
Lernpfad
Grundlagen der KI
10 Std.
Fangen wir mit ein paar grundlegenden Fragen für Vorstellungsgespräche zum Thema generative KI an. Hier wird dein Verständnis der wichtigsten Konzepte und Prinzipien getestet.
Diskriminierende Modelle lernen die Entscheidungsgrenze zwischen Klassen und Mustern, die sie voneinander unterscheiden. Sie schätzen die Wahrscheinlichkeits P(y|x), also die Wahrscheinlichkeit , dass ein bestimmtes Label y auftritt , wenn die Eingabedaten x vorliegen . Diese Modelle konzentrieren sich darauf, verschiedene Kategorien zu unterscheiden (z. B.„Ist diese E-Mail Spam?“).
Generative Modelle lernen die Verteilung der Daten selbst, indem sie die gemeinsame Wahrscheinlichkeit P(x,y)modellieren , was das Sammeln von Datenpunkten aus dieser Verteilung beinhaltet. Nachdem das System mit Tausenden von Zahlenbildern trainiert wurde, kann es ein neues Zahlenbild erzeugen.
Mehr dazu findest du in diesem Blog unter „ “ Generative vs. diskriminative Modelle: Unterschiede und Anwendungsfälle.
Tokens sind die grundlegenden Texteinheiten, die ein LLM verarbeitet; das können ganze Wörter, Silben oder sogar einzelne Buchstaben sein (zum Beispiel könnte das Wort „generative“ in „gener“, „at“ und „ive“ aufgeteilt werden).
Einbettungen sind die numerischen Vektordarstellungen dieser Token, die sie anhand ihrer Bedeutung in einem mehrdimensionalen Raum platzieren. Durch diese Umwandlung kann das Modell die Bedeutung von Wörtern erfassen und die Beziehungen zwischen ihnen verstehen, zum Beispiel, dass „König“ nah an „Königin“ dran ist.
GANs bestehen aus zwei konkurrierenden neuronalen Netzen (daher der Begriff „Adversarial“): einem Generator und einem Diskriminator.
Der Generator macht gefälschte Datenproben, während der Diskriminator sie anhand der echten Trainingsdaten überprüft. Die beiden Netzwerke werden gleichzeitig trainiert:
Durch dieses konkurrierende Lernen lernt der Generator, echt realistische Daten zu machen, die den Trainingsdaten ähnlich sind.
Die weit verbreitete Nutzung von GenAI und ihre Anwendungsfälle erfordern eine gründliche Bewertung ihrer Leistung in Bezug auf Ethik. Einige Beispiele sind:
Auch wenn die Halluzinationen von KI-Modellen zu fehlerhaften Ergebnissen führen können, sind diese generativen Modelle in vielerlei Hinsicht und für viele Anwendungen nützlich. Sie können als kreative Inspiration für Experten in verschiedenen Bereichen dienen:
Ein Foundation-Modell (wie GPT-5.2) wird mit riesigen Mengen an Internetdaten trainiert, um allgemeine Muster, Schlussfolgerungen und Sprachstrukturen zu lernen.
Ein fein abgestimmtes Modell nutzt diese allgemeine Basis und trainiert sie weiter mit einem kleineren, speziell zusammengestellten Datensatz, um eine bestimmte Aufgabe zu meistern, wie zum Beispiel medizinische Diagnosen oder das Sprechen in einer bestimmten Programmiersprache. Feinabstimmung bedeutet, dass man vielseitige Fähigkeiten gegen tieferes Fachwissen in einem bestimmten Bereich eintauscht.
Nachdem wir jetzt die Grundlagen geklärt haben, schauen wir uns ein paar fortgeschrittene Fragen zu generativer KI für Vorstellungsgespräche an.
Genau wie ein Content-Ersteller, der feststellt, dass ein bestimmtes Videoformat zu mehr Reichweite und Interaktionen führt, könnte sich das generative Modell eines GAN wahrscheinlich auf eine begrenzte Vielfalt von Outputs fixieren, die das Diskriminator-Modell täuschen. Das führt dazu, dass der Generator nur wenige Ergebnisse liefert, was die Vielfalt und Flexibilität der generierten Daten beeinträchtigt.
Mögliche Lösungen dafür könnten sein, sich auf Trainingstechniken zu konzentrieren, indem man die Hyperparameter und verschiedene Optimierungsalgorithmen anpasst, Regularisierungen anwendet, die die Vielfalt fördern, oder mehrere Generatoren kombiniert, um verschiedene Arten der Datengenerierung abzudecken.
Ein Variational Autoencoder (VAE) ist eine Art generatives Modell, das lernt, Eingabedaten in einen latenten Raum zu kodieren und sie wieder zu dekodieren, um die ursprünglichen Eingabedaten zu rekonstruieren. VAEs sind Encoder-Decoder-Modelle:
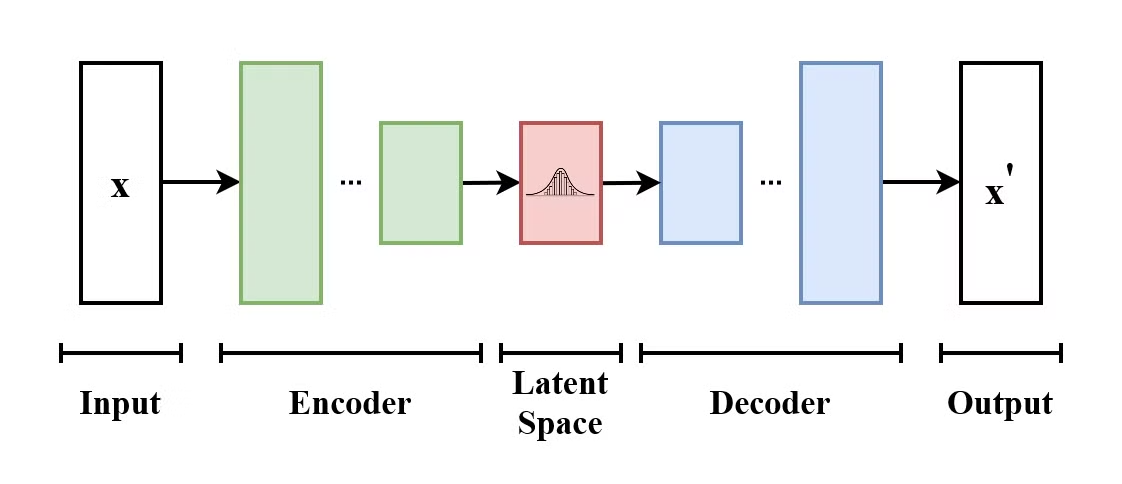
Die Struktur eines Variational Autoencoders. (Quelle: Wikimedia Commons)
Was VAE von herkömmlichen Autoencodern unterscheidet, ist, dass VAE den latenten Raum dazu bringt, einer bekannten Verteilung (wie der Gaußschen) zu folgen. Dadurch sind sie besser geeignet, um neue Daten zu generieren, indem sie aus diesem latenten Raum Proben nehmen.
RAG ( ) verbindet ein Modell mit externen Datenquellen (wie dem Wiki deines Unternehmens), um aktuelle Fakten abzurufen, ohne das Modell neu trainieren zu müssen. Die Parameter des Modells bleiben gleich; es hat nur Zugriff auf zusätzliche Daten.
Durch Feinabstimmung werden die internen Gewichte des Modells angepasst, um seine Art zu sprechen, sich zu verhalten oder zu denken zu verändern, aber es ist nicht gut, um neues Faktenwissen hinzuzufügen.
Benutz RAG, wenn du aktuelle Infos (Nachrichten, Daten von privaten Unternehmen) oder ein bestimmtes Zitat brauchst. Nutze die Feinabstimmung, wenn das Modell ein neues „Verhalten“, eine neue Sprache oder ein bestimmtes Ausgabeformat lernen soll (z. B. das Sprechen in SQL-Code).
Die Bewertung der generierten Beispiele ist eine knifflige Sache, die davon abhängt, um welche Art von Daten es geht (: Bilder, Texte, Videos usw.). Traditioneller Text Metrikwie Genauigkeit reichen für kreative Aufgaben nicht aus, weil sie nur nach Wortüberschneidungen suchen, nicht nach der Bedeutung.
LLM-Benchmarks und Ranglisten nutzen standardisierte Tests, um zu messen, wie gut ein Modell eine bestimmte Aufgabe erledigt. Sie sind super, um Modelle zu vergleichen und den Fortschritt innerhalb oder zwischen verschiedenen Modalitäten zu verfolgen.
LLM-as-a-Judge ist ein cooles Bewertungssystem, bei dem ein echt starkes „Lehrer”-Modell (wie Gemini 3) die Ergebnisse eines kleineren Modells nach bestimmten Kriterien wie Genauigkeit, Nützlichkeit und Tonfall bewertet. Das ist eine skalierbare Möglichkeit, menschliche Präferenzen zu erfassen, ohne dass es so langsam und teuer ist wie eine manuelle Überprüfung durch Menschen.
Die Stabilität und Konvergenz beim GAN-Training zu verbessern ist wichtig, um einen Modus-Kollaps zu vermeiden, ein effizientes Training zu gewährleisten und gute Ergebnisse zu erzielen. Hier sind ein paar Techniken, um die Stabilität und Konvergenz des GAN-Trainings zu verbessern:
Es gibt ein paar gängige Techniken, um den Stil der GenAI-Ausgaben zu steuern:
Um sicherzustellen, dass das Modell unvoreingenommen und fair ist, sind in jeder Phase immer wieder Anpassungen und Kontrollen nötig.
Zuerst muss man Datenverfälschung verhindern, indem man sicherstellt, dass keine Testdaten in die Trainingsdaten gelangen. In diesem Fall würde das Modell darauf trainiert werden, sich die Daten zu merken, anstatt sie zu verallgemeinern.
Außerdem müssen wir dafür sorgen, dass die Trainingsdaten so vielfältig und inklusiv wie möglich sind. Während des Trainings können wir das Modell zu einer faireren Generierung führen, indem wir Fairness-Ziele in die Verlustfunktion einbauen.
Die Modellausgaben müssen regelmäßig auf Verzerrungen überprüft werden. Um das Vertrauen der Öffentlichkeit zu gewinnen, ist es gut, den Entscheidungsprozess des Modells, die Details des Datensatzes und die Vorverarbeitungsschritte so transparent wie möglich zu machen.
Bei generativen Modellen ist der latente Raum ein Raum mit weniger Dimensionen, der die wichtigsten Merkmale der Daten so erfasst, dass ähnliche Eingaben näher beieinander liegen. Durch die Stichprobenentnahme aus diesem latenten Raum können die Modelle neue Daten generieren und bestimmte Attribute oder Merkmale manipulieren (Variationen von Bildern erzeugen).
Latente Räume sind super wichtig, um Ergebnisse zu machen, die man gut im Griff hat, die den Trainingsdaten entsprechen und die vielfältig sind.
Die Hauptidee beim selbstüberwachten Lernen ist, einen riesigen Korpus unbeschrifteter Daten zu nutzen, um nützliche Darstellungen zu lernen, ohne dass manuelle Beschriftungen nötig sind. Modelle wie BERT und GPT werden mit selbstüberwachenden Methoden wie der Vorhersage des nächsten Tokens und dem Lernen der Struktur und Semantik von Sprachen trainiert. Dadurch muss man sich nicht mehr so sehr auf beschriftete Daten verlassen, die teuer und zeitaufwendig sind. So können Modelle im Grunde riesige unbeschriftete Datensätze fürs Training nutzen.
Ein riesiges Modell mit 70 Milliarden Parametern neu zu trainieren, ist für die meisten Unternehmen einfach zu teuer und dauert viel zu lange. Low-Rank Adaptation (LoRA) löst das, indem es die Hauptmodellgewichte einfriert und nur eine winzige „Adapter“-Schicht (oft weniger als 1 % der Gesamtparameter) trainiert, die oben drauf sitzt. So kannst du Dutzende verschiedener „benutzerdefinierter” Modelle von einem einzigen Basismodell aus bereitstellen, was die Rechenkosten und den Speicherbedarf echt runterbringt.
Für alle, die nach höheren Positionen suchen oder ihr tiefes Verständnis von generativer KI zeigen wollen, schauen wir uns ein paar fortgeschrittene Interviewfragen an.
Diffusionsmodelle funktionieren im Wesentlichen so, dass sie nach und nach Rauschen zu einem Bild hinzufügen, bis nur noch Rauschen übrig ist – und dann lernen sie, wie man diesen Prozess umkehrt, um aus dem Rauschen neue Samples zu erzeugen. Dieser Prozess heißt„ diffusion“ (). Diese Modelle sind echt beliebt geworden, weil sie super hochwertige und super detaillierte Bilder machen können.

Erzeugung eines Bildes durch Diffusionsschritte. (Quelle: Wikimedia Commons)
Der Prozess zum Trainieren dieser Modelle besteht aus zwei Schritten:
Im Gegensatz zu älteren GANs, die oft Probleme mit der Trainingsstabilität hatten, sind Diffusionsmodelle stabiler und besser skalierbar, können aber wegen ihrer iterativen Natur langsamer sein.
Moderne Varianten wie die latente Diffusion arbeiten in einem komprimierten „latenten Raum“, um die Generierung zu beschleunigen, und Flow-Matching-Architekturen ersetzen jetzt die Standarddiffusion, um eine noch bessere Leistung zu erzielen.
Die Transformatorarchitektur , die in dem Artikel „Attention is All You Need”, hat den Bereich der generativen KI, vor allem in der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), total verändert.
Im Gegensatz zu herkömmlichen rekurrenten neuronalen Netzen (RNNs), die Daten sequenziell verarbeiten, verwenden Transformer den Selbstaufmerksamkeitsmechanismus, um verschiedenen Teilen der Eingabedaten gleichzeitig Gewichte zuzuweisen. Dadurch kann das Modell kontextuelle Beziehungen effektiv erfassen und Sequenzen parallel verarbeiten, was das Training deutlich beschleunigt.
Das Hauptproblem ist, dass dieser Aufmerksamkeitsmechanismus quadratisch mit der Sequenzlänge wächst – wenn man das Kontextfenster verdoppelt, braucht man viermal so viel Rechenleistung. Das macht „unendlichen Kontext“ theoretisch möglich, aber rechnerisch aufwendig, was die Forschung zu effizienteren Aufmerksamkeitsmethoden vorantreibt.
Standard-LLMs denken wie „System 1“-Denker und sagen das nächste Wort sofort voraus, indem sie sich an oberflächlichen Mustern orientieren.
Argumentationsmodelle (wie Gemini 3 oder DeepSeek-R1) sind so trainiert, dass sie eine versteckte „Gedankenkette” bilden, bevor sie eine Antwort geben. So können sie „denken”, planen und Fehler selbst korrigieren. Dadurch sind sie bei komplizierten Matheaufgaben, Programmierung und Logikrätseln echt besser, auch wenn sie langsamer und teurer im Betrieb sind.
Wenn du die Komplexität der KI-Generierung erhöhst, solltest du auch Folgendes angehen:
Der Bereich der generativen KI entwickelt sich schnell weiter und verändert sich ständig. Das umfasst:
Ein System zu entwickeln, das generative KI für bestimmte Anwendungsfälle in der Industrie nutzt, ist ein ziemlich gründlicher Ansatz. Die allgemeinen Richtlinien können auch für andere Branchen angepasst und geändert werden.
Kontextbezogenes Lernen ist die Fähigkeit von LLMs, ihren Stil und ihre Ergebnisse je nach Kontext anzupassen, ohne dass man sie extra feinabstimmen muss.
Man könnte es auch als Few-Shot-Lernen oder Prompt Engineering Das kann man erreichen, indem man ein oder mehrere Beispiele für die gewünschte Reaktion angibt oder genau beschreibt, wie sich das Modell verhalten soll.
Das kontextbezogene Lernen hat auch seine Grenzen. Es ist kurzfristig und auf bestimmte Aufgaben ausgerichtet, weil das Modell bei anderen Sitzungen, in denen diese Technik angewendet wird, eigentlich kein Wissen behält.
Außerdem braucht das Modell vielleicht viele Beispiele, wenn die gewünschte Ausgabe kompliziert ist. Wenn die Beispiele nicht klar genug sind oder die Aufgabe schwieriger ist, als das Modell bewältigen kann, kann es manchmal falsche oder unlogische Ergebnisse liefern.
Prompting ist wichtig, um LLMs dazu zu bringen, auf bestimmte Aufgaben zu reagieren. Effektive Eingabeaufforderungen können sogar die Notwendigkeit der Feinabstimmung von Modellen verringern, indem Techniken wie Few-Shot-Lernen, Aufgabenzerlegung und Eingabeaufforderungsvorlagen eingesetzt werden.
Einige bewährte Verfahren für effektives und schnelles Engineering sind:
Mehr dazu findest du in diesem Blog unter Techniken zur Optimierung von Eingabeaufforderungen.
Bei der bedingten Generierung macht das Modell Ergebnisse, die auf bestimmten Bedingungen oder Kontexten basieren. Dadurch kann man den erstellten Inhalt besser kontrollieren. Bei bedingten GANs (cGANs) hängen sowohl der Generator als auch der Diskriminator von zusätzlichen Infos ab, wie zum Beispiel Klassenbezeichnungen. So geht's:
Mixture of Experts (MoE) ersetzt ein einzelnes dichtes neuronales Netzwerk durch viele spezialisierte „Experten”-Subnetzwerke. Für jedes Token wählt ein Router nur die relevantesten Experten aus, um die Daten zu verarbeiten. Das heißt, ein Modell kann 100 Milliarden Parameter haben, aber nur 10 Milliarden für die Inferenz nutzen.
Diese Architektur macht Modelle echt clever (viele Parameter insgesamt), während sie trotzdem schnell und günstig laufen (wenige aktive Parameter).
Wenn du dich für eine Stelle als KI-Ingenieur mit Schwerpunkt auf generativer KI bewirbst, solltest du dich auf Fragen einstellen, die deine Fähigkeiten beim Entwerfen, Implementieren und Einsetzen generativer Modelle testen.
Ein normaler Chatbot ist eher passiv: Er kriegt eine Frage und gibt dann eine Antwort, die er gelernt hat.
Ein agenter Workflow gibt dem LLM Zugriff auf Tools (wie einen Webbrowser, einen Code-Interpreter oder eine API) und die Freiheit, einen mehrstufigen Prozess zu planen, um ein Ziel zu erreichen. Der Agent könnte planen, das Internet zu durchsuchen, die Daten mit Python-Code zu analysieren und dann einen Bericht zu schreiben, wobei er so lange weitermacht, bis die Aufgabe erledigt ist.
Die Sicherheit und Robustheit von LLMs zu gewährleisten, bringt einige Herausforderungen mit sich. Eine der größten Herausforderungen ist, dass diese Modelle auf riesigen oder sogar ungefilterten Datenquellen trainiert werden und dadurch möglicherweise schädliche oder irreführende Inhalte erzeugen können.
Ein weiteres großes Problem bei Inhalten, die von LLM generiert werden, ist die Gefahr von Halluzinationen, bei denen das Modell Inhalte erzeugt, die überzeugend klingen, aber eigentlich falsche Infos sind. Eine weitere Herausforderung ist die Sicherheit gegen böswillige Eingaben, die die Sicherheitsmaßnahmen des Modells umgehen und schädliche oder unethische Antworten erzeugen, wie bei verschiedenen Modellen schon oft gezeigt wurde.
Durch den Einsatz von Sicherheitsfiltern und Moderationsschichten kann man schädliche Inhalte, die erstellt werden, besser erkennen und entfernen. Die ständige Überwachung durch Menschen macht das Modell noch sicherer.
Außerdem müssen Ingenieure explizite Schutzvorrichtungen (wie NeMo Guardrails oder Llama Guard) einbauen, die zwischen dem Benutzer und dem Modell stehen. Diese Systeme checken Eingaben, um Versuche von Prompt-Injection oder das Durchsickern von personenbezogenen Daten zu verhindern, und checken auch die Ausgaben, um schädliche oder irreführende Antworten abzufangen, bevor sie den Nutzer erreichen. Das macht eine sichere Ebene, die unabhängig von der Wahrscheinlichkeit des Modells funktioniert.
Die Antwort auf diese Frage hängt echt von deinen Projekten und Erfahrungen ab. Du kannst aber diese Punkte im Hinterkopf behalten, wenn du solche Fragen beantwortest:
Genau wie die Frage oben kannst du diese Frage nach deiner Erfahrung beantworten, aber denk auch daran, dass:
Selbst bei riesigen Kontextfenstern (z. B. 1 Million Token) haben LLMs oft Probleme, Infos zu finden, die mitten in der Eingabe versteckt sind, und konzentrieren sich stattdessen auf den Anfang und das Ende.
Ingenieure machen das wieder wett, indem sie clevere Algorithmen zum Neuanordnen nutzen, die die wichtigsten gefundenen Teile an den Anfang oder das Ende des Kontextfensters verschieben. Eine andere Strategie ist der „Map-Reduce“-Algorithmus, bei dem das Modell Teile des langen Dokuments erst mal unabhängig voneinander zusammenfasst, bevor es sie für eine endgültige Antwort kombiniert.
Ein RAG-System aufzubauen braucht einen systematischen Ansatz. So könnte die Pipeline aussehen:
Die Antwort hängt auch hier von deinen persönlichen Vorlieben ab, aber hier sind ein paar Themen, die du ansprechen kannst:
Da generative KI immer mehr Einfluss auf unser Leben und unsere Karrieren nimmt, ist es wichtig, die wesentlichen Themen im Auge zu behalten. Die möglichen GenAI-Fragen, die man in einem Vorstellungsgespräch stellen kann, hängen zwar von der jeweiligen Position und dem Unternehmen ab, aber ich habe versucht, 30 Fragen und Antworten zusammenzustellen, um dir den Einstieg in die Vorbereitung auf dein Vorstellungsgespräch zu erleichtern.
Um mehr Interviewfragen zu entdecken, empfehle ich dir diese Blogs:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach