
Cours
Extreme Gradient Boosting avec XGBoost
4 h
60.7K
Python est l'un des langages de programmation les plus populaires utilisés dans diverses disciplines technologiques, en particulier dans les domaines de la science des données et de l'apprentissage automatique. Python est un langage de programmation de haut niveau, orienté objet, facile à coder, qui dispose d'une vaste collection de bibliothèques pour une multitude de cas d'utilisation. Elle compte plus de 200 000 bibliothèques.
L'une des raisons pour lesquelles Python est si précieux pour la science des données réside dans sa vaste collection de bibliothèques dédiées à la manipulation et à la visualisation des données, ainsi qu'à l'apprentissage automatique et profond. Étant donné que Python dispose d'un écosystème si riche en bibliothèques de science des données, il est pratiquement impossible de tout couvrir dans un seul article. La liste des meilleures bibliothèques présentée ici se concentre sur cinq domaines principaux :
Il existe de nombreux autres domaines qui ne sont pas abordés dans cette liste, tels que le MLOps, le Big Data et la vision par ordinateur. La liste présentée dans ce blog n'est pas classée dans un ordre particulier et ne doit en aucun cas être considérée comme un classement.
NumPy est l'une des bibliothèques Python open source les plus utilisées et sert principalement au calcul scientifique. Ses fonctions mathématiques intégrées permettent des calculs extrêmement rapides et prennent en charge les données multidimensionnelles et les matrices de grande taille. Il est également utilisé en algèbre linéaire. Les tableaux NumPy sont souvent préférés aux listes, car ils utilisent moins de mémoire et sont plus pratiques et efficaces.
Selon le site web de NumPy, il s'agit d'un projet open source visant à permettre le calcul numérique avec Python. Elle a été créée en 2005 et s'appuie sur les travaux antérieurs des bibliothèques Numeric et Numarray. L'un des principaux avantages de NumPy est qu'il a été publié sous licence BSD modifiée, ce qui garantit qu'il restera toujours libre d'utilisation pour tous.
NumPy est développé de manière ouverte sur GitHub avec le consensus de la communauté NumPy et de la communauté scientifique Python au sens large. Vous pouvez en apprendre davantage à ce sujet dans notre cours d'introduction à Numpy.
⭐ Étoiles GitHub : 25K | Nombre total de téléchargements : 2,4 milliards
Pandas est une bibliothèque open source couramment utilisée en science des données. Il est principalement utilisé pour l'analyse, la manipulation et le nettoyage des données. Pandas permet de réaliser facilement des opérations de modélisation et d'analyse de données sans avoir à écrire beaucoup de code. Comme indiqué sur leur site web, pandas est un outil open source d'analyse et de manipulation de données rapide, puissant, flexible et facile à utiliser. Voici quelques-unes des principales fonctionnalités de cette bibliothèque :
La prise en main de pandas est simple et intuitive. Nous vous invitons à consulter le cours « Analyzing Police Activity with pandas » (Analyse des activités policières avec pandas) de DataCamp pour apprendre à utiliser pandas sur des ensembles de données réels.
⭐ Étoiles GitHub : 41K | Nombre total de téléchargements : 1,6 milliard
Alors que Pandas reste la solution par défaut pour les petites données, Polars est devenu la norme pour le traitement haute performance des données. Écrit en Rust, il utilise un moteur d'« évaluation paresseuse » pour traiter des ensembles de données (10 Go à 100 Go et plus) qui entraîneraient normalement le plantage des machines dont la mémoire vive est limitée. Contrairement à Pandas, qui exécute les opérations de manière séquentielle, Polars optimise les requêtes de bout en bout et les exécute en parallèle sur tous les cœurs de processeur disponibles.
Il est conçu pour être une mise à niveau facile à intégrer pour les charges de travail importantes, offrant une syntaxe souvent plus lisible et 10 à 50 fois plus rapide que les DataFrame traditionnels.
Voici un exemple de code permettant d'effectuer une sélection filtrée, groupée et agrégée à partir d'un ensemble de données CSV volumineux :
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ Étoiles GitHub : 40K+ | Statut : Norme haute performance
Matplotlib est une bibliothèque complète permettant de créer des visualisations Python fixes, interactives et animées. Un grand nombre de paquets tiers étendent et développent les fonctionnalités de Matplotlib, notamment plusieurs interfaces graphiques de haut niveau (Seaborn, HoloViews, ggplot, etc.).
Matplotlib est conçu pour être aussi fonctionnel que MATLAB, avec l'avantage supplémentaire de pouvoir utiliser Python. Il présente également l'avantage d'être gratuit et open source. Il permet à l'utilisateur de visualiser les données à l'aide de différents types de graphiques, notamment des nuages de points, des histogrammes, des graphiques à barres, des graphiques d'erreurs et des boîtes à moustaches. De plus, toutes les visualisations peuvent être mises en œuvre à l'aide de quelques lignes de code seulement.
Exemples de graphiques développés à l'aide de Matplotlib
Commencez à utiliser Matplotlib grâce à ce tutoriel étape par étape.
⭐ Étoiles GitHub : 18,7 K | Nombre total de téléchargements : 653 millions
Autre framework Python populaire basé sur Matplotlib pour la visualisation de données, Seaborn est une interface de haut niveau permettant de créer des visuels statistiques esthétiques et pertinents, essentiels pour étudier et comprendre les données. Cette bibliothèque Python est étroitement liée aux structures de données NumPy et pandas. Le principe directeur de Seaborn est de faire de la visualisation un élément essentiel de l'analyse et de l'exploration des données ; ainsi, ses algorithmes de graphique utilisent des cadres de données qui englobent l'ensemble des ensembles de données.
Galerie d'exemples Seaborn
Ce tutoriel Seaborn pour débutants constitue une excellente ressource pour vous familiariser avec cette bibliothèque de visualisation dynamique.
⭐ Étoiles GitHub : 11,6 K | Nombre total de téléchargements : cent quatre-vingts millions
La bibliothèque graphique open source très populaire Plotly peut être utilisée pour créer des graphiques interactifs de données. Plotly est développé à partir de la bibliothèque JavaScript Plotly (plotly.js) et peut être utilisé pour créer des graphiques de données sur le Web qui peuvent être enregistrés sous forme de fichiers HTML ou affichés dans des notebooks Jupyter et des applications Web à l'aide de Dash.
Il propose plus de 40 types de graphiques uniques, tels que des nuages de points, des histogrammes, des graphiques linéaires, des graphiques à barres, des graphiques circulaires, des barres d'erreur, des boîtes à moustaches, des axes multiples, des graphiques sparkline, des dendrogrammes et des graphiques en 3D. Plotly propose également des graphiques de contours, qui ne sont pas très courants dans les autres bibliothèques de visualisation de données.
Si vous recherchez des graphiques interactifs ou des graphiques de type tableau de bord, Plotly constitue une alternative intéressante à Matplotlib et Seaborn. Il est actuellement disponible pour utilisation sous licence MIT.
Vous pouvez commencer à maîtriser Plotly dès aujourd'hui grâce à ce cours sur la visualisation des graphiques Plotly.
⭐ Étoiles GitHub : 14,7 K | Nombre total de téléchargements : 190 millions
Les termes « apprentissage automatique » et « scikit-learn » sont indissociables. Scikit-learn est l'une des bibliothèques d'apprentissage automatique les plus utilisées en Python. Basée sur NumPy, SciPy et Matplotlib, il s'agit d'une bibliothèque Python open source utilisable à des fins commerciales sous licence BSD. Il s'agit d'un outil simple et efficace pour les tâches d'analyse prédictive des données.
Lancé initialement en 2007 dans le cadre du projet Google Summer of Code, Scikit-learn est un projet communautaire ; cependant, des subventions institutionnelles et privées contribuent à assurer sa pérennité.
Le principal avantage de scikit-learn réside dans sa grande facilité d'utilisation.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Crédit : Code reproduit à partir de la documentation officielle de scikit-learn.
Vous pouvez vous-même essayer scikit-learn grâce à ce tutoriel d'introduction à scikit-learn.
⭐ Étoiles GitHub : 57K | Nombre total de téléchargements : sept cent trois millions
L'époque où les scientifiques des données ne fournissaient que des rapports PDF statiques est révolue. Streamlit transforme les scripts Python en applications web interactives et partageables en quelques minutes. Il n'est pas nécessaire de posséder des connaissances en HTML, CSS ou JavaScript. En 2025, il est largement utilisé pour créer des outils internes, des prototypes de tableaux de bord et des démonstrations de modèles interactifs destinés aux parties prenantes.
Grâce à des appels API simples tels que st.write() et st.slider(), vous pouvez créer une interface utilisateur qui réagit en temps réel aux modifications des données, comblant ainsi le fossé entre l'analyse et l'ingénierie.
⭐ Étoiles GitHub : 42K+ | Statut : Indispensable pour la livraison
Initialement conçu comme un outil de développement web, Pydantic est désormais un élément essentiel de la pile IA. Il effectue la validation des données et la gestion des paramètres à l'aide d'annotations de type Python. À l'ère des LLM, il est essentiel de s'assurer que les données (et les résultats des modèles) correspondent strictement à un schéma spécifique.
Pydantic est le moteur qui alimente des bibliothèques telles que LangChain et Hugging Face, garantissant que les sorties JSON complexes des modèles d'IA sont converties en objets Python structurés et valides qui ne perturberont pas votre code en aval.
⭐ Étoiles GitHub : 26K+ | Statut : Infrastructure critique
LightGBM est une bibliothèque open source de gradient boosting extrêmement populaire qui utilise des algorithmes basés sur des arbres. Il présente les avantages suivants :
Il peut être utilisé à la fois pour des tâches de classification supervisée et de régression. Vous pouvez consulter la documentation officielle ou leur GitHub pour en savoir plus sur ce formidable framework.
⭐ Étoiles GitHub : 15,8 K | Nombre total de téléchargements : 162 millions
XGBoost est une autre bibliothèque de gradient boosting distribuée largement utilisée, conçue pour être portable, flexible et efficace. Il permet la mise en œuvre d'algorithmes d'apprentissage automatique dans le cadre du gradient boosting. XGBoost propose des arbres de décision à gradient boosté (GBDT), un boosting d'arbres parallèles qui offre des solutions rapides et précises à de nombreux problèmes liés à la science des données. Le même code fonctionne sur les principaux environnements distribués (Hadoop, SGE, MPI) et peut résoudre de nombreux problèmes.
XGBoost a acquis une grande popularité au cours des dernières années en aidant des individus et des équipes à remporter pratiquement tous les concours Kaggle sur les données structurées. Les avantages de XGBoost comprennent :
XGBoost a été développé et est maintenu par des membres actifs de la communauté. Il est distribué sous licence Apache. Ce tutoriel XGBoost constitue une excellente ressource si vous souhaitez approfondir vos connaissances.
⭐ Étoiles GitHub : 25,2 K | Nombre total de téléchargements : 179 millions
Catboost est une bibliothèque rapide, évolutive et hautement performante de gradient boosting sur les arbres de décision, utilisée pour le classement, la classification, la régression et d'autres tâches d'apprentissage automatique pour Python, R, Java et C++. Il prend en charge les calculs sur CPU et GPU.
En tant que successeur de l'algorithme MatrixNet, il est largement utilisé pour les tâches de classement, les prévisions et les recommandations. Grâce à son caractère universel, il peut être appliqué dans un large éventail de domaines et à divers problèmes.
Les avantages de CatBoost, selon leur référentiel, sont les suivants :
⭐ Étoiles GitHub : 7,5 K | Nombre total de téléchargements : 53 millions
Statsmodels fournit des classes et des fonctions qui permettent aux utilisateurs d'estimer divers modèles statistiques, d'effectuer des tests statistiques et d'explorer des données statistiques. Une liste complète des statistiques de résultats est ensuite fournie pour chaque estimateur. La précision des résultats peut ensuite être vérifiée à l'aide de progiciels statistiques existants.
La plupart des résultats des tests dans la bibliothèque ont été vérifiés à l'aide d'au moins un autre progiciel statistique : R, Stata ou SAS. Voici quelques fonctionnalités de statsmodels :
Ce cours d'introduction à statsmodels constitue un excellent point de départ si vous souhaitez approfondir vos connaissances.
⭐ Étoiles GitHub : 9,2 K | Nombre total de téléchargements : 161 millions
La suite de bibliothèques logicielles open source RAPIDS exécute des pipelines de science des données et d'analyse de bout en bout entièrement sur des GPU. Il s'adapte de manière transparente aux stations de travail GPU, aux serveurs multi-GPU et aux clusters multi-nœuds avec Dask. Ce projet bénéficie du soutien de NVIDIA et s'appuie également sur Numba, Apache Arrow et de nombreux autres projets open source.
cuDF est une bibliothèque GPU DataFrame utilisée pour charger, joindre, agréger, filtrer et manipuler des données. Il a été développé sur la base du format de mémoire en colonnes utilisé dans Apache Arrow. Il fournit une API de type pandas qui sera familière aux ingénieurs et scientifiques des données, leur permettant d'accélérer facilement leurs flux de travail sans entrer dans les détails de la programmation CUDA.
cuML est une suite de bibliothèques qui implémente des algorithmes d'apprentissage automatique et des fonctions mathématiques primitives qui partagent des API compatibles avec d'autres projets RAPIDS. Il permet aux scientifiques des données, aux chercheurs et aux ingénieurs logiciels d'exécuter des tâches traditionnelles de ML tabulaire sur des GPU sans entrer dans les détails de la programmation CUDA. L'API Python de cuML correspond généralement à l'API scikit-learn.
Ce cadre open source d'optimisation des hyperparamètres est principalement utilisé pour automatiser la recherche d'hyperparamètres. Il utilise des boucles, des conditions et la syntaxe Python pour rechercher automatiquement les hyperparamètres optimaux. Il est capable d'explorer de grands espaces et d'éliminer les essais peu prometteurs afin d'obtenir des résultats plus rapides. De plus, il est facile à paralléliser et à adapter à des ensembles de données volumineux.
Principales fonctionnalités selon leur référentiel GitHub:
⭐ Étoiles GitHub : 9,1K | Nombre total de téléchargements : 18 millions
Cette bibliothèque d'apprentissage automatique open source, très populaire, automatise les workflows d'apprentissage automatique en Python à l'aide d'un minimum de code. Il s'agit d'un outil complet pour la gestion des modèles et l'apprentissage automatique qui peut considérablement accélérer le cycle d'expérimentation.
Par rapport à d'autres bibliothèques open source d'apprentissage automatique, PyCaret propose une solution low-code qui permet de remplacer des centaines de lignes de code par quelques lignes seulement. Cela rend les expériences extrêmement rapides et efficaces.
PyCaret est actuellement disponible sous licence MIT. Pour en savoir plus sur PyCaret, vous pouvez consulter la documentation officielle ou leur dépôt GitHub, ou encore suivre ce tutoriel d'introduction à PyCaret.
Exemple de modèle de flux de travail dans PyCaret - Source
⭐ Étoiles GitHub : 8,1 K | Nombre total de téléchargements : 3,9 millions
H2O est une plateforme d'apprentissage automatique et d'analyse prédictive qui permet la construction de modèles d'apprentissage automatique sur le big data. Il facilite également la mise en production de ces modèles dans un environnement d'entreprise.
Le code principal de H2O est écrit en Java. Les algorithmes utilisent le framework Java Fork/Join pour le multithreading et sont implémentés sur le framework Map/Reduce distribué de H2O.
H2O est distribué sous licence Apache, version 2.0, et est disponible pour les langages Python, R et Java. Pour en savoir plus sur H2O AutoML, veuillez consulter leur documentation officielle.
⭐ Étoiles GitHub : 10,6 K | Nombre total de téléchargements : quinze millions et cent mille
Auto-sklearn est une boîte à outils d'apprentissage automatique automatisée et un substitut approprié au modèle scikit-learn. Il procède automatiquement au réglage des hyperparamètres et à la sélection des algorithmes, ce qui permet aux praticiens du machine learning de gagner un temps considérable. Sa conception reflète les avancées récentes en matière de méta-apprentissage, de construction d'ensembles et d'optimisation bayésienne.
Conçu comme un module complémentaire à scikit-learn, auto-sklearn utilise une procédure de recherche par optimisation bayésienne afin d'identifier le pipeline de modèles le plus performant pour un ensemble de données donné.
Auto-sklearn est extrêmement facile à utiliser et peut être employé à la fois pour des tâches de classification supervisée et de régression.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Source : Exemple tiré de la documentation officielle d'auto-sklearn.
Pour en savoir plus sur auto-sklearn, veuillez consulter leur référentiel GitHub.
⭐ Étoiles GitHub : 7,3 K | Nombre total de téléchargements : 675 000
FLAML est une bibliothèque Python légère qui identifie automatiquement les modèles d'apprentissage automatique précis. Il sélectionne automatiquement les apprenants et les hyperparamètres, ce qui permet aux praticiens du machine learning de gagner un temps considérable et d'économiser leurs efforts. Selon leur référentiel GitHub, certaines fonctionnalités de FLAML sont les suivantes :
Avec seulement trois lignes de code, vous pouvez obtenir un estimateur de type scikit-learn grâce à ce moteur AutoML rapide.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Source : Exemple reproduit à partir du référentiel GitHub officiel
⭐ Étoiles GitHub : 3,5 K | Nombre total de téléchargements : 456K
Alors que d'autres bibliothèques AutoML privilégient la rapidité, AutoGluon (développé par Amazon) met l'accent sur la robustesse et une précision de pointe. Il est réputé pour sa stratégie d'« assemblage multicouche », qui lui permet souvent de surpasser les modèles ajustés par des humains sur les benchmarks de données tabulaires.
Il prend en charge non seulement les données tabulaires, mais également les problèmes multimodaux. Cela signifie qu'il est possible de former un seul prédicteur sur un ensemble de données contenant simultanément des colonnes de texte, d'images et de chiffres sans avoir recours à une ingénierie complexe des caractéristiques.
L'extrait de code suivant illustre la syntaxe d'AutoGluon :
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ Étoiles GitHub : 10K+ | Statut : Précision de premier ordre
TensorFlow est une bibliothèque open source très appréciée pour le calcul numérique haute performance, développée par l'équipe Google Brain chez Google, et un pilier dans le domaine de la recherche sur l'apprentissage profond.
Comme indiqué sur le site officiel, TensorFlow est une plateforme open source de bout en bout pour l'apprentissage automatique. Il propose un large éventail d'outils, de bibliothèques et de ressources communautaires polyvalentes destinés aux chercheurs et développeurs dans le domaine de l'apprentissage automatique.
Certaines des fonctionnalités de TensorFlow qui en ont fait une bibliothèque d'apprentissage profond populaire et largement utilisée :
Pour en savoir plus sur TensorFlow, veuillez consulter leur guide officiel ou le référentiel GitHub, ou bien essayez de l'utiliser vous-même en suivant ce tutoriel TensorFlow étape par étape.
⭐ Étoiles GitHub : 180K | Nombre total de téléchargements : 384 millions
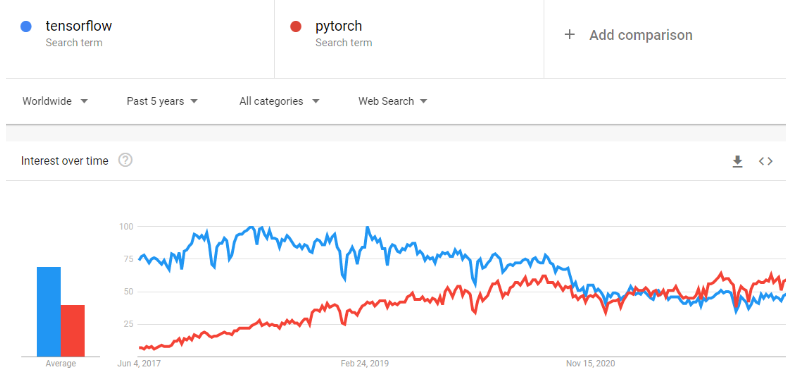
PyTorch est un framework d'apprentissage automatique qui accélère considérablement le processus, depuis le prototypage de la recherche jusqu'au déploiement en production. Il s'agit d'une bibliothèque tensorielle optimisée pour l'apprentissage profond utilisant des processeurs graphiques (GPU) et des processeurs centraux (CPU), considérée comme une alternative à TensorFlow. Au fil du temps, la popularité de PyTorch a augmenté au point de dépasser celle de TensorFlow sur Google Trends.
Il a été développé et est maintenu par Facebook et est actuellement disponible pour utilisation sous licence BSD.
Selon le site officiel, les principales fonctionnalités de PyTorch sont les suivantes :
⭐ Étoiles GitHub : 74K | Nombre total de téléchargements : cent dix-neuf millions
FastAI est une bibliothèque d'apprentissage profond qui fournit aux utilisateurs des composants de haut niveau permettant d'obtenir facilement des résultats de pointe. Il comprend également des composants de bas niveau qui peuvent être interchangés pour développer de nouvelles approches. Il vise à accomplir ces deux objectifs sans compromettre de manière significative sa facilité d'utilisation, sa flexibilité ou ses performances.
Caractéristiques :
Pour en savoir plus sur le projet, veuillez consulter leur documentation officielle.
⭐ Étoiles GitHub : 25,1 K | Nombre total de téléchargements : six millions cent mille
Keras est une API d'apprentissage profond conçue pour les humains, et non pour les machines. Keras respecte les meilleures pratiques en matière de réduction de la charge cognitive : il propose des API cohérentes et simples, minimise le nombre d'actions requises de la part de l'utilisateur pour les cas d'utilisation courants et fournit des messages d'erreur clairs et exploitables. Keras est si intuitif que TensorFlow l'a adopté comme API par défaut dans la version TF 2.0.
Keras propose un mécanisme plus simple pour exprimer les réseaux neuronaux et comprend également certains des meilleurs outils pour développer des modèles, traiter des ensembles de données, visualiser des graphiques, etc.
Caractéristiques :
Pour en savoir plus sur Keras, veuillez consulter leur documentation officielle ou suivre ce cours d'introduction : Apprentissage profond avec Keras.
⭐ Étoiles GitHub : 60,2 K | Nombre total de téléchargements : 163 millions
PyTorch Lightning fournit une interface de haut niveau pour PyTorch. Son infrastructure performante et légère permet d'organiser le code PyTorch afin de dissocier la recherche de l'ingénierie, rendant ainsi les expériences d'apprentissage profond plus simples à comprendre et à reproduire. Il a été développé pour créer des modèles d'apprentissage profond évolutifs pouvant fonctionner de manière transparente sur du matériel distribué.
Selon le site officiel, PyTorch Lightning est conçu pour vous permettre de consacrer davantage de temps à la recherche et moins à l'ingénierie. Une refonte rapide vous permettra de :
Pour en savoir plus sur cette bibliothèque, veuillez consulter son site Web officiel.
⭐ Étoiles GitHub : 25,6 K | Nombre total de téléchargements : 18,2 millions
JAX est une bibliothèque de calcul numérique haute performance développée par Google. Alors que PyTorch est la norme conviviale, JAX est la « voiture de Formule 1 » utilisée par les chercheurs (y compris DeepMind) qui ont besoin d'une vitesse extrême. Il permet au code NumPy d'être automatiquement compilé pour fonctionner sur des accélérateurs (GPU/TPU) via XLA (Accelerated Linear Algebra).
Sa capacité à effectuer une différenciation automatique sur les fonctions Python natives en fait un outil de prédilection pour le développement de nouveaux algorithmes à partir de zéro, en particulier dans le domaine de la modélisation générative et des simulations physiques.
⭐ Étoiles GitHub : 35K+ | Statut : Norme de recherche
spaCy est une bibliothèque open source de traitement du langage naturel en Python, conçue pour un usage industriel. spaCy excelle dans les tâches d'extraction d'informations à grande échelle. Il est entièrement écrit en Cython, un langage soigneusement géré en mémoire. spaCy est la bibliothèque idéale à utiliser si votre application doit traiter d'importants volumes de données web.
Caractéristiques :
Pour en savoir plus sur spaCy, veuillez consulter leur site web officiel ou le dépôt GitHub. Vous pouvez également vous familiariser rapidement avec ses fonctionnalités à l'aide de cette fiche pratique spaCY.
⭐ Étoiles GitHub : 28K | Nombre total de téléchargements : 81 millions
Hugging Face Transformers est une bibliothèque open source développée par Hugging Face. Les transformateurs permettent aux API de télécharger et de former facilement des modèles pré-entraînés de pointe. L'utilisation de modèles pré-entraînés peut réduire vos coûts informatiques, votre empreinte carbone et vous faire gagner du temps en vous évitant d'avoir à entraîner un modèle à partir de zéro. Les modèles conviennent à diverses modalités, notamment :
La bibliothèque des transformateurs prend en charge l'intégration transparente entre trois des bibliothèques d'apprentissage profond les plus populaires : PyTorch, TensorFlow, and JAX. Vous pouvez entraîner votre modèle en trois lignes de code dans un cadre et le charger pour l'inférence dans un autre. L'architecture de chaque transformateur est définie dans un module Python autonome, ce qui les rend facilement personnalisables pour les expériences et la recherche.
La bibliothèque est actuellement disponible sous licence Apache 2.0.
Pour en savoir plus sur les transformateurs, veuillez consulter leur site web officiel ou le référentiel GitHub, ainsi que notre tutoriel sur l'utilisation des transformateurs et de Hugging Face.
⭐ Étoiles GitHub : 119K | Nombre total de téléchargements : 62 millions
LangChain est le cadre d'orchestration standard de l'industrie pour les grands modèles linguistiques (LLM). Il permet aux développeurs de « relier » différents composants entre eux, par exemple en connectant un LLM (comme GPT 5.2) à d'autres sources de calcul ou de connaissances.
Il simplifie la complexité du travail avec les invites, vous permettant de créer facilement des « agents » capables d'utiliser des outils (tels qu'une calculatrice, Google Search ou un REPL Python) pour résoudre des problèmes de raisonnement en plusieurs étapes.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ Étoiles GitHub : 123K+ | Statut : GenAI Essentiel
Alors que LangChain gère le raisonnement, LlamaIndex gère les données. Il s'agit du principal cadre pour le RAG (Retrieval-Augmented Generation, ou génération augmentée par la recherche). Il est spécialisé dans l'ingestion, l'indexation et la récupération de vos données privées (PDF, bases de données SQL, feuilles Excel) afin que les LLM puissent répondre avec précision aux questions qui s'y rapportent.
En 2025, « discuter avec vos documents » est une exigence commerciale standard, et LlamaIndex fournit les structures de données optimisées pour rendre cela efficace et sans hallucination.
⭐ Étoiles GitHub : 35K+ | Statut : RAG Standard
Pour que les LLM puissent « mémoriser » des informations, il est nécessaire d'utiliser une base de données vectorielle. ChromaDB est une base de données vectorielle open source native pour l'IA qui est devenue la référence pour les développeurs Python. Il gère la complexité de l'intégration de texte (conversion de mots en listes de chiffres) et de leur stockage pour la recherche sémantique.
Contrairement aux bases de données SQL traditionnelles qui recherchent des mots-clés exacts, ChromaDB vous permet d'effectuer des requêtes par signification, ce qui en fait le backend de mémoire à long terme pour les applications d'IA modernes.
⭐ Étoiles GitHub : 25K+ | Statut : Norme Vector Store
Choisir la bibliothèque Python adaptée à vos tâches de science des données, d'apprentissage automatique ou de traitement du langage naturel est une décision cruciale qui peut avoir un impact significatif sur la réussite de vos projets. Compte tenu du vaste choix de bibliothèques disponibles, il est essentiel de prendre en considération divers facteurs afin de faire un choix éclairé. Voici quelques éléments clés à prendre en considération pour vous guider :
En évaluant soigneusement ces facteurs, vous pouvez prendre une décision éclairée lors du choix des bibliothèques Python pour vos projets en science des données ou en apprentissage automatique. Veuillez noter que la bibliothèque la plus appropriée pour votre projet dépend des exigences spécifiques et des objectifs que vous souhaitez atteindre.
Pour démarrer votre carrière dans la science des données, veuillez suivre le cursus professionnel Data Scientist in Python.
Cours sur les bibliothèques Python chez DataCamp
Cours
Cours
Cours
Tutoriel
Sejal Jaiswal
Tutoriel
DataCamp Team
Tutoriel
Abid Ali Awan
Tutoriel
Laiba Siddiqui
Tutoriel
Derrick Mwiti
