Cours
Intermediate Data Visualization with Seaborn
4 h
75K
La visualisation est un aspect crucial de l'analyse et de l'interprétation des données, car elle permet de comprendre facilement des ensembles de données complexes. Elle permet d'identifier des modèles, des relations et des tendances qui pourraient ne pas être apparents à partir des seules données brutes. Ces dernières années, Python est devenu l'un des langages de programmation les plus populaires pour l'analyse de données, en raison de son vaste éventail de bibliothèques et de cadres.
Les bibliothèques de visualisation en Python permettent aux utilisateurs de créer des visualisations de données intuitives et interactives qui peuvent communiquer efficacement des idées à un large public. Parmi les bibliothèques et cadres de visualisation populaires en Python, citons Matplotlib, Plotly, Bokeh et Seaborn. Chacune de ces bibliothèques possède des caractéristiques et des capacités uniques qui répondent à des besoins spécifiques.
Dans ce tutoriel, nous nous concentrerons sur Seaborn, une bibliothèque de visualisation de données populaire en Python qui offre une interface facile à utiliser pour créer des graphiques statistiques informatifs.
Construite au-dessus de Matplotlib, Seaborn est une bibliothèque Python bien connue pour la visualisation de données qui offre une interface conviviale pour produire des graphiques statistiques visuellement attrayants et informatifs. Il est conçu pour fonctionner avec les dataframes Pandas, ce qui facilite la visualisation et l'exploration des données de manière rapide et efficace.
Seaborn offre une variété d'outils puissants pour visualiser les données, y compris les diagrammes de dispersion, les diagrammes linéaires, les diagrammes à barres, les cartes thermiques, et bien d'autres encore. Il prend également en charge les analyses statistiques avancées, telles que les analyses de régression, les diagrammes de distribution et les diagrammes catégoriels.
Vous pouvez apprendre tout ce qu'il faut savoir sur Seborn et ses utilisations grâce à notre cours Introduction à la visualisation de données avec Seaborn.
Le principal avantage de Seaborn réside dans sa capacité à générer des tracés attrayants avec un minimum d'efforts de codage. Il propose une série de thèmes et de palettes de couleurs par défaut, que vous pouvez facilement personnaliser en fonction de vos préférences. En outre, Seaborn offre une gamme de fonctions statistiques intégrées, permettant aux utilisateurs d'effectuer facilement des analyses statistiques complexes avec leurs visualisations.
Une autre caractéristique notable de Seaborn est sa capacité à créer des visualisations complexes à plusieurs parcelles. Avec Seaborn, les utilisateurs peuvent créer des grilles de tracés qui permettent de comparer facilement plusieurs variables ou sous-ensembles de données. Il s'agit donc d'un outil idéal pour l'analyse et la présentation de données exploratoires.
Seaborn est une bibliothèque de visualisation de données puissante et flexible en Python qui offre une interface facile à utiliser pour créer des graphiques statistiques informatifs et esthétiques. Il fournit une gamme d'outils de visualisation des données, y compris des analyses statistiques avancées, et permet de créer facilement des visualisations complexes à plusieurs tableaux.
Les deux bibliothèques de visualisation de données les plus utilisées de Python sont Matplotlib et Seaborn. Bien que les deux bibliothèques soient conçues pour créer des graphiques et des visualisations de haute qualité, elles présentent plusieurs différences essentielles qui les rendent plus adaptées à différents cas d'utilisation.
L'une des principales différences entre Matplotlib et Seaborn est leur orientation. Matplotlib est une bibliothèque de traçage de bas niveau qui fournit une large gamme d'outils pour créer des visualisations hautement personnalisables. Il s'agit d'une bibliothèque très flexible, qui permet aux utilisateurs de créer presque tous les types d'intrigues qu'ils peuvent imaginer. Cette flexibilité se fait au prix d'une courbe d'apprentissage plus raide et d'un code plus verbeux.
Seaborn, quant à lui, est une interface de haut niveau pour la création de graphiques statistiques. Il est construit au-dessus de Matplotlib et fournit une interface plus simple et plus intuitive pour créer des graphiques statistiques courants. Seaborn est conçu pour fonctionner avec les dataframes Pandas, ce qui facilite la création de visualisations avec un minimum de code. Il offre également une gamme de fonctions statistiques intégrées, permettant aux utilisateurs d'effectuer facilement des analyses statistiques complexes avec leurs visualisations.
Une autre différence clé entre Matplotlib et Seaborn est leur style par défaut et leur palette de couleurs. Matplotlib fournit un ensemble limité de styles et de palettes de couleurs par défaut, ce qui oblige les utilisateurs à personnaliser manuellement leurs tracés pour obtenir l'aspect souhaité. Seaborn, quant à lui, propose une gamme de styles par défaut et de palettes de couleurs optimisées pour différents types de données et de visualisations. Cela permet aux utilisateurs de créer facilement des tracés visuellement attrayants avec un minimum de personnalisation.
Bien que les deux bibliothèques aient leurs forces et leurs faiblesses, Seaborn est généralement mieux adapté à la création de graphiques statistiques et à l'analyse exploratoire des données, tandis que Matplotlib est mieux adapté à la création de graphiques hautement personnalisables pour les présentations et les publications. Cependant, il convient de noter que Seaborn est construit au-dessus de Matplotlib, et que les deux bibliothèques peuvent être utilisées ensemble pour créer des visualisations complexes et hautement personnalisables qui tirent parti des forces des deux bibliothèques.
Vous pouvez explorer Matplotlib plus en détail avec notre tutoriel Introduction au traçage avec Matplotlib en Python.
Matplotlib et Seaborn sont toutes deux de puissantes bibliothèques de visualisation de données en Python, avec des forces et des faiblesses différentes. Comprendre les différences entre les deux bibliothèques peut aider les utilisateurs à choisir le bon outil pour leurs besoins spécifiques en matière de visualisation de données.
Seaborn est supporté par Python 3.7+ et a très peu de dépendances de base. L'installation de Seaborn est assez simple. Vous pouvez l'installer avec le gestionnaire de paquets Python (pip) ou le gestionnaire de paquets conda.
# install seaborn with pip
pip install seaborn
Lorsque vous utilisez pip, Seaborn et ses dépendances seront installés. Si vous souhaitez accéder à des fonctionnalités supplémentaires et optionnelles, vous pouvez également inclure des dépendances optionnelles dans pip install. Par exemple :
pip install seaborn[stats]
Ou avec conda :
# install seaborn with conda
conda install seaborn
Seaborn fournit plusieurs ensembles de données intégrés que nous pouvons utiliser pour la visualisation des données et l'analyse statistique. Ces ensembles de données sont stockés dans des dataframes pandas, ce qui facilite leur utilisation avec les fonctions de traçage de Seaborn.
L'un des ensembles de données les plus courants, qui est également utilisé dans tous les exemples officiels de Seaborn, s'appelle `tips dataset` ; il contient des informations sur les pourboires donnés dans les restaurants. Voici un exemple de chargement et de visualisation de l'ensemble de données Tips dans Seaborn :
import seaborn as sns
# Load the Tips dataset
tips = sns.load_dataset("tips")
# Create a histogram of the total bill amounts
sns.histplot(data=tips, x="total_bill")Sortie:
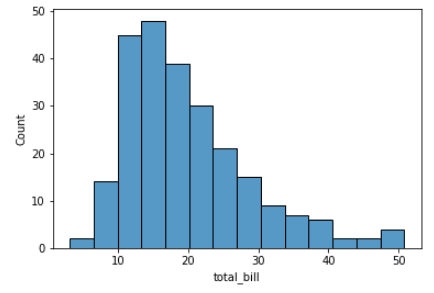
Si vous ne comprenez pas encore cette intrigue, ne vous inquiétez pas. C'est ce qu'on appelle un histogramme. Nous reviendrons plus en détail sur les histogrammes dans la suite de ce tutoriel. Pour l'instant, ce qu'il faut retenir, c'est que Seaborn est livré avec un grand nombre d'échantillons de données sous forme de DataFrame pandas qui sont faciles à utiliser et qui vous permettent de mettre en pratique vos compétences en matière de visualisation. Voici un autre exemple de chargement du jeu de données `exercise`.
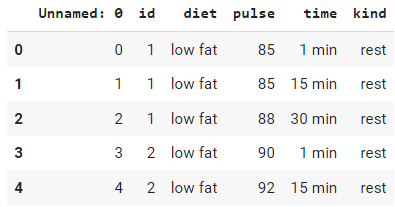
import seaborn as sns
# Load the exercise dataset
exercise = sns.load_dataset("exercise")
# check the head
exercise.head()Sortie:
Seaborn propose un large éventail de types de graphiques qui peuvent être utilisés pour la visualisation et l'analyse exploratoire des données. D'une manière générale, toute visualisation peut être classée dans l'une de ces trois catégories.

Voici quelques-uns des types de parcelles les plus couramment utilisés dans Seaborn :
Nous allons maintenant voir des exemples et des explications détaillées pour chacun d'entre eux dans la section suivante de ce tutoriel.
Les diagrammes de dispersion sont utilisés pour visualiser la relation entre deux variables continues. Chaque point du graphique représente un seul point de données, et la position du point sur les axes x et y représente les valeurs des deux variables.
Le graphique peut être personnalisé à l'aide de différentes couleurs et de marqueurs permettant de distinguer les différents groupes de points de données. Dans Seaborn, les diagrammes de dispersion peuvent être créés à l'aide de la fonction scatterplot().
import seaborn as sns
tips = sns.load_dataset("tips")
sns.scatterplot(x="total_bill", y="tip", data=tips)Sortie:
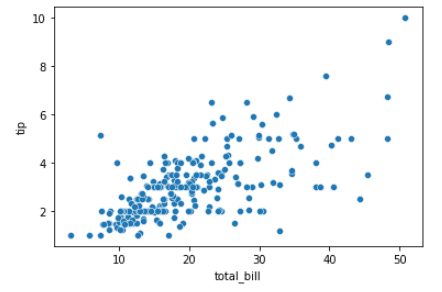
Ce tracé simple peut être amélioré en personnalisant les paramètres `hue` et `size` du tracé. Voici comment :
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
# customize the scatter plot
sns.scatterplot(x="total_bill", y="tip", hue="sex", size="size", sizes=(50, 200), data=tips)
# add labels and title
plt.xlabel("Total Bill")
plt.ylabel("Tip")
plt.title("Relationship between Total Bill and Tip")
# display the plot
plt.show()Sortie:
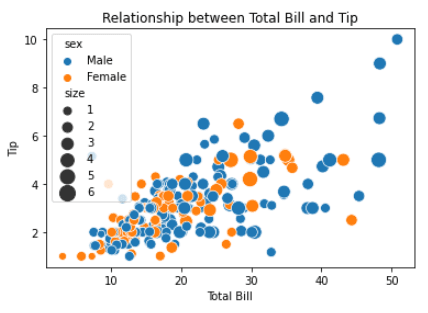
Dans cet exemple, nous avons utilisé la bibliothèque `seaborn` pour un diagramme de dispersion simple et nous avons utilisé `matplotlib` pour personnaliser davantage le diagramme de dispersion.
Les graphiques linéaires sont utilisés pour visualiser les tendances des données dans le temps ou d'autres variables continues. Dans un graphique linéaire, chaque point de données est relié par une ligne, créant ainsi une courbe régulière. Dans Seaborn, il est possible de créer des graphiques linéaires à l'aide de la fonction lineplot().
import seaborn as sns
fmri = sns.load_dataset("fmri")
sns.lineplot(x="timepoint", y="signal", data=fmri)Sortie:
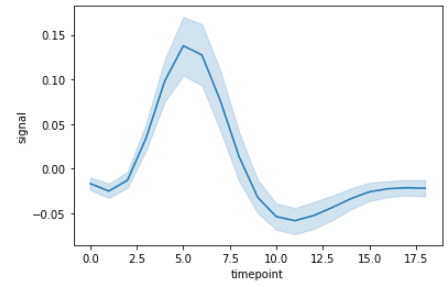
Nous pouvons très facilement personnaliser ceci en utilisant les colonnes `event` et `region` de l'ensemble de données.
import seaborn as sns
import matplotlib.pyplot as plt
fmri = sns.load_dataset("fmri")
# customize the line plot
sns.lineplot(x="timepoint", y="signal", hue="event", style="region", markers=True, dashes=False, data=fmri)
# add labels and title
plt.xlabel("Timepoint")
plt.ylabel("Signal Intensity")
plt.title("Changes in Signal Intensity over Time")
# display the plot
plt.show()Sortie:
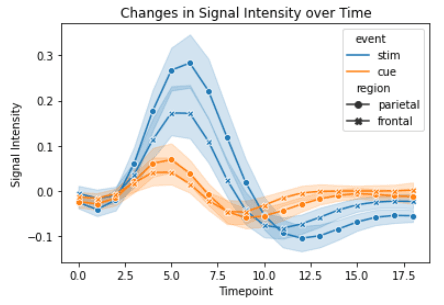
Là encore, nous avons utilisé la bibliothèque `seaborn` pour réaliser un simple tracé linéaire et nous avons utilisé la bibliothèque `matplotlib` pour personnaliser et améliorer le tracé linéaire simple. Vous pouvez examiner plus en détail les tracés linéaires de Seaborn dans notre tutoriel séparé.
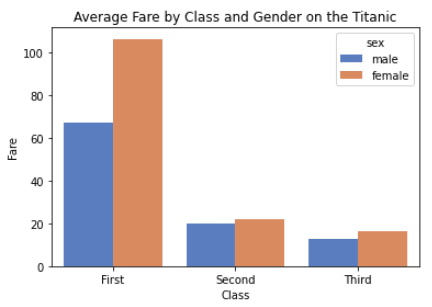
Les diagrammes en barres sont utilisés pour visualiser la relation entre une variable catégorielle et une variable continue. Dans un diagramme en bâtons, chaque bâton représente la moyenne ou la médiane (ou toute autre agrégation) de la variable continue pour chaque catégorie. Dans Seaborn, les diagrammes à barres peuvent être créés à l'aide de la fonction barplot().
import seaborn as sns
titanic = sns.load_dataset("titanic")
sns.barplot(x="class", y="fare", data=titanic)Sortie:
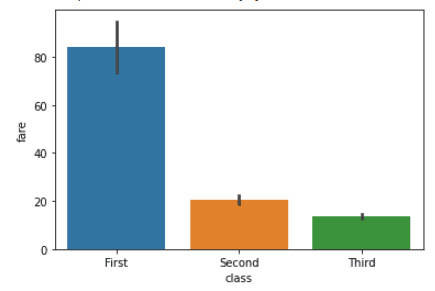
Personnalisons ce graphique en incluant la colonne `sex` de l'ensemble de données.
import seaborn as sns
import matplotlib.pyplot as plt
titanic = sns.load_dataset("titanic")
# customize the bar plot
sns.barplot(x="class", y="fare", hue="sex", ci=None, palette="muted", data=titanic)
# add labels and title
plt.xlabel("Class")
plt.ylabel("Fare")
plt.title("Average Fare by Class and Gender on the Titanic")
# display the plot
plt.show()Sortie:
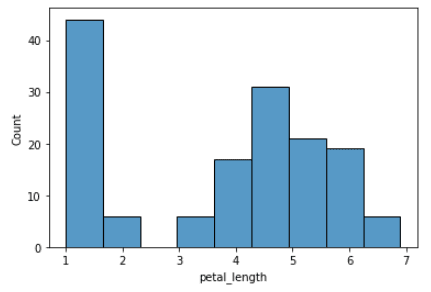
Les histogrammes permettent de visualiser la distribution d'une variable continue. Dans un histogramme, les données sont divisées en cases et la hauteur de chaque case représente la fréquence ou le nombre de points de données dans cette case. Dans Seaborn, les histogrammes peuvent être créés à l'aide de la fonction histplot().
import seaborn as sns
iris = sns.load_dataset("iris")
sns.histplot(x="petal_length", data=iris)Sortie:
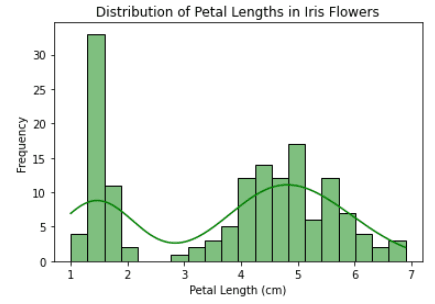
import seaborn as sns
import matplotlib.pyplot as plt
iris = sns.load_dataset("iris")
# customize the histogram
sns.histplot(data=iris, x="petal_length", bins=20, kde=True, color="green")
# add labels and title
plt.xlabel("Petal Length (cm)")
plt.ylabel("Frequency")
plt.title("Distribution of Petal Lengths in Iris Flowers")
# display the plot
plt.show()Sortie:
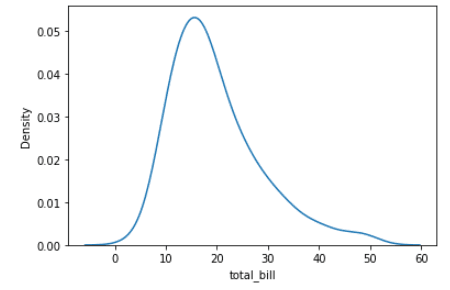
Les diagrammes de densité, également connus sous le nom de diagrammes de densité à noyau, sont un type de visualisation de données qui affiche la distribution d'une variable continue. Ils sont similaires aux histogrammes, mais au lieu de représenter les données sous forme de barres, les diagrammes de densité utilisent une courbe lisse pour estimer la densité des données. Dans Seaborn, des graphiques de densité peuvent être créés à l'aide de la fonction kdeplot().
import seaborn as sns
tips = sns.load_dataset("tips")
sns.kdeplot(data=tips, x="total_bill")Sortie:
Améliorons l'intrigue en la personnalisant.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset from Seaborn
tips = sns.load_dataset("tips")
# Create a density plot of the "total_bill" column from the "tips" dataset
# We use the "hue" parameter to differentiate between "lunch" and "dinner" meal times
# We use the "fill" parameter to fill the area under the curve
# We adjust the "alpha" and "linewidth" parameters to make the plot more visually appealing
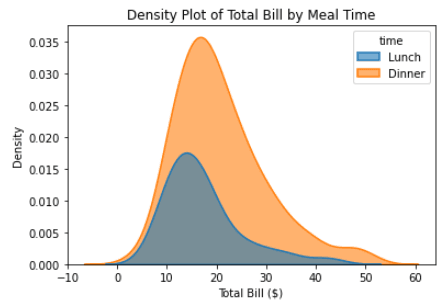
sns.kdeplot(data=tips, x="total_bill", hue="time", fill=True, alpha=0.6, linewidth=1.5)
# Add a title and labels to the plot using Matplotlib
plt.title("Density Plot of Total Bill by Meal Time")
plt.xlabel("Total Bill ($)")
plt.ylabel("Density")
# Show the plot
plt.show()Sortie:
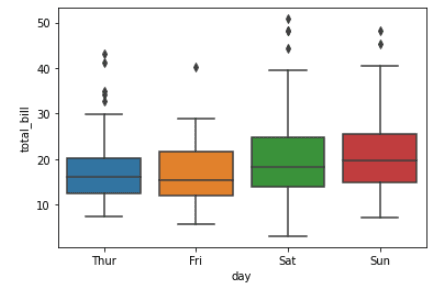
Les diagrammes en boîte sont un type de visualisation qui montre la distribution d'un ensemble de données. Ils sont couramment utilisés pour comparer la distribution d'une ou plusieurs variables dans différentes catégories.
import seaborn as sns
tips = sns.load_dataset("tips")
sns.boxplot(x="day", y="total_bill", data=tips)Sortie:
Personnalisez le diagramme en boîte en incluant la colonne `time` de l'ensemble de données.
import seaborn as sns
import matplotlib.pyplot as plt
# load the tips dataset from Seaborn
tips = sns.load_dataset("tips")
# create a box plot of total bill by day and meal time, using the "hue" parameter to differentiate between lunch and dinner
# customize the color scheme using the "palette" parameter
# adjust the linewidth and fliersize parameters to make the plot more visually appealing
sns.boxplot(x="day", y="total_bill", hue="time", data=tips, palette="Set3", linewidth=1.5, fliersize=4)
# add a title, xlabel, and ylabel to the plot using Matplotlib functions
plt.title("Box Plot of Total Bill by Day and Meal Time")
plt.xlabel("Day of the Week")
plt.ylabel("Total Bill ($)")
# display the plot
plt.show()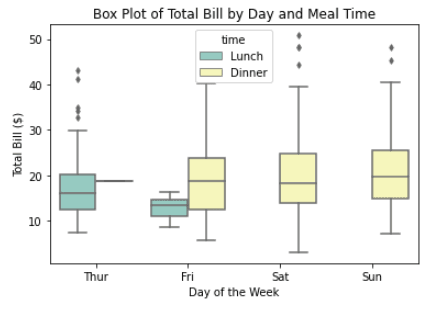
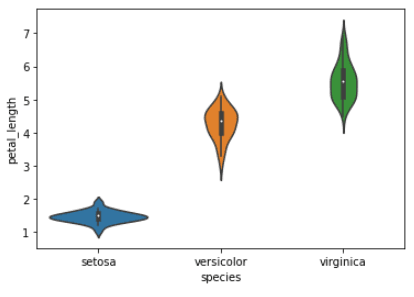
Un diagramme en forme de violon est un type de visualisation de données qui combine des aspects des diagrammes en boîte et des diagrammes de densité. Il affiche une estimation de la densité des données, généralement lissée par un estimateur de densité à noyau, ainsi que l'intervalle interquartile (IQR) et la médiane sous la forme d'un diagramme en boîte.
La largeur du violon représente l'estimation de la densité, les parties les plus larges indiquant une densité plus élevée, et l'IQR et la médiane sont représentés par un point blanc et une ligne à l'intérieur du violon.
import seaborn as sns
# load the iris dataset from Seaborn
iris = sns.load_dataset("iris")
# create a violin plot of petal length by species
sns.violinplot(x="species", y="petal_length", data=iris)
# display the plot
plt.show()Sortie:
Une carte thermique est une représentation graphique de données qui utilise des couleurs pour décrire la valeur d'une variable dans un espace bidimensionnel. Les cartes thermiques sont couramment utilisées pour visualiser la corrélation entre les différentes variables d'un ensemble de données.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
tips = sns.load_dataset('tips')
# Create a heatmap of the correlation between variables
corr = tips.corr()
sns.heatmap(corr)
# Show the plot
plt.show()Sortie:

Un autre exemple de carte thermique utilisant le jeu de données `flights`.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
flights = sns.load_dataset('flights')
# Pivot the data
flights = flights.pivot('month', 'year', 'passengers')
# Create a heatmap
sns.heatmap(flights, cmap='Blues', annot=True, fmt='d')
# Set the title and axis labels
plt.title('Passengers per month')
plt.xlabel('Year')
plt.ylabel('Month')
# Show the plot
plt.show()Sortie:
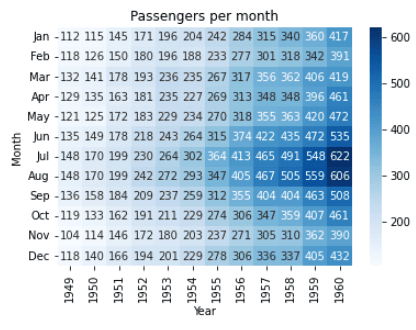
Dans cet exemple, nous utilisons le jeu de données `flights` de la bibliothèque `seaborn`. Nous pivotons les données pour les adapter à la représentation sous forme de carte thermique à l'aide de la méthode .pivot(). Ensuite, nous créons une carte thermique à l'aide de la fonction sns.heatmap() et transmettons la variable des vols pivotés comme argument.
Les diagrammes en paires sont un type de visualisation dans lequel plusieurs diagrammes de dispersion par paires sont affichés dans un format matriciel. Chaque diagramme de dispersion montre la relation entre deux variables, tandis que les diagrammes diagonaux montrent la distribution des variables individuelles.
import seaborn as sns
# Load iris dataset
iris = sns.load_dataset("iris")
# Create pair plot
sns.pairplot(data=iris)
# Show plot
plt.show()Sortie:
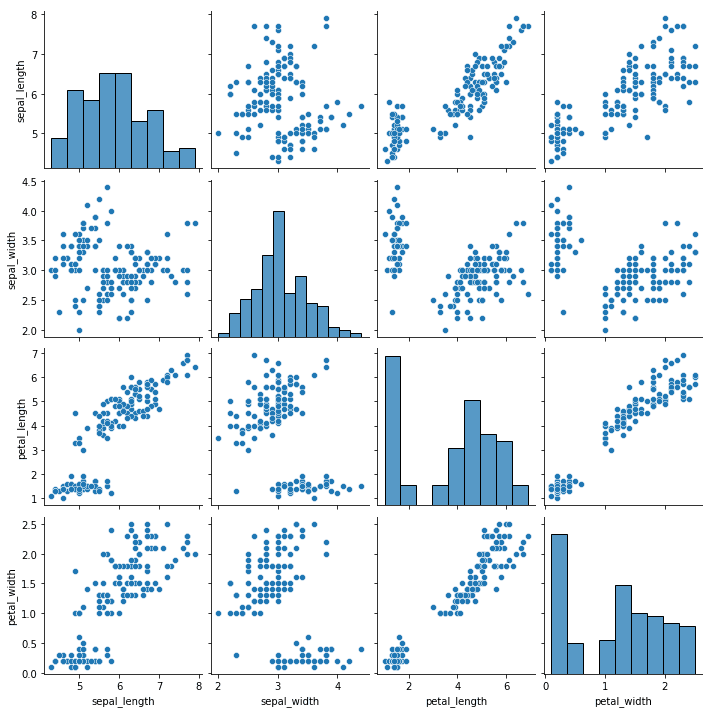
Nous pouvons personnaliser ce graphique en utilisant les paramètres `hue` et `diag_kind`.
import seaborn as sns
import matplotlib.pyplot as plt
# Load iris dataset
iris = sns.load_dataset("iris")
# Create pair plot with custom settings
sns.pairplot(data=iris, hue="species", diag_kind="kde", palette="husl")
# Set title
plt.title("Iris Dataset Pair Plot")
# Show plot
plt.show()Sortie:
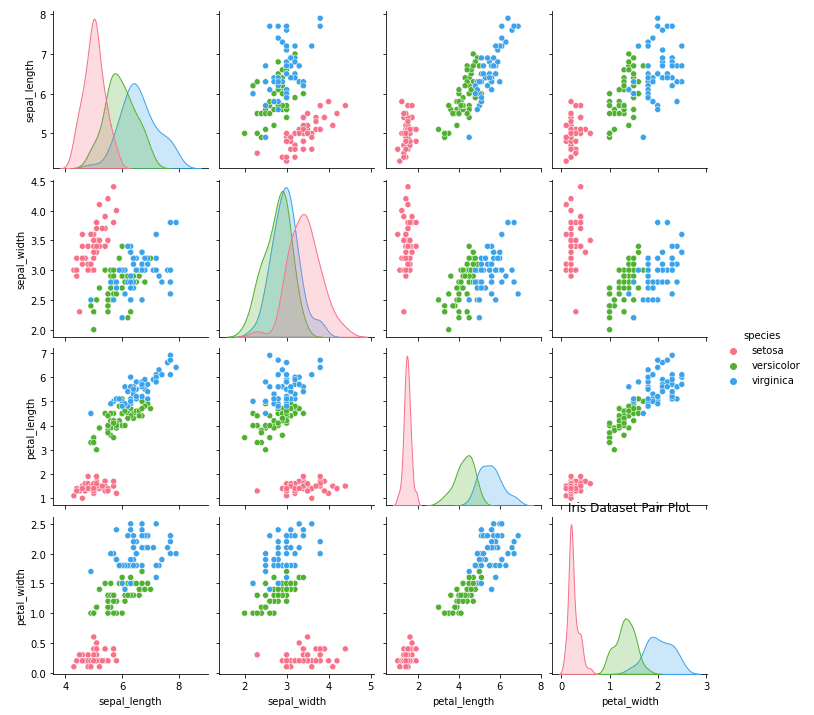
Le graphique conjoint est une technique de visualisation puissante de seaborn qui combine deux graphiques différents en une seule visualisation : un diagramme de dispersion et un histogramme. Le diagramme de dispersion montre la relation entre deux variables, tandis que l'histogramme montre la distribution de chaque variable individuelle. Cela permet une analyse plus complète des données, car cela montre la corrélation entre les deux variables et leurs distributions individuelles.
Voici un exemple simple de construction d'un diagramme de jointures de seaborn à l'aide de l'ensemble de données d'iris :
import seaborn as sns
import matplotlib.pyplot as plt
# load iris dataset
iris = sns.load_dataset("iris")
# plot a joint plot of sepal length and sepal width
sns.jointplot(x="sepal_length", y="sepal_width", data=iris)
# display the plot
plt.show()Sortie:
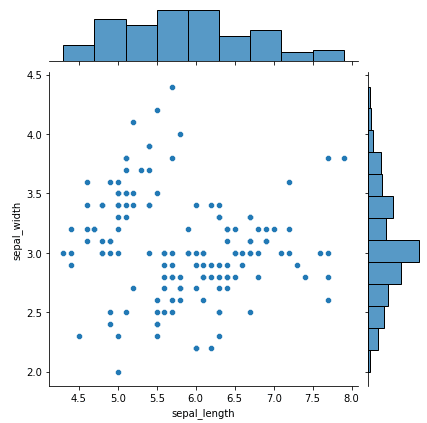
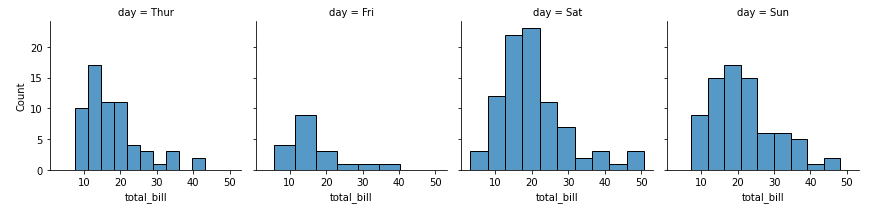
FacetGrid est un outil puissant qui vous permet de visualiser la distribution d'une variable ainsi que la relation entre deux variables, à travers des niveaux de variables catégorielles supplémentaires.
FacetGrid crée une grille de sous-graphes basée sur les valeurs uniques de la variable catégorielle spécifiée.
import seaborn as sns
# load the tips dataset
tips = sns.load_dataset('tips')
# create a FacetGrid for day vs total_bill
g = sns.FacetGrid(tips, col="day")
# plot histogram for total_bill in each day
g.map(sns.histplot, "total_bill")Sortie:
|
Python Seaborn Cheat Sheet |
Seaborn est une puissante bibliothèque de visualisation de données qui offre de nombreux moyens de personnaliser l'apparence des graphiques. La personnalisation des tracés Seaborn est une partie essentielle de la création de visualisations significatives et visuellement attrayantes.
Voici quelques exemples de personnalisation des parcelles de seaborn :
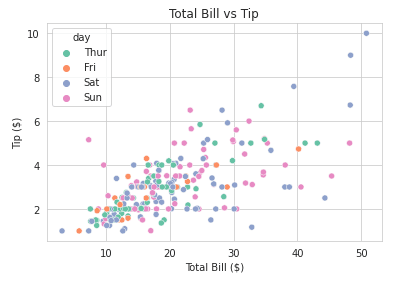
Voici un exemple de la façon dont vous pouvez modifier les palettes de couleurs de vos parcelles seaborn :
import seaborn as sns
import matplotlib.pyplot as plt
# Load sample dataset
tips = sns.load_dataset("tips")
# Create a scatter plot with color palette
sns.scatterplot(x="total_bill", y="tip", hue="day", data=tips, palette="Set2")
# Customize plot
plt.title("Total Bill vs Tip")
plt.xlabel("Total Bill ($)")
plt.ylabel("Tip ($)")
plt.show()Sortie:
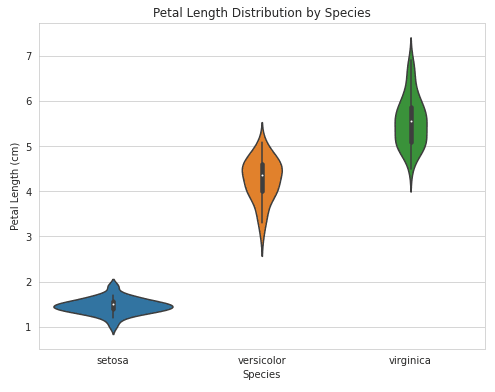
Pour ajuster la taille des chiffres sur vos parcelles de seaborn, vous pouvez vous inspirer de l'exemple ci-dessous :
import seaborn as sns
import matplotlib.pyplot as plt
# Load sample dataset
iris = sns.load_dataset("iris")
# Create a violin plot with adjusted figure size
plt.figure(figsize=(8,6))
sns.violinplot(x="species", y="petal_length", data=iris)
# Customize plot
plt.title("Petal Length Distribution by Species")
plt.xlabel("Species")
plt.ylabel("Petal Length (cm)")
plt.show()Sortie:
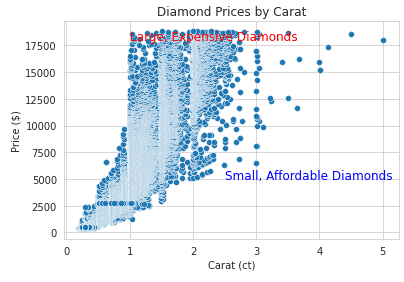
Les annotations peuvent faciliter la lecture de vos visualisations. Vous trouverez ci-dessous un exemple de la manière de les ajouter :
import seaborn as sns
import matplotlib.pyplot as plt
# Load sample dataset
diamonds = sns.load_dataset("diamonds")
# Create a scatter plot with annotations
sns.scatterplot(x="carat", y="price", data=diamonds)
# Add annotations
plt.text(1, 18000, "Large, Expensive Diamonds", fontsize=12, color="red")
plt.text(2.5, 5000, "Small, Affordable Diamonds", fontsize=12, color="blue")
# Customize plot
plt.title("Diamond Prices by Carat")
plt.xlabel("Carat (ct)")
plt.ylabel("Price ($)")
plt.show()Sortie:
Seaborn propose une large gamme de types de parcelles, chacune conçue pour différents types de données et d'analyses. Il est important de choisir le bon type de graphique pour vos données afin de communiquer efficacement vos résultats. Par exemple, un diagramme de dispersion peut être plus approprié pour visualiser la relation entre deux variables continues, tandis qu'un diagramme à barres peut être plus approprié pour visualiser des données catégorielles.
La couleur peut être un outil puissant pour la visualisation des données, mais il est important de l'utiliser efficacement. Évitez d'utiliser trop de couleurs ou des couleurs trop vives, car cela peut rendre la visualisation difficile à lire. Utilisez plutôt la couleur pour mettre en évidence les informations importantes ou pour regrouper des points de données similaires.
Les étiquettes et les titres sont essentiels pour une visualisation efficace des données. Veillez à étiqueter clairement vos axes et à donner un titre descriptif à votre visualisation. Cela aidera votre public à comprendre le message que vous essayez de transmettre.
Lorsque vous créez des visualisations, il est important de tenir compte du public et du message que vous essayez de communiquer. Si votre public n'est pas technique, utilisez un langage clair et concis, évitez le jargon technique et fournissez des explications claires sur les concepts statistiques.
Seaborn propose une série de fonctions statistiques que vous pouvez utiliser pour analyser vos données. Lorsque vous choisissez une fonction statistique, assurez-vous de choisir celle qui est la plus appropriée à vos données et à votre question de recherche.
Vous trouverez dans Seaborn un large éventail d'options de personnalisation que vous pouvez utiliser pour améliorer vos visualisations. Expérimentez différentes polices, styles et couleurs pour trouver celle qui communique le mieux votre message.
Seaborn est construit au-dessus de Matplotlib et fournit une interface de plus haut niveau pour créer des graphiques statistiques. Alors que Matplotlib est une bibliothèque de traçage polyvalente, Seaborn est spécifiquement conçu pour la visualisation de données statistiques.
Seaborn offre plusieurs avantages par rapport à Matplotlib, notamment une syntaxe plus simple pour créer des graphiques complexes, un support intégré pour les visualisations statistiques et des paramètres par défaut esthétiques qui peuvent être facilement personnalisés.
En outre, Seaborn propose plusieurs types de tracés spécialisés qui ne sont pas disponibles dans Matplotlib, tels que les tracés de violon et les tracés d'essaims.
Pandas est une puissante bibliothèque de manipulation de données en Python qui offre un éventail de fonctionnalités pour travailler avec des données structurées. Alors que Pandas offre des capacités de traçage de base grâce à sa méthode DataFrame.plot(), Seaborn propose des fonctionnalités de visualisation plus avancées, spécifiquement conçues pour les données statistiques.
Les fonctions de Seaborn sont optimisées pour fonctionner avec les structures de données Pandas, ce qui facilite la création d'un large éventail de visualisations informatives directement à partir de cadres de données Pandas.
Seaborn propose également des types de tracés spécialisés, tels que les grilles à facettes et les tracés par paires, qui ne sont pas disponibles dans Pandas.
Plotly est une bibliothèque de visualisation de données basée sur le web qui offre des visualisations de données interactives et collaboratives.
Alors que Seaborn se concentre principalement sur la création de visualisations statiques, Plotly offre des visualisations plus interactives et dynamiques qui peuvent être utilisées dans des applications web ou partagées en ligne. Plotly propose également plusieurs types de tracés spécialisés qui ne sont pas disponibles dans Seaborn, tels que les tracés de contour et les tracés de surface en 3D.
Cependant, Seaborn offre une syntaxe plus simple et une personnalisation plus aisée pour la création de visualisations statiques, ce qui en fait un meilleur choix pour certains types de projets.
Seaborn est une puissante bibliothèque de visualisation de données en Python qui offre une interface intuitive et facile à utiliser pour créer des graphiques statistiques informatifs. Grâce à sa vaste gamme d'outils de visualisation, Seaborn permet d'explorer et de communiquer rapidement et efficacement des informations à partir d'ensembles de données complexes.
Des diagrammes de dispersion et des diagrammes linéaires aux cartes thermiques et aux grilles à facettes, Seaborn offre une large gamme de visualisations pour répondre à différents besoins. De plus, la capacité de Seaborn à s'intégrer avec Pandas et Numpy en fait un outil indispensable pour les analystes de données et les scientifiques.
Grâce à ce guide d'initiation à Python, vous pouvez commencer à explorer le monde de la visualisation de données et communiquer efficacement vos idées à un public plus large.
Si vous souhaitez approfondir vos connaissances dans ce domaine, consultez nos cours Introduction à la visualisation de données avec Seaborn ou Visualisation de données intermédiaire avec Seaborn.
Tout au long de ces cours, vous apprendrez à utiliser les outils de visualisation avancés de Seaborn pour analyser divers ensembles de données du monde réel, tels que l'American Housing Survey, les données sur les frais d'inscription à l'université et les invités du Daily Show.
Vous pouvez également consulter l'aide-mémoire gratuit de Seaborn :
|
Python Seaborn : Visualisation de données statistiques |
En savoir plus sur Python et Seaborn
Cours
Cours
Cours
Tutoriel
DataCamp Team
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
Tutoriel
Laiba Siddiqui
Tutoriel
Aditya Sharma
Tutoriel
Abid Ali Awan
