Kurs
Fortgeschrittene Datenvisualisierung mit Seaborn
4 Std.
75K
Die Visualisierung ist ein entscheidender Aspekt der Datenanalyse und -interpretation, da sie ein einfaches Verständnis komplexer Datensätze ermöglicht. Sie hilft dabei, Muster, Beziehungen und Trends zu erkennen, die aus den Rohdaten allein vielleicht nicht ersichtlich sind. In den letzten Jahren hat sich Python dank seiner zahlreichen Bibliotheken und Frameworks zu einer der beliebtesten Programmiersprachen für die Datenanalyse entwickelt.
Visualisierungsbibliotheken in Python ermöglichen es den Nutzern, intuitive und interaktive Datenvisualisierungen zu erstellen, die einem breiten Publikum Erkenntnisse vermitteln können. Einige der beliebtesten Visualisierungsbibliotheken und Frameworks in Python sind Matplotlib, Plotly, Bokeh und Seaborn. Jede dieser Bibliotheken hat ihre eigenen einzigartigen Funktionen und Möglichkeiten, die auf bestimmte Bedürfnisse zugeschnitten sind.
In diesem Tutorial konzentrieren wir uns auf Seaborn, eine beliebte Datenvisualisierungsbibliothek in Python, die eine einfach zu bedienende Oberfläche für die Erstellung informativer statistischer Grafiken bietet.
Seaborn baut auf Matplotlib auf und ist eine bekannte Python-Bibliothek für die Datenvisualisierung, die eine benutzerfreundliche Oberfläche für die Erstellung von visuell ansprechenden und informativen statistischen Grafiken bietet. Es wurde für die Arbeit mit Pandas DataFrames entwickelt und macht es einfach, Daten schnell und effektiv zu visualisieren und zu untersuchen.
Seaborn bietet eine Vielzahl von leistungsstarken Werkzeugen zur Visualisierung von Daten, darunter Streudiagramme, Liniendiagramme, Balkendiagramme, Heatmaps und viele mehr. Es bietet auch Unterstützung für fortgeschrittene statistische Analysen wie Regressionsanalysen, Verteilungsdiagramme und kategoriale Diagramme.
In unserem Kurs Einführung in die Datenvisualisierung mit Se aborn erfährst du alles über Seborn und seine Einsatzmöglichkeiten.
Der Hauptvorteil von Seaborn liegt in der Fähigkeit, mit minimalem Programmieraufwand attraktive Diagramme zu erstellen. Es bietet eine Reihe von Standardthemen und Farbpaletten, die du leicht an deine Vorlieben anpassen kannst. Darüber hinaus bietet Seaborn eine Reihe eingebauter statistischer Funktionen, die es den Nutzern ermöglichen, auf einfache Weise komplexe statistische Analysen mit ihren Visualisierungen durchzuführen.
Ein weiteres bemerkenswertes Merkmal von Seaborn ist die Fähigkeit, komplexe Multiplot-Visualisierungen zu erstellen. Mit Seaborn können Nutzer/innen Raster von Diagrammen erstellen, die einen einfachen Vergleich zwischen mehreren Variablen oder Teilmengen von Daten ermöglichen. Das macht sie zu einem idealen Werkzeug für die explorative Datenanalyse und -präsentation.
Seaborn ist eine leistungsstarke und flexible Datenvisualisierungsbibliothek in Python, die eine einfach zu bedienende Schnittstelle zur Erstellung informativer und ästhetisch ansprechender statistischer Grafiken bietet. Es bietet eine Reihe von Werkzeugen zur Visualisierung von Daten, einschließlich fortgeschrittener statistischer Analysen, und macht es einfach, komplexe Multi-Plot-Visualisierungen zu erstellen.
Die beiden am weitesten verbreiteten Bibliotheken zur Datenvisualisierung in Python sind Matplotlib und Seaborn. Obwohl beide Bibliotheken darauf ausgelegt sind, hochwertige Grafiken und Visualisierungen zu erstellen, gibt es einige wichtige Unterschiede, die sie für unterschiedliche Anwendungsfälle besser geeignet machen.
Einer der Hauptunterschiede zwischen Matplotlib und Seaborn ist ihr Fokus. Matplotlib ist eine Low-Level Plot-Bibliothek, die eine breite Palette von Werkzeugen für die Erstellung hochgradig anpassbarer Visualisierungen bietet. Es handelt sich um eine äußerst flexible Bibliothek, mit der du fast jede Art von Plot erstellen kannst, die du dir vorstellen kannst. Diese Flexibilität geht mit einer steileren Lernkurve und ausführlicherem Code einher.
Seaborn hingegen ist eine High-Level-Schnittstelle zur Erstellung statistischer Grafiken. Es baut auf Matplotlib auf und bietet eine einfachere, intuitivere Schnittstelle zur Erstellung gängiger statistischer Diagramme. Seaborn ist so konzipiert, dass es mit Pandas DataFrames zusammenarbeitet, sodass du mit minimalem Code ganz einfach Visualisierungen erstellen kannst. Außerdem bietet es eine Reihe eingebauter statistischer Funktionen, mit denen die Nutzer/innen problemlos komplexe statistische Analysen mit ihren Visualisierungen durchführen können.
Ein weiterer wichtiger Unterschied zwischen Matplotlib und Seaborn sind die Standardstile und Farbpaletten. Matplotlib bietet nur eine begrenzte Anzahl von Standardstilen und Farbpaletten, sodass die Nutzer ihre Plots manuell anpassen müssen, um das gewünschte Aussehen zu erreichen. Seaborn hingegen bietet eine Reihe von Standardstilen und Farbpaletten, die für verschiedene Arten von Daten und Visualisierungen optimiert sind. Das macht es den Nutzern leicht, mit minimalen Anpassungen visuell ansprechende Plots zu erstellen.
Beide Bibliotheken haben ihre Stärken und Schwächen. Seaborn eignet sich im Allgemeinen besser für die Erstellung statistischer Grafiken und die explorative Datenanalyse, während Matplotlib besser geeignet ist, um hochgradig anpassbare Diagramme für Präsentationen und Veröffentlichungen zu erstellen. Es ist jedoch erwähnenswert, dass Seaborn auf Matplotlib aufbaut und die beiden Bibliotheken zusammen verwendet werden können, um komplexe, stark anpassbare Visualisierungen zu erstellen, die die Stärken beider Bibliotheken nutzen.
Du kannst Matplotlib in unserem Tutorial Einführung in das Plotten mit Matplotlib in Python genauer kennenlernen.
Matplotlib und Seaborn sind beides leistungsstarke Datenvisualisierungsbibliotheken in Python, mit unterschiedlichen Stärken und Schwächen. Die Unterschiede zwischen den beiden Bibliotheken zu verstehen, kann den Nutzern helfen, das richtige Tool für ihre spezifischen Datenvisualisierungsbedürfnisse zu wählen.
Seaborn wird von Python 3.7+ unterstützt und hat nur minimale Abhängigkeiten vom Kern. Die Installation von Seaborn ist ziemlich einfach. Du kannst es entweder mit dem Python-Paketmanager pip oder mit dem Paketmanager conda installieren.
# install seaborn with pip
pip install seaborn
Wenn du pip verwendest, werden Seaborn und seine benötigten Abhängigkeiten installiert. Wenn du auf zusätzliche und optionale Funktionen zugreifen möchtest, kannst du auch optionale Abhängigkeiten in pip install einbinden. Zum Beispiel:
pip install seaborn[stats]
Oder mit conda:
# install seaborn with conda
conda install seaborn
Seaborn bietet mehrere integrierte Datensätze, die wir für die Datenvisualisierung und statistische Analyse verwenden können. Diese Datensätze werden in Pandas DataFrames gespeichert, sodass sie leicht mit den Plot-Funktionen von Seaborn verwendet werden können.
Einer der gebräuchlichsten Datensätze, der auch in allen offiziellen Beispielen von Seaborn verwendet wird, heißt "Trinkgeld-Datensatz"; er enthält Informationen über Trinkgelder, die in Restaurants gegeben werden. Hier ist ein Beispiel für das Laden und Visualisieren des Tips-Datensatzes in Seaborn:
import seaborn as sns
# Load the Tips dataset
tips = sns.load_dataset("tips")
# Create a histogram of the total bill amounts
sns.histplot(data=tips, x="total_bill")Ausgabe:
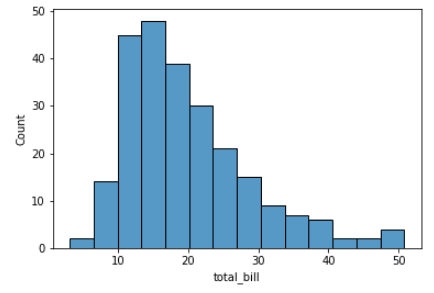
Wenn du diese Handlung noch nicht verstehst - keine Sorge. Dies nennt man ein Histogramm. Wir werden später in diesem Lernprogramm mehr über Histogramme erklären. Das Wichtigste ist, dass Seaborn viele Beispieldatensätze in Form von Pandas DataFrames enthält, mit denen du deine Visualisierungsfähigkeiten üben kannst. Hier ist ein weiteres Beispiel für das Laden des Datensatzes "Übung".
import seaborn as sns
# Load the exercise dataset
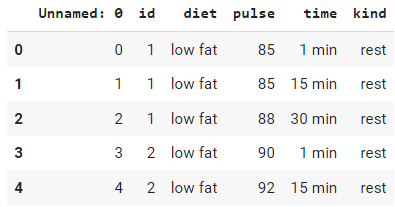
exercise = sns.load_dataset("exercise")
# check the head
exercise.head()Ausgabe:
Seaborn bietet eine breite Palette von Diagrammtypen, die für die Datenvisualisierung und explorative Datenanalyse verwendet werden können. Grob gesagt, kann jede Visualisierung in eine der drei Kategorien fallen.

Hier sind einige der am häufigsten verwendeten Grundstücksarten in Seaborn:
Im nächsten Abschnitt dieses Tutorials werden wir Beispiele und ausführliche Erklärungen zu jedem dieser Punkte sehen.
Streudiagramme werden verwendet, um die Beziehung zwischen zwei kontinuierlichen Variablen zu visualisieren. Jeder Punkt auf dem Diagramm stellt einen einzelnen Datenpunkt dar, und die Position des Punktes auf der x- und y-Achse repräsentiert die Werte der beiden Variablen.
Die Darstellung kann mit verschiedenen Farben und Markierungen angepasst werden, um verschiedene Gruppen von Datenpunkten zu unterscheiden. In Seaborn kannst du mit der Funktion scatterplot() Streudiagramme erstellen.
import seaborn as sns
tips = sns.load_dataset("tips")
sns.scatterplot(x="total_bill", y="tip", data=tips)Ausgabe:
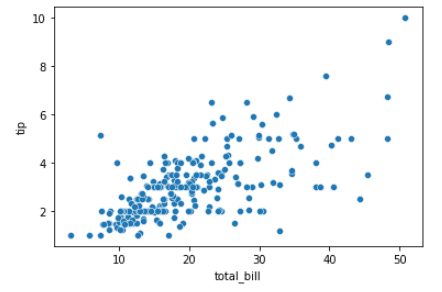
Diese einfache Darstellung kann verbessert werden, indem du die Parameter "Farbton" und "Größe" der Darstellung anpasst. Und so geht's:
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
# customize the scatter plot
sns.scatterplot(x="total_bill", y="tip", hue="sex", size="size", sizes=(50, 200), data=tips)
# add labels and title
plt.xlabel("Total Bill")
plt.ylabel("Tip")
plt.title("Relationship between Total Bill and Tip")
# display the plot
plt.show()Ausgabe:
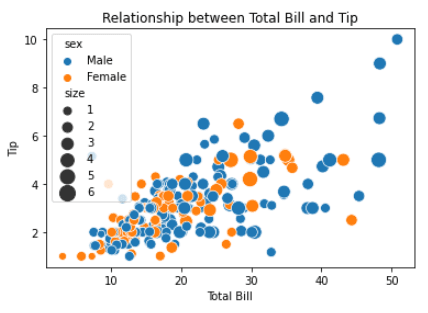
In diesem Beispiel haben wir die Bibliothek `seaborn` für ein einfaches Streudiagramm verwendet und `matplotlib` für weitere Anpassungen des Streudiagramms genutzt.
Liniendiagramme werden verwendet, um die Entwicklung von Daten im Zeitverlauf oder von anderen kontinuierlichen Variablen zu visualisieren. In einem Liniendiagramm wird jeder Datenpunkt durch eine Linie verbunden, wodurch eine glatte Kurve entsteht. In Seaborn können Liniendiagramme mit der Funktion lineplot() erstellt werden.
import seaborn as sns
fmri = sns.load_dataset("fmri")
sns.lineplot(x="timepoint", y="signal", data=fmri)Ausgabe:
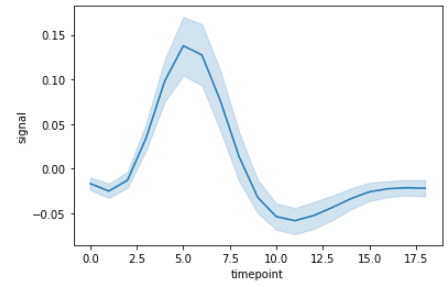
Wir können dies ganz einfach anpassen, indem wir die Spalten "Ereignis" und "Region" aus dem Datensatz verwenden.
import seaborn as sns
import matplotlib.pyplot as plt
fmri = sns.load_dataset("fmri")
# customize the line plot
sns.lineplot(x="timepoint", y="signal", hue="event", style="region", markers=True, dashes=False, data=fmri)
# add labels and title
plt.xlabel("Timepoint")
plt.ylabel("Signal Intensity")
plt.title("Changes in Signal Intensity over Time")
# display the plot
plt.show()Ausgabe:
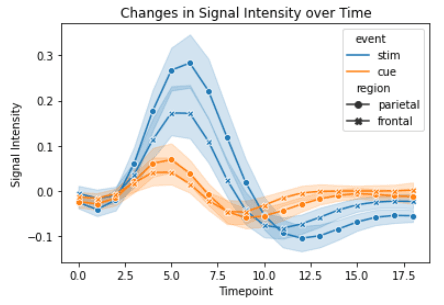
Auch hier haben wir die Bibliothek "Seaborn" verwendet, um ein einfaches Liniendiagramm zu erstellen, und die Bibliothek "Matplotlib" benutzt, um das einfache Liniendiagramm anzupassen und zu verbessern. Einen genaueren Blick auf die Seaborn-Liniendiagramme kannst du in unserem separaten Lernprogramm werfen.
Balkendiagramme werden verwendet, um die Beziehung zwischen einer kategorialen Variable und einer kontinuierlichen Variable zu visualisieren. In einem Balkendiagramm stellt jeder Balken den Mittelwert oder Median (oder eine andere Aggregation) der kontinuierlichen Variable für jede Kategorie dar. In Seaborn kannst du mit der Funktion barplot() Balkendiagramme erstellen.
import seaborn as sns
titanic = sns.load_dataset("titanic")
sns.barplot(x="class", y="fare", data=titanic)Ausgabe:
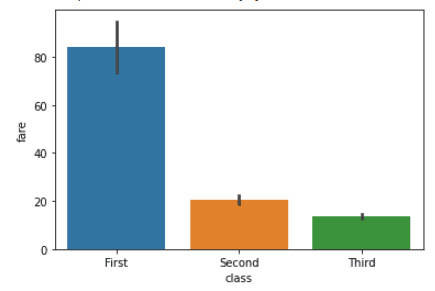
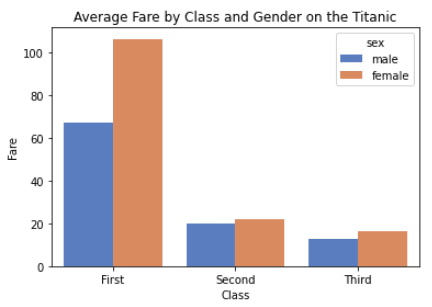
Lass uns dieses Diagramm anpassen, indem wir die Spalte "Geschlecht" aus dem Datensatz hinzufügen.
import seaborn as sns
import matplotlib.pyplot as plt
titanic = sns.load_dataset("titanic")
# customize the bar plot
sns.barplot(x="class", y="fare", hue="sex", ci=None, palette="muted", data=titanic)
# add labels and title
plt.xlabel("Class")
plt.ylabel("Fare")
plt.title("Average Fare by Class and Gender on the Titanic")
# display the plot
plt.show()Ausgabe:
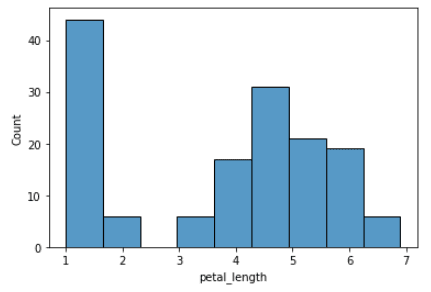
Histogramme visualisieren die Verteilung einer kontinuierlichen Variable. In einem Histogramm werden die Daten in Bins unterteilt und die Höhe jedes Bins stellt die Häufigkeit oder Anzahl der Datenpunkte innerhalb dieses Bins dar. In Seaborn können Histogramme mit der Funktion histplot() erstellt werden.
import seaborn as sns
iris = sns.load_dataset("iris")
sns.histplot(x="petal_length", data=iris)Ausgabe:
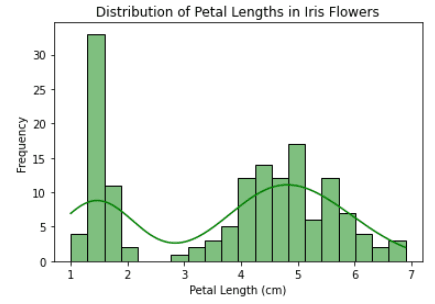
import seaborn as sns
import matplotlib.pyplot as plt
iris = sns.load_dataset("iris")
# customize the histogram
sns.histplot(data=iris, x="petal_length", bins=20, kde=True, color="green")
# add labels and title
plt.xlabel("Petal Length (cm)")
plt.ylabel("Frequency")
plt.title("Distribution of Petal Lengths in Iris Flowers")
# display the plot
plt.show()Ausgabe:
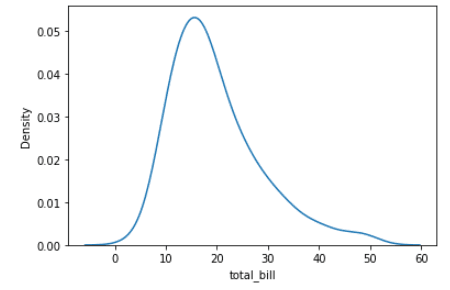
Dichte-Diagramme, auch bekannt als Kernel-Dichte-Diagramme, sind eine Art der Datenvisualisierung, die die Verteilung einer kontinuierlichen Variable darstellt. Sie ähneln den Histogrammen, aber anstatt die Daten als Balken darzustellen, verwenden Dichtegrafiken eine glatte Kurve, um die Dichte der Daten zu schätzen. In Seaborn kannst du mit der Funktion kdeplot() Dichteplots erstellen.
import seaborn as sns
tips = sns.load_dataset("tips")
sns.kdeplot(data=tips, x="total_bill")Ausgabe:
Lass uns die Handlung verbessern, indem wir sie anpassen.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset from Seaborn
tips = sns.load_dataset("tips")
# Create a density plot of the "total_bill" column from the "tips" dataset
# We use the "hue" parameter to differentiate between "lunch" and "dinner" meal times
# We use the "fill" parameter to fill the area under the curve
# We adjust the "alpha" and "linewidth" parameters to make the plot more visually appealing
sns.kdeplot(data=tips, x="total_bill", hue="time", fill=True, alpha=0.6, linewidth=1.5)
# Add a title and labels to the plot using Matplotlib
plt.title("Density Plot of Total Bill by Meal Time")
plt.xlabel("Total Bill ($)")
plt.ylabel("Density")
# Show the plot
plt.show()Ausgabe:
Boxplots sind eine Art der Visualisierung, die die Verteilung eines Datensatzes zeigt. Sie werden häufig verwendet, um die Verteilung einer oder mehrerer Variablen über verschiedene Kategorien hinweg zu vergleichen.
import seaborn as sns
tips = sns.load_dataset("tips")
sns.boxplot(x="day", y="total_bill", data=tips)Ausgabe:
Passe das Boxplot an, indem du die Spalte "Zeit" aus dem Datensatz einfügst.
import seaborn as sns
import matplotlib.pyplot as plt
# load the tips dataset from Seaborn
tips = sns.load_dataset("tips")
# create a box plot of total bill by day and meal time, using the "hue" parameter to differentiate between lunch and dinner
# customize the color scheme using the "palette" parameter
# adjust the linewidth and fliersize parameters to make the plot more visually appealing
sns.boxplot(x="day", y="total_bill", hue="time", data=tips, palette="Set3", linewidth=1.5, fliersize=4)
# add a title, xlabel, and ylabel to the plot using Matplotlib functions
plt.title("Box Plot of Total Bill by Day and Meal Time")
plt.xlabel("Day of the Week")
plt.ylabel("Total Bill ($)")
# display the plot
plt.show()
Ein Violinplot ist eine Art der Datenvisualisierung, die Aspekte von Boxplots und Dichteplots kombiniert. Er zeigt eine Dichteschätzung der Daten an, die in der Regel durch einen Kernel-Dichte-Schätzer geglättet wird, zusammen mit dem Interquartilsbereich (IQR) und dem Median in einer Box-Plot-ähnlichen Form.
Die Breite der Geige steht für die geschätzte Dichte, wobei breitere Teile eine höhere Dichte anzeigen. Der IQR und der Median werden als weißer Punkt und Linie innerhalb der Geige angezeigt.
import seaborn as sns
# load the iris dataset from Seaborn
iris = sns.load_dataset("iris")
# create a violin plot of petal length by species
sns.violinplot(x="species", y="petal_length", data=iris)
# display the plot
plt.show()Ausgabe:
Eine Heatmap ist eine grafische Darstellung von Daten, die den Wert einer Variablen in einem zweidimensionalen Raum farblich darstellt. Heatmaps werden häufig verwendet, um die Korrelation zwischen verschiedenen Variablen in einem Datensatz zu visualisieren.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
tips = sns.load_dataset('tips')
# Create a heatmap of the correlation between variables
corr = tips.corr()
sns.heatmap(corr)
# Show the plot
plt.show()Ausgabe:

Ein weiteres Beispiel für eine Heatmap mit dem Datensatz "Flights".
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
flights = sns.load_dataset('flights')
# Pivot the data
flights = flights.pivot('month', 'year', 'passengers')
# Create a heatmap
sns.heatmap(flights, cmap='Blues', annot=True, fmt='d')
# Set the title and axis labels
plt.title('Passengers per month')
plt.xlabel('Year')
plt.ylabel('Month')
# Show the plot
plt.show()Ausgabe:
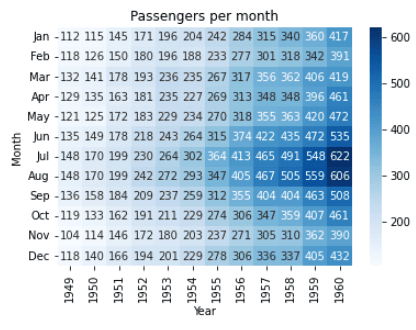
In diesem Beispiel verwenden wir den Datensatz "Flights" aus der Bibliothek "Seaborn". Wir drehen die Daten so, dass sie für die Darstellung in der Heatmap geeignet sind, indem wir die Methode .pivot() verwenden. Dann erstellen wir eine Heatmap mit der Funktion sns.heatmap() und übergeben die Variable "pivoted flights" als Argument.
Pair Plots sind eine Art der Visualisierung, bei der mehrere paarweise Streudiagramme in einem Matrixformat dargestellt werden. Jedes Streudiagramm zeigt die Beziehung zwischen zwei Variablen, während die diagonalen Diagramme die Verteilung der einzelnen Variablen zeigen.
import seaborn as sns
# Load iris dataset
iris = sns.load_dataset("iris")
# Create pair plot
sns.pairplot(data=iris)
# Show plot
plt.show()Ausgabe:
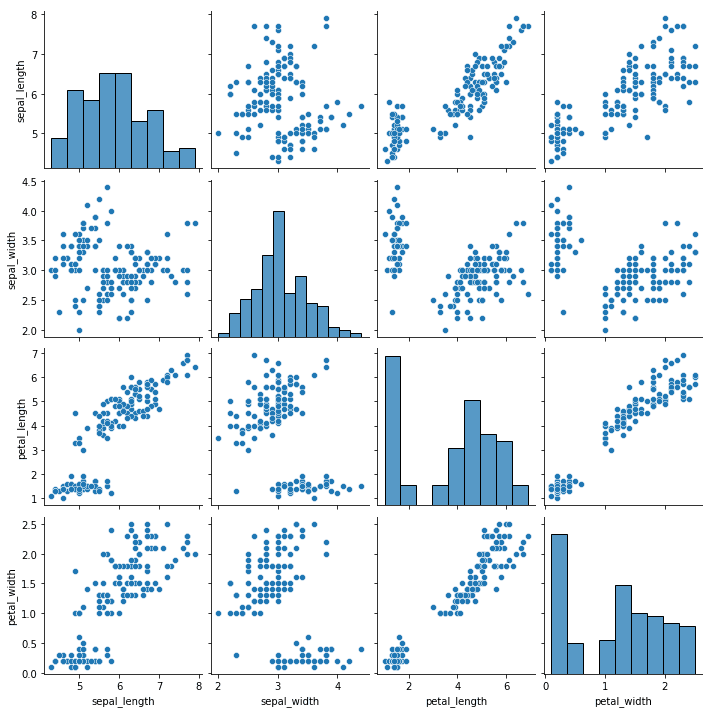
Wir können diese Darstellung mit den Parametern "Farbton" und "Diag_kind" anpassen.
import seaborn as sns
import matplotlib.pyplot as plt
# Load iris dataset
iris = sns.load_dataset("iris")
# Create pair plot with custom settings
sns.pairplot(data=iris, hue="species", diag_kind="kde", palette="husl")
# Set title
plt.title("Iris Dataset Pair Plot")
# Show plot
plt.show()Ausgabe:
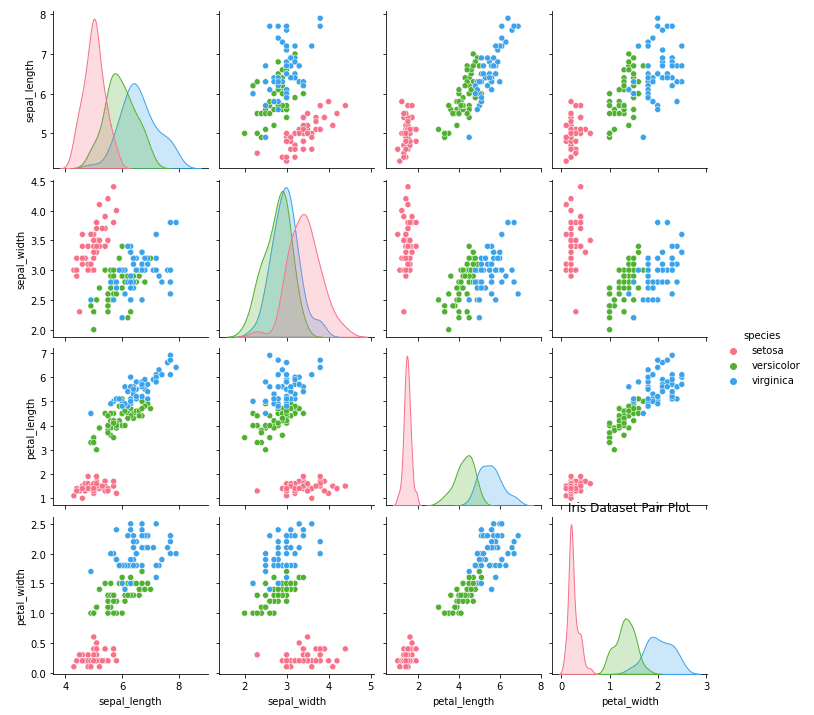
Joint Plot ist eine leistungsstarke Visualisierungstechnik in Seaborn, die zwei verschiedene Darstellungen in einer Visualisierung kombiniert: ein Scatter Plot und ein Histogramm. Das Streudiagramm zeigt die Beziehung zwischen zwei Variablen, während das Histogramm die Verteilung der einzelnen Variablen darstellt. Dies ermöglicht eine umfassendere Analyse der Daten, da sie die Korrelation zwischen den beiden Variablen und ihren individuellen Verteilungen zeigt.
Hier ist ein einfaches Beispiel für die Erstellung einer gemeinsamen Darstellung mit dem Iris-Datensatz:
import seaborn as sns
import matplotlib.pyplot as plt
# load iris dataset
iris = sns.load_dataset("iris")
# plot a joint plot of sepal length and sepal width
sns.jointplot(x="sepal_length", y="sepal_width", data=iris)
# display the plot
plt.show()Ausgabe:
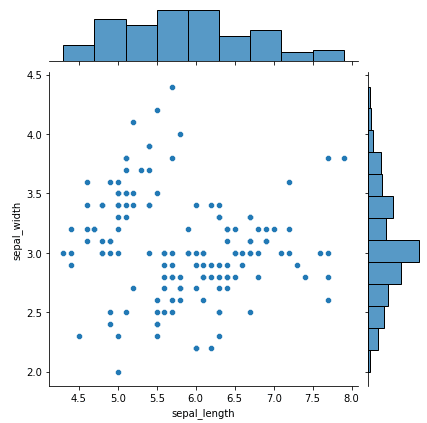
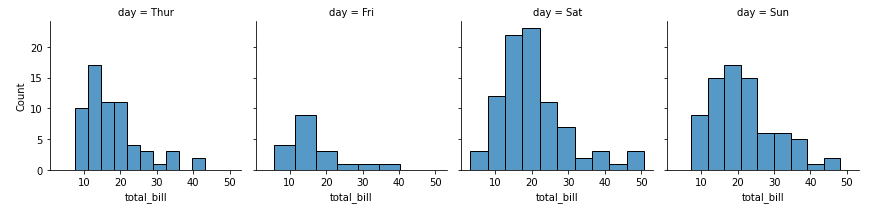
FacetGrid ist ein leistungsfähiges Werkzeug, mit dem du die Verteilung einer Variable sowie die Beziehung zwischen zwei Variablen über Ebenen zusätzlicher kategorialer Variablen hinweg visualisieren kannst.
FacetGrid erstellt ein Raster aus Teilplots, die auf den eindeutigen Werten der angegebenen kategorialen Variable basieren.
import seaborn as sns
# load the tips dataset
tips = sns.load_dataset('tips')
# create a FacetGrid for day vs total_bill
g = sns.FacetGrid(tips, col="day")
# plot histogram for total_bill in each day
g.map(sns.histplot, "total_bill")Ausgabe:
|
Python Seaborn Spickzettel |
Seaborn ist eine leistungsstarke Datenvisualisierungsbibliothek, die zahlreiche Möglichkeiten bietet, das Aussehen von Diagrammen anzupassen. Die Anpassung von Seaborn-Diagrammen ist ein wesentlicher Bestandteil der Erstellung aussagekräftiger und visuell ansprechender Visualisierungen.
Hier sind einige Beispiele für die Anpassung von Seegeborenen-Grundstücken:
Hier ist ein Beispiel dafür, wie du die Farbpaletten deiner Seegeborenen-Plots ändern kannst:
import seaborn as sns
import matplotlib.pyplot as plt
# Load sample dataset
tips = sns.load_dataset("tips")
# Create a scatter plot with color palette
sns.scatterplot(x="total_bill", y="tip", hue="day", data=tips, palette="Set2")
# Customize plot
plt.title("Total Bill vs Tip")
plt.xlabel("Total Bill ($)")
plt.ylabel("Tip ($)")
plt.show()Ausgabe:
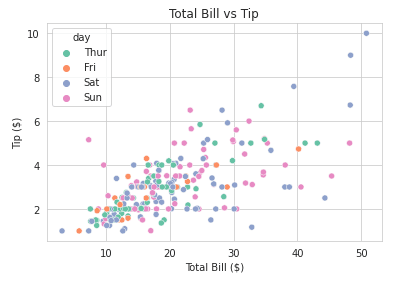
Um die Größe der Zahlen auf deinen Seegeborenenplots anzupassen, kannst du dich an dem folgenden Beispiel orientieren:
import seaborn as sns
import matplotlib.pyplot as plt
# Load sample dataset
iris = sns.load_dataset("iris")
# Create a violin plot with adjusted figure size
plt.figure(figsize=(8,6))
sns.violinplot(x="species", y="petal_length", data=iris)
# Customize plot
plt.title("Petal Length Distribution by Species")
plt.xlabel("Species")
plt.ylabel("Petal Length (cm)")
plt.show()Ausgabe:
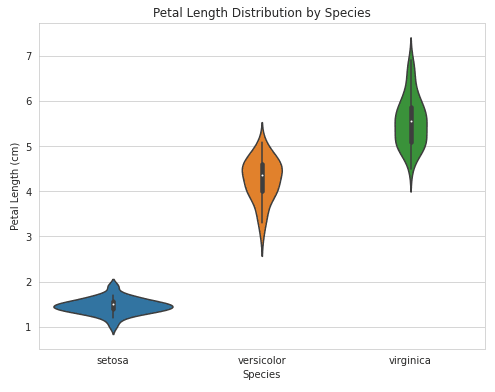
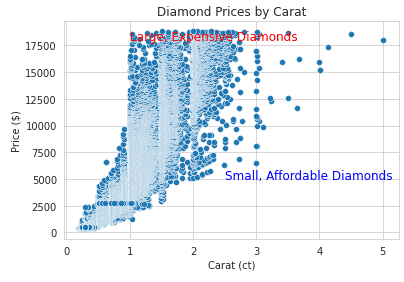
Anmerkungen können dazu beitragen, dass deine Visualisierungen leichter zu lesen sind. Wir zeigen dir unten ein Beispiel, wie du sie hinzufügen kannst:
import seaborn as sns
import matplotlib.pyplot as plt
# Load sample dataset
diamonds = sns.load_dataset("diamonds")
# Create a scatter plot with annotations
sns.scatterplot(x="carat", y="price", data=diamonds)
# Add annotations
plt.text(1, 18000, "Large, Expensive Diamonds", fontsize=12, color="red")
plt.text(2.5, 5000, "Small, Affordable Diamonds", fontsize=12, color="blue")
# Customize plot
plt.title("Diamond Prices by Carat")
plt.xlabel("Carat (ct)")
plt.ylabel("Price ($)")
plt.show()Ausgabe:
Seaborn bietet eine breite Palette von Diagrammtypen, die jeweils für verschiedene Arten von Daten und Analysen konzipiert sind. Es ist wichtig, die richtige Darstellungsart für deine Daten zu wählen, um deine Ergebnisse effektiv zu kommunizieren. Ein Streudiagramm kann zum Beispiel besser geeignet sein, um die Beziehung zwischen zwei kontinuierlichen Variablen darzustellen, während ein Balkendiagramm besser geeignet ist, um kategorische Daten zu visualisieren.
Farbe kann ein mächtiges Werkzeug zur Datenvisualisierung sein, aber es ist wichtig, sie effektiv einzusetzen. Vermeide es, zu viele Farben oder zu helle Farben zu verwenden, da dies die Lesbarkeit der Visualisierung erschweren kann. Verwende stattdessen Farbe, um wichtige Informationen hervorzuheben oder um ähnliche Datenpunkte zu gruppieren.
Beschriftungen und Titel sind für eine effektive Datenvisualisierung unerlässlich. Achte darauf, dass du deine Achsen deutlich beschriftest und einen aussagekräftigen Titel für deine Visualisierung angibst. Das wird deinem Publikum helfen, die Botschaft zu verstehen, die du vermitteln willst.
Bei der Erstellung von Visualisierungen ist es wichtig, die Zielgruppe und die Botschaft, die du vermitteln willst, zu berücksichtigen. Wenn dein Publikum kein Fachpublikum ist, solltest du eine klare und prägnante Sprache verwenden, Fachjargon vermeiden und alle statistischen Konzepte klar erklären.
Seaborn bietet eine Reihe von statistischen Funktionen, die du zur Analyse deiner Daten nutzen kannst. Achte bei der Auswahl einer statistischen Funktion darauf, dass du diejenige wählst, die für deine Daten und deine Forschungsfrage am besten geeignet ist.
In Seaborn findest du eine Vielzahl von Anpassungsoptionen, mit denen du deine Visualisierungen verbessern kannst. Experimentiere mit verschiedenen Schriftarten, Stilen und Farben, um diejenige zu finden, die deine Botschaft am besten transportiert.
Seaborn baut auf Matplotlib auf und bietet eine übergeordnete Schnittstelle zur Erstellung statistischer Grafiken. Während Matplotlib eine universelle Plot-Bibliothek ist, wurde Seaborn speziell für die Visualisierung statistischer Daten entwickelt.
Seaborn bietet mehrere Vorteile gegenüber Matplotlib, darunter eine einfachere Syntax für die Erstellung komplexer Plots, integrierte Unterstützung für statistische Visualisierungen und ästhetisch ansprechende Standardeinstellungen, die leicht angepasst werden können.
Außerdem bietet Seaborn mehrere spezielle Plot-Typen, die in Matplotlib nicht verfügbar sind, wie z. B. Violin-Plots und Schwarm-Plots.
Pandas ist eine leistungsstarke Bibliothek zur Datenmanipulation in Python, die eine Reihe von Funktionen für die Arbeit mit strukturierten Daten bietet. Während Pandas mit seiner DataFrame.plot()-Methode grundlegende Plot-Funktionen bietet, stellt Seaborn erweiterte Visualisierungsfunktionen zur Verfügung, die speziell für statistische Daten entwickelt wurden.
Die Funktionen von Seaborn sind für die Arbeit mit Pandas-Datenstrukturen optimiert und machen es einfach, eine Vielzahl von informativen Visualisierungen direkt aus Pandas-Datenrahmen zu erstellen.
Seaborn bietet auch spezielle Plot-Typen wie Facettenraster und Paarplots, die in Pandas nicht verfügbar sind.
Plotly ist eine webbasierte Datenvisualisierungsbibliothek, die interaktive und kollaborative Datenvisualisierungen bietet.
Während sich Seaborn in erster Linie auf die Erstellung statischer Visualisierungen konzentriert, bietet Plotly interaktivere und dynamischere Visualisierungen, die in Webanwendungen verwendet oder online geteilt werden können. Plotly bietet auch einige spezielle Plot-Typen, die in Seaborn nicht verfügbar sind, wie z. B. Konturplots und 3D-Oberflächenplots.
Seaborn bietet jedoch eine einfachere Syntax und leichtere Anpassungsmöglichkeiten für die Erstellung statischer Visualisierungen, was es für bestimmte Arten von Projekten zu einer besseren Wahl macht.
Seaborn ist eine leistungsstarke Datenvisualisierungsbibliothek in Python, die eine intuitive und einfach zu bedienende Oberfläche für die Erstellung informativer statistischer Grafiken bietet. Mit seiner großen Auswahl an Visualisierungswerkzeugen ermöglicht Seaborn die schnelle und effiziente Erforschung und Vermittlung von Erkenntnissen aus komplexen Datensätzen.
Von Streudiagrammen und Liniendiagrammen bis hin zu Heatmaps und Facettenrastern bietet Seaborn eine breite Palette an Visualisierungen für die unterschiedlichsten Bedürfnisse. Außerdem macht die Fähigkeit von Seaborn, sich mit Pandas und Numpy zu integrieren, es zu einem unverzichtbaren Werkzeug für Datenanalysten und Wissenschaftler.
Mit diesem Einsteigerhandbuch zu Python Seaborn kannst du in die Welt der Datenvisualisierung eintauchen und deine Erkenntnisse effektiv an ein breites Publikum weitergeben.
Wenn du dein Wissen zu diesem Thema weiter vertiefen möchtest, schau dir unsere Kurse Einführung in die Datenvisualisierung mit Seaborn oder Datenvisualisierung für Fortgeschrittene mit Seaborn an.
In diesen Kursen lernst du, wie du die fortschrittlichen Visualisierungstools von Seaborn nutzen kannst, um verschiedene reale Datensätze zu analysieren, z. B. die American Housing Survey, Daten zu Studiengebühren und Gäste der Daily Show.
Du kannst dir auch diesen kostenlosen Seaborn-Spickzettel ansehen:
|
Python Seaborn: Statistische Datenvisualisierung |
Erfahre mehr über Python und Seaborn
Kurs
Kurs
Kurs
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
Aditya Sharma
Tutorial
Aditya Sharma