
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Ich habe versucht OpenAIdas neue Modell-Destillations-Tool-Es erfordert nur einen minimalen Programmieraufwand und ermöglicht es uns, den gesamten Destillationsprozess auf einer einzigen Plattform zu verwalten, von der Erstellung von Datensätzen bis zur Feinabstimmung der Modelle und Bewertung ihrer Leistung.
In diesem Tutorial helfe ich dir, mit OpenAIs Modell-Destillationstool loszulegen. Zuerst werden wir die Grundlagen der Modell-Destillation behandeln und dann ein Demo-Destillationsprojekt mit der OpenAIs API.
Stell dir vor, eine gut ausgebildete Lehrerin oder ein gut ausgebildeter Lehrer bringt den Schülerinnen und Schülern ihre Denkprozesse und ihr Wissen bei. Das sind die Grundlagen, wie die Modelldestillation funktioniert.
Bei dieser Technik ist der Lehrer ein großes, vortrainiertes Modell und der Schüler ein kleineres Modell, das lernt, die Ergebnisse des Lehrers zu kopieren. So kann der Schüler/die Schülerin bestimmte Aufgaben auf einem vergleichbaren Niveau wie der Lehrer/die Lehrerin ausführen, nur mit weniger Ressourcen.
Die Modelldestillation gibt es in vielen Formen, jede mit ihren eigenen Methoden und Zielen. In einem Fall muss der Schüler nur die Ergebnisse eines größeren Modells nachahmen. In einem anderen Fall wollen wir den Problemlösungsansatz der Lehrkraft in das kleinere Modell einfließen lassen. Letztlich geht es darum, mit einem effizienten Modell von den Möglichkeiten eines großen Modells zu profitieren.
Eine gängige Methode, um Wissen von einem "Lehrermodell" auf ein "Schülermodell" zu übertragen, ist die Feinabstimmung des Schülermodells anhand eines Datensatzes, der aus Eingaben und den entsprechenden Ausgaben des Lehrermodells besteht.
Während dieses überwachten Lernens lernt das Schülermodell, die Antworten des Lehrers zu wiederholen, wenn es ähnliche Eingaben erhält.
Das Destillationsverfahren bringt viele Vorteile mit sich:
Um mehr über die Destillation zu erfahren, kannst du diesen Artikel lesen: LLM-Destillation erklärt.
In diesem Abschnitt werden wir ein Beispiel für die Modelldestillation auf der OpenAI-Plattform untersuchen. Unser Hauptaugenmerk liegt auf , um Git-Befehle für die Anfrage eines Nutzers zu generieren.
Wir werden zunächst einen Datensatz der kleinen OpenAIs erstellen GPT-4o mini (Schüler) und werten die Ergebnisse aus.
Als nächstes verwenden wir GPT-4o (Lehrer), um dieselben Sätze zu übersetzen und das Schülermodell anhand des vom Lehrer produzierten Datensatzes zu verfeinern.
Schließlich müssen wir das Schülermodell auswerten und die Verbesserung beurteilen.
Zusammengefasst sind das die Schritte, die wir unternehmen werden:
Der erste Schritt der Modelldestillation ist die Auswahl des Lehrers und des Schülers, die durch die beabsichtigte Aufgabe und dein Rechenbudget bestimmt wird.
Wenn du mit Open-Source-Modellen arbeitest, gibt es eine Vielzahl von LLMs mit unterschiedlichen Fähigkeiten und Größen. Mit der Plattform von OpenAI sind die Möglichkeiten begrenzt.

Für unser Beispiel wählen wir GPT-4o mini als das kleinere Schülermodell und GPT-4o als Lehrermodell.
Das GPT-4o-mini ist ein relativ kleines Modell und ein guter Kandidat für die Schülerrolle. Das GPT-4o ist relativ groß, aber viel leistungsfähiger und kann als effizienter Lehrer für den Schüler arbeiten.
Es gibt andere Möglichkeiten, und die Änderung der Modelle würde nur einen minimalen Aufwand in unserem Projekt zur Modelldestillation erfordern.
Dein Datensatz für diese Aufgabe muss anspruchsvoll genug für das Schülermodell sein, aber nicht so anspruchsvoll für die Lehrkraft. Die Qualitäten eines guten Datensatzes, wie Vielfalt, Repräsentativität oder Genauigkeit, sind bei der Modelldestillation immer noch wichtig.
Es ist sehr wichtig, einen ausreichend großen Datensatz zu haben, um das Schülermodell zu beeinflussen. Es gibt keine eindeutige Antwort auf "Wie groß sollte der Destillationsdatensatz sein?", denn das hängt von der Komplexität deiner Zielaufgabe und den Modellen ab, die du als Lehrer/in und Schüler/in ausgewählt hast.
Wie in der OpenAIs Dokumentationkönnen zwar ein paar hundert Proben ausreichen, aber eine vielfältigere Gruppe von Tausenden von Proben kann manchmal zu besseren Ergebnissen führen.
Unser Datensatz in diesem Artikel besteht aus 386 Nutzeranfragen, die in einem JSON Datei gespeichert sind (du könntest sie genauso gut in Form einer Python-Liste speichern).
{
"requests": [
"Initialize a new Git repository in the current directory.",
"Clone the repository from GitHub to my local machine.",
"Create a new branch called 'feature-login'.",
...
"Show the differences between the working directory and the staging area.",
"Stage all modified and deleted files for commit.",
]
}Unser Datensatz besteht derzeit nur aus Eingaben, und wir sollten auch Ausgaben generieren. Die Ergebnisse des Schülers sind für die Destillation nicht notwendig, aber wir brauchen sie, um eine Basislinie für die Genauigkeit des Schülermodells zu erhalten (Schritt 4).
Mit dem folgenden Code iterieren wir über den Eingabedatensatz und erzeugen für jeden eine Ausgabe:
def generate_responses():
with open(JSON_PATH, 'r') as file:
user_messages = json.load(file)
for sentence in user_messages['requests']:
# Call the OpenAI model gpt-4o-mini and store the response
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": sentence
},
],
store=True,
metadata={
"task": "git"
}
)
generate_responses()Beachte, dass wir beim Aufruf des OpenAI-Modells store=True verwenden. Dieses Argument speichert die Input/Output-Paare in unserem OpenAI-Dashboard, sodass wir die Outputs nicht mit Code speichern müssen.
Um diese Chatvervollständigungen später zu identifizieren und herauszufiltern, vergiss nicht, beim Aufruf der Funktion client.chat.completions.create Metadaten anzugeben. Die Argumente für diese Metadaten sind frei wählbar.
Die erzeugten Ausgaben finden Sie auf der Seite Chat-Abschlüsse Abschnitt unseres OpenAI Dashboards.
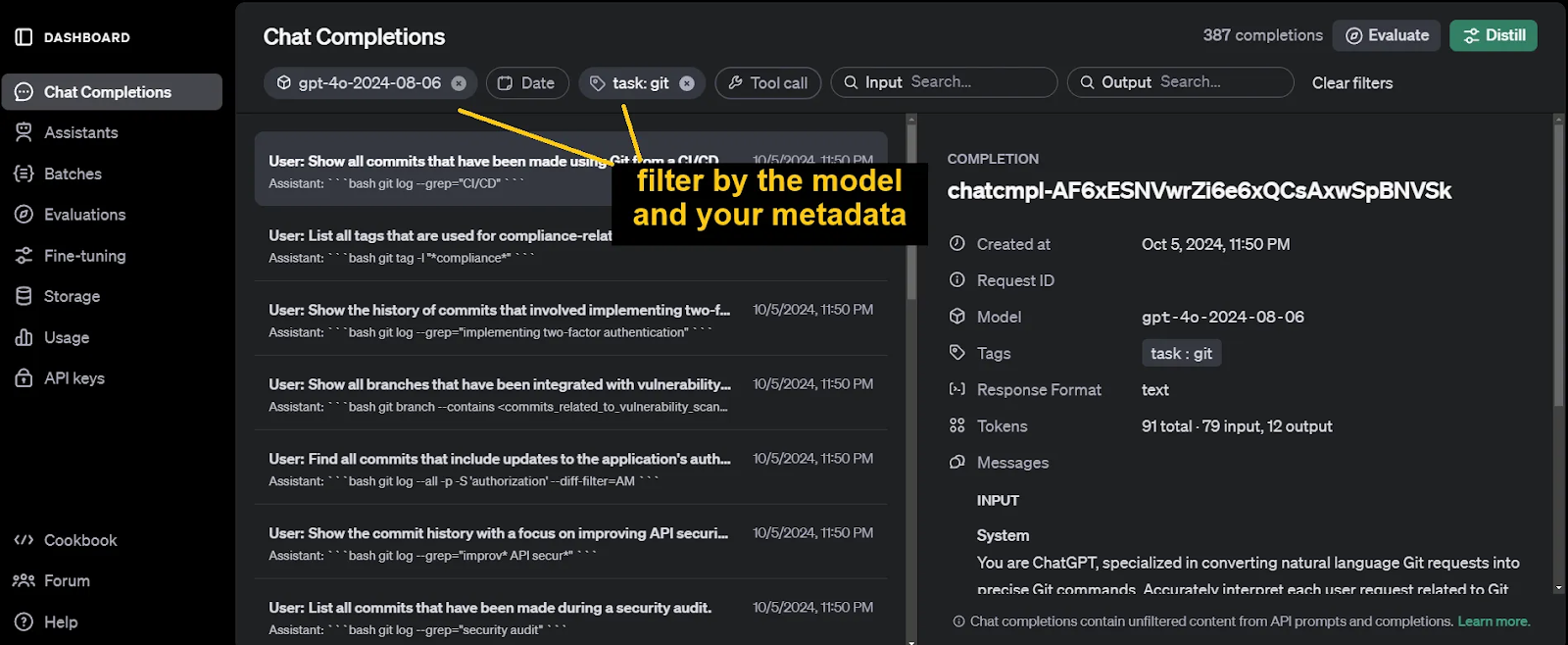
Ein weiteres Tool von OpenAI, das für die Modelldestillation nützlich ist, sind die Auswertungen Werkzeug. Wir verwenden dieses Tool, um die Leistung des Schülermodells vor dem Training zu bewerten. Wir werden sie später auch bei der Bewertung des fein abgestimmten Schülermodells verwenden.
Nachdem du die Chatverläufe des vorherigen Schritts herausgefiltert hast, klicke auf die SchaltflächeAuswerten. Wir müssen nun Prüfkriterien hinzufügen.
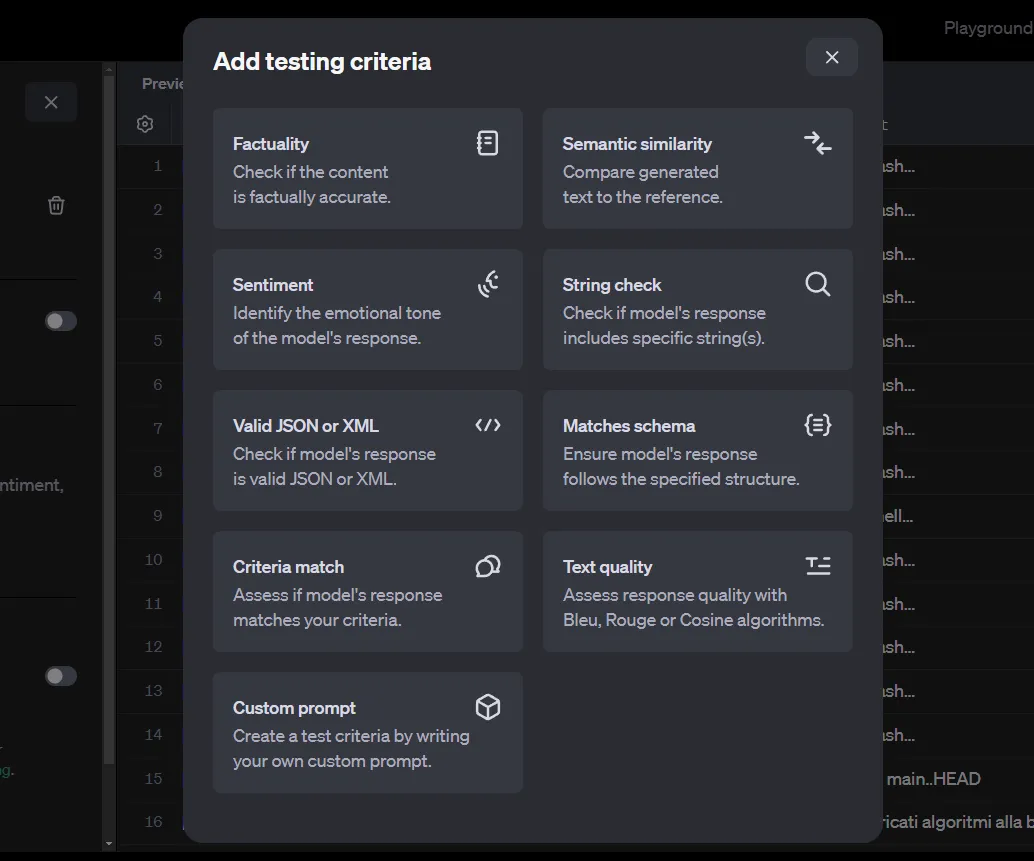
Es gibt eine Vielzahl von Methoden, um die Ein-/Ausgangspaare zu bewerten. Beachte, dass unser aktueller Datensatz automatisch von den Chatverläufen von OpenAI generiert wird und nur die Ein- und Ausgänge enthält. Einige dieser Kriterien erfordern jedoch auch eine Referenz, mit der sie verglichen werden können.
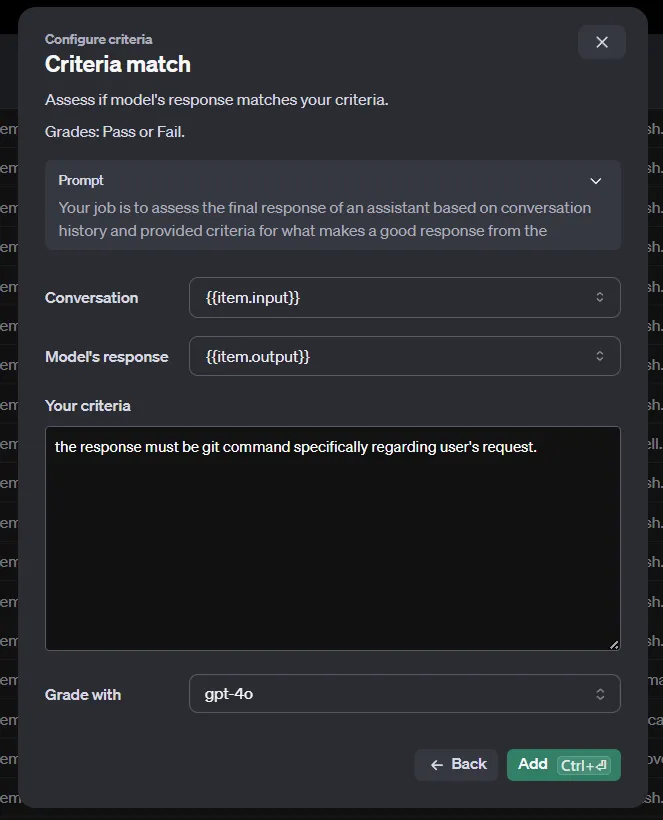
Diese Referenz könnten die Ergebnisse eines anspruchsvolleren Modells sein, wie z.B. GPT-4o oder o1-Vorschau. Da wir die Chats nicht automatisch in OpenAI speichern können, müssen wir die Methoden Criteriamatch oder Custom prompt verwenden, die nur eine Eingabe und eine Ausgabe benötigen.
Wenn du andere Methoden verwenden musst, kannst du die Chatvervollständigungen von OpenAI nicht nutzen und musst deine JSON Datei mit Code erstellen . Das ist nicht kompliziert, aber wir werden in diesem Artikel nicht näher darauf eingehen.
Sobald du die Auswertungen durchgeführt hast, erhältst du in Kürze deine Ergebnisse.
Für die Feinabstimmung des Schülermodells benötigen wir einen hochwertigen Datensatz, der von der Lehrkraft erstellt wurde. Dieser Schritt ist fast identisch mit Schritt 3 - du musst nur das Argument model von gpt-4o-mini in gpt-4o ändern.
Auch hier filterst du bei den Chat-Abschlüssen nach dem Lehrermodell und den Metadaten. Als Nächstes wählst du die Schaltfläche Destillieren. OpenAIs Distill ist im Wesentlichen das Werkzeug für die Feinabstimmung.
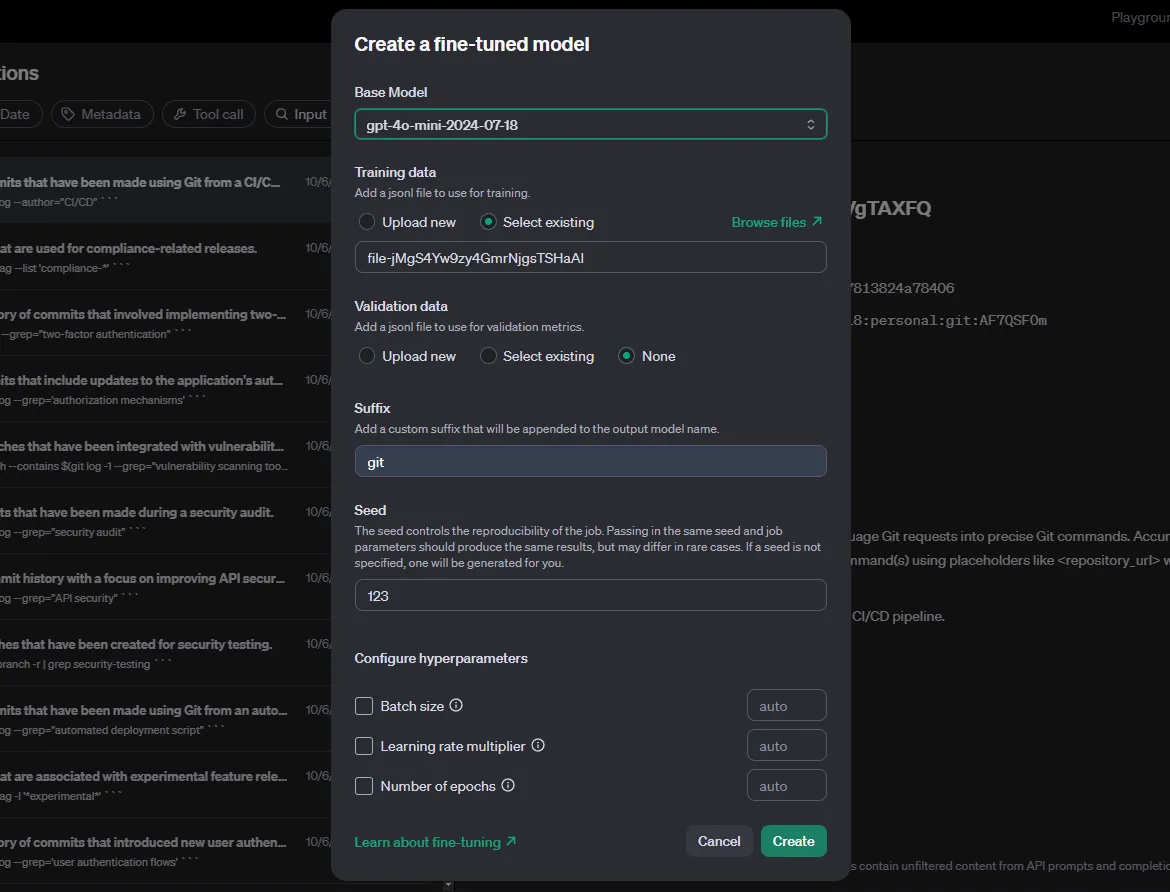
Für das Basismodell wählen wir den Schüler. Mit den Hyperparametern muss experimentiert und getestet werden, um die besten Ergebnisse zu erzielen - setze sie auf auto. Wähle schließlich Erstellen und warte, bis die Feinabstimmung abgeschlossen ist.
Sobald wir fertig sind, verwenden wir den Code aus Schritt 3 erneut, dieses Mal mit dem fein abgestimmten Modell als model Argument. Der Name des Feinabstimmungsmodells wird als "Ausgabemodell" auf deiner Feinabstimmungsseite angezeigt.
def generate_responses():
with open(JSON_PATH, 'r') as file:
user_messages = json.load(file)
for sentence in user_messages['requests']:
# Call the OpenAI model gpt-4o-mini and store the response
response = client.chat.completions.create(
model="ft:gpt-4o-mini-2024-07-18:personal:git:AF7QSF0m",
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": sentence
},
],
store=True,
metadata={
"task": "git"
}
)
generate_responses()Nachdem du mit der Erstellung der Outputs fertig bist, nutze die Auswertungen, um die Leistungsfähigkeit deines neuen Modells anhand der Inputs zu beurteilen.
OpenAIs Rezept für die Destillation ist einfach, aber geradlinig. Das ist besonders hilfreich, weil du dich nicht selbst um die Feinabstimmung der Modelle kümmern oder die Ergebnisse mit Code auswerten musst.
Die Modelle von OpenAI, selbst die kleineren, sind schon ziemlich ausgefeilt. Experimentiere mit den Hyperparametern, bevor du die Feinabstimmung des Modells vornimmst, bereite angemessene und herausfordernde Aufforderungen für Lehrer und Schüler vor und vergleiche die feinabgestimmte Auswertung mit der Basisauswertung.
Bevor du dich mit deiner eigenen Modelldestillation beschäftigst, empfehle ich dir, diese beiden OpenAI-Ressourcen zu lesen: OpenAI Model Distillation in der API und Model Distillation Dokument.
Lerne, KI-Anwendungen zu entwickeln!
Lernpfad
Lernpfad
Kurs