Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Um mit Imagen 3 in Python loszulegen, müssen wir ein paar wichtige Schritte durchführen. Zuerst erstellen wir ein Google Cloud-Projekt. Sobald unser Projekt fertig ist, müssen wir einen API-Schlüssel erstellen. Dieser Schlüssel ermöglicht es unserem Python-Code, mit dem Imagen 3-Dienst zu interagieren.
Die Erstellung eines Google Cloud-Projekts ist der erste Schritt zur Nutzung der KI-API von Google. Lass uns gemeinsam durch den Prozess gehen:
Imagen-tutorial. Die Organisation kann leer gelassen werden.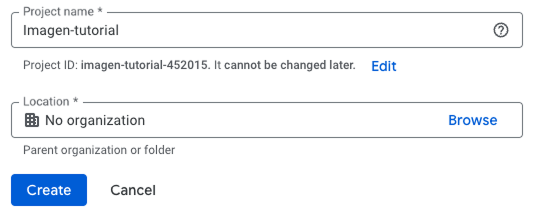
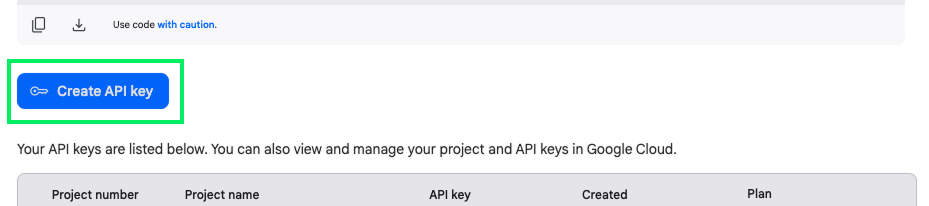
Jetzt, wo das Google Cloud-Projekt erstellt ist, können wir einen API-Schlüssel erstellen, indem wir zur API-Schlüssel-Seite in Google AI Studio navigieren.
Um den Schlüssel zu erstellen, klicke auf die Schaltfläche "API-Schlüssel erstellen":
Gib in dem Popup den Namen des Projekts ein, das wir oben erstellt haben, wähle es aus und klicke auf "API-Schlüssel in bestehendem Projekt erstellen":
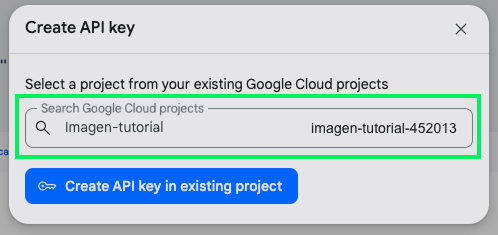
Kopiere den Schlüssel und erstelle eine Datei mit dem Namen .env in demselben Ordner, in dem wir das Python-Skript schreiben werden. Der Inhalt der Datei .env sollte sein:
GEMINI_API_KEY=<paste_your_key_here>Wenn wir jetzt versuchen würden, den API-Schlüssel zu verwenden, würden wir eine Fehlermeldung erhalten, die besagt: "Die Imagen-API ist derzeit nur für abgerechnete Nutzer zugänglich." Das liegt daran, dass die API nicht kostenlos ist und wir ein Abrechnungskonto mit dem Projekt verknüpfen müssen, bevor wir sie nutzen können.
Zum Zeitpunkt der Erstellung dieses Artikels beträgt der Preis für die Erstellung eines Bildes mit Imagen 3 $0,03. Weitere Informationen findest du auf der Seite mit den Preisen.
Um ein Abrechnungskonto hinzuzufügen, klicke auf die Schaltfläche "Abrechnung einrichten" neben dem API-Schlüssel in Google AI Studio.

Dadurch werden wir auf die Google Cloud-Website weitergeleitet, wo wir entweder ein bestehendes Abrechnungskonto auswählen können, indem wir auf "Abrechnungskonto verknüpfen" klicken, oder ein neues erstellen können, indem wir auf "Abrechnungskonten verwalten" klicken.
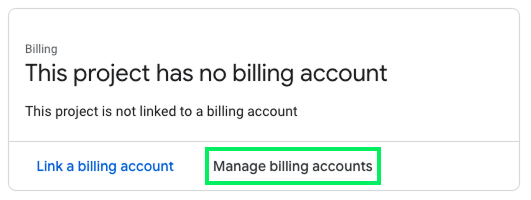
Nehmen wir an, wir haben keine, also erstellen wir "Rechnungskonten verwalten". Oben links auf der Seite gibt es eine Schaltfläche "Konto erstellen". Um das Konto zu erstellen, müssen wir unsere persönlichen Daten eingeben und eine Kreditkarte angeben, um die Zahlungen abzuwickeln.
In diesem Tutorial verwenden wir Anaconda, eine beliebte Plattform, die die Paketverwaltung und das Einrichten von Projekten vereinfacht und so die Ausführung von Python-Skripten erleichtert.
Wir können Anaconda von ihrer offiziellen Website installieren.
Um die Anaconda-Umgebung einzurichten, öffne ein Terminal und:
conda create -n imagen python=3.9. Mit diesem Befehl wurde eine Umgebung mit dem Namen imagen erstellt, die die Version 3.9 von Python verwendet.conda activate imagen.pip install -q -U google-genai.pip install pillow.pip install python-dotenvWir können die Pakete auch direkt installieren, ohne Anaconda zu verwenden. Dabei besteht jedoch die Gefahr, dass einige der aktuell installierten Pakete mit einigen der neuen Pakete in Konflikt geraten oder dass unsere Python-Installation eine andere Version von Python verwendet. Mit Anaconda werden diese potenziellen Probleme vermieden.
Wir sind jetzt bereit, Imagen 3 zu benutzen. Erstelle ein neues Python-Skript, z. B. gen_image.py, im selben Ordner wie die Datei .env..
Zuerst importieren wir die notwendigen Pakete:
# Google generative AI:
from google import genai
from google.genai import types
# Packages to process the generated image:
from PIL import Image
from io import BytesIO
# Packages to load the .env file:
import os
from dotenv import load_dotenvAls Nächstes laden wir den API-Schlüssel aus der Datei .env:
load_dotenv()
api_key = os.getenv("GEMINI_API_KEY")Dann initialisieren wir den generativen KI-Client von Google. Dies ist das Objekt, mit dem wir mit der Google API kommunizieren können:
client = genai.Client(api_key=api_key)Um ein Bild zu erzeugen, verwenden wir die Funktion client.models.generate_images():
prompt="""
A dog surfing at the beach
"""
response = client.models.generate_images(
model="imagen-3.0-generate-002",
prompt=prompt,
config=types.GenerateImagesConfig(
number_of_images=1,
)
)Schließlich zeigen wir das erzeugte Bild mit dem Objekt Image an:
for generated_image in response.generated_images:
image = Image.open(BytesIO(generated_image.image.image_bytes))
image.show()Hier ist das Ergebnis:

Eine der interessanten Funktionen von Imagen 3 im Vergleich zu anderen Text-Bild-Modellen ist die Möglichkeit, Text zu erzeugen. Probieren wir es aus, indem wir das Wort "Tee" aus frischen Teeblättern erzeugen lassen:
prompt="""
Word "tea" made from fresh tea leaves, white background
"""
response = client.models.generate_images(
model="imagen-3.0-generate-002",
prompt=prompt,
)Hier ist das Ergebnis:

Die Optionen für die Bilderzeugung werden über die types.GenerateImagesConfig Optionen bereitgestellt. Im obigen Beispiel haben wir nur die Anzahl der zu erzeugenden Bilder angegeben:
config=types.GenerateImagesConfig(
number_of_images=1,
)In diesem Abschnitt erkunden wir die anderen Optionen, die die Imagen 3 API bietet. Siehe die offizielle Dokumentation für weitere Informationen.
Wir können den Parameter number_of_images verwenden, um mehrere Bilder mit einer einzigen Eingabeaufforderung zu erzeugen. Standardmäßig werden vier Bilder erstellt.
Versuchen wir, zwei Bilder für einen Comic zu erstellen.
prompt="""
Single comic book panel of two people overlooking a destroyed city.
A speech bubble points from one of them and says: I guess this is the end.
"""
response = client.models.generate_images(
model="imagen-3.0-generate-002",
prompt=prompt,
config=types.GenerateImagesConfig(
number_of_images=2,
)
)Hier ist das Ergebnis:

Dies ist ein weiteres Beispiel für die Erstellung von Text in Bildern. Auch wenn das Bild auf der linken Seite zusätzlichen unerwünschten Text enthält, können wir durch die Möglichkeit, mehrere Bilder zu erstellen, unsere Chancen erhöhen, das gewünschte Ergebnis zu erhalten. Das Bild auf der rechten Seite entspricht fast vollständig unserer Aufforderung.
Standardmäßig sind die erzeugten Bilder quadratisch und haben ein Seitenverhältnis von 1:1. Das Modell unterstützt die folgenden Seitenverhältnisse: 1:1, 3:4, 4:3, 9:16, und 16:9.
Lass uns ein 9:16 Bild erstellen, das wir als Telefonhintergrund verwenden können:
prompt="""
A drone shot of a river flowing between mountains with a stormy sky.
"""
response = client.models.generate_images(
model="imagen-3.0-generate-002",
prompt=prompt,
config=types.GenerateImagesConfig(
aspect_ratio="9:16",
)
)Hier ist das Ergebnis:

In der Dokumentation wird erwähnt, dass wir die safety_filter_level verwenden können, um den Grad der Bildfilterung festzulegen. Jedes generierte Bild erhält einen Wahrscheinlichkeitswert, der die Wahrscheinlichkeit misst, dass das Bild unsicher ist (z. B. unangemessener Inhalt).
Die Einstellung des Filters für die Sicherheitsstufe ist wichtig, weil sie dazu beiträgt, dass die generierten Inhalte angemessen sind und den Präferenzen der Nutzer/innen entsprechen.
In der Dokumentation steht, dass es drei Stufen unterstützt:
BLOCK_LOW_AND_ABOVE: Blockiere das Bild auch bei einer niedrigen Wahrscheinlichkeitszahl.BLOCK_MEDIUM_AND_ABOVE : Blockiere nur Bilder mit mittleren und hohen Wahrscheinlichkeitswerten.BLOCK_ONLY_HIGH : Nur Bilder mit einer hohen Wahrscheinlichkeitsbewertung blockierenNach einigen Versuchen unterstützt die API jedoch nur noch die Option BLOCK_LOW_AND_ABOVE. Jede andere Angabe führt zu einem Fehler.
Mit der Option person_generation können wir steuern, ob das Modell Personen erzeugen darf. Sie bietet zwei Optionen:
DONT_ALLOW: Bilder, auf denen Menschen zu sehen sind, werden gesperrt.ALLOW_ADULT: So können wir Bilder mit Menschen (nur Erwachsene) erstellen.Die Standardoption ist, Menschen zuzulassen. Wenn wir zum Beispiel die Option "Personen nicht zulassen" einstellen und versuchen, ein Bild von jemandem zu erzeugen, der kocht, werden wir keine Bilder erhalten.
prompt="""
A person cooking.
"""
response = client.models.generate_images(
model="imagen-3.0-generate-002",
prompt=prompt,
config=types.GenerateImagesConfig(
person_generation="DONT_ALLOW",
)
)
print(response.generated_images)Hier ist die Ausgabe:
NoneDie offizielle Dokumentation bietet eine umfassende Anleitung zur Eingabeaufforderung für Imagen 3, daher werde ich sie hier nicht wiederholen. Hier sind die wichtigsten Ideen, wie du einen guten Prompt erstellen kannst:
Imagen 3 bietet auch die Möglichkeit, Bilder zu bearbeiten und anzupassen. Leider sind diese Funktionen immer noch gesperrt und nur für bestimmte Nutzer zugänglich.
Die Anpassungsfunktion ermöglicht es uns zum Beispiel, ein Referenzbild aus einer Eingabeaufforderung heraus anzupassen. In dem Beispiel wird ein Foto einer Frau gegeben, und die Eingabeaufforderung ändert dieses Bild in eines, auf dem dieselbe Person Orangen hält.

Weitere Informationen dazu und das Antragsformular für den Zugang finden Sie auf ihrer Website.
In diesem Lernprogramm haben wir gelernt, wie man mit Imagen 3 Bilder mit Python und der Generativen API von Google erstellt. Insgesamt bin ich mit den Ergebnissen zufrieden, die ich beim Experimentieren mit der API erhalten habe. Ich habe das Gefühl, dass die Ergebnisse von hoher Qualität sind und weniger KI-Artefakte enthalten, wodurch es schwieriger wird, sie von echten Bildern zu unterscheiden.
Die Möglichkeit, mit Text in Bildern zu arbeiten, ist nützlich für Branding und Marketing. Insgesamt finde ich, dass dieses Modell gut funktioniert. Ich wünschte nur, alle Funktionen wären offen, denn ich finde, dass die Bildbearbeitung noch nützlicher ist als die Bilderstellung.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
