Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Die neu eingeführte OpenAI Realtime API ermöglicht es uns, schnelle, multimodale Erlebnisse mit geringer Latenz in unsere Anwendungen zu integrieren. Mit dieser API können wir nahtlose Speech-to-Speech-Interaktionen zwischen Nutzern und großen Sprachmodellen (LLMs).
Diese API macht mehrere Modelle für sprachgesteuerte Erlebnisse überflüssig, da sie die komplette Lösung in einer einzigen integrierten API bietet. Es zielt nicht nur darauf ab, die Latenzzeit zu reduzieren, sondern auch die emotionalen Nuancen und den natürlichen Fluss von Gesprächen zu erhalten.
In diesem Artikel lernen wir, wie man die OpenAI Realtime API nutzt, um sprachgesteuerte KI-Assistenten zu bauen. Wir werden persistente WebSocket-Verbindungen mit Node.js erstellen und erfahren, wie diese im Terminal genutzt werden können, um mit der API zu kommunizieren. Außerdem zeige ich dir, wie du eine React-App einrichtest, die die Möglichkeiten dieser API nutzt.
Zur Verwendung der OpenAI Realtime API zu nutzen, müssen wir zunächst einen API-Schlüssel erstellen. Navigieren Sie dazu zur der API-Schlüssel-Seite. Beachte, dass dafür ein Konto erforderlich ist. Klicke oben auf der Seite auf die Schaltfläche "Neuen geheimen Schlüssel erstellen".

Ein Pop-up-Fenster wird geöffnet. Wir können die Standardoptionen verwenden und auf "Geheimschlüssel erstellen" klicken.
Wenn der Schlüssel erstellt ist, bekommen wir die Möglichkeit, ihn zu kopieren. Achte darauf, dass du ihn kopierst, bevor du das Fenster schließt, denn nur dann wird er angezeigt.
Wenn der Schlüssel verloren geht, können wir ihn jederzeit löschen und einen neuen Schlüssel erstellen.
Um den Schlüssel zu speichern, empfehlen wir, eine Datei mit dem Namen .env zu erstellen und den Schlüssel dort im folgenden Format zu speichern:
OPENAI_API_KEY=<paste_they_key_here>Wir werden diese Datei in diesem Artikel verwenden, um uns mit der API zu verbinden.
Bevor du fortfährst, solltest du wissen, dass die Realtime API nicht kostenlos ist und wir Guthaben auf unser Konto laden müssen, um sie zu nutzen. Wir können Guthaben auf der Abrechnungsseitehinzufügen, die sich in unserem Profil befindet.
Um eine Vorstellung von den Kosten zu bekommen, hier ein Überblick darüber, wie viel es mich gekostet hat, mit der API zu experimentieren, während ich an diesem Artikel gearbeitet habe:
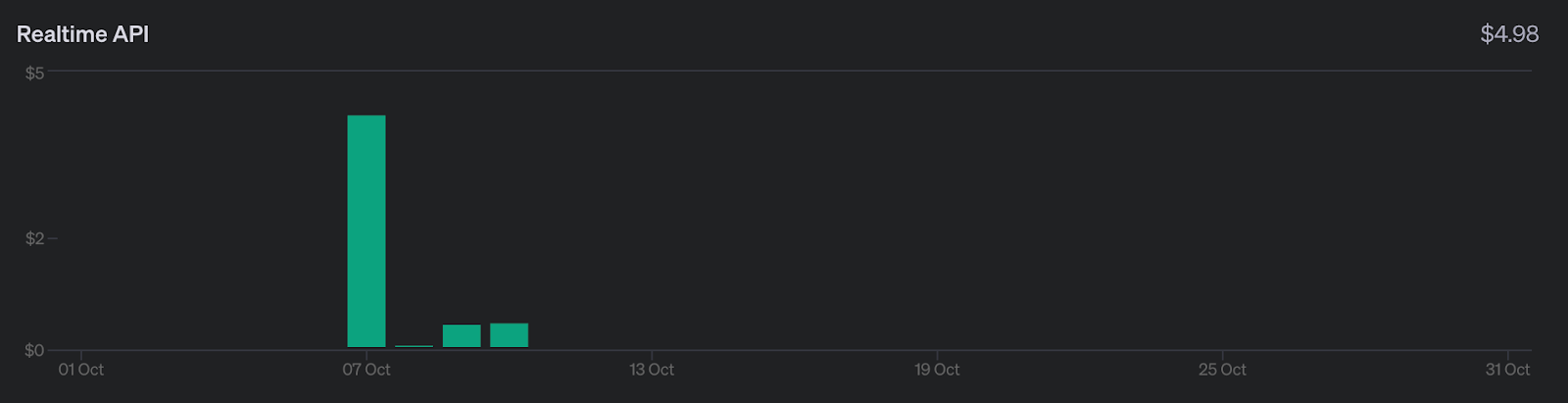
Ich habe insgesamt etwa fünf Dollar ausgegeben. Das ist kein großer Betrag, aber viel teurer als die anderen APIs von OpenAI. Denke daran, wenn du an diesem Artikel arbeitest.
Der größte Teil der Kosten (erster Balken) entfällt auf das Spielen mit der React-Konsolen-App, die wir am Ende dieses Artikels untersuchen. Der Rest, etwa ein halber Dollar, ist das, was es mich gekostet hat, die API über WebSockets zu nutzen. Deshalb ist es möglich, diesen Artikel für weniger als einen Dollar zu lesen.
Weitere Informationen zu den Preisen der API findest du im Abschnitt "Realtime API" auf ihrer Preisseite.
Im Gegensatz zu anderen Komponenten der OpenAI APInutzt die Realtime API WebSockets. WebSockets ist ein Kommunikationsprotokoll, das einen bidirektionalen Kommunikationskanal zwischen einem Client und einem Server einrichtet. Im Gegensatz zum herkömmlichen Anfrage-Antwort-Modell von HTTP unterstützen WebSockets laufende Interaktionen in Echtzeit. Dadurch eignen sich WebSockets besonders gut für Echtzeitanwendungen, wie z.B. Voice-Chat.
In diesem Artikel erfährst du, wie WebSockets funktionieren und findest einige Beispiele für die Interaktion mit der Realtime API.
Wir werden Node.js verwenden, also müssen wir sicherstellen, dass es auf unserem Computer installiert ist. Wenn nicht, können wir Node.js von der offiziellen Website herunterladen und installieren. der offiziellen Website.
Wir empfehlen, einen Ordner mit der oben erstellten .env Datei anzulegen. In diesem Ordner führst du den folgenden Befehl aus, um das Skript zu initialisieren:
npm init -y && touch index.jsNach Beendigung dieses Befehls sollten sich diese Dateien in dem Ordner befinden:

Beginne mit der Installation von zwei Paketen:
ws: Dies ist das WebSocket-Paket, das Hauptpaket, das für die Interaktion mit der API benötigt wird.dotenv: Ein Hilfspaket, das den API-Schlüssel aus der Datei .env lädt.Installiere sie, indem du den Befehl ausführst:
npm install ws dotenvUm eine Verbindung mit der Echtzeit-API herzustellen, erstellen wir ein neues WebSocket Objekt, das die API-URL und die Header mit den erforderlichen Informationen zur Verbindung übergibt:
// Import the web socket library
const WebSocket = require("ws");
// Load the .env file into memory so the code has access to the key
const dotenv = require("dotenv");
dotenv.config();
function main() {
// Connect to the API
const url = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-10-01";
const ws = new WebSocket(url, {
headers: {
"Authorization": "Bearer " + process.env.OPENAI_API_KEY,
"OpenAI-Beta": "realtime=v1",
},
});
}
main();Der obige Code stellt die Web-Socket-Verbindung zur API her, macht aber noch nichts mit ihr.
WebSockets ermöglichen es uns, Aktionen einzurichten, die ausgeführt werden, wenn bestimmte Ereignisse eintreten. Wir können das Ereignis open verwenden, um einen Code anzugeben, der ausgeführt werden soll, sobald die Verbindung hergestellt ist.
Die allgemeine Syntax zum Hinzufügen eines Ereignis-Listeners lautet wie folgt:
ws.on(<event>, <function>);Ersetze durch eine Zeichenkette mit dem Namen des Ereignisses und durch eine Funktion, die ausgeführt wird, wenn das Ereignis eintritt.
So können wir den Text anzeigen, sobald die Verbindung hergestellt ist:
// Add inside the main() function of index.js after creating ws
async function handleOpen() {
console.log("Connection is opened");
}
ws.on("open", handleOpen);Um diesen Code auszuführen, verwenden wir den Befehl:
node index.jsWenn der API-Schlüssel richtig gesetzt ist, wird im Terminal die Meldung "Verbindung ist offen" angezeigt. Das Skript läuft weiter, weil die Verbindung noch offen ist, also müssen wir es manuell stoppen.
Ein weiteres Ereignis, auf das wir bei der Verwendung von WebSockets reagieren können, ist das message Ereignis. Dies wird jedes Mal ausgelöst, wenn eine Nachricht vom Server empfangen wird. Fügen wir eine Funktion hinzu, die jede empfangene Nachricht anzeigt:
// Add inside the main() function of index.js
async function handleMessage(messageStr) {
const message = JSON.parse(messageStr);
console.log(message);
}
ws.on("message", handleMessage);Wenn Sie das Skript jetzt ausführen, sollte auch das session.created Ereignis anzeigen, das die API bei der Initialisierung der Sitzung sendet.
Oben haben wir gelernt, wie man Ereignislisten für die Ereignisse open und message hinzufügt. WebSockets unterstützen zwei zusätzliche Ereignisse, die wir in unseren Beispielen nicht verwenden werden.
Das Ereignis close kann verwendet werden, um einen Callback hinzuzufügen, wenn der Socket geschlossen wird:
async function handleClose() {
console.log(“Socket closed”);
}
ws.on(“close”, handleClose);Das Ereignis error wird verwendet, um einen Callback hinzuzufügen, wenn ein Fehler auftritt:
async function handleError(error) {
console.log(“Error”, error);
}
ws.on(“error”, handleError);Die Arbeit mit WebSockets erfordert, dass wir in einer ereignisgesteuert Weise zu programmieren. Nachrichten werden über den Kommunikationskanal hin- und hergeschickt, und wir können nicht kontrollieren, wann diese Nachrichten zugestellt oder empfangen werden.
Der Code, der die Kommunikation initiiert, sollte innerhalb von handleOpen() eingefügt werden. O Andernfalls würde ein Fehler auftreten, da dieser Code ausgeführt werden könnte, bevor der Web-Socket-Kommunikationskanal erstellt wird.
Das Gleiche gilt für den Code, der die Nachrichten verarbeitet. Die gesamte Logik sollte in der Funktion handleMessage() enthalten sein.
In den folgenden Beispielen werden wir den folgenden Code als Ausgangspunkt verwenden. Die meisten Änderungen betreffen die Aktualisierung von handleOpen() und handleMessage().
// Import the web socket library
const WebSocket = require("ws");
// Load the .env file into memory so the code has access to the key
const dotenv = require("dotenv");
dotenv.config();
function main() {
// Connect to the API
const url = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-10-01";
const ws = new WebSocket(url, {
headers: {
"Authorization": "Bearer " + process.env.OPENAI_API_KEY,
"OpenAI-Beta": "realtime=v1",
},
});
async function handleOpen() {
console.log("Connection is opened");
}
ws.on("open", handleOpen);
async function handleMessage(messageStr) {
const message = JSON.parse(messageStr);
console.log(message);
}
ws.on("message", handleMessage);
}
main();Die Kommunikation mit der Realtime API erfolgt über Ereignisse. Die OpenAI Echtzeit-Dokumentation API listet die Ereignisse auf, die sie unterstützt. Wir verwenden das conversation.item.create Ereignis um eine Konversation einzuleiten. Ereignisse werden als JSON-Objekte dargestellt, deren Felder in der Dokumentation beschrieben werden.
Hier ist ein Beispiel für eine conversation.item.create Ereignis, das die Aufforderung "Erkläre in einem Satz, was ein Websocket ist" sendet:
const createConversationEvent = {
type: "conversation.item.create",
item: {
type: "message",
role: "user",
content: [
{
type: "input_text",
text: "Explain in one sentence what a web socket is"
}
]
}
};Dieses Ereignis teilt der API mit, dass wir eine textuelle Konversation beginnen wollen. Dies wird im Feld content angegeben, wobei ein Typ von ”input_text” verwendet wird und eine Textabfrage erfolgt.
Wir verwenden die Methode ws.send(), um eine Nachricht zu senden. Das Websocket-Paket erwartet einen String als Argument, also müssen wir unser JSON-Ereignis mit der Funktion JSON.stringify() in einen String umwandeln. So können wir das obige Ereignis verschicken:
ws.send(JSON.stringify(createConversationEvent));Dadurch wird die Konversation eingeleitet, aber die API schickt uns nicht automatisch eine Antwort. Um eine Antwort auszulösen, senden wir ein response.create Ereignis. Hier ist ein Beispiel:
const createResponseEvent = {
type: "response.create",
response: {
modalities: ["text"],
instructions: "Please assist the user.",
}
}
ws.send(JSON.stringify(createResponseEvent));Dieses Ereignis verwendet den Antwortparameter modalities, um eine textuelle Antwort anzufordern. Die Anweisungen sind der wichtigste Teil. Sie beschreiben, was das Modell tun soll, in diesem Fall eine allgemeine Aufforderung, dem Benutzer zu helfen.
Wir senden diese beiden Ereignisse in der Funktion handleOpen(), damit eine Konversation begonnen wird, sobald die Verbindung hergestellt ist. Hier ist die vollständige Implementierung der Funktion handleOpen() aus diesem Beispiel:
async function handleOpen() {
// Define what happens when the connection is opened
// Create and send an event to initiate a conversation
const createConversationEvent = {
type: "conversation.item.create",
item: {
type: "message",
role: "user",
content: [
{
type: "input_text",
text: "Explain in one sentence what a web socket is"
}
]
}
};
// Create and send an event to initiate a response
ws.send(JSON.stringify(createConversationEvent));
const createResponseEvent = {
type: "response.create",
response: {
modalities: ["text"],
instructions: "Please assist the user.",
}
}
ws.send(JSON.stringify(createResponseEvent));
}Bei den eingehenden Nachrichten gibt es drei Arten von Ereignissen, die für dieses Beispiel erwähnenswert sind: die Ereignisse response.text.delta, response.text.done und response.done:
response.text.delta Ereignisse enthalten die Antwort in Chunks unterteilt im Feld delta. Sie sind wichtig, wenn wir ein Echtzeit-Erlebnis bieten wollen, denn sie ermöglichen es uns, die Antwort sofort Stück für Stück zu streamen. response.text.done Ereignis markiert das Ende der textlichen Antwort und enthält die vollständige Antwort im Feld text.response.done Ereignis markiert das Ende der Antwort.Wir können festlegen, wie unser Skript auf diese Ereignisse reagieren soll, indem wir eine switch Anweisung in der Funktion handleMessage() verwenden:
async function handleMessage(messageStr) {
const message = JSON.parse(messageStr);
// Define what happens when a message is received
switch(message.type) {
case "response.text.delta":
// We got a new text chunk, print it
process.stdout.write(message.delta);
break;
case "response.text.done":
// The text is complete, print a new line
process.stdout.write("\n");
break;
case "response.done":
// Response complete, close the socket
ws.close();
break;
}
}In diesem Beispiel verwenden wir das Ereignis response.text.delta, um Teile der Antwort auf der Konsole auszugeben, sobald wir sie erhalten. Wenn die Antwort vollständig ist, wird das Ereignis response.text.done ausgelöst, und wir drucken eine neue Zeile, um zu zeigen, dass die Ausgabe abgeschlossen ist. Schließlich schließen wir den Websocket, wenn wir das Ereignis response.done erhalten.
Um dieses Beispiel auszuführen, fügen wir diese Funktionen in den obigen Vorlagencode ein und führen ihn mit dem Befehl aus:
node index.jsDies erzeugt eine Antwort im Terminal auf die Aufforderung "Erklären Sie in einem Satz, was ein Websocket ist", ähnlich wie bei der Verwendung von ChatGPT.
Der vollständige Code für das Textbeispiel ist verfügbar hier.
Das vorherige Beispiel hat gezeigt, wie wir mit Textdaten umgehen. Das eigentliche Interesse an der Realtime API besteht jedoch darin, einen Sprachassistenten zu schaffen, der in Echtzeit antwortet.
Der Umgang mit Audiodaten ist etwas komplizierter als der mit Textdaten. Wir werden einige Details zur Funktionsweise von Audio auslassen, da sie uns vom Hauptthema dieses Artikels ablenken würden.
Zuerst installieren wir zwei Pakete:
npm install node-record-lpcm16 speakernode-record-lpcm16 nimmt den Ton vom Mikrofon auf, damit wir eine Sprachansage senden können.speaker wird verwendet, um die KI-Sprachausgabe abzuspielen.Außerdem müssen wir SoX (Sound eXchange) installieren, ein Kommandozeilenprogramm für die Audiobearbeitung, mit dem die Node Library die Schnittstelle zum Mikrofon herstellt und Audio aufnimmt. Verwende brew install sox, um es unter macOS zu installieren, oder sudo apt install sox unter Linux.
Nachdem wir diese Pakete installiert haben, importieren wir sie und fügen eine Funktion startRecording() hinzu, die die Audio-Eingaben des Benutzers aufzeichnet. Wir erklären die Funktion nicht im Detail, denn das würde uns zu sehr von unserem Hauptthema ablenken.
Füge den folgenden Code in die Datei index.js ein, nachdem du die Umgebung geladen hast:
// Add to index.js before the main() function
// Import the web socket library
const WebSocket = require("ws");
// Load the .env file into memory so the code has access to the key
const dotenv = require("dotenv");
dotenv.config();
const Speaker = require("speaker");
const record = require("node-record-lpcm16");
// Function to start recording audio
function startRecording() {
return new Promise((resolve, reject) => {
console.log("Speak to send a message to the assistant. Press Enter when done.");
// Create a buffer to hold the audio data
const audioData = [];
// Start recording in PCM16 format
const recordingStream = record.record({
sampleRate: 16000, // 16kHz sample rate (standard for speech recognition)
threshold: 0, // Start recording immediately
verbose: false,
recordProgram: "sox", // Specify the program
});
// Capture audio data
recordingStream.stream().on("data", (chunk) => {
audioData.push(chunk); // Store the audio chunks
});
// Handle errors in the recording stream
recordingStream.stream().on("error", (err) => {
console.error("Error in recording stream:", err);
reject(err);
});
// Set up standard input to listen for the Enter key press
process.stdin.resume(); // Start listening to stdin
process.stdin.on("data", () => {
console.log("Recording stopped.");
recordingStream.stop(); // Correctly stop the recording stream
process.stdin.pause(); // Stop listening to stdin
// Convert audio data to a single Buffer
const audioBuffer = Buffer.concat(audioData);
// Convert the Buffer to Base64
const base64Audio = audioBuffer.toString("base64");
resolve(base64Audio); // Resolve the promise with Base64 audio
});
});
};Die Funktion startRecording() nimmt Audio vom Mikrofon auf und wartet darauf, dass "Enter" gedrückt wird.
Als Nächstes aktualisieren wir die Funktion main(), indem wir die Speaker() initialisieren, die zum Abspielen der Antwort der KI verwendet wird:
// Add to the main() function after ws is initialized
const speaker = new Speaker({
channels: 1, // Mono or Stereo
bitDepth: 16, // PCM16 (16-bit audio)
sampleRate: 24000, // Common sample rate (44.1kHz)
});Nachdem das geklärt ist, können wir handleOpen() und handleMessage() implementieren, um Audio zu verarbeiten.
In der Funktion handleOpen() müssen wir nur die Funktion startRecording() aufrufen, um den Audio-Prompt des Nutzers aufzuzeichnen. Wir müssen auch die Ereignisse etwas aktualisieren:
createConversationEvent, um den Typ ”input_audio” anstelle von ”input_text zu verwenden und ersetze das Feld text durch audio: base64AudioData.”audio” zu der Antwortmodalität in der createResponseEvent hinzu.Hier ist die aktualisierte handleOpen() Funktion:
async function handleOpen() {
// Define what happens when the connection is opened
const base64AudioData = await startRecording();
const createConversationEvent = {
type: "conversation.item.create",
item: {
type: "message",
role: "user",
content: [
{
type: "input_audio",
audio: base64AudioData,
},
],
},
};
ws.send(JSON.stringify(createConversationEvent));
const createResponseEvent = {
type: "response.create",
response: {
modalities: ["text", "audio"],
instructions: "Please assist the user.",
},
};
ws.send(JSON.stringify(createResponseEvent));
}Um die Funktion handleMessage() zu implementieren, ändern wir das Ereignis ”response.audio.delta”, um den Audiopuffer zu aktualisieren und das neue Sound-Delta abzuspielen:
case "response.audio.delta":
// We got a new audio chunk
const base64AudioChunk = message.delta;
const audioBuffer = Buffer.from(base64AudioChunk, "base64");
speaker.write(audioBuffer);
break;Wir entfernen das Ereignis ”response.text.done” aus der Switch-Anweisung und aktualisieren das Ereignis ”response.done”, um den Sprecher zu stoppen:
case "response.audio.done":
speaker.end();
ws.close();
break;Die endgültige Implementierung der Funktion handleMessage() sieht wie folgt aus:
function handleMessage(messageStr) {
const message = JSON.parse(messageStr);
// Define what happens when a message is received
switch (message.type) {
case "response.audio.delta":
// We got a new audio chunk
const base64AudioChunk = message.delta;
const audioBuffer = Buffer.from(base64AudioChunk, "base64");
speaker.write(audioBuffer);
break;
case "response.audio.done":
speaker.end();
ws.close();
break;
}
}Um dieses Beispiel auszuführen, wende diese Änderungen am Code der Vorlage an und führe sie mit dem Befehl aus:
node index.jsDas Mikrofon beginnt mit der Aufnahme. Wir können unsere Anfrage sagen und "Enter" drücken, um sie zu senden. Dann wird die Antwort der KI über die Lautsprecher abgespielt (vergewissere dich, dass das Mikrofon nicht stummgeschaltet ist und die Lautsprecher eine gute Lautstärke haben).
Der vollständige Code für das Audiobeispiel ist verfügbar hier.
Ein nettes Feature der OpenAI API ist die Möglichkeit, Funktionsaufrufe. Wir können dem Assistenten Funktionen hinzufügen und wenn er erkennt, dass eine dieser Funktionen nützlich sein könnte, um die Antwort zu liefern, sendet er ein Ereignis, das den Aufruf einer bestimmten Funktion anfordert.
In der OpenAI-Dokumentation findest du das folgende Diagramm, das den Lebenszyklus eines Funktionsaufrufs erklärt:
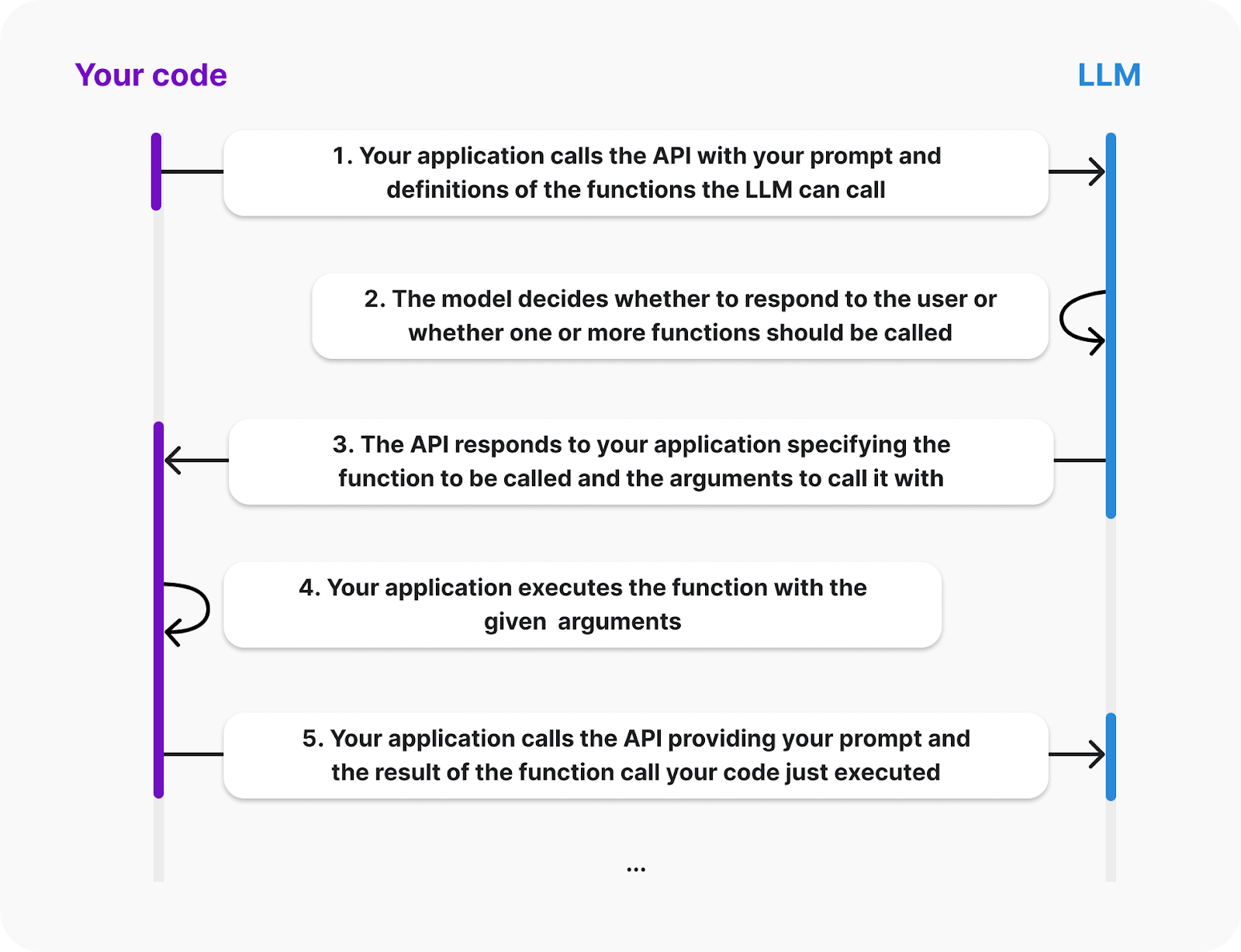
Quelle: OpenAI
Aus dem Diagramm geht hervor, dass der Client die Definitionen der Funktionen bereitstellen muss, die der LLM aufrufen kann. Auch die Ausführung der Funktion erfolgt auf der Client-Seite; die KI sendet ein Ereignis, das die aufzurufende Funktion und ihre Argumente anfordert. Dann sind wir dafür verantwortlich, das Ergebnis zurückzuschicken.
Wir wollen unseren Assistenten mit einer Funktion ausstatten, die zwei Zahlen zusammenzählt. Wir bauen dieses Beispiel auf, indem wir das Audiobeispiel oben erweitern.
Um die verfügbaren Funktionen festzulegen, müssen wir dem LLM eine Liste von Werkzeugen zur Verfügung stellen. Jedes Tool ist ein JSON-Objekt, das die Informationen über die Funktion angibt. So können wir ein Werkzeug für die Summenfunktion definieren:
const sumTool = {
type: "function",
name: "calculate_sum",
description: "Use this function when asked to add numbers together, for example when asked 'What's 4 + 6'?.",
parameters: {
type: "object",
properties: {
"a": { "type": "number" },
"b": { "type": "number" }
},
required: ["a", "b"]
}
}Lass uns die Objektstruktur erklären:
type gibt an, dass wir eine Funktion definieren.name wird verwendet, um die Funktion zu identifizieren. Damit teilt uns der LLM mit, welche Funktion er aufrufen will.description wird verwendet, um zu bestimmen, wann der LLM diese Funktion verwenden soll.parameters werden verwendet, um die Argumente der Funktion anzugeben. In diesem Fall sind es zwei Zahlen namens a und b.Der nächste Schritt besteht darin, die Funktion in unserem Code zu definieren. Wir werden ein Wörterbuch mit dem Schlüssel calculate_sum verwenden, um es einfacher zu machen, die entsprechende Funktion aufzurufen, wenn wir auf ein Funktionsaufrufereignis reagieren:
const functions = {
calculate_sum: (args) => args.a + args.b,
}Die API stellt die Funktionsargumente als Wörterbuch mit der gleichen Struktur zur Verfügung, die auf parameters oben definiert ist. In diesem Fall, um z.B. 3 und 5 hinzuzufügen, würde das Wörterbuch {“a”: 3, “b”: 5} lauten.
Die Konstanten sumTool und functions können am Anfang von index.js eingefügt werden, nach den Importen und vor der Funktion main().
Als Nächstes aktualisieren wir das Ereignis response.create, um dem LLM mitzuteilen, dass die sumTools verfügbar ist. Dazu werden die Felder tools und tool_choice zu response hinzugefügt:
const createResponseEvent = {
type: "response.create",
response: {
modalities: ["text", "audio"],
instructions: "Please assist the user.",
tools: [sumTool], // New
tool_choice: "auto", // New
},
};Wenn der LLM beschließt, eine Funktion aufzurufen, sendet er ein response.function_call_arguments.done Ereignis aus. Wir müssen darauf reagieren, indem wir:
Wir handhaben dies, indem wir die switch Anweisung innerhalb der hanldeMessage() Funktion um den folgenden Fall erweitern:
case "response.function_call_arguments.done":
console.log(Using function ${message.name} with arguments ${message.arguments});
// 1. Get the function information and call the function
const function_name = message.name;
const function_arguments = JSON.parse(message.arguments);
const result = functions[function_name](function_arguments);
// 2. Send the result of the function call
const functionOutputEvent = {
type: "conversation.item.create",
item: {
type: "function_call_output",
role: "system",
output: ${result},
}
};
ws.send(JSON.stringify(functionOutputEvent));
// 3. Request a response
ws.send(JSON.stringify({type: "response.create"}));
break;Wenn wir nun das Skript ausführen und das Ergebnis der Addition zweier Zahlen abfragen, sollte das Modell die Funktion aufrufen und das Ergebnis liefern.
Diese Funktion ist relativ einfach, aber da die Funktion vom Client ausgeführt wird, kann sie alles Mögliche sein. Im nächsten Abschnitt werden wir uns zwei Beispiele für komplexere Funktionen ansehen.
Der vollständige Code dieses Beispiels ist verfügbar hier.
Das OpenAI-Team stellt eine React-Demo-App zur Verfügung, um die Realtime-API zu präsentieren. Hier erfährst du, wie du es einrichten kannst und wie es funktioniert. Das ist ein guter Ausgangspunkt, um eine komplexere App zu bauen.
React-Kenntnisse sind nicht erforderlich, um es zum Laufen zu bringen. Allerdings musst du dich mit React auskennen, um es zu ändern oder zu erweitern.
Ihre App wird in diesem Repository gehostet diesem Repository. Um es einzurichten, musst du zunächst klonen unter Verwendung der folgenden Git Befehl:
git clone org-14957082@github.com:openai/openai-realtime-console.gitAlternativ können wir sie auch manuell über die GitHub-Schnittstelle herunterladen.
Um die App zu installieren, verwenden wir den folgenden NPM-Befehl (Node Package Manage):
npm installWenn die Installation abgeschlossen ist, erstelle eine Datei namens .env im Stammordner des Projekts und füge den folgenden Inhalt ein:
OPENAI_API_KEY=<openai_api_key>
REACT_APP_LOCAL_RELAY_SERVER_URL=http://localhost:8081Ersetze durch den OpenAI API-Schlüssel.
Die Anwendung sollte jetzt bereit sein, ausgeführt zu werden. Sie besteht aus zwei Teilen:
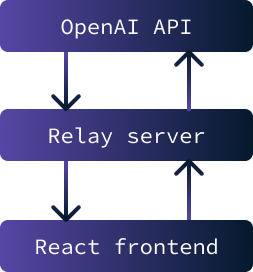
Der Hauptzweck der Implementierung eines Relay-Servers zwischen dem Frontend und der OpenAI API besteht darin, den API-Schlüssel sicher zu speichern. Ohne diesen Schlüssel ist es nicht möglich, mit der API zu interagieren.
Wenn der Schlüssel jedoch auf dem Frontend gespeichert würde, wäre er für jeden Nutzer zugänglich. Die Lösung besteht daher darin, einen Server einzurichten, der den Schlüssel sicher speichert und den Datenaustausch zwischen der API und dem Frontend ermöglicht. In diesem speziellen Szenario sind die Sicherheitsbedenken minimal, da die Anwendung nur lokal ausgeführt wird.
Um die Anwendung zu starten, müssen sowohl der Relay Server als auch das Frontend gestartet werden. Um den Relay-Server zu starten, verwende den folgenden Befehl:
npm run relayUm das React-Frontend zu starten, verwende den Befehl:
npm startNachdem die Anwendung geladen wurde, wird ein Tab im Browser geöffnet, in dem die Anwendung läuft.
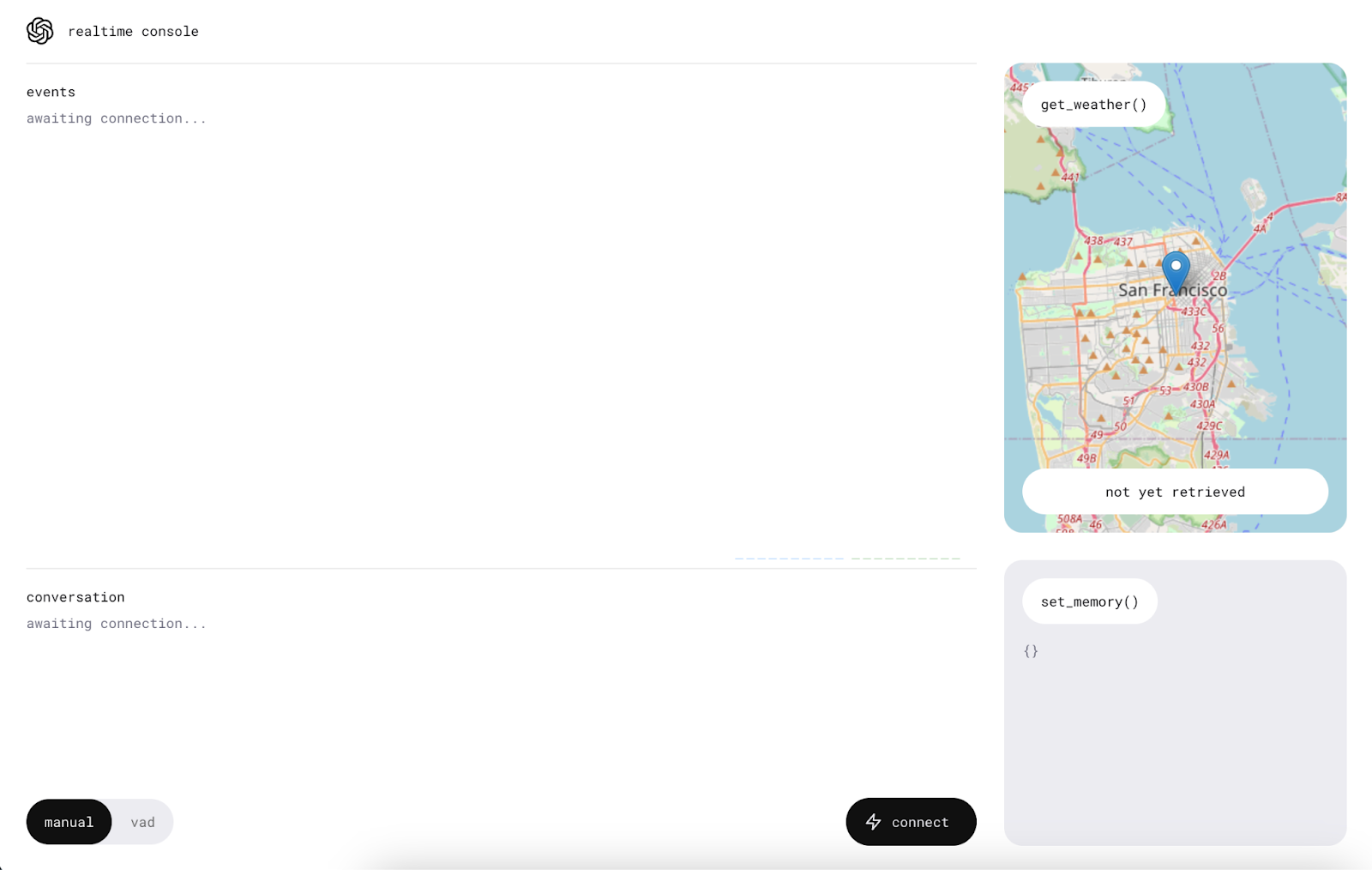
Vergewissere dich vor der Nutzung der App, dass der Computer nicht stumm geschaltet ist und erlaube den Mikrofonzugriff auf die Anwendung.
Wir beginnen mit einem Klick auf die Schaltfläche "Verbinden". Dadurch wird eine "Hallo"-Nachricht an die Realtime API gesendet und wir erhalten eine Begrüßung.

Sobald die Verbindung hergestellt ist, erscheint in der Mitte eine neue Schaltfläche, über die wir mit dem KI-Assistenten sprechen können.

Um sie zu benutzen, drückst du und sprichst, ohne die Taste loszulassen. Die Nachricht wird gesendet, wenn die Taste losgelassen wird.
Die Anwendung verfügt auch über einen VAD-Modus (Voice Activity Detection), in dem wir keine Taste drücken müssen. In diesem Modus hört die Anwendung ununterbrochen zu und ermöglicht es uns, ein aktives Gespräch mit dem Assistenten zu führen. Um sie zu benutzen, drückst du einfach die Taste "vad" und sprichst.

Wie wir erfahren haben, bietet die Realtime API eine Funktion, die es der KI ermöglicht, bestimmte Funktionen auszuführen. In dieser Demonstration werden zwei Funktionen gezeigt: eine für die Abfrage der Wettervorhersage an einem bestimmten Ort und eine weitere für das Hinzufügen von Speicherelementen, um den Assistenten zu personalisieren.
Erfahre diese Funktionen, indem du Fragen stellst wie "Wie ist das Wetter morgen in New York?" und Vorlieben angibst wie "Meine Lieblingsfarbe ist blau". Der Assistent gibt mündliche Antworten auf diese Fragen und die Informationen werden auch auf der rechten Seite der Anwendung angezeigt.
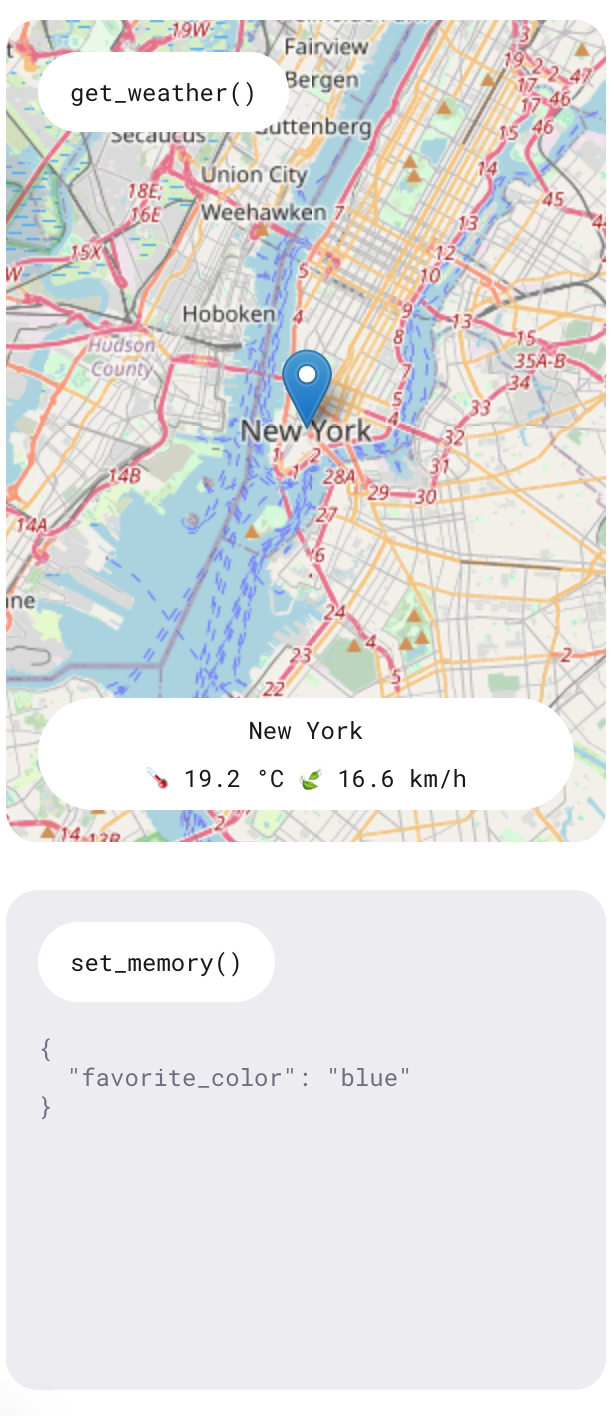
Es gab Zeiten, in denen ich einen Wetterbericht angefordert habe und die Antwort anzeigte, dass er zu diesem Zeitpunkt nicht verfügbar war. Die Informationen wurden jedoch immer auf der rechten Seite angezeigt. Da es sich um eine Demo-App handelt, ist sie nicht als voll funktionsfähiges Produkt gedacht, sondern dient eher dazu, die Möglichkeiten der API zu zeigen.
Dieser Abschnitt setzt ein grundlegendes Verständnis von React voraus, da wir einige Implementierungsdetails der Anwendung behandeln.
Wir werden uns die die Datei ConsolePage.tsx . Hier wird der größte Teil der Anwendungslogik definiert. Die Demo-App verwendet nicht die rohen WebSockets, wie wir es in unseren Node.js-Kommandozeilen-Beispielen getan haben. Sie haben einen Echtzeit-Client entwickelt, der ihnen hilft, mit der API zu interagieren. Das ist das, was oben in der Datei importiert wird:
import { RealtimeClient } from '@openai/realtime-api-beta';Die Integration mit der API ist definiert in diesem useEffect() Aufruf. Der Code in diesem useEffect() wird ausgeführt, wenn die Konsolenseite erstmals gerendert wird. Ähnlich wie unser Node.js-Skript beschreibt es, wie man auf API-Ereignisse reagiert. Der wichtigste Unterschied ist die Verwendung des RealtimeClient Client Wrappers.
Die Funktion RealtimeClient.addTool() wird verwendet, um Werkzeuge zu definieren. Sie benötigt zwei Parameter:
Dieser Ansatz vereinfacht die Integration von Tools, da der Client bereits so ausgestattet ist, dass er Ereignisse verarbeiten und Funktionsaufrufe automatisieren kann. Das Speicherwerkzeug ist definiert hierdefiniert, während die Definition des Wetter-Tools hier.
Um zum Beispiel das zuvor definierte Summenwerkzeug hinzuzufügen, können wir Folgendes tun:
client.addTool(
{
name: "calculate_sum",
description: "Use this function when asked to add numbers together, for example when asked 'What's 4 + 6'?.",
parameters: {
type: "object",
properties: {
"a": { "type": "number" },
"b": { "type": "number" }
},
required: ["a", "b"]
}
},
(a: number, b: number): number => a + b
);Beachte, dass die Anwendung TypeScript verwendet und daher die Angabe von Typen in der Funktionsdefinition erforderlich ist.
Um ein Ereignis zu hören, wird die Funktion RealtimeClient.on() verwendet. Sie nimmt zwei Parameter entgegen:
Dieser Ansatz ähnelt der zuvor verwendeten Funktion WebSocket.on(), nur dass sie eine andere Reihe von Ereignissen implementiert. Ihre GitHub-Seite findest du die Liste der unterstützten Ereignisse.
In diesem speziellen Beispiel werden die folgenden Ereignisse verwendet:
realtime.event hier wird verwendet, um ein Protokoll aller Ereignisse zu führen.error hier protokolliert die Fehler zu Debugging-Zwecken einfach auf der Konsole.conversation.interrupted hier wird verwendet, um die Anfragen abzubrechen, wenn die Umwandlung unterbrochen wird.conversation.updated hier wird verwendet, um neue Audiodaten an den Audiostrom anzuhängen, wenn neue Chucks von der API eintreffen.In diesem Tutorial haben wir uns die OpenAI Realtime API angesehen und wie sie WebSockets für die Echtzeitkommunikation nutzt. Wir haben die Einrichtung einer Node.js-Umgebung für die Interaktion mit der API, das Senden und Empfangen von Text- und Audiomeldungen und die Implementierung von Funktionsaufrufen für erweiterte Funktionen behandelt.
Wir haben uns auch die OpenAI Demo React App angesehen, die zeigt, wie man eine einfache Sprachassistenten-Anwendung einsetzt.
Um mehr über die neuesten OpenAI-Entwicklungstools zu erfahren, empfehle ich diese Tutorials:
Lerne, KI-Apps zu entwickeln!
Lernpfad
Kurs
Kurs