
Kurs
Building Agentic Workflows with LlamaIndex
2 Std.
1.2K
Google hat kürzlich denDeep Think-Modus „ “ für Gemini 2.5 Pro rausgebracht . Deep Think ist eine Funktion, die dir hilft, knifflige Probleme zu lösen. Es funktioniert so, dass man mehrere Ideen gleichzeitig mit parallelem Denken durchdenkt, sie vergleicht und dann die beste Lösung auswählt.
In diesem Artikel werde ich seine Fähigkeiten erkunden, indem ich ihm reale Probleme zum Lösen gebe. Von Fragen auf Doktoranden-Niveau bis hin zu geschäftlichen Herausforderungen habe ich Deep Think an fünf kniffligen Problemen getestet, um zu sehen, wie gut es funktioniert.
Wir halten unsere Leser über die neuesten Entwicklungen im Bereich KI auf dem Laufenden, indem wir ihnen jeden Freitag unseren kostenlosen Newsletter„The Median “ schicken , der die wichtigsten Meldungen der Woche zusammenfasst. Abonniere unseren Newsletter und bleib in nur wenigen Minuten pro Woche auf dem Laufenden:
Gemini Deep Think ist eine neue Verbesserung des Modells Gemini 2.5 Pro, die die Fähigkeiten zur Problemlösung auf ein neues Niveau hebt. Die Version, die jetzt verfügbar ist, ist eine vereinfachte Version des Modells, das kürzlich bei der diesjähriger Internationalen Mathematik-Olympiade (IMO).
Die alte Version braucht ewig, um schwierige Matheaufgaben zu lösen, aber die neue Version, die heute rausgekommen ist, ist viel schneller und besser für den Alltag geeignet, und erreicht trotzdem noch die Bronze-Stufe bei der IMO 2025.
Deep Think ist für alltägliche Fragen gedacht, hat aber trotzdem starke Fähigkeiten zum Lösen von Problemen. Die Nutzer können sich auf gründliche und aufschlussreiche Antworten freuen, da Deep Think komplexe Aufgaben durch Verlängerung seiner „Denkzeit“ bewältigt und so verschiedene Ideen sehr effizient generieren, bewerten und kombinieren kann.
Beachte, dass die Funktion „Deep Think” nicht dasselbe ist wie „Deep Research”, die zum Sammeln und Zusammenfassen von Infos aus dem Internet mit Quellenangaben und strukturierten Berichten gedacht ist. Der eine denkt mehr nach, der andere recherchiert genauer.
Ab sofort ist Deep Think auf der Gemini App , aber nur mit dem Google AI Ultra-Abo, das 274,99 € im Monat kostet.
Es ist auch über die API verfügbar, aber nur für bestimmte Nutzer. Wir wissen noch nicht, ob es für alle verfügbar sein wird.
Wenn du ein Google AI Ultra-Abo hast, kannst du Deep Think aktivieren, indem du auf die Schaltfläche unten in der Eingabeaufforderung klickst.
Denk dran, dass du auch mit dem Ultra-Abo nur etwa fünf Nachrichten pro Tag verschicken kannst.
Gemini Deep Think funktioniert wie beim Brainstorming, wo man viele Ideen auf einmal sammelt, um ein Problem zu lösen.
Das wird durch paralleles Denken erreicht, wodurch die KI verschiedene Wege und Alternativen gleichzeitig in Betracht ziehen kann, anstatt nur einen linearen Ansatz zu verfolgen. Gemini Deep Think gibt dir mehr Zeit zum Nachdenken und analysiert, vergleicht und kombiniert verschiedene Ideen, um die beste Lösung zu finden.
Mit dieser Methode kann Gemini komplexe Aufgaben gut meistern, indem es mehrere Ergebnisse und Strategien durchspielt und so in kurzer Zeit solide und kreative Antworten auf schwierige Fragen liefert.
Als ich meine Doktorarbeit geschrieben habe, habe ich ein paar offene Probleme gelassen, die ich nicht lösen konnte. Ich hab's einfach mal mit Gemini Deep Think auf einem von ihnen ausprobiert.
Das Problem betrifft Computernetzwerke. Der Datenverkehr in einem Computernetzwerk geht über die kürzesten Wege, ähnlich wie bei der Navigation mit einem GPS im Auto. Die Länge jeder Netzwerkverbindung ist einfach eine positive Zahl und kann beliebig konfiguriert werden.
Es ist aber nicht so praktisch, ganz lange Netzwerkverbindungen einzurichten, deshalb wollen wir die längste Verbindung so kurz wie möglich halten.
Hier ist die Anfrage, die an Gemini Deep Think geschickt wurde:

Nach etwa 15 Minuten kam eine Antwort zurück. Es wurde ein gieriger Algorithmus vorgeschlagen. Das ist ein Algorithmus, der zwar nicht optimal ist, aber versucht, eine ausreichend gute Lösung zu finden.
Ich hab gemerkt, dass meine erste Frage nicht das war, was ich eigentlich wissen wollte. Ich wollte entweder einen Algorithmus finden, der die beste Lösung findet, oder beweisen, dass so ein Algorithmus wahrscheinlich nicht existiert.
Also hab ich das Gespräch weitergeführt:

Nach weiteren 15 Minuten kam die Antwort, dass das Problem NP-schwierig ist. Das heißt, dass es wahrscheinlich keinen schnellen Algorithmus für dieses Problem gibt.
Das ist auch meine Meinung dazu. Ich hab angefangen, den Korrekturabzug zu lesen, aber es fehlen viele wichtige Details. Stattdessen würde es ein paar allgemeine Infos geben und sagen, dass die Antwort echt kompliziert ist:

Ich hab immer wieder nachgefragt, was fehlt, aber ich hab nie einen vollständigen Beweis bekommen, sodass ich nicht überprüfen konnte, ob das Problem damit gelöst war.
Es fühlte sich ein bisschen an wie das klassische Mathe-Meme von Sidney Harris:

In den Antworten ist mir aufgefallen, dass es so geschrieben war, als wäre die Antwort nicht selbst gefunden worden, sondern als würde ein bekannter Beweis verwendet werden. Ich hab nachgefragt und es ist tatsächlich ein bekanntes Ergebnis, das schon 2002 in einem Artikel veröffentlicht wurde.
Der Name des Artikels wurde angegeben, aber ich konnte ihn online nirgends finden. Wie sich herausstellte, war der Autor in meinem Prüfungsausschuss. Es wäre echt witzig, wenn sie das Problem schon gelöst hätten und mir einfach nichts gesagt hätten.
Ich weiß nicht, was ich von diesem Beispiel halten soll. Hast du die Antwort gefunden, aber nicht alle Details geteilt? Hat es gerade eine vorhandene Antwort ausgespuckt? Oder fehlen die Details, weil die Antwort nicht stimmt?
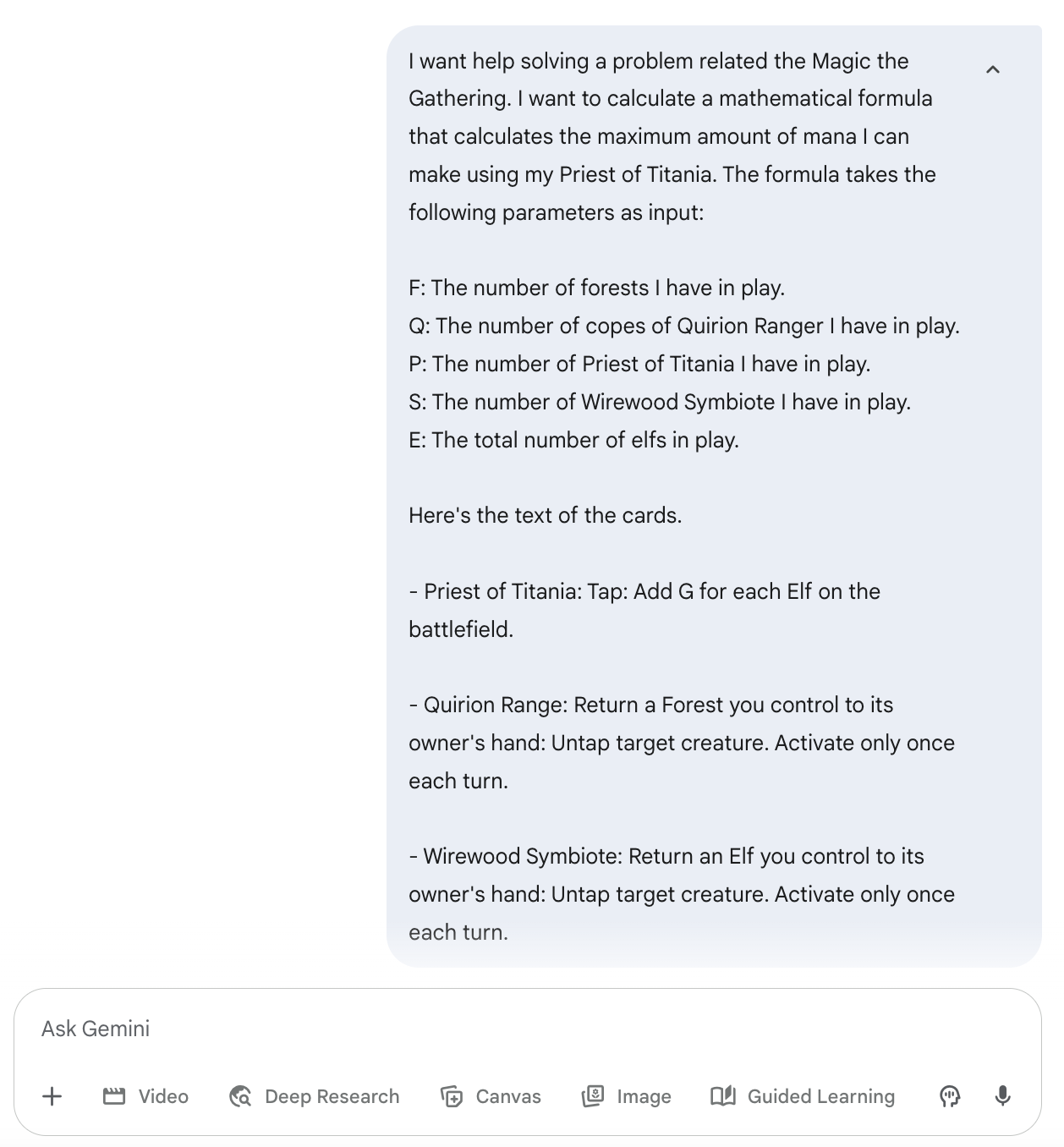
Ich spiele ein strategisches Kartenspiel und versuche gerade, die maximale Menge an Ressourcen zu finden, die ich in einem bestimmten Spielzustand generieren kann.
Ich hab vor einiger Zeit Formeln gefunden, die ich für optimal halte, aber ich hab nicht nachgewiesen, dass sie wirklich optimal sind. Damals habe ich andere KI-Modelle gebeten, die Lösung zu finden, aber alle sind kläglich gescheitert. Es war nicht nur so, dass die Antworten nicht optimal waren, sie passten auch nicht zu den Spielregeln.
Also hab ich beschlossen, Gemini Deep Think mal für dieses Problem auszuprobieren. Ich hab die Spielregeln nicht erklärt (ich dachte, die wären Teil des Trainings). Aber ich hab die Regeln für jede Karte erklärt. Du musst weder das Spiel noch meine Anweisungen verstehen, um diesem Beispiel folgen zu können.
Hier ist die Frage:
Bei Gemini solltest du wissen, dass es im Vergleich zu anderen Modellen ziemlich langsam ist. Rechne also mit einer Wartezeit von 5 bis 20 Minuten, bis du eine Antwort bekommst. Dieses Beispiel war ziemlich schnell und hat etwa 5 Minuten gedauert.
Hier ist ein Teil der Antwort, die wir bekommen haben. Hier sind die Schritte und Formeln. Zuvor hat sie ihre Gründe erklärt:

Da ich das Problem aber schon mal gelöst hatte, wusste ich, dass das nicht richtig war und dass es besser ging. Das liegt an einer Regel, die es ermöglicht, einige Einschränkungen der Karten zu umgehen, die ich nicht ausdrücklich erwähnt habe. Ich weiß nicht, ob es mir wegen schlechter Argumentation entgangen ist oder weil die Regeln im Training nicht richtig angewendet wurden.
Das zeigt aber, dass es in bestimmten Bereichen vielleicht nicht alles weiß, also sollte man mit den Antworten, die man bekommt, vorsichtig sein. Wenn das 'ne wichtige Frage gewesen wär, die ich vorher nicht geklärt hatte, hätte ich nicht gewusst, dass die Antwort nicht stimmt, und hätte sie vielleicht einfach so verwendet, weil ich davon ausgegangen wäre, dass sie stimmt. Wenn ich es aber selbst lösen muss, brauch ich die KI gar nicht erst.
Ich hab gesagt, dass die Antwort nicht stimmt, und ein paar Infos dazu gegeben, um zu sehen, ob die Antwort besser werden kann.
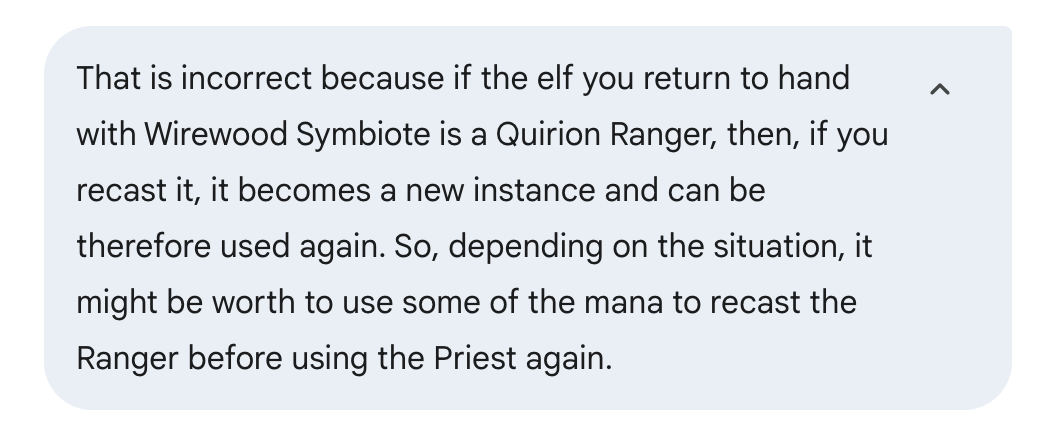
Diesmal kam ich auf die gleiche Antwort wie zuvor. Hier ist ein Teil der Antwort, die ich bekommen habe:

Was mich ein bisschen genervt hat, ist, dass es keinen Beweis dafür gibt, dass das die beste Antwort ist.
Als Nächstes habe ich versucht, damit ein Logikrätsel zu lösen, das mir echt gut gefällt.

In diesem Fall hat es viel schneller geantwortet. Die Antwort fing damit an, dass es ein klassisches Logikproblem sei.

Dann wurde eine Strategie erklärt, wie man das Rätsel lösen kann. In diesem Fall ist klar, dass nicht viel nachgedacht wurde und dass die KI schon auf die Lösung trainiert war.
Das ist eine der schwierigen Fragen bei der Bewertung dieser Modelle. Findet es die Antwort, weil es sie selbst gefunden hat, oder war die Antwort schon da und es musste sie nur ausspucken?
Um noch einen Schritt weiter zu gehen, habe ich eine weitere Einschränkung hinzugefügt, um das Ergebnis zu sehen. Ich hab mir diese Variante gerade ausgedacht und hab sie noch nie gesehen. Ich wusste nicht, ob es für diese Version eine Lösung gibt.
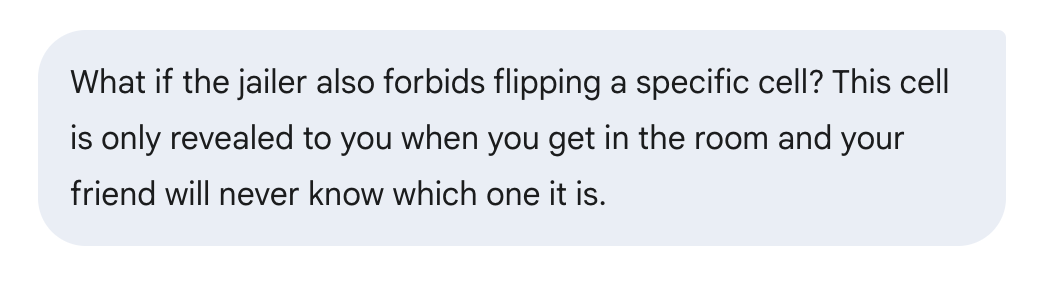
Diesmal hat die Antwort wieder lange gedauert, was ein gutes Zeichen ist. Es hieß, man habe eine Lösung für diese schwierigere Variante gefunden:

Nachdem ich die ganze Antwort gelesen habe, scheint die Lösung aber ein paar Fehler zu haben. Am Ende der Antwort gibt's ein Beispiel, wie der Plan umgesetzt wird, und es wird klar, dass er nicht funktioniert.

Es steht zwar, dass es eine Lösung gibt, aber ich hab nicht weiter nachgefragt. Das Verhalten ist ein bisschen wie im vorherigen Beispiel, wo ein paar wichtige Schritte fehlen und wir nicht so sicher sind, ob das Problem damit wirklich gelöst ist.
Ich setz in meinem Café ein digitales Treuekartenprogramm auf und frag mich, wie ich das am besten anpacken soll. Ich hab Gemini Deep Think alle Infos gegeben und um eine komplette Analyse verschiedener Strategien und eine Empfehlung gebeten.
Hier ist die Eingabeaufforderung, die ich verwendet habe:
Auch hier ging die Antwort schnell raus. Es wurden vier Lösungen vorgeschlagen und die Vor- und Nachteile jeder Lösung aufgezeigt.




Bei diesem Problem fand ich die Antwort zwar gut, aber nicht so anders als bei anderen Modellen. Ich finde, Deep Think ist für solche Probleme übertrieben und dass generische KI-Modelle diese Aufgaben genauso gut erledigen können.
Zum Schluss habe ich Gemini Deep Think bei einer Programmieraufgabe getestet. Ich hab keine Sprache oder technische Details angegeben, nur das Problem, das ich lösen wollte.
Die Antwort war echt enttäuschend und es gab nicht mal den Code dazu. Das könnte ein einfacher Fehler gewesen sein, aber bei dem Preis von Deep Think ist das nicht okay.
Die Antwort hat nicht nur den Code nicht geliefert, sondern auch nicht erklärt, wie die Lösung funktioniert. Ich hab beim Senden dieser Nachricht das Nachrichtenlimit erreicht, also frag ich mich, ob das irgendwie die Antwort beeinflusst hat. Ich finde das allerdings komisch, weil die Nachricht selbst noch im Limit war.
Bei den Problemen, die ich ausprobiert habe, hatte ich nicht das Gefühl, dass es große Unterschiede zwischen den Antworten von Deep Think und denen von anderen Chain-of-Thought-Modellen gab. Also, trotz der besseren Benchmark-Leistung und der Goldmedaillen, frage ich mich, ob es für die meisten Leute wirklich so viel bringt. Ich sehe es als ein Tool für Forscher.
Was mich genervt hat, war, dass man nach Erreichen des Deep-Think-Limits das Gespräch mit einem normalen Modell nicht fortsetzen kann. Oft dachte ich, dass es gut gewesen wäre, die Problemlösung mit Deep Think anzustoßen und dann ein normales Modell die ersten Ideen weiterentwickeln zu lassen, um zu einer endgültigen Lösung zu kommen.
Ich finde echt, dass Deep Think ein paar beeindruckende Erfolge vorweisen kann. Eine Medaille bei der IMO zu gewinnen, ist echt keine Kleinigkeit, und wenn diese Modelle weiterentwickelt werden, können sie für Forscher echt nützliche Werkzeuge werden. Ich denke, dass Deep Think zusammen mit einem Menschen die Forschung voranbringen kann.
Während meiner Doktorarbeit hatte ich oft Probleme, Ideen mit anderen zu teilen, auch wenn sie keine Lösung hatten. Es wäre echt cool gewesen, ein Modell wie Deep Think zu haben, um öfter Ideen zu sammeln und schneller Ideen zu überprüfen oder zu verwerfen.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Blog
Nathaniel Taylor-Leach