
The terms machine learning and scikit-learn are inseparable. Scikit-learn is one of the most used machine learning libraries in Python. Built on NumPy, SciPy, and Matplotlib, it is an open-source Python library that is commercially usable under the BSD license. It is a simple and efficient tool for predictive data analysis tasks.
Initially launched in 2007 as a Google Summer of Code project, Scikit-learn is a community-driven project; however, institutional and private grants help to ensure its sustainability.
The best thing about scikit-learn is that it is very easy to use.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Credit: Code reproduced from the official documentation of scikit-learn.
You can try out scikit-learn yourself with this beginning scikit-learn tutorial.
⭐ GitHub Stars: 57K | Total Downloads: 703 million
Gone are the days when Data Scientists only delivered static PDF reports. Streamlit turns Python scripts into interactive, shareable web applications in minutes. It requires no knowledge of HTML, CSS, or JavaScript. It is widely used in 2025 to build internal tools, dashboard prototypes, and interactive model demos for stakeholders.
With simple API calls like st.write() and st.slider(), you can build a frontend that reacts to data changes in real-time, bridging the gap between analysis and engineering.
⭐ GitHub Stars: 42K+ | Status: Essential for Delivery
Originally a web development tool, Pydantic is now a cornerstone of the AI stack. It performs data validation and settings management using Python type annotations. In the era of LLMs, ensuring that data (and model outputs) strictly match a specific schema is critical.
Pydantic is the engine powering libraries like LangChain and Hugging Face, ensuring that the messy JSON outputs from AI models are coerced into structured, valid Python objects that won't break your downstream code.
⭐ GitHub Stars: 26K+ | Status: Critical Infrastructure
LightGBM is an immensely popular open-source gradient boosting library that employs tree-based algorithms. It offers the following advantages:
It can be used for both supervised classification and regression tasks. You can check out the official documentation or their GitHub to learn more about this amazing framework.
⭐ GitHub Stars: 15.8K | Total Downloads: 162 million
XGBoost is another widely-used distributed gradient boosting library created to be portable, flexible, and efficient. It enables the implementation of machine learning algorithms within the gradient boosting framework. XGBoost offers (GBDT) gradient boosted decision trees, a parallel tree boosting that offers solutions to many data science problems quickly and accurately. The same code runs on major distributed environments (Hadoop, SGE, MPI) and can solve innumerable problems.
XGBoost has gained significant popularity over the last few years as a result of helping individuals and teams win virtually every Kaggle structured data competition. XGBoost’s advantages include:
XGBoost has been developed and maintained by active community members and is licensed for use under the Apache license. This XGBoost tutorial is a great resource if you'd like to learn more.
⭐ GitHub Stars: 25.2K | Total Downloads: 179 million
Catboost is a fast, scalable, high-performance gradient boosting on decision trees library used for ranking, classification, regression, and other machine learning tasks for Python, R, Java, and C++. It supports computation on CPU and GPU.
As the successor of the MatrixNet algorithm, it is widely used for ranking tasks, forecasting, and making recommendations. Thanks to its universal character, it can be applied across a wide range of areas and to a variety of problems.
The advantages of CatBoost according to their repository are:
⭐ GitHub Stars: 7.5K | Total Downloads: 53 million
Statsmodels provides classes and functions that allow users to estimate various statistical models, conduct statistical tests, and do statistical data exploration. A comprehensive list of result statistics is then provided for each estimator. The accuray of results can then be tested against existing statistical packages.
Most test results in the library have been verified with at least one other statistical package: R, Stata or SAS. Some features of statsmodels are:
This beginning statsmodels course is an excellent place to start if you'd like to learn more.
⭐ GitHub Stars: 9.2K | Total Downloads: 161 million
The RAPIDS suite of open-source software libraries executes end-to-end data science and analytics pipelines entirely on GPUs. It seamlessly scales from GPU workstations to multi-GPU servers and multi-node clusters with Dask. The project is supported by NVIDIA and also relies on Numba, Apache Arrow, and many other open-source projects.
cuDF is a GPU DataFrame library used to load, join, aggregate, filter, and otherwise manipulate data. It was developed based on the columnar memory format found in Apache Arrow. It provides a pandas-like API that will be familiar to data engineers & data scientists, which allows them to easily accelerate their workflows without going into the details of CUDA programming.
cuML is a suite of libraries that implements machine learning algorithms and mathematical primitive functions that share compatible APIs with other RAPIDS projects. It enables data scientists, researchers, and software engineers to run traditional tabular ML tasks on GPUs without going into the details of CUDA programming. cuML's Python API usually matches the scikit-learn API.
This open-source hyperparameter optimization framework is used primarily to automate hyperparameter searches. It uses Python loops, conditionals, and syntax to automatically look for optimal hyperparameters and can search large spaces and prune unpromising trials for swifter results. Best of all, it is easy to parallelize and scale on large datasets.
Key features as per their GitHub repository:
⭐ GitHub Stars: 9.1K | Total Downloads: 18 million
This hugely popular, open-source machine learning library automates machine learning workflows in Python using very little code. It is an end-to-end tool for model management and machine learning that can dramatically accelerate the experiment cycle.
Compared to other open-source machine learning libraries, PyCaret offers a low-code solution that can replace hundreds of lines of code with a mere few. This makes experiments exponentially fast and efficient.
PyCaret is currently available for use under the MIT license. To learn more about PyCaret, you can check out the official documentation or their GitHub repository or check out this introductory PyCaret tutorial.
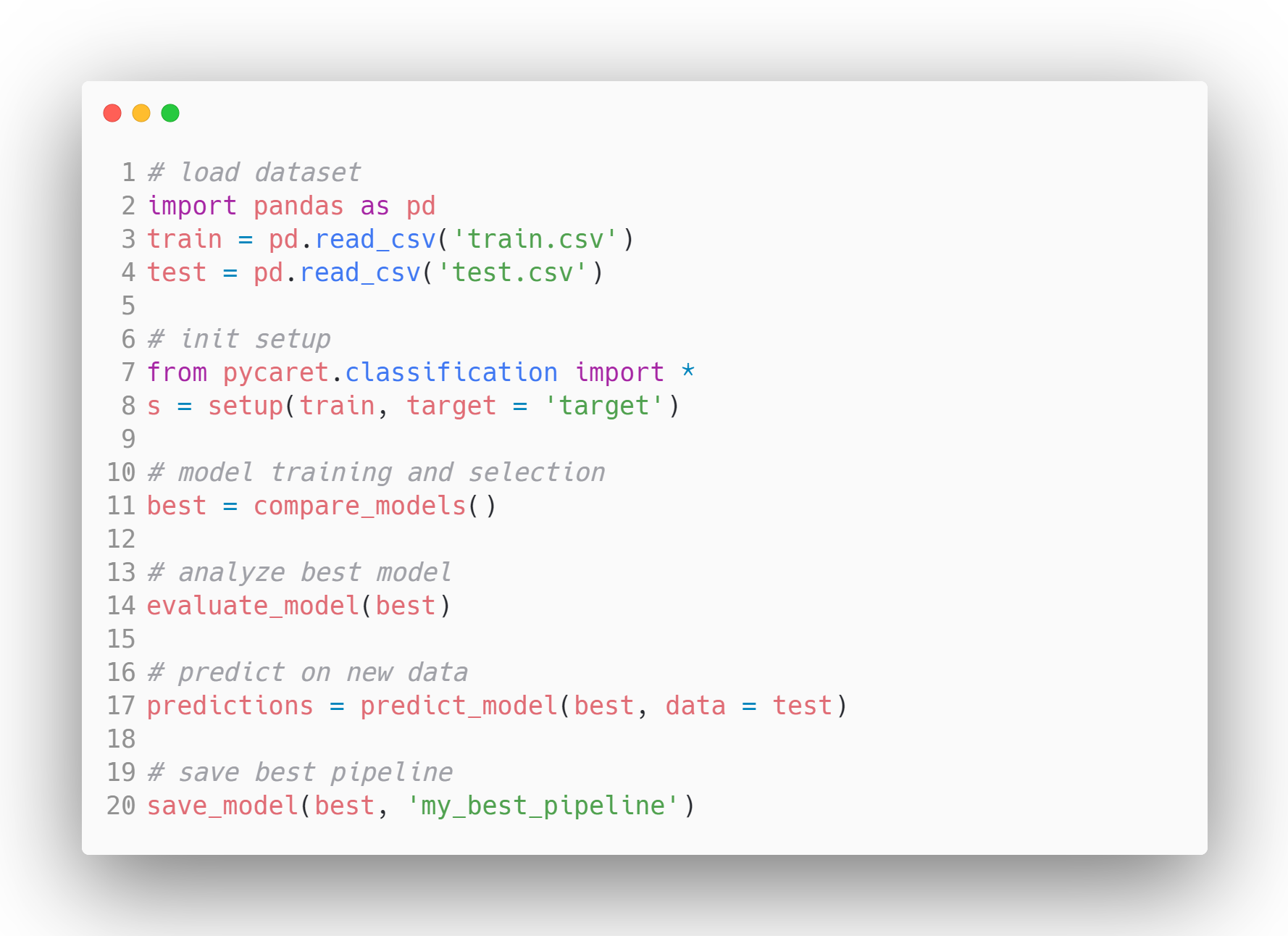
Example Model Workflow in PyCaret - Source
⭐ GitHub Stars: 8.1K | Total Downloads: 3.9 million
H2O is a machine learning and predictive analytics platform that enables the construction of machine learning models on big data. It also provides easy productionalization of those models in an enterprise environment.
H2O’s core code is written in Java. The algorithms use the Java Fork/Join framework for multi-threading and are implemented on top of H2O’s distributed Map/Reduce framework.
H2O is licensed under the Apache License, Version 2.0, and is available for Python, R, and Java languages. To learn more about H2O AutoML, check out their official documentation.
⭐ GitHub Stars: 10.6K | Total Downloads: 15.1 million
Auto-sklearn is an automated machine learning toolkit and a suitable substitute for a scikit-learn model. It performs hyperparameter tuning and algorithm selection automatically, saving considerable time for machine learning practitioners. Its design reflects recent advances in meta-learning, ensemble construction, and Bayesian optimization.
Built as an add-on to scikit-learn, auto-sklearn uses a Bayesian Optimization search procedure to identify the best-performing model pipeline for a given dataset.
It is extremely easy to use auto-sklearn, and it can be employed for both supervised classification and regression tasks.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Source: Example reproduced from official documentation of auto-sklearn.
To learn more about auto-sklearn, check out their GitHub repository.
⭐ GitHub Stars: 7.3K | Total Downloads: 675K
FLAML is a lightweight Python library that automatically identifies accurate machine learning models. It selects learners and hyperparameters automatically, saving machine learning practitioners considerable time and effort. According to their GitHub repository, some features of FLAML are:
With only three lines of code, you can get a scikit-learn style estimator with this fast AutoML engine.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Source: Example reproduced from official GitHub repository
⭐ GitHub Stars: 3.5K | Total Downloads: 456K
While other AutoML libraries focus on speed, AutoGluon (developed by Amazon) focuses on robustness and state-of-the-art accuracy. It is famous for its "multi-layer stack ensembling" strategy, which often allows it to outperform human-tuned models on tabular data benchmarks.
It supports not just tabular data, but also multimodal problems. That means it allows you to train a single predictor on a dataset containing columns of text, images, and numbers simultaneously without complex feature engineering.
The following code snippet shows you the AutoGluon syntax:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ GitHub Stars: 10K+ | Status: Best-in-Class Accuracy
TensorFlow is a popular open-source library for high-performance numerical computation developed by the Google Brain team at Google, and a mainstay in the field of deep learning research.
As stated on the official website, TensorFlow is an end-to-end open-source platform for machine learning. It offers an extensive, versatile assortment of tools, libraries, and community resources for machine learning researchers and developers.
Some of the features of TensorFlow that made it a popular and widely used deep learning library:
To learn more about TensorFlow, check out their official guide or the GitHub repository or try using it yourself by following along with this step-by-step TensorFlow tutorial.
⭐ GitHub Stars: 180K | Total Downloads: 384 million
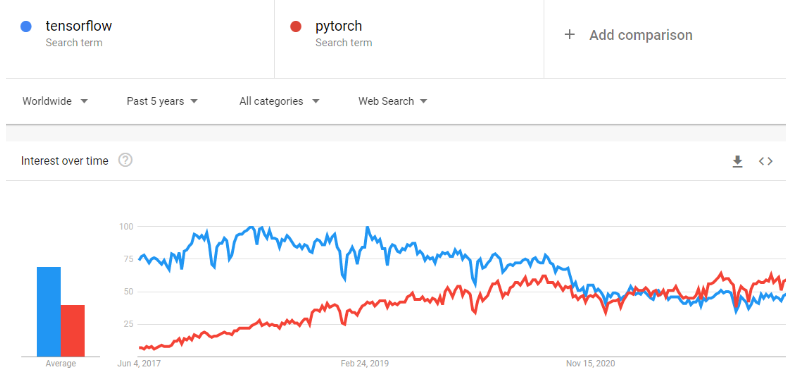
PyTorch is a machine learning framework that dramatically speeds up the journey from research prototyping to production deployment. It is an optimized tensor library for deep learning using GPUs and CPUs, and is considered to be an alternative to TensorFlow. Over time, PyTorch’s popularity has grown to overtake TensorFlow on Google trends.
It was developed and is maintained by Facebook and is currently available for use under BSD.
According to the official website, key features of PyTorch are:
⭐ GitHub Stars: 74K | Total Downloads: 119 million
FastAI is a deep learning library offering users high-level components that can generate state-of-the-art results effortlessly. It also includes low-level components that can be interchanged to develop new approaches. It aims to do both of these things without substantially compromising its ease of use, flexibility, or performance.
Features:
To learn more about the project, check out their official documentation.
⭐ GitHub Stars: 25.1K | Total Downloads: 6.1 million
Keras is a deep learning API designed for human beings, not machines. Keras follows best practices for reducing cognitive load: it offers consistent and simple APIs, minimizes the number of user actions required for common use cases, and provides clear and actionable error messages. Keras is so intuitive that TensorFlow adopted Keras as their default API in the TF 2.0 release.
Keras offers a simpler mechanism for expressing neural networks and also includes some of the best tools for developing models, data set processing, graph visualization, and more.
Features:
To learn more about the Keras, check out their official documentation or take this introductory course: Deep Learning with Keras.
⭐ GitHub Stars: 60.2K | Total Downloads: 163 million
PyTorch Lightning offers a high-level interface for PyTorch. Its high-performance and lightweight framework can organize PyTorch code to decouple the research from the engineering, making deep learning experiments simpler to understand and reproduce. It was developed to create scalable deep learning models that can seamlessly run on distributed hardware.
According to the official website, PyTorch lightning is designed so that you can spend more time on research and less on engineering. A quick refactor will allow you to:
To learn more about this library, check out its official website.
⭐ GitHub Stars: 25.6K | Total Downloads: 18.2 million
JAX is a high-performance numerical computing library developed by Google. While PyTorch is the user-friendly standard, JAX is the "Formula 1 car" used by researchers (including DeepMind) who need extreme speed. It allows NumPy code to be automatically compiled to run on accelerators (GPUs/TPUs) via XLA (Accelerated Linear Algebra).
Its ability to perform automatic differentiation on native Python functions makes it a favorite for developing new algorithms from scratch, particularly in generative modeling and physics simulations.
⭐ GitHub Stars: 35K+ | Status: Research Standard
spaCy is an industrial-strength, open-source natural language processing library in Python. spaCy excels at large-scale information extraction tasks. It is written from the ground up in carefully memory-managed Cython. spaCy is the ideal library to use if your application needs to process massive web dumps.
Features:
To learn more about spaCy, check out their official website or the GitHub repository. You can also familarize yourself with its functionalities quicky using this handy spaCY cheat sheet.
⭐ GitHub Stars: 28K | Total Downloads: 81 million
Hugging Face Transformers is an open-source library by Hugging Face. Transformers allow APIs to easily download and train state-of-the-art pre-trained models. Using pre-trained models can reduce your compute costs, carbon footprint, and save you time from having to train a model from scratch. The models are suitable for a variety of modalities, including:
The transformers’ library supports seamless integration between three of the most popular deep learning libraries: PyTorch, TensorFlow, and JAX. You can train your model in three lines of code in one framework, and load it for inference with another. The architecture of each transformer is defined within a standalone Python module, making them easily customizable for experiments and research.
The library is currently available for use under the Apache License 2.0.
To learn more about transformers, check out their official website or the GitHub repository and check out our tutorial on using Transformers and Hugging Face.
⭐ GitHub Stars: 119K | Total Downloads: 62 million
LangChain is the industry-standard orchestration framework for Large Language Models (LLMs). It allows developers to "chain" different components together, e.g., connecting an LLM (like GPT 5.2) to other sources of computation or knowledge.
It abstracts the complexity of working with prompts, allowing you to easily build "Agents" that can use tools (like a calculator, Google Search, or a Python REPL) to solve multi-step reasoning problems.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ GitHub Stars: 123K+ | Status: GenAI Essential
While LangChain handles reasoning, LlamaIndex handles data. It is the leading framework for RAG (Retrieval-Augmented Generation). It specializes in ingesting, indexing, and retrieving your private data (PDFs, SQL databases, Excel sheets) so that LLMs can answer questions about it accurately.
In 2025, "chatting with your documents" is a standard business requirement, and LlamaIndex provides the optimized data structures to make that efficient and hallucination-free.
⭐ GitHub Stars: 35K+ | Status: RAG Standard
To make LLMs "remember" information, you need a Vector Database. ChromaDB is the open-source, AI-native vector database that has become the default for Python developers. It handles the complexity of embedding text (converting words into lists of numbers) and storing them for semantic search.
Unlike traditional SQL databases that match exact keywords, ChromaDB allows you to query by meaning, making it the long-term memory backend for modern AI applications.
⭐ GitHub Stars: 25K+ | Status: Vector Store Standard
Selecting the right Python library for your data science, machine learning, or natural language processing tasks is a crucial decision that can significantly impact the success of your projects. With a vast array of libraries available, it's essential to consider various factors to make an informed choice. Here are key considerations to guide you:
By carefully evaluating these factors, you can make an informed decision when selecting Python libraries for your data science or machine learning endeavors. Remember that the best library for your project depends on the specific requirements and goals you aim to achieve.
To kickstart your career in data science, take the Data Scientist in Python career track.
Courses for Python Libraries at DataCamp
Course
Course
Course
blog
Javier Canales Luna
14 min
blog
Bekhruz Tuychiev
10 min
blog
Thaylise Nakamoto
9 min
blog
Javier Canales Luna
13 min
Tutorial
Adel Nehme
Tutorial
Abid Ali Awan
