
Lernpfad
Microsoft Azure Grundlagen (AZ-900)
9 Std.
Azure Database for MySQL Flexible Server ist der verwaltete MySQL-Dienst von Microsoft für moderne, datengesteuerte Anwendungen, die hohe Leistung, Skalierbarkeit und Kontrolle brauchen. Es bietet eine anpassungsfähigere Architektur als die ältere Einzel-Server-Bereitstellung und ermöglicht dir eine genauere Feinabstimmung in Bezug auf Rechenleistung, Speicherplatz, Verfügbarkeitszonen und Wartungsfenster.
Für neue Projekte auf Azure empfiehlt Microsoft jetzt Flexible Server. Es bietet eine bessere Leistung, eine kostenoptimierte Skalierung und verbesserte Hochverfügbarkeitskonfigurationen. Flexible Server bietet Datenwissenschaftlern und Ingenieuren die perfekte Balance zwischen verwaltetem Komfort und operativer Flexibilität, egal ob sie Analyse-Pipelines aufbauen, große Transaktions-Workloads verarbeiten oder Echtzeit-Dashboards erstellen.
In diesem Artikel erkläre ich die Architektur des Flexible Servers, gehe auf die verfügbaren Skalierbarkeitsoptionen ein und gebe Tipps für die optimale Nutzung der Datenbank. Wenn du neu bei MySQL bist, empfehle ich dir, unser MySQL-Tutorial, um zu verstehen, wie man mit der MySQL-Datenbank Datenbanken erstellt und SQL-Abfragen ausführt.
Azure Database for MySQL Flexible Server trennt Rechenleistung von Speicher, sodass du beides unabhängig voneinander skalieren kannst, was bei der Optimierung von Kosten und Leistung hilft. Hier sind die wichtigsten Punkte:
Azure Database for MySQL Flexible Server hat drei Rechenstufen, die auf unterschiedliche Workload-Anforderungen zugeschnitten sind:
Flexible Server bietet diese beiden Hochverfügbarkeitsarchitekturen (HA), um die Verfügbarkeit und Datenredundanz sicherzustellen:
Flexible Server macht automatisch Standby-Replikate für hohe Verfügbarkeit mit automatischem Failover bereit und verwaltet sie. Hinter den Kulissen macht Flexible Server Folgendes:
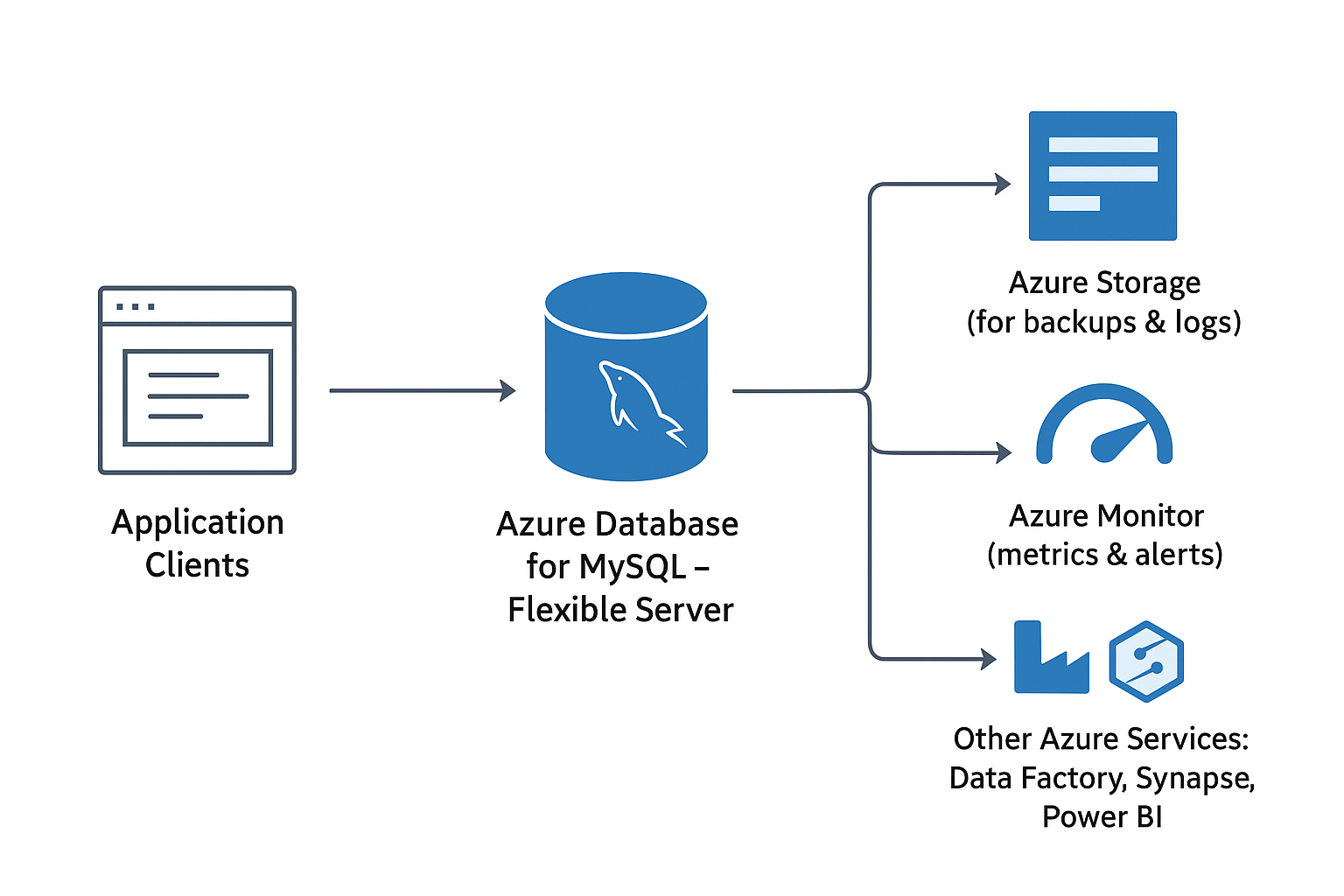
Datenfluss zwischen Clients, MySQL Flexible Server und Azure-Diensten. Bild von OpenAI.
Im obigen Diagramm haben wir Folgendes:
Azure Database for MySQL Flexible Server hat Funktionen, die Datenwissenschaftlern und App-Entwicklern eine optimierte Steuerung, hohe Leistung und Kosteneffizienz bieten. Schauen wir uns mal ein paar dieser Funktionen an:
Wie wir bei der Architektur gesehen haben, hat Flexible Server eingebaute Hochverfügbarkeitsoptionen (HA), um Ausfallzeiten und Datenverluste zu minimieren. Bei der zonenredundanten Hochverfügbarkeit wird die Standby-Replik in einer anderen Verfügbarkeitszone abgelegt, was vor kompletten Zonenausfällen schützt und die höchste Verfügbarkeit im Rahmen der SLA bietet. Andererseits setzt Same-Zone-HA die primären und Standby-Replikate in derselben Verfügbarkeitszone ein und bietet so Redundanz mit geringerer Latenz.
Als Nutzer musst du für die Rechenleistung und den Speicherplatz der primären und der Standby-Replik bezahlen. Der Standby-Server ist kein aktiver Server für Lese- oder Schreibvorgänge; er ist nur für schnelle Failover da.
Deshalb ist zonenredundante Hochverfügbarkeit die beste Wahl für Produktions-Workloads, die eine SLA von 99,99 % brauchen und vor vielen verschiedenen Ausfällen geschützt sein müssen. HA innerhalb derselben Zone ist eine kostengünstigere Option für Entwicklungs-/Testumgebungen oder Anwendungen, bei denen eine sehr geringe Latenz wichtiger ist als der Schutz vor einem Ausfall der gesamten Zone.
Ab September 2025 hat Microsoft auch eine spezielle SLB-basierte HA-Option in der öffentlichen Vorschau eingeführt, die eine zusätzliche, optionale Möglichkeit bietet, Hochverfügbarkeit für bestimmte Szenarien zu konfigurieren.
Mit Flexible Server kannst du deine Datenbankressourcen mit diesen Funktionen an die Anforderungen deiner Arbeitslast anpassen:
Um die Kosten besser im Griff zu haben, hat Flexible Server diese Funktionen:
Azure MySQL Flexible Server hat diese Sicherheitsfunktionen:
Um den Verwaltungsaufwand zu reduzieren, hat Microsoft die Wartung von MySQL Flexible Server auf folgende Weise automatisiert:
Flexible Server sind super, um skalierbare Lösungen für Data-Science-Workflows zu bieten. In diesem Abschnitt schauen wir uns die verschiedenen Anwendungen in den Bereichen Advanced Analytics und Leistungsüberwachung an.
Dank seiner Skalierbarkeit und der Integration mit anderen Azure-Diensten eignet sich MySQL Flexible Server für anspruchsvolle Analyseanwendungen wie zum Beispiel:
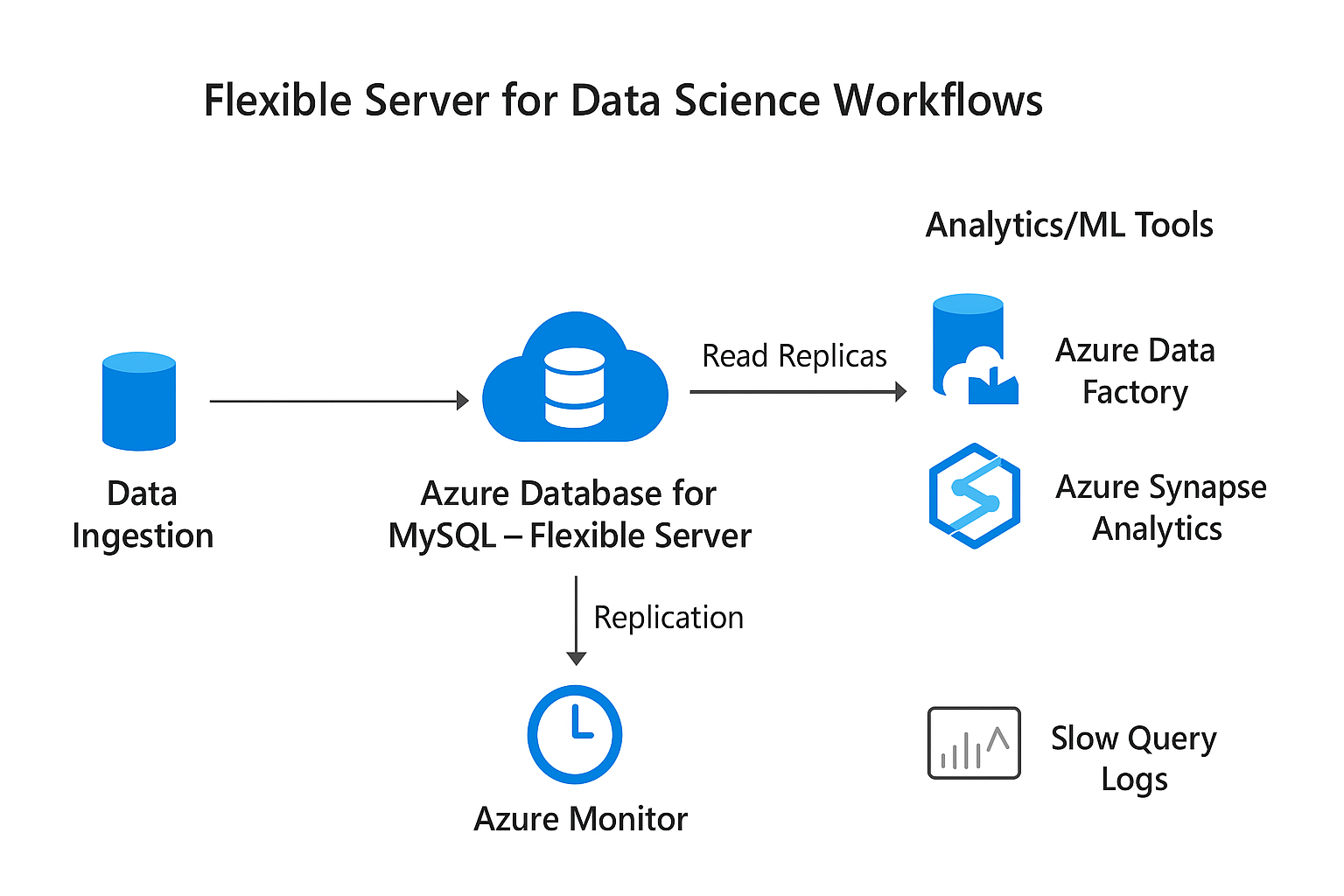
MySQL Flexible Server für Datenwissenschafts-Workflows. Bild von OpenAI.
Flexible Server unterstützt die eingehende Replikation für Hybrid- und Migrationsszenarien.
MySQL Flexible Server hat coole Tools, um Data-Science-Workflows zu überwachen und zu optimieren. Das geht über die folgenden Methoden:
Die Migration zu Azure Database for MySQL Flexible Server kann offline oder online erfolgen, je nachdem, wie viel Ausfallzeit deine Anwendung verträgt. Schauen wir uns diese Methoden an und lernen wir, die beste für deine Bedürfnisse auszuwählen.
Offline-Migrationen sind eine gute Wahl, wenn du dir eine Ausfallzeit leisten kannst, zum Beispiel bei einer nicht kritischen Anwendung oder während eines geplanten Wartungsfensters.
Der Azure Database Migration Service (DMS) ist ein komplett verwalteter Dienst, der deinen Migrationsprozess übernimmt. Bei Offline-Migrationen wird eine komplette Sicherung deiner Quelldatenbank gemacht und dann auf deinem Ziel-Flexible-Server wiederhergestellt.
Bei der Migration großer Datenbanken kannst du das Befehlszeilentool „ mydumper “ nutzen, das eine Multithread-Datensicherung durchführt. Das Tool „ myloader “ stellt es dann mit mehreren gleichzeitigen Verbindungen wieder her. Diese Methode ist super für die Migration großer Datenbanken, weil sie die Gesamtmigrationszeit im Vergleich zu herkömmlichen Single-Thread-Tools wie mysqldump deutlich verkürzen kann.
Wenn du mit Daten in einer super produktiven Umgebung arbeitest, solltest du eine Online-Migration in Betracht ziehen, wenn du möglichst wenig Unterbrechungen willst.
In diesem Fall nutzt du die Daten-In-Replikation, um deine Azure-Datenbank für MySQL Flexible Server als Replik eines externen MySQL-Servers einzurichten. Die Daten werden nach Azure kopiert, während der Quellserver weiter Transaktionen verarbeitet. Das führt zu minimalen Ausfallzeiten, normalerweise nur ein paar Sekunden bis ein paar Minuten.
Diese Methode funktioniert in Hybrid- oder Multi-Cloud-Architekturen. Du kannst von lokalen Systemen, VMs, AWS RDS, Google Cloud SQL und sogar älteren Azure Single Server-Bereitstellungen migrieren.
Wenn du diese Tipps befolgst, kannst du sicher sein, dass der Wechsel reibungslos und erfolgreich läuft, egal für welche Migrationsmethode du dich entscheidest:
Bitte beachte, dass ab dem 1. September 2025 alle neuen Flexible Server mit der neuesten Version vom September 2025 bereitgestellt werden, die Upgrades auf MySQL 8.0.42 (für bestehende 8.0-Server), die allgemeine Verfügbarkeit von MySQL 8.4 und verbesserte Sicherheit (TLS 1.2-Durchsetzung und CA-Rotation) beinhaltet. Du kannst deine aktuelle Engine-Version mit SELECT VERSION() checken.
Jetzt, wo du die Funktionen von MySQL Flexible Server kennengelernt hast, empfehle ich dir, dich mit der Nutzung der Plattform vertraut zu machen.
Microsoft bietet ein kostenloses 12-monatiges Azure-Konto mit monatlichem Kontingent an, um Azure Database for MySQL Flexible Server kostenlos auszuprobieren. Das beinhaltet 750 Stunden pro Monat für die Burstable B1ms-Instanz, genug, um eine einzelne Instanz ohne Unterbrechung laufen zu lassen. Du bekommst außerdem 32 GB Speicherplatz und 32 GB Backup-Speicherplatz. Dieses kostenlose Angebot ist super zum Testen, Lernen und für die erste Entwicklungsphase, bevor du richtig loslegst.
Microsoft hat auch Schnellstart-Tutorials, mit denen du deinen ersten Server in wenigen Minuten einrichten kannst. Du kannst dir die Azure MySQL Flexible Server Quickstart Docs, um zu erfahren, wie du einen MySQL Flexible Server erstellenerstellen, eine Verbindung von deiner Anwendung herstellen und ihn in Azure-Dienste integrieren kannst.
Du kannst dich auch über die neuesten Funktionen, Tipps und Best Practices auf dem Laufenden halten, indem du dem Azure Database for MySQL-Blogzu folgen.
Azure Database for MySQL Flexible Server ist eine robuste, skalierbare und kostengünstige Lösung für moderne Data Science-Workflows und groß angelegte Anwendungen. Es macht die Datenbankverwaltung einfacher, indem es Rechenleistung und Speicher trennt, eine detaillierte Kontrolle ermöglicht und sich in das breitere Azure-Ökosystem einfügt.
Die hohe Verfügbarkeit, die flexible Skalierbarkeit und die cleveren Tools zur Leistungsüberwachung machen den Dienst zu einer super Wahl für OLTP-Anwendungen und intensive Analysen.
Probier diese Funktionen doch einfach mal aus, indem du das 12-monatige Gratisangebot nutzt, um zu sehen, wie Flexible Server deine Datenoperationen optimieren und neue Projektmöglichkeiten eröffnen kann. Und vergiss nicht, dich für unseren Kurs „Microsoft Azure verstehen“ anzumelden. Kurs „Microsoft Azure verstehen“, um die nötigen Erfahrungen zu sammeln, damit du Azure Flexible Server bei deiner Arbeit optimal nutzen kannst.
Die besten DataCamp-Kurse
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Tutorial
Moez Ali
Tutorial
Matt Crabtree