
Curso
Building Agentic Workflows with LlamaIndex
2 h
1.2K
O Google lançou recentemente o modoDeep Think para o Gemini 2.5 Pro. O Deep Think é um recurso feito pra resolver problemas complicados. Funciona usando o pensamento paralelo pra explorar várias ideias ao mesmo tempo, comparando-as e, depois, escolhendo a solução mais eficaz.
Neste artigo, vou explorar suas capacidades pedindo que ele resolva problemas do mundo real. De questões de nível de doutorado a desafios de negócios, eu testei o Deep Think em cinco problemas complexos para ver como ele se saía.
A gente mantém nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito às sextas-feiras, que traz as principais notícias da semana. Inscreva-se e fique por dentro em só alguns minutos por semana:
O Gemini Deep Think é uma novidade que veio junto com o modelo Gemini 2.5 Pro, levando as habilidades de resolução de problemas pra outro nível. A versão que tá disponível é uma versão simplificada do modelo que recentemente teve um desempenho top na Olimpíada Internacional de Matemática (IMO) deste ano.
A versão original leva horas pra resolver problemas matemáticos difíceis, mas a versão lançada hoje é bem mais rápida e mais adequada pra tarefas do dia a dia, mesmo conseguindo um nível Bronze na IMO de 2025.
O Deep Think foi feito pra responder às perguntas do dia a dia, mas ainda assim é super bom pra resolver problemas. Os usuários podem contar com respostas completas e inteligentes, já que o Deep Think lida com tarefas complexas aumentando o seu “tempo de reflexão”, o que permite gerar, avaliar e misturar várias ideias de forma super eficiente.
Lembre-se de que o recurso Deep Think não é igual ao Deep Research, que foi feito pra juntar e resumir informações da web, com fontes e relatórios bem organizados. Um pensa mais, o outro pesquisa mais a fundo.
Agora, o Deep Think tá disponível no aplicativo Gemini , mas só está disponível na assinatura Google AI Ultra, que custa € 274,99 por mês.
Também está disponível através da API, mas só para um grupo específico de usuários. Ainda não sabemos se vai rolar para todo mundo.
Se você tem uma assinatura do Google AI Ultra, pode ativar o Deep Think clicando no botão na parte de baixo da janela de entrada de comando.
Lembre-se de que, mesmo com a assinatura Ultra, você só pode mandar mais ou menos cinco mensagens por dia.
O Gemini Deep Think funciona de um jeito parecido com o brainstorming humano, explorando várias possibilidades ao mesmo tempo pra resolver um problema.
Isso é feito com o pensamento paralelo, que deixa a IA pensar em várias possibilidades e alternativas ao mesmo tempo, em vez de só seguir uma linha. Ao dar mais tempo pra pensar, o Gemini Deep Think analisa, compara e junta ideias diferentes pra chegar na melhor solução possível.
Esse método permite que a Gemini lide com tarefas complexas de forma eficaz, simulando vários resultados e estratégias, oferecendo aos usuários respostas robustas e criativas para perguntas desafiadoras em um prazo relativamente curto.
Quando escrevi minha tese de doutorado, deixei alguns problemas em aberto que não consegui resolver. Decidi testar o Gemini Deep Think em um deles.
O problema é sobre redes de computadores. O tráfego anda numa rede de computadores usando os caminhos mais curtos, tipo quando a gente usa um GPS pra navegar de carro na estrada. O comprimento de cada ligação da rede é só um número positivo e pode ser configurado como quiser.
Mas, não dá pra configurar comprimentos muito grandes nas ligações de rede, então a gente quer deixar o maior peso o menor possível.
Aqui está a mensagem enviada para o Gemini Deep Think:

Depois de uns 15 minutos, veio a resposta. Ele sugeriu um algoritmo ganancioso. Esse é um algoritmo que não é o melhor, mas tenta achar uma solução boa o suficiente.
Percebi que minha pergunta inicial não era o que eu queria. Eu queria encontrar um algoritmo que encontrasse a melhor solução ou provar que tal algoritmo provavelmente não existe.
Então, continuei a conversa:

Depois de mais 15 minutos, ele disse que o problema é NP-difícil. Isso quer dizer que provavelmente não existe um algoritmo rápido pra resolver esse problema.
Acho que essa é a resposta também. Comecei a ler a prova, mas faltam muitos detalhes importantes. Em vez disso, daria alguns detalhes gerais e diria que a resposta é bem complexa:

Continuei insistindo e pedindo as informações que faltavam, mas nunca consegui uma prova totalmente detalhada, então não pude verificar se isso resolveu o problema.
Parecia um pouco com o meme clássico de matemática de Sidney Harris:

Nas respostas, percebi que a forma como estava escrito dava a entender que não tinha sido a resposta encontrada, mas sim uma prova já conhecida. Eu perguntei sobre isso e me disseram que é um resultado conhecido, publicado num artigo em 2002.
Ele me deu o nome do artigo, mas não consegui encontrar em lugar nenhum online. Acontece que o autor fazia parte da minha banca de tese. Seria engraçado se eles já tivessem resolvido o problema e simplesmente não tivessem me contado.
Fiquei sem saber o que pensar desse exemplo. Você chegou à resposta, mas não compartilhou todos os detalhes? Ele acabou de mostrar uma resposta que já existe? Ou será que os detalhes estão faltando porque a resposta não está certa?
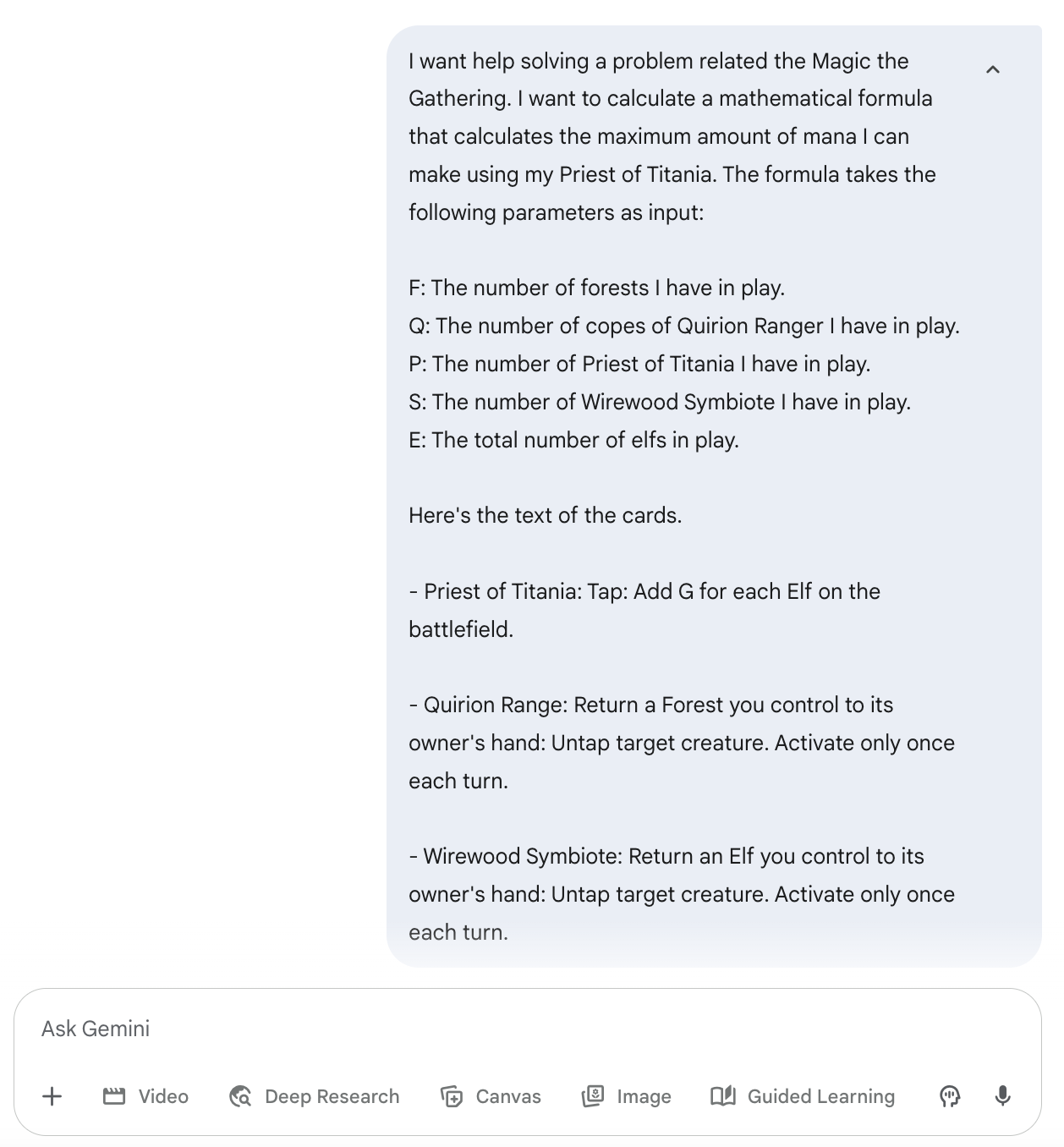
Tem um jogo de cartas estratégico que eu jogo e, ultimamente, tenho tentado descobrir a quantidade máxima de recursos que consigo gerar em uma determinada situação do jogo.
Eu inventei umas fórmulas que acho que são ótimas há um tempo, mas não provei que elas são mesmo as melhores. Na época, pedi pra outros modelos de raciocínio de IA acharem a solução, mas todos falharam feio. Não era só que as respostas que eles davam não eram as melhores; elas não faziam sentido em relação às regras do jogo.
Então, resolvi dar uma chance ao Gemini Deep Think pra resolver esse problema. Eu não dei as regras do jogo (achei que já faziam parte do treinamento). Mas eu já dei as regras de cada cartão. Você não precisa entender o jogo ou o meu prompt para seguir este exemplo.
Aqui está a pergunta:
Uma coisa que você precisa saber sobre o Gemini é que ele é bem lento em comparação com outros modelos, então espere entre 5 a 20 minutos pra receber uma resposta. Esse exemplo foi bem rápido e levou só uns 5 minutos.
Aqui está parte da resposta que recebemos. Essa parte mostra os passos e as fórmulas. Antes disso, explicou o seu raciocínio:

Mas, como eu já tinha resolvido o problema antes, sabia que isso não estava certo e que dava pra fazer melhor. Isso é por causa de uma regra que dá pra contornar algumas das limitações das cartas, que eu não tinha explicado direito. Não sei se foi por falta de raciocínio ou porque as regras não foram bem explicadas no treinamento.
Mas isso mostra que ele pode ter pontos cegos em áreas específicas, então é preciso ter cuidado com as respostas que a gente recebe. Se essa fosse uma pergunta importante que eu não tivesse resolvido antes, eu não saberia que a resposta não estava certa e poderia ter usado sem pensar, achando que estava certa. Por outro lado, se eu preciso resolver sozinho, então não preciso da IA pra começar.
Eu disse que a resposta estava errada e dei mais informações pra ver se dava pra melhorar a resposta.
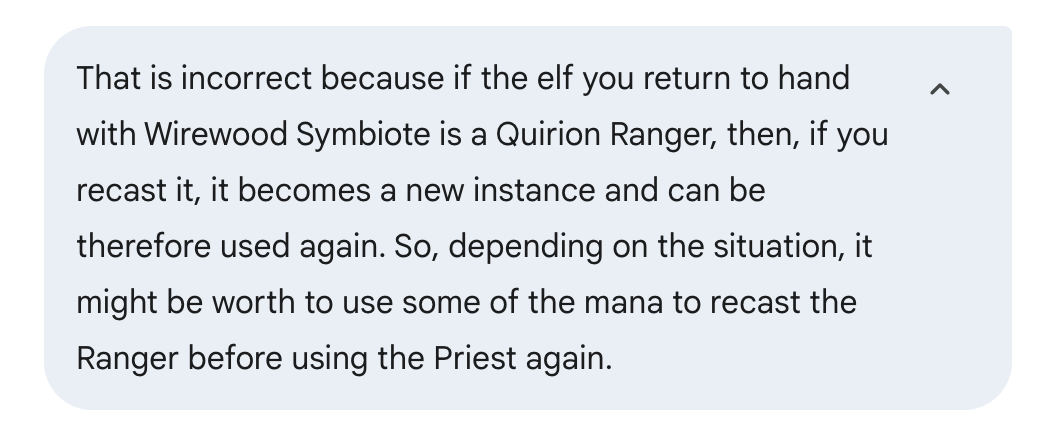
Dessa vez, ele me deu a mesma resposta que eu tinha encontrado. Aqui está parte da resposta que ele deu:

Uma coisa que me deixou meio chateado é que não mostrou que essa é a melhor resposta possível.
Depois, tentei fazer com que ele resolvesse um quebra-cabeça de lógica que eu gosto muito.

Nesse caso, a resposta foi bem mais rápida. A resposta começou dizendo que é um problema clássico de lógica.

Depois, explicou uma estratégia pra resolver o quebra-cabeça. Nesse caso, tá claro que não rolou muito raciocínio e que a IA já tinha sido treinada pra dar essa resposta.
Essa é uma das perguntas mais difíceis quando a gente avalia esses modelos. É que ele achou a resposta porque pensou nela, ou a resposta já estava lá e ele só precisava dizer?
Pra ir mais longe, eu adicionei outra restrição pra ver o resultado. Eu inventei essa variação na hora e nunca tinha visto antes. Eu não sabia se essa versão tinha uma solução.
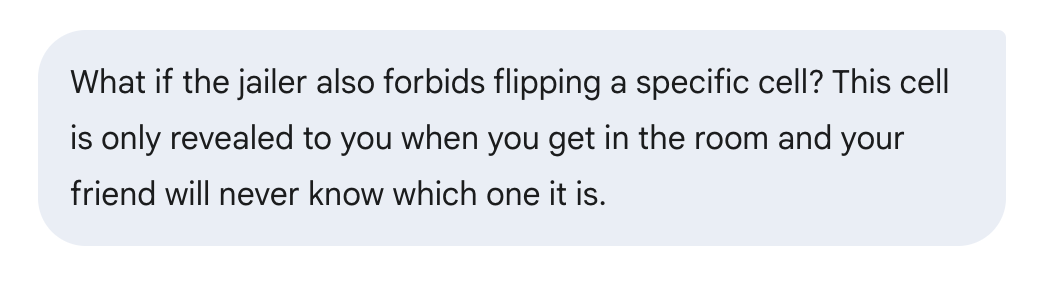
Dessa vez, demorou um tempão pra responder de novo, o que é um bom sinal. Disseram que encontraram uma solução pra essa variante mais complicada:

Mas, depois de ler a resposta completa, parece que a solução tem alguns erros. No final da resposta, dá um exemplo de como o plano foi feito e percebe que não deu certo.

Diz que tem uma solução, mas eu não fui em frente. O comportamento é um pouco parecido com o exemplo anterior, onde alguns passos importantes foram pulados, e aí ficamos sem saber se isso realmente resolve o problema ou não.
Tô implementando um programa de cartão de fidelidade digital na minha cafeteria e queria saber qual é a melhor estratégia. Eu passei os detalhes pra Gemini Deep Think e pedi uma análise completa de diferentes estratégias e uma recomendação.
Aqui está o prompt que usei:
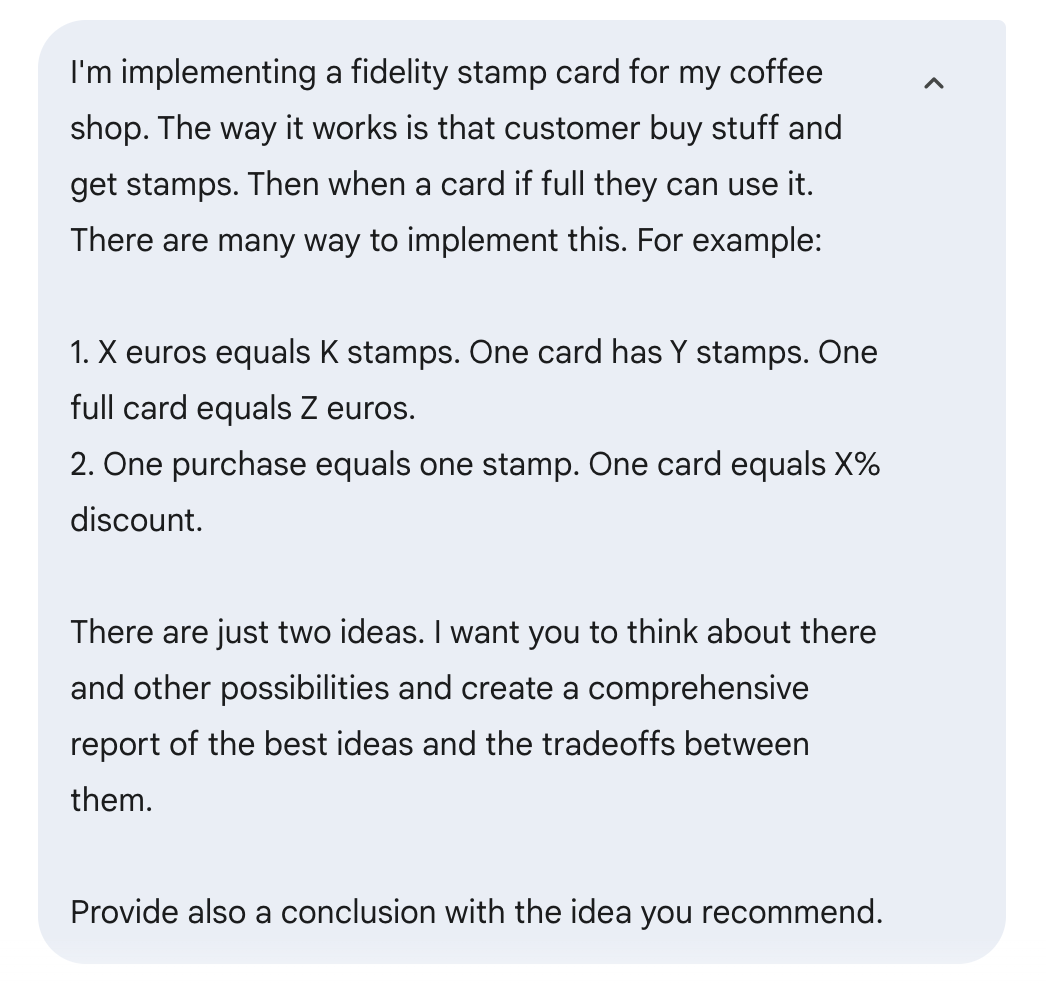
Essa foi outra vez que não demorei muito pra responder. A gente sugeriu quatro soluções e mostrou o que cada uma tem de bom e de ruim.




Pra esse problema, mesmo curtindo a resposta, não achei muito diferente do que outros modelos sugeriram. Acho que usar o Deep Think pra problemas assim é exagero e que modelos genéricos de IA dão conta do recado nessas tarefas.
Por fim, testei o Gemini Deep Think numa tarefa de codificação. Não falei qual era a linguagem ou nada técnico, só o problema que queria resolver.
A resposta foi bem decepcionante e nem deu o código. Isso pode ter sido só um bug, mas pelo preço do Deep Think, não dá pra aceitar.
A resposta não só não deu o código, como também não explicou como a solução funciona. Cheguei ao limite de mensagens ao enviar essa mensagem, então não sei se isso influenciou a resposta. Embora eu ache isso estranho, já que a mensagem em si ainda estava dentro do limite.
Com os problemas que tentei resolver, não senti que havia uma grande diferença entre as respostas fornecidas pelo Deep Think e as de outros modelos de cadeia de pensamento. Então, mesmo com um desempenho melhor nos testes e a chance de ganhar medalhas de ouro, fico pensando se isso é realmente vantajoso pra maioria das pessoas. Eu vejo isso como uma ferramenta pra quem pesquisa.
Uma coisa que me incomodou foi que, depois de atingir o limite do Deep Think, você não consegue continuar a conversa com um modelo normal. Muitas vezes, achei que teria sido bom começar a resolver o problema usando o Deep Think e, depois, deixar um modelo normal pegar as ideias iniciais para chegar à solução final.
Acho que o Deep Think tem algumas conquistas impressionantes. Ganhar uma medalha na IMO não é pouca coisa, e à medida que esses modelos evoluem, eles podem se tornar ferramentas super úteis para os pesquisadores. Acho que, junto com uma pessoa, o Deep Think pode ajudar a impulsionar a pesquisa.
Quando tava fazendo meu doutorado, muitas vezes eu ficava travado ao compartilhar ideias com outras pessoas, mesmo quando elas não conseguiam dar uma solução. Teria sido incrível ter um modelo como o Deep Think ao meu lado para trocar ideias com mais frequência e me ajudar a validar ou descartar ideias mais rapidamente.
Aprenda IA com esses cursos!
Curso
Curso
Curso
blog
Josep Ferrer
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali

